?
2006年7月9日 星期日 陰雨
昨天晚上看了前言和第一章.跟很過書一樣,主要還是在推銷自己的東西啦.
在推銷的同時也總體介紹了一下java的一些特性.
2006年7月10日 星期一 陰雨
p15 第3行 java-version 應(yīng)該改為java -version 書中少了空格.
p25 第7和第8行的命令要注意大小寫.
javac ImageViewer.java 中的"I"不能寫成i ,V不能寫成v .
java ImageViewer 中的"I"不能寫成i ,V不能寫成v .
否則會出現(xiàn)錯誤

改過來以后會顯示:

顯示一個窗口程序可以顯示gif格式的圖片.
結(jié)束程序后出現(xiàn)下面的東東:
C:\corejavabook\v1\v1ch2\ImageViewer>
2006年7月13日 星期四 晴
昨天健身腿練得太猛。在床上躺了一天。下樓梯都痛。考試停了一個星期沒練就不適應(yīng)了。哎。
轉(zhuǎn)入正題:p35 中有個例子不是很明白:
"例如,0.125可以表示成Ox1.0p-3.在十六進(jìn)制表示法中,使用p表示指數(shù),而不是e"
0.125是十進(jìn)制數(shù)的話,它的十六進(jìn)制數(shù)應(yīng)該是0.2才對啊.p表示以16為底,寫成科學(xué)記數(shù)法應(yīng)該是
Ox2p-1才對吧?難道是應(yīng)為Ox1.0p-3中只有后面的-3是十六進(jìn)制數(shù),1.0是2進(jìn)制數(shù)而且是以2為底?
問題解決:Ox1.0和p后面的-3是用十六進(jìn)制表示的,底數(shù)默認(rèn)為2.
2006年7月14日 星期五 晴
p42 字條警告處的例子"例如,1<<35與1<<3或8是相同的." 我寫了個驗(yàn)證程序,怎么輸出結(jié)果不同?
public class Test1
{
public static void main(String[] args)
{
int i=1;
int b=0;
b=i<<35;
System.out.println("i<<35"+b);
b=i<<3;
System.out.println("i<<3"+b);
b=i<<8;
System.out.println("i<<8"+b);
b=i<<29;
System.out.println("i<<29"+b);
}
}
輸出結(jié)果為
i<<358
i<<38
i<<8256
i<<29536870912
解答:
原來是1<<35==1<<3==8的意思。
驗(yàn)證程序應(yīng)該在輸出串后面加個等號
public class Test1
{
public static void main(String[] args)
{
int i=1;
int b=0;
b=i<<35;
System.out.println("i<<35"+b);
b=i<<3;
System.out.println("i<<3="+b);
b=i<<8;
System.out.println("i<<8="+b);
b=i<<29;
System.out.println("i<<29="+b);
}
}
2006年7月16日 星期日 雨
core java p33"注意"字條處:System.out不是有個 print方法么?在apidocument里怎么沒看見?

 core java 書上說有的。難道是api版本問題??
core java 書上說有的。難道是api版本問題??
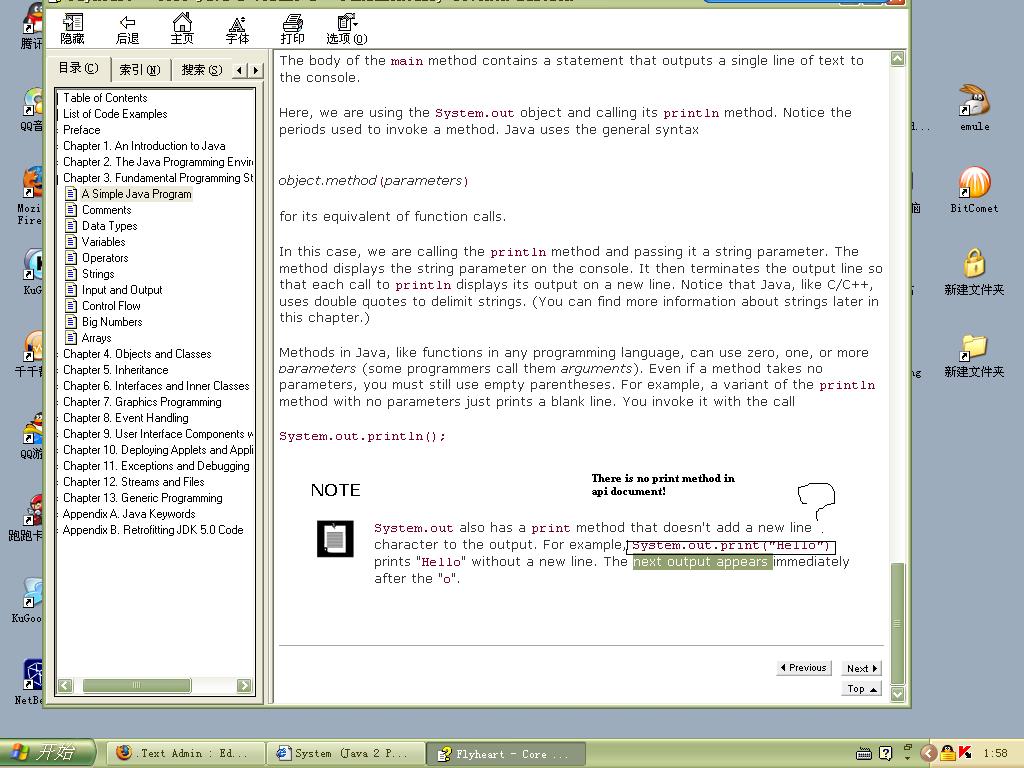
還真的有...中文api document是不是過時的版本做的?寒
這個問題已經(jīng)解決.點(diǎn)這里看解答

2006年7月18日??????????????????????? 星期二??????????????????? 小雨
關(guān)于代碼單元和代碼點(diǎn)的理解:
1、一個代碼點(diǎn)可能包含一個或兩個代碼單元。
2、在我的測試程序中,“我 ”也只占用一個代碼單元。即代碼點(diǎn)數(shù)等于代碼單元數(shù)。
下面是在unicode的官方網(wǎng)站上找到的關(guān)于unicode的中文,韓文,日文的一些說明:Q: I have heard that UTF-8 does not support some
Japanese characters. Is this correct?
A: There is a lot of misinformation floating around about the support
of Chinese, Japanese and Korean (CJK) characters. The Unicode Standard supports
all of the CJK characters from JIS X 0208, JIS X 0212, JIS X 0221, or JIS
X 0213, for example, and many more. This is true no matter which encoding form
of Unicode is used: UTF-8, UTF-16, or UTF-32.
Unicode supports over 70,000 CJK characters right now, and work is
underway to encode further additions. The International Standard ISO/IEC 10646
and the Unicode Standard are completely synchronized in repertoire and content.
And that means that Unicode has the same repertoire as GB 18030, since that also
is synchronized with ISO 10646 — although with a different ordering and byte
format.
無論是那個編碼方式(UTF-8, UTF-16, or UTF-32
)對中文,韓文,日文 支持的字?jǐn)?shù)都一樣么?碼數(shù)好像是不一樣吧?.
我的測試程序如下:
public class test0 {
??? public static void main(String[] args)
??? ???? {String a="我 ";
??? ????? int cuCount=a.length();
??? ????? System.out.println("the number of code units required for string \"test\" in the UTF-16 encoding is "+cuCount);
??? ????? int cpCount=a.codePointCount(0, a.length());
??? ????? System.out.println("the number of code points is "+cpCount);
??? ????? System.out.println("the end of string \"我 \" is "+a.charAt(a.length()-1));??? ?????
??? ?????
??? ???? }
??? ?????
}
輸出結(jié)果為:
the number of code units required for string "test" in the UTF-16 encoding is 2
the number of code points is 2
the end of string "我 " is [空格]
在eclipse里面找到了set encoding選項(xiàng),在里面可以設(shè)置編碼方式。
2006年7月27日?????? 星期四???????????? 雨
core java上對int codePointCount(int startIndex,int endIndex)的解釋中一個名詞沒弄明白。
int codePointCount(int startIndex, int endIndex) 5.0
returns the number of code points between startIndex and endIndex - 1.
Unpaired surrogates are counted as code points.
中文api對int codePointCount(int startIndex,int endIndex)的解釋:
返回此 String 的指定文本范圍中的 Unicode 代碼點(diǎn)數(shù)。文本范圍始于指定的 beginIndex,一直到索引 endIndex - 1 處的 char。因此,該文本范圍的長度(在 char 中)是 endIndex-beginIndex。該文本范圍內(nèi)未配對的代理項(xiàng)作為一個代碼點(diǎn)計(jì)數(shù)。
MSDN上對Surrogates的解釋:
A
surrogate pair is a pair of UTF-16 code values that
represent a single supplementary character; each of the two code values
in the pair is called a
surrogate. The first (high) surrogate
is a 16-bit code value in the range U+D800 to U+DBFF. The second (low)
surrogate is a 16-bit code value in the range U+DC00 to U+DFFF.
原來surrogate 就是unicode-16編碼里面的高8位或低8位存儲單元。而Unpaired surrogates的意思應(yīng)該就是指非unicode匹配字符了。而且這些不匹配的字符codePointCount()方法會以8個bit作為計(jì)數(shù)單元。