|
#
放一些屏幕截圖來看圖說話吧
流程設計界面
左邊下拉框放至了我所有允許定義流程的業務對象類型,可通過底部的"新增"\"修改"\"刪除"等操作進行維護.點擊已定義的流程可以查看對應的流程設置
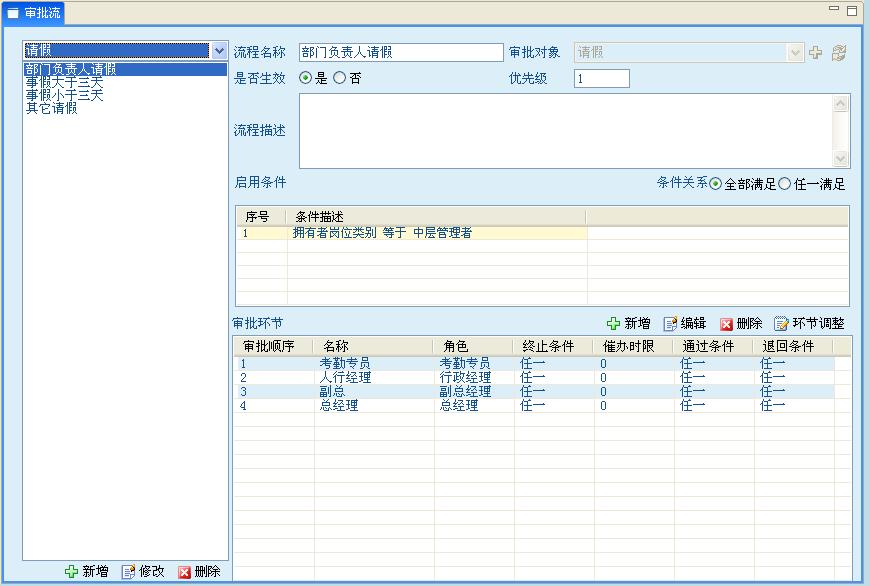
新增流程界面
新增時可為該流程設置相關啟用條件,優先級別及審批步驟等
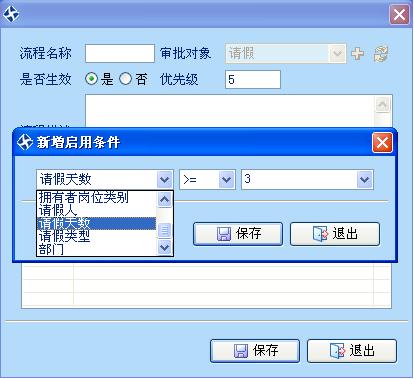
審批人的待辦工作臺,可以這里統一處理各類待辦業務:
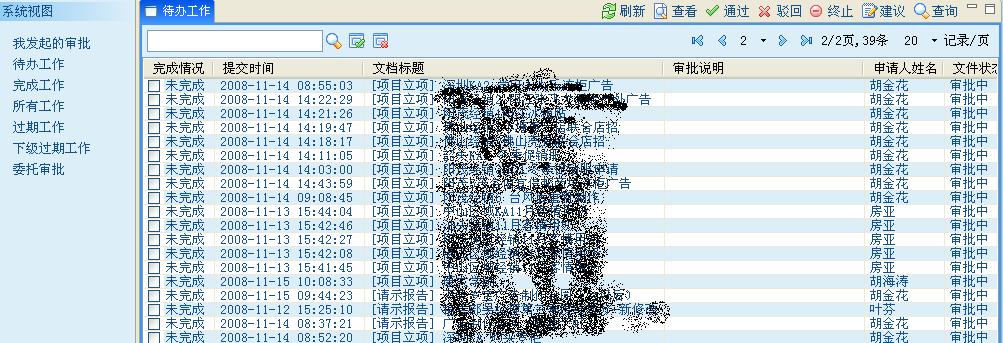
待辦業務的查看界面:
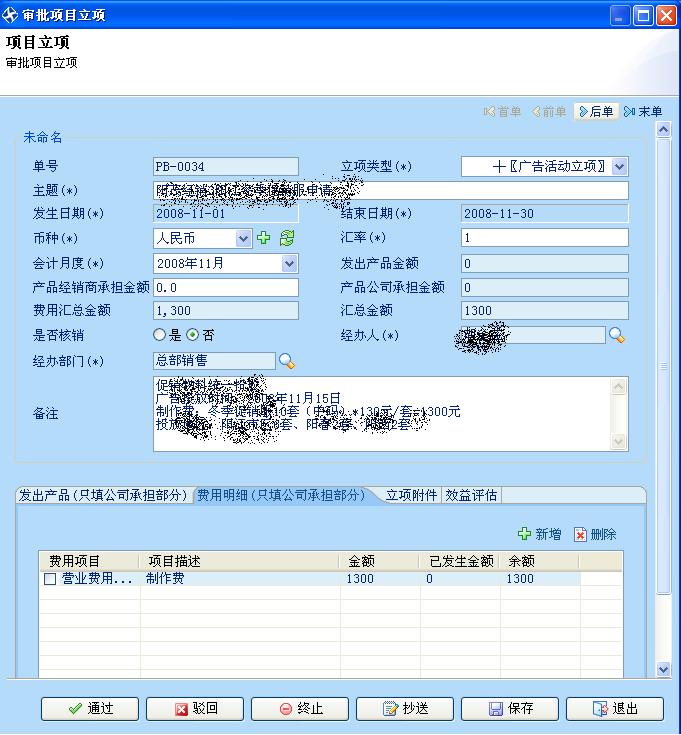
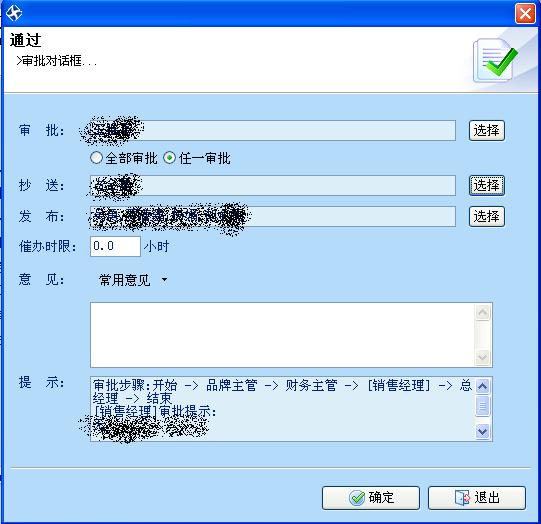
審批流轉界面(以通過為例)
下面給出UML圖供大家參考:
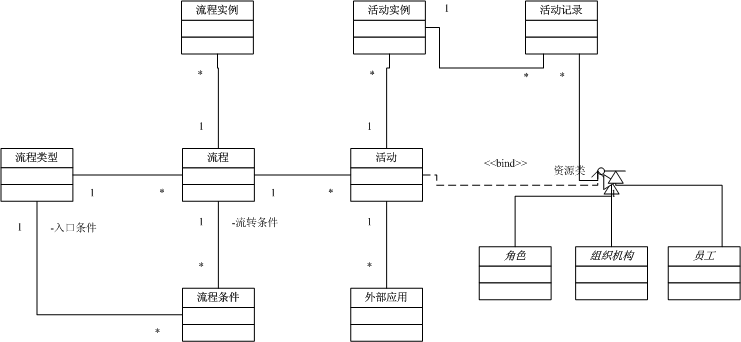
其中:
流程類型、流程、活動、流轉條件、外部應用為設計時對象,用于描述流程規則
流程實例、活動實例、活動記錄為運行時對象,用于記錄實際發生的流程運行狀況
需要解決的問題是,如何將我們的應用與此工作流引擎進行結合?我的解決方法是:
1、流程類型約定業務對象類型(即此流程可以與哪種業務對象關聯)
2、業務對象中的屬性或其組合可以定義為流轉條件(即實現業務對象信息影響工作流流轉)
3、活動執行者可以選擇業務系統的組織機構、角色、人員定義(我是通過接口方式進行約定,IOC注入)
4、活動可調用已定義的應用(可多個)
5、業務對象可以通過報批動作啟動工作流實例,之后由工作流按照設計信息與業務信息進行自動流轉或全程提供表單與審批按鈕支持。
由于此工作流系統是出于簡化的目的進行設計的,設計時與運行時信息我都使用數據庫信息來表示,設計器也未提供拖拉界面來進行設計,而是采用順序定義的方式來操作。在實際運作過程中,我覺得它可以滿足一般規模不大(文職人員100人左右)的企業的OA應用。
本人原創文章,歡迎轉載,轉載請注明出處!
工作流引擎產品無論國內或國外都有不少成熟之作,開源的工作流產品也有諸如shark之類的精品。但工作流產品做為一個獨立的中間件,無論是其本身或通過它進行流程設計及與你自己的系統整合,對很多使用過工作流產品的開發人員來說都是一件不容易的事。特別是在一些其實只是一些很簡單的流程控制應用需要時,我們是否需要一個獨立的工作流產品來運作呢?
也許你可以嘗試自己做一個工作流組件?聽起來好象有點兒難,但其實并不是一件很恐怖的工作。讓我們先從通常會使用到工作流引擎的情景分析下我們需要什么?
情景:某公司需要對員工請假進行管理,員工請假需進行系統填寫申請,如果請假天數<=1天,可以部門主管批準。如果請假天數>1天,需由部門主管->副總經理進行再行批復。批準后的請假自動記入考勤系統。
從這個簡單的業務需求,我們進行分析它的需求:
1、工作流程的選擇是由業務信息(請假單)相關聯的,工作流獨立存在是無意義的。
2、業務信息中的內容會決定流程的選擇與流向。如:請假天數,或是主管的批復意見
3、工作流程的流轉與組織結構、角色、員工相關。
4、工作流程通常會調用相關業務應用(記入考勤)來完成多應用系統之間的協作。
結合以上需求,我們定義出工作流系統所需功能與數據:
1、流程定義工具(負責生成工作流引擎能明白的流程控制信息),對應于XPDL
2、工作流控制變量定義(即用于控制流程流轉的控制量,如請假天數與各級審批意見,可由系統根據流程實體信息自動注入至工作流引擎)
3、工作流相關數據,即與業務過程相關的數據,如:業務表單、組織結構、角色、員工等
4、工作流引擎,負責解釋流程定義,創建過程實例并控制其執行,并可能提供相關的監控界面以保障工作流的正確運轉。
5、外部應用,可由工作流引擎進行調用完成多個業務系統的流程銜接。這通常是工作流引擎的最大亮點。
未完待續>>
本人原創文章,歡迎轉載,轉載請注明出處!
* 如何在minilang中使用Java靜態方法獲得數據
使用beanshell腳本:
 <set field="notApplied" value="${bsh:org.ofbiz.accounting.invoice.InvoiceWorker.getInvoiceNotApplied(invoice)}" type="Double"/> <set field="notApplied" value="${bsh:org.ofbiz.accounting.invoice.InvoiceWorker.getInvoiceNotApplied(invoice)}" type="Double"/>
警告:你必須使用type=""來轉換你的結果類型,否則的話,它將返回字符串類型.
* 如何在minilang中調用Java程序
你可以在minilang中插入一段beanshell代碼,類似于 applications/ecommerce/script/org/ofbiz/ecommerce/customer/CustomerEvents.xml的示例:
<call-bsh><![CDATA[
String password = (String) userLoginContext.get("currentPassword");
String confirmPassword = (String) userLoginContext.get("currentPasswordVerify");
String passwordHint = (String) userLoginContext.get("passwordHint");
org.ofbiz.securityext.login.LoginServices.checkNewPassword(newUserLogin, null, password, confirmPassword, passwordHint, error_list, true, locale);
]]></call-bsh>
在beanshell腳本中可以訪問在minilang中所有的變量
* 清除 與 刷新的比較
<clear-field field-name="foo"/> 設置它為null. 這可以是一個類的屬性或是集合中的一個值
<refresh-value value-name="foo"/> 從數據庫中重新獲得foo的值. foo必須是一個GenericValue.
* 如何設置一個布爾值
我無法找到任何例子,但是我這樣做是成功的:
<set field="orderAvailableCtx.countNewReturnItems" value="true" type="Boolean"/>
我想minilang使用type=""中的類型與value中的值的做為構造調用.猜想在某天我看到這些代碼時能證明我是對的...
本文檔譯自ofbiz 4.0 cookbooks,本人翻譯,歡迎轉載,請注明出處.
我的產品是被要求運行在多種常見數據庫平臺下(mysql/sqlserver/oracle)下,在開發中需要嚴格遵循相關的規范以確保能夠實現跨數據庫類型的要求.(相關的要點在我的"你的系統真的因為使用hibernate就可以適應各種數據庫嗎? "一文中已提及).在初始開發時有一個問題是比較困擾我的團隊的,我們開發的時候必定是基于某個特定的數據庫開發的(比如mysql),但在測試階段是需要在不同的數據庫平臺下進行兼容性測試,由于開發過程中數據庫結構與種子數據變化非常快,全部編寫sql方式非常浪費時間,如何能找到一種高效的數據庫相互遷移的工具,是我們當時所急需的解決方案.
其實也沒啥選擇,比較常用的數據庫遷移工具就是Sqlserver自帶的DTS,這玩意在sql server數據庫間進行數據導入/導出時倒確實比較好用,在不同數據庫類型進行操作時,就會出多多問題,如:類型轉換需手工指定/導出字段有雙引號...
所以最后的選擇就是自己做一個DTS好啦,思路如下:
1、選擇源數據庫連接與目標數據庫連接
2、根據源數據庫遍歷所有數據庫對象(表),做為基準
3、刪除目標數據庫所有表外鍵及索引、刪除所有種字數據(根據約定)數據、字段均允許null
4、遍歷源數據庫中所有表,為目標數據庫修改結構(如增刪字段,字段改類型、大小)
5、將源數據庫中種子數據表數據拷貝至目標數據庫中
6、根據源數據庫為目標數據庫中的表創建外鍵及索引、設置是否允許為null
7、搞掂!
完工后總代碼量不過兩千行(因為需考慮不同數據庫的SQL Dialet,否則應該更少)
用戶界面基于Eclipse RCP技術開發,使用JFace Wizard向導(如果不是想用向導的話,你可以用SWT來做)對話框獲得源數據庫與目標數據庫的連接內容,并在用戶點擊完成按鈕后,在進度條中提示用戶執行情況.用了這個玩意以后,測試同事的數據庫兼容性測試就再也不用來煩我們開發組啦!真是爽呀!當然很多喜歡折騰的客戶(比如突然在哪里聽說oracle是大型數據庫,非讓你幫他弄過去)此類朝三暮四也就自然不在話下啦!
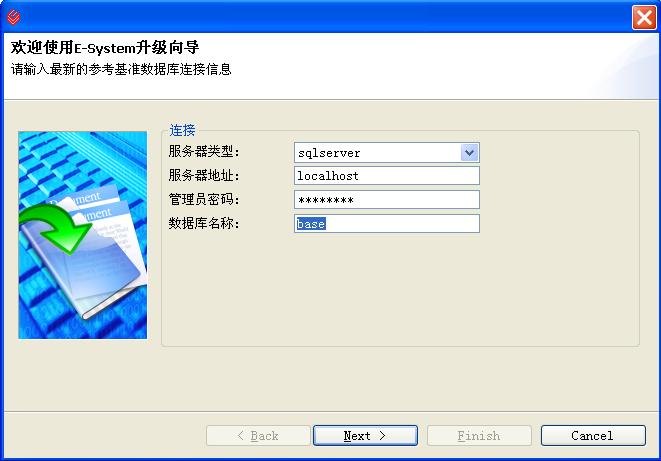
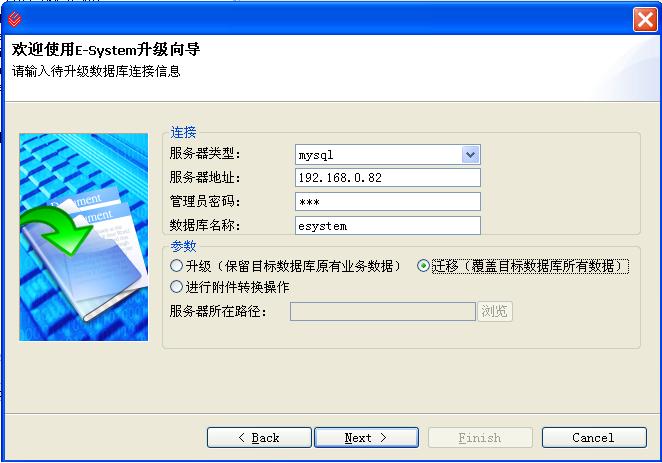
本人原創文章,歡迎轉載,轉載請注明出處!
* 如何為SELECT SUM(QUANTITY - CANCEL_QUANTITY) AS QUANTITY之類的語句設置別名
<alias entity-alias="OI" name="quantity" function="sum">
<complex-alias operator="-">
<complex-alias-field entity-alias="OI" field="quantity" default-value="0"/>
<complex-alias-field entity-alias="OI" field="cancelQuantity" default-value="0"/>
</complex-alias>
</alias>
SELECT SUM(COALESCE(OI.QUANTITY,'0') - COALESCE(0I.CANCEL_QUANTITY)) AS QUANTITY在結果集包含默認值是一個好的習慣,否則如果有一項為null,那么最終相減的結果就也為null了.
操作符可以為任何你當前使用數據庫所支持的SQL操作符,比如算術運算符+, -, * 和/ 或者字符串連接符 ||.
你可以增加function=""標簽來完成在complex-alias-field中的min, max, sum, avg, count, count-distinct, upper 及lower集合運算. 示例, 以上的定義可以用另一種方法表示為:
<alias entity-alias="OI" name="quantity">
<complex-alias operator="-">
<complex-alias-field entity-alias="OI" field="quantity" default-value="0" function="sum"/>
<complex-alias-field entity-alias="OI" field="cancelQuantity" default-value="0" function="sum"/>
</complex-alias>
</alias>
即為SELECT (SUM(COALESCE(OI.QUANTITY,'0')) - SUM(COALESCE(OI.CANCEL_QUANTITY,'0'))) AS QUANTITY查詢結果集
* 我討厭OFBiz的實體引擎,我要自己的JDBC連接!
好的,以下是你獲得JDBC連接的方法:
import org.ofbiz.entity.jdbc.ConnectionFactory;
String helperName = delegator.getGroupHelperName("org.ofbiz"); // gets the helper (localderby, localmysql, localpostgres, etc.) for your entity group org.ofbiz
Connection conn = ConnectionFactory.getConnection(helperName);
Statement statement = conn.createStatement();
statement.execute("SELECT * FROM PARTY");
ResultSet results = statement.getResultSet();
//  通過普通JDBC 的結果集來操作 通過普通JDBC 的結果集來操作
//Alternatively, you can use the SQLProcessor like this:
SQLProcessor sqlproc = new SQLProcessor(helperName);
sqlproc.prepareStatement("SELECT * FROM PARTY");
ResultSet rs1 = sqlproc.executeQuery();
ResultSet rs2 = sqlproc.executeQuery("SELECT * FROM PRODUCT");
你可以查看framework/webtools/webapp/webtools/WEB-INF/actions/entity/EntitySQLProcessor.bsh了解它的使用
在以下網址你可以獲得相關JavaDoc的內容:
http://www.opentaps.org/javadocs/version-1.0/framework/api/org/ofbiz/entity/jdbc/SQLProcessor.html
http://www.opentaps.org/javadocs/version-1.0/framework/api/org/ofbiz/entity/jdbc/ConnectionFactory.html
*** 請先考慮以下內容: 你放棄數據庫的無關性意味著你在某些方法將無法與框架或其它程序集成.你確定你要這么做嗎?
獲得更好的做法,請訪問 http://www.opentaps.org/docs/index.php/Using_the_Query_Tool
* 關于時間比較方法的一些警告
在你用 GREATER_THAN比較一個 Timestamp類型數據時, 你有可能獲得相同的時間數據:
delegator.findByAnd("XXX", UtilMisc.toList(new EntityExpr("fromDate", EntityOperator.GREATER_THAN, "2007-12-31 23:59:59.998")));
有可能包含fromDate=2007-12-31 23:59:59.998的數據. (此種情況發生于PostgreSQL 8.1并且GenericDAO 類生成的SQL代碼是'FROM_DATE > ' so 所以我也不明白發生這個問題的原因.) 所以確保安全的方法是, 增加1秒到需要比較的時間中然后使用 GREATER_THAN_EQUAL_TO方法
delegator.findByAnd("XXX", UtilMisc.toList(new EntityExpr("fromDate", EntityOperator.GREATER_THAN_EQUAL_TO, "2008-01-01 00:00:00.998")));
* 警告: 在空集合中使用EntityOperator.IN
請小心如果使用EntityOperator.IN去判斷一個非空集合在一個空集合中的包含項,你有可能獲得一個語法錯誤: 在Derby或者其它一些不為人知的數據庫中可能會出錯.
所以建議你能在使用EntityOperator.IN之間,通常執行UtilValidate.isNotEmpty方法來判斷一下結果集是否為空
* 警告: delegator.getNextSubSeqId 不能確保唯一性
很多實體有很多合成的主鍵.示例OrderItem's 主鍵是orderId + orderItemSeqId. InventoryItemDetail's 主鍵是inventoryItemId +inventoryItemSeqId. 通常, delegator.getNextSubSeqId 通常是獲得一個序列值,但是在多線程的訪問下有可能無法確保生成的值的唯一性. 此段內容在 http://issues.apache.org/jira/browse/OFBIZ-1636 中有相關文檔記錄.
當前, 如果有可能多個線程嘗試同時寫入實體組合鍵時,可以使用delegator.getNextSeqId來替代getNextSubSeqId. (此問題不會發生于OrderItem, 因為它只使用單線程寫入, 但有可能發生于 InventoryItemDetail, 它使用多線程來創建庫存記錄項.)
完>>
本文檔譯自ofbiz 4.0 cookbooks,本人翻譯,歡迎轉載,請注明出處.
* 我可以在entitymodel.xml文件中定義自己的view-entities嗎?
不能, 你可以動態定義它們.你可以查看org.ofbiz.party.party.PartyServices中的findParty方法學習它的使用
* 如果為有效期間創建條件?
我們提供了一組非常有用的方法EntityUtil.getFilterByDateExpr ,它能返回一個EntityConditionList根據有效期間來篩選一個結果集.
* 如何在大數據結果集下工作
如果你檢出一個大的數據結果集,你應當使用EntityListIterator通過迭代方式讀取數據,而非List.
示例,如果你使用:
List products = delegator.findAll("Product");
你可能獲得一個"java.lang.OutOfMemoryError". 這是由于你通過findAll, findByAnd, findByCondition等方法來獲得一個大的內存數據結果集導致內存溢出. 在這種情況下, 應該使用EntityListIterator迭代方式來讀取你的數據. 這個示例應改寫成:
productsELI = delegator.findListIteratorByCondition("Product", new EntityExpr("productId", EntityOperator.NOT_EQUAL, null), UtilMisc.toList("productId"), null);
注意獲得EntityListIterator的方法只用通過條件, 所以你需要將你的條件重寫為EntityExpr (在此次情況下,productId是主鍵字段不可能為空的, 所以將返回所有Proudct實例,)或 EntityConditionList.
此方法參數中包含檢出的字段(這里為productId)以及排序字段(這里不需要,所以賦了null)
你可以傳遞一個null作為EntityCondition參數來獲得所有結果.然后這不一定在所有數據庫下都能正常工作! 在maxdb及其它不常用的數據庫下時你要小心使用這些高級功能.
* 如何使用EntityListIterator
當我們通過EntityListIterator迭代訪問數據時, 通常是這樣:
  while ((nextProduct = productsELI.next()) != null) { while ((nextProduct = productsELI.next()) != null) {
 . .
// operations on nextProduct
 } }
在EntityListIterator 中使用 .hasNext()方法是一種不經濟的做法.
在你完成你的操作后,要記得關閉此迭代
productsELI.close();
* 如何查詢無重結果集
當前只能通過list iterator方法并指定EntityFindOptions參數,示例如下:
listIt = delegator.findListIteratorByCondition(entityName, findConditions,
null, // EntityConditions參數
fieldsToSelectList,
fieldsToOrderByList,
//關鍵部分. 第一個true表示"specifyTypeAndConcur"
// 第二個true指完是一個濾重查詢. 顯然在實體引擎中只能通過這個方法來進行濾重查詢
new EntityFindOptions(true, EntityFindOptions.TYPE_SCROLL_INSENSITIVE, EntityFindOptions.CONCUR_READ_ONLY, true));
在minilang, 它會更簡單:
<entity-condition entity-name="${entityName}" list-name="${resultList}" distinct="true">
<select field="${fieldName}"/>
.
* 如何進行一個大小寫不敏感的查詢(即不分大小寫)
你需要查詢條件表達式兩邊均轉為大寫,示例:
andExprs.add(new EntityExpr("lastName", true, EntityOperator.LIKE, "%"+lastName+"%", true));
(來源org.ofbiz.party.party.PartyServices)
* 如何將EntityListIterator轉換成List
使用EntityListIterator.getCompleteList() 及getPartialList 方法
* 如何自動獲得下一個ID值
在minilang 中使用 <sequence-id-to-env ...> 或在Java中通過delegator.getNextSeqId(...) 獲得 . id序列存放于SequenceValueItem中.
* 關于ID值的一些警告
不要在種子/演示數據中使用10000做為數據的ID,當系統嘗試自動創建數據時,它們都將嘗試10000,這將導致一個鍵值沖突錯誤.
* 如何從一個明細項中獲得序列ID
有些實體,比如擁有itemSeqId 的InvoiceItem(發票明細項) and OrderItem(訂單明細項).此項通常在你處一次為item生成GenericValue 時自動生成ID,之后向delegator要求生成項目的seq Id:
GenericValue orderItem = delegator.makeValue("OrderItem", orderItemValues);
delegator.setNextSubSeqId(orderItem, "orderItemSeqId", ORDER_ITEM_PADDING, 1);
未完待續>>
本文檔譯自ofbiz 4.0 cookbooks,本人翻譯,歡迎轉載,請注明出處.
* 保持實體名稱少于25個字符
這個限制主要是為了Oracle只支持30字符以內的數據庫對象名稱,再加上OFBiz會自動在單詞之間加上"_",所以就得出了這么個限制.
* 關聯的工作方式
它們定義于entitymodel.xml文件中的<entity>段,示例如下:
<relation type="one" fk-name="PROD_CTGRY_PARENT" title="PrimaryParent" rel-entity-name="ProductCategory">
<key-map field-name="primaryParentCategoryId" rel-field-name="productCategoryId"/>
</relation>
<relation type="many" title="PrimaryChild" rel-entity-name="ProductCategory">
<key-map field-name="productCategoryId" rel-field-name="primaryParentCategoryId"/>
</relation>
type這個屬性標簽定義關聯類型: "one"表示一對一,"many"表示從此實體引出的一對多關系
fk-name的屬性值是數據庫外鍵名.為自己的外鍵命名是一個好的習慣,雖然如果你不設置此屬性,OFiz也會自己建外建.
rel-entity-name的屬性值指向關聯的實體名稱
title用來區分兩個實體之間的多重關系
<key-map>節點定義關聯中使用到的字段.field-name指向本實體內的引用字段,rel-field-name定義關聯的實體字段,你可以通過多個字段組合關聯
當你訪問一個關聯,你可以使用title+entityName作為參數調用.getRelated("")或.getRelatedOne("")方法.在關聯為"many"時使用.getRelated("")是恰當的,因為它返回一個List,同樣在關聯為"one"時通過.getRelatedOne("")方法獲得一個值.
* view-entities相關內容
view-entities的功能非常強大,它允許你可以創建一個join-like查詢,即使你的數據庫不支持join.
關于你數據庫的join語法存放在entityengine.xml的datasource節點下的join-style屬性中.
當你通過<view-link...>節點將兩上實體連接起來時,記住:
1. 實體名稱順序是重要的
2. 默認的連接方式是inner join(即同樣的值存在于兩個實體類中),外連接需要使用rel-optional="true"
如果多個實體中擁有相同的字段名稱,比如statusId,結果集中的statusId使用第一個實體中的該列,其它實體中的同名列將被丟棄.如果你想要同時獲得這些列,你需要通過在其之前加入<alias-all>節點,一個方式是使用<alias ..>節點來為不同實體的同名字段起別名,示例:
<alias entity="EntityOne" name="entityOneStatusId" field="statusId"/>
<alias entity="EntityTwo" name="entityTwoStatusId" field="statusId"/>
另一種方法是在<alias-all>節點中使用<exclude field="">,如下:
<alias-all entity-alias="EN">
<exclude field="fieldNameToExclude1"/>
<exclude field="fieldNameToExclude2"/>
</alias-all>
這樣也可以排除掉很多不打算使用到的信息,特別是在一個非常大的表中查詢時.
如果你打算執行類似于以下的查詢語句時:
SELECT count(visitId) FROM GROUP BY trackingCodeId WHERE fromDate > '2005-01-01'
需要包含字段visitId以及function="count" 標簽,trackingCodeId需加上group-by="true"標簽,fromDate需要加上group-by="false"標簽
在你進行查詢時,有一件非常重要的事情需要注意,比如說delegator.findByCondition方法,你必須指定檢出的字段列表,并且你不能指定fromDate字段,否則你將得到一個錯誤.這就是為webtools不能夠使用view-entities來查看的原因.
你可以查看applications/marketing/entitydef/entitymodel.xml的底部內容學習,及通過applications/marketing/webapp/marketing/WEB-INF/actions/reports學習beanshell腳本的調用.
未完待續>>
本文檔譯自ofbiz 4.0 cookbooks,本人翻譯,歡迎轉載,請注明出處.
項目總結不知道大家是否都會真正去做,隔段時間會不會再去閱讀與體會當時的心情呢?找出一篇舊時的項目總結,細細讀來,看得仿佛還能感覺到當時的心酸。這個項目是我剛進入一家公司不久的情況下,我的職位是PM,當時公司有一個遲遲不能終驗的項目,拖了三年,據說在我之前項目經理已經換了四任,所有項目成員也都不在公司里了。所以公司里資深些的PM都不愿意接這個項目,我想大家做過項目都明白,項目獎早就分完了,而且公司只剩尾款未收,根本就不愿意真正投入人力去完成這個項目,只是對客戶有個交待罷了。于是,這么個爛攤子就落在我這個當時的新人身上了。
從總結中摘抄一些部分放在這里,希望可以安慰時有低落心情的我及有相似遭遇的朋友們:
一堆無人愿去看的源代碼、無一原項目組成員的參與、充斥報怨的客戶、亂七八糟的文檔、無序的需求...這一切使得每個人不禁望而生畏。說實話,當時我心里也是非常不愿意接手這個項目的,心想:這個項目我對其一無所知、因為當時項目開發已進行了多年,需求與最初已發生極大變化、重新搜集需求又得不到客戶的理解與支持、項目組普遍彌漫著一種失敗論的氣氛。
沒有人愿意接,公司領導指派我去完成這件事。那我就抱著盡力試一試的想法參與進來。從此進入了漫長的需求摸索(資料不全、負責此項目客戶的變化)、完整的功能的再次開發(我項目組無人精通Delphi,也無人愿意去看無文檔無人員支持的原有的代碼),還要在此過程去平息客戶的怒火及吸收理解客戶業務的內涵。在這漫長的過程,沒有太多的肯定或成為焦點的可能。很有些苦悶的時候,我也想要去放棄——承認自己的無能、不愿再面對這種混亂的局面... 在這個過程中,幸有項目組人員、公司領導的理解與支持及自己不愿認輸的因素才能堅持到今天。
從這個過程我也學到了對客戶業務的理解。我想今日的我再不會象初接手這個項目面對客戶時,那樣不敢說出自己的建議和業務理解了。
時至今日,總結過去所發生的,有一些經驗和想法愿意與大家分享:
(1)在你最苦惱的時候,請勿輕言放棄,你的成功不是為了得到鮮花與掌聲。做完你要做的事,是你自己的成功;離成功最近的地方也是最易放棄的地方。
(2)選擇一至兩個可以傾訴的對象,他們的支持(可能只是傾聽你的牢騷)會是你最大的動力。
(3)團隊的力量:選擇一個假想敵或是共同的目標(不能讓這些打算看你們笑話的人的陰謀得逞),會成為你這個團隊戰斗力的最大源泉
(4)表面看起來蠻不講理的客戶是你最好的老師:只因為他得不到他想要的東西,才會看起來這樣蠻不講理。
過去的經驗,也許快樂,也許心酸。但回首時,只要你有真正的努力,你一定有屬于自己的收獲!
在整理自己的文檔庫時發現了這篇五年前在另家公司工作時向公司老大提議"軟件技術支持組"的一個建議書,后來因為由于缺乏相關的推動力(當時自己還只是一個PM并缺乏相應的授權與支持),最終并沒有達到設想的效果,現在發出來聊以紀念一下年青時的想法吧:
1 前言
在近期推動組件庫項目實施的過程中,經常感覺到沒有執行能力能夠推動公司技術革新之困境。現征詢xxxx咨詢公司及其它朋友意見之后。現向您建議成立公司軟件技術支持組(PIT)并授予相應職責的權力以負責公司的技術(工具、方法和過程)的挑選和識別,并將經過挑選和驗證的技術有序地引入公司的軟件開發過程。
2 實施后的藍圖
1、公司由于技術的先進性獲得市場競爭地位的極大提高。
2、售前人員可使用PIT根據公司用戶市場情況、技術積累、成本因素、資源情況所制定出的商業解決方案向客戶銷售,對銷售可起到良好的技術支持作用。
3、將過程財富(組件、工具、方法、經驗)及規范標準在公司各軟件項目中實施,可極大降低研發部門(成本中心)所耗費的巨額開發成本,獲得最大的投入產出比。
4、可對風險進行預先評價,做好風險預防。
5、項目經理或銷售人員可在需求調研階段即可獲得公司已有財富的情況和資源分配情況,對用戶的引導可有的放矢,從而帶來諸多額外的收獲。
6、可有效的鼓舞公司研發人員的士氣,加強公司戰斗力和凝聚力。
3 PIT的職責
1、 PIT對SEPG和高層管理者負責,有專門的定期匯報渠道。經批準后的行動計劃和規范制度對公司研發部員工具有強制性。
2、 向公司高層匯報公司技術積累情況,長期技術策略以及提高公司市場競爭地位的發展路線。并負責安排和提供相應的實施計劃(包括技術更新可能涉及的范圍、更新的時機、可選的方案、評估情況、初期培訓及指導、成本耗費情況)。經同行評審和高層批準后負責安排實施。
3、 負責收集市場、客戶、項目的數據并根據公司技術積累、成本因素、資源情況、用戶市場情況制定出銷售所適用的解決方案。
4、 負責的技術范圍包括:軟件重用、CASE技術、架構設計、組件庫規劃及安排實施、語言規范及對應的形式方法。支持的范圍包括語言、數據庫、工具。并負責向外界尋求組織內部無法解決的技術問題。
5、 與各軟件項目組一同確定軟件開發計劃,向項目組提供可用技術、已有技術積累應用及相應標準開發方法、開發工具、語言、過程的選擇。并將在項目中應用的情況記錄入過程財富庫。
6、 負責提供公司的技術(工具、方法、語言、架構等)參考數據,包括:風險評價、公司資源情況、生產率、成本、進度、缺陷率、已知問題列表及公司已有技術積累情況。
7、 負責提供工具、方法、過程、新技術的培訓及指導。
8、 負責收集本組工作結果,并成文歸檔。估計其在組織中的效益與影響、風險。決定是否在公司大規模推廣、否決或重新試驗。
這只是一個建議書,只是想從實施后的效果與日常的工作職責讓老大明白這件事的意義,具體的計劃與KPA文檔就不一并附上了 。
|