本文由攜程技術團隊Aaron分享,原題“干貨 | 攜程弱網識別技術探索”,下文進行了排版和內容優化。
1、引言
網絡優化一直是移動互聯網時代的熱議話題,弱網識別作為移動端弱網優化的第一步,受到的關注和討論也是最多的。本文從方案設計、代碼開發到技術落地,詳盡的分享了攜程在移動端弱網識別方面的實踐經驗,如果你也有類似需求,這篇文章會是一個不錯的實操指南。

技術交流:
2、本文作者
Aaron:攜程移動開發專家,關注網絡優化、移動端性能優化。
3、系列文章
- 《移動端弱網優化專題(一):通俗易懂,理解移動網絡的“弱”和“慢”》
- 《移動端弱網優化專題(二):史上最全移動弱網絡優化方法總結》
- 《移動端弱網優化專題(三):現代移動端網絡短連接的優化手段總結》
- 《移動端弱網優化專題(四):百度APP網絡深度優化實踐(DNS優化篇)》
- 《移動端弱網優化專題(五):百度APP網絡深度優化實踐(網絡連接優化篇)》
- 《移動端弱網優化專題(六):百度APP網絡深度優化實踐(移動弱網優化篇)》
- 《移動端弱網優化專題(七):愛奇藝APP網絡優化實踐(網絡請求成功率優化篇)》
- 《移動端弱網優化專題(八):美團點評的網絡優化實踐(大幅提升連接成功率、速度等)》
- 《移動端弱網優化專題(九):淘寶移動端統一網絡庫的架構演進和弱網優化實踐》
- 《移動端弱網優化專題(十):愛奇藝APP跨國弱網通信的優化實踐》
- 《移動端弱網優化專題(十一):美圖APP的移動端DNS優化實踐》
- 《移動端弱網優化專題(十二):得物自研移動端弱網診斷工具的技術實踐》
- 《移動端弱網優化專題(十三):得物移動端常見白屏問題優化(網絡優化篇)》
- 《移動端弱網優化專題(十四):攜程APP移動網絡優化實踐(弱網識別篇)》(* 本文)
4、技術背景
自從2010年攜程推出”無線戰略“,并發布移動端APP以來,無線研發團隊對于客戶端網絡性能的優化就一直沒有停止過。經過這十幾年持續不斷的優化,目前攜程的端到端網絡性能已經處于一個相當不錯的水平,大盤數據趨于穩定,優化也隨之進入 ”深水區“,提升難度巨大。
結合線上的一系列客訴反饋,我們發現即使大盤的數據再優秀,用戶網絡表現不佳的個例case仍然層出不窮,排查后大部分被我們歸因到"弱網”。這部分“弱網”長尾數據相比大盤均值仍有巨大的提升空間,如果可以針對性優化的話,對于提升整體用戶體驗和減少客訴都有非常明確的價值。
既然要優化“弱網”,那第一步一定是建立相應的“弱網識別模型”,準確識別出弱網場景,本文即探討攜程在弱網識別方面的技術探索,包含技術選型細節和關鍵的路徑思考,歡迎溝通交流。
5、技術方案概覽
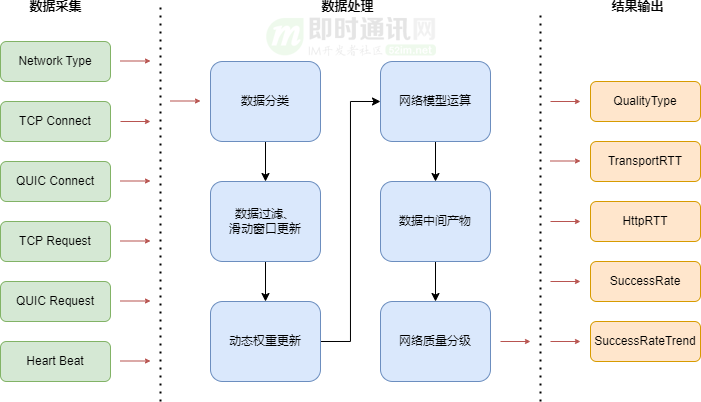
如上圖所示,攜程弱網識別模型的整個工作流程由數據采集、數據處理、結果輸出三部分組成,接下來我們順著流程來逐個剖析相關細節。
6、數據采集實現
6.1 反映網絡質量的指標有哪些
說到可以客觀反映網絡質量的指標,業內定義清晰且獲得公認的有如下這些:
- 1)HttpRTT:Http請求一次網絡往返的耗時,具體口徑是客戶端從開始發送RequestHeader到收到ResponseHeader第一個字節的時間差;
- 2)TransportRTT:網絡通道上一次數據往返的耗時,具體口徑是客戶端從開始發送數據到收到服務端返回數據第一個字節的時間差,要減去服務處理的耗時;
- 3)ThroughPut:網絡吞吐量,是指定位時間內網絡通道上下行的數據量,具體口徑是單位位時間內上行或者下行的數據量除以單位時間,由于上行數據量受到業務因素的影響較大,我們一般僅關注下行;
- 4)BandwidthDelayProduct:帶寬時延乘積,顧名思義是指網絡帶寬乘以網絡時延的結果,即當前網絡通道里正在傳輸的數據總量,是一個復合指標,可以客觀反映當前網絡承載數據的能力,計算方式是 ThroughPut * TransportRTT;
- 5)SignalStrength:信號強度,移動互聯網時代,設備依靠Wifi或者蜂窩數據接入互聯網,信號強度會影響用戶的網絡表現;
- 6)NetworkSuccessRate:網絡成功率,剔除業務影響的純網絡行為成功率,與網絡質量呈正相關,包含建聯成功率、傳輸成功率等。
6.2 哪些指標作為模型輸入?為什么?
對于網絡質量識別,業內做的比較早的是Google的NQE(Network Quality Estimator),國內大多數網絡質量識別方案也都參考了Google NQE,NQE中識別模型的輸入主要是HttpRTT、TransportRTT、DownstreamThroughput這三個指標。
對于HttpRTT、TransportRTT,在應用層和傳輸層都有很多方式可以采集到,且口徑清晰,所以這兩個指標被我們納入采集范圍。
對于DownstreamThroughput,我們實踐過程中發現,該指標受到用戶行為的影響很大,當用戶集中操作大量發送網絡請求的時候,該指標就偏高,當用戶停止操作閱讀數據時,該指標就會偏低甚至長時間得不到更新,考慮到指標的波動性,我們不將此指標納入采集范圍。
既然DownstreamThroughput被排除在外,那由他參與計算的BandwidthDelayProduct也被我們排除。
SignalStrength信號強度由于iOS無法準確獲取,考慮到多端一致性,也被我們Pass。
NetworkSuccessRate網絡成功率這個指標,可能很少被其他方案提及到,我們提出這個指標并將他納入采集范圍的主要原因是,基于RTT的網絡識別模型,在遇到網絡波動導致的用戶大面積請求失敗時,無法獲取到有效的RTT值,導致識別的準確性和實時性都收到影響,引入網絡成功率可以很好的彌補這個缺陷,最終線上生產環境驗證也證明了該指標的必要性。
最終:攜程的網絡質量識別模型采集HttpRTT、TransportRTT、NetworkSuccessRate作為輸入指標。
6.3 輸入的網絡指標如何采集
攜程的網絡請求,主要有Tcp代理通道、Quic代理通道、Http通道三種網絡通道。
對于上述提到了三個輸入指標,我們從如下網絡行為中進行數據采集:
- 1)TransportRTT:通道心跳耗時、Tcp通道建聯耗時、Http通道建聯耗時(Tips:建聯耗時不涉及業務處理,近似于純網絡傳輸耗時,所以我們把他作為TransportRTT;Quic建聯約等于Tls握手耗時,且存在0RTT等特性干擾,所以不采用);
- 2)HttpRTT:標準Http請求的responseHeader開始接收時間減去RequestHeader的開始發送時間、自定義網絡通道請求的開始接收時間減去開始發送時間;
- 3)NetworkSuccessRate:Tcp建聯成功狀態、Quic建聯成功狀態、心跳成功狀態、Http請求是否完整接收到Response。
對于自定義的Tcp、Quic代理通道,按照上述口徑在網絡通道相關狀態回調內統計數據即可,自定義實現參考價值不大,這里就不過多贅述。
對于標準的Http請求,我們可以通過獲取系統網絡框架返回的Metric信息或者監聽請求的狀態流轉來獲取網絡指標。
1)對于iOS端:
iOS 10之后NSURLSession支持通過NSURLSessionTaskDelegate的協議方法URLSession:task:didFinishCollectingMetrics:獲取到請求的Metric信息,詳細信息見附錄。
單次請求的Metric定義如下圖:

解釋一下:
- 1)TransportRTT = connectEnd - connectStart - secureConnectionEnd + secureConnectionStart;建聯耗時要減去Tls的耗時,連接復用時,相關字段為空值,不納入計算;
- 2)HttpRTT = responseStart - requestStart;
- 3)NetworkSuccessStatus = responseEnd 且沒有傳輸錯誤;網絡成功率只關心傳輸是否成功,不需要關注Response的http狀態碼。
2)對于Android端:
系統網絡框架OkHttp支持添加EventListener來獲取Http請求的狀態流轉信息,可以在各狀態回調內記錄時間戳來計算RTT,詳細信息見附錄。
單次請求的Events定義如下圖:
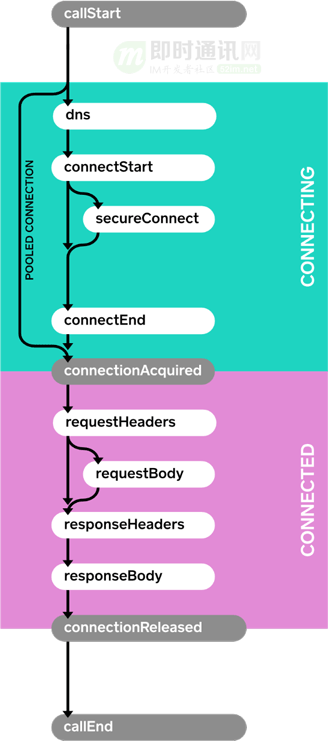
解釋一下:
- 1)TransportRTT = connectEnd - connectStart - secureConnectEnd + secureConnectStart;
- 2)HttpRTT = responseHeadersStart - requestHeadersStart;
- 3)NetworkSuccessStatus = responseBodyEnd 且沒有傳輸錯誤。
依照上述方法收集到網絡數據后,我們把數據封裝成對應的結構體,注入識別模型,攜程對于網絡數據結構體的定義如下,方便大家參考。
typedef enum : int64_t {
NQEMetricsSourceTypeInvalid = 0, // 0
NQEMetricsSourceTypeTcpConnect = 1 << 0, // 1
NQEMetricsSourceTypeQuicConnect = 1 << 1, // 2
NQEMetricsSourceTypeHttpRequest = 1 << 2, // 4
NQEMetricsSourceTypeQuicRequest = 1 << 3, // 8
NQEMetricsSourceTypeHeartBeat = 1 << 4, // 16
......
} NQEMetricsSourceType;
struct NQEMetrics {
// 本次采集到的數據來源,可以是多個枚舉值的或值
// 例如一次沒有連接復用http請求,source = TcpConnect|HttpRequest,同時存在transportRTT和httpRTT NQEMetricsSourceType source;
// 本次數據的成功狀態,用作成功率計算
bool isSuccessed;
// httpRTT,可為空
double httpRTTInSec;
// transportRTT,可為空
double transportRTTInSec;
// 數據采集時間
double occurrenceTimeInSec;
};
7、數據處理實現
7.1數據過濾和滑動窗口
網絡數據采集后,注入到識別模型內,需要一個數據結構來承載,我們采用的是隊列。
進入隊列前,我們需要先進行數據過濾,篩選掉一些無效的數據。
目前采用的篩選策略有如下這些:
- 1)單條NQEMetrics數據:在isSuccessed=true的情況下,httpRTT、transportRTT至少有一條不為空,否則為無效數據;
- 2)RTT必須大于最小閾值:用來過濾一些類似LocalHost請求的臟數據,目前采用的閾值為10ms;
- 3)RTT必須小于最大閾值:用來過濾前后臺切換進程掛起導致的RTT數值偏大,目前采用的閾值為5mins。
數據過濾后加入隊列,為了實時性和結果準確性,我們處理數據時,會根據兩個限制邏輯來確定一個具體的滑動窗口,只讓窗口內的數據參與計算。
具體窗口限制邏輯如下:
- 1)最小數量限制:當窗口內數據過少時,會放大單條數據的影響,導致結果毛刺增多,所以我們限制最小計算窗口的數據條數為5;
- 2)最大時間限制:為了數據實時性的考慮,比較舊的數據不參與計算,目前采用的閾值為5mins。
每次計算網絡質量時,可以根據這兩個限制來確定計算窗口,窗口外的數據可以實時清理出隊列,減少內存占用。
上文提到的各種閾值設置,均可通過配置系統更新。
7.2 動態權重計算
弱網識別模型的原理簡單來說就是將窗口內的一組數據經過一系列處理后,得出一個最終值,再用這個最終值與對應的弱網閾值比較來得出是否是弱網。
出于實時性的考慮,我們希望距離當前時間越近的數據權重越高,所以要用到動態權重的算法,這里我們比較推薦的是”半衰期動態權重“和”反正切動態權重“兩種算法。
1)半衰期動態權重:
半衰期顧名思義,即每經過一個固定的時間,權重降低為之前的一半。
這里衰減幅度和周期都是可以自定義的,計算公式如下:
每秒衰減因子 = pow(衰減幅度, 1.0 / 衰減周期);衰減幅度為浮點型,取值范圍 0~1,衰減周期為整形,單位為秒
動態權重 = pow(每秒衰減因子, abs(now - 數據采集時間))
以衰減幅度為0.5,衰減周期為60秒為例,對應的函數曲線如下:
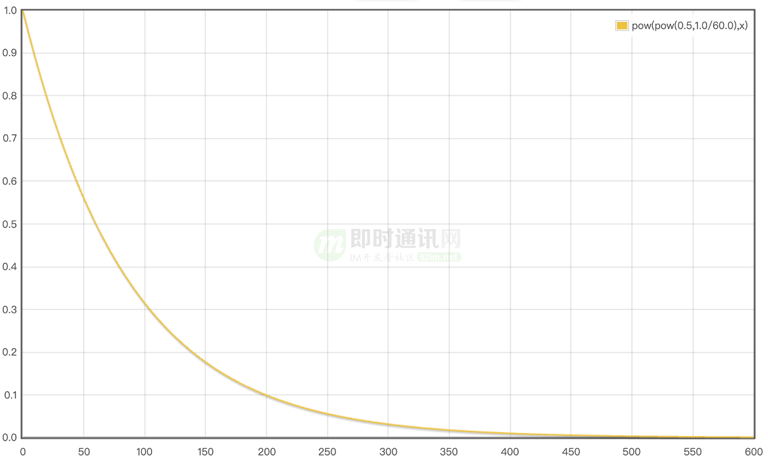
橫坐標為數據采集時間距今的時間差,縱坐標為權重,從圖上可以清晰看到,隨著時間差增大,權重無限趨近于0。
半衰期動態權重也是Google NQE采用的權重計算方案,Google采用的周期是每60秒降低50%,相關代碼詳見附錄。
部分核心代碼如下:
double GetWeightMultiplierPerSecond(
const std::map<std::string, std::string>& params) {
// Default value of the half life (in seconds) for computing time weighted
// percentiles. Every half life, the weight of all observations reduces by
// half. Lowering the half life would reduce the weight of older values
// faster.
int half_life_seconds = 60;
int32_t variations_value = 0;
auto it = params.find("HalfLifeSeconds");
if (it != params.end() && base::StringToInt(it->second, &variations_value) &&
variations_value >= 1) {
half_life_seconds = variations_value;
}
DCHECK_GT(half_life_seconds, 0);
return pow(0.5, 1.0 / half_life_seconds);
}
void ObservationBuffer::ComputeWeightedObservations(
const base::TimeTicks& begin_timestamp,
int32_t current_signal_strength,
std::vector<WeightedObservation>* weighted_observations,
double* total_weight) const {
base::TimeDelta time_since_sample_taken = now - observation.timestamp();
double time_weight =
pow(weight_multiplier_per_second_, time_since_sample_taken.InSeconds());
…
}
2)反正切動態權重:
y=arctan(x)反正切函數在第一象限的取值范圍為0~Pi/2,我們將arctan(x)取反,向上平移Pi/2,然后除以Pi/2,函數曲線即可在第一象限隨著x增大y的取值從1趨近于0。
我們還可以使用一個斜率系數來控制權重降低的趨勢快慢,公式推導過程如下:
動態權重 = (Pi / 2 - arctan(abs(now - 數據采集時間) * 斜率系數)) / (Pi / 2) = 1 - arctan(abs(now - 數據采集時間) * 斜率系數) / Pi * 2;斜率系數為浮點型,取值范圍為0~1,系數越小,權重降低的越緩慢。
以斜率系數為1/20為例,對應的函數曲線如下:
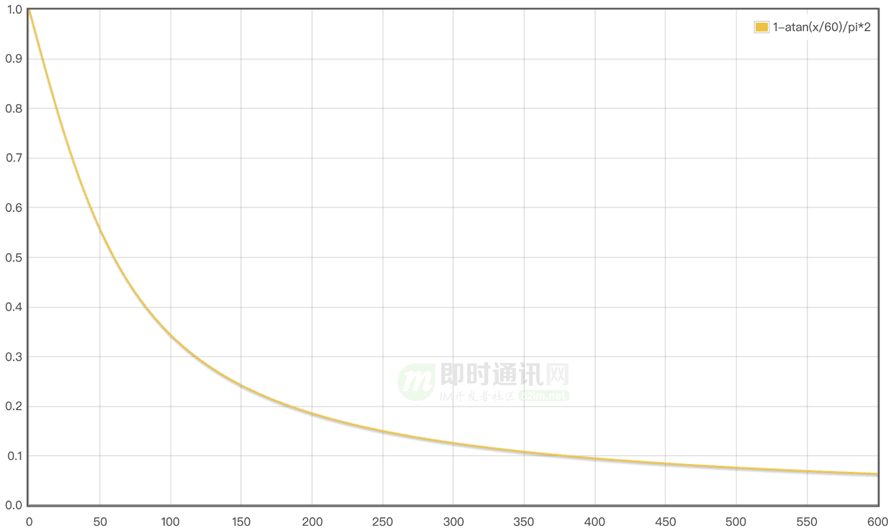
和前文的半衰期動態權重相同,橫坐標為數據采集時間距今的時間差,縱坐標為權重,隨著時間差增大,權重趨近于0,兩種動態權重算法效果類似。
反正切動態權重的實現代碼如下:
static double _nqe_getWeight(double targetTime) {
……
double interval = now - targetTime;
/// 曲率系數,數值越小權重降低的越緩慢
double rate = 20.0 / 1;
return 1.0 - atan(interval * rate) / M_PI_2;
}
從上圖的代碼實現可以看出,反正切相關的代碼實現要簡單很多,但是由于存在推導過程,所以理解起來比較困難,代碼維護成本較高(數學功底對于程序員來說也是非常重要的),大家可以酌情自行選擇。
攜程最終采用的也是半衰期動態權重的方案,出于實時性考慮,最終線上驗證后采用的衰減幅度為0.3,衰減幅度為60秒,供參考。
7.3 RTT指標加權中值計算
在確定了單條數據的權重之后,對于RTT的數值計算,我們第一個想到的是加權平均,但是加權平均很容易收到高權重臟數據的影響,準確性堪憂,所以我們改用了“加權中值”。
加權中值的計算方式是,將窗口內的數據按照數值大小升序排列,然后從頭遍歷數據,累加權重大于等于總權重的一半時,停止遍歷,當前遍歷到的數值即為最終的加權中值。
NQE對于TransportRTT和HttpRTT處理,也是使用的這種方式,相關代碼詳見附錄。
部分核心代碼如下:
std::optional<int32_t> ObservationBuffer::GetPercentile(
base::TimeTicks begin_timestamp,
int32_t current_signal_strength,
int percentile,
size_t* observations_count) const {
……
// 此處的percentile值為50,即取中值
double desired_weight = percentile / 100.0 * total_weight;
double cumulative_weight_seen_so_far = 0.0;
for (const auto& weighted_observation : weighted_observations) {
cumulative_weight_seen_so_far += weighted_observation.weight;
if (cumulative_weight_seen_so_far >= desired_weight)
return weighted_observation.value;
}
// Computation may reach here due to floating point errors. This may happen
// if |percentile| was 100 (or close to 100), and |desired_weight| was
// slightly larger than |total_weight| (due to floating point errors).
// In this case, we return the highest |value| among all observations.
// This is same as value of the last observation in the sorted vector.
return weighted_observations.at(weighted_observations.size() - 1).value;
}
7.4 成功率指標加權平均計算
對于成功率,我們的NQEMetrics結構體內定義了單次成功狀態isSuccessed,單條數據的加權成功率為 (NQEMetrics.isSuccessed ? 1 : 0) * weight,整體的加權成功率為加權成功率總和除以總權重。
相關代碼實現如下:
extern double _calculateSuccessRateByWeight(const vector &metrics, uint64_t types, const shared_ptr<NQEConfig> config) {
……
uint64_t totalValidCount = 0;
double totalWeights = 0.0;
double totalSuccessRate = 0.0;
for (const auto& m : metrics) {
/// 過濾需要的數據
if ((m.source & types) == 0) {
continue;
}
/// 累計總權重和總成功率
totalValidCount++;
totalWeights += m.weight;
totalSuccessRate += (m.isSuccessed ? 1 : 0) * m.weight;
}
/// 數據不足
if (totalValidCount < config->minValidWindowSize) {
return NQE_INVALID_RATE_VALUE;
}
if (totalWeights <= 0.0) {
return NQE_INVALID_RATE_VALUE;
}
return totalSuccessRate / totalWeights;
}
7.5 引入成功率趨勢提高實時性
網絡質量識別不僅需要準確,實時性也非常重要,在網絡質量切換時模型識別的時間越短越好。前文已經提到了TransportRTT、HttpRTT、NetworkSuccessRate三個核心指標的計算,但是在線上實際驗證的過程中,我們發現在網絡完全不可用成功率跌0后,識別模型對于網絡狀態的恢復感知很慢,原因是成功率的攀升需要較長的時間。
針對這個極端的case,我們引入了一個“成功率趨勢”的新指標,來優化模型的實時性,在成功率未達閾值當時有明顯趨勢時,提前切換網絡質量狀態。成功率趨勢是指一段時間內成功率連續上升或者下降的幅度,浮點類型,取值范圍-1 ~ +1。
成功率趨勢初始值為0,計算方式如下:
1)在每次更新成功率時,計算更新前后成功率的差值:
如果差值為正,則成功率向好:
- 1)如果當前成功率趨勢值為正,則向好趨勢持續,成功率趨勢加上當前差值;
- 2)如果當前成功率趨勢值為負,則成功率趨勢由壞轉好,成功率趨勢重置為當前差值。
如果差值為負,則成功率向壞:
- 1)如果當前成功率趨勢值為正,則成功率趨勢由好轉壞,成功率趨勢重置為當前差值;
- 2)如果當前成功率趨勢值為負,則向壞趨勢持續,成功率趨勢加上當前差值(負值)。
2)當然還需要過濾一些毛刺數據,避免趨勢變化過頻:
具體代碼實現如下:
void NQE::_updateSuccessRateTrend() {
auto oldRate;
auto newRate;
if (oldRate < 0 || newRate < 0) {
_successRateContinuousDiff = 0;
return;
}
auto diff = newRate - oldRate;
/// 數據錯誤,不做處理
if (abs(diff) > 1) {
_successRateContinuousDiff = 0;
return;
}
/// diff小于0.01,作為毛刺處理,不影響趨勢變化
if (abs(diff) < 0.01) {
_successRateContinuousDiff += diff;
return;
}
/// 計算連續diff
if (diff > 0 && _successRateContinuousDiff > 0) {
_successRateContinuousDiff += diff;
} else if (diff < 0 && _successRateContinuousDiff < 0) {
_successRateContinuousDiff += diff;
} else {
_successRateContinuousDiff = diff;
}
}
在網絡成功率和成功率趨勢的加持下,我們的識別模型實時性大幅度提升。我們控制相同請求頻率和請求數據量,線下模擬弱網切換進行測試。
測試結果如下:
- 1)單RTT識別模型:網絡質量切換后識別較慢,且存在連續切換場景識別不出弱網的情況;
- 2)RTT+成功率模型:切換識別速度較單RTT模型提升約50%,成功率跌0后的Bad切Good識別明顯較慢;
- 3)RTT+成功率+成功率趨勢模型:切換識別速度較單RTT模型提升約70%,Bad切Good識別速度明顯提升。
所以,最終攜程弱網識別模型計算的指標有TransportRTT、HttpRTT、NetworkSuccessRate、SuccessRateTrend(成功率趨勢)四個。
8、結果輸出
8.1 網絡質量定義
識別模型對外輸出的是一個網絡質量的枚舉值,Google NQE對于網絡質量的定義如下,源碼詳見附錄。
enum EffectiveConnectionType {
// Effective connection type reported when the network quality is unknown.
EFFECTIVE_CONNECTION_TYPE_UNKNOWN = 0,
// Effective connection type reported when the Internet is unreachable
// because the device does not have a connection (as reported by underlying
// platform APIs). Note that due to rare but potential bugs in the platform
// APIs, it is possible that effective connection type is reported as
// EFFECTIVE_CONNECTION_TYPE_OFFLINE. Callers must use caution when using
// acting on this.
EFFECTIVE_CONNECTION_TYPE_OFFLINE,
// Effective connection type reported when the network has the quality of a
// poor 2G connection.
EFFECTIVE_CONNECTION_TYPE_SLOW_2G,
// Effective connection type reported when the network has the quality of a
// faster 2G connection.
EFFECTIVE_CONNECTION_TYPE_2G,
// Effective connection type reported when the network has the quality of a 3G
// connection.
EFFECTIVE_CONNECTION_TYPE_3G,
// Effective connection type reported when the network has the quality of a 4G
// connection.
EFFECTIVE_CONNECTION_TYPE_4G,
// Last value of the effective connection type. This value is unused.
EFFECTIVE_CONNECTION_TYPE_LAST,
};
Google枚舉定義的最大問題是理解成本比較高,其他開發同學看到這個所謂的“3G”、“4G”,他依然不知道網絡是好是壞,是不是他認為的“弱網”。
所以我們在定義接口的時候,對于枚舉的設計考慮最多的就是理解成本,結合開發同學最想知道的“是不是弱網”。
我們的接口定義如下:
typedef enum : int64_t {
/// 未知狀態,初始狀態或者無有效計算窗口時會進入此狀態
NetworkQualityTypeUnknown = 0,
/// 離線狀態,網絡不可用
NetworkQualityTypeOffline = 1,
/// 弱網狀態
NetworkQualityTypeBad = 2,
/// 正常網絡狀態
NetworkQualityTypeGood = 3
} NetworkQualityType;
這樣是不是看起來簡單明了多了,我們接下來就講講怎么計算得出這幾個枚舉的結果。
8.2 網絡質量計算方式
NetworkQualityTypeUnknown 是在初始化或者網絡切換后的一段時間內,數據不足無法得出網絡質量,會進入此狀態。
NetworkQualityTypeOffline 的觸發條件很單一,就是操作系統識別到無網絡連接,具體的獲取方式由各平臺自行實現,例如iOS可以通過Reachability獲取,官方Demo詳見附錄6。
NetworkQualityTypeBad 也就是我們最核心的“弱網”狀態,計算方式是上文提到的TransportRTT、HttpRTT兩個指標任一指標觸發弱網閾值,或者NetworkSuccessRate和SuccessRateTrend同時滿足弱網閾值。
NetworkQualityTypeGood 是指正常的網絡質量狀態,上述三種網絡質量類型講完后,這個類型就簡單了,即非上述三種情況的場景,歸類到Good,這也是設計上占比最高的網絡質量類型。
識別模型的運轉流程如下:

解釋一下:
- 1)數據隊列在初始化和網絡連接狀態變化兩個時機會被重置,充值后網絡質量類型進入 NetworkQualityTypeUnknown;
- 2)網絡連接狀態進入無連接狀態時,數據隊列被清空,網絡質量類型直接進入 NetworkQualityTypeOffline,在網絡類型變為可用類型前,數據隊列不接受數據注入,且不進行計算;
- 3)數據隊列的數據變化觸發質量計算,出于資源開銷考慮,要限制計算的頻次,我們采用計算間隔和新增數據量兩個閾值限制,計算間隔大于60s或者新增數據量超過10條才會觸發計算;同時也暴露了對外接口,業務可按需強制刷新計算結果;
- 4)關于主動網絡探測,可結合自身的業務需求按需實現,目前攜程的APP在使用時網絡數據更新比較頻繁,無需補充主動探測數據。
8.3 弱網閾值制定
模型核心的計算邏輯,就是將加工后得到的各網絡指標與對應的弱網閾值進行對比,從而獲得是否進入弱網的結果。
關于弱網閾值的制定上,我們經歷了如下兩個階段:
1)第一階段:
主要參考NQE EFFECTIVE_CONNECTION_TYPE_2G 的閾值定義:
- 1)HttpRTT > 1726ms;
- 2)TransportRTT > 1531ms;
- 3)成功率按照內部討論的預期設置為 NetworkSuccessRate < 90%;
- 4)成功率趨勢閾值設置為 SuccessRateTrend < 0.1,即成功率連續向好增加超過10pp,即使成功率小于90%,也從Bad切換為Good,這個指標主要是為了提升Bad切Good的速度。
2)第二階段:
我們通過線上的網絡質量分布監控,和一些具體case的分析,不斷迭代我們的閾值,我們需要制定一個識別準確率的指標來指引閾值的調整工作,達到邏輯準確與自洽。
理論上:我們希望識別模型的入參與當下計算出的網絡質量類型所匹配,例如當前注入NQEMetrics數據的HttpRTT <= 1726ms ,那我們預期當前計算出的網絡質量類型就是Good。但是弱網的決策邏輯是相對復雜的,需要考慮到各種因素,以
下兩點會造成弱網狀態下的入參數據不一定符合弱網閾值定義:
- 1)弱網的計算是對過去已經發生網絡行為的分析,具有一定的滯后性,所以在識別結果切換附近,必然有部分的原數據已經滿足下一階段的網絡質量定義;
- 2)弱網的決策是對多個指標的復合計算,所以在識別到弱網狀態時,不一定所有的指標原數據都符合弱網定義,比如由HttpRTT觸發弱網時,當前的TransportRTT數據可能表現良好。
終上兩點原因,弱網分類下必然有一定的非弱網數據,這里的誤差數據占比與識別準確率負相關,誤差數據占比越低,識別準確率越高。所以想到這里,我們的模型識別準確率的指標計算口徑就有了:
模型弱網識別準確性 = 100% - 弱網狀態下不符合弱網閾值定義原數據占比
有了這個指標指引,我們在模型上線后進行了數個版本的數據統計,通過各指標閾值的微調和case by case解決異常場景,誤差數據從剛上線的15%+降低到10%以下,即模型識別準確率優化至90%以上。
最終攜程90%準確率的模型對應的弱網閾值如下(不同業務場景的網絡請求差別較大,僅供大家參考):
- 1)HttpRTT > 1220ms;這個值是線上HttpRTT的TP98值,與弱網占比相近;
- 2)TransportRTT > 520ms;同線上TP98值;
- 3)NetworkSuccessRate < 90%;
- 4)SuccessRateTrend < 0.2;之前的0.1導致模型的結果切換過于頻繁,最終調整到了0.2。
Tips:對于類似攜程這種自定義的弱網識別模型,弱網標準也是考慮業務現狀的定制標準,所以不需要太多和外部的弱網標準對齊,重點是自洽和符合業務預期。
9、落地效果
考慮到識別模型要支持多平臺(iOS、Android、Harmony等),所以我們在一開始實現方案時就采用了C++作為開發語言,天然支持了多平臺,各平臺只需要實現上層數據采集和注入模型的少量邏輯即可完成模型的接入。相同的代碼實現和弱網標準,也方便我們在不同的平臺間直接對標數據,發現各平臺的問題針對性優化。
目前攜程的網絡質量識別模型,已經在iOS、Android平臺完成接入并大面積投產,網絡質量數據與集團的APM監控平臺打通,形成了攜程官方統一的網絡質量標準,在網絡排障、框架網絡優化、業務網絡優化等多種場景下扮演重要角色,弱網優化相關的內容我們會在后面相關的專題內繼續分享,此處不再贅述。
最終網絡質量相關的分布數據如下(數據為實驗采集,不代表攜程真實業務情況,僅參考)。
網絡質量分布:
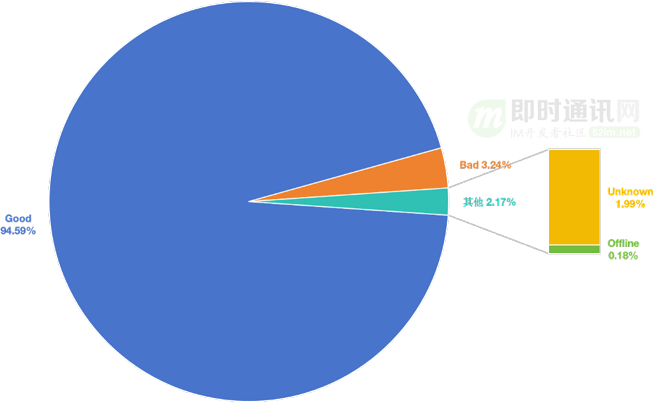
各網絡質量下對應的請求性能數據:
10、未來展望
網絡質量識別模型的完成只是我們網絡優化的開始,后續還有很多的工作需要我們繼續努力。
未來一段時間我們會從以下幾個方面繼續推進:
1)持續推進各平臺、各獨立APP的網絡質量識別模型接入,完成攜程終端全平臺的網絡質量模型覆蓋。
2)做好識別模型的防劣化工作,解決各業務場景的bad case,堅守現階段識別準確率和實時性的標準水位。
3)推出攜程內部的“網絡性能白皮書”,從APP、系統平臺、網絡質量、成功率、全鏈路耗時等各維度解析公司內部各業務線的網絡表現,形成內部的網絡性能數據基線,為業務優化提供參考。
4)借助現有的弱網標準和識別能力,從網絡框架側和業務側兩個不同的角度進行弱網優化,提高整體網絡表現;當下海外市場是業務發力的重點,海外場景的網絡表現也明顯弱于國內,我們會針對海外場景從弱網的角度進行重點優化。
攜程目前已經針對弱網場景推出了一系列優化策略,部分策略已經取得非常不錯的收益,后續我們會繼續推進,也會持續分享輸出。
11、參考資料
[1] TCP/IP詳解 - 第17章·TCP:傳輸控制協議
[2] 快速理解TCP協議一篇就夠
[3] 新手入門一篇就夠:從零開發移動端IM
[3] 騰訊原創分享(二):如何大幅壓縮移動網絡下APP的流量消耗(上篇)
[4] 深入淺出,全面理解HTTP協議
[5] 快速讀懂Http/3協議,一篇就夠!
[6] 技術掃盲:新一代基于UDP的低延時網絡傳輸層協議——QUIC詳解
[7] 冰山之下,一次網絡請求背后的技術秘密
[8] 通俗易懂,理解移動網絡的“弱”和“慢”
[9] 史上最全移動弱網絡優化方法總結
[10] 愛奇藝APP網絡優化實踐(網絡請求成功率優化篇)
[11] 美團點評的網絡優化實踐(大幅提升連接成功率、速度等)
[12] 淘寶移動端統一網絡庫的架構演進和弱網優化實踐
[13] 愛奇藝APP跨國弱網通信的優化實踐
[14] 得物自研移動端弱網診斷工具的技術實踐
(本文已同步發布于:http://www.52im.net/thread-4737-1-1.html)