本文為原創(chuàng),如需轉(zhuǎn)載,請(qǐng)注明作者和出處,謝謝!
上一篇:SQL Server2005雜談(4):在SQL Server2005中按列連接字符串的三種方法
在輸出統(tǒng)計(jì)結(jié)果時(shí)可能需要將列變成行,而將聚合結(jié)果(如count、sum)作為記錄的第一行,先看如下的SQL語句:
declare @t table(name varchar(20))
insert @t
select 'abc' union all
select 'xxx' union all
select 'xxx' union all
select 'ttt'
select * from @t
在執(zhí)行上面的SQL語句后,會(huì)輸出如圖1所示的記錄集。
圖1
上圖顯示的是一個(gè)普通的記錄集,如果要統(tǒng)計(jì)name字段的每個(gè)值的重復(fù)數(shù),需要進(jìn)行分組,如下面的SQL如示:
select count(name) as c ,name from @t group by name
執(zhí)行上面的SQL語句后的查詢結(jié)果如圖2所示。
圖2
如果我們有一個(gè)需求,需要如圖3所示的聚合結(jié)果。
圖3
從圖3可以看出,查詢結(jié)果正好是圖2的結(jié)果逆時(shí)針旋轉(zhuǎn)90度,也就是說,name列的值變成了列名,而c列的值變成了第一行的記錄。圖2所示的c和name字段消失了。
當(dāng)然,要達(dá)到這個(gè)結(jié)果并不困難,看如下的SQL語句:
select (select count(name) from @t where name='abc') as abc,
(select count(name) from @t where name='ttt') as xxx,
(select count(name) from @t where name='xxx') as ttt
上
面的SQL語句會(huì)出輸出如圖3的查詢結(jié)果。但這里有個(gè)問題,上面的SQL語句是枚舉了name列所有可能的值,在本例中只有三個(gè)值
('abc','ttt','xxx'),這非常好枚舉,但如果有很多值,SQL語句會(huì)變得非常長,非常不利于編寫。當(dāng)然,可以通過編程的方式自動(dòng)生成,
但最終結(jié)果仍然會(huì)生成很長的SQL語句。
為了解決這個(gè)問題,在SQL Server2005中提供了一個(gè)pivot函數(shù),該函數(shù)可以很容易地輸出如圖3所示的記錄集,如下面的SQL語句所示:
select * from @t pivot(count(name) for name in([abc] ,[ttt],[xxx]))
在執(zhí)行上面的SQL語句同樣可以獲得圖3所示的查詢結(jié)果。實(shí)際上,pivot函數(shù)也起到了分組的作用。在使用pivot函數(shù)時(shí)應(yīng)注意如下幾點(diǎn):
1. pivot函數(shù)需要指定聚合函數(shù),如count、sum等,for關(guān)鍵字和聚合函數(shù)都要使用需要聚合的字段名,在本例中是name。
2. in關(guān)鍵字負(fù)責(zé)指定每組需要聚合的值,用[...]將這些值括起來。實(shí)際上,這些值也相當(dāng)于我們第一種聚合方法中的where條件,例如,where name='abc'、where name='ttt',當(dāng)然,這些值也是輸出記錄集的列名。
3. 在最后要為pivot函數(shù)起一個(gè)別名。
雖然當(dāng)要聚合的值很多時(shí)(或不確定),也需要?jiǎng)討B(tài)生成SQL語句,但使用pivot函數(shù)的SQL語句卻短很多。
如
果我們還有一個(gè)需求,要將圖3的結(jié)果變成圖2的結(jié)果,也就是順時(shí)針旋轉(zhuǎn)90度,仍然以c和name作為字段名。也許方法很多,但SQL
Server2005提供了一個(gè)unpivot函數(shù),該函數(shù)是pivot函數(shù)的逆過程。也就是將記錄集順時(shí)針旋轉(zhuǎn)90度,先看下面的SQL語句:
declare @t table(name varchar(20))
insert @t
select 'abc' union all
select 'xxx' union all
select 'xxx' union all
select 'ttt'
;
with tt as(
select * from @t pivot(count(name) for name in([abc] ,[ttt],[xxx])) p)
select * from tt
上面的SQL語句將輸出如圖3所示的結(jié)果。如果將最后一條SQL語句(select * from tt)換成如下的SQL語句,將輸出如圖2所示的結(jié)果。
select * from tt unpivot([c] for name in([abc] ,[xxx],[ttt])) p
要注意的是,[c]中的c表示聚合結(jié)果列的字段名,name表示要聚合列的字段名,這兩個(gè)值可以是任意滿足字段名命名規(guī)則的字符串, [abc] ,[xxx],[ttt]分別是圖3所示的記錄集的字段名,這些值必須一致。執(zhí)行下面的SQL語句將獲得圖4的輸出結(jié)果。
select * from tt unpivot([統(tǒng)計(jì)值] for 統(tǒng)計(jì)名 in([abc] ,[xxx],[ttt])) p
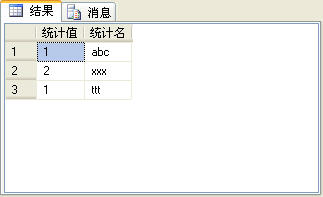
圖4
新浪微博:http://t.sina.com.cn/androidguy 昵稱:李寧_Lining