2009年11月1日
#
APACHE是一個web服務器環境程序 啟用他可以作為web服務器使用 不過只支持靜態網頁 如(asp,php,cgi,jsp)等動態網頁的就不行
如果要在APACHE環境下運行jsp 的話就需要一個解釋器來執行jsp網頁 而這個jsp解釋器就是TOMCAT, 為什么還要JDK呢?因為jsp需要連接數據庫的話 就要jdk來提供連接數據庫的驅程,所以要運行jsp的web服務器平臺就需要APACHE+TOMCAT+JDK
整合的好處是:
如果客戶端請求的是靜態頁面,則只需要Apache服務器響應請求
如果客戶端請求動態頁面,則是Tomcat服務器響應請求
因為jsp是服務器端解釋代碼的,這樣整合就可以減少Tomcat的服務開銷
============================幾種常見的服務器===============================
① Microsoft IIS
Microsoft的Web服務器產品為Internet Information Server (IIS), IIS 是允許在公共Intranet或Internet上發布信息的Web服務器。IIS是目前最流行的Web服務器產品之一,很多著名的網站都是建立在IIS的平臺上。IIS提供了一個圖形界面的管理工具,稱為 Internet服務管理器,可用于監視配置和控制Internet服務。
IIS是一種Web服務組件,其中包括Web服務器、FTP服務器、NNTP服務器和SMTP服務器,分別用于網頁瀏覽、文件傳輸、新聞服務和郵件發送等方面,它使得在網絡(包括互聯網和局域網)上發布信息成了一件很容易的事。它提供ISAPI(Intranet Server API)作為擴展Web服務器功能的編程接口;同時,它還提供一個Internet數據庫連接器,可以實現對數據庫的查詢和更新。
② IBM WebSphere
WebSphere Application Server 是一種功能完善、開放的Web應用程序服務器,是IBM電子商務計劃的核心部分,它是基于 Java 的應用環境,用于建立、部署和管理 Internet 和 Intranet Web 應用程序。 這一整套產品進行了擴展,以適應 Web 應用程序服務器的需要,范圍從簡單到高級直到企業級。
WebSphere 針對以 Web 為中心的開發人員,他們都是在基本 HTTP服務器和 CGI 編程技術上成長起來的。IBM 將提供 WebSphere 產品系列,通過提供綜合資源、可重復使用的組件、功能強大并易于使用的工具、以及支持 HTTP 和 IIOP 通信的可伸縮運行時環境,來幫助這些用戶從簡單的 Web 應用程序轉移到電子商務世界。
③ BEA WebLogic Server
是一種多功能、基于標準的web應用服務器,為企業構建自己的應用提供了堅實的基礎。各種應用開發、部署所有關鍵性的任務,無論是集成各種系統和數據庫,還是提交服務、跨 Internet 協作,起始點都是 BEA WebLogic Server。由于 它具有全面的功能、對開放標準的遵從性、多層架構、支持基于組件的開發,基于 Internet 的企業都選擇它來開發、部署最佳的應用。
BEA WebLogic Server 在使應用服務器成為企業應用架構的基礎方面繼續處于領先地位。BEA WebLogic Server 為構建集成化的企業級應用提供了穩固的基礎,它們以 Internet 的容量和速度,在連網的企業之間共享信息、提交服務,實現協作自動化。BEA WebLogic Server 的遵從 J2EE 、面向服務的架構,以及豐富的工具集支持,便于實現業務邏輯、數據和表達的分離,提供開發和部署各種業務驅動應用所必需的底層核心功能。
④ IPlanet Application Server
作為Sun與Netscape聯盟產物的iPlanet公司生產的iPlanet Application Server 滿足最新J2EE規范的要求。它是一種完整的WEB服務器應用解決方案,它允許企業以便捷的方式,開發、部署和管理關鍵任務 Internet 應用。該解決方案集高性能、高度可伸縮和高度可用性于一體,可以支持大量的具有多種客戶機類型與數據源的事務。
iPlanet Application Server的基本核心服務包括事務監控器、多負載平衡選項、對集群和故障轉移全面的支持、集成的XML 解析器和可擴展格式語言轉換(XLST)引擎以及對國際化的全面支持。iPlanet Application Server 企業版所提供的全部特性和功能,并得益于J2EE系統構架,擁有更好的商業工作流程管理工具和應用集成功能。
⑤Oracle IAS
Oracle iAS的英文全稱是Oracle Internet Application Server,即Internet應用服務器,Oracle iAS是基于Java的應用服務器,通過與Oracle 數據庫等產品的結合,Oracle iAS能夠滿足Internet應用對可靠性、可用性和可伸縮性的要求。
Oracle iAS最大的優勢是其集成性和通用性,它是一個集成的、通用的中間件產品。在集成性方面,Oracle iAS將業界最流行的HTTP服務器Apache集成到系統中,集成了Apache的Oracle iAS通信服務層可以處理多種客戶請求,包括來自Web瀏覽器、胖客戶端和手持設備的請求,并且根據請求的具體內容,將它們分發給不同的應用服務進行處理。在通用性方面,Oracle iAS支持各種業界標準,包括 JavaBeans、CORBA、Servlets以及XML標準等,這種對標準的全面支持使得用戶很容易將在其他系統平臺上開發的應用移植到Oracle平臺上。
⑥ Apache
Apache源于NCSAhttpd服務器,經過多次修改,成為世界上最流行的Web服務器軟件之一。Apache是自由軟件,所以不斷有人來為它開發新的功能、新的特性、修改原來的缺陷。Apache的特點是簡單、速度快、性能穩定,并可做代理服務器來使用。本來它只用于小型或試驗Internet網絡,后來逐步擴充到各種Unix系統中,尤其對Linux的支持相當完美。
Apache是以進程為基礎的結構,進程要比線程消耗更多的系統開支,不太適合于多處理器環境,因此,在一個Apache Web站點擴容時,通常是增加服務器或擴充群集節點而不是增加處理器。到目前為止Apache仍然是世界上用的最多的Web服務器,世界上很多著名的網站都是Apache的產物,它的成功之處主要在于它的源代碼開放、有一支開放的開發隊伍、支持跨平臺的應用(可以運行在幾乎所有的Unix、Windows、Linux系統平臺上)以及它的可移植性等方面。
⑦ Tomcat
Tomcat是一個開放源代碼、運行servlet和JSP Web應用軟件的基于Java的Web應用軟件容器。Tomcat Server是根據servlet和JSP規范進行執行的,因此我們就可以說Tomcat Server也實行了Apache-Jakarta規范且比絕大多數商業應用軟件服務器要好。
Tomcat是Java Servlet 2.2和JavaServer Pages 1.1技術的標準實現,是基于Apache許可證下開發的自由軟件。Tomcat是完全重寫的Servlet API 2.2和JSP 1.1兼容的Servlet/JSP容器。Tomcat使用了JServ的一些代碼,特別是Apache服務適配器。隨著Catalina Servlet引擎的出現,Tomcat第四版號的性能得到提升,使得它成為一個值得考慮的Servlet/JSP容器,因此目前許多WEB服務器都是采用Tomcat。
web服務器和應用服務器得區別
通俗的講,Web服務器傳送(serves)頁面使瀏覽器可以瀏覽,然而應用程序服務器提供的是客戶端應用程序可以調用(call)的方法(methods)。確切一點,你可以說:Web服務器專門處理HTTP請求(request),但是應用程序服務器是通過很多協議來為應用程序提供(serves)商業邏輯(business logic)。
下面讓我們來細細道來:
Web服務器(Web Server)
Web服務器可以解析(handles)HTTP協議。當Web服務器接收到一個HTTP請求(request),會返回一個HTTP響應(response),例如送回一個HTML頁面。為了處理一個請求(request),Web服務器可以響應(response)一個靜態頁面或圖片,進行頁面跳轉(redirect),或者把動態響應(dynamic response)的產生委托(delegate)給一些其它的程序例如CGI腳本,JSP(JavaServer Pages)腳本,servlets,ASP(Active Server Pages)腳本,服務器端(server-side)JavaScript,或者一些其它的服務器端(server-side)技術。無論它們(譯者注:腳本)的目的如何,這些服務器端(server-side)的程序通常產生一個HTML的響應(response)來讓瀏覽器可以瀏覽。
要知道,Web服務器的代理模型(delegation model)非常簡單。當一個請求(request)被送到Web服務器里來時,它只單純的把請求(request)傳遞給可以很好的處理請求(request)的程序(譯者注:服務器端腳本)。Web服務器僅僅提供一個可以執行服務器端(server-side)程序和返回(程序所產生的)響應(response)的環境,而不會超出職能范圍。服務器端(server-side)程序通常具有事務處理(transaction processing),數據庫連接(database connectivity)和消息(messaging)等功能。
雖然Web服務器不支持事務處理或數據庫連接池,但它可以配置(employ)各種策略(strategies)來實現容錯性(fault tolerance)和可擴展性(scalability),例如負載平衡(load balancing),緩沖(caching)。集群特征(clustering—features)經常被誤認為僅僅是應用程序服務器專有的特征。
應用程序服務器(The Application Server)
根據我們的定義,作為應用程序服務器,它通過各種協議,可以包括HTTP,把商業邏輯暴露給(expose)客戶端應用程序。Web服務器主要是處理向瀏覽器發送HTML以供瀏覽,而應用程序服務器提供訪問商業邏輯的途徑以供客戶端應用程序使用。應用程序使用此商業邏輯就象你調用對象的一個方法(或過程語言中的一個函數)一樣。
應用程序服務器的客戶端(包含有圖形用戶界面(GUI)的)可能會運行在一臺PC、一個Web服務器或者甚至是其它的應用程序服務器上。在應用程序服務器與其客戶端之間來回穿梭(traveling)的信息不僅僅局限于簡單的顯示標記。相反,這種信息就是程序邏輯(program logic)。 正是由于這種邏輯取得了(takes)數據和方法調用(calls)的形式而不是靜態HTML,所以客戶端才可以隨心所欲的使用這種被暴露的商業邏輯。
在大多數情形下,應用程序服務器是通過組件(component)的應用程序接口(API)把商業邏輯暴露(expose)(給客戶端應用程序)的,例如基于J2EE(Java 2 Platform, Enterprise Edition)應用程序服務器的EJB(Enterprise JavaBean)組件模型。此外,應用程序服務器可以管理自己的資源,例如看大門的工作(gate-keeping duties)包括安全(security),事務處理(transaction processing),資源池(resource pooling), 和消息(messaging)。就象Web服務器一樣,應用程序服務器配置了多種可擴展(scalability)和容錯(fault tolerance)技術。
一個例子
例如,設想一個在線商店(網站)提供實時定價(real-time pricing)和有效性(availability)信息。這個站點(site)很可能會提供一個表單(form)讓你來選擇產品。當你提交查詢(query)后,網站會進行查找(lookup)并把結果內嵌在HTML頁面中返回。網站可以有很多種方式來實現這種功能。我要介紹一個不使用應用程序服務器的情景和一個使用應用程序服務器的情景。觀察一下這兩中情景的不同會有助于你了解應用程序服務器的功能。
情景1:不帶應用程序服務器的Web服務器
在此種情景下,一個Web服務器獨立提供在線商店的功能。Web服務器獲得你的請求(request),然后發送給服務器端(server-side)可以處理請求(request)的程序。此程序從數據庫或文本文件(flat file,譯者注:flat file是指沒有特殊格式的非二進制的文件,如properties和XML文件等)中查找定價信息。一旦找到,服務器端(server-side)程序把結果信息表示成(formulate)HTML形式,最后Web服務器把會它發送到你的Web瀏覽器。
簡而言之,Web服務器只是簡單的通過響應(response)HTML頁面來處理HTTP請求(request)。
情景2:帶應用程序服務器的Web服務器
情景2和情景1相同的是Web服務器還是把響應(response)的產生委托(delegates)給腳本(譯者注:服務器端(server-side)程序)。然而,你可以把查找定價的商業邏輯(business logic)放到應用程序服務器上。由于這種變化,此腳本只是簡單的調用應用程序服務器的查找服務(lookup service),而不是已經知道如何查找數據然后表示為(formulate)一個響應(response)。 這時當該腳本程序產生HTML響應(response)時就可以使用該服務的返回結果了。
在此情景中,應用程序服務器提供(serves)了用于查詢產品的定價信息的商業邏輯。(服務器的)這種功能(functionality)沒有指出有關顯示和客戶端如何使用此信息的細節,相反客戶端和應用程序服務器只是來回傳送數據。當有客戶端調用應用程序服務器的查找服務(lookup service)時,此服務只是簡單的查找并返回結果給客戶端。
通過從響應產生(response-generating)HTML的代碼中分離出來,在應用程序之中該定價(查找)邏輯的可重用性更強了。其他的客戶端,例如收款機,也可以調用同樣的服務(service)來作為一個店員給客戶結帳。相反,在情景1中的定價查找服務是不可重用的因為信息內嵌在HTML頁中了。
總而言之,在情景2的模型中,在Web服務器通過回應HTML頁面來處理HTTP請求(request),而應用程序服務器則是通過處理定價和有效性(availability)請求(request)來提供應用程序邏輯的。
警告(Caveats)
現在,XML Web Services已經使應用程序服務器和Web服務器的界線混淆了。通過傳送一個XML有效載荷(payload)給服務器,Web服務器現在可以處理數據和響應(response)的能力與以前的應用程序服務器同樣多了。
另外,現在大多數應用程序服務器也包含了Web服務器,這就意味著可以把Web服務器當作是應用程序服務器的一個子集(subset)。雖然應用程序服務器包含了Web服務器的功能,但是開發者很少把應用程序服務器部署(deploy)成這種功能(capacity)(譯者注:這種功能是指既有應用程序服務器的功能又有Web服務器的功能)。相反,如果需要,他們通常會把Web服務器獨立配置,和應用程序服務器一前一后。這種功能的分離有助于提高性能(簡單的Web請求(request)就不會影響應用程序服務器了),分開配置(專門的Web服務器,集群(clustering)等等),而且給最佳產品的選取留有余地。
2009年10月21日
#
下面的這個簡單的 Java 程序完成四項不相關的任務。這樣的程序有單個控制線程,控制在這四個任務之間線性地移動。此外,因為所需的資源 ? 打印機、磁盤、數據庫和顯示屏 — 由于硬件和軟件的限制都有內在的潛伏時間,所以每項任務都包含明顯的等待時間。因此,程序在訪問數據庫之前必須等待打印機完成打印文件的任務,等等。如果您正在等待程序的完成,則這是對計算資源和您的時間的一種拙劣使用。改進此程序的一種方法是使它成為多線程的。
四項不相關的任務
class myclass {
static public void main(String args[]) {
print_a_file();
manipulate_another_file();
access_database();
draw_picture_on_screen();
}
}
多個進程
在大多數操作系統中都可以創建多個進程。當一個程序啟動時,它可以為即將開始的每項任務創建一個進程,并允許它們同時運行。當一個程序因等待網絡訪問或用戶輸入而被阻塞時,另一個程序還可以運行,這樣就增加了資源利用率。但是,按照這種方式創建每個進程要付出一定的代價:設置一個進程要占用相當一部分處理器時間和內存資源。而且,大多數操作系統不允許進程訪問其他進程的內存空間。因此,進程間的通信很不方便,并且也不會將它自己提供給容易的編程模型。
線程
線程也稱為輕型進程 (LWP)。因為線程只能在單個進程的作用域內活動,所以創建線程比創建進程要廉價得多。這樣,因為線程允許協作和數據交換,并且在計算資源方面非常廉價,所以線程比進程更可取。線程需要操作系統的支持,因此不是所有的機器都提供線程。Java 編程語言,作為相當新的一種語言,已將線程支持與語言本身合為一體,這樣就對線程提供了強健的支持。
使用 Java 編程語言實現線程
Java編程語言使多線程如此簡單有效,以致于某些程序員說它實際上是自然的。盡管在 Java 中使用線程比在其他語言中要容易得多,仍然有一些概念需要掌握。要記住的一件重要的事情是 main() 函數也是一個線程,并可用來做有用的工作。程序員只有在需要多個線程時才需要創建新的線程。
Thread 類
下面的代碼說明了它的用法:
創建兩個新線程
import java.util.*;
class TimePrinter extends Thread {
int pauseTime;
String name;
public TimePrinter(int x, String n) {
pauseTime = x;
name = n;
}
public void run() {
while(true) {
try {
System.out.println(name + “:” + new
Date(System.currentTimeMillis()));
Thread.sleep(pauseTime);
} catch(Exception e) {
System.out.println(e);
}
}
}
static public void main(String args[]) {
TimePrinter tp1 = new TimePrinter(1000, “Fast Guy”);
tp1.start();
TimePrinter tp2 = new TimePrinter(3000, “Slow Guy”);
tp2.start();
}
}
在本例中,我們可以看到一個簡單的程序,它按兩個不同的時間間隔(1 秒和 3 秒)在屏幕上顯示當前時間。這是通過創建兩個新線程來完成的,包括 main() 共三個線程。但是,因為有時要作為線程運行的類可能已經是某個類層次的一部分,所以就不能再按這種機制創建線程。雖然在同一個類中可以實現任意數量的接口,但 Java 編程語言只允許一個類有一個父類。同時,某些程序員避免從 Thread 類導出,因為它強加了類層次。對于這種情況,就要 runnable 接口。
Runnable 接口
此接口只有一個函數,run(),此函數必須由實現了此接口的類實現。但是,就運行這個類而論,其語義與前一個示例稍有不同。我們可以用 runnable 接口改寫前一個示例。(不同的部分用黑體表示。)
創建兩個新線程而不強加類層次
import java.util.*;
class TimePrinter implements Runnable {
int pauseTime;
String name;
public TimePrinter(int x, String n) {
pauseTime = x;
name = n;
}
public void run() {
while(true) {
try {
System.out.println(name + “:” + new
Date(System.currentTimeMillis()));
Thread.sleep(pauseTime);
} catch(Exception e) {
System.out.println(e);
}
}
}
static public void main(String args[]) {
Thread t1 = new Thread(new TimePrinter(1000, “Fast Guy”));
t1.start();
Thread t2 = new Thread(new TimePrinter(3000, “Slow Guy”));
t2.start();
}
}
請注意,當使用 runnable 接口時,您不能直接創建所需類的對象并運行它; 必須從 Thread 類的一個實例內部運行它。許多程序員更喜歡 runnable 接口,因為從 Thread 類繼承會強加類層次。
synchronized 關鍵字
到目前為止,我們看到的示例都只是以非常簡單的方式來利用線程。只有最小的數據流,而且不會出現兩個線程訪問同一個對象的情況。但是,在大多數有用的程序中,線程之間通常有信息流。試考慮一個金融應用程序,它有一個 Account 對象,如下例中所示:
一個銀行中的多項活動
public class Account {
String holderName;
float amount;
public Account(String name, float amt) {
holderName = name;
amount = amt;
}
public void deposit(float amt) {
amount += amt;
}
public void withdraw(float amt) {
amount -= amt;
}
public float checkBalance() {
return amount;
}
}
在此代碼樣例中潛伏著一個錯誤。如果此類用于單線程應用程序,不會有任何問題。但是,在多線程應用程序的情況中,不同的線程就有可能同時訪問同一個 Account 對象,比如說一個聯合帳戶的所有者在不同的 ATM 上同時進行訪問。在這種情況下,存入和支出就可能以這樣的方式發生:一個事務被另一個事務覆蓋。這種情況將是災難性的。但是,Java 編程語言提供了一種簡單的機制來防止發生這種覆蓋。每個對象在運行時都有一個關聯的鎖。這個鎖可通過為方法添加關鍵字 synchronized 來獲得。這樣,修訂過的 Account 對象(如下所示)將不會遭受像數據損壞這樣的錯誤:
對一個銀行中的多項活動進行同步處理
public class Account {
String holderName;
float amount;
public Account(String name, float amt) {
holderName = name;
amount = amt;
}
public synchronized void deposit(float amt) {
amount += amt;
}
public synchronized void withdraw(float amt) {
amount -= amt;
}
public float checkBalance() {
return amount;
}
}
deposit() 和 withdraw() 函數都需要這個鎖來進行操作,所以當一個函數運行時,另一個函數就被阻塞。請注意, checkBalance() 未作更改,它嚴格是一個讀函數。因為 checkBalance() 未作同步處理,所以任何其他方法都不會阻塞它,它也不會阻塞任何其他方法,不管那些方法是否進行了同步處理。
Java 編程語言中的高級多線程支持
線程組
線程是被個別創建的,但可以將它們歸類到線程組中,以便于調試和監視。只能在創建線程的同時將它與一個線程組相關聯。在使用大量線程的程序中,使用線程組組織線程可能很有幫助。可以將它們看作是計算機上的目錄和文件結構。
線程間發信
當線程在繼續執行前需要等待一個條件時,僅有 synchronized 關鍵字是不夠的。雖然 synchronized 關鍵字阻止并發更新一個對象,但它沒有實現線程間發信。Object 類為此提供了三個函數:wait()、notify() 和 notifyAll()。以全球氣候預測程序為例。這些程序通過將地球分為許多單元,在每個循環中,每個單元的計算都是隔離進行的,直到這些值趨于穩定,然后相鄰單元之間就會交換一些數據。所以,從本質上講,在每個循環中各個線程都必須等待所有線程完成各自的任務以后才能進入下一個循環。這個模型稱為屏蔽同步,下例說明了這個模型:
屏蔽同步
public class BSync {
int totalThreads;
int currentThreads;
public BSync(int x) {
totalThreads = x;
currentThreads = 0;
}
public synchronized void waitForAll() {
currentThreads++;
if(currentThreads < totalThreads) {
try {
wait();
} catch (Exception e) {}
}
else {
currentThreads = 0;
notifyAll();
}
}
}
當對一個線程調用 wait() 時,該線程就被有效阻塞,只到另一個線程對同一個對象調用 notify() 或 notifyAll() 為止。因此,在前一個示例中,不同的線程在完成它們的工作以后將調用 waitForAll() 函數,最后一個線程將觸發 notifyAll() 函數,該函數將釋放所有的線程。第三個函數 notify() 只通知一個正在等待的線程,當對每次只能由一個線程使用的資源進行訪問限制時,這個函數很有用。但是,不可能預知哪個線程會獲得這個通知,因為這取決于 Java 虛擬機 (JVM) 調度算法。
將 CPU 讓給另一個線程
當線程放棄某個稀有的資源(如數據庫連接或網絡端口)時,它可能調用 yield() 函數臨時降低自己的優先級,以便某個其他線程能夠運行。
守護線程
有兩類線程:用戶線程和守護線程。用戶線程是那些完成有用工作的線程。 守護線程是那些僅提供輔助功能的線程。Thread 類提供了 setDaemon() 函數。Java 程序將運行到所有用戶線程終止,然后它將破壞所有的守護線程。在 Java 虛擬機 (JVM) 中,即使在 main 結束以后,如果另一個用戶線程仍在運行,則程序仍然可以繼續運行。
避免不提倡使用的方法
不提倡使用的方法是為支持向后兼容性而保留的那些方法,它們在以后的版本中可能出現,也可能不出現。Java 多線程支持在版本 1.1 和版本 1.2 中做了重大修訂,stop()、suspend() 和 resume() 函數已不提倡使用。這些函數在 JVM 中可能引入微妙的錯誤。雖然函數名可能聽起來很誘人,但請抵制誘惑不要使用它們。
調試線程化的程序
在線程化的程序中,可能發生的某些常見而討厭的情況是死鎖、活鎖、內存損壞和資源耗盡。
死鎖
死鎖可能是多線程程序最常見的問題。當一個線程需要一個資源而另一個線程持有該資源的鎖時,就會發生死鎖。這種情況通常很難檢測。但是,解決方案卻相當好:在所有的線程中按相同的次序獲取所有資源鎖。例如,如果有四個資源 ?A、B、C 和 D ? 并且一個線程可能要獲取四個資源中任何一個資源的鎖,則請確保在獲取對 B 的鎖之前首先獲取對 A 的鎖,依此類推。如果“線程 1”希望獲取對 B 和 C 的鎖,而“線程 2”獲取了 A、C 和 D 的鎖,則這一技術可能導致阻塞,但它永遠不會在這四個鎖上造成死鎖。
活鎖
當一個線程忙于接受新任務以致它永遠沒有機會完成任何任務時,就會發生活鎖。這個線程最終將超出緩沖區并導致程序崩潰。試想一個秘書需要錄入一封信,但她一直在忙于接電話,所以這封信永遠不會被錄入。
內存損壞
如果明智地使用 synchronized 關鍵字,則完全可以避免內存錯誤這種氣死人的問題。
資源耗盡
某些系統資源是有限的,如文件描述符。多線程程序可能耗盡資源,因為每個線程都可能希望有一個這樣的資源。如果線程數相當大,或者某個資源的侯選線程數遠遠超過了可用的資源數,則最好使用資源池。一個最好的示例是數據庫連接池。只要線程需要使用一個數據庫連接,它就從池中取出一個,使用以后再將它返回池中。資源池也稱為 資源庫。
調試大量的線程
有時一個程序因為有大量的線程在運行而極難調試。在這種情況下,下面的這個類可能會派上用場:
public class Probe extends Thread {
public Probe() {}
public void run() {
while(true) {
Thread[] x = new Thread[100];
Thread.enumerate(x);
for(int i=0; i<100; i++) {
Thread t = x[i];
if(t == null)
break;
else
System.out.println(t.getName() + “\t” + t.getPriority()
+ “\t” + t.isAlive() + “\t” + t.isDaemon());
}
}
}
}
限制線程優先級和調度
Java 線程模型涉及可以動態更改的線程優先級。本質上,線程的優先級是從 1 到 10 之間的一個數字,數字越大表明任務越緊急。JVM 標準首先調用優先級較高的線程,然后才調用優先級較低的線程。但是,該標準對具有相同優先級的線程的處理是隨機的。如何處理這些線程取決于基層的操作系統策略。在某些情況下,優先級相同的線程分時運行; 在另一些情況下,線程將一直運行到結束。請記住,Java 支持 10 個優先級,基層操作系統支持的優先級可能要少得多,這樣會造成一些混亂。因此,只能將優先級作為一種很粗略的工具使用。最后的控制可以通過明智地使用 yield() 函數來完成。通常情況下,請不要依靠線程優先級來控制線程的狀態。
2009年10月17日
#
第一范式
定義:如果關系R 中所有屬性的值域都是單純域,那么關系模式R是第一范式的
那么符合第一模式的特點就有
1)有主關鍵字
2)主鍵不能為空,
3)主鍵不能重復,
4)字段不可以再分
例如:
StudyNo | Name | Sex | Contact
20040901 john Male Email:kkkk@ee.net,phone:222456
20040901 mary famale email:kkk@fff.net phone:123455
以上的表就不符合,第一范式:主鍵重復(實際中數據庫不允許重復的),而且Contact字段可以再分
所以變更為正確的是
StudyNo | Name | Sex | Email | Phone
20040901 john Male kkkk@ee.net 222456
20040902 mary famale kkk@fff.net 123455
第二范式:
定義:如果關系模式R是第一范式的,而且關系中每一個非主屬性不部分依賴于主鍵,稱R是第二范式的。
所以第二范式的主要任務就是
滿足第一范式的前提下,消除部分函數依賴。
StudyNo | Name | Sex | Email | Phone | ClassNo | ClassAddress
01 john Male kkkk@ee.net 222456 200401 A樓2
02 mary famale kkk@fff.net 123455 200402 A樓3
這個表完全滿足于第一范式,
主鍵由StudyNo和ClassNo組成,這樣才能定位到指定行
但是,ClassAddress部分依賴于關鍵字(ClassNo-〉ClassAddress),
所以要變為兩個表
表一
StudyNo | Name | Sex | Email | Phone | ClassNo
01 john Male kkkk@ee.net 222456 200401
02 mary famale kkk@fff.net 123455 200402
表二
ClassNo | ClassAddress
200401 A樓2
200402 A樓3
第三范式:
滿足第二范式的前提下,消除傳遞依賴。
例:
StudyNo | Name | Sex | Email | bounsLevel | bouns
20040901 john Male kkkk@ee.net 優秀 $1000
20040902 mary famale kkk@fff.net 良 $600
這個完全滿足了第二范式,但是bounsLevel和bouns存在傳遞依賴
更改為:
StudyNo | Name | Sex | Email | bouunsNo
20040901 john Male kkkk@ee.net 1
20040902 mary famale kkk@fff.net 2
bounsNo | bounsLevel | bouns
1 優秀 $1000
2 良 $600
這里我比較喜歡用bounsNo作為主鍵,
基于兩個原因
1)不要用字符作為主鍵。可能有人說:如果我的等級一開始就用數值就代替呢?
2)但是如果等級名稱更改了,不叫 1,2 ,3或優、良,這樣就可以方便更改,所以我一般優先使用與業務無關的字段作為關鍵字。
一般滿足前三個范式就可以避免數據冗余。
第四范式:
主要任務:滿足第三范式的前提下,消除多值依賴
product | agent | factory
Car A1 F1
Bus A1 F2
Car A2 F2
在這里,Car的定位,必須由 agent 和 Factory才能得到(所以主鍵由agent和factory組成),可以通過 product依賴了agent和factory兩個屬性
所以正確的是
表1 表2:
product | agent factory | product
Car A1 F1 Car
Bus A1 F2 Car
Car A2 F2 Bus
第五范式:
定義: 如果關系模式R中的每一個連接依賴, 都是由R的候選鍵所蘊含, 稱R是第五范式的
看到定義,就知道是要消除連接依賴,并且必須保證數據完整
例子
A | B | C
a1 b1 c1
a2 b1 c2
a1 b2 c1
a2 b2 c2
如果要定位到特定行,必須三個屬性都為關鍵字。
所以關系要變為 三個關系,分別是A 和B,B和C ,C和A
如下:
表1 表2 表3
A | B B | C C | A
a1 b1 b1 c1 c1 a1
a1 b2 b1 c2 c1 a2
數據庫范式是數據庫設計中必不可少的知識,沒有對范式的理解,就無法設計出高效率、優雅的數據庫。甚至設計出錯誤的數據庫。而想要理解并掌握范式卻并不是那 么容易。教科書中一般以關系代數的方法來解釋數據庫范式。這樣做雖然能夠十分準確的表達數據庫范式,但比較抽象,不太直觀,不便于理解,更難以記憶。
一、基礎概念
- 實體:現實世界中客觀存在并可以被區別的事物。比如“一個學生”、“一本書”、“一門課”等等。值得強調的是這里所說的“事物”不僅僅是看得見摸得著的“東西”,它也可以是虛擬的,不如說“老師與學校的關系”。
- 屬性:教科書上解釋為:“實體所具有的某一特性”,由此可見,屬性一開始是個邏輯概念,比如說,“性別”是“人”的一個屬性。在關系數據庫中,屬性又是個物理概念,屬性可以看作是“表的一列”。
- 元組:表中的一行就是一個元組。
- 分量:元組的某個屬性值。在一個關系數據庫中,它是一個操作原子,即關系數據庫在做任何操作的時候,屬性是“不可分的”。否則就不是關系數據庫了。
- 碼:表中可以唯一確定一個元組的某個屬性(或者屬性組),如果這樣的碼有不止一個,那么大家都叫候選碼,我們從候選碼中挑一個出來做老大,它就叫主碼。
- 全碼:如果一個碼包含了所有的屬性,這個碼就是全碼。
- 主屬性:一個屬性只要在任何一個候選碼中出現過,這個屬性就是主屬性。
- 非主屬性:與上面相反,沒有在任何候選碼中出現過,這個屬性就是非主屬性。
- 外碼:一個屬性(或屬性組),它不是碼,但是它別的表的碼,它就是外碼。
二、6個范式
好了,上面已經介紹了我們掌握范式所需要的全部基礎概念,下面我們就來講范式。首先要明白,范式的包含關系。一個數據庫設計如果符合第二范式,一定也符合第一范式。如果符合第三范式,一定也符合第二范式…
第一范式(1NF):屬性不可分。
在前面我們已經介紹了
屬性值的概念,我們說,它是“不可分的”。而第一范式要求屬性也不可分。那么它和屬性值不可分有什么區別呢?給一個例子:
| name |
tel |
age |
| 大寶 |
13612345678 |
22 |
| 小明 |
13988776655 |
010-1234567 |
21 |
Ps:這個表中,屬性值“分”了。
| name |
tel |
age |
| 手機 |
座機 |
| 大寶 |
13612345678 |
021-9876543 |
22 |
| 小明 |
13988776655 |
010-1234567 |
21 |
Ps:這個表中,屬性 “分”了。
這兩種情況都不滿足第一范式。不滿足第一范式的數據庫,不是關系數據庫!所以,我們在任何關系數據庫管理系統中,做不出這樣的“表”來。
第二范式(2NF):符合1NF,并且,
非主屬性完全依賴于碼。
聽起來好像很神秘,其實真的沒什么。
一 個候選碼中的主屬性也可能是好幾個。如果一個主屬性,它不能單獨做為一個候選碼,那么它也不能確定任何一個非主屬性。給一個反例:我們考慮一個小學的教務 管理系統,學生上課指定一個老師,一本教材,一個教室,一個時間,大家都上課去吧,沒有問題。那么數據庫怎么設計?(學生上課表)
| 學生 |
課程 |
老師 |
老師職稱 |
教材 |
教室 |
上課時間 |
| 小明 |
一年級語文(上) |
大寶 |
副教授 |
《小學語文1》 |
101 |
14:30 |
一個學生上一門課,一定在特定某個教室。所以有(學生,課程)->教室
一個學生上一門課,一定是特定某個老師教。所以有(學生,課程)->老師
一個學生上一門課,他老師的職稱可以確定。所以有(學生,課程)->老師職稱
一個學生上一門課,一定是特定某個教材。所以有(學生,課程)->教材
一個學生上一門課,一定在特定時間。所以有(學生,課程)->上課時間
因此(學生,課程)是一個碼。
然而,一個課程,一定指定了某個教材,一年級語文肯定用的是《小學語文1》,那么就有課程->教材。(學生,課程)是個碼,課程卻決定了教材,這就叫做不完全依賴,或者說部分依賴。出現這樣的情況,就不滿足第二范式!
有什么不好嗎?你可以想想:
1、校長要新增加一門課程叫“微積分”,教材是《大學數學》,怎么辦?學生還沒選課,而學生又是主屬性,主屬性不能空,課程怎么記錄呢,教材記到哪呢? ……郁悶了吧?
(插入異常)
2、下學期沒學生學一年級語文(上)了,學一年級語文(下)去了,那么表中將不存在一年級語文(上),也就沒了《小學語文1》。這時候,校長問:一年級語文(上)用的什么教材啊?……郁悶了吧?
(刪除異常)
3、校長說:一年級語文(上)換教材,換成《大學語文》。有10000個學生選了這么課,改動好大啊!改累死了……郁悶了吧?
(修改異常)
那應該怎么解決呢?投影分解,將一個表分解成兩個或若干個表
| 學生 |
課程 |
老師 |
老師職稱 |
教室 |
上課時間 |
| 小明 |
一年級語文(上) |
大寶 |
副教授 |
101 |
14:30 |
學生上課表新
課程的表
第三范式(3NF):符合2NF,并且,
消除傳遞依賴
上面的“學生上課表新”符合2NF,可以這樣驗證:兩個主屬性單獨使用,不用確定其它四個非主屬性的任何一個。但是它有傳遞依賴!
在哪呢?問題就出在“老師”和“老師職稱”這里。一個老師一定能確定一個老師職稱。
有什么問題嗎?想想:
1、老師升級了,變教授了,要改數據庫,表中有N條,改了N次……
(修改異常)
2、沒人選這個老師的課了,老師的職稱也沒了記錄……
(刪除異常)
3、新來一個老師,還沒分配教什么課,他的職稱記到哪?……
(插入異常)
那應該怎么解決呢?和上面一樣,投影分解:
| 學生 |
課程 |
老師 |
教室 |
上課時間 |
| 小明 |
一年級語文(上) |
大寶 |
101 |
14:30 |
BC范式(BCNF):符合3NF,并且,
主屬性不依賴于主屬性
若關系模式屬于第一范式,且每個屬性都不傳遞依賴于鍵碼,則R屬于BC范式。
通常
BC范式的條件有多種等價的表述:每個非平凡依賴的左邊必須包含鍵碼;每個決定因素必須包含鍵碼。
BC范式既檢查非主屬性,又檢查主屬性。當只檢查非主屬性時,就成了第三范式。滿足BC范式的關系都必然滿足第三范式。
還可以這么說:
若一個關系達到了第三范式,并且它只有一個候選碼,或者它的每個候選碼都是單屬性,則該關系自然達到BC范式。
一般,一個數據庫設計符合3NF或BCNF就可以了。在BC范式以上還有第四范式、第五范式。
第四范式:要求把同一表內的多對多關系刪除。
第五范式:從最終結構重新建立原始結構。
2009年9月16日
#
關鍵字: editplus
原文出自:http://www.cnblogs.com/JustinYoung/archive/2008/01/14/editplus-skills.html
除了windows操作系統,EditPlus可以說是我最經常使用的軟件了。無論是編寫xhtml頁面,還是css、js文件,甚至隨筆記記這樣的事情,我都會使用EditPlus(現在使用的是EditPlus2.31英文版),感覺它不僅功能強大,更難得的是:綠色、輕量級、啟動速度快、穩定性高……反正,我個人是愛死她了
在使用中,我個人也總結了一些使用經驗。可能作為高手的你,看來只是”相當膚淺”,但是沒有關系,因為我相信,只要把知識共享出來,總能幫助到一些還在進步中的朋友。下面就讓我們來開始配置出符合你自己使用習慣的EditPlus吧!
一邊閱讀,一邊動手吧!
為了達到更好的效果,請你先下載我打包的這個 EditPlus壓縮包文件(壓縮包文件為綠色的EditPlus2.31英文版,含自動完成文件,高亮語法文件和剪切板代碼片斷文件,這些文件在解壓目錄下的”yzyFile”目錄下),這樣就可以一邊看著這篇文章,一邊親自動手,從而達到更好的效果了。
設置EditPlus的配置文件路徑
因為EditPlus是可以綠色使用的(直接解壓那個EditPlus壓縮包文件即可直接使用,不用安裝),所以,當我們對EditPlus進行一系列的配置以后,保存下這些配置文件。以后當我們重裝系統,或者換臺電腦使用的時候,只要重新加載一下那些配置文件,以前的配置就都重新回來了,很是方便。所以,在講其他配置和技巧之前,我們先設置好EditPlus的配置文件路徑。
打開EditPlus → 【Tools】→ 【INI File Directory…】 → 在彈出的對話框中設置配置文件的保存位置(壓縮包內的配置保存文件在解壓目錄下的”yzyFile\INIFiles”目錄下)。這里你可能要重新設置一下目錄,因為,我喜歡把EditPlus放在”D:\GreenSoft\EditPlus 2″下(把所有的綠色軟件裝在一個目錄下,每次重裝系統的時候,可以直接把綠色軟件拷回去,就能直接使用了,從而避免了每次都安裝那么多軟件)。所以,就請你重新設置一下,根據你的習慣,把配置文件存放在某個目錄下吧。
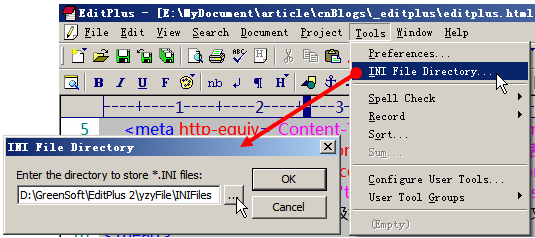
圖1:設置EditPlus的配置文件保存路徑
保護視力,從EditPlus做起
“最近眼睛好痛呀!”、”靠~眼睛簡直要瞎了!”……不知道作為程序員的你是否也經常抱怨這樣的事情,每天對著電腦看,的確對視力的傷害很大,所以能不能采取一些措施來為眼睛減減壓呢?我在EditPlus里面是這樣做的(因為EditPlus是我最長使用的工具,所以以EditPlus為例)–編輯區的背景設為灰色而不是默認的白色,使用較大字號的字體。效果如下圖所示:
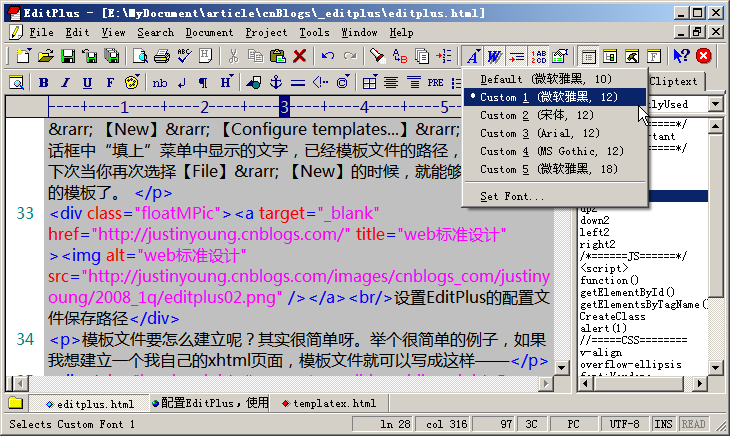
圖2:灰色的背景,12號的雅黑字體,構造”愛眼”環境你可以這樣設置EditPlus編輯環境的背景顏色和字體。菜單【Tools】→ 【Preperences】→ 【General】→ 【fonts】和【colors】。需要說明一下的是:可以設置多種fonts,這樣就可以很方便地切換fonts了(參看圖2所示),這招對日企這樣的朋友很方便哦。中文的字體設置幾個,日文的字體設置幾個,出現亂碼的時候,切換一下字體就可以了。
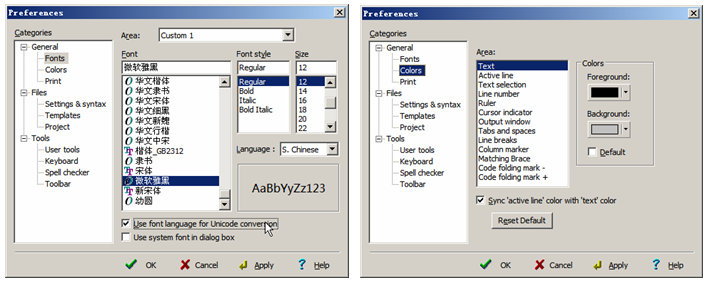
圖3:設置EditPlus的字體和顏色
配置文件模板,告別重復的體力勞動
設置好EditPlus的配置文件,就讓我們開始EditPlus的使用技巧吧。第一個技巧當然就是和”新建”有關的啦。如果我們經常建立一種文件,而這種文件總會包含一些重復的文字或者代碼的話,我們就可以建立模板,然后通過模板建立文件。從而擺脫每次都要重復的體力勞動。
我們就從建立一個屬于自己的xhtml文件開始吧。菜單【File】→ 【New】→ 【Configure templates…】→ 在打開的對話框中”填上”菜單中顯示的文字,已經模板文件的路徑,就可以了。下次當你再次選擇【File】→ 【New】的時候,就能夠看到你建立的模板了。
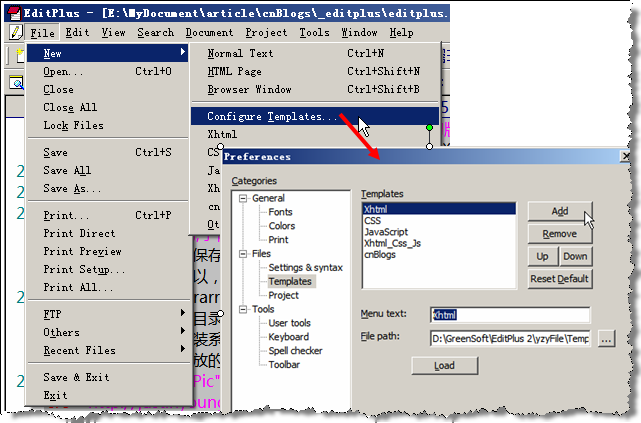
圖4:EditPlus中建立自己的模板模板文件要怎么建立呢?其實很簡單呀。舉個很簡單的例子,如果我想建立一個我自己的xhtml頁面,模板文件就可以寫成這樣–
1 <!DOCTYPE html public ”-//W3C//DTD XHTML 1.0 Transitional//EN” ”http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
<!DOCTYPE html public ”-//W3C//DTD XHTML 1.0 Transitional//EN” ”http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
2<html xmlns=”http://www.w3.org/1999/xhtml”>
3<head>
4 <meta http-equiv=”Content-Type” content=”text/html; charset=utf-8″ />
5 <meta name=”Keywords” content=”YES!B/S!,JustinYoung,web標準設計” />
6 <meta name=”Description” content=”This page is from http://Justinyoung.cnblogs.com” />
7 <title>簡單的XHTML頁面</title>
8</head>
9<body>
10^!
11</body>
12</html>顯然里面的Keywords和Description,意見title的內容都已經變成我常用的了。還有一點,請大家注意第10行的”^!”標簽。這個標簽在EditPlus中表示光標所在位置。顯然,這里的意思就是:當你用這個模板建立一個新的文件的時候,光標就會自動停留在<body>和</body>之間,從而方便你的直接輸入。
關于模板文件再說兩句:
1:在我提供的那個 EditPlus壓縮包文件中,模板文件存放在解壓目錄下的”\yzyFile\Templates”文件夾下。
2:我們知道使用快捷鍵”Ctrl + Shift + N”可以快速的建立一個html頁面,而這個可以快速的建立html的模板,位于EditPlus目錄下的,文件名為”templatex.html”。你可以通過修改這個模板文件,來達到你個性化html頁面的目的。
順手的側邊欄
如果你看不到側邊欄,可以使用快捷鍵(Alt + Shift + 1)。側邊欄包含了”快速目錄路徑”和”快速剪貼板”功能。”快速目錄路徑”就不說了,重點來說說”快速剪貼板”功能吧。其實說白了,就是一個地方,這個地方可以存放一些代碼片斷、常用文言等等文字。當你需要這些文字的時候,只要雙擊,就可以方便的添加到光標所在位置了。默認情況下會有一些html,css代碼,但是,說實話,我是不太經常使用那些東西的,那么多,找到都累死了。所以,我喜歡建立一個自己最常用的”剪貼板”庫,因為是自己建的,所以用著就會比較順手了。
你可以通過這種方式來建立自己的”剪貼板”庫文件。在Cliptext側邊欄上的下拉列表框上點擊右鍵 → 新建 → 填寫文件名和顯示標題→ 在新建的空白側邊欄上點擊右鍵 → 新建 → 填入顯示文本和代碼即可。
關于”剪貼板”庫文件再說兩句:
1:在我提供的那個 EditPlus壓縮包文件中”剪貼板”庫文件存放在解壓目錄下的”\yzyFile\CliptextLibrary”文件夾下。
2:你可以通過直接編輯,解壓目錄下的”\yzyFile\CliptextLibrary”文件夾下的”剪貼板”庫文件,來快速的建立自己的常用代碼庫(用EditPlus就可以打開,格式看一下就懂了。編輯好以后要重新”Reload”一下,或者重新啟動一下才能刷新哦)。
3:側邊欄可以放在左邊,也可以放在右面。設置的方法是:在側邊欄點擊鼠標右鍵 → 選擇【Location】菜單內的left或者right。
華麗的自動完成功能
<ul>
<li><a href=”" mce_href=”" title=”"></a></li>
<li><a href=”" mce_href=”" title=”"></a></li>
<li><a href=”" mce_href=”" title=”"></a></li>
<li><a href=”" mce_href=”" title=”"></a></li>
<li><a href=”" mce_href=”" title=”"></a></li>
</ul>可以說是俺最喜歡的功能了。想象一下,作為一個經常制作網頁的人來所,當你打一個”ua”字,然后按下空格,編輯器里面就出現了右邊的代碼,而且鼠標就停留在第一個href的雙引號之間。那是多么愉快的事情。這就是EditPlus的自動完成功能,使用EditPlus的自動完成功能將會極大的提高你的工作效率。而且我們可以根據不同的文件類型,建立不同的”自動完成”,例如,如果是xhtml文件,打”b”+ 空格”,就是 <strong></strong>,而在css文件中,”b”+ 空格”,就是 “border:1px solid red;”。非常的人性化。
你可以通過這樣的設置,來使用EditPlus的自動完成功能。【Tools】→【Preperences】→ 【Files】→ 【Settings & syntax】 → 在【File types】中設置一下文件類型,然后再【Auto completion】中選擇自動完成文件即可(如果你使用的是我那個 EditPlus壓縮包文件,請注意調整這里的自動完成文件的路徑)。自動完成文件我們可以自己進行編輯,這里我舉個簡單的例子,展開下面的代碼,這個便是我css文件自動完成的文件內容,以第11行的”#T=bor”為例,它的意思就是如果輸入bor然后按空格,就在光標所在位置插入”border:1px solid red;”
關于”自動完成”文件再說兩句:
1:在我提供的那個 EditPlus壓縮包文件中”自動完成”文件存放在解壓目錄下的”\yzyFile\AutoCompletion”文件夾下。
2:你可以通過直接編輯,解壓目錄下的”\yzyFile\AutoCompletion”文件夾下的EditPlus自動完成文件,來快速的建立自己的EditPlus自動完成文件。
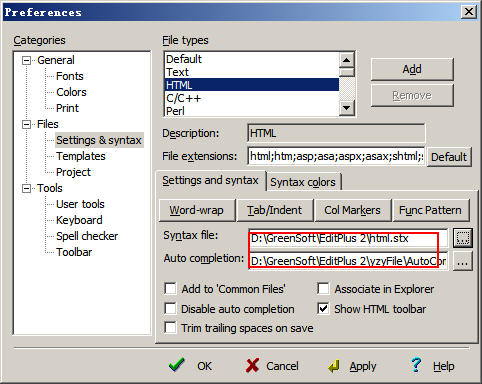
圖5:”自動完成”和”高亮語法”設置對話框
彩色的文件,高亮語法文件
很多的開發工具都有語法高亮顯示功能,EditPlus雖小,但是也有這個功能哦。設置方法可以參考圖片5所示。和”自動完成”功能一樣,只要為不同的文件類型指定”高亮語法”文件即可。css、html等常用的文件類型,EditPlus已經自帶了高亮語法文件。如果自帶的高亮語法文件沒有你需要的,你可以去EditPlus官方網站的文件下載頻道去看看,來自全球各地的朋友,貢獻了很多的不同文件類型的高亮語法文件。可以很方便地免費下載到。
這里就稍微列舉一下比較常用的EditPlus的高亮語法文件,更多的請到EditPlus的官方網站下載,EditPlus的官方地址為: http://www.editplus.com/files.html
EditPlus正則表達式
EditPlus中的查找(替換)功能,支持正則表達式。使用正則表達式可以極大的提高查找(替換)的強悍程度。因為正則表達式這東西不是一句話就能說完的,而且偏離此篇文章主題,所以這里只列舉幾個常用的例子。對此有興趣的可以參考正則表達式資料,或者在EditPlus的help中”Regular Expression”關鍵字進行索引查找。
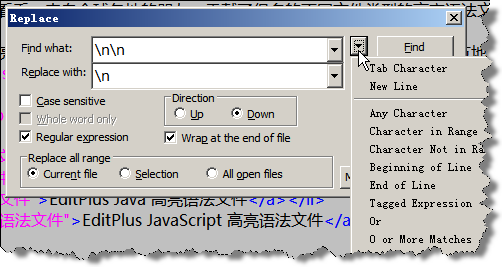
圖6:在查找(替換)對話框中使用正則表達式使用正則表達式進行查找(替換)的方法如上圖所示,選擇查找(替換)對話框中”Regular Expression”前面checkbox。點擊查找(替換)文本框后的”倒三角”可以選擇常用的正則表達式。
正則表達式實例
| 需求說明 |
正則表達式寫法 |
備注 |
| 替換指定內容(以abc為例)到行尾 |
abc.* |
“.”表示匹配任意字符;”*”表示匹配0次或更多 |
| 給所有的數字加上引號 |
查找[0-9]替換為”\0″ |
\0表示正則表達式匹配的對象 |
| 刪除空白行 |
查找\n\n 替換為\n |
把連續的2個換行符,替換成一個換行符 |
矩形選區
看到這個詞,好像是說圖像處理工具,其實非也,不管是VS還是EditPlus,其實都是支持矩形選區的。這對處理一些形如:去掉文章前端行號的情況有特效,矩形全區的選取方式就是按住Alt鍵,然后用鼠標劃矩形選區(如圖7所示)。需要注意到是在”自動換行”的情況下,是不能使用”矩形選區”的。你可以使用Ctrl+Shift +W來切換”自動換行”或者”不自動換行”視圖。
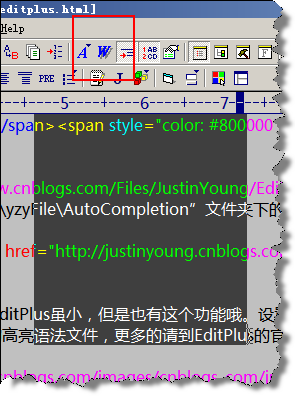
圖7:在EditPlus中選取矩形選區(注意紅色框內的”自動換行圖標”)
提高工作效率,EditPlus 快捷鍵的使用
如果一個來你們公司面試程序員,連Ctrl + C 和Ctrl + V 都不用,而是使用”選中文本”→ 鼠標右鍵 → 【復制】,然后再鼠標右鍵→ 【粘貼】。你會不會錄用他呢?(你還別笑,以前我們公司還真面試過一個這樣的,所謂的”精通asp.net”的程序員)。所以熟練的使用軟件的快捷鍵,不僅僅能夠極大的提高工作效率,也從一個側面表現出一個人對此軟件的使用能力。EditPlus同樣也有很多的快捷鍵,下面是一些我經常使用的EditPlus特有的快捷鍵(Ctrl +C 、Ctrl+H這樣的通用快捷鍵就不介紹了),略舉一二,更多的請參看文章《EditPlus快捷鍵》
| 以瀏覽器模式預覽文件 |
Ctrl + B |
| 開始編輯”以瀏覽器模式預覽的文件” |
Ctrl + E |
| 新建html文件 |
Ctrl+Shift+N |
| 新建瀏覽器窗口(類似于在EditPlus中打開ie) |
Ctrl+Shift+B |
| 選中的字母切換為小寫 |
Ctrl+L |
| 選中的字母切換為大寫 |
Ctrl+U |
| 選中的詞組首字母大寫 |
Ctrl+Shift+U |
| 復制選定文本并追加到剪貼板中 |
Ctrl+Shift+C |
| 剪切選定文本并追加到剪貼板中 |
Ctrl+Shift+X |
| 創建當前行的副本 |
Ctrl+J |
| 復制上一行的一個字符到當前行 |
Ctrl+- |
| 剪切選定文本并追加到剪貼板中 |
Ctrl+Shift+X |
| 合并選定行 |
Ctrl+Shift+J |
| 反轉選定文本的大小寫 |
Ctrl+K |
| 開始/結束選擇區域 |
Alt+Shift+B |
| 選擇當前行 |
Ctrl+R |
| 全屏模式開/關 |
Ctrl+K |
| 顯示或隱藏標尺 |
Alt+Shift+R |
| 顯示或隱藏制表符與空格 |
Alt+Shift+I |
| 顯示函數列表 |
Ctrl+F11 |
| 轉到當前文檔的指定行 |
Ctrl + G |
| 設置或清除當前行的標記 |
F9 |
| 轉到下一個標記位置 |
F4 |
| 轉到上一個標記位置 |
Shift+F4 |
| 清除當前文檔中的所有標記 |
Ctrl+Shift+F9 |
| 搜索一對匹配的括號 |
Ctrl+] |
| 搜索一對匹配的括號并選擇該文本 |
Ctrl+Shift+] |
| 切換當前文檔的自動換行功能 |
Ctrl+Shift+W |
| 編輯當前 HTML 頁面的源文件 |
Ctrl+E |
2009年9月1日
#
2009年7月24日
#
常用的類有BufferedReader,
Scanner。
實例程序:
一,利用 Scanner 實現從鍵盤讀入integer或float 型數據
import
java.util.*;
//import
java.io.*;
class Abc
{
public static
void main(String args[])
{
Scanner in=new
Scanner(System.in); //使用Scanner類定義對象
System.out.println("please input a float number");
float
a=in.nextFloat(); //接收float型數據
System.out.println(a);
System.out.println("please input a integer number");
int
b=in.nextInt(); //接收整形數據
System.out.println(b);
}
}
二,利用 BufferedReader實現從鍵盤讀入字符串并寫進文件abc.txt中
import java.io.*;
public class
Test1
{
public static
void main(String[] args) throws IOException
{
BufferedReader buf = new
BufferedReader (new
InputStreamReader(System.in));
BufferedWriter buff = new
BufferedWriter(new FileWriter("abc.txt"));
String str = buf.readLine();
while(!str.equals("exit"))
{
buff.write(str);
buff.newLine();
str = buf.readLine();
}
buf.close();
buff.close();
}
}
關于JDK1.5 Scanner類的說明
Scanner是SDK1.5新增的一個類,可是使用該類創建一個對象.
Scanner reader=new Scanner(System.in);
然后reader對象調用下列方法(函數),讀取用戶在命令行輸入的各種數據類型:
next.Byte(),nextDouble(),nextFloat,nextInt(),nextLine(),nextLong(),nextShot()
使用nextLine()方法輸入行中可能包含空格.如果讀取的是一個單詞,則可調用
.next()方法
2009年7月15日
#
Java語言細節
Java作為一門優秀的面向對象的程序設計語言,正在被越來越多的人使用。本文試圖列出作者在實際開發中碰到的一些Java語言的容易被人忽視的細節,希望能給正在學習Java語言的人有所幫助。
1,位移運算越界怎么處理
考察下面的代碼輸出結果是多少?
int a=5;
System.out.println(a<<33);
按照常理推測,把a左移33位應該將a的所有有效位都移出去了,那剩下的都是零啊,所以輸出結果應該是0才對啊,可是執行后發現輸出結果是10,為什么
呢?因為Java語言對位移運算作了優化處理,Java語言對a<<b轉化為a<<(b%32)來處理,所以當要移位的位數b超
過32時,實際上移位的位數是b%32的值,那么上面的代碼中a<<33相當于a<<1,所以輸出結果是10。
2,可以讓i!=i嗎?
當你看到這個命題的時候一定會以為我瘋了,或者Java語言瘋了。這看起來是絕對不可能的,一個數怎么可能不等于它自己呢?或許就真的是Java語言瘋了,不信看下面的代碼輸出什么?
double i=0.0/0.0;
if(i==i){
System.out.println("Yes i==i");
}else{
System.out.println("No i!=i");
}
上面的代碼輸出"No i!=i",為什么會這樣呢?關鍵在0.0/0.0這個值,在IEEE
754浮點算術規則里保留了一個特殊的值用來表示一個不是數字的數量。這個值就是NaN("Not a
Number"的縮寫),對于所有沒有良好定義的浮點計算都將得到這個值,比如:0.0/0.0;其實我們還可以直接使用Double.NaN來得到這個
值。在IEEE 754規范里面規定NaN不等于任何值,包括它自己。所以就有了i!=i的代碼。
3,怎樣的equals才安全?
我們都知道在Java規范里定義了equals方法覆蓋的5大原則:reflexive(反身性),symmetric(對稱性),transitive(傳遞性),consistent(一致性),non-null(非空性)。那么考察下面的代碼:
public class Student{
private String name;
private int age;
public Student(String name,int age){
this.name=name;
this.age=age;
}
public boolean equals(Object obj){
if(obj instanceof Student){
Student s=(Student)obj;
if(s.name.equals(this.name) && s.age==this.age){
return true;
}
}
return super.equals(obj);
}
}
你認為上面的代碼equals方法的覆蓋安全嗎?表面看起來好像沒什么問題,這樣寫也確實滿足了以上的五大原則。但其實這樣的覆蓋并不很安全,假如
Student類還有一個子類CollegeStudent,如果我拿一個Student對象和一個CollegeStudent對象equals,只要
這兩個對象有相同的name和age,它們就會被認為相等,但實際上它們是兩個不同類型的對象啊。問題就出在instanceof這個運算符上,因為這個
運算符是向下兼容的,也就是說一個CollegeStudent對象也被認為是一個Student的實例。怎樣去解決這個問題呢?那就只有不用
instanceof運算符,而使用對象的getClass()方法來判斷兩個對象是否屬于同一種類型,例如,將上面的equals()方法修改為:
public boolean equals(Object obj){
if(obj.getClass()==Student.class){
Student s=(Student)obj;
if(s.name.equals(this.name) && s.age==this.age){
return true;
}
}
return super.equals(obj);
}
這樣才能保證obj對象一定是Student的實例,而不會是Student的任何子類的實例。
4,淺復制與深復制
1)淺復制與深復制概念
⑴淺復制(淺克隆)
被復制對象的所有變量都含有與原來的對象相同的值,而所有的對其他對象的引用仍然指向原來的對象。換言之,淺復制僅僅復制所考慮的對象,而不復制它所引用的對象。
⑵深復制(深克隆)
被復制對象的所有變量都含有與原來的對象相同的值,除去那些引用其他對象的變量。那些引用其他對象的變量將指向被復制過的新對象,而不再是原有的那些被引用的對象。換言之,深復制把要復制的對象所引用的對象都復制了一遍。
2)Java的clone()方法
⑴clone方法將對象復制了一份并返回給調用者。一般而言,clone()方法滿足:
①對任何的對象x,都有x.clone() !=x//克隆對象與原對象不是同一個對象
②對任何的對象x,都有x.clone().getClass()= =x.getClass()//克隆對象與原對象的類型一樣
③如果對象x的equals()方法定義恰當,那么x.clone().equals(x)應該成立。
⑵Java中對象的克隆
①為了獲取對象的一份拷貝,我們可以利用Object類的clone()方法。
②在派生類中覆蓋基類的clone()方法,并聲明為public。
③在派生類的clone()方法中,調用super.clone()。
④在派生類中實現Cloneable接口。
請看如下代碼:
class Student implements Cloneable{
String name;
int age;
Student(String name,int age){
this.name=name;
this.age=age;
}
public Object clone(){
Object obj=null;
try{
obj=(Student)super.clone();
//Object中的clone()識別出你要復制的是哪一個對象。
}
catch(CloneNotSupportedException e){
e.printStackTrace();
}
return obj;
}
}
public static void main(String[] args){
Student s1=new Student("zhangsan",18);
Student s2=(Student)s1.clone();
s2.name="lisi";
s2.age=20;
System.out.println("name="+s1.name+","+"age="+s1.age);//修改學生2
//后,不影響學生1的值。
}
說明:
①為什么我們在派生類中覆蓋Object的clone()方法時,一定要調用super.clone()呢?在運行時刻,Object中的clone()
識別出你要復制的是哪一個對象,然后為此對象分配空間,并進行對象的復制,將原始對象的內容一一復制到新對象的存儲空間中。
②繼承自java.lang.Object類的clone()方法是淺復制。以下代碼可以證明之。
class Teacher{
String name;
int age;
Teacher(String name,int age){
this.name=name;
this.age=age;
}
}
class Student implements Cloneable{
String name;
int age;
Teacher t;//學生1和學生2的引用值都是一樣的。
Student(String name,int age,Teacher t){
this.name=name;
this.age=age;
this.t=t;
}
public Object clone(){
Student stu=null;
try{
stu=(Student)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
stu.t=(Teacher)t.clone();
return stu;
}
public static void main(String[] args){
Teacher t=new Teacher("tangliang",30);
Student s1=new Student("zhangsan",18,t);
Student s2=(Student)s1.clone();
s2.t.name="tony";
s2.t.age=40;
System.out.println("name="+s1.t.name+","+"age="+s1.t.age);
//學生1的老師成為tony,age為40。
}
}
那應該如何實現深層次的克隆,即修改s2的老師不會影響s1的老師?代碼改進如下。
class Teacher implements Cloneable{
String name;
int age;
Teacher(String name,int age){
this.name=name;
this.age=age;
}
public Object clone(){
Object obj=null;
try{
obj=super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
return obj;
}
}
class Student implements Cloneable{
String name;
int age;
Teacher t;
Student(String name,int age,Teacher t){
this.name=name;
this.age=age;
this.t=t;
}
public Object clone(){
Student stu=null;
try{
stu=(Student)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
stu.t=(Teacher)t.clone();
return stu;
}
}
public static void main(String[] args){
Teacher t=new Teacher("tangliang",30);
Student s1=new Student("zhangsan",18,t);
Student s2=(Student)s1.clone();
s2.t.name="tony";
s2.t.age=40;
System.out.println("name="+s1.t.name+","+"age="+s1.t.age);
//學生1的老師不改變。
}
3)利用串行化來做深復制
把對象寫到流里的過程是串行化(Serilization)過程,Java程序員又非常形象地稱為“冷凍”或者“腌咸菜(picking)”過程;而把對
象從流中讀出來的并行化(Deserialization)過程則叫做“解凍”或者“回鮮(depicking)”過程。應當指出的是,寫在流里的是對象
的一個拷貝,而原對象仍然存在于JVM里面,因此“腌成咸菜”的只是對象的一個拷貝,Java咸菜還可以回鮮。
在Java語言里深復制一個對象,常常可以先使對象實現Serializable接口,然后把對象(實際上只是對象的一個拷貝)寫到一個流里(腌成咸菜),再從流里讀出來(把咸菜回鮮),便可以重建對象。
如下為深復制源代碼。
public Object deepClone(){
//將對象寫到流里
ByteArrayOutoutStream bo=new ByteArrayOutputStream();
ObjectOutputStream oo=new ObjectOutputStream(bo);
oo.writeObject(this);
//從流里讀出來
ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi=new ObjectInputStream(bi);
return(oi.readObject());
}
這樣做的前提是對象以及對象內部所有引用到的對象都是可串行化的,否則,就需要仔細考察那些不可串行化的對象可否設成transient,從而將之排除在復制過程之外。上例代碼改進如下。
class Teacher implements Serializable{
String name;
int age;
Teacher(String name,int age){
this.name=name;
this.age=age;
}
}
class Student implements Serializable
{
String name;//常量對象。
int age;
Teacher t;//學生1和學生2的引用值都是一樣的。
Student(String name,int age,Teacher t){
this.name=name;
this.age=age;
this.p=p;
}
public Object deepClone() throws IOException,
OptionalDataException,ClassNotFoundException
{
//將對象寫到流里
ByteArrayOutoutStream bo=new ByteArrayOutputStream();
ObjectOutputStream oo=new ObjectOutputStream(bo);
oo.writeObject(this);
//從流里讀出來
ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi=new ObjectInputStream(bi);
return(oi.readObject());
}
}
public static void main(String[] args){
Teacher t=new Teacher("tangliang",30);
Student s1=new Student("zhangsan",18,t);
Student s2=(Student)s1.deepClone();
s2.t.name="tony";
s2.t.age=40;
System.out.println("name="+s1.t.name+","+"age="+s1.t.age);
//學生1的老師不改變。
}
5,String類和對象池 我們知道得到String對象有兩種辦法: String str1="hello"; String str2=new
String("hello");
這兩種創建String對象的方法有什么差異嗎?當然有差異,差異就在于第一種方法在對象池中拿對象,第二種方法直接生成新的對象。在JDK5.0里面,
Java虛擬機在啟動的時候會實例化9個對象池,這9個對象池分別用來存儲8種基本類型的包裝類對象和String對象。當我們在程序中直接用雙引號括起
來一個字符串時,JVM就到String的對象池里面去找看是否有一個值相同的對象,如果有,就拿現成的對象,如果沒有就在對象池里面創建一個對象,并返
回。所以我們發現下面的代碼輸出true: String str1="hello"; String str2="hello";
System.out.println(str1==str2);
這說明str1和str2指向同一個對象,因為它們都是在對象池中拿到的,而下面的代碼輸出為false: String str3="hello"
String str4=new String("hello"); System.out.println(str3==str4);
因為在任何情況下,只要你去new一個String對象那都是創建了新的對象。
與此類似的,在JDK5.0里面8種基本類型的包裝類也有這樣的差異: Integer i1=5;//在對象池中拿 Integer i2
=5;//所以i1==i2 Integer i3=new Integer(5);//重新創建新對象,所以i2!=i3
對象池的存在是為了避免頻繁的創建和銷毀對象而影響系統性能,那我們自己寫的類是否也可以使用對象池呢?當然可以,考察以下代碼: class
Student{ private String name; private int age; private static HashSet pool=new HashSet();//對象池
public Student(String name,int age){
this.name=name;
this.age=age;
}
//使用對象池來得到對象的方法
public static Student newInstance(String name,int age){
//循環遍歷對象池
for(Student stu:pool){
if(stu.name.equals(name) && stu.age==age){
return stu;
}
}
//如果找不到值相同的Student對象,則創建一個Student對象
//并把它加到對象池中然后返回該對象。
Student stu=new Student(name,age);
pool.add(stu);
return stu;
}
}
public class Test{
public static void main(String[] args){
Student stu1=Student.newInstance("tangliang",30);//對象池中拿
Student stu2=Student.newInstance("tangliang",30);//所以stu1==stu2
Student stu3=new Student("tangliang",30);//重新創建,所以stu1!=stu3
System.out.println(stu1==stu2);
System.out.println(stu1==stu3);
}
}
6,2.0-1.1==0.9嗎? 考察下面的代碼: double a=2.0,b=1.1,c=0.9; if(a-b==c){
System.out.println("YES!"); }else{ System.out.println("NO!"); }
以上代碼輸出的結果是多少呢?你認為是“YES!”嗎?那么,很遺憾的告訴你,不對,Java語言再一次cheat了你,以上代碼會輸出“NO!”。為什
么會這樣呢?其實這是由實型數據的存儲方式決定的。我們知道實型數據在內存空間中是近似存儲的,所以2.0-1.1的結果不是0.9,而是
0.88888888889。所以在做實型數據是否相等的判斷時要非常的謹慎。一般來說,我們不建議在代碼中直接判斷兩個實型數據是否相等,如果一定要比
較是否相等的話我們也采用以下方式來判斷: if(Math.abs(a-b)<1e-5){ //相等 }else{ //不相等 }
上面的代碼判斷a與b之差的絕對值是否小于一個足夠小的數字,如果是,則認為a與b相等,否則,不相等。
7,判斷奇數 以下的方法判斷某個整數是否是奇數,考察是否正確: public boolean isOdd(int n){ return
(n%2==1); }
很多人認為上面的代碼沒問題,但實際上這段代碼隱藏著一個非常大的BUG,當n的值是正整數時,以上的代碼能夠得到正確結果,但當n的值是負整數時,以上
方法不能做出正確判斷。例如,當n=-3時,以上方法返回false。因為根據Java語言規范的定義,Java語言里的求余運算符(%)得到的結果與運
算符左邊的值符號相同,所以,-3%2的結果是-1,而不是1。那么上面的方法正確的寫法應該是: public boolean isOdd(int
n){ return (n%2!=0); }
8,拓寬數值類型會造成精度丟失嗎?
Java語言的8種基本數據類型中7種都可以看作是數值類型,我們知道對于數值類型的轉換有一個規律:從窄范圍轉化成寬范圍能夠自動類型轉換,反之則必須
強制轉換。請看下圖:
byte-->short-->int-->long-->float-->double
char-->int
我們把順箭頭方向的轉化叫做拓寬類型,逆箭頭方向的轉化叫做窄化類型。一般我們認為因為順箭頭方向的轉化不會有數據和精度的丟失,所以Java語言允許自
動轉化,而逆箭頭方向的轉化可能會造成數據和精度的丟失,所以Java語言要求程序員在程序中明確這種轉化,也就是強制轉換。那么拓寬類型就一定不會造成
數據和精度丟失嗎?請看下面代碼:
int i=2000000000;
int num=0;
for(float f=i;f
9,i=i+1和i+=1完全等價嗎?
可能有很多程序員認為i+=1只是i=i+1的簡寫方式,其實不然,它們一個使用簡單賦值運算,一個使用復合賦值運算,而簡單賦值運算和復合賦值運算的最
大差別就在于:復合賦值運算符會自動地將運算結果轉型為其左操作數的類型。看看以下的兩種寫法,你就知道它們的差別在哪兒了:
(1) byte i=5;
i+=1;
(2) byte i=5;
i=i+1;
第一種寫法編譯沒問題,而第二種寫法卻編譯通不過。原因就在于,當使用復合賦值運算符進行操作時,即使右邊算出的結果是int類型,系統也會將其值轉化為
左邊的byte類型,而使用簡單賦值運算時沒有這樣的優待,系統會認為將i+1的值賦給i是將int類型賦給byte,所以要求強制轉換。理解了這一點
后,我們再來看一個例子:
byte b=120;
b+=20;
System.out.println("b="+b);
說到這里你應該明白了,上例中輸出b的值不是140,而是-116。因為120+20的值已經超出了一個byte表示的范圍,而當我們使用復合賦值運
算時系統會自動作類型的轉化,將140強轉成byte,所以得到是-116。由此可見,在使用復合賦值運算符時還得小心,因為這種類型轉換是在不知不覺中
進行的,所以得到的結果就有可能和你的預想不一樣。
下面引用由zhangyue在 2007/09/01 09:07pm 發表的內容:
唐老師:
long類型為什么能自動轉換成float類型啊!!
long是64bits;
float是32bits;
...
long
能自動轉換為float,但這種轉換會造成精度的丟失,float中只保留了原來long類型的低24位的數據。這是Java語言中三種基本類型的自動轉
換會造成精度丟失的情況之一,另兩種情況是int-->float 和long-->double,詳情請參考:
8,拓寬數值類型會造成精度丟失嗎?
下面引用由plastrio在 2007/09/01 09:08am 發表的內容:
請教個問題 您給我們0703講線程時 有段課堂代碼為什么 用synchronized(Object obj) 鎖代碼塊而不是一般教程上講的 synchronized(this)
當兩個線程在運行時this不代表同一個對象時就不能用synchronized(this)來鎖。必須定義一個唯一的公共對象來聲明,如:synchronized(obj)
例如:
public class ThreadTest{
public static void main(String[] args){
Thread t1=new Thread(new ThreadA());
Thread t2=new Thread(new ThreadA());//兩個線程對應兩個不同的ThreadA對象。
t1.start();
t2.start();
}
}
class ThreadA implements Runnable{
static int i=0;
static Object obj=new Object();
public run(){
while(i<20){
synchronized(obj){//兩個線程在執行時所引用的this不是同一個對象,所以寫this就不能達到鎖的目的。
System.out.println(i);
i++;
}
}
}
}
在java語言中,位移操作共分三種,左位移(<<),右位移(>>)和無符號右位移(>>>)。如果將位移
運算表示為公式的話,即n operator
s。其中,operator表示上述的三種位移操作之一;n和s表示操作數,必須是可以轉化成int類型的,否則出現運行時錯誤。n是原始數值,s表示位
移距離。該公式的含義是n按照operator運算符含義位移s位。位移的距離使用掩碼32(類似于子網掩碼),即位移距離總是在0~31之間,超出這個
范圍的位移距離(包括負數)會被轉化在這個范圍里。也就是說真正的位移距離是n%32,所以唐老師的位移距離33實際上是1。n<<s的結果
(無論是否溢出)總是等價于n與2的n%32次冪的乘積。在唐老師的例子里面,位移距離是33%32即1,2的1次冪是2,5與2的乘積是10.所以最終
結果是10。對于右位移操作n<<s的結果(無論是否溢出)總是等價于n與2的n%32次冪的商。(以上內容參考java規范15.9)
2009年6月15日
#
抽象類
抽象類與接口緊密相關。然接口又比抽象類更抽象,這主要體現在它們的差別上:1)類可以實現無限個接口,但僅能從一個抽象(或任何其他類型)類繼承,從抽象類派生的類仍可實現接口,從而得出接口是用來解決多重繼承問題的。2)抽象類當中可以存在非抽象的方法,可接口不能且它里面的方法只是一個聲明必須用public來修飾沒有具體實現的方法。3)抽象類中的成員變量可以被不同的修飾符來修飾,可接口中的成員變量默認的都是靜態常量(static final)。4)這一點也是最重要的一點本質的一點"抽象類是對象的抽象,然接口是一種行為規范"。
以上是它們本身的異同,下面再來從實際應用講講它們的異同!
不同之處:
1、定義
抽象類表示該類中可能已經有一些方法的具體定義,但是接口就僅僅只能定義各個方法的界面(方法名,參數列表,返回類型),并不關心具體細節。
1、用法
1)在繼承抽象類時,必須覆蓋該類中的每一個抽象方法,而每個已實現的方法必須和抽象類中指定的方法一樣,接收相同數目和類型的參數,具有同樣的返回值,這一點與接口相同。
2)當父類已有實際功能的方法時,該方法在子類中可以不必實現,直接引用的方法,子類也可以重寫該父類的方法(繼承的概念)。
3)而實現 (implement)一個接口(interface)的時候,是一定要實現接口中所定義的所有方法,而不可遺漏任何一個。
4)另外,抽象類不能產生對象的,但可以由它的實現類來聲明對象。
有鑒于此,在實現接口時,我們也常寫一個抽象類,來實現接口中的某些子類所需的通用方法,接著在編寫各個子類時,即可繼承該抽象類來使用,省去在每個都要實現通用的方法的困擾。
多態(Polymorphism)按字面的意思就是“多種形狀”。引用Charlie Calverts對多態的描述——多態性是允許你將父對象設置成為和一個或更多的他的子對象相等的技術,賦值之后,父對象就可以根據當前賦值給它的子對象的特性以不同的方式運作(摘自“Delphi4 編程技術內幕”)。簡單的說,就是一句話:允許將子類類型的指針賦值給父類類型的指針。多態性在Object Pascal和C++中都是通過虛函數(Virtual Function) 實現的。
多態性是允許將父對象設置成為和一個或多個它的子對象相等的技術,比如Parent:=Child; 多態性使得能夠利用同一類(基類)類型的指針來引用不同類的對象,以及根據所引用對象的不同,以不同的方式執行相同的操作.
多態的作用:把不同的子類對象都當作父類來看,可以屏蔽不同子類對象之間的差異,寫出通用的代碼,做出通用的編程,以適應需求的不斷變化。
賦值之后,父對象就可以根據當前賦值給它的子對象的特性以不同的方式運作。也就是說,父親的行為像兒子,而不是兒子的行為像父親。
舉個例子:從一個基類中派生,響應一個虛命令,產生不同的結果。
比如從某個基類繼承出多個對象,其基類有一個虛方法Tdoit,然后其子類也有這個方法,但行為不同,然后這些子對象中的任何一個可以附給其基類的對象,這樣其基類的對象就可以執行不同的操作了。實際上你是在通過其基類來訪問其子對象的,你要做的就是一個賦值操作。
使用繼承性的結果就是可以創建一個類的家族,在認識這個類的家族時,就是把導出類的對象 當作基類的的對象,這種認識又叫作upcasting。這樣認識的重要性在于:我們可以只針對基類寫出一段程序,但它可以適 應于這個類的家族,因為編譯器會自動就找出合適的對象來執行操作。這種現象又稱為多態性。而實現多態性的手段又叫稱動態綁定(dynamic binding)。
簡單的說,建立一個父類的變量,它的內容可以是這個父類的,也可以是它的子類的,當子類擁有和父類同樣的函數,當使用這個變量調用這個函數的時候,定義這個變量的類,也就是父類,里的同名函數將被調用,當在父類里的這個函數前加virtual關鍵字,那么子類的同名函數將被調用
class A {
public:
A() {}
virtual void foo() {
cout << "This is A." << endl;
}
};
class B : public A {
public:
B() {}
void foo() {
cout << "This is B." << endl;
}
};
int main(int argc, char* argv[]) {
A *a = new B();
a->foo();
return 0;
}
這將顯示:
This is B.
如果把virtual去掉,將顯示:
This is A.
前面的多態實現使用抽象類,并定義了虛方法.
“繼承”(Inheritance)是面向對象軟件技術當中的一個概念,例如在java語言中,java語言中不支持多重繼承,是通過接口實現多重繼承的功能。如果一個類A繼承自另一個類B,就把這個A稱為"B的子類",而把B稱為"A的父類"。繼承可以使得子類具有父類的各種屬性和方法,而不需要再次編寫相同的代碼。在令子類繼承父類的同時,可以重新定義某些屬性,并重寫某些方法,即覆蓋父類的原有屬性和方法,使其獲得與父類不同的功能。盡管子類包括父類的所有成員,它不能訪問父類中被聲明成private 的成員 ...
繼承是指一個對象直接使用另一對象的屬性和方法。事實上,我們遇到的很多實體都有繼承的含義。例如,若把汽車看成一個實體,它可以分成多個子實體,如:卡車、公共汽車等。這些子實體都具有汽車的特性,因此,汽車是它們的"父親",而這些子實體則是汽車的"孩子"。
繼承的目的:實現代碼重用
派生類聲明:
class 派生類名:繼承方式 基類名
{
新增成員聲明;
};
三種繼承方式
公有繼承 public (原封不動)
保護繼承 protected (折中)
私有繼承 private (化公為私)
繼承方式影響子類的訪問權限:
派生類成員對基類成員的訪問權限
通過派生類對象對基類成員的訪問權限
同類事物具有共同性,在同類事物中,每個事物又具有其特殊性。運用抽象的原則舍棄對象的特殊性,抽取其共同性,則得到一個適應于一批對象的類,這便是基類(父類),而把具有特殊性的類稱為派生類(子類),派生類的對象擁有其基類的全部或部分屬性與方法,稱作派生類對基類的繼承。
1、我們先建立基類BaseClass.class,然后再從該類派生新類InherienceTest,展示從基類派生的方法(Methord)及基類構造函數的執行。
package InherienceTest.BaseClass;//package 后能被繼承,不過不能執行
public class BaseClass
{
public BaseClass(){
System.out.println("I’m the Constructor Function in BaseClass!");
}
protected static void FuncTest(){
System.out.println("This is a Function Test in BaseClass!");//Static Methord
}
public static void main(String[] args){
FuncTest();
System.out.println("This is the BaseClass!");
System.out.println(new java.util.Date());
}
};
import InherienceTest.BaseClass.BaseClass;//相當于路徑:path & InherienceTest\BaseClass\BaseClass.class
public class
InherienceTest extends BaseClass//注意:public主類名必須和文件名相同
{
//基類不能和派生類在同一目錄下面。
public static void main(String[] args)
//main函數必須是pulic static
{
InherienceTest xx=new InherienceTest();//構造函數被執行
xx.FuncTest();
//調用繼承的方法
System.out.println("Hello World!");
}
}
枚舉的確是一個類,在JDK1.4及以前,沒有enum這個用法,那時候都是使用類來建立的,在《Java編程思想》中介紹了一類寫法(詳見第三版的章節8.1.3群組常量);JDK5以后,enum被引入,本質上就是一個類,所以可以被繼承,總體思路和第三版這個寫法類似,只是換了個名字(《Java編程思想》第四版第19章專門講這個)
Enum作為Sun全新引進的一個關鍵字,看起來很象是特殊的class, 它也可以有自己的變量,可以定義自己的方法,可以實現一個或者多個接口。 當我們在聲明一個enum類型時,我們應該注意到enum類型有如下的一些特征。
枚舉類型的本質:定義枚舉類型就是定義一個類別,只不過很多細節由編譯器幫您完成了,所以在某些程度上,enum關鍵字的作用就像是class或interface。
當您使用"enum"定義枚舉類型時,實質上您定義出來的類型繼承自java.lang.Enum類型,而每個枚舉的成員其實就是您定義的枚舉類型的一個個實例(instance),它們都是 public static final型的成員。不可更改它們,可直接使用。
1.它不能有public的構造函數,這樣做可以保證客戶代碼沒有辦法新建一個enum的實例。
2.所有枚舉值都是public , static , final的。注意這一點只是針對于枚舉值,我們可以和在普通類里面定義 變量一樣定義其它任何類型的非枚舉變量,這些變量可以用任何你想用的修飾符。
3.Enum默認實現了java.lang.Comparable接口。
4.Enum覆載了了toString方法,因此我們如果調用Color.Blue.toString()默認返回字符串”Blue”.
5.Enum提供了一個valueOf方法,這個方法和toString方法是相對應的。調用valueOf(“Blue”)將返回Color.Blue.因此我們在自己重寫toString方法的時候就要注意到這一點,一把來說應該相對應地重寫valueOf方法。
6.Enum還提供了values方法,這個方法使你能夠方便的遍歷所有的枚舉值。
7.Enum還有一個oridinal的方法,這個方法返回枚舉值在枚舉類種的順序,這個順序根據枚舉值聲明的順序而定,這里Color.Red.ordinal()返回0。
了解了這些基本特性,我們來看看如何使用它們。
1.遍歷所有有枚舉值. 知道了有values方法,我們可以輕車熟路地用ForEach循環來遍歷了枚舉值了。
for (Color c: Color.values())
System.out.println(“find value:” + c);
2.在enum中定義方法和變量,比如我們可以為Color增加一個方法隨機返回一個顏色。
public enum Color {
Red,
Green,
Blue;
/*
*定義一個變量表示枚舉值的數目。
*(我有點奇怪為什么sun沒有給enum直接提供一個size方法).
*/
private static int number = Color.values().length ;
/**
* 隨機返回一個枚舉值
@return a random enum value.
*/
public static Color getRandomColor(){
long random = System.currentTimeMillis() % number;
switch ((int) random){
case 0:
return Color.Red;
case 1:
return Color.Green;
case 2:
return Color.Blue;
default : return Color.Red;
}
}
}
可以看出這在枚舉類型里定義變量和方法和在普通類里面定義方法和變量沒有什么區別。唯一要注意的只是變量和方法定義必須放在所有枚舉值定義的后面,否則編譯器會給出一個錯誤。
3.覆載(Override)toString, valueOf方法
前面我們已經知道enum提供了toString,valueOf等方法,很多時候我們都需要覆載默認的toString方法,那么對于enum我們怎么做呢。其實這和覆載一個普通class的toString方法沒有什么區別。
….
public String toString(){
switch (this){
case Red:
return "Color.Red";
case Green:
return "Color.Green";
case Blue:
return "Color.Blue";
default:
return "Unknow Color";
}
}
….
這時我們可以看到,此時再用前面的遍歷代碼打印出來的是
Color.Red
Color.Green
Color.Blue
而不是
Red
Green
Blue.
可以看到toString確實是被覆載了。一般來說在覆載toString的時候我們同時也應該覆載valueOf方法,以保持它們相互的一致性。
4.使用構造函數
雖然enum不可以有public的構造函數,但是我們還是可以定義private的構造函數,在enum內部使用。還是用Color這個例子。
public enum Color {
Red("This is Red"),
Green("This is Green"),
Blue("This is Blue");
private String desc;
Color(String desc){
this.desc = desc;
}
public String getDesc(){
return this.desc;
}
}
這里我們為每一個顏色提供了一個說明信息, 然后定義了一個構造函數接受這個說明信息。
要注意這里構造函數不能為public或者protected, 從而保證構造函數只能在內部使用,客戶代碼不能new一個枚舉值的實例出來。這也是完全符合情理的,因為我們知道枚舉值是public static final的常量而已。
5.實現特定的接口
我們已經知道enum可以定義變量和方法,它要實現一個接口也和普通class實現一個接口一樣,這里就不作示例了。
6.定義枚舉值自己的方法。
前面我們看到可以為enum定義一些方法,其實我們甚至可以為每一個枚舉值定義方法。這樣,我們前面覆載 toString的例子可以被改寫成這樣。
public enum Color {
Red {
public String toString(){
return "Color.Red";
}
},
Green {
public String toString(){
return "Color.Green";
}
},
Blue{
public String toString(){
return "Color.Blue";
}
};
}
從邏輯上來說這樣比原先提供一個“全局“的toString方法要清晰一些。
總的來說,enum作為一個全新定義的類型,是希望能夠幫助程序員寫出的代碼更加簡單易懂,個
人覺得一般也不需要過多的使用enum的一些高級特性,否則就和簡單易懂的初衷想違背了。
【轉載】
一、理解多線程 多線程是這樣一種機制,它允許在程序中并發執行多個指令流,每個指令流都稱為一個線程,彼此間互相獨立。
線程又稱為輕量級進程,它和進程一樣擁有獨立的執行控制,由
操作系統負責調度,區別在于線程沒有獨立的存儲空間,而是和所屬進程中的其它線程共享一個存儲空間,這使得線程間的通信遠較進程簡單。
多個線程的執行是并發的,也就是在邏輯上“同時”,而不管是否是物理上的“同時”。如果系統只有一個CPU,那么真正的“同時”是不可能的,但是由于CPU的速度非常快,用戶感覺不到其中的區別,因此我們也不用關心它,只需要設想各個線程是同時執行即可。
多線程和傳統的單線程在程序設計上最大的區別在于,由于各個線程的控制流彼此獨立,使得各個線程之間的代碼是亂序執行的,由此帶來的線程調度,同步等問題,將在以后探討。
二、在Java中實現多線程
我們不妨設想,為了創建一個新的線程,我們需要做些什么?很顯然,我們必須指明這個線程所要執行的代碼,而這就是在Java中實現多線程我們所需要做的一切!
真是神奇!Java是如何做到這一點的?通過類!作為一個完全面向對象的語言,Java提供了類java.lang.Thread來方便多線程編程,這個類提供了大量的方法來方便我們控制自己的各個線程,我們以后的討論都將圍繞這個類進行。
那么如何提供給 Java 我們要線程執行的代碼呢?讓我們來看一看 Thread 類。Thread 類最重要的方法是run(),它為Thread類的方法start()所調用,提供我們的線程所要執行的代碼。為了指定我們自己的代碼,只需要覆蓋它!
方法一:繼承 Thread 類,覆蓋方法 run(),我們在創建的 Thread 類的子類中重寫 run() ,加入線程所要執行的代碼即可。下面是一個例子:
public class MyThread extends Thread
{
int count= 1, number;
public MyThread(int num)
{
number = num;
System.out.println
("創建線程 " + number);
}
public void run() {
while(true) {
System.out.println
("線程 " + number + ":計數 " + count);
if(++count== 6) return;
}
}
public static void main(String args[])
{
for(int i = 0;
i 〈 5; i++) new MyThread(i+1).start();
}
}
這種方法簡單明了,符合大家的習慣,但是,它也有一個很大的缺點,那就是如果我們的類已經從一個類繼承(如小程序必須繼承自 Applet 類),則無法再繼承 Thread 類,這時如果我們又不想建立一個新的類,應該怎么辦呢?
我們不妨來探索一種新的方法:我們不創建Thread類的子類,而是直接使用它,那么我們只能將我們的方法作為參數傳遞給 Thread 類的實例,有點類似回調函數。但是 Java 沒有指針,我們只能傳遞一個包含這個方法的類的實例。
那么如何限制這個類必須包含這一方法呢?當然是使用接口!(雖然抽象類也可滿足,但是需要繼承,而我們之所以要采用這種新方法,不就是為了避免繼承帶來的限制嗎?)
Java 提供了接口 java.lang.Runnable 來支持這種方法。
方法二:實現 Runnable 接口
Runnable接口只有一個方法run(),我們聲明自己的類實現Runnable接口并提供這一方法,將我們的線程代碼寫入其中,就完成了這一部分的任務。但是Runnable接口并沒有任何對線程的支持,我們還必須創建Thread類的實例,這一點通過Thread類的構造函數public Thread(Runnable target);來實現。下面是一個例子:
public class MyThread implements Runnable
{
int count= 1, number;
public MyThread(int num)
{
number = num;
System.out.println("創建線程 " + number);
}
public void run()
{
while(true)
{
System.out.println
("線程 " + number + ":計數 " + count);
if(++count== 6) return;
}
}
public static void main(String args[])
{
for(int i = 0; i 〈 5;
i++) new Thread(new MyThread(i+1)).start();
}
}
嚴格地說,創建Thread子類的實例也是可行的,但是必須注意的是,該子類必須沒有覆蓋 Thread 類的 run 方法,否則該線程執行的將是子類的 run 方法,而不是我們用以實現Runnable 接口的類的 run 方法,對此大家不妨試驗一下。
使用 Runnable 接口來實現多線程使得我們能夠在一個類中包容所有的代碼,有利于封裝,它的缺點在于,我們只能使用一套代碼,若想創建多個線程并使各個線程執行不同的代碼,則仍必須額外創建類,如果這樣的話,在大多數情況下也許還不如直接用多個類分別繼承 Thread 來得緊湊。
綜上所述,兩種方法各有千秋,大家可以靈活運用。
下面讓我們一起來研究一下多線程使用中的一些問題。
三、線程的四種狀態
1. 新狀態:線程已被創建但尚未執行(start() 尚未被調用)。
2. 可執行狀態:線程可以執行,雖然不一定正在執行。CPU 時間隨時可能被分配給該線程,從而使得它執行。
3. 死亡狀態:正常情況下 run() 返回使得線程死亡。調用 stop()或 destroy() 亦有同樣效果,但是不被推薦,前者會產生異常,后者是強制終止,不會釋放鎖。
4. 阻塞狀態:線程不會被分配 CPU 時間,無法執行。
四、線程的優先級
線程的優先級代表該線程的重要程度,當有多個線程同時處于可執行狀態并等待獲得 CPU 時間時,線程調度系統根據各個線程的優先級來決定給誰分配 CPU 時間,優先級高的線程有更大的機會獲得 CPU 時間,優先級低的線程也不是沒有機會,只是機會要小一些罷了。
你可以調用 Thread 類的方法 getPriority() 和 setPriority()來存取線程的優先級,線程的優先級界于1(MIN_PRIORITY)和10(MAX_PRIORITY)之間,缺省是5(NORM_PRIORITY)。
五、線程的同步
由于同一進程的多個線程共享同一片存儲空間,在帶來方便的同時,也帶來了訪問沖突這個嚴重的問題。Java語言提供了專門機制以解決這種沖突,有效避免了同一個數據對象被多個線程同時訪問。
由于我們可以通過 private 關鍵字來保證數據對象只能被方法訪問,所以我們只需針對方法提出一套機制,這套機制就是 synchronized 關鍵字,它包括兩種用法:synchronized 方法和 synchronized 塊。
1. synchronized 方法:通過在方法聲明中加入 synchronized關鍵字來聲明 synchronized 方法。如:
public synchronized void accessVal(int newVal);
synchronized 方法控制對類成員變量的訪問:每個類實例對應一把鎖,每個 synchronized 方法都必須獲得調用該方法的類實例的鎖方能執行,否則所屬線程阻塞,方法一旦執行,就獨占該鎖,直到從該方法返回時才將鎖釋放,此后被阻塞的線程方能獲得該鎖,重新進入可執行狀態。
這種機制確保了同一時刻對于每一個類實例,其所有聲明為 synchronized 的成員函數中至多只有一個處于可執行狀態(因為至多只有一個能夠獲得該類實例對應的鎖),從而有效避免了類成員變量的訪問沖突(只要所有可能訪問類成員變量的方法均被聲明為 synchronized)。
在 Java 中,不光是類實例,每一個類也對應一把鎖,這樣我們也可將類的靜態成員函數聲明為 synchronized ,以控制其對類的靜態成員變量的訪問。
synchronized 方法的缺陷:若將一個大的方法聲明為synchronized 將會大大影響效率,典型地,若將線程類的方法 run() 聲明為 synchronized ,由于在線程的整個生命期內它一直在運行,因此將導致它對本類任何 synchronized 方法的調用都永遠不會成功。當然我們可以通過將訪問類成員變量的代碼放到專門的方法中,將其聲明為 synchronized ,并在主方法中調用來解決這一問題,但是 Java 為我們提供了更好的解決辦法,那就是 synchronized 塊。
2. synchronized 塊:通過 synchronized關鍵字來聲明synchronized 塊。語法如下:
synchronized(syncObject)
{
//允許訪問控制的代碼
}
synchronized 塊是這樣一個代碼塊,其中的代碼必須獲得對象 syncObject (如前所述,可以是類實例或類)的鎖方能執行,具體機制同前所述。由于可以針對任意代碼塊,且可任意指定上鎖的對象,故靈活性較高。
六、線程的阻塞
為了解決對共享存儲區的訪問沖突,Java 引入了同步機制,現在讓我們來考察多個線程對共享資源的訪問,顯然同步機制已經不夠了,因為在任意時刻所要求的資源不一定已經準備好了被訪問,反過來,同一時刻準備好了的資源也可能不止一個。為了解決這種情況下的訪問控制問題,Java 引入了對阻塞機制的支持。
阻塞指的是暫停一個線程的執行以等待某個條件發生(如某資源就緒),學過操作系統的同學對它一定已經很熟悉了。Java 提供了大量方法來支持阻塞,下面讓我們逐一分析。
1. sleep() 方法:sleep() 允許 指定以毫秒為單位的一段時間作為參數,它使得線程在指定的時間內進入阻塞狀態,不能得到CPU 時間,指定的時間一過,線程重新進入可執行狀態。典型地,sleep() 被用在等待某個資源就緒的情形:測試發現條件不滿足后,讓線程阻塞一段時間后重新測試,直到條件滿足為止。
2. suspend() 和 resume() 方法:兩個方法配套使用,suspend()使得線程進入阻塞狀態,并且不會自動恢復,必須其對應的resume() 被調用,才能使得線程重新進入可執行狀態。典型地,suspend() 和 resume() 被用在等待另一個線程產生的結果的情形:測試發現結果還沒有產生后,讓線程阻塞,另一個線程產生了結果后,調用 resume() 使其恢復。
3. yield() 方法:yield() 使得線程放棄當前分得的 CPU 時間,但是不使線程阻塞,即線程仍處于可執行狀態,隨時可能再次分得 CPU 時間。調用 yield() 的效果等價于調度程序認為該線程已執行了足夠的時間從而轉到另一個線程。
4. wait() 和 notify() 方法:兩個方法配套使用,wait() 使得線程進入阻塞狀態,它有兩種形式,一種允許 指定以毫秒為單位的一段時間作為參數,另一種沒有參數,前者當對應的 notify() 被調用或者超出指定時間時線程重新進入可執行狀態,后者則必須對應的 notify() 被調用。
初看起來它們與 suspend() 和 resume() 方法對沒有什么分別,但是事實上它們是截然不同的。區別的核心在于,前面敘述的所有方法,阻塞時都不會釋放占用的鎖(如果占用了的話),而這一對方法則相反。
上述的核心區別導致了一系列的細節上的區別。
首先,前面敘述的所有方法都隸屬于 Thread 類,但是這一對卻直接隸屬于 Object 類,也就是說,所有對象都擁有這一對方法。初看起來這十分不可思議,但是實際上卻是很自然的,因為這一對方法阻塞時要釋放占用的鎖,而鎖是任何對象都具有的,調用任意對象的 wait() 方法導致線程阻塞,并且該對象上的鎖被釋放。
而調用 任意對象的notify()方法則導致因調用該對象的 wait() 方法而阻塞的線程中隨機選擇的一個解除阻塞(但要等到獲得鎖后才真正可執行)。
其次,前面敘述的所有方法都可在任何位置調用,但是這一對方法卻必須在 synchronized 方法或塊中調用,理由也很簡單,只有在synchronized 方法或塊中當前線程才占有鎖,才有鎖可以釋放。
同樣的道理,調用這一對方法的對象上的鎖必須為當前線程所擁有,這樣才有鎖可以釋放。因此,這一對方法調用必須放置在這樣的 synchronized 方法或塊中,該方法或塊的上鎖對象就是調用這一對方法的對象。若不滿足這一條件,則程序雖然仍能編譯,但在運行時會出現IllegalMonitorStateException 異常。
wait() 和 notify() 方法的上述特性決定了它們經常和synchronized 方法或塊一起使用,將它們和操作系統的進程間通信機制作一個比較就會發現它們的相似性:synchronized方法或塊提供了類似于操作系統原語的功能,它們的執行不會受到多線程機制的干擾,而這一對方法則相當于 block 和wakeup 原語(這一對方法均聲明為 synchronized)。
它們的結合使得我們可以實現操作系統上一系列精妙的進程間通信的算法(如信號量算法),并用于解決各種復雜的線程間通信問題。關于 wait() 和 notify() 方法最后再說明兩點:
第一:調用 notify() 方法導致解除阻塞的線程是從因調用該對象的 wait() 方法而阻塞的線程中隨機選取的,我們無法預料哪一個線程將會被選擇,所以編程時要特別小心,避免因這種不確定性而產生問題。
第二:除了 notify(),還有一個方法 notifyAll() 也可起到類似作用,唯一的區別在于,調用 notifyAll() 方法將把因調用該對象的 wait() 方法而阻塞的所有線程一次性全部解除阻塞。當然,只有獲得鎖的那一個線程才能進入可執行狀態。
談到阻塞,就不能不談一談死鎖,略一分析就能發現,suspend() 方法和不指定超時期限的 wait() 方法的調用都可能產生死鎖。遺憾的是,Java 并不在語言級別上支持死鎖的避免,我們在編程中必須小心地避免死鎖。
以上我們對 Java 中實現線程阻塞的各種方法作了一番分析,我們重點分析了 wait() 和 notify()方法,因為它們的功能最強大,使用也最靈活,但是這也導致了它們的效率較低,較容易出錯。實際使用中我們應該靈活使用各種方法,以便更好地達到我們的目的。
七、守護線程
守護線程是一類特殊的線程,它和普通線程的區別在于它并不是應用程序的核心部分,當一個應用程序的所有非守護線程終止運行時,即使仍然有守護線程在運行,應用程序也將終止,反之,只要有一個非守護線程在運行,應用程序就不會終止。守護線程一般被用于在后臺為其它線程提供服務。
可以通過調用方法 isDaemon() 來判斷一個線程是否是守護線程,也可以調用方法 setDaemon() 來將一個線程設為守護線程。
八、線程組
線程組是一個 Java 特有的概念,在 Java 中,線程組是類ThreadGroup 的對象,每個線程都隸屬于唯一一個線程組,這個線程組在線程創建時指定并在線程的整個生命期內都不能更改。
你可以通過調用包含 ThreadGroup 類型參數的 Thread 類構造函數來指定線程屬的線程組,若沒有指定,則線程缺省地隸屬于名為 system 的系統線程組。
在 Java 中,除了預建的系統線程組外,所有線程組都必須顯式創建。在 Java 中,除系統線程組外的每個線程組又隸屬于另一個線程組,你可以在創建線程組時指定其所隸屬的線程組,若沒有指定,則缺省地隸屬于系統線程組。這樣,所有線程組組成了一棵以系統線程組為根的樹。
Java 允許我們對一個線程組中的所有線程同時進行操作,比如我們可以通過調用線程組的相應方法來設置其中所有線程的優先級,也可以啟動或阻塞其中的所有線程。
Java 的線程組機制的另一個重要作用是線程安全。線程組機制允許我們通過分組來區分有不同安全特性的線程,對不同組的線程進行不同的處理,還可以通過線程組的分層結構來支持不對等安全措施的采用。
Java 的 ThreadGroup 類提供了大量的方法來方便我們對線程組樹中的每一個線程組以及線程組中的每一個線程進行操作。
九、總結
在本文中,我們講述了 Java 多線程編程的方方面面,包括創建線程,以及對多個線程進行調度、管理。我們深刻認識到了多線程編程的復雜性,以及線程切換開銷帶來的多線程程序的低效性,這也促使我們認真地思考一個問題:我們是否需要多線程?何時需要多線程?
多線程的核心在于多個代碼塊并發執行,本質特點在于各代碼塊之間的代碼是亂序執行的。我們的程序是否需要多線程,就是要看這是否也是它的內在特點。
假如我們的程序根本不要求多個代碼塊并發執行,那自然不需要使用多線程;假如我們的程序雖然要求多個代碼塊并發執行,但是卻不要求亂序,則我們完全可以用一個循環來簡單高效地實現,也不需要使用多線程;只有當它完全符合多線程的特點時,多線程機制對線程間通信和線程管理的強大支持才能有用武之地,這時使用多線程才是值得的。
一、繼承可以打破父類原有的封裝
class Body
{ String name;
public Body(String name)
{this.name=name;}
}
class ChildBody extends Body
{
private int age;
}
public class Test
{ public static void main(String[] args)
{
Body Tom=new ChildBody();
}
}
看看這段代碼,有沒有問題呢?能不能通過編譯呢?
父類,沒有錯誤。子類繼承了父類,并添加了私有成員變量age
看似沒有錯誤。
編譯錯誤,沒有找到0參數的構造函數Body()
這是為什么呢? 咱們沒有調用Body()呀
只是直接調用的ChildBody()構造函數,而這個應該是由編譯器提供的呀?
為什么這次它沒有提供呢?傻了嗎?
可是
究竟為什么呢?困惑中
其實 ,事實不像看到的那樣
1 類如果沒構造方法,編譯器會嘗試給創建一個默認的
2 但是子類構造方法要用父類的構造方法來初始化其父類的東西
3 這時候,編譯器就疑惑了,不能幫你合成了
需要你顯示的來寫構造方法
所以看出一個問題:
繼承雖然提高代碼復用,但是子類的編寫者需要了解父類的設計細節,因此,繼承某種程度上
打破了封裝
我們對子類做一下修改,
class ChildBody extends Body
{
private int age;
public ChildBody(String name){
super(name);
}
}
而現在就應該可以通過編譯了
我的分析是
我們用了super()句子,就是調用了父類的構造方法
而父類的此構造方法,則要調用它自己的父類無參構造函數
大家知道類Body 隱式的繼承于Object
也就是說,調用了Object的無參構造函數
自然是可以成功編譯了
2009年6月7日
#
摘要: 美國信息交換標準代碼
American Standard Code for Information Interchange, ASCII )
在計算機中,所有的數據在存儲和運算時都要使用二進制數表示(因為計算機用高電平和低電平分別表示1和0),例如,象a、b、c、d這樣的52個字母(...
閱讀全文
最近開始學習java語言,大家推薦初學者最好不要用eclipse,因為eclipse太過于集成會,很多代碼能過自動生成,對初學者來說就不太適合,那么給大家推薦一下EditPlus這個文本編輯器,剛開始安裝好后,對于EditPlsu的java配置里面的參數設置看似簡單,但是又是有容易忘記,我就犯過類似的錯誤,所以整理了一下java的配置,希望大家參考。
準備工作:1:安裝jdk,我的是jdk6.0的,我直接裝在的了C盤根目錄。2:設置系統變量,我的電腦>屬性>高級>環境變量>系統變量>path值在最后添加
;C:\jdk6.0\bin(注意要有c前面的分號)。
Editplus的java環境的所有配置見圖:
首先打開EditPlus,依次點擊“工具(Tools)”; “配置用戶工具...”進入用戶工具設置,選擇“組和工具條目”中的“Group 1”,點擊面板右邊的“組名稱...”按鈕,將文本Group1”修改成“Java工具”,點擊“添加工具”按鈕,選擇應用程序,
然后就是修改屬性:
配置編輯環境:
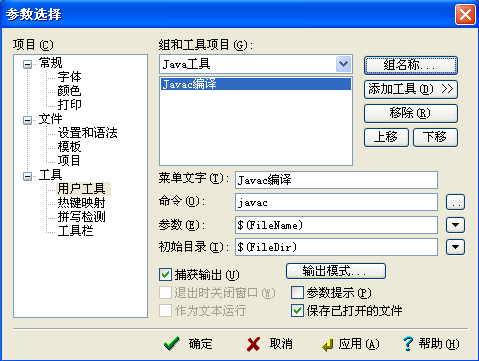
配置運行環境:
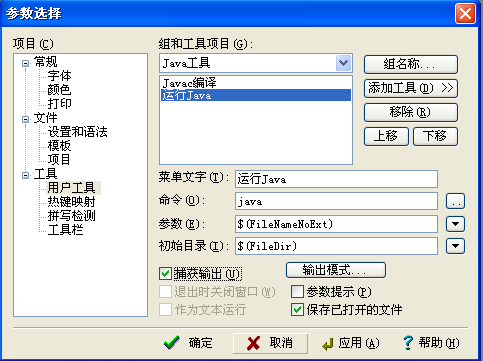
配置.jar文件運行環境(可以不用配置):
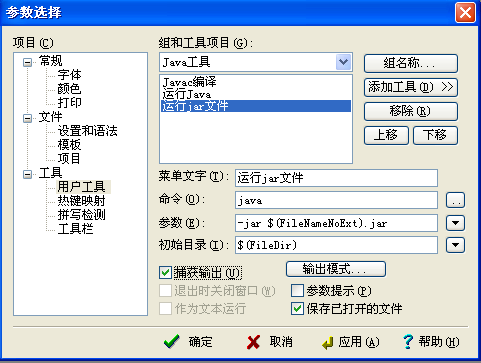
完畢!
JAVA環境配置大全
我剛學習java的時候也被各種環境配置搞得頭暈腦脹,現在把自己平時用到的整理一下,希望給大家一些幫助。比較簡單,希望大家能看懂。(最好按照我的順序裝,如果大家覺得網上看費事,我把文檔傳到網上供大家下載^_^)
安裝JDK
從java.sun.com/">;http://java.sun.com/下載jdk-1_5_0_04-windows-i586-p.exe
安裝到指定路徑,我選擇D:jdk1.5.0
配置環境變量:
JAVA_HOME: D:jdk1.5.0
PATH: D:jdk1.5.0\bin;
CLASSPATH: .;D:jdk1.5.0lib ools.jar;D:jdk1.5.0jrelib t.jar;
安裝WTK
從java.sun.com/">;http://java.sun.com/下載j2me_wireless_toolkit-2_2-windows.exe
安裝到指定路徑,我選擇D:WTK22
安裝Eclipse
從http://www.eclipse.org/下載eclipse-SDK-3.0.1-win32.zip和
NLpack-eclipse-SDK-3.0.x-win32.zip(語言包)
解壓縮eclipse-SDK-3.0.1-win32.zip即可,我的路徑:D:MyDevelopToolseclipse
解壓縮NLpack-eclipse-SDK-3.0.x-win32.zip,得到features和plugins兩個文件夾,把里面的文件分別拷入eclipse中相應的目錄下即可
安裝Tomcat
從http://jakarta.apache.org/下載jakarta-tomcat-5.5.9.zip
解壓縮jakarta-tomcat-5.5.9.zip即可
配置環境變量:
Tomcat_Home: D:MyDevelopTools omcat-5.5.9
PATH: D:MyDevelopTools omcat-5.5.9;
在eclipse中配置J2ME開發環境:
安裝eclipseme:
從http://www.eclipseme.org/下載eclipseme.feature_0.9.4_site.zip
在eclipse中選擇幫助-〉軟件更新-〉查找并安裝-〉搜索要安裝的新功能部件-〉新建已歸檔的站點
選擇eclipseme.feature_0.9.4_site.zip,打開-〉選擇eclipseme.feature_0.9.4_site.zip,剩下的一直下一步就可以了。安裝完成會在窗口-〉首選項中出現J2ME
修改JAVA-〉調試:
選中JAVA-〉調試,把暫掛執行的前兩項點去,通信中的調試器超時改為15000
配置WTK
窗口-〉首選項-〉J2ME-〉Platform Components
右鍵單擊對話框右側的Wireless Toolkit,選擇Add Wireless Toolkit,
選擇WTK安裝目錄,eclipse會自動匹配。
在eclipse中配置J2EE開發環境(Tomcat5.5.9):
安裝EMF-RunTime:
從http://www.eclipseme.org/下載emf-sdo-runtime-2.0.1.zip
解壓縮emf-sdo-runtime-2.0.1.zip,得到features和plugins兩個文件夾,把里面的文件分別拷入eclipse中相應的目錄下即可。
安裝Lomboz:
從http://forge.objectweb.org下載org.objectweb.lomboz_3.0.1.N20050106.zip解壓縮org.objectweb.lomboz_3.0.1.N20050106.zip,得到features和plugins兩個文件夾,把里面的文件分別拷入eclipse中相應的目錄下。如果在窗口-〉首選項中有Lomboz選項就安裝正確,如果沒有,在D:eclipseconfiguration下刪除org.eclipse.update這個文件夾,再重起eclipse就可以了。
配置Lomboz:
在D:eclipsepluginscom.objectlearn.jdt.j2ee_3.0.1servers下新建一個文件tomcat559.server,里面的內容從tomcat50x.server全部復制過來,把name="Apache Tomcat v5.0.x"替換成name="Apache Tomcat v5.5.9",然后把所有的
“${serverRootDirectory}/bin;${serverRootDirectory}/common/endorsed”替換成
“${serverRootDirectory}/common/endorsed”就可以了。然后進入eclipse,窗口-〉首選項-〉Lomboz,把JDK Tools.jar改為:D:jdk1.5.0lib ools.jar,窗口-〉首選項-〉Lomboz-〉Server Definitions,在Server types中選擇Tomcat5.5.9在Application Server Directory和Classpath Variable的路徑改為D:/MyDevelopTools/tomcat-5.5.9先應用,再確定就可以了。
2009年5月3日
#
JAVA中靜態數組與動態數組
前面我們學習的數組都是靜態數組,其實在很多的時候,靜態數組根本不能滿足我們編程的實際需要,比方說我需要在程序運行過程中動態的向數組中添加數據,這時我們的靜態數組大小是固定的,顯然就不能添加數據,要動態添加數據必須要用到動態數組,動態數組中的各個元素類型也是一致的,不過這種類型已經是用一個非常大的類型來攬括—Object類型。
Object類是JAVA.LANG包中的頂層超類。所有的類型都可以與Object類型兼容,所以我們可以將任何Object類型添加至屬于Object類型的數組中,能添加Object類型的的集合有ArrayList、Vector及LinkedList,它們對數據的存放形式仿造于數組,屬于集合類,下面是他們的特點:
特點一、容量擴充性
從內部實現機制來講ArrayList和Vector都是使用Objec的數組形式來存儲的。當你向這兩種類型中增加元素的時候,如果元素的數目超出了內部數組目前的長度它們都需要擴展內部數組的長度,Vector缺省情況下自動增長原來一倍的數組長度,ArrayList是原來的50%,所以最后你獲得的這個集合所占的空間總是比你實際需要的要大。所以如果你要在集合中保存大量的數據那么使用Vector有一些優勢,因為你可以通過設置集合的初始化大小來避免不必要的資源開銷。
特點二、同步性
ArrayList,LinkedList是不同步的,而Vestor是的。所以如果要求線程安全的話,可以使用ArrayList或LinkedList,可以節省為同步而耗費開銷。但在多線程的情況下,有時候就不得不使用Vector了。當然,也可以通過一些辦法包裝ArrayList,LinkedList,使他們也達到同步,但效率可能會有所降低。
特點三、數據操作效率
ArrayList和Vector中,從指定的位置(用index)檢索一個對象,或在集合的末尾插入、刪除一個對象的時間是一樣的,可表示為O(1)。但是,如果在集合的其他位置增加或移除元素那么花費的時間會呈線形增長:O(n-i),其中n代表集合中元素的個數,i代表元素增加或移除元素的索引位置。為什么會這樣呢?以為在進行上述操作的時候集合中第i和第i個元素之后的所有元素都要執行(n-i)個對象的位移操作。
LinkedList中,在插入、刪除集合中任何位置的元素所花費的時間都是一樣的—O(1),但它在索引一個元素的時候比較慢,為O(i),其中i是索引的位置。
所以,如果只是查找特定位置的元素或只在集合的末端增加、移除元素,那么使用Vector或ArrayList都可以。如果是對其它指定位置的插入、刪除操作,最好選擇LinkedList
ArrayList 和Vector是采用數組方式存儲數據,此數組元素數大于實際存儲的數據以便增加和插入元素,都允許直接序號索引元素,但是插入數據要設計到數組元素移動等內存操作,所以索引數據快插入數據慢,Vector由于使用了synchronized方法(線程安全)所以性能上比ArrayList要差,LinkedList使用雙向鏈表實現存儲,按序號索引數據需要進行向前或向后遍歷,但是插入數據時只需要記錄本項的前后項即可,所以插入數度較快。