本文由騰訊技術團隊peter分享,原題“騰訊網關TGW架構演進之路”,下文進行了排版和內容優化等。
1、引言
TGW全稱Tencent Gateway,是一套實現多網統一接入,支持自動負載均衡的系統, 是公司有10+年歷史的網關,因此TGW也被稱為公司公網的橋頭堡。
本文從騰訊公網TGW網關系統的應用場景、背景需求講起,重點解析了從山海1.0架構到山海2.0架構需要解決的問題和架構規劃與設計實現,以及對于未來TGW山海網關的發展和演進方向。

技術交流:
2、專題目錄
本文是專題系列文章的第11篇,總目錄如下:
- 《長連接網關技術專題(一):京東京麥的生產級TCP網關技術實踐總結》
- 《長連接網關技術專題(二):知乎千萬級并發的高性能長連接網關技術實踐》
- 《長連接網關技術專題(三):手淘億級移動端接入層網關的技術演進之路》
- 《長連接網關技術專題(四):愛奇藝WebSocket實時推送網關技術實踐》
- 《長連接網關技術專題(五):喜馬拉雅自研億級API網關技術實踐》
- 《長連接網關技術專題(六):石墨文檔單機50萬WebSocket長連接架構實踐》
- 《長連接網關技術專題(七):小米小愛單機120萬長連接接入層的架構演進》
- 《長連接網關技術專題(八):B站基于微服務的API網關從0到1的演進之路》
- 《長連接網關技術專題(九):去哪兒網酒店高性能業務網關技術實踐》
- 《長連接網關技術專題(十):百度基于Go的千萬級統一長連接服務架構實踐》
- 《長連接網關技術專題(十一):揭秘騰訊公網TGW網關系統的技術架構演進》(* 本文)
3、TGW網關系統的重要性
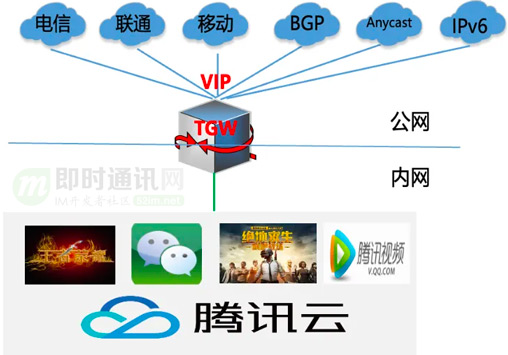
TGW全稱Tencent Gateway,是一套實現多網統一接入、支持自動負載均衡的系統, 是公司有10+年歷史的網關,因此TGW也被稱為公司公網的橋頭堡。它對外連接了各大運營商并支撐公有云上EIP、CLB等產品功能,對內提供了公網網絡的接入功能,如為游戲、微信等業務提供公網接入服務。
TGW主要有兩大產品:
- 1)彈性EIP(比如購買一臺虛擬機CVM或是一個NAT實例后,通過EIP連通外網);
- 2)四層CLB。
四層CLB一般分為內網CLB和外網CLB:
- 1)內網CLB是在vpc內創建一個CLB實例,把多個CVM服務掛在了內網CLB上,為后端RS提供負載均衡的能力;
- 2)外網CLB面對的是公網側負載均衡的需求。
當在內部部署CLB集群時,可分為IPV4或者IPV6兩大類,根據物理網絡類型又細分為BGP和三網兩類。三網指這些IP地址是靜態的,不像BGP一樣能夠在多個運營商之間同時進行廣播。
以上就是四層TGW產品及功能,山海網關在原有產品基礎上做了網絡架構方面的演進。
4、Region EIP的引入
具體介紹下EIP和CLB兩個產品。
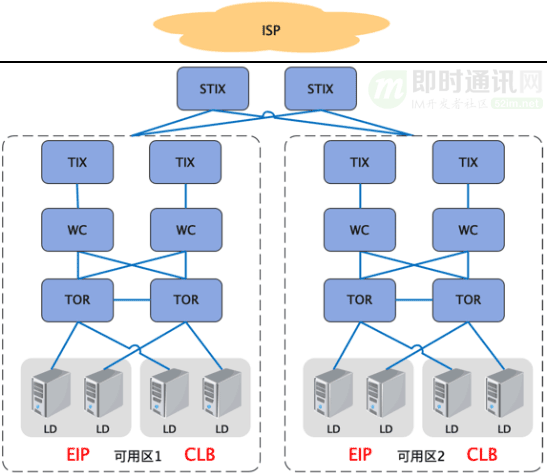
過去CLB和EIP使用不同的IP地址池,導致資源池上的隔離問題。使得我們無法把EIP地址綁定到公有云CLB實例上。
例如:一個創業公司最初只購買一臺虛擬機并掛載一個公網EIP來提供服務。隨著用戶量的增長,如果想將這個EIP地址遷移到一個公網CLB實例上,在原有架構下是無法實現這種遷移的。
此外:EIP和CLB部署在每個機房,因此在每個機房都需要建立EIP出口。但是各個機房的公網出口之間缺無法相互容災。
所以這種情形下,我們確定了產品的目標:
- 1)希望將所有公網出口整合到一到兩個機房之內,以避免重復建設,節省成本;
- 2)通過將出口集中,我們可以將對應的網關服務器也進行集中,進而提高設備的利用率;
- 3)通過這樣的布局可實現跨機房的容災方案。
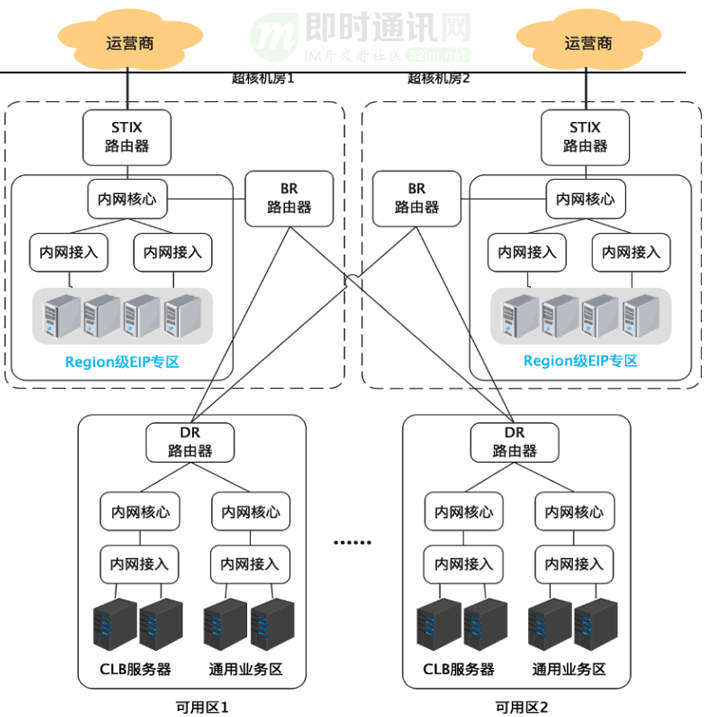
因此:最早的Region EIP(REIP)計劃應運而生。
以北京這類大型region為例的:我們將EIP專區建設到位于兩個城市的超核機房。這兩個機房通常會放置物理網絡的交換設備,并為各自設立了一個REIP專區。在REIP專區內部署Region EIP集群。為了實現跨AZ容災,兩個機房的集群之間借助大小網段實現互相備份容災的能力。一旦其中一個機房的集群發生故障或出現網絡問題,另一個機房的集群可以立即承擔起容災任務。
同時:因為新的Region EIP的網絡架構跟原來的網絡架構不一樣,通過網絡架構升級以及機型升級,我們能夠把單臺Region EIP的性能做到原有單臺EIP性能的5倍。這樣我們通過容量的提升進一步提升了設備利用率,在完成全量Region EIP后,設備數量會從3000+臺縮減至700+臺。同時原有的CLB集群還保留在各個機房不變,這些CLB集群的外網接入能力由Region EIP承擔。
5、公網CLB的演進
5.1概述
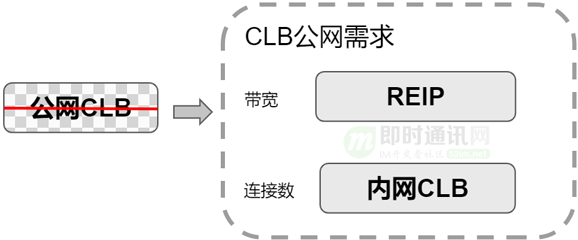
公網CLB最早是有公網接入能力的。引入到Region EIP之后,當初設想是公網CLB不再演進,盡量讓存量用戶遷移到另外一種形式,上層是Region EIP,下層是內網CLB。用戶先買一個內網CLB,如果需要對公網提供服務就再買一個彈性EIP,把EIP跟內網CLB綁定在一起,提供CLB公網的能力,替代原有的公網CLB,這是最早公網CLB的替代方案。
兩個方案的區別是:原有公網CLB,用戶僅看到一個CLB實例。新的模式下,用戶看到的是兩個實例:一個EIP+一個內網CLB,兩個實例都可以獨立運營管理。這就是我們最早的兩層架構設想,想把公網CLB跟外網解耦。
但是,真正去跟用戶或產品交流時,這個想法遇到了比較大的挑戰:
1)用戶體驗的改變:以前公網CLB用戶看到是一個實例,但是現在用戶看到兩個實例,必然會給用戶帶來一些適配工作。比如用戶進行創建、管理實例時,API不一樣了。以前使用通過自動化腳本創建公網CLB實例的,現在腳本還要改變去適配新的API。
2)用戶習慣改變:以前用戶習慣在一個實例下,點擊頁面,就能夠查看流量、鏈接數等監控信息。現在EIP流量需要到REIP查看,而鏈接數還需在CLB產品上看。
3)存量客戶無法遷移:原來客戶買的公網CLB實例,是無法直接無感知遷移到內網CLB+REIP這種新形式的。
在這些挑戰下,這個替代方案沒能真正落地。結合用戶的要求,我們最終跟產品定下的策略是:公網CLB保持不變。原有的公網CLB繼續保留,同時如果用戶新增的公網CLB需求,也要繼續支持。
5.2公網CLB模型
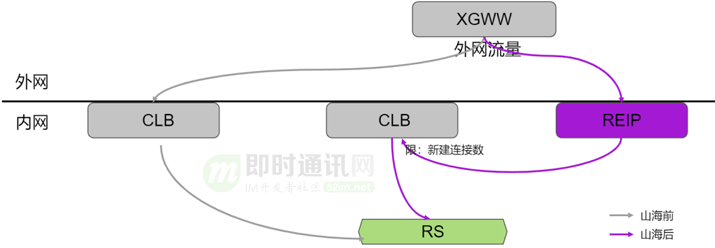
那么,公網CLB到底怎么演變?
我們的初衷并不是把公網CLB這個產品摒棄掉,而是要收斂公網入口。所以我們針對這個初始需求,提出了上面這個兩級架構模型。
首先:用REIP將公網流量先引進來,再將這個流量通過隧道報文的形式轉發給原有的公網CLB集群,這樣公網CLB不需要原有外網接入的能力,不需要再跟外網打交道,可以演變成只在機房內部的集群;同時因為公網CLB的流量都會經過REIP,REIP自然也就是公網CLB的流量入口。從而達到我們最初收斂公網入口的目的。這樣的架構升級,可實現用戶無感知。架構升級切換過程中,用戶在訪問公網CLB,不會出現卡頓或者重連的現象。
這個架構模型也有一定的局限性的。公網CLB實例只能承載公網的流量,無法像上文提到的兩層RERP+CLB那樣,內外網隨時進行轉化。REIP+CLB實例中的CLB既承載內網側CLB的流量,又承載公網側CLB的流量。
6、山海架構 1.0
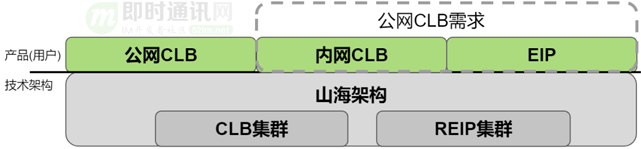
借助這個兩級架構模型,我們能夠把公網CLB保留下來,并且通過REIP把公網入口收斂。
進一步思考并完善,我們提出了下面的想法:跟產品進行解耦。
以前我們一個地區上線公網CLB產品,底層就要搭建有一個公網CLB的集群去支持。用戶需要內網CLB服務,就要對應搭建個內網CLB的集群。底層集群類型跟產品是強耦合,有IPv4/IPv6, 公網/內網、BGP/三網組合出的多個產品形態。
這種模式在小地域部署,因為產品業務的流量小,集群利用率低,就會造成很大的成本壓力。
為了應對這種小帶寬低成本的訴求,我們將CLB+REIP的模型進一步抽象,引入山海架構:我們只建設CLB和REIP兩類集群。通過這兩類集群上的不同實例組合,滿足多個產品形態的要求。從而實現產品形態和底層物理網絡集群類型解耦。
解耦合的方式是:CLB和REIP通過不同的實例類型,組合出不同的產品形態。
山海架構在TGW內部做閉環,不涉及到產品側和用戶側的改動。整個過程升級,對產品側不做任何接口上的更新。因為產品側的API接口保持不變,對用戶側就可以做到完全無感知。在產品側保持不變,就需要我們在內部管控,識別接入用戶實例是哪種形態的產品,拆分成不同形式的CLB和REIP的實例。其他的相關功能的比如流量統計、限速等模塊也都要適配不同的產品形態,通過模塊的適配,做到山海架構對上層產品側應用的透明。
山海架構1.0歸納起來有兩個重點:收斂公網入口和集群類型歸一。
1)REIP:部署在城核機房,同時承載的是CLB和REIP兩類產品的公網流量。之前EIP,在物理網絡上有BGP+三網、v4/v6等多種集群類型。REIP借助vlan的隔離支持,把所有的網絡類型都集中到一種REIP集群上來,我們稱之為全通集群。在物理網絡層面實現網絡類型的歸一, 然后再通過軟件層的適配,實現REIP支持多通類型的網絡接入能力。
2)CLB:在山海兩級架構下,REIP集群處理公網側的各種場景組合,CLB集群通過隧道與REIP處理公網流量。之前一個機房如果要把所有的產品能力支持起來,大概有7種集群類型。現在CLB集群可以用一種集群類型來支持所有的產品的公網CLB產品,以及內網CLB產品的能力。我們把三網+BGP以及內外網還有V4V6等集群類型都用一種類型來支持,山海架構完全落地后,開區的最小服務器數量可以降低到8臺服務器,來承載所有的EIP和CLB產品需求。
歸納起來一句話:對于用戶來說,產品形態沒有改變,用戶使用習慣也沒有改變。而在底層,我們把集群類型收斂到一個CLB集群和一個REIP集群上。
7、山海架構1.0限速技術
在山海架構演進中,有許多技術點,本文選取限速技術進行分享。

首先Region EIP支持三網。以前BGP跟三網分開獨立支持,山海網關統一用Region EIP支持。Region EIP本身的網絡架構分成兩個機房,每個機房放4臺TGW設備,每個EIP只會走左邊或者右邊。一個EIP進來的流量經過上面這層交換機時,經過了ECMP分流,然后分到了4臺設備上。這樣對每個EIP其實是采用了分布式限速。
限速有兩個要求:
- 1)精確性,限速上下浮動要小,要限得準;
- 2)要有容災能力。
限速最極端的精準就是把它放到單點上去做限速,但是單點限速就會面臨單點故障和容災的問題。在X86服務器上,使用的是分布式限速,一個EIP均分到4臺服務器上,每五秒鐘做一次流量的的匯總統計,通過流量比例計算將這個EIP的帶寬配額,重新分配并分發到4臺設備上,以此來實現集群上的限速。在單臺設備上,也是沒隔一段時間,就重新計算配額并分配到每個CPU核上,我們目前用的是300毫秒周期。
需要說明的是:在限速的實現上,業務有多重實現方式,我們了解到有的實現的是靜態分配,比如120兆的帶寬,4臺設備,我們每臺設備分40M(三分之一)的帶寬。1/3而不是1/4的帶寬,目的是防止某一臺設備斷了之后,用戶總帶寬不達標,影響用戶體驗。在單臺設備上限速,也有另外一種實現方式,大小桶。比如限速1M的帶寬,那么每個核第一次取回100K或者200K配額。后續報文處理時候,先消耗上次取回的配額,如果帶寬配額消耗光了,再重新取。周期調整跟大小桶這兩種實現方式各有優缺點。從資源消耗來說,300毫秒周期的資源消耗相對會更少一些,兩者大概有10%左右的性能偏差。
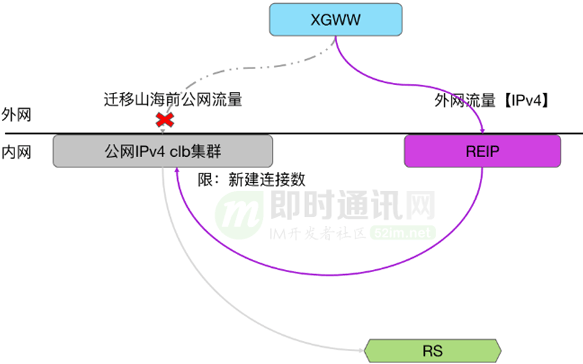
限速上另一訴求:小帶寬的限速的精準限速。
大帶寬比如100兆,分到每個核上相對富裕。小帶寬如一M帶寬,一秒鐘100k字節等,分到四臺機器再分到幾十個核上,每個核都可能不到一個大報,這時候再去做精準限速就會非常困難,因為既然要提前分配資源,資源那么少,分配到單核上,可能一個包都過不去,但凡有一個報文過去了,又可能超了。所以在小帶寬限速時,我們把它退化成類似于單點限速的模式。由于入方向帶寬最小也是100兆,因此保持原有的分布式限速不變。只對出方向小帶寬,使用單點限速。方案是這樣的:
每臺REIP有自己一個獨享的內網地址,只有這臺服務器故障時候,這個地址的流量才被分發到其他三臺服務器。
入方向流量被分到四臺REIP服務器后,REIP處理完通過tunnel轉發給母機。隧道的外層源地址,只使用其中一臺REIP服務器的獨享的IP地址。每個外網IP地址在掛載到集群下管理時候,就確定下來了。
母機在接受到網關發過去的流量,解析外層報文地址,并記錄在本地會話表里,我們稱之為母機的自學習能力。當母機側轉發出方向報文時,就只會使用本地學習并記錄的外層地址去封裝隧道。這樣出方向的流量,就回到單臺TGW設備上,實現了單點限速。
獨享的內網地址本身是有容災能力:
- 1)當其服務器故障了,流量就被分散到集群其他服務器,放棄單點限速;
- 2)當服務器被修復上線后,又可以重新變成精準的單點限速。
這樣保證小帶寬精準限速的同時,又避免了單點故障。
在限速過程中,還有一個問題,因為CLB集群原來的限速是在CLB集群上自己做的,引入山海之后,REIP上有限速能力,那么公網CLB的限速要不要挪到REIP上?
我們經過多次討論, 最終還是維持**這個限速在公網CLB上不變。
這里有幾種場景考量:
1)內外網攻擊:如果我們把它放到REIP上,這里可以扛住外網的攻擊,但同時內網的攻擊我們是防不住的,因為公網CLB上沒有限速后,流量內網的攻擊就會先把CLB上壓過載,導致丟包,影響業務的穩定性。
2)有效流量的準確統計:原有架構下,從公網流量首先到達CLB,我們需要檢查公網CLB上與port對應的服務是否已配置規則并啟用。如果沒有啟用,則將報文直接丟棄且不記錄為公網CLB的帶寬使用量。山海架構下,如果先經過Region EIP限速,這類無服務訪問流量(如惡意攻擊和垃圾流量)也將占用限速資源。盡管這部分限速流量會送達至CLB集群,但由于缺乏相應服務支持,它們最終還是將被丟棄。結果導致用戶帶寬不及預期。比如用戶購買10M帶寬,實際有效運行的僅有8M流量,而其余2M被無服務流量占用了。
3)多重限速的影響:還有一個這個場景中,當Region EIP實施帶寬限速后,這些流量最終可能進入公網CLB。然而,由于CLB的規格限制,例如新建連接數或并發連接數已達到上限,部分數據包可能會被丟棄。這些丟失的數據包已經消耗了購買的公網帶寬,從而導致用戶觀察到的公網CLB流量帶寬未達到預期。因此,我們保留公網CLB限速功能不變,僅進行引流調整。
8、山海架構1.0的優勢
CLB產品及REIP產品,在使用山海1.0之后的幾點優勢。
1)CLB產品本身支持熱遷移,擴容到山海熱遷移,不會引起用戶的斷流,有助于運維做用戶產品升級迭代。這方面有個典型案例,比如某臺設備壞了或者發現某臺設備上有問題,需要把流量遷走的時候,我們可以不用中斷用戶的流量的。我們了解到,以前有的競品,因為熱遷移做的不是特別完善,在設備出現問題或者是需要升級版本的時候,常選擇低峰期做升級。
2)EIP在做限速的時候,在出方向時是小帶寬,可以做到比較精準的限速。好處是用戶做壓測或測試的時,帶寬不會抖動影響自己的業務的穩定性。
3)高低優先級限速。用戶買一些比較小的比如10M帶寬或者5M帶寬,用來服務本身業務,同時也會ssh或者遠程桌面登錄EIP;因為一起我們是做無差別的限速丟包的話,這樣會造成它本身的控制流量,如遠程桌面的流量也會被丟包,造成登錄的卡頓。用戶需要在不超限速的前提下,優先保證遠程桌面不卡,然后再提供其他的下載服務。我們把流量根據端口進行區分,比如22端口或者是遠程桌面的3389端口的流量,標記為高優先級。在做限速時,只要高優先流量不超限速,就全部放行。當高優先級流量再疊加上低優先級的流量超限速時,把低優先級的流量丟掉,這樣ssh訪問服務器的時候能夠非常順暢。
4)山海架構上線后,基于vip粒度的調度,可以讓調度更加靈活。比如原來一個集群為了節省路由條目,我們按照一個網段發路由,不是每個VIP都發路由的。山海兩級架構之后,沒有了這個限制,就可以按照VIP,把CLB實例調度到不同CLB集群。這樣如果用戶需要一個特別大規格的VIP的時候,我們可用一個集群的能力去扛用戶一個VIP,從而滿足超大規格實例的訴求。當然真實使用產品時,很少有客戶把上百G的流量用一個VIP來承載。用戶出于容災考慮,通常不會把所有的雞蛋放到一個籃子里。
9、山海架構 2.0
9.1概述
如前所述:山海 1.0 主要目標是整合公共網絡并將所有公網出口集中在城市核心機房內。至于剩余的 CLB 群集,我們會繼續將其保存在原有各機房的專區里。這是因為網關設備有其與服務器不同的網絡訴求,例如普通服務器不能提供發布動態路由,并通過動態路由引流處理業務流量。
再比如:網關專區的收斂比1:1,而服務器雖然帶寬也是100G, 但其收斂比率往往小于1:1。
在這種情況下,我們不能簡單地將 CLB 網關群集群平移放置到服務器區。因此,CLB 網關群集通常在構建每個機房時,預先規劃并預留相應的網關專區。機房建設起來后,如業務量小,又會因預留資源空置造成浪費。目前專區閑置機位也是一筆較大的費用。
同時,還有一種臨時擴容的需求場景,例如VIP大客戶,臨時會有大流量的轉發需求,這時常態運營水位沒法滿足需要,需要調配設備做集群擴容。如果本機房的設備不夠還需要跨機房搬遷,搬遷周期比較長,對我們運營壓力會很大。
所以,我們希望通過山海2.0能把專區建設的空置率降下來,同時提升彈性,能夠低成本的快速擴縮容。
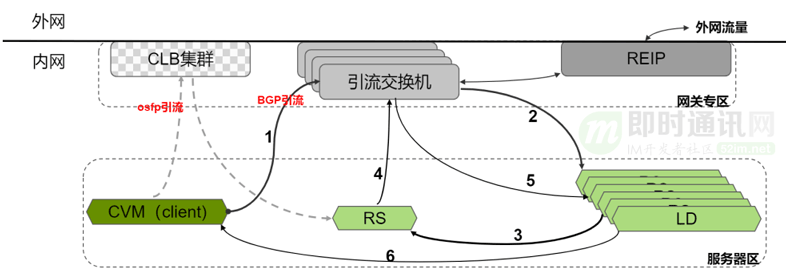
9.2引流交換機
在山海 2.0里,我們采用了“引流交換機”。在每個機房的建設時,我們可以放置兩組共四臺引流交換機。
考慮到單個交換機的容量可以達到 1 T 以上,有四臺交換機工作,一個機房能夠承受大約 4T~ 6T 的流量峰值。這意味著后續無需再額外擴容,一次性的建設和布局就可以滿足長期的需求。相比于 CLB 群集占用的機位空間,四臺交換機所需的機位顯著減少。
我們把原來CLB集群對外聲明路由的能力放到了引流交換機上,把CLB服務器用用通用服務器區的設備來代替。考慮收斂比和容災,不會把一個集群放到一兩個機架上,會相對分散些,更不會把整個機架全部再用成CLB集群。這樣CLB集群不再單獨建設網關專區,引流交換機把路由聲明發出去,通過隧道跟CLB設備轉發流量。
9.3山海2.0的變化
我們以內網CLB為例,原來一臺虛擬機訪問CLB集群,CLB集群把它的流量轉到對應的RS。
引入交換機之后,其進出兩個方向都會有變化:入方向(訪問LB方向),虛擬機的流量先被引流到了引流交換機,交換機把報文做一次封裝,然后發送給對應的服務器,進行負載均衡轉換。最后處理后的結果,被轉發給真正的RS。原來的兩跳訪問變成了現在的三跳。同樣反方向流量返回時,RS的流量先回到引流交換機,然后被分發到對應的LD設備上。LD處理完之后,再把報文直接轉到client虛擬機上。借助引流交換機的中轉,我們就能夠讓負載均衡的專區設備的放到普通的服務器區里。
另外:這里的CLB服務器,可以跟其他的網關包括母機復用一些相同機型的服務器,當需要擴容時,就可以使用通用服務器。而不像以前CLB既有自己獨立的機型,又對服務器的物理位置有要求。有了引流交換機跟LD之間是做隧道傳輸,LD具體的物理位置就沒有像原來一樣有硬性的要求。這樣CLB可以通過通用服務器區域,調配服務器。
最后一項是:原有跟REIP類似的,CLB設備做路由通告時,也是按照網段通告,有引流交換機之后,我們可以在引流交換機上去做細粒度的調度,一個VIP或是幾個vip放到一個集群。還可以在引流交換機上做更細粒度的調度,如IP+port這樣的五元組的粒度的調度。
10、未來展望
目前網關設備最重要也是最大的一個方向就是做高性能、硬件卸載。依賴硬件來實現高性能的轉發。
網關設備分為有狀態和無狀態兩種:
- 1)無狀態設備就像IP轉換一樣,只要依據規則,任何時刻來了報文,轉換出來的形式都是固定的;
- 2)有狀態設備是需要記錄TCP、 UDP狀態,記錄轉發到后端設備,當不同的時間轉發即使相同的類型的流量,它轉發的目的地也不一樣,轉換的格式也可能不一樣。
硬件卸載在有狀態和無狀態時,基本上用到的設備都是DPU和交換機,用到的介質幾乎都是FPGA。
FPGA和ASIC本質上是一個東西,無論友商還是我們自己內部研發,更多的是FPGA上做功能,并小規模的灰度上線驗證,一旦穩定下來,就轉化成批量的ASIC,以此來降低成本。
DPU和交換機在無狀態設備上,交換機相對更有優勢,因為無狀態設備對容量的要求相對小些,像EIP網關以及內部無狀態的網關大多用交換機形態實現。DPU目前更多的用在母機側,做有狀態類的網絡處理。當然, 采用DPU不僅僅局限網絡訴求,還有存儲安全等其他需求。去年英特爾宣布已不再進行交換機tf芯片的演進迭代,大家對交換機的質疑會增大。
所以,也衍化了另一種方案:在一臺額外的服務器中插入 DPU 網卡以實現卸載功能。
但不同方案有不同的優缺點:
1)使用交換機的最大優勢在于其強大的交換性能(可達 1T或幾個T及更高),可支持很大的接入容量。但是,交換機僅能是一個底座,若要擴展容量仍需依賴 FPGA 技術。
2) DPU 的優點則包括成熟的產業鏈、龐大的產量以及穩定的供應保障;此外,由于 DPU 在母機側已被廣泛驗證和采用,許多功能的實現都相對固定。
這是兩種方案各自的優缺點。
在兩個產品運用負載均衡狀態的交換上,業內不同的廠家也有不同的玩法,有的是交換機,有的是DPU。當前,無論是交換機還是 DPU,都依賴FPGA(ASIC)來做大容量的會話管理,同時越來越多的設備或多或少的支持P4。在 X86 上進行編程時,通常選擇 DPDK。
相較之下:使用 P4 進行編程的門檻較低。P4 編寫一般功能需求的代碼非常簡單快捷,只需一兩周時間即可完成,甚至對于熟練者來說,可以在幾個小時就開發出一個小功能。雖然充分發揮硬件的性能,P4類芯片還需要進行很深入細節的研究,但P4還是大大降低了數據面編程的門檻,特別是在高性能轉發的需求方面。
另一個特點是:小型化。大家過去比較關注數據中心和海量數據的優化問題,隨著業務發展,逐步轉向降低運營成本和提高效率的場景,開設小型站點。這類小型站點,是典型的“麻雀雖小,五臟俱全”,希望用盡量少的設備成本來滿足各種功能需求。所以我們將設備設計為具有較小規格的產品系列,并在易用性上進行改進,通過集群合并、虛擬機等承擔更多的任務負載。這樣在業務規模和流量不大,也能以較少的資源應對較高的功能性需求。一旦業務規模擴大,我們可將這些小型站點升級為傳統的數據中心級物理設備。
以上未來網關兩個主要的方向。
11、相關資料
[1] IPv6技術詳解:基本概念、應用現狀、技術實踐(上篇)
[2] 網絡編程入門從未如此簡單(三):什么是IPv6?漫畫式圖文,一篇即懂!
[3] 網絡編程懶人入門(十五):外行也能讀懂的網絡硬件設備功能原理速成
[4] 腦殘式網絡編程入門(六):什么是公網IP和內網IP?NAT轉換又是什么鬼?
[5] 腦殘式網絡編程入門(七):面視必備,史上最通俗計算機網絡分層詳解
[6] 以網游服務端的網絡接入層設計為例,理解實時通信的技術挑戰
[7] 百度統一socket長連接組件從0到1的技術實踐
[8] 淘寶移動端統一網絡庫的架構演進和弱網優化技術實踐
[9] 百度APP移動端網絡深度優化實踐分享(二):網絡連接優化篇
[10] 新手入門:零基礎理解大型分布式架構的演進歷史、技術原理、最佳實踐
[11] 一套高可用、易伸縮、高并發的IM群聊、單聊架構方案設計實踐
(本文已同步發布于:http://www.52im.net/thread-4641-1-1.html)