
2011年2月17日
摘要: Reactor 模式的 JAVA NIO 多線程服務器,這是比較完善的一版了。Java 的 NIO 網絡模型實在是不好用,還是使用現成的好。Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->public class NIOServer...
閱讀全文
posted @
2013-05-14 16:31 nianzai 閱讀(2727) |
評論 (1) |
編輯 收藏 我學東西通常是通過動手的方式來學習,比如最近學習分布式服務協議paxos,自己就動手開發了一個該協議的實現版本。如果不動手實現只是靠學習理論是很難理解這個理論的本身。理解它最好的方式就是實踐它。
根據理論或者原理就來做實現確實很難,這需要很強的代碼功底、極高的理解能力以及持久的耐心。
扎實的功底是一切的開始,沒有扎實的功底就無法下手。沒有很好的悟性就很難保證事情的正確性。沒有良好的耐心就很難保證事情的結果。一次性就能將事情做成做好的,這種人實在太少了。做成一件事情就是在無數的失敗、錯誤中來接近成功,通過失敗來糾正、從而一步一步的接近成功。這就注定了需要持久的耐心才能保證成功。
posted @
2013-04-27 10:13 nianzai 閱讀(1975) |
評論 (0) |
編輯 收藏
1、提出者向leader發出詢問消息
2、leader向所有的QuorumPeer發出投票請求
3、QuorumPeer對該請求進行投票,如果消息的txid大于QuorumPeer的txid則通過該投票,否則反對該投票
4、leader根據所有的QuorumPeer投票結果進行計算,如果有一半以上的QuorumPeer通過則接受提出者的請求,否則拒絕提出者的請求
 switch (message.getType())
switch (message.getType())


 {
{
 case QuorumCode.ask://詢問類型
case QuorumCode.ask://詢問類型
//詢問該事務是否可操作
Ask task=new Ask(message,sc);
My.executor.execute(task);
m.setCode(JuiceCode.OK);
break;
case QuorumCode.vote://投票類型
if(My.txid>=message.getTxid())
//拒絕
m.setCode(JuiceCode.ERROR);
else

 {
{
//通過
m.setCode(JuiceCode.OK);
My.updateMyTxid(message.getTxid());
 }
}
break;
case QuorumCode.ping://ping
m.setCode(JuiceCode.OK);
m.setMyid(message.getMyid());
break;
 }
}
public static boolean sendAndVote(Message m) throws IOException
{
m.setType(QuorumCode.vote);
Map<Integer,Response> mp=new TreeMap<Integer,Response>();
for(Map.Entry<Integer,NIOClient> entry:voteClientMap.entrySet())
{
NIOClient client=entry.getValue();
Response response=client.send(ByteUtil.getBytes(m));
mp.put(entry.getKey(), response);
}
Map<Integer,Message> vote=new TreeMap<Integer,Message>();
for(Map.Entry<Integer,Response> entry:mp.entrySet())
vote.put(entry.getKey(), (Message)ByteUtil.getObject(entry.getValue().getData()));
int ok=0;
for(Map.Entry<Integer,Message> entry:vote.entrySet())
{
Message f=entry.getValue();
if(f.getCode()==JuiceCode.OK)
ok++;
}
if(ok/(vote.size()*1.0)>1/2.0)
return true;
return false;
}posted @
2013-04-23 13:19 nianzai 閱讀(1757) |
評論 (0) |
編輯 收藏1、收集第一輪投票結果
2、統計投票數,計算出投票數最大的id
3、如果投票數超過1/2則選該id為leader
4、如果最大投票數id沒有超過1/2,則推薦txid最大的id為leader
5、計算出最大的txid及其服務器id
6、計算出最大的txid有幾個
7、如果最大txid超過一個,則比較服務器id,推薦服務id最大的為leader
8、發起第二輪投票
Java實現代碼如下:
/** *//**
* 選舉leader
* @param vote 投票信息
* @return
*/
public int forLeader(Map<Integer,Notification> vote)
{
//統計leader投票數
TreeMap<Integer,Integer> tmap=new TreeMap<Integer,Integer>();
for(Map.Entry<Integer,Notification> entry:vote.entrySet())
{
Notification nf=entry.getValue();
if(tmap.containsKey(nf.leader))
tmap.put(nf.leader, tmap.get(nf.leader)+1);
else
tmap.put(nf.leader, 1);
}
//計算出投票數最大的id
int a=0;
int l=0;
for(Map.Entry<Integer,Integer> entry:tmap.entrySet())
{
if(entry.getValue()>a)
{
a=entry.getValue();
l=entry.getKey();
}
}
//如果投票數超過1/2則選該id為leader
if(a/(My.serverList.size()*1.0)>1/2.0)
{
//選出leader
if(l==My.myid)
My.myServerState=ServerState.LEADING;
else
My.myServerState=ServerState.FLLOWING;
My.leader=l;
return -1;
}
//如果最大投票數leader沒有超過1/2,則推薦txid最大的id為leader
//計算出最大的txid及其服務器id
long txid=0;
int leader=0;
for(Map.Entry<Integer,Notification> entry:vote.entrySet())
{
if(entry.getValue().txid>txid)
{
leader=entry.getKey();
txid=entry.getValue().txid;
}
}
//計算出最大的txid有幾個
Map<Integer,Notification> vte=new TreeMap<Integer,Notification>();
for(Map.Entry<Integer,Notification> entry:vote.entrySet())
{
if(entry.getValue().txid==txid)
{
vte.put(entry.getValue().id, entry.getValue());
}
}
//如果超過一個,則比較服務器id,推薦服務id最大的為leader
if(vte.size()>1)
{
for(Map.Entry<Integer,Notification> entry:vte.entrySet())
{
if(entry.getValue().id>leader)
leader=entry.getKey();
}
}
return leader;
}
}
posted @
2013-04-17 11:15 nianzai 閱讀(1880) |
評論 (0) |
編輯 收藏
原理:通過瀏覽器去訪問要抓取的Ajax、腳本網頁地址,通過讀取瀏覽器內存document來得到腳本執行以后的網頁內容
在原有的基礎上增加 自定義命令腳本 抓取功能。該功能能夠通過用戶自定義的腳本來實現與網頁的交互,比如填寫內容,點擊網頁上的提交按鈕。
這樣便能抓取需要提交的網頁內容了,特別是需要提交的ajax網頁。

Ajax、腳本網頁內容抓取工具(第二版)
點這下載
posted @
2012-09-29 14:26 nianzai 閱讀(1847) |
評論 (1) |
編輯 收藏
摘要: 本隱馬可夫(HMM)中文分詞詞性標注程序 中的 隱馬可夫(HMM)概率模型 是由 PFR人民日報標注語料199801語料庫 生成Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->public class HMM{ ...
閱讀全文
posted @
2012-09-14 17:08 nianzai 閱讀(3862) |
評論 (0) |
編輯 收藏
wikipedia上有個java版的Viterbi(維特比)實現程序(
http://en.wikipedia.org/wiki/Viterbi_algorithm),但是3個觀察序列會標注出4個狀態序列。
下面本人寫的這個Viterbi(維特比)實現程序就沒這個問題,3個觀察序列就只標注出3個狀態序列。
public class Viterbi
{
public static void main(String[] args)
{
String[] states = {"Rainy", "Sunny"};
String[] observations = {"walk", "shop", "clean"};
double[] start_probability = {0.6, 0.4};
double[][] transition_probability = {{0.7, 0.3}, {0.4, 0.6}};
double[][] emission_probability = {{0.1, 0.4, 0.5}, {0.6, 0.3, 0.1}};
forward_viterbi(observations,states,start_probability,transition_probability,emission_probability);
}
public static void forward_viterbi(String[] observations, String[] states,double[] start_probability, double[][] transition_probability, double[][] emission_probability)
{
int[][] path=new int[observations.length][states.length];
double[][] r=new double[observations.length][states.length];
for(int j=0;j<states.length;j++)
{
r[0][j]=start_probability[j]*emission_probability[j][0];
path[0][j]=0;
}
for(int t=1;t<observations.length;t++)
{
for(int i=0;i<states.length;i++)
{
double tmp=0;int m=0;
for(int j=0;j<states.length;j++)
{
double tem=r[t-1][j]*transition_probability[j][i]*emission_probability[i][t];
if(tem>tmp)
{
tmp=tem;
m=j;
}
}
r[t][i]=tmp;
path[t][i]=m;
}
}
double p=0;int m=0;
for(int i=0;i<r[0].length;i++)
{
if(r[r.length-1][i]>p)
{
p=r[r.length-1][i];
m=i;
}
}
System.out.println("p="+p);
int[] trace=new int[observations.length];
trace[observations.length-1]=m;
for(int t=observations.length-1;t>0;t--)
{
trace[t-1]=path[t][m];
m=path[t][m];
}
for(int i=0;i<trace.length;i++)
System.out.println(states[trace[i]]);
}
} 。
posted @
2012-09-07 16:43 nianzai 閱讀(1987) |
評論 (0) |
編輯 收藏
摘要: 最大概率分詞程序,在所有可能分詞路徑中選擇概率最大的一條路徑最為分詞結果Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->public class MPM extends M{ &...
閱讀全文
posted @
2012-08-31 10:12 nianzai 閱讀(2448) |
評論 (0) |
編輯 收藏
最短路徑分詞法
public class SPM2 extends M
{
public static final HashMap<Character,TreeNode> dic = Dictionary.loadFreqDictionary("sogou.txt");
/** *//**
* @return 返回可能匹配詞的長度, 沒有找到返回 0.
*/
public ArrayList<Integer> maxMatch(TreeNode node,char[] sen, int offset)
{
ArrayList<Integer> list=new ArrayList<Integer>();
for(int i=offset; i<sen.length; i++)
{
node = node.subNode(sen[i]);
if(node != null)
{
if(node.isAlsoLeaf())
list.add(i+1);
}
else
break;
}
return list;
}
@Override
public ArrayList<Token> getToken(ArrayList<Sentence> list)
{
ArrayList<Token> tokenlist=new ArrayList<Token>();
for(Sentence sen:list)
{
AdjList g = new AdjList(sen.getText().length+1);//存儲所有被切分的可能的詞
int i=0;
while(i<sen.getText().length)
{
Token token = new Token(new String(sen.getText(),i,1),i,i+1);
token.setWeight(1);
g.addEdge(token);
TreeNode n=dic.get(sen.getText()[i]);
if(n!=null)
{
ArrayList<Integer> ilist =maxMatch(n, sen.getText(),i);
if(ilist.size()>0)
for(int j=0;j<ilist.size();j++)
{
token = new Token(new String(sen.getText(),i,ilist.get(j)-i),i,ilist.get(j));
token.setWeight(1);
g.addEdge(token);
}
}
i++;
}
//System.out.println(g);
ArrayList<Integer> ret=maxProb(g);
Collections.reverse(ret);
int first=0;
for(Integer last:ret)
{
Token token = new Token(new String(sen.getText(),first,last-first),sen.getStartOffset()+first,sen.getStartOffset()+last);
tokenlist.add(token);
first=last;
}
}
return tokenlist;
}
int[] prevNode;
double[] prob;
//計算出路徑最短的數組
public ArrayList<Integer> maxProb(AdjList g)
{
prevNode = new int[g.verticesNum]; //最佳前驅節點
prob = new double[g.verticesNum]; //節點路徑
prob[0] = 0;//節點0的初始路徑是0
//按節點求最佳前驅
for (int index = 1; index < g.verticesNum; index++)
getBestPrev(g,index);//求出最佳前驅
ArrayList<Integer> ret = new ArrayList<Integer>();
for(int i=(g.verticesNum-1);i>0;i=prevNode[i]) // 從右向左找最佳前驅節點
ret.add(i);
return ret;
}
//計算節點i的最佳前驅節點
void getBestPrev(AdjList g,int i)
{
Iterator<Token> it = g.getPrev(i);//得到前驅詞集合,從中挑選最佳前趨詞
double maxProb = 1000;
int maxNode = -1;
while(it.hasNext())
{
Token itr = it.next();
double nodeProb = prob[itr.getStart()]+itr.getWeight();//候選節點路徑
//System.out.println(itr.getWord()+","+nodeProb);
if (nodeProb < maxProb)//路徑最短的算作最佳前趨
{
maxNode = itr.getStart();
maxProb = nodeProb;
}
}
prob[i] = maxProb;//節點路徑
prevNode[i] = maxNode;//最佳前驅節點
}
}
posted @
2012-08-24 14:57 nianzai 閱讀(1973) |
評論 (0) |
編輯 收藏
全切分分詞程序。中華人民共和國切分成 {中華人民共和國|中華|華人|人民|共和國}。
能實現中英文數字混合分詞。比如能分出這樣的詞:bb霜、3室、樂phone、touch4、mp3、T恤。
public class FMW extends M
{
public static final HashMap<Character,TreeNode> dic = Dictionary.getFmmdic();
/** *//**
* @return 返回可能匹配詞的長度, 沒有找到返回 0.
*/
public ArrayList<Integer> maxMatch(TreeNode node,char[] sen, int offset)
{
ArrayList<Integer> list=new ArrayList<Integer>();
for(int i=offset; i<sen.length; i++)
{
node = node.subNode(sen[i]);
if(node != null)
{
if(node.isAlsoLeaf())
list.add(i+1);
}
else
break;
}
if(list.size()==0)
list.add(offset);
return list;
}
public ArrayList<Token> getToken(ArrayList<Sentence> list)
{
ArrayList<Token> tokenlist=new ArrayList<Token>();
for(Sentence sen:list)
{
int i=0;
while(i<sen.getText().length)
{
TreeNode n=dic.get(sen.getText()[i]);
if(n!=null)
{
ArrayList<Integer> ilist =maxMatch(n, sen.getText(),i);
if(ilist.size()>1)
{
for(int j=0;j<ilist.size();j++)
{
Token token = new Token(new String(sen.getText(),i,ilist.get(j)-i),sen.getStartOffset()+i,sen.getStartOffset()+ilist.get(j));
tokenlist.add(token);
}
}
else
{
if(ilist.get(0)>i)
{
Token token = new Token(new String(sen.getText(),i,ilist.get(0)-i),sen.getStartOffset()+i,sen.getStartOffset()+ilist.get(0));
tokenlist.add(token);
}
else
{
if(tokenlist.size()==0 || tokenlist.get(tokenlist.size()-1).getEnd()<=i+sen.getStartOffset())
{
Token token = new Token(new String(sen.getText(),i,1),sen.getStartOffset()+i,sen.getStartOffset()+i+1);
tokenlist.add(token);
}
}
}
}
else
{
if(tokenlist.size()==0 || tokenlist.get(tokenlist.size()-1).getEnd()<=i+sen.getStartOffset())
{
Token token = new Token(new String(sen.getText(),i,1),sen.getStartOffset()+i,sen.getStartOffset()+i+1);
tokenlist.add(token);
}
}
i++;
}
}
return tokenlist;
}
}
posted @
2012-07-02 14:17 nianzai 閱讀(3078) |
評論 (4) |
編輯 收藏推翻了第一版,參考了其他分詞程序,重新寫的第二版。
逆向最大匹配中文分詞程序,能實現中英文數字混合分詞。比如能分出這樣的詞:bb霜、3室、樂phone、touch4、mp3、T恤
public class RMM2 extends M
{
public static final HashMap<Character,TreeNode> dic = Dictionary.getRmmdic();
/** *//**
* @return 返回匹配最長詞的長度, 沒有找到返回 0.
*/
public int maxMatch(TreeNode node,char[] sen, int offset)
{
int idx = offset;
for(int i=offset; i>=0; i--)
{
node = node.subNode(sen[i]);
if(node != null)
{
if(node.isAlsoLeaf())
idx = i;
}
else
break;
}
return idx ;
}
public ArrayList<Token> getToken(ArrayList<Sentence> list)
{
Collections.reverse(list);
ArrayList<Token> tokenlist=new ArrayList<Token>();
for(Sentence sen:list)
{
int i=sen.getText().length-1;
while(i>-1)
{
TreeNode n=dic.get(sen.getText()[i]);
if(n!=null)
{
int j=maxMatch(n, sen.getText(),i);
if(j<i)
{
Token token = new Token(new String(sen.getText(),j,i-j+1),sen.getStartOffset()+j,sen.getStartOffset()+i+1);
tokenlist.add(token);
i=j-1;
}
else
{
Token token = new Token(new String(sen.getText(),i,1),sen.getStartOffset()+i,sen.getStartOffset()+i+1);
tokenlist.add(token);
i--;
}
}
else
{
Token token = new Token(new String(sen.getText(),i,1),sen.getStartOffset()+i,sen.getStartOffset()+i+1);
tokenlist.add(token);
i--;
}
}
}
Collections.reverse(tokenlist);
return tokenlist;
}
}
posted @
2012-06-29 17:29 nianzai 閱讀(1371) |
評論 (0) |
編輯 收藏
推翻了第一版,參考了其他分詞程序,重新寫的第二版。
正向最大匹配中文分詞程序,能實現中英文數字混合分詞。比如能分出這樣的詞:bb霜、3室、樂phone、touch4、mp3、T恤
public class FMM2 extends Seg
{
public static final HashMap<Character,TreeNode> dic = Dictionary.getFmmdic();
/** *//**
* @return 返回匹配最長詞的長度, 沒有找到返回 0.
*/
public static int maxMatch(TreeNode node,char[] sen, int offset)
{
int idx = offset - 1;
for(int i=offset; i<sen.length; i++)
{
node = node.subNode(sen[i]);
if(node != null)
{
if(node.isAlsoLeaf())
idx = i;
}
else
break;
}
return idx + 1;
}
public ArrayList<Token> getToken(ArrayList<Sentence> list)
{
ArrayList<Token> tokenlist=new ArrayList<Token>();
for(Sentence sen:list)
{
int i=0;
while(i<sen.getText().length)
{
TreeNode n=FMM2.dic.get(sen.getText()[i]);
if(n!=null)
{
int j=FMM2.maxMatch(n, sen.getText(),i);
if(j>i)
{
Token token = new Token(new String(sen.getText(),i,j-i),sen.getStartOffset()+i,sen.getStartOffset()+j);
tokenlist.add(token);
i=j;
}
else
{
Token token = new Token(new String(sen.getText(),i,1),sen.getStartOffset()+i,sen.getStartOffset()+i+1);
tokenlist.add(token);
i++;
}
}
else
{
Token token = new Token(new String(sen.getText(),i,1),sen.getStartOffset()+i,sen.getStartOffset()+i+1);
tokenlist.add(token);
i++;
}
}
}
return tokenlist;
}
}
posted @
2012-06-27 13:39 nianzai 閱讀(1269) |
評論 (0) |
編輯 收藏
摘要: Reactor 模式的 JAVA NIO 多線程服務器
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->public class MiniServer extends Thread{ &nb...
閱讀全文
posted @
2011-08-29 18:35 nianzai 閱讀(3101) |
評論 (3) |
編輯 收藏
摘要: 基于詞典的逆向最大匹配中文分詞算法,能實現中英文數字混合分詞。比如能分出這樣的詞:bb霜、3室、樂phone、touch4、mp3、T恤。實際分詞效果比正向分詞效果好 查看第2版:逆向最大匹配分詞程序,能實現中英文數字混合分詞 (第二版)
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://w...
閱讀全文
posted @
2011-08-19 13:22 nianzai 閱讀(4487) |
評論 (2) |
編輯 收藏
摘要: 基于詞典的正向最大匹配中文分詞算法,能實現中英文數字混合分詞。比如能分出這樣的詞:bb霜、3室、樂phone、touch4、mp3、T恤第一次寫中文分詞程序,歡迎拍磚。查看第2版:正向最大匹配分詞程序,能實現中英文數字混合分詞 (第二版)
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.Code...
閱讀全文
posted @
2011-08-04 15:31 nianzai 閱讀(3461) |
評論 (1) |
編輯 收藏
原理:通過瀏覽器去訪問要抓取的Ajax、腳本網頁地址,通過讀取瀏覽器內存document來得到腳本執行以后的網頁內容
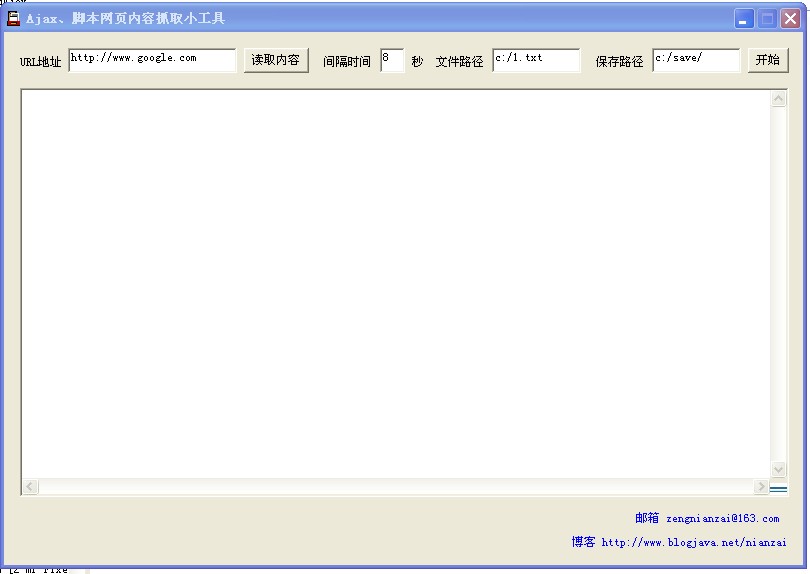
1、文件路徑為帶抓取網頁地址,格式如下:
1,http://www.google.com
2,http://www.baidu.com
......
......
2、保存路徑為抓取下來的網頁保存路徑
Ajax、腳本網頁內容抓取小工具
點這下載
posted @
2011-04-27 13:37 nianzai 閱讀(2170) |
評論 (1) |
編輯 收藏blog: http://www.tkk7.com/nianzai/
code: http://code.google.com/p/nutla/
一、安裝
1、 安裝虛擬機 Oracle VM VirtualBox4.0.4
2、 在虛擬機下安裝 Red Hat 6.0
3、 安裝jdk jdk-6u24-linux-i586.bin 安裝路徑為:/home/nianzai/jdk1.6.0_24
4、 安裝hadoop hadoop-0.20.2.tar.gz 安裝路徑為:/home/nianzai/hadoop-0.20.2
5、 安裝zookeeper zookeeper-3.3.3.tar.gz 安裝路徑為:/home/nianzai/zookeeper-3.3.3
6、 安裝hbase hbase-0.90.2.tar.gz 安裝路徑為:/home/nianzai/hbase-0.90.2
二、配置
1、Linux配置
ssh-keygen –t rsa -P ''
cd .ssh
cp id_rsa.pub authorized_keys
/etc/hosts里增加 192.168.195.128 master
/etc/profile 里增加
export JAVA_HOME=/home/nianzai/jdk1.6.0_24
export PATH=$PATH:$JAVA_HOME/bin
2、hadoop配置
hadoop-env.sh
JAVA_HOME=/home/nianzai/jdk1.6.0._24
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/nianzai/hadoop</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
masters
master
sh hadoop namenode -format
sh start-all.sh
sh hadoop fs -mkdir input
3、zookeeper配置
zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/nianzai/zkdata
clientPort=2181
sh zkServer.sh start
4、hbase配置
hbase-env.sh
export JAVA_HOME=/home/nianzai/jdk1.6.0_24
export HBASE_MANAGES_ZK=false
將hbase0.90.2 lib目錄下hadoop-core-0.20-append-r1056497.jar刪除,替換成hadoop0.20.2 下的hadoop-0.20.2-core.jar
hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master</value>
</property>
</configuration>
regionservers
master
sh start-hbase.sh
posted @
2011-04-19 11:32 nianzai 閱讀(4074) |
評論 (6) |
編輯 收藏http://code.google.com/p/nutla/
1、概述
不管程序性能有多高,機器處理能力有多強,都會有其極限。能夠快速方便的橫向與縱向擴展是Nut設計最重要的原則,以此原則形成以分布式并行計算為核心的架構設計。以分布式并行計算為核心的架構設計是Nut區別于Solr、Katta的地方。
Nut是一個Lucene+Hadoop分布式并行計算搜索框架,能對千G以上索引提供7*24小時搜索服務。在服務器資源足夠的情況下能達到每秒處理100萬次的搜索請求。
Nut開發環境:jdk1.6.0.23+lucene3.0.3+eclipse3.6.1+hadoop0.20.2+zookeeper3.3.2+hbase0.20.6+memcached+mongodb+linux
2、特新
a、熱插拔
b、可擴展
c、高負載
d、易使用,與現有項目無縫集成
e、支持排序
f、7*24服務
g、失敗轉移
3、搜索流程
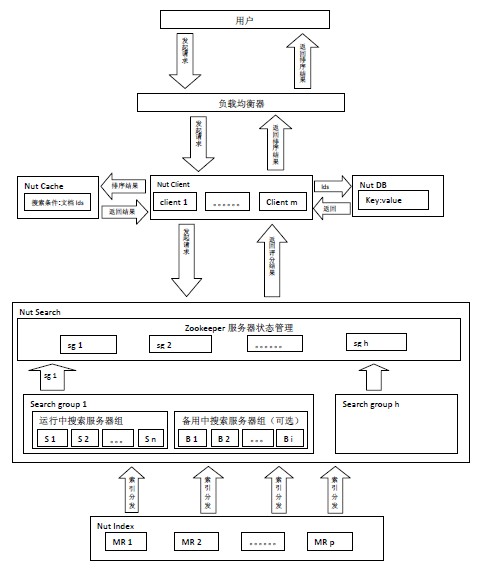
Nut由Index、Search、Client、Cache和DB五部分構成。(Cache實現了對memcached的支持,DB實現了對hbase,mongodb的支持)
Client處理用戶請求和對搜索結果排序。Search對請求進行搜索,Search上只放索引,數據存儲在DB中,Nut將索引和存儲分離。Cache緩存的是搜索條件和結果文檔id。DB存儲著數據,Client根據搜索排序結果,取出當前頁中的文檔id從DB上讀取數據。
用戶發起搜索請求給由Nut Client構成的集群,由某個Nut Client根據搜索條件查詢Cache服務器是否有該緩存,如果有緩存根據緩存的文檔id直接從DB讀取數據,如果沒有緩存將隨機選擇一組搜索服務器組(Search Group i),將查詢條件同時發給該組搜索服務器組里的n臺搜索服務器,搜索服務器將搜索結果返回給Nut Client由其排序,取出當前頁文檔id,將搜索條件和當前文檔id緩存,同時從DB讀取數據。
4、索引流程
Hadoop Mapper/Reducer 建立索引。再將索引從HDFS分發到各個索引服務器。
對索引的更新分為兩種:刪除和添加(更新分解為刪除和添加)。
a、刪除
在HDFS上刪除索引,將生成的*.del文件分發到所有的索引服務器上去或者對HDFS索引目錄刪除索引再分發到對應的索引服務器上去。
b、添加
新添加的數據用另一臺服務器來生成。
刪除和添加步驟可按不同定時策略來實現。
5、Nut分布式并行計算特點
Nut分布式并行計算雖然也是基于M/R模型,但是與Hadoop M/R模型是不同的。在Hadoop M/R模型中 Mapper和Reducer是一個完整的流程,Reducer依賴于Mapper。數據源通過Mapper分發本身就會消耗大量的I/O,并且是消耗I/O最大的部分。所以Hadoop M/R 并發是有限的。
Nut M/R模型是將Mapper和Reducer分離,各自獨立存在。在Nut中 索引以及索引管理 構成M,搜索以及搜索服務器組 構成 R。
以一個分類統計來說明Nut分布式并行計算的流程。假設有10個分類,對任意關鍵詞搜索要求統計出該關鍵詞在這10個分類中的總數。同時假設有10組搜索服務器。索引以及索引管理進行索引數據的Mapper,這塊是后臺獨自運行管理的。Nut Client將這10個分類統計分發到10組搜索服務器上,每組搜索服務器對其中一個分類進行Reducer,并且每組搜索服務器可進行多級Reducer。最后將最終結果返回給Nut Client。
6、設計圖
7、Zookeeper服務器狀態管理策略
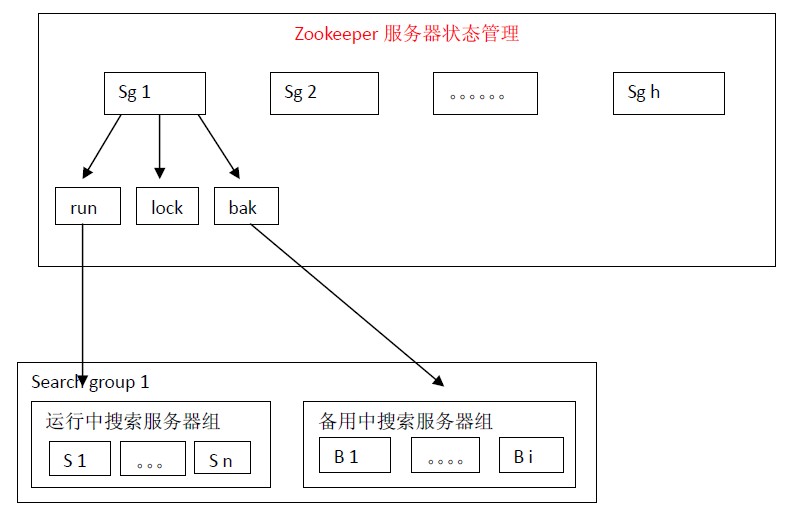
在架構設計上通過使用多組搜索服務器可以支持每秒處理100萬個搜索請求。
每組搜索服務器能處理的搜索請求數在1萬—1萬5千之間。如果使用100組搜索服務器,理論上每秒可處理100萬個搜索請求。
假如每組搜索服務器有100份索引放在100臺正在運行中搜索服務器(run)上,那么將索引按照如下的方式放在備用中搜索服務器(bak)上:index 1,index 2,index 3,index 4,index 5,index 6,index 7,index 8,index 9,index 10放在B 1 上,index 6,index 7,index 8,index 9,index 10,index 11,index 12,index 13,index 14,index 15放在B 2上。。。。。。index 96,index 97,index 98,index 99,index 100,index 5,index 4,index 3,index 2,index 1放在最后一臺備用搜索服務器上。那么每份索引會存在3臺機器中(1份正在運行中,2份備份中)。
盡管這樣設計每份索引會存在3臺機器中,仍然不是絕對安全的。假如運行中的index 1,index 2,index 3同時宕機的話,那么就會有一份索引搜索服務無法正確啟用。這樣設計,作者認為是在安全性和機器資源兩者之間一個比較適合的方案。
備用中的搜索服務器會定時檢查運行中搜索服務器的狀態。一旦發現與自己索引對應的服務器宕機就會向lock申請分布式鎖,得到分布式鎖的服務器就將自己加入到運行中搜索服務器組,同時從備用搜索服務器組中刪除自己,并停止運行中搜索服務器檢查服務。
為能夠更快速的得到搜索結果,設計上將搜索服務器分優先等級。通常是將最新的數據放在一臺或幾臺內存搜索服務器上。通常情況下前幾頁數據能在這幾臺搜索服務器里搜索到。如果在這幾臺搜索服務器上沒有數據時再向其他舊數據搜索服務器上搜索。
優先搜索等級的邏輯是這樣的:9最大為搜索全部服務器并且9不能作為level標識。當搜索等級level為1,搜索優先級為1的服務器,當level為2時搜索優先級為1和2的服務器,依此類推。
posted @
2011-02-17 13:20 nianzai 閱讀(5389) |
評論 (9) |
編輯 收藏