詞法分析是編譯器實現(xiàn)的第一步。主要是分析輸入的源程序(字符串),輸出該字符串中出現(xiàn)的所有的合法的單詞。例如:int a = 3 + 5;經(jīng)過詞法分析會輸出 int,a,=,3,+,5和;這七個單詞。實現(xiàn)詞法分析器的官方做法是:
1.寫出各個單詞的正規(guī)式(正則表達式);
2.根據(jù)正規(guī)式構(gòu)造NFA(不確定的有限自動機);
3.將NFA轉(zhuǎn)換DFA(確定的有限自動機);
4.根據(jù)DFA就可以實現(xiàn)詞法分析器,寫出程序。
下面用實例來說明上面的各個步驟:
假設我們要實現(xiàn)一個很簡單的腳本,該腳本中只有兩種類型的單詞,一種就是變量,變量名的規(guī)則就是以字母開頭后面緊跟0個或多個字母或數(shù)字的的字符串,如 a 和 a12d3 等;另一種就是操作符,很簡單只有 &,|,~,(,),==,!= 這幾個。給出幾個腳本的實例:result1 & result2,rst1&(rst2|rst3),answer1 | (~answer2)。
按照上面的步驟,讓我們來看一下如何實現(xiàn)這個詞法分析器:
第一步:寫出正規(guī)式
變量的正規(guī)式是:letter(letter|digit)
*
操作符的正規(guī)式:&,|,~,(,)。由于操作符都是固定字符的,所以正規(guī)式就是它本身。
第二步:根據(jù)正規(guī)式構(gòu)造NFA
正規(guī)式構(gòu)造NFA的基礎是先構(gòu)造正規(guī)式中每個字符的NFA,如變量的正規(guī)式中只有兩個字符 letter 和 digit,他們的正規(guī)式分別是:
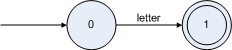
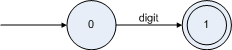
根據(jù)構(gòu)造|形式的NFA的公式可以構(gòu)造 letter|digit 的NFA如下圖:
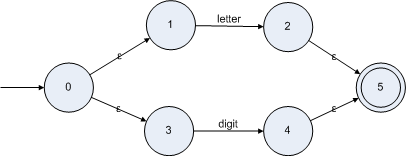
(letter|digit)
*的NFA為:
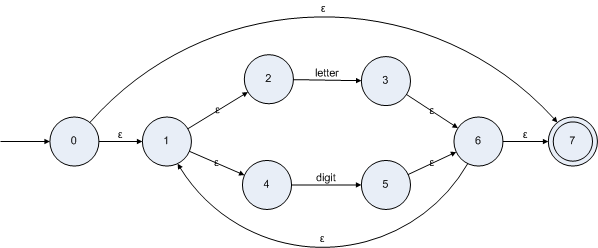
letter(letter|digit)
*的NFA為:

第三步:將NFA轉(zhuǎn)換為DFA
先是將所有通過
ε可以到達的狀態(tài)合并,由上圖NFA可以看出1,2,3,4,6,9都是通過ε可以直接用箭頭連接的,以此類推5,8,9,3,4,6和7,8,9,3,4,6都是可以合并稱一個狀態(tài)的,如下圖:
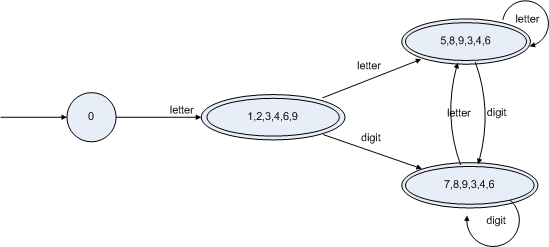
此圖用新的DFA表示如下:
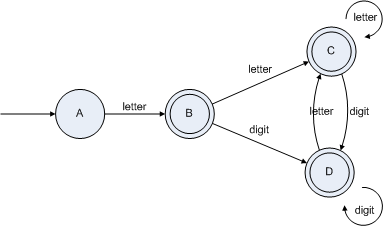
由于生成的DFA的狀態(tài)過多,需要將上面的DFA最小化,生成狀態(tài)數(shù)最少的DFA,最小化DFA的過程就是將那些無論怎樣轉(zhuǎn)換都仍然轉(zhuǎn)換到本組合內(nèi)部的狀態(tài)組合合并,如上圖{B,C,D}這三個狀態(tài)組合稱狀態(tài)組無論經(jīng)過letter還是digit轉(zhuǎn)換都仍然轉(zhuǎn)換到該組合,那么就可以將這三個狀態(tài)合并,如下圖:
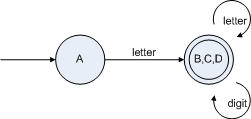 用新狀態(tài)表示為:
用新狀態(tài)表示為: 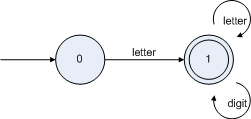
腳本中變量的DFA已經(jīng)構(gòu)造好了。
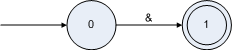
由于操作符都是固定字符,所以DFA比較簡單,下面給出幾個的圖示例子:

現(xiàn)在我們將各個單詞的DFA組合在一起,大致類似下圖:
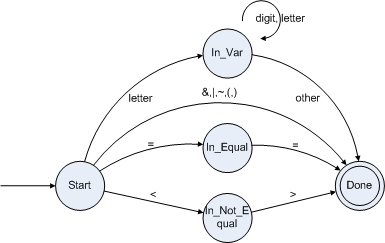
實際上,由于這種很簡單的例子不必套用這種正規(guī)的步驟來得到DFA,可以直接把圖畫出來。首先畫一個開始狀態(tài)(Start)和一個結(jié)束狀態(tài)(Done),然后再考慮各個單詞之間的關系將其分類,這種分類的過程就看你的經(jīng)驗了,依據(jù)各個單詞挨個字符被識別的過程即可畫出類似上圖的DFA,然后再根據(jù)這個DFA寫出詞法分析的程序來就非常的簡單了。
下面給出根據(jù)這個DFA的寫出的大概程序,這段代碼可執(zhí)行,但是沒有考慮各種意外、出錯以及相關優(yōu)化處理等,所以僅供參考,請斟酌使用:
1
2 public class ScriptScanner
3 {
4 private String scriptInput = null;
5
6 /**
7 * @param scriptInput
8 */
9 public ScriptScanner(String scriptInput)
10 {
11 this.scriptInput = scriptInput;
12 }
13
14 /** 標記當前讀取段的開始位置 */
15 private int start_read_pos = 0;
16
17 /** 當前位置 */
18 private int current_pos = 0;
19
20 private char readChar()
21 {
22 if (scriptInput == null || current_pos >= scriptInput.length())
23 return EOF;
24
25 return scriptInput.charAt(current_pos);
26 }
27
28 public Token getNextToken()
29 {
30 Token currentToken = null;
31
32 int state = STATE_START;
33
34 start_read_pos = current_pos;
35
36 while (state != STATE_DONE)
37 {
38 char ch = readChar();
39
40 switch (state)
41 {
42 case STATE_START:
43 {
44 if (Character.isLetter(ch))
45 {
46 state = STATE_IN_VAR;
47 }
48 else if (ch == '=')
49 {
50 state = STATE_IN_EQUAL;
51 }
52 else if (ch == '<')
53 {
54 state = STATE_IN_NOTEQUAL;
55 }
56 else
57 {
58 state = STATE_DONE;
59
60 switch (ch)
61 {
62 case EOF:
63 currentToken = new Token(TokenType.EOF);
64 break;
65
66 case '&':
67 currentToken = new Token(TokenType.AND);
68 break;
69
70 case '|':
71 currentToken = new Token(TokenType.OR);
72 break;
73
74 case '~':
75 currentToken = new Token(TokenType.NOT);
76 break;
77
78 case '(':
79 currentToken = new Token(TokenType.LPAREN);
80 break;
81
82 case ')':
83 currentToken = new Token(TokenType.RPAREN);
84 break;
85
86 default:
87 currentToken = new Token(TokenType.ERROR, "無法識別的字符");
88 break;
89 }
90
91 } // End: else
92
93 current_pos ++; // 開始狀態(tài)下除 EOF 外都需要將位置后移
94
95 break;
96
97 } // End: case STATE_START
98
99 case STATE_IN_EQUAL:
100 {
101 state = STATE_DONE;
102
103 if (ch == '=')
104 {
105 currentToken = new Token(TokenType.EQUAL);
106 }
107 else
108 {
109 currentToken = new Token(TokenType.ERROR, "錯誤的運算符");
110 }
111
112 current_pos ++;
113
114 break;
115
116 } // End: case STATE_IN_EQUAL
117
118 case STATE_IN_NOTEQUAL:
119 {
120 state = STATE_DONE;
121
122 if (ch == '>')
123 {
124 currentToken = new Token(TokenType.NOTEQUAL);
125 }
126 else
127 {
128 currentToken = new Token(TokenType.ERROR, "錯誤的運算符");
129 }
130
131 current_pos ++;
132
133 break;
134
135 } // End: case STATE_IN_NOTEQUAL
136
137 case STATE_IN_VAR:
138 {
139 if (! Character.isLetterOrDigit(ch))
140 {
141 state = STATE_DONE;
142
143 String value = scriptInput.substring(start_read_pos, current_pos);
144
145 currentToken = new Token(TokenType.ID, value);
146 }
147 else
148 {
149 current_pos ++;
150 }
151
152 break;
153
154 } // End: case STATE_IN_VAR
155
156 default:
157 {
158 state = STATE_DONE;
159
160 currentToken = new Token(TokenType.ERROR);
161 }
162 } // End: switch (state)
163 }
164
165 return currentToken;
166 }
167
168 public final static char EOF = '\0';
169
170 /*
171 * 定義 DFA 的狀態(tài)。
172 */
173
174 /** 開始狀態(tài) */
175 public final static int STATE_START = 0;
176
177 /** 當前 Token 是變量 */
178 public final static int STATE_IN_VAR = 1;
179
180 /** 當前 Token 是 "==" */
181 public final static int STATE_IN_EQUAL = 2;
182
183 /** 當前 Token 是 "<>" */
184 public final static int STATE_IN_NOTEQUAL = 3;
185
186 /** 當前 Token 結(jié)束 */
187 public final static int STATE_DONE = 4;
188 }
189
從代碼中可以看出,預先根據(jù)DFA定義了5個狀態(tài):STATE_START,STATE_IN_VAR,STATE_IN_EQUAL,STATE_IN_NOTEQUAL,STATE_DONE,然后每個記號(Token)都是從STATE_START開始到STATE_DONE結(jié)束,中間根據(jù)輸入字符的不同在各個狀態(tài)中不斷的轉(zhuǎn)換,直到識別出記號或者錯誤為止。由此可見只要畫好DFA寫代碼就簡單多了。
有興趣的朋友可以研究一下語法分析,生成語法樹,根據(jù)語法樹求值;也可以研究一下利用中綴表達式求值。
http://www.tkk7.com/qujinlong123/