第六條 在改寫equals的時候請遵守通用規定
有一種“值類”可以不要求改寫equals方法,類型安全枚舉類型,因為類型安全枚舉類型保證每一個值之多只存在一個對象,所有對于這樣的類而言,Object的queals方法等同于邏輯意義上的equals方法。
在改寫equals方法的時候,要遵循的規范:
1,自反性。對任意的引用值x,x.equals(x)一定是true
2,對稱性。對于任意的引用值x和y,當且僅當y.equals(x)返回true時,x.equals(y)也一定返回true.
3,傳遞性。對于任意的引用值x,y和z,如果x.equals(y)==true and y.equals(z)==true,so x.equals(z)==true.
4,一致性。對于任意的引用值x和y,如果用于equals比較的對象信息沒有被修改的話,那么,多次調用x.equals(y)要么一致地返回true,要么一致地返回false.
5,非空性。對于任意的非空引用值x,x.equals(null)一定返回false.
自反性:要求一個對象必須等于其自身。一個例子:你把該類的實例加入到一個集合中,則該集合的contains方法
將果斷地告訴你,該集合不包含你剛剛加入的實例.
對稱性:
例如:
public final class CaseInsensitiveString{
private String s;
public CaseInsensitiveString(String s){
if(s==null) throw new NullPointerException();
this.s=s;
}
public boolean equals(Object o){
if(o instanceof CaseInsensitiveString)
return s.equalsIgnoreCase(((CaseInsensitiveString)o).s);
if(o instanceof String)
return s.equalsIgnoreCase((String)o);
return false;
}
}
調用:
CaseInsensitiveString cis=new CaseInsensitiveString("Polish");
String s="polish";
正如我們期望的:cis.equals(s)==true but s.equals(cis)==false
這就違反了對稱性的原則.為了解決這個問題,只需把企圖與String互操作的這段代碼從equals方法中去掉舊可以了.這樣做之后,你可以重構代碼,使他變成一條返回語句:
public boolean equals(Object o){
return o instanceof CaseInsensitiveString && ((CaseInsensitiveString)o).s.equalsIgnoreCase(s);
}
傳遞性---即如果一個對象等于第二個對象,并且第二個對象又等于第三個對象,則第一個對象一定等于第三個對象。
例如:
public class Point{
private final int x;
private final int y;
public Point(int x,int y){
this.x=x;
this.y=y;
}
public boolean equals(Object o){
if(!(o instanceof Point))
return false;
Point p=(Point)o;
return p.x==x&&p.y==y;
}
}
現在我們來擴展這個類,為一個點增加顏色信息:
public class ColorPoint extends Point{
private Color color;
public ColorPoint(int x,int y,Color color){
super(x,y);
this.color=color;
}
}
分析: equals方法會怎么樣呢?如果你完全不提供equals方法,而是直接從Point繼承過來,那么在equals座比較的時候顏色信息會被忽略掉。如果你編寫一個equals方法,只有當實參是另一個有色點,并且具有同樣的位置和顏色的時候,它才返回true:
public boolean equals(Object o){
if(!(o instanceof ColorPoint)) return false;
ColorPoint cp=(ColorPoint)o;
return super.equals(o) && cp.color==color;
}
分析:這個方法的問題在于,我們在比較一個普通點和一個有色點,以及反過來的情形的時候,可能會得到不同的結果。前一種比較忽略了顏色信息,而后一種比較總是返回false,因為實參的類型不正確。例如:
Point p=new Point(1,2);
ColorPoint cp=new ColorPoint(1,2,Color.RED);
然后:p.equals(cp)==true but cp.equals(p)==false
修正:讓ColorPoint.equals在進行“混合比較”的時候忽略顏色信息:
public boolean equals(Object o){
if(!(o instanceof Point)) return false;
if(!(o instanceof ColorPoint)) return o.equals(this);
ColorPoint cp=(ColorPoint)o;
return super.equals(o) && cp.color==color;
}
這種方法確實提供了對稱性,但是卻犧牲了傳遞性:
ColorPoint p1=new ColorPoint(1,2,Color.RED);
Point p2=new Point(1,2);
ColorPoint p3=new ColorPoint(1,2,Color.BLUE);
此時:p1.equals(p2)==true and p2.equals(p3)==true but p1.equals(p3)==false很顯然違反了傳遞性。前兩個比較不考慮顏色信息,而第三個比較考慮了顏色信息。
結論:要想在擴展一個可實例華的類的同時,既要增加新的特征,同時還要保留equals約定,沒有一個簡單的辦法可以做到這一點。根據"復合優于繼承",這個問題還是有好的解決辦法:我們不讓ColorPoint擴展Point,而是在ColorPoint中加入一個私有的Point域,以及一個公有的視圖方法,此方法返回一個與該有色 點在同一位置上的普通Point對象:
public class ColorPoint{
private Point point;
private Color color;
public ColorPoint(int x,int y,Color color){
point=new Point(x,y);
this.color=color;
}
public Point asPoint(){
return point;
}
public boolean equals(Object o){
if(!(o instanceof ColorPoint)) return false;
ColorPoint cp=(ColorPoint)o;
return cp.point.equals.(point) && cp.color.equals(color);
}
}
注意,你可以在一個抽象類的子類中增加新的特征,而不會違反equals約定。
一致性:
如果兩個對象相等的話,那么它們必須始終保持相等,除非有一個對象被修改了。由于可變對象在不同的時候可以與不同的對象相等,而非可變對象不會這樣,這個約定沒有嚴格界定。
非空性:沒什么好說的。
1,使用==操作符檢查“實參是否為指向對象的一個應用”。如果是的話,則返回true。
2,使用instanceof操作符檢查“實參是否為正確的類型”。如果不是的話,則返回false。
3,把實參轉換到正確的類型。
4,對于該類中每一個“關鍵(significant)”域,檢查實參中的域與當前對象中對應的域值是否匹配
if (!(this.field == null ? o.field == null : this.equals(o.field)))
//或者寫成 if(!(this.field == o.field || (this.field != null && this.field.equals(o.field)))) 對于this.field和o.field通常是相同的對象引用,會更快一些。
return false;
//比較下一個field
//都比較完了
return true;
5.最后還要確認以下事情
5.1)改寫equals的同時,總是(必須)要改寫hashCode方法(見【第8條】),這是極容易被忽略的,有極為重要的
5.2)不要企圖讓equals方法過于聰明
5.3)不要使用不可靠的資源。如依賴網絡連接
5.4)不要將equals聲明中的Object對象替換為其他類型。
public boolean equals(MyClass) 這樣的聲明并不鮮見,往外使程序員數小時搞不清楚為什么不能正常工作
原因是這里是重載(overload)而并不是改寫(override)(或稱為覆蓋、重寫)
相當于給equals又增加了一個實參類型為MyClass的重載,而實參為Object的那個equals并沒有被改寫,依然還是從Object繼承來的最初的那個equals,所總是看不到程序員想要的效果。因為類庫或其他人寫的代碼都是調用實參為Object型的那個equals方法的(別人又如何在事前知曉你今天寫的MyClass呢?)
ExtJS可以用來開發RIA也即富客戶端的AJAX應用,是一個用javascript寫 的,主要用于創建前端用戶界面,是一個與后臺技術無關的前端ajax框架。因此,可以把ExtJS用在.Net、Java、Php等各種開發語言開發的應 用中。
ExtJs最開始基于YUI技術,由開發人員Jack Slocum開發,通過參考Java Swing等機制來組織可視化組件,無論從UI界面上CSS樣式的應用,到數據解析上的異常處理,都可算是一款不可多得的JavaScript客戶端技術 的精品。
ExtJS: http://www.spket.com/demos/js.html spket插件(eclipse)
· Start Aptana and navigate the application menu to: Help → Software Updates → Find and Install… → Search for new features to install → New remote site…
· Name: “Spket”, Url: “http://www.spket.com/update/”
· Restart Eclipse
· Watch this Spket IDE Tutorial to see how to easily add Ext code assist (you can point it at the latest /src/ext.jsb to keep code assist up to date with the latest Ext version). The steps are basically:
o Window → Preferences → Spket → JavaScript Profiles → New
o Enter “ExtJS” and click OK
o Select “ExtJS” and click “Add Library”, then choose “ExtJS” from the dropdown
o Select “ExtJS” and click “Add File”, then choose the “ext.jsb” file in your “./ext-2.x/source” directory
o Set the new ExtJS profile as the default by selecting it an clicking the “Default” button on the right-hand side of the “JavaScript Profiles” dialog.
o Restart Eclipse
o Create a new JS file and type: Ext. and you should get the Ext Code completion options.
一個簡單的例子:
http://extjs.org.cn/node/83
java程序設計風格:(類的說明介紹)
Java文件注釋頭
類中開頭處插入如下 注釋
/******************************************************************
*該類功能及特點的描述(例如:該類是用來.....)
*
*
*該類未被編譯測試過。
*
*@see(與該類相關聯的類):(AnotherClass.java)
*
*
*
*開發公司或單位:XXX軟件有限公司研發中心
*
*版權:本文件版權歸屬XXX公司研發中心
*
*
*@author(作者):XXX
*
*@since(該文件所支持的JDK版本):Jdk1.3或Jdk1.4
*
*@version(版本):1.0
*
*
*@date(開發日期): 1999-01-29
*
*最后更改日期: 2003-01-02
*
*
*修改人: XXXX
*
*復審人: 張三李四 王五
*
*/
內存管理
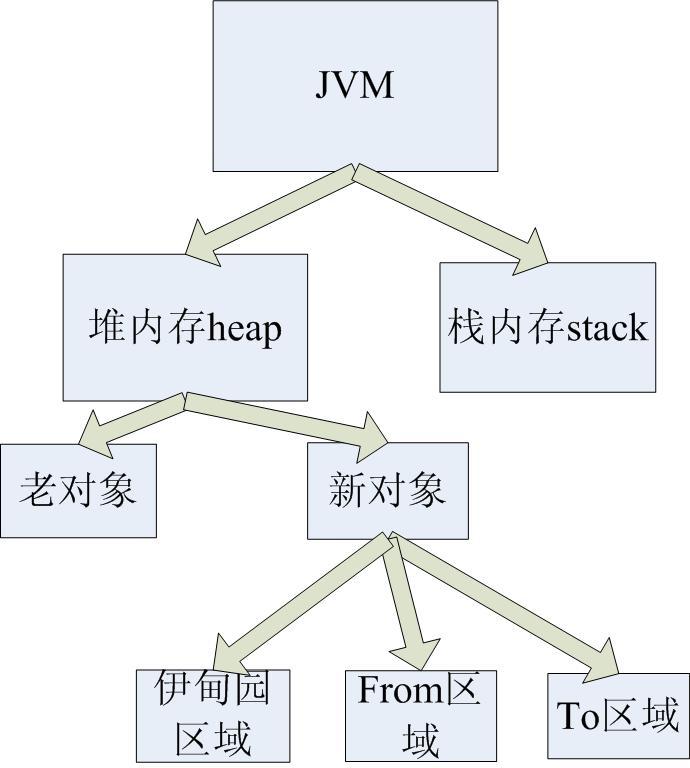
伊甸園用來保存新的對象,它就像一個堆棧,新的對象被創建,就像指向該棧的指針在不斷的增長一樣,當伊甸園區域中的對象滿了之后,JVM系統將要做可到達性測試,主要任務是檢測有哪些對象由根集合出發是不可到達的,這些對象就可以被JVM回收,并且將所有的活動對象從伊甸園區域拷到TO區域,此時一些對象將發生狀態交換,有的對象就從TO區域被轉移到From區域,此時From區域就有了對象,這個過程都是JVM控制完成的。
Java 中的析構方法 finalize
對象是使用完了 盡量都賦 為 null
共享靜態變量存儲空間
不要提前創建對象
........
void f(){
int i;
A a = new A();
//類A的對象a被創建
//在判斷語句之中沒有
//應用過a對象
.....
if(....){
//類A的對象a僅在此處被應用
a.showMessage();
....
}
.....
}
..........
正確的書寫方式為:
void f(){
int i;
.....
if(...){
A a = new A();
//類A的對象a被創建
//應用過a對象
a.showMessage();
}
......
}
JVM內存參數調優
表達式、語句和保留字
非靜態方法中可引用靜態變量
靜態方法不可以引用非靜態變量
靜態方法中可 創建 非靜態變量
調用父類的構造方法必須將其放置子類構造方法的第一行
JAVA核心類與性能優化
線程同步:Vector Hashtable
非線程同步: ArrayList HashMap
字符串累加 盡量使用 StringBuffer +=
方法length() 和 length屬性 區別
IO緩存,讀寫文件優化。
類與接口
內部類(Inner Class)是Java語言中特有的類型,內部類只能被主類以外的其他內部類繼承,主類是不能繼承其內部類的,因為這樣就引起了類循環繼承的錯誤,下面的代碼就是錯誤的。
public class A extends x {
public A(){}
……
Classs x{
…..
}
}
上面的代碼將引發類循環繼承的錯誤,這種錯誤在編譯時就會被發現,比較容易發現和排除。
但是下面例子中的內部類的繼承方式卻是正確的:
class A{
….
public A(){}
……
class X extends Y {
……….
}
calss Y {
……
}
}
什么時候使用繼承,什么樣的繼承是合理的:
1. 現實世界的事物繼承關系,可以作為軟件系統中類繼承關系的依據。
2. 包含關系的類之間不存在繼承關系。如:主機,外設 ,電腦。 把主機類和外設類作為電腦類的成員就可以了。
3. 如果在邏輯上類B是類A的一種,并且類的所有屬性和行為對類而言都有意義,則允許B繼承A的行為和屬性(私有屬性與行為除外)。
原帖javaeye上的:
http://yongtech.javaeye.com/blog/428671 ,覺得寫得挺不錯的!不知道您到什么階段了。。。。hoho
本來我想把這篇文章的名字命名為: <怎樣成為一個優秀的Java程序員>的, 但是自己還不夠優秀, 而本篇所涉及的都是自己學習和工作中的一些經驗, 后來一想, 叫<怎樣進階Java>可能更為合適吧. 能給初學Java的人一個參考, 也就是我本來的心愿. 如果有大牛看到不妥之處, 敬請指正. 我一定會修正的 :).
Java目前是最流行的語言之一, 是很多公司和程序員喜愛的一門程序語言. 而且, Java的入門比C++相對來說要簡單一些, 所以有很大一部分程序員都選擇Java作為自己的開發語言. 我也是其中之一, 就是因為覺得學C++太難, 當初在學校學了將近一個學期的C++, 啥進步都沒有, 哈哈, 天資太差, 所以才選擇自學Java(當時學校并沒有開設Java的課程), 才走上了程序開發這條路.
Java雖然入門要容易, 然而要精通它, 要成為專家卻很難. 主要原因是Java所涉及的技術面比較寬, 人的精力總是有限的. 有些Java方面的技術是必須要要掌握的, 鉆研得越深入越好, 比如多線程技術.
1. 基礎階段
基礎階段, 可能需要經歷1-2年吧. 這個時段, 應該多寫一些基礎的小程序(自己動手寫的越多越好). 計算機是一門實踐性很強的學科, 自己動手的東西, 記憶非常深刻, 效果要勝過讀好多書. 當然, 學Java基礎的時候, 書籍的選擇也非常重要, 好的書籍事半功倍, 能讓你打個非常好的基礎. 而差的書籍, 很容易將你帶入歧途, 多走很多彎路. 書籍不在多, 而在乎讀得精(有些書, 你讀十遍都不為過). 我記得我學Java的第一本書是<Thinking in Java>的中文版, 網上有很多人都建議不要把這本書作為第一本的入門教程來看, 太難. 我卻想在此極力推薦它, 這本書確實是本經典之作. 而且書中確實講的也是Java中的一些基礎技術, 沒有什么太難的東西, 只不過比較厚, 學習周期比較長, 所以很多人中途會選擇放棄. 其實, 這本書是一本難得的入門教程, 對Java一些基礎的東西, 講得很全, 而且也很清晰, 更重要的是, 這本書能讓你養成很多好的編程習慣, 例子也很多. 建議你把大部分的例子自己去實現一遍. 我的親身經歷, 我記得當時認真的看了2遍, 花了大概7個月的時間, 不過真的有很好的效果. 另外一個教程, 就是<Java核心技術>卷一, 卷二的話可以不必要買. 卷一看完, 自己再鉆研一下, 就已經能達到卷二的高度了:). 到那時, 你就會覺得看卷二沒啥意思, 感覺浪費錢了. 還有一個, 就是張孝祥的Java視頻, 看視頻有個好處, 就是比看書的記憶要深刻, 還有很多你可以跟著視頻的演示同步操作. 張孝祥的Java視頻對初學者來說, 確實很有作用. 總結起來: 看這些資料的時候, 一定要多寫例子, 寫的越多越好!
2. 中級階段
中級階段, 是一個更漫長的時期, 能否突破此階段, 跟個人的努力和天資有著很大的關系. 你不得不承認, 同樣一門新技術, 有些人一個月領悟到的東西, 比你一年的都多. 這就是天資, 程序員是一個需要天才的工作. 我想, 很多人聽說李一男吧, 此君就是這樣的人物, 三個月的時間就能解決好大一幫人幾年解決不了的問題, 給華為某部門帶來了很多的收益. 哦, 這是題外話了, 與此篇的主題無關, 只是本人偶爾的感慨而已:). 這個階段, 就需要研究很多專題性的東西了, 比如: IO的實現原理, 多線程和Java的線程模型, 網絡編程, swing, RMI, reflect, EJB, JDBC等等很多很多的專題技術, 鉆研得越深越好. 為了更好的提高, 研究的更深入, 你需要經常到網絡上搜索資料, 這個時候往往一本書起不來很大的作用. 選一個JDK版本吧, 目前建議選用1.6, 多多研究它, 尤其是源代碼(盡量! 就是盡自己最大的努力, 雖然研究透是不可能滴). 比如說: util, collection, io, nio, concurrent等等包. 可能有人會反對我說, 不是有API文檔嗎, 為什么還要研究這么多的源代碼? 錯了, 有API文檔, 你僅僅只是知道怎么用而已, 而認真仔細的研讀這些大牛的源碼, 你就會深入更高的一個階層, 自己的編碼, 設計都會有很大的提高. 如果有能力和精力, 我建議你把JDK的每一行代碼都熟悉一遍, 絕對只有好處, 沒有壞處! 而且你會有些意外的收獲, 比如, 當你仔細地讀完concurrent包的時候(不多, 好像總共是86個類吧), 你就會對Doug Lea佩服得五體投地. 這個時候最忌碰到難題就去尋找幫助, 去網上找答案! 先把自己的腦袋想破吧, 或者等你的老板拿著砍刀沖過來要把你殺了, 再去尋求幫助吧. 對于專題的學習, 英文原版的閱讀是非常必要的, 看的越多越好, 多上上IBM的developer, SUN的網站吧, 當然Javaeye也很不錯:), 有很多大牛, 呵呵.
這個時候, 你應該建立自己的代碼庫了, 你應該自己去研究很多有意思的東西了. 從一個200多M的文件中尋找一個字段, 最壞情況(在文件的末尾咯)也只需要1秒左右的時間, 你知道嗎? 這個階段, 有很多很多類似的有趣的東西可以供你去研究, 你需要更多地關注性能, 規范性, 多解決一些疑難問題. 需要學會所有的調試技術, 運用各種性能工具, 還有JDK附帶的很多工具, 這些你都要熟練得跟屠夫操刀一樣. 也可以看看<Effective Java>, 這本書總結的也不錯, 對寫高效穩定的Java程序有些幫助. 也可以看看模式方面的東西, 但是我建議模式不要濫用, 非得要用的時候才用, 模式往往會把問題搞復雜:). 總結起來: 這個階段是一個由點延伸到面的過程, 經過不斷的學習, 演變成全面的深入! Java技術中你沒什么盲點了, 還能解決很多性能問題和疑難問題, 你就成了一個合格的程序員了! :) [要想成為優秀程序員, 還得對數據庫和操作系統很精通.]
3. 高級階段
高級階段, 我就不敢妄言了. 呵呵, 我感覺自己也是處于中級階段吧. 也是根據自己的一些經驗, 談談自己的理解吧:
這個階段, 需要研究各種框架, Spring, struts, Junit, Hibernate, iBatis, Jboss, Tomcat, snmp4j等等, 我覺得這個時候, 只要是用Java實現的經典框架, 你都可以去研究. ------在此申明一下, 我的意思不是說會用. 光會用其實是遠遠不夠的, 你可以選擇自己喜歡鉆研的框架, 去好好研究一下, 興趣是最好的老師嘛.(2009.07.21)
建議開始的時候, 研究Junit和Struts吧, 小一點, 里面都采用了很多的模式, 呵呵, 可以熟悉一下, 盡量想想人家為什么這么做. 我建議主要的精力可以花在spring和jboss上, 尤其是jboss, 經典中的經典, 設計, 性能, 多線程, 資源管理等等, 你從中可以學到的東西簡直是太多了. 而且它還有一本寫得很好的參考書, 叫<Jboss管理與開發核心技術>, 英文方面的資料也是非常的多. 在工作中如果有機會參與架構的設計, 業務問題的討論, 一定想方設法殺進去! 這對自己的設計能力, 以及對設計如何運用在業務上有很大的幫助. 畢竟, 程序都是為了更好地實現用戶的業務的. 這個時候, 需要更多看看軟件工程和UML方面的資料, 或者自己主持一個項目玩玩, 不一定非得出去拉項目賺錢(能賺錢當然更好), 不管成功或失敗, 都是很寶貴的經驗, 都能提高很多!
該書介紹了在Java編程中極具實用價值的經驗規則,這些經驗規則涵蓋了大多數開發人員每天所面臨的問題的解決方案。通過對Java平臺設計專家所使用的技術的全面描述,揭示了應該做什么,不應該做什么才能產生清晰、健壯和高效的代碼。
每天下班花點時間學習下吧,盡量在一個星期內把它看完,總結出來,大多數內容都來自書上,個人覺得該書不錯的地方摘出來。
第一條:考慮用靜態工廠方法代替構造函數
靜態工廠方法(優點):
1.每次調用的時候,不一定要創建一個新的對象,這個可以自由控制。
2.它可以返回一個原返回類型的子類型的對象。
第二條:使用私有構造函數強化singleton屬性
第一種:提供共有的靜態final域

 public class Elvis
public class Elvis {
{
 public static final Elvis INSTANCE = new Elvis();
public static final Elvis INSTANCE = new Elvis();

 private Elvis(){
private Elvis(){
 }
}
 }
}
第二種:提供一個共有的靜態工廠方法
1public class Elvis{
2 private static final Elvis INSTANCE = new Elvis();
3 private Elvis(){
4
5 }
6
7 public static Elvis getInstance(){
8 return INSTANCE;
9 }
10
11}
第一種性能上會稍微好些
第二種提供了靈活性,在不改變API的前提下,允許我們改變想法,把該類做成singleton,或者不做,容易被修改。
注意點:為了使一個singleton類變成克序列花的(Serializable),僅僅在聲明中加上implements Serializable是不夠的,
為了維護singleton性,必須也要提供一個
private Object readResolve() throws ObjectStreamException{
return INSTANCE;
}
第三條:通過私有構造函數強化不可實例化的能力
只要讓這個類包含單個顯式的私有構造函數,則它就不可被實例化;
1 public class UtilityClass{
2 private UtilityClass(){
3
4 }
5
6 }
企圖通過將一個類做成抽象類來強制該類不可被實例化,這是行不通的。該類可以被子類化,并且該子類也可以被實例化。
更進一步,這樣做會誤導用戶,以為這種類是專門為了繼承而設計的。
第四條:避免創建重復的對象
String s = new Sting("silly");//這么惡心的代碼就不要寫啦。。。
1.靜態工廠方法可幾乎總是優先于構造方法;Boolean.valueOf(...) > Boolean(...),構造函數每次被調用的時候都會創建一個新的對象,
而靜態工廠方法從來不要求這樣做。
2.
public class Person {
private final Date birthDate;
public Person(Date date){
this.birthDate = date;
}
//don't do this
public boolean isBabyBoomer(){
Calendar gmtCal = Calendar.getInstance(TimeZone.getTimeZone("GMT"));
gmtCal.set(1946,Calendar.JANUARY,1,0,0,0);
Date boomStart = gmtCal.getTime();
gmtCal.set(1965,Calendar.JANUARY,1,0,0,0);
Date boomEnd = gmtCal.getTime();
return birthDate.compareTo(boomStart) >=0 && birthDate.compareTo(boomEnd) <0;
}
}
isBabyBoomer每次被調用的時候,都會創建一個新的Calendar,一個新的TimeZone和兩個新的Date實例。。。
下面的版本避免了這種低效率的動作,代之以一個static 塊初始化Calendar對象,而且最體現效率的是,他的生命周期只實例化一次Calendar并且把
80年,90年的出生的值賦值給類靜態變量BOOM_START和BOOM_END
class Person {
private final Date birthDate;
public Person(Date birthDate) {
this.birthDate = birthDate;
}
private static final Date BOOM_START;
private static final Date BOOM_END;
static {
Calendar gmtCal = Calendar.getInstance(TimeZone.getTimeZone("GMT"));
gmtCal.set(1980, Calendar.JANUARY, 1, 0, 0, 0);
BOOM_START = gmtCal.getTime();
gmtCal.set(1990, Calendar.JANUARY, 1, 0, 0, 0);
BOOM_END = gmtCal.getTime();
}
public boolean isBabyBoomer() {
return birthDate.compareTo(BOOM_START) >= 0
&& birthDate.compareTo(BOOM_END) < 0;
}
最近在翻《首先,打破一切常規》,書不只翻一遍了,每次都會有一些新的收獲.書中經常提到的6個問題越想越覺得有道理,列出跟大家分享:
1.你知道對你工作的要求嗎?
第一優先級的問題,如果不知道對你的工作要求,那么你如何衡量你工作的好壞?其他人如何衡量你的工作成果?首當其沖需要考慮的問題.
2.你有做好你當前工作的材料和設備或者資源嗎?
當然明確工作要求的時候需要明確你達到你目標的途徑,此時需要衡量你能掌控的資源,或者你能夠使用到的潛在資源.
3.在工作中你每天都有機會做你最擅長的事情嗎?
是否能夠發揮自己的潛力,是否是自己的興趣愛好,是否能做的更好.
4.過去的7天內,你有因你的工作出色而受到表揚嗎?
周圍同事或者你的主管關注你的個人價值,為什么會受到表揚?是否可以在這件工作上受到一貫的認可.
5.你覺得你的主管或者同事關心你的個人情況嗎?
恒定自己在團隊中的作用,如果不關心,為什么?你是否了解過其他人的感受?如果關心?關心那點?如何滿足期望.
6.工作單位里面有人會鼓勵你的發展嗎?
職業發展的考慮,企業是否值得呆下去,是否能夠共同進步.
定期拿這些問題進行自勉,會有很多收獲.包括你的同事,你的主管,你的合作伙伴,甚至會改變你的人生.
問題:
下面一個簡單的類:
public class MyTest {
private static String
className = String.class.getName(); //紅色部分是下面問題的關鍵
public static void
main(String[] args){
System.out.println(className);
}
}
經eclipse3.1.1編譯后(指定類兼容性版本為1.4),再反編譯的結果是:
public class MyTest
{
public MyTest()
{
}
public static void main(String args[])
{
System.out.println(className);
}
private static String className;
static
{
className =
java.lang.String.class.getName();
}
}
而經過sun javac(或者ant, antx)編譯后(JDK版本1.4,或者JDK1.5,但是編譯結果指定版本為1.4),再反編譯的結果是:
public class MyTest
{
public MyTest()
{
}
public static void main(String args[])
{
System.out.println(className);
}
static Class _mthclass$(String x0)
{
return Class.forName(x0);
ClassNotFoundException
x1;
x1;
throw (new
NoClassDefFoundError()).initCause(x1);
}
private static String className;
static
{
className =
(java.lang.String.class).getName();
}
}
也就是說sun javac編譯出來的結果里面多了一個_mthclass$方法,這個通常不會有什么問題,不過在使用hot swap技術(例如Antx
eclipse plugin中的快速部署插件利用hot swap來實現類的熱替換,或者某些類序列化的地方,這個就成為問題了。
用_mthclass$在google上搜一把,結果不多,比較有價值的是這一篇:http://coding.derkeiler.com/Archive/Java/comp.lang.java.softwaretools/2004-01/0138.html
按照這個說法,這個問題是由于Sun本身沒有遵循規范,而eclipse compiler遵循規范導致的,而且eclipse
compiler是沒有辦法替換的。
嘗試將JDK版本換成1.5,sun
javac生成出來的_mthclass$是不見了,不過,這回奇怪的是eclipse的編譯結果中多了一個成員變量class$0,
下面是經eclipse3.1.1編譯后(指定類兼容性版本為5.0),再反編譯的結果:
public
class MyTest
{
public MyTest()
{
}
public static void main(String args[])
{
System.out.println(className);
}
private static String className = java/lang/String.getName();
static Class class$0;
}
而經過sun javac(或者ant, antx)編譯后(JDK版本1.5),再反編譯的結果是:
public class
MyTest
{
public MyTest()
{
}
public static void main(String args[])
{
System.out.println(className);
}
private static String className = java/lang/String.getName();
}
再在goole上搜了一把,發現了Eclipse3.2有兩個比較重要的特征:
1.與javac的兼容性更好。
2.提供了單獨的編譯器,可以在eclipse外部使用,包括ant中使用。
于是下載eclipse3.2版本,首先驗證一下其與sun javac的兼容性如何,
使用JDK1.4版本的時候,還是老樣子,sun
javac編譯出來的_mthclass$方法在eclipse3.2的編譯結果中還是不存在,所以還是不兼容的。
不過使用JDK1.5版本的時候,這會eclipse
3.2的編譯結果總算和sun javac一致了。
雖然,用JDK1.5加上eclipse
3.2已經保證了這個類在兩種編譯器下的兼容性,不過總覺得不踏實:
1.誰知道這兩個編譯器還有沒有其它不兼容的地方呢?
2.版本要求太嚴格,很多由于各種原因沒有使用這些版本的很麻煩。
因此,還是從根本上解決這個問題比較合適:根本上解決最好就是不要使用兩種不同的編譯器,而使用同一種。
由于eclipse環境下的編譯器是不可替換的,所以企圖都使用sun
javac的方式不太可行,那么統一使用eclipse自帶的編譯器如何呢?
剛才提到的eclipse3.2的第二個比較重要的特性就派上用場了。
獨立的eclipse編譯器(1M大小而已)可以在如下地址下載:http://www.eclipse.org/downloads/download.php?file=/eclipse/downloads/drops/R-3.2-200606291905/ecj.jar
這個獨立的編譯器在antx下的使用也很簡單:(關于該編譯器的獨立使用或者ant下面的使用可以參看this help section: JDT
Plug-in Developer Guide>Programmer's Guide>JDT Core>Compiling Java
code)
1.將下載下來的編譯器放在ANTX_HOME/lib目錄下面。
2.在總控項目文件的project.xml增加這么一行即可:<property
name="build.compiler"
value="org.eclipse.jdt.core.JDTCompilerAdapter"/>
這樣就保證了通過antx打包的類也是用eclipse的編譯器編譯出來的,當然就不應該存在類不兼容的情況了。
實際上,eclipse3.1.1版本也已經提供了獨立的eclipse編譯器,不過當時并沒有單獨提供獨立的包下載,如果希望使用3.1.1版本的eclipse編譯器,可以使用org.eclipse.jdt.core_3.1.1.jar以及其中包含的jdtCompilerAdapter.jar。(eclipse3.1.1環境的編譯器我沒有獨立驗證過)
Unicode是一種字符編碼規范 。
先從ASCII說起。ASCII是用來表示英文字符的一種編碼規范,每個ASCII字符占用1個字節(8bits)
因此,ASCII編碼可以表示的最大字符數是256,其實英文字符并沒有那么多,一般只用前128個(最高位為0),其中包括了控制字符、數字、大小寫字母和其他一些符號 。
而最高位為1的另128個字符被成為“擴展ASCII”,一般用來存放英文的制表符、部分音標字符等等的一些其他符號
這種字符編碼規范顯然用來處理英文沒有什么問題 。(實際上也可以用來處理法文、德文等一些其他的西歐字符,但是不能和英文通用),但是面對中文、阿拉伯文之類復雜的文字,255個字符顯然不夠用
于是,各個國家紛紛制定了自己的文字編碼規范,其中中文的文字編碼規范叫做“GB2312-80”,它是和ASCII兼容的一種編碼規范,其實就是利用擴展ASCII沒有真正標準化這一點,把一個中文字符用兩個擴展ASCII字符來表示。
但是這個方法有問題,最大的問題就是,中文文字沒有真正屬于自己的編碼,因為擴展ASCII碼雖然沒有真正的標準化,但是PC里的ASCII碼還是有一個事實標準的(存放著英文制表符),所以很多軟件利用這些符號來畫表格。這樣的軟件用到中文系統中,這些表格符就會被誤認作中文字,破壞版面。而且,統計中英文混合字符串中的字數,也是比較復雜的,我們必須判斷一個ASCII碼是否擴展,以及它的下一個ASCII是否擴展,然后才“猜”那可能是一個中文字 。
總之當時處理中文是很痛苦的。而更痛苦的是GB2312是國家標準,臺灣當時有一個Big5編碼標準,很多編碼和GB是相同的,所以……,嘿嘿。
這時候,我們就知道,要真正解決中文問題,不能從擴展ASCII的角度入手,也不能僅靠中國一家來解決。而必須有一個全新的編碼系統,這個系統要可以將中文、英文、法文、德文……等等所有的文字統一起來考慮,為每個文字都分配一個單獨的編碼,這樣才不會有上面那種現象出現。
于是,Unicode誕生了。
Unicode有兩套標準,一套叫UCS-2(Unicode-16),用2個字節為字符編碼,另一套叫UCS-4(Unicode-32),用4個字節為字符編碼。
以目前常用的UCS-2為例,它可以表示的字符數為2^16=65535,基本上可以容納所有的歐美字符和絕大部分的亞洲字符 。
UTF-8的問題后面會提到 。
在Unicode里,所有的字符被一視同仁。漢字不再使用“兩個擴展ASCII”,而是使用“1個Unicode”,注意,現在的漢字是“一個字符”了,于是,拆字、統計字數這些問題也就自然而然的解決了 。
但是,這個世界不是理想的,不可能在一夜之間所有的系統都使用Unicode來處理字符,所以Unicode在誕生之日,就必須考慮一個嚴峻的問題:和ASCII字符集之間的不兼容問題。
我們知道,ASCII字符是單個字節的,比如“A”的ASCII是65。而Unicode是雙字節的,比如“A”的Unicode是0065,這就造成了一個非常大的問題:以前處理ASCII的那套機制不能被用來處理Unicode了 。
另一個更加嚴重的問題是,C語言使用'\0'作為字符串結尾,而Unicode里恰恰有很多字符都有一個字節為0,這樣一來,C語言的字符串函數將無法正常處理Unicode,除非把世界上所有用C寫的程序以及他們所用的函數庫全部換掉 。
于是,比Unicode更偉大的東東誕生了,之所以說它更偉大是因為它讓Unicode不再存在于紙上,而是真實的存在于我們大家的電腦中。那就是:UTF 。
UTF= UCS Transformation Format UCS轉換格式
它是將Unicode編碼規則和計算機的實際編碼對應起來的一個規則。現在流行的UTF有2種:UTF-8和UTF-16 。
其中UTF-16和上面提到的Unicode本身的編碼規范是一致的,這里不多說了。而UTF-8不同,它定義了一種“區間規則”,這種規則可以和ASCII編碼保持最大程度的兼容 。
UTF-8有點類似于Haffman編碼,它將Unicode編碼為00000000-0000007F的字符,用單個字節來表示;
00000080-000007FF的字符用兩個字節表示
00000800-0000FFFF的字符用3字節表示
因為目前為止Unicode-16規范沒有指定FFFF以上的字符,所以UTF-8最多是使用3個字節來表示一個字符。但理論上來說,UTF-8最多需要用6字節表示一個字符。
在UTF-8里,英文字符仍然跟ASCII編碼一樣,因此原先的函數庫可以繼續使用。而中文的編碼范圍是在0080-07FF之間,因此是2個字節表示(但這兩個字節和GB編碼的兩個字節是不同的),用專門的Unicode處理類可以對UTF編碼進行處理。
下面說說中文的問題。
由于歷史的原因,在Unicode之前,一共存在過3套中文編碼標準。
GB2312-80,是中國大陸使用的國家標準,其中一共編碼了6763個常用簡體漢字。Big5,是臺灣使用的編碼標準,編碼了臺灣使用的繁體漢字,大概有8千多個。HKSCS,是中國香港使用的編碼標準,字體也是繁體,但跟Big5有所不同。
這3套編碼標準都采用了兩個擴展ASCII的方法,因此,幾套編碼互不兼容,而且編碼區間也各有不同
因為其不兼容性,在同一個系統中同時顯示GB和Big5基本上是不可能的。當時的南極星、RichWin等等軟件,在自動識別中文編碼、自動顯示正確編碼方面都做了很多努力 。
他們用了怎樣的技術我就不得而知了,我知道好像南極星曾經以同屏顯示繁簡中文為賣點。
后來,由于各方面的原因,國際上又制定了針對中文的統一字符集GBK和GB18030,其中GBK已經在Windows、Linux等多種操作系統中被實現。
GBK兼容GB2312,并增加了大量不常用漢字,還加入了幾乎所有的Big5中的繁體漢字。但是GBK中的繁體漢字和Big5中的幾乎不兼容。
GB18030相當于是GBK的超集,比GBK包含的字符更多。據我所知目前還沒有操作系統直接支持GB18030。
談談Unicode編碼,簡要解釋UCS、UTF、BMP、BOM等名詞
這是一篇程序員寫給程序員的趣味讀物。所謂趣味是指可以比較輕松地了解一些原來不清楚的概念,增進知識,類似于打RPG游戲的升級。整理這篇文章的動機是兩個問題:
問題一:
使用Windows記事本的“另存為”,可以在GBK、Unicode、Unicode big endian和UTF-8這幾種編碼方式間相互轉換。同樣是txt文件,Windows是怎樣識別編碼方式的呢?
我很早前就發現Unicode、Unicode big endian和UTF-8編碼的txt文件的開頭會多出幾個字節,分別是FF、FE(Unicode),FE、FF(Unicode big endian),EF、BB、BF(UTF-8)。但這些標記是基于什么標準呢?
問題二:
最近在網上看到一個ConvertUTF.c,實現了UTF-32、UTF-16和UTF-8這三種編碼方式的相互轉換。對于Unicode(UCS2)、GBK、UTF-8這些編碼方式,我原來就了解。但這個程序讓我有些糊涂,想不起來UTF-16和UCS2有什么關系。
查了查相關資料,總算將這些問題弄清楚了,順帶也了解了一些Unicode的細節。寫成一篇文章,送給有過類似疑問的朋友。本文在寫作時盡量做到通俗易懂,但要求讀者知道什么是字節,什么是十六進制。
0、big endian和little endian
big endian和little endian是CPU處理多字節數的不同方式。例如“漢”字的Unicode編碼是6C49。那么寫到文件里時,究竟是將6C寫在前面,還是將49寫在前面?如果將6C寫在前面,就是big endian。還是將49寫在前面,就是little endian。
“endian”這個詞出自《格列佛游記》。小人國的內戰就源于吃雞蛋時是究竟從大頭(Big-Endian)敲開還是從小頭(Little-Endian)敲開,由此曾發生過六次叛亂,其中一個皇帝送了命,另一個丟了王位。
我們一般將endian翻譯成“字節序”,將big endian和little endian稱作“大尾”和“小尾”。
1、字符編碼、內碼,順帶介紹漢字編碼
字符必須編碼后才能被計算機處理。計算機使用的缺省編碼方式就是計算機的內碼。早期的計算機使用7位的ASCII編碼,為了處理漢字,程序員設計了用于簡體中文的GB2312和用于繁體中文的big5。
GB2312(1980年)一共收錄了7445個字符,包括6763個漢字和682個其它符號。漢字區的內碼范圍高字節從B0-F7,低字節從A1-FE,占用的碼位是72*94=6768。其中有5個空位是D7FA-D7FE。
GB2312支持的漢字太少。1995年的漢字擴展規范GBK1.0收錄了21886個符號,它分為漢字區和圖形符號區。漢字區包括21003個字符。2000年的GB18030是取代GBK1.0的正式國家標準。該標準收錄了27484個漢字,同時還收錄了藏文、蒙文、維吾爾文等主要的少數民族文字。現在的PC平臺必須支持GB18030,對嵌入式產品暫不作要求。所以手機、MP3一般只支持GB2312。
從ASCII、GB2312、GBK到GB18030,這些編碼方法是向下兼容的,即同一個字符在這些方案中總是有相同的編碼,后面的標準支持更多的字符。在這些編碼中,英文和中文可以統一地處理。區分中文編碼的方法是高字節的最高位不為0。按照程序員的稱呼,GB2312、GBK到GB18030都屬于雙字節字符集 (DBCS)。
有的中文Windows的缺省內碼還是GBK,可以通過GB18030升級包升級到GB18030。不過GB18030相對GBK增加的字符,普通人是很難用到的,通常我們還是用GBK指代中文Windows內碼。
這里還有一些細節:
GB2312的原文還是區位碼,從區位碼到內碼,需要在高字節和低字節上分別加上A0。
在DBCS中,GB內碼的存儲格式始終是big endian,即高位在前。
GB2312的兩個字節的最高位都是1。但符合這個條件的碼位只有128*128=16384個。所以GBK和GB18030的低字節最高位都可能不是1。不過這不影響DBCS字符流的解析:在讀取DBCS字符流時,只要遇到高位為1的字節,就可以將下兩個字節作為一個雙字節編碼,而不用管低字節的高位是什么。
2、Unicode、UCS和UTF
前面提到從ASCII、GB2312、GBK到GB18030的編碼方法是向下兼容的。而Unicode只與ASCII兼容(更準確地說,是與ISO-8859-1兼容),與GB碼不兼容。例如“漢”字的Unicode編碼是6C49,而GB碼是BABA。
Unicode也是一種字符編碼方法,不過它是由國際組織設計,可以容納全世界所有語言文字的編碼方案。Unicode的學名是"Universal Multiple-Octet Coded Character Set",簡稱為UCS。UCS可以看作是"Unicode Character Set"的縮寫。
根據維基百科全書(
http://zh.wikipedia.org/wiki/)的記載:歷史上存在兩個試圖獨立設計Unicode的組織,即國際標準化組織(ISO)和一個軟件制造商的協會(unicode.org)。ISO開發了ISO 10646項目,Unicode協會開發了Unicode項目。
在1991年前后,雙方都認識到世界不需要兩個不兼容的字符集。于是它們開始合并雙方的工作成果,并為創立一個單一編碼表而協同工作。從Unicode2.0開始,Unicode項目采用了與ISO 10646-1相同的字庫和字碼。
目前兩個項目仍都存在,并獨立地公布各自的標準。Unicode協會現在的最新版本是2005年的Unicode 4.1.0。ISO的最新標準是10646-3:2003。
UCS規定了怎么用多個字節表示各種文字。怎樣傳輸這些編碼,是由UTF(UCS Transformation Format)規范規定的,常見的UTF規范包括UTF-8、UTF-7、UTF-16。
IETF的RFC2781和RFC3629以RFC的一貫風格,清晰、明快又不失嚴謹地描述了UTF-16和UTF-8的編碼方法。我總是記不得IETF是Internet Engineering Task Force的縮寫。但IETF負責維護的RFC是Internet上一切規范的基礎。
3、UCS-2、UCS-4、BMP
UCS有兩種格式:UCS-2和UCS-4。顧名思義,UCS-2就是用兩個字節編碼,UCS-4就是用4個字節(實際上只用了31位,最高位必須為0)編碼。下面讓我們做一些簡單的數學游戲:
UCS-2有2^16=65536個碼位,UCS-4有2^31=2147483648個碼位。
UCS-4根據最高位為0的最高字節分成2^7=128個group。每個group再根據次高字節分為256個plane。每個plane根據第3個字節分為256行 (rows),每行包含256個cells。當然同一行的cells只是最后一個字節不同,其余都相同。
group 0的plane 0被稱作Basic Multilingual Plane, 即BMP。或者說UCS-4中,高兩個字節為0的碼位被稱作BMP。
將UCS-4的BMP去掉前面的兩個零字節就得到了UCS-2。在UCS-2的兩個字節前加上兩個零字節,就得到了UCS-4的BMP。而目前的UCS-4規范中還沒有任何字符被分配在BMP之外。
4、UTF編碼
UTF-8就是以8位為單元對UCS進行編碼。從UCS-2到UTF-8的編碼方式如下:
UCS-2編碼(16進制) UTF-8 字節流(二進制)
0000 - 007F 0xxxxxxx
0080 - 07FF 110xxxxx 10xxxxxx
0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
例如“漢”字的Unicode編碼是6C49。6C49在0800-FFFF之間,所以肯定要用3字節模板了:1110xxxx 10xxxxxx 10xxxxxx。將6C49寫成二進制是:0110 110001 001001, 用這個比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
讀者可以用記事本測試一下我們的編碼是否正確。
UTF-16以16位為單元對UCS進行編碼。對于小于0x10000的UCS碼,UTF-16編碼就等于UCS碼對應的16位無符號整數。對于不小于0x10000的UCS碼,定義了一個算法。不過由于實際使用的UCS2,或者UCS4的BMP必然小于0x10000,所以就目前而言,可以認為UTF-16和UCS-2基本相同。但UCS-2只是一個編碼方案,UTF-16卻要用于實際的傳輸,所以就不得不考慮字節序的問題。
5、UTF的字節序和BOM
UTF-8以字節為編碼單元,沒有字節序的問題。UTF-16以兩個字節為編碼單元,在解釋一個UTF-16文本前,首先要弄清楚每個編碼單元的字節序。例如收到一個“奎”的Unicode編碼是594E,“乙”的Unicode編碼是4E59。如果我們收到UTF-16字節流“594E”,那么這是“奎”還是“乙”?
Unicode規范中推薦的標記字節順序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。BOM是一個有點小聰明的想法:
在UCS編碼中有一個叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的編碼是FEFF。而FFFE在UCS中是不存在的字符,所以不應該出現在實際傳輸中。UCS規范建議我們在傳輸字節流前,先傳輸字符"ZERO WIDTH NO-BREAK SPACE"。
這樣如果接收者收到FEFF,就表明這個字節流是Big-Endian的;如果收到FFFE,就表明這個字節流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被稱作BOM。
UTF-8不需要BOM來表明字節順序,但可以用BOM來表明編碼方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8編碼是EF BB BF(讀者可以用我們前面介紹的編碼方法驗證一下)。所以如果接收者收到以EF BB BF開頭的字節流,就知道這是UTF-8編碼了。
Windows就是使用BOM來標記文本文件的編碼方式的。
6、進一步的參考資料
本文主要參考的資料是 "Short overview of ISO-IEC 10646 and Unicode" (
http://www.nada.kth.se/i18n/ucs/unicode-iso10646-oview.html)。
我還找了兩篇看上去不錯的資料,不過因為我開始的疑問都找到了答案,所以就沒有看:
"Understanding Unicode A general introduction to the Unicode Standard" (
http://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&item_id=IWS-Chapter04a)
"Character set encoding basics Understanding character set encodings and legacy encodings" (
http://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&item_id=IWS-Chapter03)
下面列舉10個攻擊:
1.AJAX中的跨站點腳本
前幾個月,人們發現了多種跨站點的腳本攻擊。在此類攻擊中,受害者的包含信息的瀏覽器上會運行來自特定網站的惡意JAVA腳本代碼。
Yamanner蠕蟲就是一個最近的范例,它利用Yahoo郵件的AJAX調用中的跨站點腳本機會來攻擊受害者。另一個近期的范例就是Samy蠕蟲,它利
用MySpace.com的跨站點腳本漏洞來攻擊。AJAX在客戶端上運行,它允許錯誤書寫的腳本被攻擊者利用。攻擊者能夠編寫惡意鏈接來哄騙那些沒有準
備的用戶,讓他們用瀏覽器去訪問特定的網頁。傳統應用中也存在這樣的弱點,但AJAX給它添加了更多可能的漏洞。例子, Yamanner蠕蟲利用了Yahoo
Mail的AJAX的跨站腳本漏洞,Samy蠕蟲利用了MySpace.com的跨站腳本漏洞。
2.XML中毒
很多Web2.0應用中,XML傳輸在服務器和瀏覽器之間往復。網絡應用接收來自AJAX客戶端的XML塊。這XML塊很可能染毒。多次將遞歸
負載應用到產出相似的XML節點,這樣的技術還并不普遍。如果機器的處理能力較弱,這將導致服務器拒絕服務。很多攻擊者還制作結構錯誤的XML文檔,這些
文檔會擾亂服務器上所使用的依賴剖析機制的邏輯。服務器端的剖析機制有兩種類型,它們是SAX和DOM。網絡服務也使用相同的攻擊向量,這是因為網絡服務
接收SOAP消息,而SOAP就是XML消息。在應用層大范圍地使用XMLs使攻擊者有更多的機會利用這個新的攻擊向量。
XML外部實體參照是能被攻擊者偽造的一個XML的屬性。這會使攻擊者能夠利用人意的文件或者TCP連接的缺陷。XML
schema中毒是另一個XML中毒的攻擊向量,它能夠改變執行的流程。這個漏洞能幫助攻擊者獲得機密信息。攻擊者可以通過復制節點進行DOS攻擊,或者生成不合法的XML導致服務器端邏輯的中斷。攻擊者也可以操縱外部實體,導致打開任何文件或TCP連接端口。XML數據定義的中毒也可以導致運行流程的改變,助攻擊者獲取機密信息。
3.惡意AJAX代碼的執行
AJAX調用非常不易察覺,終端用戶無法確定瀏覽器是否正在用XMLHTTP請求對象發出無記載的調用。瀏覽器發出AJAX調用給任意網站的時
候,該網站會對每個請求回應以cookies。這將導致出現泄漏的潛在可能性。例如,約翰已經登陸了他的銀行,并且通過了服務器認證。完成認證過程后,他
會得到一個會話
cookie。銀行的頁面中包含了很多關鍵信息。現在,他去瀏覽器他網頁,并同時仍然保持銀行賬戶的登陸狀態。他可能會剛好訪問一個攻擊者的網頁,在這個
網頁上攻擊者寫了不易被察覺的AJAX
代碼,這個代碼不用經過約翰的同意,就能夠發出后臺調用給約翰的銀行網頁,因而能夠從銀行頁面取得關鍵信息并且把這些信息發送到攻擊者的網站。這將導致機
密信息的泄漏甚至引發安全突破。AJAX
編碼可以在不為用戶所知的情形下運行,假如用戶先登錄一個機密網站,機密網站返回一個會話cookie,然后用戶在沒有退出機密網站的情形下,訪問攻擊者
的網站,攻擊者網頁上的AJAX編碼可以(通過這個會話cookie?)去訪問機密網站上的網頁,從而竊取用戶的機密信息。(注:這里的解釋有點含糊,理
論上講,瀏覽器不會把一個網站的會話cookie傳給另外一個網站的,即文中的這句“When the browser makes an AJAX
call to any Web site it replays cookies for each request. ”,不完全對)
4.RSS/Atom 注入
這是一項新的web2.0攻擊。RSS反饋是人們在門戶網站或者網絡應用中共享信息的常用手段。網絡應用接受這些反饋然后發送給客戶端的瀏覽器。人們可
以在該RSS反饋中插入文本的JavaScript來產生對用戶瀏覽器的攻擊。訪問特定網站的終端用戶加載了帶有該RSS反饋的網頁,這個腳本
就會運行起來——它能夠往用戶的電腦中安裝軟件或者竊取cookies信息。這就是一個致命的客戶端攻擊。更糟糕的是,它可以變異。隨著RSS和ATOM
反饋成為網絡應用中整合的組件,在服務器端將數據發布給終端用戶之前,過濾特定字符是非常必要的。攻擊者可以在RSS
feeds里注入Javascript腳本,如果服務器端沒有過濾掉這些腳本的話,在瀏覽器端會造成問題。
5.WSDL掃描和enumeration
WSDL(網絡服務界定語言)是網絡服務的一個接口。該文件提供了技術,開放方法,創新形式等等的關鍵信息。這是非常敏感信息,而且能夠幫助人
們決定利用什么弱點來攻擊。如果將不必要的功能或者方法一直開著,這會為網絡服務造成潛在的災難。保護WSDL文件或者限定對其的訪問是非常重要的。在實
際情況中,很有可能找到一些使用WSDL掃描的一些漏洞。WSDL提供了Web服務所用的技術,以及外露的方法,調用的模式等信息。假如Web服務對不必要的方法沒有禁止的話,攻擊者可以通過WSDL掃描找到潛在的攻擊點。
6.AJAX常規程序中客戶端的確認
基于web2.0的應用使用AJAX常規程序來在客戶端上進行很多操作,比如客戶端數據類型的確認,內容檢查,數據域等等。正常情況下,服務端
也應該備份這些客戶端檢查信息。大部分開發者都沒有這么做;他們這樣做的理由是,他們假設這樣的確認是由AJAX常規程序來負責的。避開基于AJAX的確
認和直接發送POST或者GET請求給那些應用——這些應用是諸如SQL注入,LDAP注入等類隨確認進入的攻擊主要來源,它們能夠攻擊網絡應用的關鍵資
源——都是可以做到的。這都增加了能夠為攻擊者所利用的潛在攻擊向量的數量。假如開發人員只依賴客戶端驗證,不在服務器端重新驗證的話,會導致SQL注入,LDAP注入等等。
7.網絡服務路由問題
網絡服務安全協議包括WS-Routing服務。WS-Routing允許SOAP消息在互聯網上各種各樣不同的節點中的特別序列中傳輸。通常
加密的信息在這些節點來回傳送。交互的節點中的任意一個被攻擊都將致使攻擊者能夠訪問到在兩個端點之間傳輸的SOAP消息。這將造成SOAP消息的嚴重的
安全泄漏。隨著網絡應用開始被網絡服務框架所采用,攻擊者們開始轉而利用這些新協議和新的攻擊向量。Web服務安全協議使用WS-Routing服務,假如任何中轉站被攻占,SOAP消息可以被截獲。
8.SOAP消息的參數操作
網絡服務接收信息和來自SOAP消息的變量。修改這些變量是很可能的。例如,“10”是SOAP消息中多個節點中的一個。攻擊者可以修改點,并
且嘗試不同種的注入攻擊——比如,SQL,LDAP,XPATH,命令行解釋器——并且探索能被他用來掌握及其內部信息的攻擊向量。網絡服務代碼中錯誤的
或者不夠完備的輸入確認使網絡服務應用易于發生泄漏.這是一個目標指向網絡服務所帶的網絡應用的一項新的攻擊向量。類似于SQL注入,假如對SOAP消息里節點的數據不做驗證的話。
9.SOAP消息中的XPATH注入
XPATH是一種用來查詢XML文檔的語言,它跟SQL語句很類似:我們提供某些信息(參數)然后從數據庫中得到查詢結果。很多語言都支持
XPATH
解析的功能。網絡應用接收大型XML文檔,很多時候這些應用從終端用戶和XPATH語句中取得輸入量。這些代碼的段落對XPATH注入沒有什么防御能力。
如果XPATH執行成功,攻擊者能夠繞過認證機制或者造成機密信息的一些損失。現在人們只知道很少部分的能夠被攻擊者利用的XPATH的漏洞。阻止這個攻
擊向量的唯一方法就是在給XPATH語句傳遞變量值的時候提供適當的輸入確認。類似于SQL注入,假如對數據不做驗證而直接做XPATH查詢的話。
10. RIA瘦客戶端二進制的偽造
豐富網絡應用(RIA)使用非常豐富的UI要素比如Flash,ActiveX控件或者Applets,它使用這些要素作為網絡應用的基本接
口。這個框架存在幾個安全問題。其中最主要的一個就是關于會話管理。它是在瀏覽器中運行的,并且共享相同的會話。同時,由于客戶端將下載整個二進制元件到
自己的主機,攻擊者就可以顛倒工程的那個二進制文件并且反編譯代碼。把這些二進制串打包并繞過一些包含在代碼中的認證邏輯是有可能實現的。這是
WEB2.0框架下的另一個有趣的攻擊向量。因為Rich Internet
Applications的組件是下載到瀏覽器本地的,攻擊者可以對二進制文件進行逆向工程,反編譯編碼,通過改動文件,跳過認證邏輯
。
結論
AJAX,RIA以及網絡服務是WEB2.0應用空間的三項重要的技術向量。這些技術很有前景,它們帶給桌面新的程式,加強了網絡應用的整體效
率和效用。隨著這些新技術而來的是新的安全問題,忽略這些問題將會導致整個世界發生巨大的災難。本文中,我們只討論了10種攻擊。但是實際上還有很多其他
的攻擊向量。對這些新的攻擊向量的最好的防御方法是增加WEB2.0的安全意識,提高代碼操作的安全性以及配置的安全性
匹配中文字符的正則表達式: [\u4e00-\u9fa5]
匹配雙字節字符(包括漢字在內):[^\x00-\xff]
應用:計算字符串的長度(一個雙字節字符長度計2,ASCII字符計1)
String.prototype.len=function(){return this.replace([^\x00-\xff]/g,"aa").length;}
匹配空行的正則表達式:\n[\s| ]*\r
匹配HTML標記的正則表達式:/<(.*)>.*<\/\1>|<(.*) \/>/
匹配首尾空格的正則表達式:(^\s*)|(\s*$)
應用:javascript中沒有像vbscript那樣的trim函數,我們就可以利用這個表達式來實現,如下:
String.prototype.trim = function()
{ return this.replace(/(^\s*)|(\s*$)/g, "");
} 利用正則表達式分解和轉換IP地址:
下面是利用正則表達式匹配IP地址,并將IP地址轉換成對應數值的Javascript程序:
function IP2V(ip)
{
re=/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //匹配IP地址的正則表達式
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1
}
else
{
throw new Error("Not a valid IP address!")
}
}
不過上面的程序如果不用正則表達式,而直接用split函數來分解可能更簡單,程序如下:
var ip="10.100.20.168"
ip=ip.split(".")
alert("IP值是:"+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1))
匹配Email地址的正則表達式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配網址URL的正則表達式:http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
利用正則表達式限制網頁表單里的文本框輸入內容:
用正則表達式限制只能輸入中文:onkeyup="value=value.replace(/[^\u4E00-\u9FA5]/g,'')"
onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\u4E00-\u9FA5]/g,''))"
用正則表達式限制只能輸入全角字符: onkeyup="value=value.replace(/[^\uFF00-\uFFFF]/g,'')"
onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\uFF00-\uFFFF]/g,''))"
用正則表達式限制只能輸入數字:onkeyup="value=value.replace(/
[^\d]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"
用正則表達式限制只能輸入數字和英文:onkeyup="value=value.replace(/
[\W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"