]]>
]]>
ArchiveDetector detector = new DefaultArchiveDetector(ArchiveDetector.ALL,
new Object[] { "zip", new CheckedZip32Driver("GBK") } );
File zipFile = new File("zipFile", detector);
File dst = new File("dst");
// 解压�~?/span>
zipFile.copyAllTo(dst);
代码十分����z�,注意�q�个File�?/p>
de.schlichtherle.io.File
不是
java.io.File
当处理完业务要删除这个Zip File�Ӟ��问题出现了:
�q�个文�g删不掉!�Q�!
把自��q��代码���查了好久�Q�确认没问题后,开始从TrueZIP下手�Q�发现它有特�D�的地方的,是提�C����的:
File file = new File(“archive.zip”); // de.schlichtherle.io.File!
Please do not do this instead:
de.schlichtherle.io.File file = new de.schlichtherle.io.File(“archive.zip”);
This is for the following reasons:
1.Accidentally using java.io.File and de.schlichtherle.io.File instances referring to the same path concurrently will result in erroneous behaviour and may even cause loss of data! Please refer to the section “Third Party Access” in the package Javadoc of de.schlichtherle.io for for full details and workarounds.
2.A de.schlichtherle.io.File subclasses java.io.File and thanks to polymorphism can be used everywhere a java.io.File could be used.
原来两个File不能交叉使用�Q�搞清楚原因了,加这么一句代码搞定�?/p>
zipFile.deleteAll();
]]>
final private int capacity;
final private Map<K,Reference<V>> map;
final private ReentrantLock lock = new ReentrantLock();
final private ReferenceQueue<Reference<V>> queue = new ReferenceQueue<Reference<V>>();
public LRUCache(int capacity) {
this.capacity = capacity;
map = new LinkedHashMap<K,Reference<V>>(capacity,1f,true){
@Override
protected boolean removeEldestEntry(Map.Entry<K,Reference<V>> eldest) {
return this.size() > LRUCache.this.capacity;
}
};
}
public V put(K key,V value) {
lock.lock();
try {
map.put(key, new SoftReference(value,queue));
return value;
}finally {
lock.unlock();
}
}
public V get(K key) {
lock.lock();
try {
queue.poll();
return map.get(key).get();
}finally {
lock.unlock();
}
}
public void remove(K key) {
lock.lock();
try {
map.remove(key);
}finally {
lock.unlock();
}
}
}
]]>
先从ASCII说�v。ASCII是用来表�C����文字�W�的一�U�编码规范,每个ASCII字符占用1个字节(8bits�Q?nbsp;
因此�Q�ASCII�~�码可以表示的最大字�W�数�?56�Q�其实英文字�W��ƈ没有那么多,一般只用前128个(最高位�?�Q�,其中包括了控制字�W�、数字、大���写字母和其他一些符�?nbsp;�?br />
而最高位�?的另128个字�W�被成�ؓ“扩展ASCII”�Q�一般用来存放英文的制表�W�、部分音标字�W�等�{�的一些其他符�?nbsp;
�q�种字符�~�码规范昄���用来处理英文没有什么问�?nbsp;。(实际上也可以用来处理法文、�d文等一些其他的西欧字符�Q�但是不能和英文通用�Q�,但是面对中文、阿拉伯文之�c�d��杂的文字�Q?55个字�W�显然不够用
于是�Q�各个国家纷�U�制定了自己的文字编码规范,其中中文的文字编码规范叫�?#8220;GB2312-80”�Q�它是和ASCII兼容的一�U�编码规范,其实���是利用扩展ASCII没有真正标准化这一点,把一个中文字�W�用两个扩展ASCII字符来表�C��?nbsp;
但是�q�个�Ҏ��有问题,最大的问题���是�Q�中文文字没有真正属于自��q���~�码�Q�因为扩展ASCII码虽然没有真正的标准化,但是PC里的ASCII码还是有一个事实标准的�Q�存攄���英文制表�W�)�Q�所以很多��Y件利用这些符��h��画表根{��这��L��软�g用到中文�pȝ��中,�q�些表格�W�就会被误认作中文字�Q�破坏版面。而且�Q�统计中英文混合字符串中的字敎ͼ�也是比较复杂的,我们必须判断一个ASCII码是否扩展,以及它的下一个ASCII是否扩展�Q�然后才“�?#8221;那可能是一个中文字 �?br />
��M��当时处理中文是很痛苦的。而更痛苦的是GB2312是国家标准,台湾当时有一个Big5�~�码标准�Q�很多编码和GB是相同的�Q�所�?#8230;…�Q�嘿�ѝ�?nbsp;
�q�时候,我们���q��道,要真正解决中文问题,不能从扩展ASCII的角度入手,也不能仅靠中国一家来解决。而必���L��一个全新的�~�码�pȝ���Q�这个系�l�要可以���中文、英文、法文、�d�?#8230;…�{�等所有的文字�l�一��h��考虑�Q��ؓ每个文字都分配一个单独的�~�码�Q�这��h��不会有上面那�U�现象出现�?nbsp;
于是�Q�Unicode诞生了�?nbsp;
Unicode有两套标准,一套叫UCS-2(Unicode-16)�Q�用2个字节�ؓ字符�~�码�Q�另一套叫UCS-4(Unicode-32)�Q�用4个字节�ؓ字符�~�码�?nbsp;
以目前常用的UCS-2��Z���Q�它可以表示的字�W�数�?^16=65535�Q�基本上可以容纳所有的�Ƨ美字符和绝大部分的亚洲字符 �?br />
UTF-8的问题后面会提到 �?br />
在Unicode里,所有的字符被一视同仁。汉字不再���?#8220;两个扩展ASCII”�Q�而是使用“1个Unicode”�Q�注意,现在的汉字是“一个字�W?#8221;了,于是�Q�拆字、统计字数这些问题也���p��然而然的解决了 �?br />
但是�Q�这个世界不是理想的�Q�不可能在一夜之间所有的�pȝ��都��用Unicode来处理字�W�,所以Unicode在诞生之日,���必��考虑一个严�ȝ��问题�Q�和ASCII字符集之间的不兼定w��题�?nbsp;
我们知道�Q�ASCII字符是单个字节的�Q�比�?#8220;A”的ASCII�?5。而Unicode是双字节的,比如“A”的Unicode�?065�Q�这���造成了一个非常大的问题:以前处理ASCII的那套机制不能被用来处理Unicode�?nbsp;�?br />
另一个更加严重的问题是,C语言使用'\0'作�ؓ字符串结���,而Unicode里恰恰有很多字符都有一个字节�ؓ0�Q�这样一来,C语言的字�W�串函数���无法正常处理Unicode�Q�除非把世界上所有用C写的�E�序以及他们所用的函数库全部换�?nbsp;�?br />
于是�Q�比Unicode更伟大的东东诞生了,之所以说它更伟大是因为它让Unicode不再存在于纸上,而是真实的存在于我们大家的电脑中。那���是�Q�UTF �?br />
UTF= UCS Transformation Format UCS转换格式
它是���Unicode�~�码规则和计���机的实际编码对应�v来的一个规则。现在流行的UTF�?�U�:UTF-8和UTF-16 �?br />
其中UTF-16和上面提到的Unicode本��n的编码规范是一致的�Q�这里不多说了。而UTF-8不同�Q�它定义了一�U?#8220;区间规则”�Q�这�U�规则可以和ASCII�~�码保持最大程度的兼容 �?br />
UTF-8有点�c�M��于Haffman�~�码�Q�它���Unicode�~�码�?0000000-0000007F的字�W�,用单个字节来表示�Q?nbsp;
00000080-000007FF的字�W�用两个字节表示
00000800-0000FFFF的字�W�用3字节表示
因�ؓ目前为止Unicode-16规范没有指定FFFF以上的字�W�,所以UTF-8最多是使用3个字节来表示一个字�W�。但理论上来��_��UTF-8最多需要用6字节表示一个字�W��?nbsp;
在UTF-8里,英文字符仍然跟ASCII�~�码一��P��因此原先的函数库可以�l�箋使用。而中文的�~�码范围是在0080-07FF之间�Q�因此是2个字节表�C�(但这两个字节和GB�~�码的两个字节是不同的)�Q�用专门的Unicode处理�c�d��以对UTF�~�码�q�行处理�?nbsp;
下面说说中文的问题�?nbsp;
�׃��历史的原因,在Unicode之前�Q�一共存在过3套中文编码标准�?nbsp;
GB2312-80�Q�是中国大陆使用的国家标准,其中一��q��码了6763个常用简体汉字。Big5�Q�是台湾使用的编码标准,�~�码了台湾��用的�J�体汉字�Q�大概有8千多个。HKSCS�Q�是中国香港使用的编码标准,字体也是�J�体�Q�但跟Big5有所不同�?nbsp;
�q?套编码标准都采用了两个扩展ASCII的方法,因此�Q�几套编码互不兼容,而且�~�码区间也各有不�?nbsp;
因�ؓ其不兼容性,在同一个系�l�中同时昄���GB和Big5基本上是不可能的。当时的南极星、RichWin�{�等软�g�Q�在自动识别中文�~�码、自动显�C�正���编码方面都做了很多努力 �?br />
他们用了怎样的技术我��׃��得而知了,我知道好像南极星曄���以同屏显�C�繁���中文为卖炏V�?nbsp;
后来�Q�由于各斚w��的原因,国际上又制定了针对中文的�l�一字符集GBK和GB18030�Q�其中GBK已经在Windows、Linux�{�多�U�操作系�l�中被实现�?nbsp;
GBK兼容GB2312�Q��ƈ增加了大量不常用汉字�Q�还加入了几乎所有的Big5中的�J�体汉字。但是GBK中的�J�体汉字和Big5中的几乎不兼宏V�?nbsp;
GB18030相当于是GBK的超集,比GBK包含的字�W�更多。据我所知目前还没有操作�pȝ��直接支持GB18030�?nbsp;
谈谈Unicode�~�码�Q�简要解释UCS、UTF、BMP、BOM�{�名�?nbsp;
�q�是一���程序员写给�E�序员的���味�ȝ��。所谓趣��x��指可以比较轻村֜�了解一些原来不清楚的概念,增进知识�Q�类��g��打RPG游戏的升�U�。整理这���文章的动机是两个问题:
问题一�Q?nbsp;
使用Windows��C��本的“另存�?#8221;�Q�可以在GBK、Unicode、Unicode big endian和UTF-8�q�几�U�编码方式间�怺�转换。同��h��txt文�g�Q�Windows是怎样识别�~�码方式的呢�Q?br />
我很早前���发现Unicode、Unicode big endian和UTF-8�~�码的txt文�g的开头会多出几个字节�Q�分别是FF、FE�Q�Unicode�Q?FE、FF�Q�Unicode big endian�Q?EF、BB、BF�Q�UTF-8�Q�。但�q�些标记是基于什么标准呢�Q?br />
问题二:
最�q�在�|�上看到一个ConvertUTF.c�Q�实��C��UTF-32、UTF-16和UTF-8�q�三�U�编码方式的�怺�转换。对于Unicode(UCS2)、GBK、UTF-8�q�些�~�码方式�Q�我原来��׃��解。但�q�个�E�序让我有些�p�涂�Q�想不�v来UTF-16和UCS2有什么关�p�R�?nbsp;
查了查相兌���料,�ȝ�����这些问题弄清楚了,��带也了解了一些Unicode的细节。写成一���文章,送给有过�c�M��疑问的朋友。本文在写作时尽量做到通俗易懂�Q�但要求读者知道什么是字节�Q�什么是十六�q�制�?br />
0、big endian和little endian
big endian和little endian是CPU处理多字节数的不同方式。例�?#8220;�?#8221;字的Unicode�~�码�?C49。那么写到文仉����Ӟ���I�竟是将6C写在前面�Q�还是将49写在前面�Q�如果将6C写在前面�Q�就是big endian。还是将49写在前面�Q�就是little endian�?br />
“endian”�q�个词出自《格列佛游记》。小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开�q�是从小�?Little-Endian)敲开�Q�由此曾发生�q�六�ơ叛乱,其中一个皇帝送了命,另一个丢了王位�?br />
我们一般将endian���译�?#8220;字节�?#8221;�Q�将big endian和little endian�U�C��“大尾”�?#8220;���尾”�?br />
1、字�W�编码、内码,��带介绍汉字�~�码
字符必须�~�码后才能被计算机处理。计���机使用的缺省编码方式就是计���机的内码。早期的计算��Z���?位的ASCII�~�码�Q��ؓ了处理汉字,�E�序员设计了用于���体中文的GB2312和用于繁体中文的big5�?br />
GB2312(1980�q?一共收录了7445个字�W�,包括6763个汉字和682个其它符受���汉字区的内码范围高字节从B0-F7�Q�低字节从A1-FE�Q�占用的码位�?2*94=6768。其中有5个空位是D7FA-D7FE�?br />
GB2312支持的汉字太����?995�q�的汉字扩展规范GBK1.0收录�?1886个符��P��它分为汉字区和图形符号区。汉字区包括21003个字�W��?000�q�的GB18030是取代GBK1.0的正式国家标准。该标准收录�?7484个汉字,同时�q�收录了藏文、蒙文、维向ְ�文等主要的少数民族文字。现在的PC�q�_��必须支持GB18030�Q�对嵌入式��品暂不作要求。所以手机、MP3一般只支持GB2312�?br />
从ASCII、GB2312、GBK到GB18030�Q�这些编码方法是向下兼容的,卛_��一个字�W�在�q�些�Ҏ��中��L��有相同的�~�码�Q�后面的标准支持更多的字�W�。在�q�些�~�码中,英文和中文可以统一地处理。区分中文编码的�Ҏ��是高字节的最高位不�ؓ0。按照程序员的称��|��GB2312、GBK到GB18030都属于双字节字符�?nbsp;(DBCS)�?br />
有的中文Windows的缺省内码还是GBK�Q�可以通过GB18030升��包升�U�到GB18030。不�q�GB18030相对GBK增加的字�W�,普通�h是很隄���到的�Q�通常我们�q�是用GBK指代中文Windows内码�?br />
�q�里�q�有一些细节:
GB2312的原文还是区位码�Q�从��Z��码到内码�Q�需要在高字节和低字节上分别加上A0�?br />
在DBCS中,GB内码的存储格式始�l�是big endian�Q�即高位在前�?br />
GB2312的两个字节的最高位都是1。但�W�合�q�个条�g的码位只�?28*128=16384个。所以GBK和GB18030的低字节最高位都可能不�?。不�q�这不媄响DBCS字符���的解析�Q�在��d��DBCS字符���时�Q�只要遇到高位�ؓ1的字节,���可以将下两个字节作��Z��个双字节�~�码�Q�而不用管低字节的高位是什么�?br />
2、Unicode、UCS和UTF
前面提到从ASCII、GB2312、GBK到GB18030的编码方法是向下兼容的。而Unicode只与ASCII兼容�Q�更准确地说�Q�是与ISO-8859-1兼容�Q�,与GB码不兼容。例�?#8220;�?#8221;字的Unicode�~�码�?C49�Q�而GB码是BABA�?br />
Unicode也是一�U�字�W�编码方法,不过它是由国际组�l�设计,可以容纳全世界所有语�a�文字的编码方案。Unicode的学名是"Universal Multiple-Octet Coded Character Set"�Q�简�U�CؓUCS。UCS可以看作�?Unicode Character Set"的羃写�?br />
�Ҏ���l�基癄���全书(http://zh.wikipedia.org/wiki/)的记载:历史上存在两个试囄���立设计Unicode的组�l�,卛_��际标准化�l�织�Q�ISO�Q�和一个��Y件制造商的协会(unicode.org�Q�。ISO开发了ISO 10646��目�Q�Unicode协会开发了Unicode��目�?br />
�?991�q�前后,双方都认识到世界不需要两个不兼容的字�W�集。于是它们开始合�q�双方的工作成果�Q��ƈ为创立一个单一�~�码表而协同工作。从Unicode2.0开始,Unicode��目采用了与ISO 10646-1相同的字库和字码�?br />
目前两个��目仍都存在�Q��ƈ独立地公布各自的标准。Unicode协会现在的最新版本是2005�q�的Unicode 4.1.0。ISO的最新标准是10646-3:2003�?br />
UCS规定了怎么用多个字节表�C�各�U�文字。怎样传输�q�些�~�码�Q�是由UTF(UCS Transformation Format)规范规定的,常见的UTF规范包括UTF-8、UTF-7、UTF-16�?br />
IETF的RFC2781和RFC3629以RFC的一贯风��|��清晰、明快又不失严�}地描�q�C��UTF-16和UTF-8的编码方法。我��L����C��得IETF是Internet Engineering Task Force的羃写。但IETF负责�l�护的RFC是Internet上一切规范的基础�?br />
3、UCS-2、UCS-4、BMP
UCS有两�U�格式:UCS-2和UCS-4。顾名思义�Q�UCS-2���是用两个字节编码,UCS-4���是�?个字节(实际上只用了31位,最高位必须�?�Q�编码。下面让我们做一些简单的数学游戏�Q?br />
UCS-2�?^16=65536个码位,UCS-4�?^31=2147483648个码位�?br />
UCS-4�Ҏ��最高位�?的最高字节分�?^7=128个group。每个group再根据次高字节分�?56个plane。每个plane�Ҏ���W?个字节分�?56�?nbsp;(rows)�Q�每行包�?56个cells。当然同一行的cells只是最后一个字节不同,其余都相同�?br />
group 0的plane 0被称作Basic Multilingual Plane, 即BMP。或者说UCS-4中,高两个字节�ؓ0的码位被�U�C��BMP�?br />
���UCS-4的BMP��L��前面的两个零字节���得��C��UCS-2。在UCS-2的两个字节前加上两个零字节,���得��C��UCS-4的BMP。而目前的UCS-4规范中还没有��M��字符被分配在BMP之外�?br />
4、UTF�~�码
UTF-8���是�?位�ؓ单元对UCS�q�行�~�码。从UCS-2到UTF-8的编码方式如下:
UCS-2�~�码(16�q�制) UTF-8 字节��?二进�?
0000 - 007F 0xxxxxxx
0080 - 07FF 110xxxxx 10xxxxxx
0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
例如“�?#8221;字的Unicode�~�码�?C49�?C49�?800-FFFF之间�Q�所以肯定要�?字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是�Q?110 110001 001001�Q?nbsp;用这个比�Ҏ��依次代替模板中的x�Q�得刎ͼ�11100110 10110001 10001001�Q�即E6 B1 89�?br />
读者可以用��C��本测试一下我们的�~�码是否正确�?br />
UTF-16�?6位�ؓ单元对UCS�q�行�~�码。对于小�?x10000的UCS码,UTF-16�~�码���q��于UCS码对应的16位无�W�号整数。对于不���于0x10000的UCS码,定义了一个算法。不�q�由于实际��用的UCS2�Q�或者UCS4的BMP必然���于0x10000�Q�所以就目前而言�Q�可以认为UTF-16和UCS-2基本相同。但UCS-2只是一个编码方案,UTF-16却要用于实际的传输,所以就不得不考虑字节序的问题�?br />
5、UTF的字节序和BOM
UTF-8以字节�ؓ�~�码单元�Q�没有字节序的问题。UTF-16以两个字节�ؓ�~�码单元�Q�在解释一个UTF-16文本前,首先要弄清楚每个�~�码单元的字节序。例如收��C���?#8220;�?#8221;的Unicode�~�码�?94E�Q?#8220;�?#8221;的Unicode�~�码�?E59。如果我们收到UTF-16字节��?#8220;594E”�Q�那么这�?#8220;�?#8221;�q�是“�?#8221;�Q?br />
Unicode规范中推荐的标记字节��序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。BOM是一个有点小聪明的想法:
在UCS�~�码中有一个叫�?ZERO WIDTH NO-BREAK SPACE"的字�W�,它的�~�码是FEFF。而FFFE在UCS中是不存在的字符�Q�所以不应该出现在实际传输中。UCS规范�����我们在传输字节流前,先传输字�W?ZERO WIDTH NO-BREAK SPACE"�?br />
�q�样如果接收者收到FEFF�Q�就表明�q�个字节���是Big-Endian的;如果收到FFFE�Q�就表明�q�个字节���是Little-Endian的。因此字�W?ZERO WIDTH NO-BREAK SPACE"又被�U�C��BOM�?br />
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字�W?ZERO WIDTH NO-BREAK SPACE"的UTF-8�~�码是EF BB BF�Q�读者可以用我们前面介绍的编码方法验证一下)。所以如果接收者收��C��EF BB BF开头的字节���,���q��道这是UTF-8�~�码了�?br />
Windows���是使用BOM来标记文本文件的�~�码方式的�?br />
6、进一步的参考资�?br /> 本文主要参考的资料�?nbsp;"Short overview of ISO-IEC 10646 and Unicode" (http://www.nada.kth.se/i18n/ucs/unicode-iso10646-oview.html)�?br />
我还找了两篇看上��M��错的资料�Q�不�q�因为我开始的疑问都找��C���{�案�Q�所以就没有看:
"Understanding Unicode A general introduction to the Unicode Standard" (http://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&item_id=IWS-Chapter04a)
"Character set encoding basics Understanding character set encodings and legacy encodings" (http://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&item_id=IWS-Chapter03)
]]>
1.AJAX中的跨站点脚�?/font>
前几个月�Q��h们发��C��多种跨站点的脚本��d��。在此类��d��中,受害者的包含信息的浏览器上会�q�行来自特定�|�站的恶意JAVA脚本代码�? Yamanner蠕虫���是一个最�q�的范例�Q�它利用Yahoo邮�g的AJAX调用中的跨站点脚本机会来��d��受害者。另一个近期的范例���是Samy蠕虫�Q�它�? 用MySpace.com的跨站点脚本漏洞来攻凅R��AJAX在客��L��上运行,它允讔R��误书写的脚本被攻击者利用。攻击者能够编写恶意链接来哄骗那些没有�? 备的用户�Q�让他们用浏览器去访问特定的�|�页。传�l�应用中也存在这��L����q���Q�但AJAX�l�它��d��了更多可能的漏洞�?font color="#ff0000">例子�Q?Yamanner蠕虫利用了Yahoo Mail的AJAX的跨站脚本漏�z�,Samy蠕虫利用了MySpace.com的跨站脚本漏�z��?/font>
2.XML中毒
很多Web2.0应用中,XML传输在服务器和浏览器之间往复。网�l�应用接收来自AJAX客户端的XML块。这XML块很可能染毒。多�ơ将递归 负蝲应用��C�出相似的XML节点,�q�样的技术还�q�不普遍。如果机器的处理能力较弱�Q�这���导致服务器拒绝服务。很多攻击者还制作�l�构错误的XML文档�Q�这�? 文档会扰乱服务器上所使用的依赖剖析机制的逻辑。服务器端的剖析机制有两�U�类型,它们是SAX和DOM。网�l�服务也使用相同的攻��d��量,�q�是因�ؓ�|�络服务 接收SOAP消息�Q�而SOAP���是XML消息。在应用层大范围��C��用XMLs使攻击者有更多的机会利用这个新的攻��d��量�?/font>
XML外部实体参照是能被攻击者伪造的一个XML的属性。这会����d��者能够利用�h意的文�g或者TCP�q�接的缺陗���XML schema中毒是另一个XML中毒的攻��d��量,它能够改变执行的���程。这个漏�z�能帮助��d��者获得机密信息�?font color="#ff0000">��d��者可以通过复制节点�q�行DOS��d���Q�或者生成不合法的XML��D��服务器端逻辑的中断。攻击者也可以操纵外部实体�Q�导致打开��M��文�g或TCP�q�接端口。XML数据定义的中毒也可以��D���q�行���程的改变,助攻击者获取机密信息�?/font>
3.恶意AJAX代码的执�?/font>
AJAX调用非常不易察觉�Q�终端用��h��法确定浏览器是否正在用XMLHTTP��h��对象发出无记载的调用。浏览器发出AJAX调用�l��Q意网站的�? 候,该网站会�Ҏ��个请求回应以cookies。这���导致出现泄漏的潜在可能性。例如,�U�翰已经登陆了他的银行,�q�且通过了服务器认证。完成认证过�E�后�Q�他 会得��C��个会�? cookie。银行的��面中包含了很多关键信息。现在,他去���览器他�|�页�Q��ƈ同时仍然保持银行账户的登陆状态。他可能会刚好访问一个攻击者的�|�页�Q�在�q�个 �|�页上攻击者写了不易被察觉的AJAX 代码�Q�这个代码不用经�q�约���的同意�Q�就能够发出后台调用�l�约���的银行�|�页�Q�因而能够从银行��面取得关键信息�q�且把这些信息发送到��d��者的�|�站。这���导致机 密信息的泄漏甚至引发安全�H�破�?font color="#ff0000">AJAX �~�码可以在不为用��h��知的情�Ş下运行,假如用户先登录一个机密网站,机密�|�站�q�回一个会话cookie�Q�然后用户在没有退出机密网站的情�Ş下,讉K����d���? 的网站,��d��者网��上的AJAX�~�码可以(通过�q�个会话cookie?)去访问机密网站上的网��,从而窃取用��L��机密信息�?注:�q�里的解释有点含�p�,�? ��Z���Ԍ�����览器不会把一个网站的会话cookie传给另外一个网站的�Q�即文中的这�?#8220;When the browser makes an AJAX call to any Web site it replays cookies for each request. ”�Q�不完全�?
4.RSS/Atom 注入
�q�是一��Ҏ��的web2.0��d��。RSS反馈是�h们在门户�|�站或者网�l�应用中�׃�n信息的常用手�D�c��网�l�应用接受这些反馈然后发送给客户端的���览器。�h们可 以在该RSS反馈中插入文本的JavaScript来��生对用户���览器的��d��。访问特定网站的�l�端用户加蝲了带有该RSS反馈的网��,�q�个脚本 ��׃���q�行��h��——它能够往用户的电脑中安装软�g或者窃取cookies信息。这���是一个致命的客户端攻凅R��更�p�糕的是�Q�它可以变异。随着RSS和ATOM 反馈成�ؓ�|�络应用中整合的�l��g�Q�在服务器端���数据发布给�l�端用户之前�Q�过滤特定字�W�是非常必要的�?font color="#ff0000">��d��者可以在RSS feeds里注入Javascript脚本�Q�如果服务器端没有过滤掉�q�些脚本的话�Q�在���览器端会造成问题�?/font>
5.WSDL扫描和enumeration
WSDL(�|�络服务界定语言)是网�l�服务的一个接口。该文�g提供了技术,开放方法,创新形式�{�等的关键信息。这是非常敏感信息,而且能够帮助�? 们决定利用什么弱�Ҏ����d��。如果将不必要的功能或者方法一直开着�Q�这会�ؓ�|�络服务造成潜在的灾难。保护WSDL文�g或者限定对其的讉K��是非帔R��要的。在�? 际情况中�Q�很有可能找��C��些��用WSDL扫描的一些漏�z��?font color="#ff0000">WSDL提供了Web服务所用的技术,以及外露的方法,调用的模式等信息。假如Web服务对不必要的方法没有禁止的话,��d��者可以通过WSDL扫描扑ֈ�潜在的攻�ȝ���?/font>
6.AJAX常规�E�序中客��L��的确�?/strong>
��Z��web2.0的应用��用AJAX常规�E�序来在客户端上�q�行很多操作�Q�比如客��L��数据�c�d��的确认,内容���查,数据域等�{�。正常情况下�Q�服务端 也应该备份这些客��L�����查信息。大部分开发者都没有�q�么�?他们�q�样做的理由是,他们假设�q�样的确认是由AJAX常规�E�序来负责的。避开��Z��AJAX的确 认和直接发送POST或者GET��h���l�那些应用——这些应用是诸如SQL注入,LDAP注入�{�类随确认进入的��d��主要来源�Q�它们能够攻�ȝ���l�应用的关键�? 源——都是可以做到的。这都增加了能够为攻击者所利用的潜在攻��d��量的数量�?font color="#ff0000">假如开发�h员只依赖客户端验证,不在服务器端重新验证的话�Q�会��D��SQL注入�Q�LDAP注入�{�等�?/font>
7.�|�络服务路由问题
�|�络服务安全协议包括WS-Routing服务。WS-Routing允许SOAP消息在互联网上各�U�各样不同的节点中的特别序列中传输。通常 加密的信息在�q�些节点来回传送。交互的节点中的��L��一个被��d��都将致����d��者能够访问到在两个端点之间传输的SOAP消息。这���造成SOAP消息的严重的 安全泄漏。随着�|�络应用开始被�|�络服务框架所采用�Q�攻击者们开始�{而利用这些新协议和新的攻��d��量�?font color="#ff0000">Web服务安全协议使用WS-Routing服务�Q�假如�Q何中转站被攻占,SOAP消息可以被截莗��?/font>
8.SOAP消息的参数操�?/font>
�|�络服务接收信息和来自SOAP消息的变量。修改这些变量是很可能的。例如,“10”是SOAP消息中多个节点中的一个。攻击者可以修改点�Q��ƈ 且尝试不同种的注入攻几Z��—比如,SQL,LDAP,XPATH,命��o行解释器——�ƈ且探索能被他用来掌握及其内部信息的攻��d��量。网�l�服务代码中错误�? 或者不够完备的输入���认使网�l�服务应用易于发生泄�?�q�是一个目标指向网�l�服务所带的�|�络应用的一��Ҏ��的攻��d��量�?font color="#ff0000">�c�M��于SQL注入�Q�假如对SOAP消息里节点的数据不做验证的话�?/font>
9.SOAP消息中的XPATH注入
XPATH是一�U�用来查询XML文档的语�a��Q�它跟SQL语句很类�?我们提供某些信息(参数)然后从数据库中得到查询结果。很多语�a�都支�? XPATH 解析的功能。网�l�应用接收大型XML文档�Q�很多时候这些应用从�l�端用户和XPATH语句中取得输入量。这些代码的�D�落对XPATH注入没有什么防御能力�? 如果XPATH执行成功�Q�攻击者能够绕�q�认证机制或者造成机密信息的一些损失。现在�h们只知道很少部分的能够被��d��者利用的XPATH的漏�z�。阻止这个攻 ��d��量的唯一�Ҏ�����是在给XPATH语句传递变量值的时候提供适当的输入确认�?font color="#ff0000">�c�M��于SQL注入�Q�假如对数据不做验证而直接做XPATH查询的话�?/font>
10. RIA瘦客��L��二进制的伪�?/strong>
丰富�|�络应用(RIA)使用非常丰富的UI要素比如Flash,ActiveX控�g或者Applets�Q�它使用�q�些要素作�ؓ�|�络应用的基本接 口。这个框架存在几个安全问题。其中最主要的一个就是关于会话管理。它是在���览器中�q�行的,�q�且�׃�n相同的会话。同�Ӟ���׃��客户端将下蝲整个二进制元件到 自己的主机,��d��者就可以颠倒工�E�的那个二进制文件�ƈ且反�~�译代码。把�q�些二进制串打包�q�绕�q�一些包含在代码中的认证逻辑是有可能实现的。这�? WEB2.0框架下的另一个有���的��d��向量�?font color="#ff0000">因�ؓRich Internet Applications的组件是下蝲到浏览器本地的,��d��者可以对二进制文件进行逆向工程�Q�反�~�译�~�码�Q�通过改动文�g�Q�蟩�q�认证逻辑 �?/font>
�l�论
AJAX,RIA以及�|�络服务是WEB2.0应用�I�间的三��w��要的技术向量。这些技术很有前景,它们带给桌面新的�E�式�Q�加��Z���|�络应用的整体效 率和效用。随着�q�些新技术而来的是新的安全问题�Q�忽略这些问题将会导致整个世界发生巨大的��N��。本文中�Q�我们只讨论�?0�U�攻凅R��但是实际上�q�有很多其他 的攻��d��量。对�q�些新的��d��向量的最好的防�M�Ҏ��是增加WEB2.0的安全意识,提高代码操作的安全性以及配�|�的安全�?/font>
]]>
匚w��中文字符的正则表辑ּ��Q?[\u4e00-\u9fa5]
匚w��双字节字�W?包括汉字在内)�Q�[^\x00-\xff]
应用�Q�计���字�W�串的长度(一个双字节字符长度�?�Q�ASCII字符�?�Q?br /> String.prototype.len=function(){return this.replace([^\x00-\xff]/g,"aa").length;}
匚w���I����的正则表辑ּ��Q�\n[\s| ]*\r
匚w��HTML标记的正则表辑ּ��Q?<(.*)>.*<\/\1>|<(.*) \/>/
匚w��首尾�I�格的正则表辑ּ��Q?^\s*)|(\s*$)
应用�Q�javascript中没有像vbscript那样的trim函数�Q�我们就可以利用�q�个表达式来实现�Q�如下:
String.prototype.trim = function()
{ return this.replace(/(^\s*)|(\s*$)/g, "");
} 利用正则表达式分解和转换IP地址�Q?br /> 下面是利用正则表辑ּ�匚w��IP地址�Q��ƈ���IP地址转换成对应数值的Javascript�E�序�Q?br /> function IP2V(ip)
{
re=/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //匚w��IP地址的正则表辑ּ�
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1
}
else
{
throw new Error("Not a valid IP address!")
}
}
不过上面的程序如果不用正则表辑ּ��Q�而直接用split函数来分解可能更���单,�E�序如下�Q?/p>
var ip="10.100.20.168"
ip=ip.split(".")
alert("IP值是�Q?+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1))
匚w��Email地址的正则表辑ּ��Q�\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匚w���|�址URL的正则表辑ּ��Q�http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
利用正则表达式限制网��表单里的文本框输入内容�Q?/p>
用正则表辑ּ�限制只能输入中文�Q�onkeyup="value=value.replace(/[^\u4E00-\u9FA5]/g,'')"
onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\u4E00-\u9FA5]/g,''))"
用正则表辑ּ�限制只能输入全角字符�Q?onkeyup="value=value.replace(/[^\uFF00-\uFFFF]/g,'')"
onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\uFF00-\uFFFF]/g,''))"
用正则表辑ּ�限制只能输入数字�Q�onkeyup="value=value.replace(/
[^\d]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"
用正则表辑ּ�限制只能输入数字和英文:onkeyup="value=value.replace(/
[\W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"
]]>
web��目�Q�分析不了腾讯是怎么加密�Q�但我可以作��Z���U�代理,如图�Q?br />
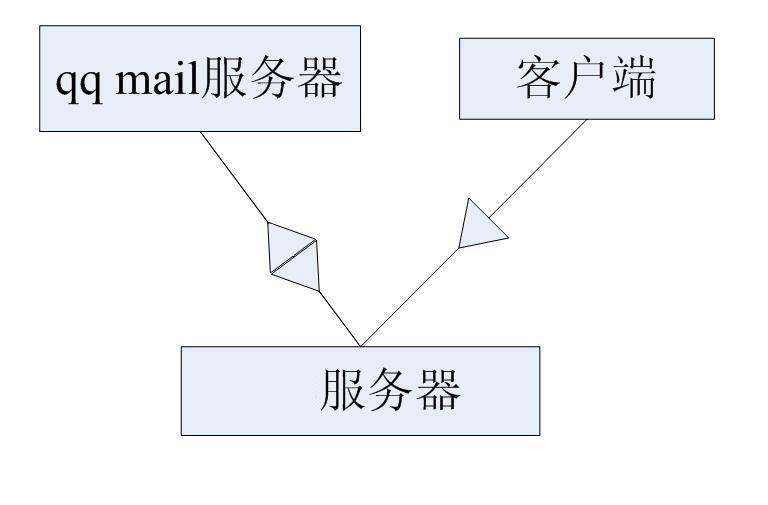
要采用上面的方式来获取好友,大致可以分�ؓ一下几个步骤:
1.首先制作一个login.jsp��面�Q�代码直接从腾讯邮�g的登陆页面中复制�q�来�Q�把��面交互的改成我们自��q��服务�?
(1)获取验证码的地址�Q?a >http://ptlogin2.qq.com/getimage?aid=23000101 后面带个随机敎ͼ���Z��防止���览器缓存�?br /> (2)当用戯���入用户名 密码 和验证码�Q�点登陆的时候,也让用户提交到我们的服务器来�?br /> 2. 我这里写了一个servlet�Q�该�c�L��从qq邮�g服务器中获取验证码的�Q�如何获取呢�Q�我采用的是
httpclient4.0-beta2 包,该包是apache�?Apache HttpComponents project�Q�是个开源的�Q�具体��用和了解可以讉K���Q?br /> http://hc.apache.org/httpcomponents-client/index.html�Q�(该项目功能很强大�Q?br /> 在获取了验证码之后,qq服务器他在cookie中写了一个verifysession�Q�当你点登陆的时�?br /> 客户端校验需要�?br /> 3. 把客��L��提交�q�来的信息我们去��h��qq服务器,�q�样��׃��登陆成功了,服务器会�q�回带sid的html代码�Q�解析出来sid的�?br /> 然后讉K��http://m11.mail.qq.com/cgi-bin/addr_listall?sid=" +sid+"&sorttype=null&category=common�Q�就获取到qq中好友分�l�,以及每一个组的链接地址
4.��h��每一个链�? ���可以得到每一�l�的好友�?
上面我只是写了实现的思�\�Q�有兴趣的可以跟我联�p�,具体代码可以分��n �l�大�?。。�?nbsp; qq�Q?53041869
]]>
开源的opencsv�Q?用来操作csv�Q�这个还是不错的�?nbsp; 要看介绍�q�是�ȝ��官方的文档吧�Q�下了,感觉�q�不错的~ 一些��用的东东上面说的很清楚,我也懒的复制了,�q�个�l�自己标注下吧。�?hoho
]]>
 String urlStr = "http://xxx.xxx.xx.xx"; URL url = new URL(urlStr); URLConnection conn = url.openConnection(); conn.connect(); InputStream is = conn.getInputStream(); //得到输入的编码器�Q�将文�g���进行jpg格式�~�码 JPEGImageDecoder decoder = JPEGCodec.createJPEGDecoder(is); //得到�~�码后的囄���对象 BufferedImage image = decoder.decodeAsBufferedImage(); //得到输出的编码器 OutputStream output = response.getOutputStream(); JPEGImageEncoder encoder = JPEGCodec.createJPEGEncoder(output); encoder.encode(image);//对图片进行输出编�?/span> is.close();//关闭文�g��?/span> output.close();
String urlStr = "http://xxx.xxx.xx.xx"; URL url = new URL(urlStr); URLConnection conn = url.openConnection(); conn.connect(); InputStream is = conn.getInputStream(); //得到输入的编码器�Q�将文�g���进行jpg格式�~�码 JPEGImageDecoder decoder = JPEGCodec.createJPEGDecoder(is); //得到�~�码后的囄���对象 BufferedImage image = decoder.decodeAsBufferedImage(); //得到输出的编码器 OutputStream output = response.getOutputStream(); JPEGImageEncoder encoder = JPEGCodec.createJPEGEncoder(output); encoder.encode(image);//对图片进行输出编�?/span> is.close();//关闭文�g��?/span> output.close();]]>