|
|
2006年6月21日
System.getProperty()參數大全
java.version Java Runtime Environment version
java.vendor Java Runtime Environment vendor
java.vendor.url Java vendor URL
java.home Java installation directory
java.vm.specification.version Java Virtual Machine specification version
java.vm.specification.vendor Java Virtual Machine specification vendor
java.vm.specification.name Java Virtual Machine specification name
java.vm.version Java Virtual Machine implementation version
java.vm.vendor Java Virtual Machine implementation vendor
java.vm.name Java Virtual Machine implementation name
java.specification.version Java Runtime Environment specification version
java.specification.vendor Java Runtime Environment specification vendor
java.specification.name Java Runtime Environment specification name
java.class.version Java class format version number
java.class.path Java class path
java.library.path List of paths to search when loading libraries
java.io.tmpdir Default temp file path
java.compiler Name of JIT compiler to use
java.ext.dirs Path of extension directory or directories
os.name Operating system name
os.arch Operating system architecture
os.version Operating system version
file.separator File separator ("/" on UNIX)
path.separator Path separator (":" on UNIX)
line.separator Line separator ("\n" on UNIX)
user.name User's account name
user.home User's home directory
user.dir User's current working directory
服務類型
在axis中有4中服務類型
RPC服務采用soap rpc的標準,and also the SOAP "section 5" encoding.
Document 服務沒有采用任何編碼(所以你在組裝時不會看到復雜對象的序列化以及soap-style數組),但是仍然作了xml和java對象的互映射。
Wrapped服務和Document服務類似
Message 服務接受和返回soap Envelope中的任意的xml而不需要mapping/data得榜定。如果你想處理來自外部的原始的xml,可以采用Message 服務。
RPC服務
這個服務是axis默認的服務。我們在前面的例子中寫的就是rpc服務。<service ... provider="java:RPC"> 。rpc服務遵從soap rpc規范和編碼規則,意味著來自rpc服務的xml將類似上面例子中的“echoString”--每個rpc調用被模塊化為一個外部元素,匹配操作名稱,并包含了很多內部元素,每一個都是操作的一個參數。axis將把這些xml轉化為java對象,配送給你得服務,并將序列化來自服務的java對象為xml.因為rpc服務默認采用soap section 5規則,對象將會通過"multi-ref" 序列化來編碼。
Document / Wrapped 服務
這2個服務很類似,都不需要用soap編碼來處理數據。他就是一個普通的xml格式。無論哪種情況,axis還是對他們做了xml到java得榜定,所以你最終處理的還是java對象,而不是xml結構的字符串。
下面的例子來說明他們2個之間的區別。
<soap:Envelope xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java">
<soap:Body>
<myNS:PurchaseOrder xmlns:myNS="http://commerce.com/PO">
<item>SK001</item>
<quantity>1</quantity>
<description>Sushi Knife</description>
</myNS:PurchaseOrder>
</soap:Body>
</soap:Envelope>
相關的PurchaseOrder類型定義如下:
<schema targetNamespace="http://commerce.com/PO">
<complexType name="POType">
<sequence>
<element name="item" type="xsd:string"/>
<element name="quantity" type="xsd:int"/>
<element name="description" type="xsd:string"/>
</sequence>
</complexType>
<element name="PurchaseOrder" type="POType"/>
</schema>
對于一個document服務來說,他將對應到這樣的方法
public void method(PurchaseOrder po)
換句話說,整個PurchaseOrder元素將被處理為一個單一的對象,包含3個屬性。
而對于wrapped服務來說,他對應于下面的方法
public void purchaseOrder(String item, int quantity, String description)
注意到,在wrapped中,PurchaseOrder元素被映射為代表了一個方法。他的參數就是他的那些元素。
他們在wsdd得使用如下
<service ... style="document"> for document style
<service ... style="wrapped"> for wrapped style
Message 服務
當你需要處理純xml而不是java對象時,你將會用到這種服務。
message服務的方法有4中簽名
public Element [] method(Element [] bodies);
public SOAPBodyElement [] method (SOAPBodyElement [] bodies);
public Document method(Document body);
public void method(SOAPEnvelope req, SOAPEnvelope resp);
發布service
有2種發布方式,一種是實例發布,一種是描述符發布
實例發布很簡單
把我們的java源文件拷貝到axis目錄下,改擴展名為jws
然后就可以直接訪問了,例如:
java samples.userguide.example2.CalcClient -p8080 add 2 5
他將調用add方法,傳遞的2個變量分別為2和5。
很顯然,第一種方法有很多弊端,比如需要源文件,不能有包路徑等等
描述符發布
一個最簡單的例子如下:
<deployment xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java">
<service name="MyService" provider="java:RPC">
<parameter name="className" value="samples.userguide.example3.MyService"/>
<parameter name="allowedMethods" value="*"/>
</service>
</deployment>
一個服務是一個targeted chain ,可能包含下面的一些或者全部:請求Handler,pivot Handler 支點Handler,響應Handler。支點hander在服務中叫做provider,在例子中我們的provider是java:RPC,他被axis內嵌,代表了Java RPC service,具體的類是org.apache.axis.providers.java.RPCProvider.
我們告訴RPCProvider 我們要調用的服務MyService,并以參數的形式告訴他具體的目標以及可以被調用的方法。
我們也可以給我們要調用的對象設置作用范圍scope,和servlet的scope一樣,有request,session,application.
我們需要把這個描述符定義的內容告訴應用服務器才能真正提供我們需要的服務。
如果已經部署axis到tomcat,我們可以這樣發布
org.apache.axis.client.AdminClient deploy.wsdd
這樣我們的服務就可以通過soap來訪問了
測試一下
java samples.userguide.example3.Client
-lhttp://localhost:8080/axis/services/MyService "test me!"
可以通過下面來查看所有已經部署的服務
java org.apache.axis.client.AdminClient list
來看看更進一步的應用,使用一下request handler
<deployment xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java">
<!-- define the logging handler configuration -->
<handler name="track" type="java:samples.userguide.example4.LogHandler">
<parameter name="filename" value="MyService.log"/>
</handler>
<!-- define the service, using the log handler we just defined -->
<service name="LogTestService" provider="java:RPC">
<requestFlow>
<handler type="track"/>
</requestFlow>
<parameter name="className" value="samples.userguide.example4.Service"/>
<parameter name="allowedMethods" value="*"/>
</service>
</deployment>
這個例子會在客戶端掉用LogTestService的時候,先調用samples.userguide.example4.LogHandler作記錄操作
遠程管理
默認狀態下,axis只允許在axis部署的機器上使用管理請求,如果希望在其他的機器上進行管理操作可以參照下面的例子
<service name="AdminService" provider="java:MSG">
<parameter name="className" value="org.apache.axis.util.Admin"/>
<parameter name="allowedMethods" value="*"/>
<parameter name="enableRemoteAdmin" value="true"/>
</service>
注意,這樣配置需要作必要的安全配置
原文見:
http://blog.csdn.net/huabingl/archive/2008/02/12/2089145.aspx
說dtree是使用最廣泛的目錄樹javascript應該也不為過.這得意于他簡單的使用方式和良好的結構.
可能這里是他最早的發源地之一http://www.destroydrop.com/javascripts/tree/
上面有他的示例和api文檔.
dtree使用簡單,使用起來就是引入一個dtree.js,dtree.css和一些小圖片文件。.在需要顯示樹的地方,插入類似下面的代碼
可以參照這里做些配置,觀看效果.可選的選項有folderLinks, useIcons, useLines, useSelection, useStatusText, closeSameLevel
http://www.destroydrop.com/javascripts/tree/example/
你可以放置radio或者checkbox在相應的節點上,或者在節點上加上鏈接.
原文見
http://blog.csdn.net/huabingl/archive/2008/02/12/2088711.aspx
opencms列表顯示
先準備要顯示的數據。比如在站點下建立一個sports目錄,里面以news的格式放入一些xmlpage.
注意給這些xmlpage準備好detail顯示頁面。
<%@ taglib prefix="cms" uri="
<%@ page import="java.util.*"%>
<%@ page import="org.opencms.jsp.*"%>
<%
String sPageIndex=request.getParameter("pageIndex");
int iPageIndex=1;
if(sPageIndex!=null){
iPageIndex=Integer.parseInt(sPageIndex);
}
pageContext.setAttribute("pageIndex", iPageIndex+"");
%>
<cms:contentload collector="allInFolderDateReleasedDesc" param="/myfirstsite/sports/%(number)_news.html|news" pageIndex="%(pageContext.pageIndex)" pageSize="2">
<cms:contentinfo var="contentInfo" scope="request" />
<a href="<cms:link><cms:contentshow element="%(opencms.filename)"/></cms:link>" target=_blank><cms:contentshow element="Title"/> </a>
<%out.println("---");%>
</cms:contentload>
<%
CmsContentInfoBean info = (CmsContentInfoBean)request.getAttribute("contentInfo");
int totalNum=info.getResultSize();
%>
共<%=totalNum%>條數據,當前第<%=info.getPageIndex()%>/<%=info.getPageCount()%>
<a href="list_taglib?pageIndex=<%=info.getPageNavStartIndex()%>">第一頁</a>
<a href="list_taglib?pageIndex=<%=(info.getPageNavStartIndex()-1)>0?(info.getPageNavStartIndex()-1):1%>">上一頁</a>
<a href="list_taglib?pageIndex=<%=(info.getPageNavStartIndex()+1)>info.getPageCount()?info.getPageCount():(info.getPageNavStartIndex()+1)%>">下一頁</a>
<a href="list_taglib?pageIndex=<%=info.getPageNavEndIndex()%>">最后頁</a>
上面的例子力求盡可能少的使用標簽。主要使用了CmsContentInfoBean ,CmsJspXmlContentBean ,I_CmsXmlContentContainer(CmsJspTagContentLoad )等多個對象。分頁的關鍵在CmsContentInfoBean 和 CmsJspTagContentLoad的關系上。
參考資料:
http://www.javaedu.com/bbs/viewthread?thread=128
http://wangyi878750.blog.sohu.com/41725191.html
http://l--w.blog.sohu.com/47996664.html
http://wangyi878750.blog.sohu.com/41378072.html
Ruby之Blocks,Iterator
-------讀《Programming Ruby 2nd》
Ruby是”一種用于迅速和簡便的面向對象編程的解釋性腳本語言”;這意味著什么?
解釋性腳本語言:
- 有直接呼叫系統調用的能力
- 強大的字符串操作和正則表達式
- 開發中快速回饋
迅速和簡便:
- 無需變量聲明
- 變量無類型
- 語法簡單而堅實
- 自動內存管理
面向對象編程
- 任何事物都是一個對象
- 類,繼承,方法,等等
- 單態方法
- 模塊糅合
- 迭代器和閉包(closures)
以及:
如果你對上面的那些概念還不熟悉,繼續讀,別擔心.Ruby的箴言是”迅速和簡便”.
<script language="javascript">
//定義全局變量,用于清理工作
var word;
var doc;
function editFile(){
//調用word控件
word= new ActiveXObject("Word.Application");
//屏蔽“另存為”按鈕
word.CommandBars("File").Controls(5).Enabled= false;
word.CommandBars("File").Controls(5).visible= false;
//屏蔽"另存為網頁"按鈕
word.CommandBars("File").Controls(6).Enabled= false;
word.CommandBars("File").Controls(6).visible= false;
word.visible = true;
// word.activate();
try{
//打開文件
doc=word.Documents.Open(" //痕跡保留
word.ActiveDocument.TrackRevisions =true;
//切換成web視圖
word.ActiveDocument.ActiveWindow.View.Type=3
}catch(e){
alert(e.message);
};
}
function myfinalize(){
//文檔保存
doc.save();
//文檔關閉
doc.close();
//把屏蔽的功能打開
word.CommandBars("File").Controls(5).Enabled= true;
word.CommandBars("File").Controls(5).visible= true;
//word退出
word.quit();
}
//參考文檔
http://bbs.hidotnet.com/712/ShowPost.aspx
原文:
http://blog.csdn.net/huabingl/archive/2008/02/11/2088477.aspx
摘要: AXIS User Guide(1) 閱讀全文
摘要: Sliding into WebDAV 閱讀全文
摘要: HibernateTemplate方法索引 閱讀全文
最近又遇到個對js取名不帥導致錯誤的問題,特開此貼,以示警戒:
不要把自己的js函數取成close(),open(),start()之類的名字!!
window得resizeto和resizeby方法對模式窗口無效。
最近研究了一下webdav,關于webdav的詳細信息可以在 google上搜索或者參看官方網站 筆者簡單的嘗試了它下面的slide和mod_dav.
slide是jakarta下面的子項目,分為服務端和客戶端.個人認為服務端是專門為tomcat定做的一個webdav實現.關于slide,javaeye上有些討論,可以參考http://www.javaeye.com/t/5267.html.本人涉入的不是很深,中文問題讓我碰到了,slide提供2中存儲方式,文件形式和數據庫形式,限于時間,筆者沒有對數據庫形式進行測試.slide的工作目錄默認在服務器bin目錄下.
用mod_dav來實現相比就簡單多了,如果你熟悉apache httpserver,應該很容易搞定.http://www.webdav.org/mod_dav/ 上的有部分資料.可以根據http://www.webdav.org/mod_dav/install.html 的講解來配置.apache server1.3以后(包括1.3)在發布的時候都自帶了mod_dav包.需要做的就是加載和配置它.
LoadModule dav_module libexec/libdav.so
AddModule mod_dav.c
筆者在配置的時候由于沒有認真看文檔,犯了個小小的錯誤.所以注意下面的文字:
"In the following example, the DAV lock database will be stored in the /usr/local/apache/var directory (which must be writable by the server process). The file's name will be DAVLock when mod_dav needs to create it.
(actually, mod_dav will create one or more files using this file name plus an extension)
DAVLockDB /usr/local/apache/var/DAVLock"
然后你需要配置一個webdav的工作目錄,由于訪問apache服務的用戶會默認是nobody用戶,所以你至少得讓工作目錄對nobody可讀寫.在目錄的定義中加入DAV on這樣的屬性就 ok了
eg:
"Alias /pages /home/www/davhome
<Location /pages>
DAV On
</Location>
"
測試webdav
安裝完webdav后,你可以做簡單的測試:
IE瀏覽器-〉文件-〉打開,然后輸入配置的url,客戶端API.
如果是 java可以 采用slide的客戶端.(php用戶咋辦?).
這個最新的客戶端使用的是最新的jdom,注意哦..
參考資料:
http://www.uplinux.com/www/net/02/131.shtml
?? mvnforum是一個開源的論壇軟件.網址如下:
http://sourceforge.net/projects/mvnforum/
?? 本文主要研究它的權限部分,以作為使用借鑒.
?? 這里有篇中文的文檔,以作參考:
? http://www.cn-java.com/target/news.php?news_id=3298
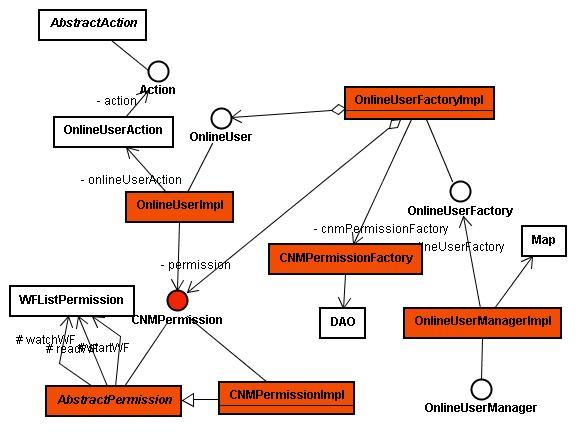
權限部分的UML圖如下:
?? 
數據流程:
1,系統從OnlineUserManager這個入口進入.這個部件有個Map用來存儲當前的非過期用戶。OnlineUserManager會先根據當前時間和最后一個用戶的請求時間做對比,檢查是否有刷新過期用戶的必要,如果超過所設置的時間,那么先更新Map。然后OnlineUserManager根據提供的用戶的 sessionid和username在這個Map中查找。如果找到,則刷新該用戶的最后一次訪問時間;否則,OnlineUserManager調用OnlineUserFactory部件創建該OnlineUser,并把這個OnlineUser存入Map之中。
判對用戶是否過期的原理是:從OnlineUser的OnlineUserAction中取出最后一次的訪問時間和當前時間做對比.
2,OnlineUserFactory負責創建OnlineUser并為該OnlineUser提供完整的權限信息.OnlineUser包括3大部分信息,一部分是用戶的基本信息,一部分是用戶的權限信息,一部分是用戶的在線信息.在線信息由OnlineUserManager負責管理,其他2部分信息由OnlineUserFactory從持久層獲得.
獲得權限信息并把它設置到OnlineUser部件上,提供給OnlineUserManager管理.
3.CNMPermissionFactory類似我們常說的service.主要負責和持久層通信,最終返回一個CNMPermission部件供OnlineUserFactory合成OnlineUser部件.在下面的章節里,筆者會對他細化討論.
權限結構:
用來實現用戶權限的主要的是CNMPermission接口和他是2個子類AbstractPermission和CNMPermissionImpl.CNMPermission接口負責定義權限有關的常量和對外API.AbstractPermission設置了保存權限信息的變量并實現了CNMPermission接口中定義的抽象方法,因此,筆者把這個抽象類叫做鑒權類.CNMPermissionImpl 則負責對AbstractPermission使用的變量進行設值,因此,筆者稱之為賦權類.
先看看AbstractPermission的結構。這里涉及到這么幾個概念:全局權限,特定權限,單個權限,組合權限。
全局權限用true/false來設置。
特定權限是指某一個動作所作用的不同的對象。比如:某用戶只能將寫操作作用于1,2,4這3個論壇板塊之上。表示為這個特定權限內部的ArrayList容器中只有1,2,4三個編號。
單個權限是指單個動作。比如讀操作。
組合權限是為了方便設置提供的對單個權限的組合。比如對某用戶一次設置某板塊的“讀”和“發布”2種權限。
前2種權限是一個緯度的劃分,后2個是另一個緯度的劃分。
如何鑒權?
鑒權的接口都會在CNMPermission中定義。對全局權限,直接返回對應的標志位的值,對于特定權限,則先判斷是否特定權限全開,否,則然后判斷其ArrayList中是否包含對應的對象編號。
如何賦權?
這里要承接到上述數據流程的第三步。由CNMPermissionFactory根據一定先后循序(其實無關順序,因為采用的為真覆蓋原則,即持久層返回的權限都是真值,后面的真值對前面的真值可覆蓋)從持久層獲得所有的全局權限和特定權限。mvnforum只有用戶和角色2種概念(當然也可以擴展),因此它的順序是:用戶全局全縣-〉用戶特定權限-〉角色全局全縣-〉角色特定權限。當然無論哪一部都是對同一個CNMPermission進行操作。
無論在設置全局權限還是特定權限的時候都可能會遇到所定義的組合權限。具體的組合權限拆分是由CNMPermissionImpl來做的.
相關的表結構:
?? member表,存貯用戶基本信息。
?? membergroup ,存儲用戶和組(角色)的對應關系。
?? groups表,存儲組/角色的基本信息
?? grouppermission,存儲組/角色的全局權限,字段為groupid permissionid
?? groupforum,存儲組/角色 的論壇權限, 字段為groupid ,forum,permissionid
?? memberpermission 存貯用戶的全局權限,字段為 memberid permissionid
?? memberforum 存貯用戶的論壇權限,字段為memberid ,forum,permissionid
? 修改于2006/12/16? 晚8時
? 目前的很多商業和非商業的服務器中間件都默認集成了common-log甚至是log4j.因此當我門把我們的應用發布在上面的時候,都會遇到關于log方面的問題. ? 1.webshpere下面集成log4j. ? "WebSphere的類裝入器方式有兩種方式:PARENT_FIRST和PARENT_LAST。默認值是PARENT_FIRST,這種方式在載入當前classpath的類之前先載入其上一級classloader能夠裝入的類。這是標準的JVM classloader的默認策略。如果采用PARENT_LAST,則過程正好相反,即先載入當前classpath的類,再載入其上一級classloader能夠裝入的類,這樣可以用當前classpath中更新的類覆蓋其上一級classloader的相同類。受類裝入器方式影響的classloader包括application classloader、WAR classloader以及共享類庫的classloader。" ?因為websphere在共享類庫的classloader中有一套common logging,但是確沒有合適配置文件.如果我們把配置正確的log4j.properties文件放在共享類庫下,我們會發現log4j可以運行.但還有另外一個很通用的方式--改變webshpere的類庫加載順序.我們讓他先加載我們web應用所需的類庫.即我們把web應用的加栽方式改為PARENT_LAST. ? 哎,盡管我小心的提防,今天還是中招了,在我的配置里,log4j的配置文件只能讀取一次,不能一個應用一個配置文件.為了讓它加載自己的配置,可以自己寫(或者用spring的)servlet/listener去手動加載這個配置文件. ?2.jboss下面的集成log4j ? 大家可能都曾在為jboss下面配置log4j郁悶過.jboss比webshpere走的還遠.無論你的項目是否使用了log4j,jboss在自己啟動的時候就已經運行他了.也就是說在jboss加載自己共享類庫的時候,已經讀取了自己log4j.xml文件配置.這個文件在conf中可以找到.如果你需要為你的應用單獨配置一個catagory,你需要直接在這里配置. ???在webloader裝載應用的時候,如果應用中有log4j的包,似乎總出現appender已被占用的問題.筆者把log4j的包連帶應用中的log4j配置文件一并移去,世界清凈了. 關于為了讓應用自帶的log4j配置文件生效,有人建議修改 ?<attribute name="Java2ClassLoadingCompliance">false</attribute> 和 ?<attribute name="UseJBossWebLoader">false</attribute> 這兩個屬性. 3.sunone下面集成log4j ??? 距離上次用SunOne服務器已經好長時間了,似乎sunOne的log有些類似jboss,也是一個服務器的log集中管理.由于使用的不是很多,暫且在這里站個位子. 隨手貼點關于log的信息: http://wiki.apache.org/jakarta-commons/Logging/FrequentlyAskedQuestionshttp://www-128.ibm.com/developerworks/cn/websphere/library/techarticles/0408_baigang/part3.html?
OpenLDAP
快速上手
?? Ben
的項目里面要用到
OpenLDAP,
我的項目里面也要用到
LDAP,
所以這
2
天集中看了一下
LDAP
相關的內容。做了個筆記,也算是為人類知識的積累做點或有或無的貢獻。
?? OpenLDAP
的官方站點是
http://www.openldap.org
。
??????
上面有個
QuickStart,
我將大致按照這個來講解。
一、
安裝
在官方站點上發布的是
linux/unix
下的
OpenLDAP
源文件,當然也很容易找到
windows
系統下的版本。筆者學習安裝的就是
windows
版本的。
二、
配置
OpenLDAP
有
2
個用戶最關注的配置文件。
一個是
slapd.conf
,
在他里面定義了最基本的
DN
以及管理員的賬號和密碼。
另一個是
LDIF
的文件。在它里面可以配置所有的用戶和組織。
1、?
我們先來了解
LDAP
的相關概念。
我們知道
LDAP
的全稱為(
Lightweight Directory Access Protocol
),即輕量級目錄訪問協議。
Ldap
是怎樣的一個結構呢
?用官方的話說:“
In LDAP, directory entries are arranged in a hierarchical tree-like structure. Traditionally, this structure reflected the geographic and/or organizational boundaries. Entries representing countries appear at the top of the tree. Below them are entries representing states and national organizations. Below them might be entries representing organizational units, people, printers, documents, or just about anything else you can think of..
”他是一個樹狀的結構。每一個節點被稱為一個
Entry
。這些
Entry
有著有趣的含義。
下面是他的
2
個實例。一個反映了
geographic
,一個反映了
organizational
。
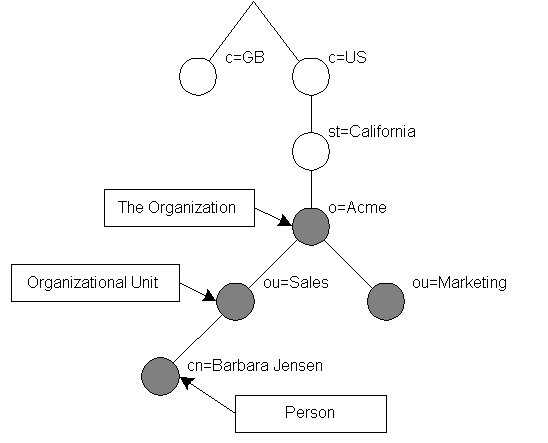
?????????????????????????????????????????????????????????? 傳統命名
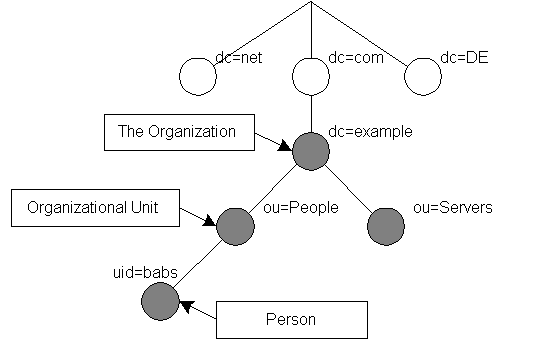
?????????????????????????????????????????????????????????? 網絡命名
我們來看看個個節點的定義方式。
每個
Entry
都有一個自己得一個標示
,我們把他叫
DN(Distinguished Name)
,這個
dn
包含了一個
RDN
(
Relative Distinguished Name
)。在上面的第二個圖例
中,Barbara Jensen的RDN是
uid=babs,他的dn是
uid=babs,ou=People,dc=example, dc=com。
每個節點都需要一個類別
,
這個類別信息用objectClass來表示。ObjectClass就是該節點的schema,他定義了該節點該有和不該有的屬性。默認的objectClass都在schema/core.schema中有定義。如果在你的配置過程中出現了關于找不到objectClass的問題,您不妨參看一下這里面有沒有你用到的objectClass
. 在schema文件夾下還有其他一些schema文件,你也可以定義自己的schema.想要加載其他的schema,你可以在slapd.conf文件中用include加入.如:include??./schema/core.schema.
為了方便識別,其實我們在DN里面用的都是objectClass的簡寫形式。如:ou代表organizationUnit,c代表country,st代表state,dc代表??等。
2、?
來看看
slapd.conf
這個文件
這個文件的主要信息是如下幾行:
database bdb
suffix "dc=<MY-DOMAIN>,dc=<COM>"
rootdn "cn=Manager,dc=<MY-DOMAIN>,dc=<COM>"
rootpw secret
directory /usr/local/var/openldap-data
定義了數據庫,最基本的后綴,管理員的
dn
和密碼,以及數據存放路徑。
編輯好這個文件,我們就可以啟動了。
如果你把
ldap
安裝為
windows
服務,你可以像我一樣啟動:
net start OpenLDAP-slapd
?
3、?
我們主要操作的就是這個
LDIF
文件
我們需要在這個文件里面加入所需要的
dn.
注意,因為我們在
slapd.conf
中定義了一個
base dn
和一個管理員
dn
,所以我們需要首先把這
2
個
dn
加進來。
dn: dc=<MY-DOMAIN>,dc=<COM>
objectclass: dcObject
objectclass: organization
o: <MY ORGANIZATION>
dc: <MY-DOMAIN>
?
dn: cn=Manager,dc=<MY-DOMAIN>,dc=<COM>
objectclass: organizationalRole
cn: Manager
保存為
ldif
后綴的文件。然后我們用命令把這些信息加到
ldap
中去:
ldapadd -x -D "cn=Manager,dc=<MY-DOMAIN>,dc=<COM>" -W -f example.ldif
讓我們來查看以下我們的設置是否出現問題:
ldapsearch -x -b 'dc=example,dc=com' '(objectclass=*)'
上面的是
linux/unix
下的命令,
windows
下我們需要做點更改:
ldapsearch -x -b dc=example,dc=com (objectclass=*)
對,就是去掉引號。
為了察看方便,筆者建議使用
GUI
工具來查看,比如筆者使用的
Softerra LDAP Browser 2.6
。
?
三、
和
java
集成
我們的
ldap Server
已經搭建起來了,我們需要在我們的
java
程序中訪問這個服務。
Openldap.org
上有沒有講?有講?下面介紹的
JLDAP
就是干這個的。
我們需要看一下“
Java LDAP Overview
”里面的內容。內容不是很多,但很實用。
要在
java
中訪問
ldap
,我們需要一套
api,
你可以在下面的網站上獲得:
http://developer.novell.com/wiki/index.php/LDAP_Classes_for_Java
在下在的文件里面有許多的例子,在
novell
的網站上也有很多的例子。我就不講了。
Try yourself
。
?? 沒有華麗的Rose,也沒有Togather,用JUDE的感覺也不錯.剛剛把PicoContainer反向了.可惜,好東西都陸續要收費了.只能用用 Community /Free 版.
? JUDE的一個下載地址:
?? http://jude.change-vision.com/jude-web/product/community.html
摘要: 一、簡介?? 感謝“簡易java框架”分享的學習心得。循著他的足跡,我把picocontainer讀了一遍。源代碼的版本是1.2-RC-2。?? pico的官方站點:http://www.picocontainer.org/?? 由于它是一個專門的ioc容器,所以使用起來沒有spring那么麻煩。關于他的文檔,在官方站點上有一篇《5分鐘搞定pico》的文章。國人似乎也有很多的翻譯版本。講解得很詳細... 閱讀全文
一個簡單的ThreadPool ? 原文來自 http://www.informit.com/articles/printerfriendly.asp?p=30483&r1=1&rl=1? 項目是多線程的,所以引入了線程池這個東西。池子是個老美寫的。在項目中表現的還不錯。所以把它摘出來,介紹給以后或許需要用到它的同行們。 ? 關于為什么要采用ThreadPool,原文已經提到了:創建一個線程是需要開銷的;如果線程數量過大的話,cpu就會浪費很大的精力做線程切換。 ? ThreadPool的實現過程就是對WorkerThread的同步和通信的管理過程。 ? 我們來看代碼。 ? 首先,在ThreadPool構造的時候,創建10個WorkerThread(size=10)并讓他們運行。每個WorkerThread線程都有個ThreadPool的引用,用于查詢ThreadPool的狀態和獲得同步鎖.WorkerThread運行以后,循環調用ThreadPool的方法進行查詢,如果沒有發現任務,ThreadPool告訴正在查詢的線程進入休眠狀態,WorkerThread釋放對查詢方法的鎖定.這樣在還沒有任務的時候,所有的10個WorkerThread都會進入休眠狀態,進入等待ThreadPool對象的等待鎖定池,只有ThreadPool對象發出notify方法(或notifyAll)后WorkerThread線程才進入對象鎖定池準備獲得對象鎖進入運行狀態。 代碼片斷: while ( !assignments.iterator().hasNext() ) ??? wait(); 如果你有jprofile或者其他的觀察線程的工具,你可以看到有10個線程都在休眠狀態. ? 接著,我們向ThreadPool中加入任務,這些任務都實現了Runnable的run方法.(至于為什么把任務都做成Runnable,譯者至今也有些疑問?預定俗成?TimerTask也是實現自Runnable,弄得初學者經常把真正運行的線程搞混).ThreadPool每assign一個任務,就會發出一條消息,通知它的等待鎖定池中的線程.各個線程以搶占的方式獲得對象鎖,然后很順利的獲得一條任務.并把此任務從ThreadPool里面刪除.沒有搶到的繼續等待. Runnable r = (Runnable)assignments.iterator().next(); ?? assignments.remove(r); WorkerThread從ThreadPool那里獲得了任務,繼續向下執行。 target = owner.getAssignment(); ?? if (target!=null) { ??? target.run();????? ??? owner.done.workerEnd(); ?? } 記住,這里調用的是target.run();而不是調用的線程的start()方法。也就是說在這里表現出的WorkerThread和task之間的關系僅僅是簡單的方法調用的關系,并沒有額外產生新線程。(這就是我上面納悶為什么大家都實現Runnable來做task的原因) ?大家可能注意到,WorkerThread并沒有對異常作處理。而我們知道發生在線程上的異常會導致線程死亡。解決的辦法有2中,一種是通過threadpool的管理來重新激起一個線程,一種是把異常在線程之內消滅。在項目中,我采用的是第二中,因此這個片斷改稱這樣: if (target!=null) { ? try{ ??? target.run();????? ?? } ? catch(Throwable t){ ?....... ?? } ??? owner.done.workerEnd(); } 在WorkerThread完成一個task以后,繼續循環作同樣的流程. 在這個ThreadPool的實現里面,Jeff Heaton用了一個Done類來觀察WorkerThread的執行情況.和ThreadPoool的等待鎖定池不同,Done的等待鎖定池里面放的是初始化ThreadPool的線程(可能是你的主線程),我們叫他母線程. ? 在給出的測試例子中.母線程在調用complete()方法后進入休眠(在監視中等待),一開始是waitBegin()讓他休眠,在assign加入task以后,waitDone()方法讓他休眠.在WorkerThread完成一個task以后,通知waitDone()起來重新檢查activeThreads的數值.若不為0,繼續睡覺.若為0,那么母線程走完,死亡(這個時候該做的task已經做完了).母線程走完,ThreadPool還存在嗎?答案是存在,因為WorkerThread還沒有消亡,他們在等待下一批任務,他們有ThreadPool的引用,保證ThreadPool依然存在.大家或許已經明白Done這個類的作用了. ? 細心的讀者或許會發現,發生在Done實例上的notify()并不是像ThreadPool上的notify()那樣每次都能完成一項工作.比如除了第一個被assign的task,其他的task在assign進去的時候,發出的notify()對于waitDone()來說是句"狼來了". ?最后在ThreadPool需要被清理得時候,使每一個WorkerThread中斷(這個時候或許所有的WorkerThread都在休眠)并銷毀.記住這里也是一個異步的過程.等到每一個WorkerThread都已經銷毀,finalize()的方法體走完.ThreadPool被銷毀. ?for (int i=0;i<threads.length;i++) { ?? threads[i].interrupt(); ?? done.workerBegin(); ?? threads[i].destroy(); ? } ? done.waitDone(); 為什么有句done.workerBegin();?不明白. 參考文章: http://www.zdnet.com.cn/developer/common/printfriend/printfriendly.htm?AT=39276905-3800066897t-20000560c
??? 呂華兵,男,24歲。
??? 2000-2004年,在中國民航大學讀書。學習期間,筆者以技術部長身份參與了校易航工作室暨易航網站的創建和發展工作,參與和獨立完成了多個項目的設計和開發。
?? 2004年5月到2006年5月,在北京環亞時代(港新合資)天津軟件中心從事Java的開發工作。參與了CMCC的OA的實施工作,主力開發了MOCHA AM的前端顯示和MOCHA ITAM的報表系統。
? 2006年5月至今,在美國易達軟件有限公司工作。設計并開發了Information Publisher的多線程后端程序。
??
? 筆者長期從事j2se,j2ee的開發工作,對各種設計模式亦有豐富的使用經驗。
? 筆者從來重視規范的軟件流程,對RUP有很深的理解。
? 對于javascript,dhtml,ajax,筆者有著豐富的經驗。
? 筆者也是“拿來主義”的擁躉,不遺余力的翻譯、學習、使用和宣傳各種開源項目。目前使用過的開源項目有:spring、picocontainer、hibernate、ibatis、struts、webwork等框架系列,DOM系列,commons系列,Quartz,log4j,ant,oscache,proxool以及各種報表工具等等。
?筆者從來重視知識的提取和積累,這也是筆者開此blog的主要原因,同時,也希望通過此blog結交更多的朋友。
譯者安:你敢大膽采用最新的技術嗎?你顧慮哪些方面?下面的采訪將給我們提供一個參考。
?原文:Interview: Real-world Experience with Google Web Toolkit (GWT)
? ?? 在java中,對技術的采用是一件讓人心煩的事情,因為我們獲得通知的途徑太多。不同的會議,不同的站點如slashdot和theserverside,而且還有數不清的個人博客如dhh和o'Reilly's Radar.
一個讓人感興趣的技術總是讓業界議論紛紛,正如人們所意識到的,這個產品并不是成熟期。
??? 為了讓一個產品成為主流,早期的采用者必須足夠喜歡這項產品來承擔很多非常的任務以便
讓更為膽怯的開發者相信這項新技術值得采用。像Hibernate和Spring Framework這樣的技術花了好幾年
才成為一個成熟產品。許多產品,比如maven,在版本確定之前經歷了痛苦的時期因為他們早期缺乏
足夠的文檔或者有不同的足夠強大的挑戰者比如ant.本人對這個過程中的盲點很感興趣,從議論這個產品的介紹到大范圍的采用往往要經歷成月上年,而且很難指定時間表。hibernate并不是暴雨似的到來,而是通過大量用戶自我采用.一個失敗的項目比如ojb出來的時候也是引起轟動,但是它最終沒有承諾的那么好.在這種情況下,早期的hibernate使用者其實信心不足.
? 讓我們來看Google Web Toolkit (GWT)…
GWT在這個進程中處于什么位置?
gwt看起來是在早期使用(early-adopter)的中期。一開始的議論聲已經消去,現在陸續出現了許多關于gwt的文章和博客,表明了人們正在期待關于gwt的第一個helloworld的反饋報告。我的很多謹慎的同行都在回避他,事實上認為它是個不好的主意。風險阻礙了開發者對大多數新技術的評估直到他們在現實中看到了一個活生生的實例解決方案--就像maven被ibm使用一樣。那些有能力來嘗試風險的開發者正在對這個框架進行測試。他們中的某一個或許宣稱gwt不適合它的組織。另外一個同行已經原則上接受了gwt的觀點,但是沒有時間來在他的應用中集成。所以,到底gwt處于什么時期?早期的使用人群有哪些經驗呢?
?? 關于這個問題,我專門采訪了Grassroots Technologies公司的Michael Podrazik。Grassroots Technologies是一個在紐約的咨詢小組。通過在Grassroots的工作,michael已經正在把gwt應用在他們的一個新的正在開發的web應用當中。在下面的采訪里面,我要求他來交流他的產品經驗來幫助其他人去理解gwt.我特別要求他給一些gwt客觀的意見,而且細致的描述他在用gwt開發過程中遇到的挑戰。幸運的是,他的信息將會幫助你決定是否gwt是你項目的正確選擇。
采訪內容:
q:什么使你選擇了gwt?
a:我訂閱了google的blog,所以我聽說了gwt當他發布到javaone的時候。在閱讀了他的文檔之后我開始對這種方式很好奇,因此我把它down了下來而且開始使用它(play with it).我剛剛開始了一個項目,這個項目是把遺留的 Access/VBA的桌面應用升級為一個web應用。在UI方面有許多ajaxian特性所以我想我可以讓gwt一展身手。我認為(figure)只要我保持我的架構足夠抽象,我就有能力用更為傳統的web應用框架來替換gwt層。gwt會很傷腦筋嗎?至少目前為止我很開心。
q:gwt出現了那些挑戰?你圍繞著gwt設計的web框架嗎?gwt是否挑戰了你關于web應用開發的觀點?
a:你確實不能簡單的認為gwt是一個webapp的框架,他更是一個有著rpc和對象序列化的ui類庫。因為你需要改變你項目組織的assumptions以及包的結構。在java服務端開發rich-client用戶界面我們有大量的經驗,比如flash/actionscript.gwt和他們十分類似,因此可以想象有這些元素的項目--分隔的服務端和客戶端而不是同一的webapp--很爽。
? 朝著這個方向,你需要明確區分服務端和客戶端的功能。我相信一個好的哲學就是使你的客戶端僅僅用于展示。
? 你需要思考你服務接口的設計,比如每個操作的粒度
? 你不能在客戶端代碼上用java5得語法
Q:你的意思是不能再gwt的具體類或者普通的web應用里面用java5的語法?
a:你不能在客戶代碼里面使用java5的語法。我們在服務端代碼中使用了許多java5的特性,但是所有將要被轉換成javascript的代碼必須是1.4的規范。
這個也包括許多事實上你用在服務端的類。因為rpc框架允許用戶定義的數據類型的序列化,意思是你將在瀏覽器端得到一個已經被轉化為javascript實例的類,這個類作為一個參數傳遞到服務端的實現中。在你的服務端代碼中,你將操縱同一個class而且是編譯過的字節碼。
?這個時候就出現了一個選擇,domain module和gwt的耦合度怎樣才合適呢?
What we decided was to keep value objects implementation-agnostic so as to avoid “infecting” the API and persistence layers with beans implementing GWT’s IsSerializable interface.
舉個例子,在服務端我們有個IUser接口的用戶模塊,這個借口繼承自IPersistable.gwt的實現接受和返回實現IsSerializable接口的GwtUser的實例并把這些實例利用commons-beanutils發送到服務端。
?對于這一點可能有些爭論,這樣做并不非必要。但是我覺得這點額外的工作將帶給你更為清晰的層次劃分。我們可以嵌入gwt到任何一點,而且可以轉換到springmvc或者struct或者其他的地方,而不需要擔心代碼上?的反應。
q:你發現gwt產生的javascript不能垮瀏覽器的地方了嗎?你發現gwt產生的javascript包含一些錯誤需要手動調試了嗎?
a:都沒有,這正是令我們驚訝的地方。跨瀏覽器javascript的開發是PITA,而且GWT真正的把你從他那里隔離開來。
我發現了大量的在FIREFOX和IE不同的地方,但是這些最后被確認都是CSS支持的問題而于GWT無關。
我也遇到了一大隊JAVASCRIPT錯誤,但是這些錯誤都是應為變量而不在初始化,這些問題很快就會找到并且不需要大量的調試。目前已經完成的大多數工作并不全是ui控件的問題,或許隨著我們的深入,我們會遇到一些問題,但是目前為止,我們還沒有多少麻煩。
q:你的工作組的成員是更喜歡java還是javascript呢?
顯然是java,哈哈。但是我們有人對javascript和actionscript也很精通。就像譯者本人。
q:一句話,對正在考慮gwt的人,你有什么建議?你會推薦他嗎?你對這項技術的客觀觀點是什么?thumbs up or thumbs down?
a:目前是thumbs up.我們目前仍然在開發的早期,而且我還不想說在它是完美的或者在以后的進程中不會咬我們一口。意思是說,你的建構要搭好。 它真的像是在作swing或者其他UI的桌面應用。
?我們用基于Controller和IView實現的GWT生成了全部的ui.除了gwt模塊引入以外,那里沒有html。
? 這是對幾乎所有主流web應用范例的違背,但是如果你喜歡ui編程,他完美的抽象了ajax/dhtml的行為到一個十分友好和可擴展的api.
? 我或許會說如果你的工作是php,asp或者其他語言,你或許需要花更多的功夫。如果你已經是一個有經驗的java程序員,那么你可以很快投入其中。
java.sql.Date,java.sql.Time和java.sql.Timestamp三個都是java.util.Date的子類(包裝類)。 但是為什么java.sql.Date類型的值插入到數據庫中Date字段中會發生數據截取呢? java.sql.Date是為了配合SQL DATE而設置的數據類型。“規范化”的java.sql.Date只包含年月日信息,時分秒毫秒都會清零。格式類似:YYYY-MM-DD 當我們調用ResultSet的getDate()方法來獲得返回值時,java程序會參照"規范"的java.sql.Date來格式化數據庫中的數值。因此,如果 數據庫中存在的非規范化部分的信息將會被劫取。在sun提供的ResultSet.java中這樣對getDate進行注釋的: Retrieves the value of the designated column in the current row of this <code>ResultSet</code> object as a “java.sql.Date” object in the Java programming language. 同理。如果我們把一個java.sql.Date值通過PrepareStatement的setDate方法存入數據庫時,java程序會對傳入的java.sql.Date規范化 ,非規范化的部分將會被劫取。 ?然而,我們java.sql.Date一般由java.util.Date轉換過來,如:java.sql.Date sqlDate=new java.sql.Date(new java.util.Date().getTime()). ?顯然,這樣轉換過來的java.sql.Date往往不是一個規范的java.sql.Date. ?在 http://www.thunderguy.com/semicolon/2003/08/14/java-sql-date-is-not-a-real-date/ 文章中提到,要保存java.util.Date的精確值, ?我們需要利用java.sql.Timestamp. ?感謝這篇文章的鋪墊: http://community.csdn.net/Expert/topic/4354/4354971.xml?temp=.5256616
官方網址:
http://logging.apache.org/log4j/docs/index.html
一個中文翻譯的文檔:
http://www.jaxwiki.org/zh/project/logging.apache.org/log4j/docs/manual.html
我摘出黃色字體表明幾條列在下面,也是筆者認為log4j最主要特點的濃縮:
1.階層式的命名:
如果一個logger 的名字后面跟著一個點號(dot),它就是點號(dot)后面的那個logger的前輩( ancestor),是這個晚輩(descendant) 的前綴。如果在它自己和這個晚輩之間沒有其它的前輩,它和這個晚輩之間就是父子關系。
2.級別繼承
對于一個給定的logger C,它繼承的級別等于logger階層里,從C開始往root logger上去的第一個non-null級別。
3.執行規則
在一個級別為q(被指定的或繼承的)的logger里,一個級別為p的日志請求,只有在p >= q 時才能夠被執行。
4.appender添加性的規則
Logger C的log輸出信息將被輸出到C的所有appenders和它的前輩的 appenders。這就是"appender additivity"的意思。但是,如果logger C的前輩,比如說P,P的additivity flag被設置為 false,那么,C的輸出信息將被輸出到C的所有appenders中去,以及它的前輩的——截止在P那里,包括P在內的,appenders中去,但是不會輸出到P的前輩的 appenders中去。 默認情況下,Loggers的additivity flag設置為true。
關于日志格式:暫貼幾個樣例:
log4j.appender.A1.layout.ConversionPattern=%d %-5p [%t] %-c (%13F:%L) %3x - %m%n
在配置文件中,log4j可以訪問到系統環境變量。具體的變量參考相關資料。
一篇我很早以前在csdn寫的文章:
http://blog.csdn.net/huabingl/archive/2005/02/19/293933.aspx
我承認我用mysql有很長時間了,不過似乎我仍然很白。好吧,還是寫寫吧。
1。1067錯誤,無法啟動。7/3/2006
解決步驟和方案:察看日至,mysql.user表莫名其妙的弄丟了。從其他地方扒下一個放在這里就可以了。
2.非安裝版mysql的安裝和啟動。
一般情況下,本人習慣用非安裝版的軟件。為了安裝方便,你可以把解壓后的文件拷貝到c盤根目錄下,并把總目錄改為mysql.然后進入windows命令 控制臺,在c:/mysql/bin下面運行mysqld-nt --install把它安裝為一個服務,然后調用net start mysql啟動它,停止的命令是net stop mysql .想要移除這個服務,用命令mysqld-nt --remove
3.訪問mysql的命令:mysql -h host -u user -p 。不過有好多好用的客戶端可以使用,比如5.0自帶的工具和SQLyog Enterprise
4。庫表相關的命令:SHOW DATABASES;SHOW TABLES;DESCRIBE table1/desc table1;
5.察看當前配置:show variables;
6.關于中文亂碼問題,到一定積累,筆者準備開專題。目前簡要列下:
在mysql的一次會話中,服務器收到客戶端發來的指令后,大致要執行3個動作:
1、服務器認為收到的指令是按當前character_set_client環境變量所指定的字符集編碼的,
2、然后再將其轉換成character_set_connection所指定的字符集編碼
3、分析、執行該指令。
4、 用character_set_results變量所指定的字符集返回服務器向客戶端傳輸的數據
解決這個問題的關鍵點在于設置 default-character-set 變量。
7,在創建數據庫的時候,我們有時會需要提供一些編碼上的參數,如:
#1. Create mvnforum database with the "Create database" syntax (for unicode and others):
# mysql> CREATE DATABASE mvnforum CHARACTER SET [charater_set] COLLATE [collation]
# mysql> CREATE DATABASE mvnforum CHARACTER SET utf8 collate
# Where charater_set and collation : @see http://dev.mysql.com/doc/refman/4.1/en/charset-mysql.html
#
# a, practice to view all supported character set
# mysql> SHOW CHARACTER SET;
# b, practice to view all supported collation:
# mysql> SHOW COLLATION;
#
# c, Example for Unicode:
# mysql> CREATE DATABASE mvnforum CHARACTER SET utf8 COLLATE utf8_general_ci
#"
"
未完待續。
歡迎回帖。
1。什么是異常
???異常是一種狀態,是程序出現了符合該異常條件的一種狀態。因此,他也可以說成是一種條件。
2。為什么要捕獲異常
? 捕獲異常是為了對程序中出現的某種狀況進行處理。如果有異常而沒有捕獲,異常將會向上一層傳播,最終導致線程在此中止。
3。什么是check異常和unchecked異常
? uncheck異常一般是RuntimeException.出現這類異常,編譯器不會強制要用戶去捕獲(當然你可以捕獲)。?? 編譯器會強制要求用戶對checked異常進行捕獲并作出一定的處理。
4。為什么不推薦捕獲頂層異常(Exception)
? 程序中會發生各種各樣的異常。除非你的程序是個終端(一個業務的終點),否則不推薦捕獲頂層異常。
?在程序的中間環節捕獲所有異常毫無意義,并有可能導致流程上的隱患。比如,出現某種異常后,期望線程就此結束,不去做下面的工作,但是如果在中間環節對頂層異常進行了非法處理,程序有可能會運行下去,將導致不可控的錯誤。
5。為什么要自定義異常
?自定義異常是為了設置異常鏈的起點。一般情況下,我們都是允許每個程序員看到所有的異常信息,這個時候大多數都是把下一層的異常直接重擲到上一層。然而在多層次的結構中,我們有時候需要隱藏底層異常(這種異常的信息很多,很枯燥),而給消費者提供一個更為直觀的異常,這個時候我們需要自定義異常。有的異常類jdk已經給我們提供,比如常用的IllegalArgumentException。如果你想在此再作包裝,你可以創建自己的異常類。如此,消費者將以此異常作為異常鏈的起點。
6。為什么要重擲異常
?重擲異常是處理異常的一種方式。在捕獲了某種異常后,用戶可能不希望在這一層做出裁決,或者即使做出了一定的處理,但仍然需要向上一層報告,因此需要重擲異常。
7。異常機制。
?? 一旦某個點發生異常,這個點下面和catch語句之間的代碼將不會被執行。因此,異常是一種中止流程的很有效的機制。
?? 關于異常,在effective java中提到“異常轉譯”和“異常連接”的概念。本人傾向于用“異常轉譯”,前提是要配置log4j,并作詳細的日志紀錄。
?XmlBeans由 BEA公司發明,后捐贈給Apache基金會的。
?在項目中遇到這樣的需求,根據已有的schema對xml進行格式校驗,并讀取出xml得數據。
?在大搜一番后,我最終把目光停留在xmlbeans上面。被淘汰的是digester.
?下面是一篇dev2dev得文章:
??http://dev2dev.bea.com/pub/a/2006/05/xmlbeans-2.html?page=4
?我就不炒飯了。
?好心的人給簡單翻譯了一下:
http://dev2dev.bea.com.cn/techdoc/200403127.html
?翻譯得內容很少,有空本人補上。
ibm dw上也有個豆腐塊:
http://www-128.ibm.com/developerworks/cn/xml/x-beans1/
關于digester的內容,只選了一篇文章:來自devx得
http://www.devx.com/Java/Article/21832/1763
關于2中方法的對比,他們的文章已經說的很詳細了。
xmlbeans采用的是sax來讀取數據。2004年,由bea公司發明的stax(stream API for XML)已經被jcp列為標準jsr-173,在jdk6.0中會出現。
?
關于stax,sax和dom的對比超出本篇范圍,在此略過。
后記:
? 在正在完成的項目中,我采用了xmlbeans,它的引入給我帶來了很大的方便.
|