|
2012年8月16日
#
這幾天自己琢磨起來javascript,以前都是看看沒有實戰過,現在覺得實戰起來果然錯誤多多,以后要不斷總結錯誤,關鍵可以減少調試時間,菜鳥啊: 1.js通常有一個地方錯誤了, 下邊的函數都不會再繼續執行啦(本來覺得很正常的事,但是...) 2.為什么open()請求服務器的時候,請求的servlet后邊要加一個參數變化,告知服務器這是一個新的請求???否則在IE8中請求失敗
var bojingNum = 0; //定義一個變量用來存儲xmlHttpRequest對象
var xmlHttp= null; //該函數用于創建一個xmlHttpRequest對象
function createXMLHttpRequest() { if (window.ActiveXObject) //ActiveXObject這個對象是IE瀏覽器提供的控件,所以有的網銀只支持這樣的控件的IE瀏覽器
{ xmlHttp = new ActiveXObject("Microsoft.XMLHTTP"); //IE瀏覽器生成的對象
} else if (window.XMLHttpRequest) //除了IE外的其他瀏覽器
{ xmlHttp = new XMLHttpRequest(); } } //這是一個通過ajax刷新統計圖的方法
function autoFlush() { //創建日期變量時間變量
var tempTime = new Date(); var tempParameter = tempTime.getTime(); //創建一個xmlHttpRequest對象
createXMLHttpRequest(); if(xmlHttp!= null) { //這里放置一個時間參數是為了讓服務器知道這是一個新的請求
xmlHttp.open("GET", "SerialDataSvt?tmd="+tempParameter); //將狀態觸發器綁定到一個函數
xmlHttp.onreadystatechange=processor; //請求發送
xmlHttp.send( null); } } //處理從服務器返回的xml文檔
function processor() { //定義一個變量用于存儲從服務器返回的結果
var result; if(xmlHttp.readyState==4) //如果響應完成
{ if(xmlHttp.status==200) //如果返回成功
{ //取出服務器返回的xml文檔的所有counter標簽的子節點
result = xmlHttp.responseXML.getElementsByTagName("data"); //alert(result);
//解析xml中的數據并更新統計圖狀態
for( var i = 0 ; i < result.length; i++) { //用于統計數據更新統計圖片狀態
var id =result[i].getAttribute("id"); //alert(id);
var dir =result[i].getAttribute("dir"); //alert(dir);
var datas =xmlHttp.responseXML.getElementsByTagName("dataContent")[0].childNodes[0].nodeValue; var addTime =xmlHttp.responseXML.getElementsByTagName("addTime")[0].childNodes[0].nodeValue; if(datas.substring(17,18)=="1") { document.getElementById("yujing"+(i+1)).innerHTML="<embed src='video/wartgroud.mp3' type=audio/x-ms-wma autostart='true' loop='true'>報警中  </embed> "; document.getElementById("yujingPic"+(i+1)).style.display = 'block'; bojingNum++; document.getElementById("yujingNum"+(i+1)).innerHTML="預警次數:"+bojingNum; } else { document.getElementById("yujing"+(i+1)).innerHTML="暫無報警 "; document.getElementById("yujingPic"+(i+1)).style.display = 'none'; } document.getElementById("n_nodeID"+i).innerHTML= id+dir; document.getElementById("n_nodeData"+i).innerHTML= datas; document.getElementById("n_nodeTime"+i).innerHTML= addTime; document.getElementById("s_nodeID"+i).innerHTML= id+dir; document.getElementById("s_nodeData"+i).innerHTML= datas; document.getElementById("s_nodeTime"+i).innerHTML= addTime; document.getElementById("e_nodeID"+i).innerHTML= id+dir; document.getElementById("e_nodeData"+i).innerHTML= datas; document.getElementById("e_nodeTime"+i).innerHTML= addTime; document.getElementById("w_nodeID"+i).innerHTML= id+dir; document.getElementById("w_nodeData"+i).innerHTML= datas; document.getElementById("w_nodeTime"+i).innerHTML= addTime; } } } } //每隔一秒就執行一次autoFlush方法
setInterval(autoFlush, 2000);
昨天看到C#群里有人問一個投票功能如何實現... 我對此很感興趣,為了練習一下,就有了以下代碼。 投票功能使用jQuery實現..純html代碼...數據通過json字符串傳遞,通過 eval轉換為json對象 投票功能分為: 1.設置投票內容: 
2.投票: 
3.投票結果: 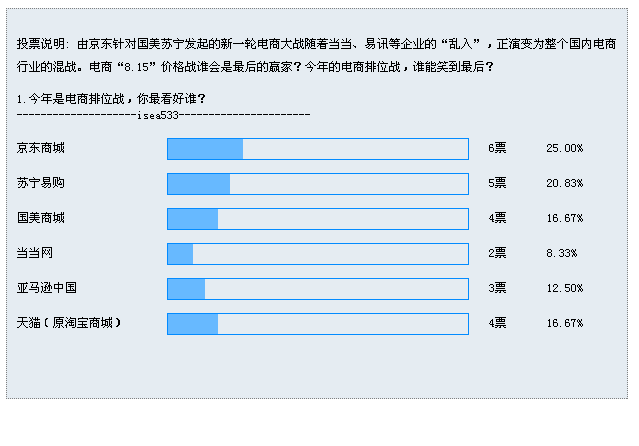
文件列表: 
傳值:
{
info: " 由京東針對國美蘇寧發起的新一輪電商大戰隨著當當、易訊等企業的“亂入”,正演變為整個國內電商行業的混戰。電商“8.15”價格戰誰會是最后的贏家?今年的電商排位戰,誰能笑到最后?<br/><br/>1.今年是電商排位戰,你最看好誰?<br/>--------------------isea533----------------------",
choices: [{
name: "choice0",
value: "京東商城",
num: 6,
percent: 0.25
},
{
name: "choice1",
value: "蘇寧易購",
num: 5,
percent: 0.20833333333333334
},
{
name: "choice2",
value: "國美商城",
num: 4,
percent: 0.16666666666666666
},
{
name: "choice3",
value: "當當網",
num: 2,
percent: 0.08333333333333333
},
{
name: "choice4",
value: "亞馬遜中國",
num: 3,
percent: 0.125
},
{
name: "choice5",
value: "天貓(原淘寶商城)",
num: 4,
percent: 0.16666666666666666
}]
}
jQuery對象初始化的傳參方式包括:
1.$(DOMElement)
2.$('<h1>...</h1>'), $('#id'), $('.class') 傳入字符串, 這是最常見的形式, 這種傳參數經常也傳入第二個參數context指定上下文,其中context參數可以為$(...), DOMElement
3.$(function() {}); <===> $(document).ready(function() { });
4.$({selector : '.class', context : context}) <===> $('.class', context)
jQuery.fn = jQuery.prototype = {
constructor: jQuery,
init: function( selector, context, rootjQuery ) {
var match, elem, ret, doc;
// 處理$(""), $(null), $(undefined), $(false)這幾種參數,直接返回this
if ( !selector ) {
return this;
}
// 當傳參selector為DOM結點時,將context置為selector
if ( selector.nodeType ) {
this.context = this[0] = selector;
this.length = 1;
return this;
}
// Handle HTML strings
// 當傳入的selector參數為字符串時,
if ( typeof selector === "string" ) {
if ( selector.charAt(0) === "<" && selector.charAt( selector.length - 1 ) === ">" && selector.length >= 3 ) {
// Assume that strings that start and end with <> are HTML and skip the regex check
match = [ null, selector, null ];
} else {
match = rquickExpr.exec( selector );
}
// Match html or make sure no context is specified for #id
if ( match && (match[1] || !context) ) {
// HANDLE: $(html) -> $(array)
if ( match[1] ) {
context = context instanceof jQuery ? context[0] : context;
doc = ( context && context.nodeType ? context.ownerDocument || context : document );
// scripts is true for back-compat
selector = jQuery.parseHTML( match[1], doc, true );
if ( rsingleTag.test( match[1] ) && jQuery.isPlainObject( context ) ) {
this.attr.call( selector, context, true );
}
return jQuery.merge( this, selector );
// HANDLE: $(#id)
} else {
elem = document.getElementById( match[2] );
// Check parentNode to catch when Blackberry 4.6 returns
// nodes that are no longer in the document #6963
if ( elem && elem.parentNode ) {
// Handle the case where IE and Opera return items
// by name instead of ID
if ( elem.id !== match[2] ) {
return rootjQuery.find( selector );
}
// Otherwise, we inject the element directly into the jQuery object
this.length = 1;
this[0] = elem;
}
this.context = document;
this.selector = selector;
return this;
}
// HANDLE: $(expr, $(...))
} else if ( !context || context.jquery ) {
return ( context || rootjQuery ).find( selector );
// HANDLE: $(expr, context)
// (which is just equivalent to: $(context).find(expr)
} else {
return this.constructor( context ).find( selector );
}
// HANDLE: $(function)
// Shortcut for document ready
// 當selector為function時相當于$(document).ready(selector);
} else if ( jQuery.isFunction( selector ) ) {
return rootjQuery.ready( selector );
}
// 當selector參數為{selector:'#id', context:document}之類時,重置屬性selector和context
if ( selector.selector !== undefined ) {
this.selector = selector.selector;
this.context = selector.context;
}
return jQuery.makeArray( selector, this );
}
};
2012年8月12日
#
最近項目任務繁重,更新博客會較慢,不過有時間希望可以把自己的積累分享出來。 JavaScript正則實戰(會根據最近寫的不斷更新) 1、javascript 正則對象替換創建 和用法: /pattern/flags 先簡單案例學習認識下replace能干什么 正則表達式構造函數: new RegExp("pattern"[,"flags"]); 正則表達式替換變量函數:stringObj.replace(RegExp,replace Text); 參數說明:
pattern -- 一個正則表達式文本
flags -- 如果存在,將是以下值:
g: 全局匹配
i: 忽略大小寫
gi: 以上組合
//下面的例子用來獲取url的兩個參數,并返回urlRewrite之前的真實Url
var reg=new RegExp("(http://www.qidian.com/BookReader/)(\\d+),(\\d+).aspx","gmi");
var url="http://www.qidian.com/BookReader/1017141,20361055.aspx";
//方式一,最簡單常用的方式
var rep=url.replace(reg,"$1ShowBook.aspx?bookId=$2&chapterId=$3");
alert(rep);
//方式二 ,采用固定參數的回調函數
var rep2=url.replace(reg,function(m,p1,p2,p3){return p1+"ShowBook.aspx?bookId="+p3+"&chapterId="+p3});
alert(rep2);
//方式三,采用非固定參數的回調函數
var rep3=url.replace(reg,function(){var args=arguments; return args[1]+"ShowBook.aspx?bookId="+args[2]+"&chapterId="+args[3];});
alert(rep3);
//方法四
//方式四和方法三很類似, 除了返回替換后的字符串外,還可以單獨獲取參數
var bookId;
var chapterId;
function capText()
{
var args=arguments;
bookId=args[2];
chapterId=args[3];
return args[1]+"ShowBook.aspx?bookId="+args[2]+"&chapterId="+args[3];
}
var rep4=url.replace(reg,capText);
alert(rep4);
alert(bookId);
alert(chapterId);
//使用test方法獲取分組
var reg3=new RegExp("(http://www.qidian.com/BookReader/)(\\d+),(\\d+).aspx","gmi");
reg3.test("http://www.qidian.com/BookReader/1017141,20361055.aspx");
//獲取三個分組
alert(RegExp.$1);
alert(RegExp.$2);
alert(RegExp.$3);
2、 學習最常用的 test exec match search replace split 6個方法 1) test 檢查指定的字符串是否存在
var data = “123123″;
var reCat = /123/gi;
alert(reCat.test(data)); //true
//檢查字符是否存在 g 繼續往下走 i 不區分大小寫 2) exec 返回查詢值
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /cat/i;
alert(reCat.exec(data)); //Cat 3)match 得到查詢數組
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /cat/gi;
var arrMactches = data.match(reCat)
for (var i=0;i < arrMactches.length ; i++)
{
alert(arrMactches[i]); //Cat cat
} 4) search 返回搜索位置 類似于indexof
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /cat/gi;
alert(data.search(reCat)); //23 5) replace 替換字符 利用正則替換
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /cat/gi;
alert(data.replace(reCat,”libinqq”)); 6)split 利用正則分割數組
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /\,/;
var arrdata = data.split(reCat);
for (var i = 0; i < arrdata.length; i++)
{
alert(arrdata[i]);
} 3、常用表達式收集:"^\\d+$" //非負整數(正整數 + 0)
"^[0-9]*[1-9][0-9]*$" //正整數
"^((-\\d+)|(0+))$" //非正整數(負整數 + 0)
"^-[0-9]*[1-9][0-9]*$" //負整數
"^-?\\d+$" //整數
"^\\d+(\\.\\d+)?$" //非負浮點數(正浮點數 + 0)
"^(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*))$"
//正浮點數
"^((-\\d+(\\.\\d+)?)|(0+(\\.0+)?))$" //非正浮點數(負浮點數 + 0)
"^(-(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"
//負浮點數
"^(-?\\d+)(\\.\\d+)?$" //浮點數
"^[A-Za-z]+$" //由26個英文字母組成的字符串
"^[A-Z]+$" //由26個英文字母的大寫組成的字符串
"^[a-z]+$" //由26個英文字母的小寫組成的字符串
"^[A-Za-z0-9]+$" //由數字和26個英文字母組成的字符串
"^\\w+$" //由數字、26個英文字母或者下劃線組成的字符串
"^[\\w-]+(\\.[\\w-]+)*@[\\w-]+(\\.[\\w-]+)+$" //email地址
"^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$" //url
"^[A-Za-z0-9_]*$"。
============================================正則表達式基礎知識============================================== ^ 匹配一個輸入或一行的開頭,/^a/匹配"an A",而不匹配"An a"
$ 匹配一個輸入或一行的結尾,/a$/匹配"An a",而不匹配"an A"
* 匹配前面元字符0次或多次,/ba*/將匹配b,ba,baa,baaa
+ 匹配前面元字符1次或多次,/ba+/將匹配ba,baa,baaa
? 匹配前面元字符0次或1次,/ba?/將匹配b,ba
(x) 匹配x保存x在名為$1...$9的變量中
x|y 匹配x或y
{n} 精確匹配n次
{n,} 匹配n次以上
{n,m} 匹配n-m次
[xyz] 字符集(character set),匹配這個集合中的任一一個字符(或元字符)
[^xyz] 不匹配這個集合中的任何一個字符
[\b] 匹配一個退格符
\b 匹配一個單詞的邊界
\B 匹配一個單詞的非邊界
\cX 這兒,X是一個控制符,/\cM/匹配Ctrl-M
\d 匹配一個字數字符,/\d/ = /[0-9]/
\D 匹配一個非字數字符,/\D/ = /[^0-9]/
\n 匹配一個換行符
\r 匹配一個回車符
\s 匹配一個空白字符,包括\n,\r,\f,\t,\v等
\S 匹配一個非空白字符,等于/[^\n\f\r\t\v]/
\t 匹配一個制表符
\v 匹配一個重直制表符
\w 匹配一個可以組成單詞的字符(alphanumeric,這是我的意譯,含數字),包括下劃線,如[\w]匹配"$5.98"中的5,等于[a-zA-Z0-9]
\W 匹配一個不可以組成單詞的字符,如[\W]匹配"$5.98"中的$,等于[^a-zA-Z0-9]。
在瀏覽網頁時,經常會看到分頁顯示的頁面。如果想把大量的數據提供給瀏覽者,分頁顯示是個非常實用的方法。分頁顯示數據能夠幫助瀏覽者更好地查看信息,能夠有條理的顯示信息。
在傳統的web技術中,分頁顯示的相關操作都是在服務器端進行的,服務器端獲取客戶端的請求分頁,并根據請求頁數獲取指定的結果集。最后把結果集中的數據返回到客戶端,這時返回結果中不但包含了數據,還可能包含了數據的顯示樣式。客戶端的每一次數據更新,都會重新打開一個網頁,如果網頁中包含了很多html元素,就會造成網頁打開速度較慢的情況。
為了顯示部分數據,而需要加載整個頁面的數據,顯得有點得不償失。使用Ajax技術可以很好的彌補這些問題,服務器端只傳輸數據庫表中的數據,客戶端獲取這些數據只更新局部內容,與數據無關的其他元素保持不變。
現在創建一個實例,以演示使用Ajax技術實現數據的分頁顯示。該實例的代碼實現分為服務器端和客戶端。
1,準備工作
我們這里使用Mysql數據庫,我在shop數據庫中創建了一張mobileshop表,這張表有兩個字段name,model。
打開記事本,輸入下列代碼:
<%@ page language="java" import="java.util.*,java.sql.*,java.io.*" pageEncoding="GBK"%>
<%
class DBManager{
String userName="root";
String password="123456";
Connection conn=null;
Statement stmt=null;
String url="jdbc:mysql://localhost:3306/shop";
ResultSet rst;
public DBManager(String sql){
try {
Class.forName("com.mysql.jdbc.Driver");
conn=DriverManager.getConnection(url,userName,password);
stmt=conn.createStatement();
rst=stmt.executeQuery(sql);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public ResultSet getResultSet(){
return rst;
}
}
%> 將上述代碼保存為Conn.jsp,用于返回查詢結果集。 2,服務器端代碼
在本實例中,服務器端代碼具有獲取客戶端請求頁數和產生指定記錄集的功能。打開記事本,輸入下列代碼:
<%@ page contentType="text/html; charset=utf-8" import="java.sql.*" errorPage="" %>
<%@ include file="Conn.jsp" %>
<%@ page import="java.util.*" %>
<%@ page import="java.io.*" %>
<%
try
{
ResultSet rs=new DBManager("select name,model from mobileshop").getResultSet();
int intPageSize; //一頁顯示的記錄數
int intRowCount; //記錄的總數
int intPageCount; //總頁數
int intPage; //待顯示的頁碼
String strPage;
int i;
intPageSize=2; //設置一頁顯示的記錄數
strPage=request.getParameter("page"); //取得待顯示的頁碼
if(strPage==null) //判斷strPage是否等于null,如果是,則顯示第一頁數據
{
intPage=1;
}else{
intPage=java.lang.Integer.parseInt(strPage); //將字符串轉化為整形
}
if(intPage<1)
{
intPage=1;
}
//獲取記錄總數
rs.last();
intRowCount=rs.getRow();
//計算總頁數
intPageCount=(intRowCount+intPageSize-1)/intPageSize;
//調整顯示的頁碼
if(intPage>intPageCount) intPage=intPageCount;
if(intPageCount>0)
{
//將記錄指針定位到待顯示頁的第一條記錄上
rs.absolute((intPage-1)*intPageSize+1);
}
//下面用于顯示數據
i=0;
StringBuffer content=new StringBuffer("");
response.setContentType("text/xml");
response.setHeader("Cache-Control","no-cache");
content.append("<?xml version=\"1.0\" encoding=\"UTF-8\" ?>");
content.append("<contents>");
while(i<intPageSize && !rs.isAfterLast())
{
String name=rs.getString("name");
String email=rs.getString("model");
content.append("<content>");
content.append("<name>"+ name +"</name>");
content.append("<model>"+email+"</model>");
content.append("</content>");
rs.next();
i++;
}
content.append("</contents>");
System.out.print(content);
out.print(content);
}
catch(Exception e)
{
e.printStackTrace();
}
%>
網頁自動刷新功能在web網站上已經屢見不鮮了,如即時新聞信息,股票信息等,都需要不斷獲取最新信息。在傳統的web實現方式中,想要實現類似的效果,必須進行整個頁面的刷新,在網絡速度受到一定限制的情況下,這種因為一個局部變動而牽動整個頁面的處理方式顯得有些得不償失。Ajax技術的出現很好的解決了這個問題,利用Ajax技術可以實現網頁的局部刷新,只更新指定的數據,并不更新其他的數據。
現在創建一個實例,以演示網頁的自動刷新功能,該實例模擬火車侯票大廳的顯示字幕。 1,服務器端代碼
該實例服務器端代碼的功能比較簡單,即產生一個隨機數,并以XML文件形式返回給客戶端。打開記事本,輸入下列代碼:
<%@ page contentType="text/html; charset=gb2312" %>
<%
response.setContentType("text/xml; charset=UTF-8");//設置輸出信息的格式及字符集
response.setHeader("Cache-Control","no-cache");
out.println("<response>");
for(int i=0;i<2;i++){
out.println("<name>"+(int)(Math.random()*10)+"</name>");
out.println("<count>" +(int)(Math.random()*100)+ "</count>");
}
out.println("</response>");
out.close();
%>
保存上述代碼,名稱為auto.jsp。在該文件中,使用java.lang包中的Math類,產生一個隨機數。
2,客戶端代碼
本實例客戶端代碼主要利用服務器端返回的數字,指定顯示樣式。打開記事本,輸入下列代碼
<%@ page language="java" import="java.util.*" pageEncoding="GBK"%>
<head>
<META http-equiv=Content-Type content="text/html; charset=gb2312">
</head>
<script language="javascript">
var XMLHttpReq;
//創建XMLHttpRequest對象
function createXMLHttpRequest() {
if(window.XMLHttpRequest) { //Mozilla 瀏覽器
XMLHttpReq = new XMLHttpRequest();
}
else if (window.ActiveXObject) { // IE瀏覽器
try {
XMLHttpReq = new ActiveXObject("Msxml2.XMLHTTP");
} catch (e) {
try {
XMLHttpReq = new ActiveXObject("Microsoft.XMLHTTP");
} catch (e) {}
}
}
}
//發送請求函數
function sendRequest() {
createXMLHttpRequest();
var url = "auto.jsp";
XMLHttpReq.open("GET", url, true);
XMLHttpReq.onreadystatechange = processResponse;//指定響應函數
XMLHttpReq.send(null); // 發送請求
}
// 處理返回信息函數
function processResponse() {
if (XMLHttpReq.readyState == 4) { // 判斷對象狀態
if (XMLHttpReq.status == 200) { // 信息已經成功返回,開始處理信息
DisplayHot();
setTimeout("sendRequest()", 1000);
} else { //頁面不正常
window.alert("您所請求的頁面有異常。");
}
}
}
function DisplayHot() {
var name = XMLHttpReq.responseXML.getElementsByTagName("name")[0].firstChild.nodeValue;
var count = XMLHttpReq.responseXML.getElementsByTagName("count")[0].firstChild.nodeValue;
document.getElementById("cheh").innerHTML = "T-"+name+"次列車";
document.getElementById("price").innerHTML = count+"元";
}
</script>
<body onload =sendRequest()>
<table style="BORDER-COLLAPSE: collapse" borderColor=#5555555 cellSpacing=0 cellPadding=0 width=200 border=0>
<TR>
<TD align=middle bgColor=#abc2d0 height=19 colspan="2"><B>開往北京的列車</B> </TD>
</TR>
<tr>
<td height="20"> 車號:</td>
<td height="20" id="cheh"> </td>
</tr>
<tr>
<td height="20"> 價格:</td>
<td height="20" id="price"> </td>
</tr>
</table>
</body>
將上述代碼保存,名稱為autoRefresh.jsp。在該文件中,createXMLHttpRequest()函數用于創建異步調用對象;sendRequest()函數用于發送請求到客戶端;processResponse()函數用于處理服務器端的響應,在處理過程中調用DisplayHot()函數設定數據的顯示樣式。其中,setTimeout(“sendRequest()”,1000)函數的含義為每隔1秒的時間調用sendRequest()函數,該函數在Ajax頁面刷新中起了一個主導作用。DisplayHot()函數主要用于從服務器端返回的XML文件進行解析,并獲取返回數據,顯示在當前頁面。
2012年7月30日
#
機房收費系統完成了已經有很長一段時間了,本以為就此結束了。可是,前幾天突然要求對其進行驗收了。 開始的時候,感覺驗收就驗收沒什么。可是,有小道消息稱,做的不好的有可能重構。如果是因為當初的設計思路或者是邏輯錯誤而重構,那無話可說,必須要重構。但是如果是因為一些注釋、UML圖、命名規范等而重構,都會讓大家笑話。 于是,在前面人驗收的時候,后面的人都在討論驗收人員的側重點。然后大家在修改自己的收費系統。 通過這次驗收,雖然我沒有被要求重構,但是,在驗收過程中還是出現了很多的問題,驗收人員也給提出了很多的寶貴意見。 首先就是出現的問題。 命名不規范。尤其是參數的命名,當初以為參數只是使用在某一個方法或者函數中,不會和其他的類、函數產生關系,不用太在意它的命名。可是,這種代碼只適合與自己看,其他人看你的代碼就會感覺不舒服,同時給人一種外行的感覺。 注釋不全。雖說對于類、方法和函數都做了注釋,但是,不是很完整。例如,所有的remarks都是空著的。通過驗收人員的講解,理解了它的作用,記錄版本號,編寫時間以及修改時間。還有就是,對于注釋的代碼,不要刪除,而應該保留并完整寫明修改人,以及修改的時間。雖說是個人版的,但對于注釋,都是被刪除了。 文檔不全。當時做收費系統的時候,只寫了需求、概要、數據庫設計以及詳細設計文檔。其他的則沒有寫。當初就是由于惰性的原因吧,感覺寫文檔太枯燥了,就急于編寫代碼了,當系統實現之后,就以為系統實現了就行了,至于其他文檔就算了吧。 對UML圖理解不深。當初在畫UML圖的時候,對用例圖理解的不是太深,以至于我的用例圖中的用例都是窗體。在驗收過程中,自己都不禁問自己,當初是怎么想的呢?怎么會出現那種用例圖呢? 再說一些個別人出現的問題吧(也算是給自己提個醒) 文檔、數據庫沒了。在做完機房收費系統到現在有很長的時間了,有的同學重裝了系統。有的沒有提前把數據庫中的數據備份,導致現在沒有了原先的數據。而文檔,有的是在第一遍的基礎上修改的,原先的也沒有備份。導致現在的文檔是合作版的時候,自己第三次修改的文檔,前兩次的文檔都沒了。 UML圖不知道哪一個是最新版本。有的同學UML圖畫了好幾遍,但是在文件保存的時候,沒有注意到命名,沒有表明版本號。以至于尋找的時候花費了很長時間,有的甚至就找不到了。 應該說,通過這次驗收,讓我們認識到了當初所做的系統存在著很大的不足。這次要求我們都要補全文檔、注釋,規范命名等等,讓我們長了一個記性。對我們來說沒有壞處。同時通過這次驗收,也讓我們認識到,文件備份、管理、保存的重要性。在以后大家都會記住這次的驗收來提醒自己。
為了檢查八期分層重要階段學習成果,老師,七期全體成員參與驗收工作。 在提高班,四年的學習中,分了幾個重要的模塊。其中在重要的關鍵的方向性的學習上是需要把控的,是需要及時檢驗以及驗收的。 在驗收八期學習的過程中,不僅發現他們的問題,同時也發現自己的問題。 驗收工作,不僅是驗收他們,同時也是驗收自己對此知識點掌握的情況。 首先說一下驗收過程中,八期普遍存在的問題。 1. 對文檔的認識不夠,導致文檔與程序不對應。 包圖與程序集的對應,這個沒意識到。命名是其中一方面,還有就是其中包圖中的每條線的作用,意義,以及在代碼中體現。 2. UML認識不夠,需要進步學習。 UML中的共九種圖,常用的像用例圖,類圖,對象圖,時序圖,包圖,活動圖,狀態圖這幾種,每種圖的符號以及畫法掌握不夠。并且對每種圖的概念以及適合什么場景有所欠缺。并且圖中的關系需要進步掌握。比如用例之間的包含關系、擴展關系等,還有UML中的五種關系以及在代碼中的體現。 3. 對分層的認識不夠,導致假隔離真耦合。 不僅僅把程序分成了UI,BLL,DAL,但是最主要的是各個層之間的隔離。比如因為DAL生成的路徑的原因,導致了明明UI與DAL隔離,卻因為路徑問題而再次耦合,結果確是一種假隔離真耦合。還有就是BLL,DAL引入UI中的某個包,導致了后面與前面分層再次耦合。 4. 規范問題。命名規范,注釋規范。 5. 對文檔中的內容理解不到位,導致人云亦云。 常寫的幾種需求說明書,概要說明書,詳細說明書。對其中的內容不了解,不知道文檔中應該寫什么。也不知道那些圖應該放在那個文檔中。導致了結果,每個文檔中都有重復的東西。 6. 項目驅動未做到。 大家著急開發,忽略文檔。在開發過程中,文檔一直沒有起到任何作用,所以對文檔沒有深度認識。 八期出現的問題,確實可以理解。當時的七期,也翻過如此的錯誤。這畢竟是八期第一次的個人版。做到這種程度,已經是相當好了。當初的七期,幾乎每人重構了三四遍。對這個分層,文檔才有了今天的理解以及重視。 然后說一下驗收過程中,自己的收獲問題。 1. 發言溝通交流。通過這次發言機會,鍛煉與他人溝通,交流。 2. 在驗收他們的過程中,進一步考驗自己的對過去知識點的理解。 提問他們,促進他們的思考,同時與自己所學的知識進行比對,補充自己的欠缺。 其中有個學生的包圖,自己也理解錯了,對工廠模式,抽象工廠模式,反射,以及接口,多態這些應用有了進一步認識。 3. 對某個知識點的問題學習。 其中有個學生用了單例模式。單利模式的作用,以及好處都是可以理解的,但是當時的他利用的嵌套類實現的單例模式,對嵌套類,靜態塊有了進一步認識。 另一個是錯誤處理。Trycatch,throw,throws知識點的學習。 4. 對文檔中的內容進一步補充。 全體七期發言,正好補充自己對文檔的認識不足的問題。 5. 驗收中記錄下自己的不懂的問題。 對UML中活動圖,狀態圖,構件圖,部署圖的概念理解,但是畫出某一個圖,無法確定對與錯,說明自己對這方面欠缺。 6. 再次加深文檔的問題。規范問題。 當把問題提給八期的學生時,同時也在提給自己。嚴格要求自己,以專業程序猿的身份要求自己。各種文檔,代碼規范化。 驗收別人,也在驗收自己。抓住一切可以提升自己的機會。
2012年7月26日
#
兩步
(1)date 042612492005
(2)hwclock -w
第一步的意思是設置時間,設置完了可以用date命令查看對不對...注意是月日時分年
第二步的意思是寫入主板的rtc芯片..
=======================================
su -c 'date -s 月/日/年'
su -c 'date -s 時:分:秒'
=======================================
了解Linux的時鐘
由于Linux時鐘和Windows時鐘從概念的分類、使用到設置都有很大的不同,所以,搞清楚Linux時鐘的工作方式與設置操作,不僅對于Linux初學者有著重大意義,而且對于使用Linux服務器的用戶來說尤為重要。
Linux時鐘的分類
Windows 時鐘大家可能十分熟悉了,Linux時鐘在概念上類似Windows時鐘顯示當前系統時間,但在時鐘分類和設置上卻和Windows大相徑庭。和 Windows不同的是,Linux將時鐘分為系統時鐘(System Clock)和硬件(Real Time Clock,簡稱RTC)時鐘兩種。系統時間是指當前Linux Kernel中的時鐘,而硬件時鐘則是主板上由電池供電的那個主板硬件時鐘,這個時鐘可以在BIOS的“Standard BIOS Feture”項中進行設置。
既然Linux有兩個時鐘系統,那么大家所使用的Linux默認使用哪種時鐘系統呢?會不回出現兩種系統時鐘沖突的情況呢?這些疑問和擔心不無道理。首先,Linux并沒有默認哪個時鐘系統。當Linux啟動時,硬件時鐘會去讀取系統時鐘的設置,然后系統時鐘就會獨立于硬件運作。
從Linux啟動過程來看,系統時鐘和硬件時鐘不會發生沖突,但Linux中的所有命令(包括函數)都是采用的系統時鐘設置。不僅如此,系統時鐘和硬件時鐘還可以采用異步方式,見圖1所示,即系統時間和硬件時間可以不同。這樣做的好處對于普通用戶意義不大,但對于Linux網絡管理員卻有很大的用處。例如,要將一個很大的網絡中(跨越若干時區)的服務器同步,假如位于美國紐約的Linux服務器和北京的 Linux服務器,其中一臺服務器無須改變硬件時鐘而只需臨時設置一個系統時間,如要將北京服務器上的時間設置為紐約時間,兩臺服務器完成文件的同步后,再與原來的時鐘同步一下即可。這樣系統和硬件時鐘就提供了更為靈活的操作。
設置Linux的時鐘
在 Linux中,用于時鐘查看和設置的命令主要有date、hwclock和clock。其中,clock和hwclock用法相近,只不過clock命令除了支持x86硬件體系外,還支持Alpha硬件體系。由于目前絕大多數用戶使用x86硬件體系,所以可以視這兩個命令為一個命令來學習。
1.在虛擬終端中使用date命令來查看和設置系統時間
查看系統時鐘的操作:
# date
設置系統時鐘的操作:
# date 091713272003.30
通用的設置格式:
# date 月日時分年.秒
2.使用hwclock或clock命令查看和設置硬件時鐘
查看硬件時鐘的操作:
# hwclock --show 或
# clock --show
2003年09月17日 星期三 13時24分11秒 -0.482735 seconds
設置硬件時鐘的操作:
# hwclock --set --date="09/17/2003 13:26:00"
或者
# clock --set --date="09/17/2003 13:26:00"
通用的設置格式:hwclock/clock --set --date=“月/日/年 時:分:秒”。
3.同步系統時鐘和硬件時鐘
Linux系統(筆者使用的是Red Hat 8.0,其它系統沒有做過實驗)默認重啟后,硬件時鐘和系統時鐘同步。如果不大方便重新啟動的話(服務器通常很少重啟),使用clock或hwclock命令來同步系統時鐘和硬件時鐘。
硬件時鐘與系統時鐘同步:
# hwclock --hctosys
或者
# clock --hctosys
上面命令中,--hctosys表示Hardware Clock to SYStem clock。
系統時鐘和硬件時鐘同步:
# hwclock --systohc
或者
# clock --systohc
使用圖形化系統設置工具設置時間
對于初學者來,筆者推薦使用圖形化的時鐘設置工具,如Red Hat 8.0中的日期與時間設置工具,可以在虛擬終端中鍵“redhat-config-time”命令,或者選擇“K選單/系統設置/日期與時間”來啟動日期時間設置工具。使用該工具不必考慮系統時間和硬件時間,只需從該對話框中設置日期時間,可同時設置、修改系統時鐘和硬件時鐘。
Internet同步時鐘設置
在Windows XP日期與時間設置中有一項與Internet同步的功能,有了這項功能只要上網便可得到十分準確的時間。Red Hat 8.0也提供了這樣的功能,在日期與時間設置工具對話框中的下部,有一個“啟用網絡時間協議”的選項,將該項選中就可以使用網絡時間協議來同步Linux 系統時鐘。選中該項后,其下面的服務器下拉列表框就變為可用狀態,可從中選擇一個時間服務器作為遠程時間服務器。然后單擊確定按鈕,便可連接所設定的時間服務器,并與之同步時間。
關于網絡校時: ntpdate
基本上,網絡校時需要兩個步驟:
1. 由 time.stdtime.gov.tw 取得最新的時間,并實時更新 Linux 系統時間;
2. 更改 BIOS 的時間。
[root @test root]# ntpdate time.stdtime.gov.tw
[root @test root]# clock –w
描述
tar 程序用于儲存或展開 tar 存檔文件。存檔文件可放在磁盤中 ,也可以存為普通文件。 tar是需要參數的,可選的參數是A、c、d、r、t、u、x,您在使用tar時必須首先為 tar 指定至少一個參數;然后,您必須指定要處理的文件或目錄。如果指定一個目錄則該目錄下的所有子目錄都將被加入存檔。
應用舉例: 1)展開 abc.tar.gz 使用命令: tar xvzf abc.tar.gz 展開 abc.tar 使用命令: tar xvf abc.tar 2)將當前目錄下的 man 目錄及其子目錄存成存檔 man.tar tar cf man.tar ./man
參數說明
運行tar時必須要有下列參數中的至少一個才可運行 -A, --catenate, --concatenate
將一存檔與已有的存檔合并
-c, --create
建立新的存檔
-d, --diff, --compare
比較存檔與當前文件的不同之處
--delete
從存檔中刪除
-r, --append
附加到存檔結尾
-t, --list
列出存檔中文件的目錄
-u, --update
僅將較新的文件附加到存檔中
-x, --extract, --get
從存檔展開文件 其他參數 --atime-preserve
不改變轉儲文件的存取時間 -b, --block-size N
指定塊大小為 Nx512 字節(缺省時 N=20) -B, --read-full-blocks
讀取時重組塊(???!!!) -C, --directory DIR 轉到指定的目錄 --checkpoint
讀取存檔時顯示目錄名 -f, --file [HOSTNAME:]F
指定存檔或設備 (缺省為 /dev/rmt0) --force-local
強制使用本地存檔,即使存在克隆 -F, --info-script F --new-volume-script F
在每個磁盤結尾使用腳本 F (隱含 -M) -G, --incremental
建立老 GNU 格式的備份 -g, --listed-incremental F
建立新 GNU 格式的備份 -h, --dereference
不轉儲動態鏈接,轉儲動態鏈接指向的文件。 -i, --ignore-zeros
忽略存檔中的 0 字節塊(通常意味著文件結束) --ignore-failed-read
在不可讀文件中作 0 標記后再退出??? -k, --keep-old-files
保存現有文件;從存檔中展開時不進行覆蓋 -K, --starting-file F
從存檔文件 F 開始 -l, --one-file-system
在本地文件系統中創建存檔 -L, --tape-length N
在寫入 N*1024 個字節后暫停,等待更換磁盤 -m, --modification-time
當從一個檔案中恢復文件時,不使用新的時間標簽 -M, --multi-volume
建立多卷存檔,以便在幾個磁盤中存放 -N, --after-date DATE, --newer DATE
僅存儲時間較新的文件 -o, --old-archive, --portability
以 V7 格式存檔,不用 ANSI 格式 -O, --to-stdout
將文件展開到標準輸出 -p, --same-permissions, --preserve-permissions
展開所有保護信息 -P, --absolute-paths
不要從文件名中去除 '/' --preserve
like -p -s
與 -p -s 相似 -R, --record-number
顯示信息時同時顯示存檔中的記錄數 --remove-files
建立存檔后刪除源文件 -s, --same-order, --preserve-order
???
--same-owner
展開以后使所有文件屬于同一所有者 -S, --sparse
高效處理 -T, --files-from F
從文件中得到要展開或要創建的文件名 --null
讀取空結束的文件名,使 -C 失效 --totals
顯示用 --create 參數寫入的總字節數 -v, --verbose
詳細顯示處理的文件 -V, --label NAME
為存檔指定卷標 --version
顯示 tar 程序的版本號 -w, --interactive, --confirmation
每個操作都要求確認 -W, --verify
寫入存檔后進行校驗 --exclude FILE
不把指定文件包含在內 -X, --exclude-from FILE
從指定文件中讀入不想包含的文件的列表 -y, --bzip2, --bunzip2
用 bzip2 對存檔壓縮或解壓 -Z, --compress, --uncompress
用 compress 對存檔壓縮或解壓 -z, --gzip, --ungzip
用 gzip 對存檔壓縮或解壓 --use-compress-program PROG
用 PROG 對存檔壓縮或解壓 ( PROG 需能接受 -d 參數) --block-compress
為便于磁盤存儲,按塊記錄存檔 -[0-7][lmh]
指定驅動器和密度[高中低]
|