http://code.google.com/p/nutla/
1、概述
不管程序性能有多高,機器處理能力有多強,都會有其極限。能夠快速方便的橫向與縱向擴展是Nut設計最重要的原則。
Nut是一個Lucene+Hadoop分布式搜索框架,能對千G以上索引提供7*24小時搜索服務。在服務器資源足夠的情況下能達到每秒處理100萬次的搜索請求。
Nut開發環境:jdk1.6.0.21+lucene3.0.2+eclipse3.6.1+hadoop0.20.2+zookeeper3.3.1+hbase0.20.6+memcached+linux
2、特新
a、熱插拔
b、可擴展
c、高負載
d、易使用,與現有項目無縫集成
e、支持排序
f、7*24服務
g、失敗轉移
3、搜索流程
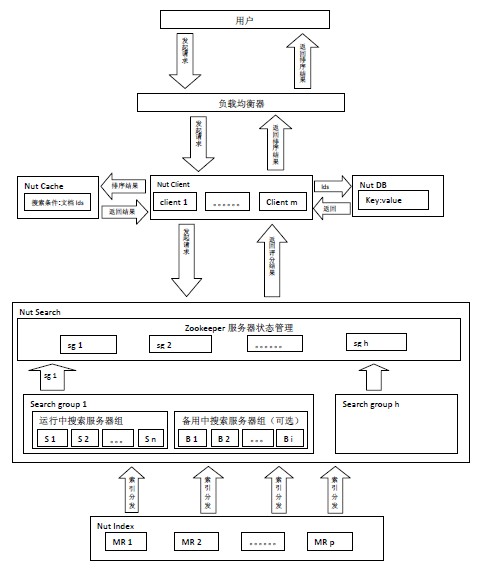
Nut由Index、Search、Client、Cache和DB五部分構成。(Cache默認使用memcached,DB默認使用hbase)
Client處理用戶請求和對搜索結果排序。Search對請求進行搜索,Search上只放索引,數據存儲在DB中,Nut將索引和存儲分離。Cache緩存的是搜索條件和結果文檔id。DB存儲著數據,Client根據搜索排序結果,取出當前頁中的文檔id從DB上讀取數據。
用戶發起搜索請求給由Nut Client構成的集群,由某個Nut Client根據搜索條件查詢Cache服務器是否有該緩存,如果有緩存根據緩存的文檔id直接從DB讀取數據,如果沒有緩存將隨機選擇一組搜索服務器組(Search Group i),將查詢條件同時發給該組搜索服務器組里的n臺搜索服務器,搜索服務器將搜索結果返回給Nut Client由其排序,取出當前頁文檔id,將搜索條件和當前文檔id緩存,同時從DB讀取數據。
4、索引流程
Hadoop Mapper/Reducer 建立索引。再將索引從HDFS分發到各個索引服務器。
對索引的更新分為兩種:刪除和添加(更新分解為刪除和添加)。
a、刪除
在HDFS上刪除索引,將生成的*.del文件分發到所有的索引服務器上去或者對HDFS索引目錄刪除索引再分發到對應的索引服務器上去。
b、添加
新添加的數據用另一臺服務器來生成。
刪除和添加步驟可按不同定時策略來實現。
5、Zookeeper服務器狀態管理策略
在架構設計上通過使用多組搜索服務器可以支持每秒處理100萬個搜索請求。
每組搜索服務器能處理的搜索請求數在1萬—1萬5千之間。如果使用100組搜索服務器,理論上每秒可處理100萬個搜索請求。
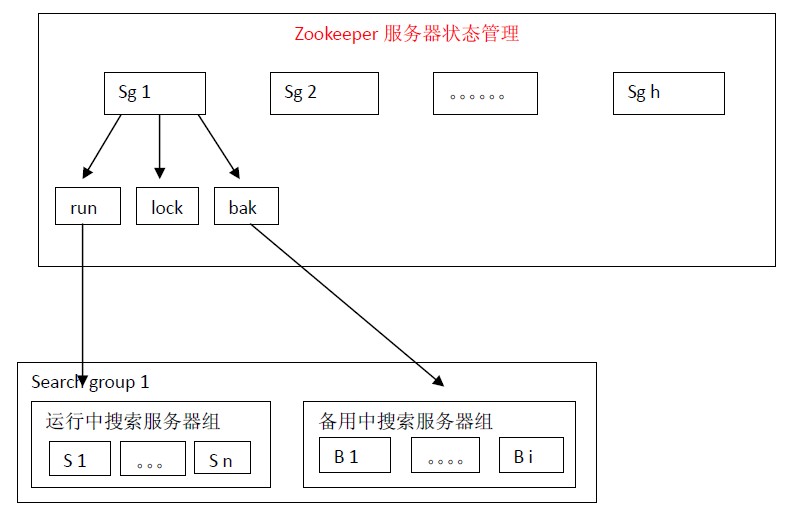
假如每組搜索服務器有100份索引放在100臺正在運行中搜索服務器(run)上,那么將索引按照如下的方式放在備用中搜索服務器(bak)上:index 1,index 2,index 3,index 4,index 5,index 6,index 7,index 8,index 9,index 10放在B 1 上,index 6,index 7,index 8,index 9,index 10,index 11,index 12,index 13,index 14,index 15放在B 2上。。。。。。index 96,index 97,index 98,index 99,index 100,index 5,index 4,index 3,index 2,index 1放在最后一臺備用搜索服務器上。那么每份索引會存在3臺機器中(1份正在運行中,2份備份中)。
盡管這樣設計每份索引會存在3臺機器中,仍然不是絕對安全的。假如運行中的index 1,index 2,index 3同時宕機的話,那么就會有一份索引搜索服務無法正確啟用。這樣設計,作者認為是在安全性和機器資源兩者之間一個比較適合的方案。
備用中的搜索服務器會定時檢查運行中搜索服務器的狀態。一旦發現與自己索引對應的服務器宕機就會向lock申請分布式鎖,得到分布式鎖的服務器就將自己加入到運行中搜索服務器組,同時從備用搜索服務器組中刪除自己,并停止運行中搜索服務器檢查服務。
為能夠更快速的得到搜索結果,設計上將搜索服務器分優先等級。通常是將最新的數據放在一臺或幾臺內存搜索服務器上。通常情況下前幾頁數據能在這幾臺搜索服務器里搜索到。如果在這幾臺搜索服務器上沒有數據時再向其他舊數據搜索服務器上搜索。
優先搜索等級的邏輯是這樣的:9最大為搜索全部服務器并且9不能作為level標識。當搜索等級level為1,搜索優先級為1的服務器,當level為2時搜索優先級為1和2的服務器,依此類推。