1、引言
在《IM消息ID技術專題》系列文章的前幾篇中,我們已經深切體會到消息ID在分布式IM聊天系統中的重要性以及技術實現難度,各種消息ID生成算法及實現雖然各有優勢,但受制于具體的應用場景,也并不能一招吃遍天下,所以真正在IM系統中該如何落地消息ID算法和實現邏輯,還是要因地致宜,根據自已系統的設計邏輯和產品定義取其精華,綜合應用之。
本文將基于網易嚴選的訂單ID使用現狀,分享我們是如何結合業內常用的分布式ID解決方案,從而在此基礎之上進行ID特性豐富,并不斷提升系統可用性和穩定性保障。同時,也對ID生成算法的落地實踐過程中遇到坑進行了深入剖析。
本篇中的訂單ID雖然不同于IM系統中的消息ID,但其技術實踐仍然相通,希望能給你的IM系統消息ID技術選型也來更多的啟發。
(本文已同步發布于:http://www.52im.net/thread-4069-1-1.html)
2、關于作者
西狂:服務端研發工程師, 早期參與嚴選采購、嚴選財務、嚴選合伙人以及報警平臺等系統后端建設,目前主要致力于嚴選交易域技術演進以及業務研發工作。
3、系列文章
本文是系列文章中的第7篇,本系列總目錄如下:
4、為什么需要分布式ID?
4.1 業務背景
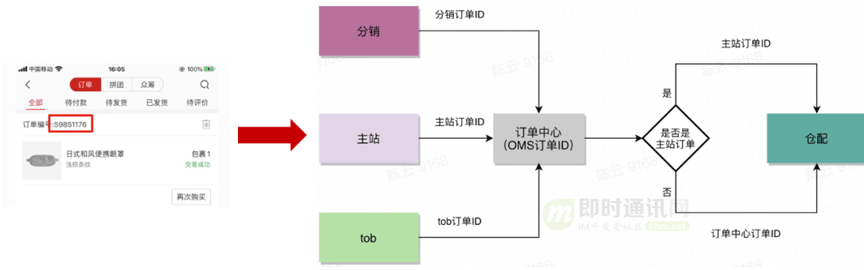
如上圖所示,對于網易嚴選的主站、分銷和tob都會生成各自的訂單ID,在同步訂單數據到訂單中心的時候,訂單中心會生成一個訂單中心內部的一個訂單號,只是推送給到下游倉配時使用的訂單ID略有不同。
4.2 帶來的問題
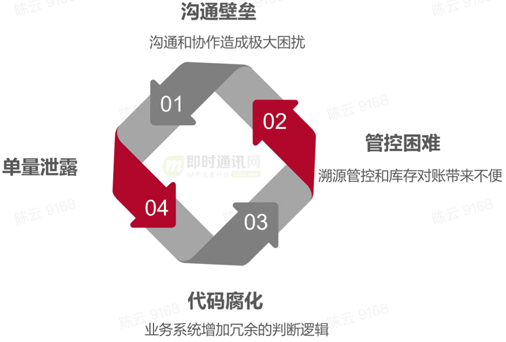
因為訂單ID使用的混亂,導致了一系列問題的產生,例如: 溝通壁壘 、管控困難以及代碼腐化等等。
4.3 技術目標

我們希望通過分布式ID來幫助生成訂單ID,在業務規則上必須全局唯一、安全性高,在性能上要高可用、低延遲。
5、我們的分布式ID架構原理
5.1 技術選型
下表是業內常見的分布式ID解決方案:
綜合考慮是否支持水平擴展以及能夠顯示指定ID長度,最終選擇的是Leaf的Segment模式(詳見《深度解密美團的分布式ID生成算法》)。
5.2 架構簡介
Leaf采用了預分發的方式來生成ID(如下圖所示),在DB之上搭載若干個Server,每個Server在啟動的時候,都會去DB中拿固定長度的ID列表,存放于內存中,因為ID是基于內存分發的,所以可以做到很高效。
在數據持久化方面,每次去DB拿固定長度的ID列表,只是把最大的ID持久化。
整體架構實現比較簡單,主要是為了盡快解決業務層DB壓力的問題,但是在生產環境中也暴露出一些問題。
比如:
- 1)TP999數據波動大,當號段使用完之后還是會hang在更新數據庫的I/O上,tp999數據會出現偶爾的尖刺;
- 2)當更新DB號段的時候,如果DB宕機或者發生主從切換,會導致一段時間的服務不可用。
5.3 可用性優化
為了解決上面提到這個兩個問題,引入雙Buffer機制和異步更新策略,當一個Buffer消耗到某個臨界點時,就會異步的觸發任務,把下一個號段加載到內存中。
保證無論何時DB出現問題,都能有一個Buffer的號段可以正常對外提供服務,只要DB在一個Buffer的下發的周期內恢復,就不會影響整個Leaf的可用性。
5.4 步長動態調整
號段長度在固定不變的前提下,流量的突增和銳減都會使得正常流量下維持原有號段正常工作的時間縮短和提升。
可以嘗試使用以下關系表達式來描述:
Q * T = L
(Q:服務qps L:號段長度 T:號段更新周期)
但是Leaf的本質是希望T固定,如果Q和L可以正相關,T就可以趨于一個定值。
所以在Leaf每次更新號段的時候,會根據上一次號段更新的周期T和號段長度step,來決定下一次號段長度nextStep。
如下所示:
T < 15min,nextStep = step * 2
15min < T < 30min,nextStep = step
T > 30min,nextStep = step / 2
(初始指定step <= nextStep <= 最大值(自定義:100W))
6、我們做了什么改進?
6.1 特性豐富
通過結合嚴選的實際業務場景,進行了特性化支持,例如支持批量ID獲取、大促提前擴容以及提前跳段處理。
6.2 可用性保障
1)針對DB:
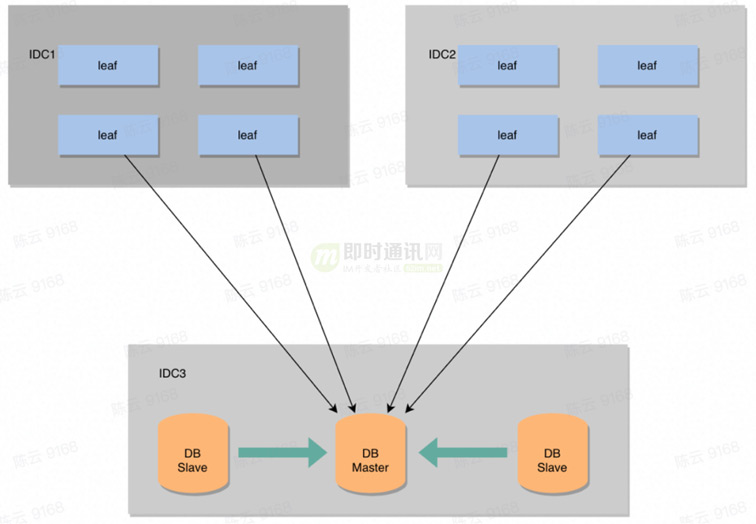
DB(MySql)采用主從模式(讀寫分離、降低主庫壓力),一主兩從的配置方式,Master和Slave之間采用的是半同步復制(數據一致性要求,后期可考慮使用MySql Group Replication)。同時還添加了雙1配置,保證不丟數據。
2)引入SDK:
通過引入SDK可以降低各個業務方的接入成本、降低Leaf服務端壓力以及在Leaf服務不可用時,客戶端起到短暫降級的效果。
SDK的實現原理和Leaf類似,在項目啟動之初會加載業務關心參數配置信息,在應用構建本地緩存,同樣采用了雙Buffer存儲模式。
6.3 穩定性保障
1)運維方面:
主要分為3個方面:
- 1)日志監控:可以幫助發現預期之外的異常情況;
- 2)流量監控:流有助于號段長度的評估范圍,預防號段被快速消費的極端場景;
- 3)線上巡檢:可以時刻對服務進行存活校驗。
2)SLA高可用方面:
除了運維之外還做了SLA的接入,通常用SLA來衡量系統的穩定性,除此之外我們還按照接口維度設定了SLO目標規則,目前的指標項比較單一只有請求延遲和錯誤率這兩項。
7、我們遇到的坑
7.1 問題發現
如下圖所示,我們發現每次服務啟動上線接口的rt(響應時間)都要比平時高的多,但是過了一段時間之后卻又恢復成正常水平。
7.2 問題探究
在分析之前,我們可以先簡單的回顧下java虛擬機是如何運行Java字節碼的。
虛擬機視角下Java字節碼如何被虛擬機運行:
Java虛擬機將class文件加載到虛擬機中,然后將字節碼翻譯成機器碼給底層硬件執行,而這里的翻譯有兩種形式,解釋執行和編譯執行。前者的優勢在于無需等待編譯,后者的優勢在于實際運行速度更快。HotSpot默認采用混合模式,它會先解釋執行字節碼,然后將其中反復執行的熱點代碼,以方法為單位進行即時編譯,JVM是依據方法的調用次數以及循環回邊的執行次數來觸發JIT編譯的。
在Java7之前我們可以根據程序的特性選擇對應的即時編譯器。Java7開始引入分層編譯機制(-XX:+TieredCompilation):綜合了C1的啟動性能優勢和C2的峰值性能優勢。
分層編譯將JVM的執行狀態分為了5個層次:
- L0:解釋執行(也會profiling);
- L1:執行不帶profiling的C1代碼;
- L2:執行僅帶方法調用次數和循環回邊執行次數profiling的C1代碼;
- L3:執行帶所有profiling的C1代碼;
- L4:執行C2代碼。
對于C1編譯的三個層次,按執行效率從高至低:L1 > L2 > L3, 這是因為profiling越多,額外的性能開銷越大。通常情況下,C2代碼的執行效率比C1代碼高出30%以上。(這里需要注意的是Java8默認開啟了分層編譯)
這張圖列出了常見的分層編譯的編譯路徑:
- 1)通常情況下,熱點方法會被第三層的C1編譯器編譯,再被C2編譯器編譯(0-> 3-> 4);
- 2)如果方法的字節數目比較少并且第三層的profilling沒有可收集的數據,jvm會判定該方法對于C1和C2的執行效率相同,在經過3層的C1編譯過后,直接回到1層的C1(0-> 3-> 1);
- 3)在C1忙碌的情況下,JVM在解釋執行過程中對程序進行profiling,而后直接由4層的C2編譯(0-> 4);
- 4)在C2忙碌的情況下,方法會被2層的C1編譯,然后再被3層的C1編譯,以減少方法在3層的執行時間(0-> 2-> 3-> 4)。
上圖是項目啟動時的分層編譯日志以及整個過程接口響應RT。
從圖中可以看到先是執行了C1編譯,再執行C2編譯(日志文件中的3和4分別打標L3和L4),滿足 0->3->4 編譯順序。
發現從C1編譯到C2編譯耗時過程比較長,這符合我們一開始提出的疑問,為什么項目啟動需要經過一段時間接口RT才能趨于穩定。
7.3 解決方案
為了能在項目啟動之初,快速達到接口RT峰值,因此只要盡最大程度縮短解釋執行這個中間過程即可。
相應的解決方案:
- 方案 1:關閉分層編譯,降低編譯閾值;
- 方案 2:Mock接口數據, 快速觸發JIT編譯以及C2編譯;
- 方案 3:Java9 AOT提前編譯。
針對方案3:Java9中支持新特性AOT提前編譯,相比較于JIT即時編譯而言,AOT在運行前就已經編譯好了,避免 JIT 編譯器的運行時性能消耗,同時避免解釋程序的早期性能開銷,可以極大提高java代碼性能。
8、落地使用概況
Leaf已經在線上環境投入使用,各個業務方(包括主站、渠道、tob)也相應接入進行統一整改,自此嚴選訂單ID生成得到統一收攏。
在整個嚴選的落地情況,按照業務維度,目前累計接入3個業務,分別是訂單ID、訂單快照ID、訂單商品快照ID,都經受住了雙十一和雙十二考驗。
9、參考資料
[1] 微信的海量IM聊天消息序列號生成實踐(算法原理篇)
[2] 解密融云IM產品的聊天消息ID生成策略
[3] 深度解密美團的分布式ID生成算法
[4] 深度解密滴滴的高性能ID生成器(Tinyid)
(本文已同步發布于:http://www.52im.net/thread-4069-1-1.html)