http://code.google.com/p/nutla/
1、概述
不管程序性能有多高,機(jī)器處理能力有多強(qiáng),都會(huì)有其極限。能夠快速方便的橫向與縱向擴(kuò)展是Nut設(shè)計(jì)最重要的原則,以此原則形成以分布式并行計(jì)算為核心的架構(gòu)設(shè)計(jì)。以分布式并行計(jì)算為核心的架構(gòu)設(shè)計(jì)是Nut區(qū)別于Solr、Katta的地方。
Nut是一個(gè)Lucene+Hadoop分布式并行計(jì)算搜索框架,能對(duì)千G以上索引提供7*24小時(shí)搜索服務(wù)。在服務(wù)器資源足夠的情況下能達(dá)到每秒處理100萬(wàn)次的搜索請(qǐng)求。
Nut開(kāi)發(fā)環(huán)境:jdk1.6.0.23+lucene3.0.3+eclipse3.6.1+hadoop0.20.2+zookeeper3.3.2+hbase0.20.6+memcached+mongodb+linux
2、特新
a、熱插拔
b、可擴(kuò)展
c、高負(fù)載
d、易使用,與現(xiàn)有項(xiàng)目無(wú)縫集成
e、支持排序
f、7*24服務(wù)
g、失敗轉(zhuǎn)移
3、搜索流程
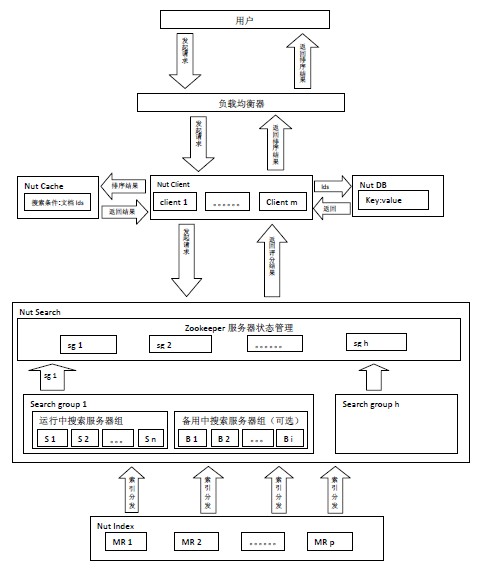
Nut由Index、Search、Client、Cache和DB五部分構(gòu)成。(Cache實(shí)現(xiàn)了對(duì)memcached的支持,DB實(shí)現(xiàn)了對(duì)hbase,mongodb的支持)
Client處理用戶請(qǐng)求和對(duì)搜索結(jié)果排序。Search對(duì)請(qǐng)求進(jìn)行搜索,Search上只放索引,數(shù)據(jù)存儲(chǔ)在DB中,Nut將索引和存儲(chǔ)分離。Cache緩存的是搜索條件和結(jié)果文檔id。DB存儲(chǔ)著數(shù)據(jù),Client根據(jù)搜索排序結(jié)果,取出當(dāng)前頁(yè)中的文檔id從DB上讀取數(shù)據(jù)。
用戶發(fā)起搜索請(qǐng)求給由Nut Client構(gòu)成的集群,由某個(gè)Nut Client根據(jù)搜索條件查詢Cache服務(wù)器是否有該緩存,如果有緩存根據(jù)緩存的文檔id直接從DB讀取數(shù)據(jù),如果沒(méi)有緩存將隨機(jī)選擇一組搜索服務(wù)器組(Search Group i),將查詢條件同時(shí)發(fā)給該組搜索服務(wù)器組里的n臺(tái)搜索服務(wù)器,搜索服務(wù)器將搜索結(jié)果返回給Nut Client由其排序,取出當(dāng)前頁(yè)文檔id,將搜索條件和當(dāng)前文檔id緩存,同時(shí)從DB讀取數(shù)據(jù)。
4、索引流程
Hadoop Mapper/Reducer 建立索引。再將索引從HDFS分發(fā)到各個(gè)索引服務(wù)器。
對(duì)索引的更新分為兩種:刪除和添加(更新分解為刪除和添加)。
a、刪除
在HDFS上刪除索引,將生成的*.del文件分發(fā)到所有的索引服務(wù)器上去或者對(duì)HDFS索引目錄刪除索引再分發(fā)到對(duì)應(yīng)的索引服務(wù)器上去。
b、添加
新添加的數(shù)據(jù)用另一臺(tái)服務(wù)器來(lái)生成。
刪除和添加步驟可按不同定時(shí)策略來(lái)實(shí)現(xiàn)。
5、Nut分布式并行計(jì)算特點(diǎn)
Nut分布式并行計(jì)算雖然也是基于M/R模型,但是與Hadoop M/R模型是不同的。在Hadoop M/R模型中 Mapper和Reducer是一個(gè)完整的流程,Reducer依賴于Mapper。數(shù)據(jù)源通過(guò)Mapper分發(fā)本身就會(huì)消耗大量的I/O,并且是消耗I/O最大的部分。所以Hadoop M/R 并發(fā)是有限的。
Nut M/R模型是將Mapper和Reducer分離,各自獨(dú)立存在。在Nut中 索引以及索引管理 構(gòu)成M,搜索以及搜索服務(wù)器組 構(gòu)成 R。
以一個(gè)分類統(tǒng)計(jì)來(lái)說(shuō)明Nut分布式并行計(jì)算的流程。假設(shè)有10個(gè)分類,對(duì)任意關(guān)鍵詞搜索要求統(tǒng)計(jì)出該關(guān)鍵詞在這10個(gè)分類中的總數(shù)。同時(shí)假設(shè)有10組搜索服務(wù)器。索引以及索引管理進(jìn)行索引數(shù)據(jù)的Mapper,這塊是后臺(tái)獨(dú)自運(yùn)行管理的。Nut Client將這10個(gè)分類統(tǒng)計(jì)分發(fā)到10組搜索服務(wù)器上,每組搜索服務(wù)器對(duì)其中一個(gè)分類進(jìn)行Reducer,并且每組搜索服務(wù)器可進(jìn)行多級(jí)Reducer。最后將最終結(jié)果返回給Nut Client。
6、設(shè)計(jì)圖
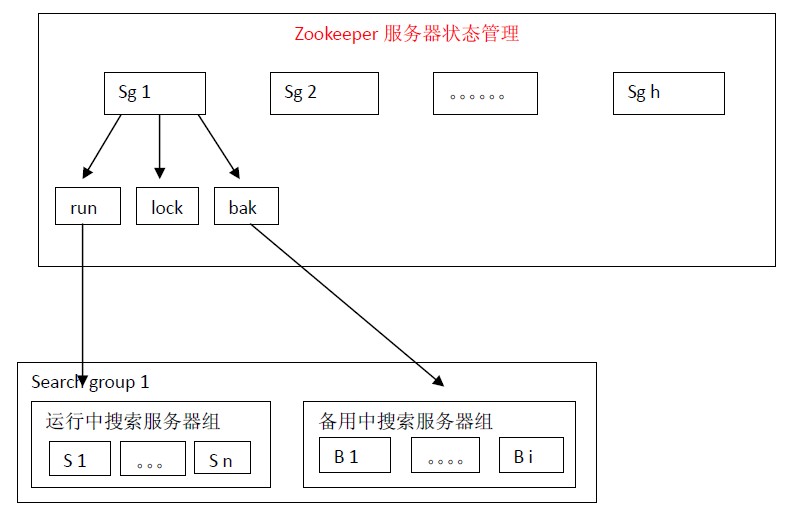
7、Zookeeper服務(wù)器狀態(tài)管理策略
在架構(gòu)設(shè)計(jì)上通過(guò)使用多組搜索服務(wù)器可以支持每秒處理100萬(wàn)個(gè)搜索請(qǐng)求。
每組搜索服務(wù)器能處理的搜索請(qǐng)求數(shù)在1萬(wàn)—1萬(wàn)5千之間。如果使用100組搜索服務(wù)器,理論上每秒可處理100萬(wàn)個(gè)搜索請(qǐng)求。
假如每組搜索服務(wù)器有100份索引放在100臺(tái)正在運(yùn)行中搜索服務(wù)器(run)上,那么將索引按照如下的方式放在備用中搜索服務(wù)器(bak)上:index 1,index 2,index 3,index 4,index 5,index 6,index 7,index 8,index 9,index 10放在B 1 上,index 6,index 7,index 8,index 9,index 10,index 11,index 12,index 13,index 14,index 15放在B 2上。。。。。。index 96,index 97,index 98,index 99,index 100,index 5,index 4,index 3,index 2,index 1放在最后一臺(tái)備用搜索服務(wù)器上。那么每份索引會(huì)存在3臺(tái)機(jī)器中(1份正在運(yùn)行中,2份備份中)。
盡管這樣設(shè)計(jì)每份索引會(huì)存在3臺(tái)機(jī)器中,仍然不是絕對(duì)安全的。假如運(yùn)行中的index 1,index 2,index 3同時(shí)宕機(jī)的話,那么就會(huì)有一份索引搜索服務(wù)無(wú)法正確啟用。這樣設(shè)計(jì),作者認(rèn)為是在安全性和機(jī)器資源兩者之間一個(gè)比較適合的方案。
備用中的搜索服務(wù)器會(huì)定時(shí)檢查運(yùn)行中搜索服務(wù)器的狀態(tài)。一旦發(fā)現(xiàn)與自己索引對(duì)應(yīng)的服務(wù)器宕機(jī)就會(huì)向lock申請(qǐng)分布式鎖,得到分布式鎖的服務(wù)器就將自己加入到運(yùn)行中搜索服務(wù)器組,同時(shí)從備用搜索服務(wù)器組中刪除自己,并停止運(yùn)行中搜索服務(wù)器檢查服務(wù)。
為能夠更快速的得到搜索結(jié)果,設(shè)計(jì)上將搜索服務(wù)器分優(yōu)先等級(jí)。通常是將最新的數(shù)據(jù)放在一臺(tái)或幾臺(tái)內(nèi)存搜索服務(wù)器上。通常情況下前幾頁(yè)數(shù)據(jù)能在這幾臺(tái)搜索服務(wù)器里搜索到。如果在這幾臺(tái)搜索服務(wù)器上沒(méi)有數(shù)據(jù)時(shí)再向其他舊數(shù)據(jù)搜索服務(wù)器上搜索。
優(yōu)先搜索等級(jí)的邏輯是這樣的:9最大為搜索全部服務(wù)器并且9不能作為level標(biāo)識(shí)。當(dāng)搜索等級(jí)level為1,搜索優(yōu)先級(jí)為1的服務(wù)器,當(dāng)level為2時(shí)搜索優(yōu)先級(jí)為1和2的服務(wù)器,依此類推。