本文由微信開發團隊工程師“ qiuwenchen”分享����,發布于WeMobileDev公眾號����,有修訂�。
1�����、引言
全文搜索是使用倒排索引進行搜索的一種搜索方式���。倒排索引也稱為反向索引����,是指對輸入的內容中的每個Token建立一個索引��,索引中保存了這個Token在內容中的具體位置�。全文搜索技術主要應用在對大量文本內容進行搜索的場景���。
微信終端涉及到大量文本搜索的業務場景主要包括:im聯系人���、im聊天記錄����、收藏的搜索。
這些功能從2014年上線至今,底層技術已多年沒有更新:
- 1)聊天記錄使用的全文搜索引擎還是SQLite FTS3���,而現在已經有SQLite FTS5;
- 2)收藏首頁的搜索還是使用簡單的Like語句去匹配文本;
- 3)聯系人搜索甚至用的是內存搜索(在內存中遍歷所有聯系人的所有屬性進行匹配)�。
隨著用戶在微信上積累的im聊天數據越來越多��,提升微信底層搜索技術的需求也越來越迫切。于是,在2021年我們對微信iOS端的全文搜索技術進行了一次全面升級�,本文主要記錄了本次技術升級過程中的技術實踐��。

學習交流:
(本文同步發布于:http://www.52im.net/thread-3839-1-1.html)
2、系列文章
本文是專題系列文章中的第4篇:
3、全文檢索引擎的選型
iOS客戶端可以使用的全文搜索引擎并不多,主要有:
這里給出了這些引擎在事務能力���、技術風險����、搜索能力����、讀寫性能等方面的比較(見下圖)。
1)在事務能力方面:
Lucene沒有提供完整的事務能力�����,因為Lucene使用了多文件的存儲結構����,它沒有保證事務的原子性。
而SQLite的FTS組件因為底層還是使用普通的表來實現的����,可以完美繼承SQLite的事務能力���。
2)在技術風險方面:
Lucene主要應用于服務端����,在客戶端沒有大規模應用的案例���,而且CLucene和Lucy自2013年后官方都停止維護了�����,技術風險較高��。
SQLite的FTS3和FTS4組件則是屬于SQLite的舊版本引擎,官方維護不多了���,而且這兩個版本都是將一個詞的索引存到一條記錄中,極端情況下有超出SQLite單條記錄最大長度限制的風險�。
SQLite的FTS5組件作為最新版本引擎也已經推出超過六年了���,在安卓微信上也已經全量應用��,所以技術風險是最低的。
3)在搜索能力方面:
Lucene的發展歷史比SQLite的FTS組件長很多�,搜索能力相比也是最豐富的�。特別是Lucene有豐富的搜索結果評分排序機制�,但這個在微信客戶端沒有應用場景。因為我們的搜索結果要么是按照時間排序����,要么是按照一些簡單的自定義規則排序����。
在SQLite幾個版本的引擎中���,FTS5的搜索語法更加完備嚴謹���,提供了很多接口給用戶自定義搜索函數�,所以搜索能力也相對強一點。
4)在讀寫性能方面:
下面3個圖是用不同引擎對100萬條長度為10的隨機生成中文語句生成Optimize狀態的索引的性能數據��,其中每個語句的漢字出現頻率按照實際的漢字使用頻率�。
從上面的3張圖可以看到:Lucene讀取命中數量的性能比SQLite好很多,說明Lucene索引的文件格式很有優勢���,但是微信沒有只讀取命中數量的應用場景。Lucene的其他性能數據跟SQLite的差距不明顯�。SQLite FTS3和FTS5的大部分性能很接近�����,FTS5索引的生成耗時比FTS3高一截���,這個有優化方法�����。
綜合考慮這些因素:我們選擇SQLite FTS5作為iOS微信全文搜索的搜索引擎���。
4�、引擎層優化1:實現FTS5的Segment自動Merge機制
SQLite FTS5會把每個事務寫入的內容保存成一個獨立的b樹�����,稱為一個segment��,segment中保存了本次寫入內容中的每個詞在本次內容中行號(rowid)、列號和字段中的每次出現的位置偏移,所以這個segment就是該內容的倒排索引。
多次寫入就會形成多個segment,查詢時就需要分別查詢這些segment再匯總結果�,從而segment數量越多���,查詢速度越慢�����。
為了減少segment的數量,SQLite FTS5引入了merge機制。新寫入的segment的level為0�����,merge操作可以把level為i的現有segment合并成一個level為i+1的新的segment�。
merge的示例如下:
FTS5默認的merge操作有兩種:
- 1)automerge:某一個level的segment達到4時就開始在寫入內容時自動執行一部分merge操作,稱為一次automerge。每次automerge的寫入量跟本次更新的寫入量成正比�����,需要多次automerge才能完整合并成一個新segment���。Automerge在完整生成一個新的segment前���,需要多次裁剪舊的segment的已合并內容���,引入多余的寫入量�����;
- 2)crisismerge:本次寫入后某一個level的segment數量達到16時�,一次性合并這個level的segment��,稱為crisismerge��。
FTS5的默認merge操作都是在寫入時同步執行的,會對業務邏輯造成性能影響,特別是crisismerge會偶然導致某一次寫入操作特別久,這會讓業務性能不可控(之前的測試中FTS5的建索引耗時較久,也主要因為FTS5的merge操作比其他兩種引擎更加耗時)����。
我們在WCDB中實現FTS5的segment自動merge機制�,將這些merge操作集中到一個單獨子線程執行��,并且優化執行參數���。
具體做法如下:
- 1)監聽有FTS5索引的數據庫每個事務變更到的FTS5索引表��,拋通知到子線程觸發WCDB的自動merge操作;
- 2)Merge線程檢查所有FTS5索引表中segment數超過 1 的level執行一次merge����;
- 3)Merge時每寫入16頁數據檢查一次有沒有其他線程的寫入操作因為merge操作阻塞����,如果有就立即commit�,盡量減小merge對業務性能的影響���。
自動merge邏輯執行的流程圖如下:

限制每個level的segment數量為1�����,可以讓FTS5的查詢性能最接近optimize(所有segment合并成一個)之后的性能�,而且引入的寫入量是可接受的�。假設業務每次寫入量為M,寫入了N次����,那么在merge執行完整之后�,數據庫實際寫入量為MN(log2(N)+1)����。業務批量寫入,提高M也可以減小總寫入量����。
性能方面����,對一個包含100w條中文內容��,每條長度100漢字的fts5的表查詢三個詞�����,optimize狀態下耗時2.9ms,分別限制每個level的segment數量為2�����、3�、4時的查詢耗時分別為4.7ms����、8.9ms、15ms�。100w條內容每次寫入100條的情況下�,按照WCDB的方案執行merge的耗時在10s內����。
使用自動Merge機制��,可以在不影響索引更新性能的情況下,將FTS5索引保持在最接近Optimize的狀態�����,提高了搜索速度����。
5、引擎層優化2:分詞器優化
5.1 分詞器性能優化
分詞器是全文搜索的關鍵模塊��,它實現將輸入內容拆分成多個Token并提供這些Token的位置�,搜索引擎再對這些Token建立索引。SQLite的FTS組件支持自定義分詞器����,可以按照業務需求實現自己的分詞器�。
分詞器的分詞方法可以分為按字分詞和按詞分詞����。前者只是簡單對輸入內容逐字建立索引,后者則需要理解輸入內容的語義���,對有具體含義的詞組建立索引���。相比于按字分詞�����,按詞分詞的優勢是既可以減少建索引的Token數量���,也可以減少搜索時匹配的Token數量�,劣勢是需要理解語義���,而且用戶輸入的詞不完整時也會有搜不到的問題�。
為了簡化客戶端邏輯和避免用戶漏輸內容時搜不到的問題,iOS微信之前的FTS3分詞器OneOrBinaryTokenizer是采用了一種巧妙的按字分詞算法,除了對輸入內容逐字建索引��,還會對內容中每兩個連續的字建索引�����,對于搜索內容則是按照每兩個字進行分詞�����。
下面是用“北京歡迎你”去搜索相同內容的分詞例子:
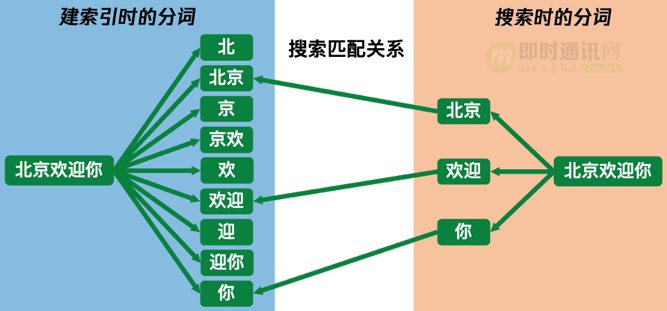
相比于簡單的按字分詞,這種分詞方式的優勢是可以將搜索時匹配的Token數量接近降低一半�����,提高搜索速度����,而且在一定程度上可以提升搜索精度(比如搜索“歡迎你北京”就匹配不到“北京歡迎你”)�����。這種分詞方式的劣勢就是保存的索引內容很多�����,基本輸入內容的每個字都在索引中保存了三次,是一種用空間換時間的做法���。
因為OneOrBinaryTokenizer用接近三倍的索引內容增長才換取不到兩倍的搜索性能提升,不是很劃算����,所以我們在FTS5上重新開發了一種新的分詞器VerbatimTokenizer��,這個分詞器只采用基本的按字分詞,不保存冗余索引內容�����。同時在搜索時,每兩個字用引號引起來組成一個Phrase��,按照FTS5的搜索語法�����,搜索時Phrase中的字要按順序相鄰出現的內容才會命中�,實現了跟OneOrBinaryTokenizer一樣的搜索精度��。
VerbatimTokenizer的分詞規則示意圖如下:
5.2 分詞器能力擴展
VerbatimTokenizer還根據微信實際的業務需求實現了五種擴展能力來提高搜索的容錯能力:
1)支持在分詞時將繁體字轉換成簡體字:這樣用戶可以用繁體字搜到簡體字內容�,用簡體字也能搜到繁體字內容��,避免了因為漢字的簡體和繁體字形相近導致用戶輸錯的問題�。
2)支持Unicode歸一化:Unicode支持相同字形的字符用不同的編碼來表示���,比如編碼為\ue9的é和編碼為\u65\u301的é有相同的字形�����,這會導致用戶用看上去一樣的內容去搜索結果搜不到的問題。Unicode歸一化就是把字形相同的字符用同一個編碼表示�����。
3)支持過濾符號:大部分情況下���,我們不需要支持對符號建索引��,符號的重復量大而且用戶一般也不會用符號去搜索內容��,但是聯系人搜索這個業務場景需要支持符號搜索,因為用戶的昵稱里面經常出現顏文字���,符號的使用量不低。
4)支持用Porter Stemming算法對英文單詞取詞干:取詞干的好處是允許用戶搜索內容的單復數和時態跟命中內容不一致�,讓用戶更容易搜到內容�����。但是取詞干也有弊端,比如用戶要搜索的內容是“happyday”��,輸入“happy”作為前綴去搜索卻會搜不到��,因為“happyday”取詞干變成“happydai”�,“happy”取詞干變成“happi”���,后者就不能成為前者的前綴��。這種badcase在內容為多個英文單詞拼接一起時容易出現�����,聯系人昵稱的拼接英文很常見���,所以在聯系人的索引中沒有取詞干�����,在其他業務場景中都用上了���。
5)支持將字母全部轉成小寫:這樣用戶可以用小寫搜到大寫�����,反之亦然。
這些擴展能力都是對建索引內容和搜索內容中的每個字做變換,這個變換其實也可以在業務層做,其中的Unicode歸一化和簡繁轉換以前就是在業務層實現的�。
但是這樣做有兩個弊端:
- 1)一個是業務層每做一個轉換都需要對內容做一次遍歷��,引入冗余計算量;
- 2)一個是寫入到索引中的內容是轉變后的內容�,那么搜索出來的結果也是轉變后的���,會和原文不一致�����,業務層做內容判斷的時候容易出錯����。
鑒于這兩個原因���,VerbatimTokenizer將這些轉變能力都集中到了分詞器中實現��。
6、引擎層優化3:索引內容支持多級分隔符
SQLite的FTS索引表不支持在建表后再添加新列,但是隨著業務的發展��,業務數據支持搜索的屬性會變多�,如何解決新屬性的搜索問題呢?
特別是在聯系人搜索這個業務場景,一個聯系人支持搜索的字段非常多。
一個直接的想法是:將新屬性和舊屬性用分隔符拼接到一起建索引。
但這樣會引入新的問題:FTS5是以整個字段的內容作為整體去匹配的�,如果用戶搜索匹配的Token在不同的屬性���,那這條數據也會命中���,這個結果顯然不是用戶想要的�,搜索結果的精確度就降低了�。
我們需要搜索匹配的Token中間不存在分隔符,那這樣可以確保匹配的Token都在一個屬性內。同時���,為了支持業務靈活擴展,還需要支持多級分隔符�,而且搜索結果中還要支持獲取匹配結果的層級�����、位置以及該段內容的原文和匹配詞。
這個能力FTS5還沒有,而FTS5的自定義輔助函數支持在搜索時獲取到所有命中結果中每個命中Token的位置�,利用這個信息可以推斷出這些Token中間有沒有分隔符�,以及這些Token所在的層級���,所以我們開發了SubstringMatchInfo這個新的FTS5搜索輔助函數來實現這個能力���。
這個函數的大致執行流程如下:
7�、應用層優化1:數據庫表格式優化
7.1 非文本搜索內容的保存方式
在實際應用中,我們除了要在數據庫中保存需要搜索的文本的FTS索引,還需要額外保存這個文本對應的業務數據的id、用于結果排序的的屬性(常見的是業務數據的創建時間)以及其他需要直接跟隨搜索結果讀出的內容�,這些都是不參與文本搜索的內容�����。
根據非文本搜索內容的不同存儲位置,我們可以將FTS索引表的表格式分成兩種:
1)第一種方式:是將非文本搜索內容存儲在額外的普通表中,這個表保存FTS索引的Rowid和非文本搜索內容的映射關系���,而FTS索引表的每一行只保存可搜索的文本內容���。
這個表格式類似于這樣:

這種表格式的優勢和劣勢是很明顯�,分別是:
- a)優勢是:FTS索引表的內容很簡單,不熟悉FTS索引表配置的同學不容易出錯��,而且普通表的可擴展性好���,支持添加新列�;
- b)劣勢是:搜索時需要先用FTS索引的Rowid讀取到普通表的Rowid,這樣才能讀取到普通表的其他內容�,搜索速度慢一點���,而且搜索時需要聯表查詢��,搜索SQL語句稍微復雜一點。
2)第二種方式:是將非文本搜索內容直接和可搜索文本內容一起存儲在FTS索引表中�����。
表格式類似于這樣:

這種方式的優劣勢跟前一種方式恰好相反:
- a)優勢是:搜索速度快而且搜索方式簡單�����;
- b)劣勢是:擴展性差且需要更細致的配置��。
因為iOS微信以前是使用第二種表格式,而且微信的搜索業務已經穩定不會有大變化���,我們現在更加追求搜索速度,所以我們還是繼續使用第二種表格式來存儲全文搜索的數據��。
7.2 避免冗余索引內容
FTS索引表默認對表中的每一列的內容都建倒排索引����,即便是數字內容也會按照文本來處理�,這樣會導致我們保存在FTS索引表中的非文本搜索內容也建了索引�����,進而增大索引文件的大小、索引更新的耗時和搜索的耗時�,這顯然不是我們想要的���。
FTS5支持給索引表中的列添加UNINDEXED約束�����,這樣FTS5就不會對這個列建索引了,所以給可搜索文本內容之外的所有列添加這個約束就可以避免冗余索引�����。
7.3 降低索引內容的大小
前面提到����,倒排索引主要保存文本中每個Token對應的行號(rowid)、列號和字段中的每次出現的位置偏移�����,其中的行號是SQLite自動分配的���,位置偏移是根據業務的實際內容����,這兩個我們都決定不了,但是列號是可以調整的���。
在FTS5索引中,一個Token在一行中的索引內容的格式是這樣的:

從中可以看出�,如果我們把可搜索文本內容設置在第一列的話(多個可搜索文本列的話��,把內容多的列放到第一列)�,就可以少保存列分割符0x01和列號,這樣可以明顯降低索引文件大小。
所以我們最終的表格式是這樣:
7.4 優化前后的效果對比
下面是iOS微信優化前后的平均每個用戶的索引文件大小對比:
8�、應用層優化2:索引更新邏輯優化
8.1 概述
為了將全文搜索邏輯和業務邏輯解耦���,iOS微信的FTS索引是不保存在各個業務的數據庫中的����,而是集中保存到一個專用的全文搜索數據庫�,各個業務的數據有更新之后再異步通知全文搜索模塊更新索引。
整體流程如下:

這樣做既可以避免索引更新拖慢業務數據更新的速度,也能避免索引數據更新出錯甚至索引數據損壞對業務造成影響,讓全文搜索功能模塊能夠充分獨立���。
8.2 保證索引和數據的一致
業務數據和索引數據分離且異步同步的好處很多,但實現起來也很難。
最難的問題是如何保證業務數據和索引數據的一致��,也即要保證業務數據和索引數據要逐條對應���,不多不少�。
曾經iOS微信在這里踩了很多坑,打了很多補丁都不能完整解決這個問題,我們需要一個更加體系化的方法來解決這個問題��。
為了簡化問題���,我們可以把一致性問題可以拆成兩個方面分別處理:
- 1)一是保證所有業務數據都有索引��,這個用戶的搜索結果就不會有缺漏�;
- 2)二是保證所有索引都對應一個有效的業務數據�,這樣用戶就不會搜到無效的結果。
要保證所有業務數據都有索引,首先要找到或者構造一種一直增長的數據來描述業務數據更新的進度,這個進度數據的更新和業務數據的更新能保證原子性����。而且根據這個進度的區間能拿出業務數據更新的內容�����,這樣我們就可以依賴這個進度來更新索引。
在微信的業務中,不同業務的進度數據不同:
- 1)聊天記錄是使用消息的rowid�;
- 2)收藏是使用收藏跟后臺同步的updateSequence;
- 3)聯系人找不到這種一直增長的進度數據(我們是通過在聯系人數據庫中標記有新增或有更新的聯系人的微信號來作為索引更新進度)���。
針對上述第3)點,進度數據的使用方法如下:
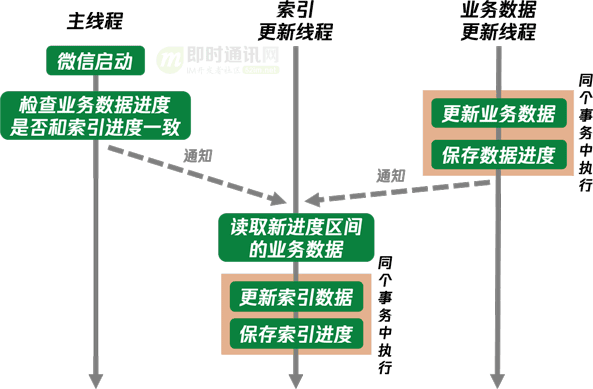
無論業務數據是否保存成功�����、更新通知是否到達全文搜索模塊、索引數據是否保存成功,這套索引更新邏輯都能保證保存成功的業務數據都能成功建到索引����。
這其中的一個關鍵點是數據和進度要在同個事務中一起更新���,而且要保存在同個數據庫中���,這樣才能保證數據和進度的更新的原子性(WCDB創建的數據庫因為使用WAL模式而無法保證不同數據庫的事務的原子性)���。
還有一個操作圖中沒有畫出���,具體是微信啟動時如果檢查到業務進度小于索引進度�,這種一般意味著業務數據損壞后被重置了���,這種情況下要刪掉索引并重置索引進度���。
對于每個索引都對應有效的業務數據���,這就要求業務數據刪除之后索引也要必須刪掉?,F在業務數據的刪除和索引的刪除是異步的,會出現業務數據刪掉之后索引沒刪除的情況����。
這種情況會導致兩個問題:
- 1)一是冗余索引會導致搜索速度變慢,但這個問題出現概率很小�����,這個影響可以忽略不計��;
- 2)二是會導致用戶搜到無效數據��,這個是要避免的。
針對上述第2)點:因為要完全刪掉所有無效索引成本比較高�,所以我們采用了惰性檢查的方法來解決這個問題��,具體做法是搜索結果要顯示給用戶時,才檢查這個數據是否有效���,無效的話不顯示這個搜索結果并異步刪除對應的索引。因為用戶一屏能看到的數據很少��,所以檢查邏輯帶來的性能消耗也可以忽略不計�����。而且這個檢查操作實際上也不算是額外加的邏輯��,為了搜索結果展示內容的靈活性,我們也要在展示搜索結果時讀出業務數據���,這樣也就順帶做了數據有效性的檢查。
8.3 建索引速度優化
索引只有在搜索的時候才會用到�,它的更新優先級并沒有業務數據那么高���,可以盡量攢更多的業務數據才去批量建索引���。
批量建索引有以下三個好處:
- 1)減少磁盤的寫入次數��,提高平均建索引速度;
- 2)在一個事務中��,建索引SQL語句的解析結果可以反復使用����,可以減少SQL語句的解析次數���,進而提高平均建索引速度�;
- 3)減少生成Segment的數量,從而減少Merge Segment帶來的讀寫消耗�。
當然:也不能保留太多業務數據不建索引�,這樣用戶要搜索時會來不及建索引��,從而導致搜索結果不完整��。
有了前面的Segment自動Merge機制�����,索引的寫入速度非常可控����,只要控制好量��,就不用擔心批量建索引帶來的高耗時問題。
我們綜合考慮了低端機器的建索引速度和搜索頁面的拉起時間���,確定了最大批量建索引數據條數為100條。
同時:我們會在內存中cache本次微信運行期間產生的未建索引業務數據���,在極端情況下給沒有來得及建索引的業務數據提供相對內存搜索,保證搜索結果的完整性�����。因為cache上一次微信運行期間產生的未建索引數據需要引入額外的磁盤IO���,所以微信啟動后會觸發一次建索引邏輯��,對現有的未建索引業務數據建一次索引。
總結一下觸發建索引的時機有三個:
- 1)未建索引業務數據達到100條;
- 2)進入搜索界面�;
- 3)微信啟動���。
8.4 刪除索引速度優化
索引的刪除速度經常是設計索引更新機制時比較容易忽視的因素���,因為被刪除的業務數據量容易被低估���,會被誤以為是低概率場景����。
但實際被用戶刪除的業務數據可能會達到50%��,是個不可忽視的主場景�����。而且SQLite是不支持并行寫入的,刪除索引的性能也會間接影響到索引的寫入速度,會為索引更新引入不可控因素。
因為刪除索引的時候是拿著業務數據的id去刪除的�。
所以提高刪除索引速度的方式有兩種:
- 1)建一個業務數據id到FTS索引的rowid的普通索引���;
- 2)在FTS索引表中去掉業務數據Id那一列的UNINDEXED約束,給業務數據Id添加倒排索引。
這里倒排索引其實沒有普通索引那么高效��,有兩個原因:
- 1)倒排索引相比普通索引還帶了很多額外信息��,搜索效率低一些�����;
- 2)如果需要多個業務字段才能確定一條倒排索引時,倒排索引是建不了聯合索引的,只能匹配其中一個業務字段,其他字段就是遍歷匹配,這種情況搜索效率會很低。
8.5 優化前后的效果對比
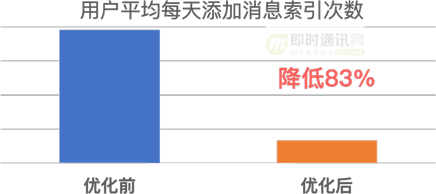
聊天記錄的優化前后索引性能數據如下:


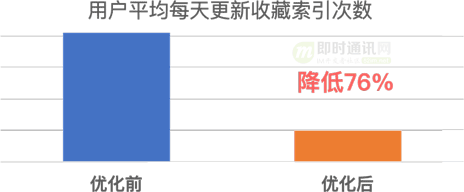
收藏的優化前后索引性能數據如下:


9�����、應用層優化3:搜索邏輯優化
9.1 問題
用戶在iOS微信的首頁搜索內容時�����,交互邏輯如下:
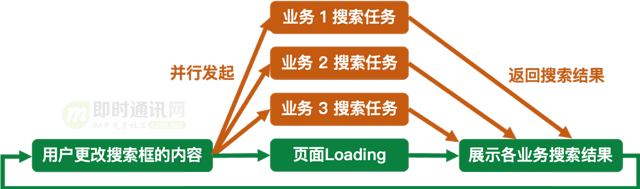
如上圖所示:當用戶變更搜索框的內容之后,會并行發起所有業務的搜索任務���,各個搜索任務執行完之后才再將搜索結果返回到主線程給頁面展示。這個邏輯會隨著用戶變更搜索內容而繼續重復�。
9.2 單個搜索任務應支持并行執行
雖然現在不同搜索任務已經支持并行執行�,但是不同業務的數據量和搜索邏輯差別很大���,數據量大或者搜索邏輯復雜的任務耗時會很久�����,這樣還不能充分發揮手機的并行處理能力����。
我們還可以將并行處理能力引入單個搜索任務內,這里有兩種處理方式:
1)對于搜索數據量大的業務(比如聊天記錄搜索):可以將索引數據均分存儲到多個FTS索引表(注意這里不均分的話還是會存在短板效應)����,這樣搜索時可以并行搜索各個索引表��,然后匯總各個表的搜索結果,再進行統一排序。這里拆分的索引表數量既不能太多也不能太少,太多會超出手機實際的并行處理能力��,也會影響其他搜索任務的性能���,太少又不能充分利用并行處理能力���。以前微信用了十個FTS表存儲聊天記錄索引�����,現在改為使用四個FTS表。
2)對于搜索邏輯復雜的業務(比如聯系人搜索):可以將可獨立執行的搜索邏輯并行執行(比如:在聯系人搜索任務中���,我們將聯系人的普通文本搜索、拼音搜索�、標簽和地區的搜索����、多群成員的搜索并行執行��,搜完之后再合并結果進行排序)���。這里為什么不也用拆表的方式呢���?因為這種搜索結果數量少的場景�,搜索的耗時主要是集中在搜索索引的環節���,索引可以看做一顆B樹��,將一顆B樹拆分成多個�����,搜索耗時并不會成比例下降。
9.3 搜索任務應支持中斷
用戶在搜索框持續輸入內容的過程中可能會自動多次發起搜索任務���,如果在前一次發起的搜索任務還沒執行完時,就再次發起搜索任務����,那前后兩次搜索任務就會互相影響對方性能�。
這種情況在用戶輸入內容從短到長的過程中還挺容易出現的�,因為搜索文本短的時候命中結果就很多,搜索任務也就更加耗時���,從而更有機會撞上后面的搜索任務��。太多任務同時執行還會容易引起手機發燙��、爆內存的問題。
所以我們需要讓搜索任務支持隨時中斷,這樣就可以在后一次搜索任務發起的時候�,能夠中斷前一次的搜索任務��,避免任務量過多的問題。
搜索任務支持中斷的實現方式是給每個搜索任務設置一個CancelFlag,在搜索邏輯執行時每搜到一個結果就判斷一下CancelFlag是否置位����,如果置位了就立即退出任務��。外部邏輯可以通過置位CancelFlag來中斷搜索任務。
邏輯流程如下圖所示:
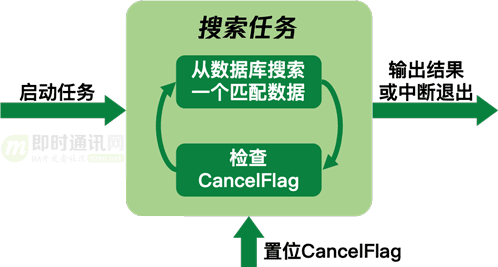
為了讓搜索任務能夠及時中斷,我們需要讓檢查CancelFlag的時間間隔盡量相等,要實現這個目標就要在搜索時避免使用OrderBy子句對結果進行排序���。
因為FTS5不支持建立聯合索引,所以在使用OrderBy子句時,SQLite在輸出第一個結果前會遍歷所有匹配結果進行排序��,這就讓輸出第一個結果的耗時幾乎等于輸出全部結果的耗時����,中斷邏輯就失去了意義。
不使用OrderBy子句就對搜索邏輯添加了兩個限制:
1)從數據庫讀取所有結果之后再排序:我們可以在讀取結果時將用于排序的字段一并讀出,然后在讀完所有結果之后再對所有結果執行排序�����。因為排序的耗時占總搜索耗時的比例很低,加上排序算法的性能大同小異�����,這種做法對搜索速度的影響可以忽略�。
2)不能使用分段查詢:在全文搜索這個場景中,分段查詢其實是沒有什么作用的���。因為分段查詢就要對結果排序,對結果排序就要遍歷所有結果�,所以分段查詢并不能降低搜索耗時(除非按照FTS索引的Rowid分段查詢����,但是Rowid不包含實際的業務信息)����。
9.4 搜索讀取內容應最少化
搜索時讀取內容的量也是決定搜索耗時的一個關鍵因素��。
FTS索引表實際是有多個SQLite普通表組成的����,這其中一些表格存儲實際的倒排索引內容���,還有一個表格存儲用戶保存到FTS索引表的全部原文�����。當搜索時讀取Rowid以外的內容時�,就需要用Rowid到保存原文的表的讀取內容��。
索引表輸出結果的內部執行過程如下:
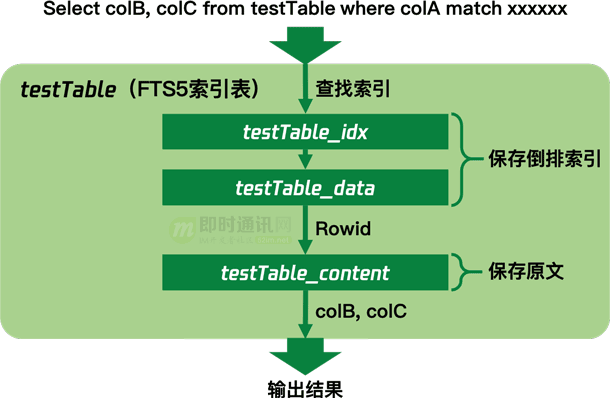
所以讀取內容越少輸出結果的速度越快��,而且讀取內容過多也會有消耗內存的隱患。
我們采用的方式是:搜索時只讀取業務數據id和用于排序的業務屬性,排好序之后,在需要給用戶展示結果時,才用業務數據id按需讀取業務數據具體內容出來展示。這樣做的擴展性也會很好�����,可以在不更改存儲內容的情況下��,根據各個業務的需求不斷調整搜索結果展示的內容��。
還有個地方要特別提一下:就是搜索時盡量不要讀取高亮信息(SQLite的highlight函數有這個能力)。因為要獲取高亮字段不僅要將文本的原文讀取出來,還要對文本原文再次分詞�����,才能定位命中位置的原文內容�,搜索結果多的情況下分詞帶來的消耗非常明顯����。
那展示搜索結果時如何獲取高亮匹配內容呢?我們采用的方式是將用戶的搜索文本進行分詞�����,然后在展示結果時查找每個Token在展示文本中的位置�,然后將那個位置高亮顯示(同樣因為用戶一屏看到的結果數量是很少的,這里的高亮邏輯帶來的性能消耗可以忽略)����。
當然在搜索規則很復雜的情況下�����,直接讀取高亮信息是比較方便(比如:聯系人搜索就使用前面提到的SubstringMatchInfo函數來讀取高亮內容)。這里主要還是因為要讀取匹配內容所在的層級和位置用于排序����,所以逐個結果重新分詞的操作在所難免���。
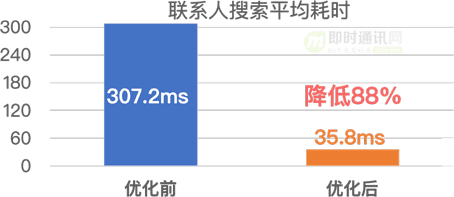
9.5 優化前后的效果對比
下面是微信各搜索業務優化前后的搜索耗時對比:


10�����、本文小結
目前iOS微信已經將這套新全文搜索技術方案全量應用到聊天記錄�����、聯系人和收藏的搜索業務中。
使用新方案之后:全文搜索的索引文件占用空間更小����、索引更新耗時更少、搜索速度也更快了�����,可以說全文搜索的性能得到了全方位提升���。
附錄:QQ���、微信團隊技術文章匯總
《微信朋友圈千億訪問量背后的技術挑戰和實踐總結》
《騰訊技術分享:Android版手機QQ的緩存監控與優化實踐》
《微信團隊分享:iOS版微信的高性能通用key-value組件技術實踐》
《微信團隊分享:iOS版微信是如何防止特殊字符導致的炸群�����、APP崩潰的�����?》
《騰訊技術分享:Android手Q的線程死鎖監控系統技術實踐》
《iOS后臺喚醒實戰:微信收款到賬語音提醒技術總結》
《微信團隊分享:微信每日億次實時音視頻聊天背后的技術解密》
《騰訊團隊分享 :一次手Q聊天界面中圖片顯示bug的追蹤過程分享》
《微信團隊分享:微信Android版小視頻編碼填過的那些坑》
《企業微信客戶端中組織架構數據的同步更新方案優化實戰》
《微信團隊披露:微信界面卡死超級bug“15。�。�。���。”的來龍去脈》
《QQ 18年:解密8億月活的QQ后臺服務接口隔離技術》
《月活8.89億的超級IM微信是如何進行Android端兼容測試的》
《微信后臺基于時間序的海量數據冷熱分級架構設計實踐》
《微信團隊原創分享:Android版微信的臃腫之困與模塊化實踐之路》
《微信后臺團隊:微信后臺異步消息隊列的優化升級實踐分享》
《微信團隊原創分享:微信客戶端SQLite數據庫損壞修復實踐》
《騰訊原創分享(一):如何大幅提升移動網絡下手機QQ的圖片傳輸速度和成功率》
《微信新一代通信安全解決方案:基于TLS1.3的MMTLS詳解》
《微信團隊原創分享:Android版微信后臺?�;顚崙鸱窒?網絡?��;钇?》
《微信技術總監談架構:微信之道——大道至簡(演講全文)》
《微信海量用戶背后的后臺系統存儲架構(視頻+PPT) [附件下載]》
《微信異步化改造實踐:8億月活���、單機千萬連接背后的后臺解決方案》
《微信朋友圈海量技術之道PPT [附件下載]》
《微信對網絡影響的技術試驗及分析(論文全文)》
《架構之道:3個程序員成就微信朋友圈日均10億發布量[有視頻]》
《快速裂變:見證微信強大后臺架構從0到1的演進歷程(一)》
《微信團隊原創分享:Android內存泄漏監控和優化技巧總結》
《Android版微信安裝包“減肥”實戰記錄》
《iOS版微信安裝包“減肥”實戰記錄》
《移動端IM實踐:iOS版微信界面卡頓監測方案》
《微信“紅包照片”背后的技術難題》
《移動端IM實踐:iOS版微信小視頻功能技術方案實錄》
《移動端IM實踐:Android版微信如何大幅提升交互性能(一)》
《移動端IM實踐:實現Android版微信的智能心跳機制》
《移動端IM實踐:谷歌消息推送服務(GCM)研究(來自微信)》
《移動端IM實踐:iOS版微信的多設備字體適配方案探討》
《IPv6技術詳解:基本概念�����、應用現狀�����、技術實踐(上篇)》
《手把手教你讀取Android版微信和手Q的聊天記錄(僅作技術研究學習)》
《微信技術分享:微信的海量IM聊天消息序列號生成實踐(算法原理篇)》
《社交軟件紅包技術解密(一):全面解密QQ紅包技術方案——架構�����、技術實現等》
《社交軟件紅包技術解密(二):解密微信搖一搖紅包從0到1的技術演進》
《社交軟件紅包技術解密(三):微信搖一搖紅包雨背后的技術細節》
《社交軟件紅包技術解密(四):微信紅包系統是如何應對高并發的》
《社交軟件紅包技術解密(五):微信紅包系統是如何實現高可用性的》
《社交軟件紅包技術解密(六):微信紅包系統的存儲層架構演進實踐》
《社交軟件紅包技術解密(十一):解密微信紅包隨機算法(含代碼實現)》
《IM開發寶典:史上最全,微信各種功能參數和邏輯規則資料匯總》
《微信團隊分享:微信直播聊天室單房間1500萬在線的消息架構演進之路》
《企業微信的IM架構設計揭秘:消息模型、萬人群��、已讀回執�����、消息撤回等》
(本文同步發布于:http://www.52im.net/thread-3839-1-1.html)