
2006年8月15日
兒子:謝謝你!昨天過母親節請我吃飯。還送了我那么貴的u盤。這是我好久以來最開心的一回了!
今天上午我在電腦上看電視劇《盛夏晚晴天》的45集,夏正朗的話我很認可,有道理。說給你看一下:一個男人在30歲之前,能有一次徹底的失敗,讓他一無所有,那將是一個很幸運的事情。
因為他能可以從失敗中,認識失敗,戰勝失敗,卷土重來。他可以以自己的魅力,銳不可擋的干勁來改變。
在這個世界上,只有想不到的事,沒有做不到的事。要敢愛、敢恨、敢錯、敢當!希望你幸福、快樂、健康!
我的兒子是一個誠實、善良、靠得住的好孩子。希望你在社會這所深凹的大學里,經得起風吹浪打,經得起考驗。有一句話,很有哲理。就是激勵自己的不是鮮花和掌聲,而是挫折、失敗和教訓!
我和你爸都是在這個世界里,最愛你的人,我們也在期盼你能照顧我們一輩子。嘿嘿、、、謝謝你,為我們奉獻了很多。、
posted @
2013-06-07 22:06 Stephen 閱讀(179) |
評論 (0) |
編輯 收藏 海爾總裁張瑞敏在序言中寫到:“看德魯克的書是一種享受,因為常常使人有茅塞頓開之感。” 的確,德魯克的書沒有任何故弄玄虛,都是實實在在的道理,尤其是這本經典中的經典,每次讀過以后都有不同的感受。
管理是一門學問,如何讓管理變得卓有成效的確是一個很大的問題。很多人從做具體的事情開始走向管理崗位的時候,都會覺得有點無所適從:有些人開始抱怨時間變得不可控,尤其是可能沒有機會做一些曾經讓自己很有“成就感”的工作;有些人不知道如何與下屬和上級打交道,不知道怎樣讓團隊變得有效率;有些人不知道如何做決策,每次做決策不是瞻前顧后,就是武斷決策。《卓有成效的管理者》這本書,恰恰給了這些人最好的答案,最佳的實踐經驗,這本薄薄的書,沒有大費周折的闡述什么講大道理,沒有長篇累牘的講故事,只是把這種好像很明顯但又往往讓我們經常想不到的道理娓娓道來。其實卓有成效的管理很簡單:管理好自己的時間、學會用人和讓團隊有成效、做好決策。
一、管理好自己的時間
作為一個卓有成效的管理者要會掌握自己的時間,要合理的利用自己的時間,時間用在能產生效益的事情上。管理者必須面對四個無法避免的難題:時間往往只屬于別人,而不屬于自己;管理者往往被迫忙于“日常運作”,除非他們敢于采取行動來改變周圍的一切;本身處于一個組織中,受組織的局限。要成為有效管理者,首先,必須知道自己的時間用在什么地方上;其次,要學會將時間整塊運用;再次,管理好自己的時間,消除浪費時間的活動,統一安排可以自由支配的時間。
二、學會用人和讓團隊有效率
管理者的作用不僅是自己如何可以高效率的工作,而更重要的是如何讓團隊有效的工作,因為一個人再優秀也只是一個人,而一個優秀的團隊的作用更是遠遠大于把這些人的單產累加起來,這就是為什么很多人說1+1>2的道理。從德魯克的書中,我們明白了,讓團隊有效率其實很簡單,就是正確的用人并發揮他們長處,然后學會自己可為團隊做些什么。
漢高祖劉邦說:“夫運籌帷帳之中,決勝千里之外,吾不如子房(即張良)。鎮國家,撫百姓,給饋餉,不絕糧道,吾不如蕭何。連百萬之軍,戰必勝,攻必取,吾不如韓信。此三者,皆人杰也,吾能用之,此吾所以取天下也。”有效的管理者在用人時,不在于如何克服人的短處,而在于如何發揮人的長處。
同時,作為一個有成效的管理者要知道自己能做些什么貢獻,并且要知道能為下屬做些什么貢獻,才能讓這些知識工作者有效的工作。重視貢獻,才能使管理者的注意力不為自己的專長所限,不為其本身的技術所限,不為其本身所在的部門所限,才能看到整體的績效,同時,也能使其更加重視團隊,只有團隊才是真正產生成果的地方。
三、做好決策
決策是非常具有風險的舉動,但是如何一個管理人都需要做出各種決策,你的決策可能會影響到公司的利益和伙伴的利益、績效及成果,這就是管理者存在的最重要的一項功能。
卓有成效的管理者必須善于做出正確的決策,要做出決策就要有明確目標、權衡現有資源、反復推敲,反復的斟酌、落實行動、實時反饋,衡量你的決策是否正確,給你的決策留更多的調整空間和機會。
在做決策之前要善于聽取各方意見,善于使用發散性思維和收斂性思維來搜集聽取各方信息;要進行大量的風險評估如果收益大于支出那么就立即執行;一旦執行就要頂住壓力,處理好時間問題、處理好人際問題;重視反饋學會聽取各方意見擠反饋的信息,信息中有好有壞要通盤分析,驗證決策的正確性。
posted @
2010-04-18 21:42 Stephen 閱讀(307) |
評論 (0) |
編輯 收藏
最近同事推薦office 2007比較好用,于是裝了一個,
但是在用outlook時比較麻煩,我其中的一個郵箱沒辦法收pop3的郵件,總提示密碼錯誤,要求輸入密碼,
但是我用2003的時候是可以的,
于是我在嘗試各種組合,發現outlook 2003 、foxmail,都可以從這個pop3收到郵件,
但是outlook 2007就是不可以,
于是嘗試用office 2007+outlook2003來用,
結果出現的新的問題,outlook不能使用word作為郵件編輯器了,
經過嘗試:
1、office 2003 與office 2007 不能在同系統共存;
2、outlook 2003 與 outlook 2007 也是同樣;
3、office 2007 與 outlook 2003可以共存,但是問題是outlook2003只能使用word2003作為編輯器,而不能使用2007的;
麻煩呢,目前我暫時用的第三種方案,
關于不能收郵件的原因,目前估計是端口的問題,因為公司的網絡環境比較嚴格,需要申請開通端口,
估計是2007驗證時使用了什么不知道的端口,等有時間再網絡工程師調試一下。
posted @
2009-04-13 22:54 Stephen 閱讀(820) |
評論 (0) |
編輯 收藏
最近總感覺事情太多,要做的事情很多,要學習的東西很多,要看的書很多,
然后準備好了以后,又沒毅力做下去了,
還是執行力不夠,
目標太多,就沒有了方向,
要減少目標:
1、職業發展方向要確定,不能每個方面都兼顧,可以關注,但要確定一個主要的方向;
2、不能每本書都精讀,沒有那么多時間,計劃的十本書,選兩本到三本精讀;
3、計劃時間不能定的太長,沒有約束力,要短、可達到。
工作上目標確定要少,上半年只有兩個月了,如果想看到成效,必須精力集中關鍵項上面:
1、完成配置管理與問題管理的優化;
2、平穩接手項目組的工作,融入到項目環境中;
3、初步了解項目的業務、背景;
posted @
2009-04-13 22:39 Stephen 閱讀(212) |
評論 (0) |
編輯 收藏
一、學習英語
二、讀十本書,完成讀書筆記
圖書目錄:
《走出軟件作坊》
《Scrum敏捷項目管理》
《IT管理知識體系》
《Head First 設計模式》
《UML寶典》
《人件》
《哲學與人生》
《web信息架構》
兩本待定
三、讀兩個開源框架代碼
四、寫十篇文章(項目管理、IT管理方面)
posted @
2009-02-15 21:29 Stephen 閱讀(224) |
評論 (0) |
編輯 收藏安裝RAR:
sudo apt-get install rar
sudo ln -fs /usr/bin/rar /usr/bin/unrar
posted @
2009-01-23 23:35 Stephen 閱讀(198) |
評論 (0) |
編輯 收藏進入vi的命令
vi filename: 打開或新建文件,并將光標置于第一行首
vi +n filename: 打開文件,并將光標置于第n行首
vi + filename: 打開文件,并將光標置于最后一行首
vi +/pattern filename: 打開文件,并將光標置于第一個與pattern匹配的串處
vi -r filename: 在上次正用vi編輯時發生系統崩潰,恢復filename
vi filename....filename: 打開多個文件,依次進行編輯
移動光標類命令
h: 光標左移一個字符
l: 光標右移一個字符
space: 光標右移一個字符
Backspace: 光標左移一個字符
k或Ctrl+p: 光標上移一行
j或Ctrl+n: 光標下移一行
Enter: 光標下移一行
w或W : 光標右移一個字至字首
b或B : 光標左移一個字至字首
e或E : 光標右移一個字至字尾
): 光標移至句尾
(: 光標移至句首
}: 光標移至段落開頭
{: 光標移至段落結尾
nG: 光標移至第n行首
n+: 光標下移n行
n-: 光標上移n行
n$: 光標移至第n行尾
H: 光標移至屏幕頂行
M: 光標移至屏幕中間行
L: 光標移至屏幕最后行
0: 光標移至當前行首
$: 光標移至當前行尾
屏幕翻滾類命令
Ctrl+u: 向文件首翻半屏
Ctrl+d: 向文件尾翻半屏
Ctrl+f: 向文件尾翻一屏
Ctrl+b: 向文件首翻一屏
nz: 將第n行滾至屏幕頂部,不指定n時將當前行滾至屏幕頂部。
插入文本類命令
i: 在光標前
I: 在當前行首
a: 光標后
A: 在當前行尾
o: 在當前行之下新開一行
O: 在當前行之上新開一行
r: 替換當前字符
R: 替換當前字符及其后的字符,直至按ESC鍵
s: 從當前光標位置處開始,以輸入的文本替代指定數目的字符
S: 刪除指定數目的行,并以所輸入文本代替之
ncw或nCW: 修改指定數目的字
nCC: 修改指定數目的行
刪除命令
ndw或ndW: 刪除光標處開始及其后的n-1個字
do: 刪至行首
d$: 刪至行尾
ndd: 刪除當前行及其后n-1行
x或X: 刪除一個字符,x刪除光標后的,而X刪除光標前的
Ctrl+u: 刪除輸入方式下所輸入的文本
搜索及替換命令
/pattern: 從光標開始處向文件尾搜索pattern
?pattern: 從光標開始處向文件首搜索pattern
n: 在同一方向重復上一次搜索命令
N: 在反方向上重復上一次搜索命令
:s/p1/p2/g: 將當前行中所有p1均用p2替代
:n1,n2s/p1/p2/g: 將第n1至n2行中所有p1均用p2替代
:g/p1/s//p2/g: 將文件中所有p1均用p2替換
選項設置
all: 列出所有選項設置情況
term: 設置終端類型
ignorance: 在搜索中忽略大小寫
list: 顯示制表位(Ctrl+I)和行尾標志($)
number: 顯示行號
report: 顯示由面向行的命令修改過的數目
terse: 顯示簡短的警告信息
warn: 在轉到別的文件時若沒保存當前文件則顯示NO write信息
nomagic: 允許在搜索模式中,使用前面不帶“\”的特殊字符
nowrapscan: 禁止vi在搜索到達文件兩端時,又從另一端開始
mesg: 允許vi顯示其他用戶用write寫到自己終端上的信息
最后行方式命令
:n1,n2 co n3: 將n1行到n2行之間的內容拷貝到第n3行下
:n1,n2 m n3:將n1行到n2行之間的內容移至到第n3行下
:n1,n2 d: 將 n1行到n2行之間的內容刪除
:w: 保存當前文件
:e filename: 打開文件filename進行編輯
:x: 保存當前文件并退出
:q: 退出vi
:q!: 不保存文件并退出vi
:!command: 執行shell命令command
:n1,n2 w!command: 將文件中n1行至n2行的內容作為command的輸入并執行之,
若不指定n1,n2,則表示將整個文件內容作為command的輸入
:r!command: 將命令command的輸出結果放到當前行
寄存器操作
"?nyy: 將當前行及其下n行的內容保存到寄存器?中,其中?為一個字母,n為一個數字
"?nyw: 將當前行及其下n個字保存到寄存器?中,其中?為一個字母,n為一個數字
"?nyl: 將當前行及其下n個字符保存到寄存器?中,其中?為一個字母,n為一個數字
"?p: 取出寄存器?中的內容并將其放到光標位置處。這里?可以是一個字母,也可以是一個數字
ndd: 將當前行及其下共n行文本刪除,并將所刪內容放到1號刪除寄存器中
posted @
2009-01-21 21:40 Stephen 閱讀(266) |
評論 (0) |
編輯 收藏
1. 先從網上下載jdk(jdk-1_5_0_02-linux-i586.rpm) ,推薦SUN的官方網站www.sun.com,下載后放在/home目錄中,當然其它地方也行。
進入安裝目錄
#cd /home
#cp jdk-1_5_0_02-linux-i586.rpm /usr/local
#cd /usr/local
給所有用戶添加可執行的權限
#chmod +x jdk-1_5_0_02-linux-i586.rpm.bin
#./jdk-1_5_0_02-linux-i586.rpm.bin
此時會生成文件jdk-1_5_0_02-linux-i586.rpm,同樣給所有用戶添加可執行的權限
#chmod +x jdk-1_5_0_02-linux-i586.rpm
安裝程序
#rpm -ivh jdk-1_5_0_02-linux-i586.rpm
出現安裝協議等,按接受即可。
2.設置環境變量。
#vi /etc/profile
在最后面加入
#set java environment
JAVA_HOME=/usr/java/jdk-1_5_0_02
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
保存退出。
要使JDK在所有的用戶中使用,可以這樣:
vi /etc/profile.d/java.sh
在新的java.sh中輸入以下內容:
#set java environment
JAVA_HOME=/usr/java/jdk-1_5_0_02
CLASSPATH=.:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
保存退出,然后給java.sh分配權限:chmod 755 /etc/profile.d/java.sh
3.在終端使用echo命令檢查環境變量設置情況。
#echo $JAVA_HOME
#echo $CLASSPATH
#echo $PATH
4.檢查JDK是否安裝成功。
#java -version
如果看到JVM版本及相關信息,即安裝成功!
posted @
2009-01-21 21:33 Stephen 閱讀(600) |
評論 (0) |
編輯 收藏命令
語法:
tar [主選項+輔選項] 文件或者目錄
使用該命令時,主選項是必須要有的,它告訴
tar要做什么事情,輔選項是輔助使用的,可以選用。
主選項:
c 創建新的檔案文件。如果用戶想備份一個目錄或是一些文件,就要選擇這個選項。
r 把要存檔的文件追加到檔案文件的未尾。例如用戶已經作好備份文件,又發現還有一個目錄或是一些文件忘記備份了,這時可以使用該選項,將忘記的目錄或文件追加到備份文件中。
t 列出檔案文件的內容,查看已經備份了哪些文件。
u 更新文件。就是說,用新增的文件取代原備份文件,如果在備份文件中找不到要更新的文件,則把它追加到備份文件的最后。
x 從檔案文件中釋放文件。
輔助選項:
b 該選項是為磁帶機設定的。其后跟一數字,用來說明區塊的大小,系統預設值為20(20*512 bytes)。
f 使用檔案文件或設備,這個選項通常是必選的。
k 保存已經存在的文件。例如我們把某個文件還原,在還原的過程中,遇到相同的文件,不會進行覆蓋。
m 在還原文件時,把所有文件的修改時間設定為現在。
M 創建多卷的檔案文件,以便在幾個磁盤中存放。
v 詳細報告
tar處理的文件信息。如無此選項,
tar不報告文件信息。
w 每一步都要求確認。
z 用gzip來壓縮/解壓縮文件,加上該選項后可以將檔案文件進行壓縮,但還原時也一定要使用該選項進行解壓縮。
Linux下的壓縮文件剖析
對于剛剛接觸Linux的人來說,一定會給Linux下一大堆各式各樣的文件名給搞暈。別個不說,單單就壓縮文件為例,我們知道在Windows下最常見的壓縮文件就只有兩種,一是,zip,另一個是.rap。可是Linux就不同了,它有.gz、.
tar.gz、tgz、bz2、.Z、.
tar等眾多的壓縮文件名,此外windows下的.zip和.rar也可以在Linux下使用,不過在Linux使用.zip和.rar的人就太少了。本文就來對這些常見的壓縮文件進行一番小結,希望你下次遇到這些文件時不至于被搞暈:)
在具體總結各類壓縮文件之前呢,首先要
弄清兩個概念:打包和壓縮。打包是指將一大堆文件或目錄什么的變成一個總的文件,壓縮則是將一個大的文件通過一些壓縮算法變成一個小文件。為什么要區分這
兩個概念呢?其實這源于Linux中的很多壓縮程序只能針對一個文件進行壓縮,這樣當你想要壓縮一大堆文件時,你就得先借助另它的工具將這一大堆文件先打
成一個包,然后再就原來的壓縮程序進行壓縮。
Linux下最常用的打包程序就是
tar了,使用
tar程序打出來的包我們常稱為
tar包,
tar包文件的命令通常都是以.
tar結尾的。生成
tar包后,就可以用其它的程序來進行壓縮了,所以首先就來講講
tar命令的基本用法:
tar命令的選項有很多(用man
tar可以查看到),但常用的就那么幾個選項,下面來舉例說明一下:
#
tar -cf all.
tar *.jpg
這條命令是將所有.jpg的文件打成一個名為all.
tar的包。-c是表示產生新的包,-f指定包的文件名。
#
tar -rf all.
tar *.gif
這條命令是將所有.gif的文件增加到all.
tar的包里面去。-r是表示增加文件的意思。
#
tar -uf all.
tar logo.gif
這條命令是更新原來
tar包all.
tar中logo.gif文件,-u是表示更新文件的意思。
#
tar -tf all.
tar
這條命令是列出all.
tar包中所有文件,-t是列出文件的意思
#
tar -xf all.
tar
這條命令是解出all.
tar包中所有文件,-t是解開的意思
以上就是
tar的最基本的用法。為了方便用戶在打包解包的同時可以壓縮或解壓文件,
tar提供了一種特殊的功能。這就是
tar可以在打包或解包的同時調用其它的壓縮程序,比如調用gzip、bzip2等。
1)
tar調用gzip
gzip是GNU組織開發的一個壓縮程序,.gz結尾的文件就是gzip壓縮的結果。與gzip相對的解壓程序是gunzip。
tar中使用-z這個參數來調用gzip。下面來舉例說明一下:
#
tar -czf all.
tar.gz *.jpg
這條命令是將所有.jpg的文件打成一個
tar包,并且將其用gzip壓縮,生成一個gzip壓縮過的包,包名為all.
tar.gz
#
tar -xzf all.
tar.gz
這條命令是將上面產生的包解開。
2)
tar調用bzip2
bzip2是一個壓縮能力更強的壓縮程序,.bz2結尾的文件就是bzip2壓縮的結果。與bzip2相對的解壓程序是bunzip2。
tar中使用-j這個參數來調用gzip。下面來舉例說明一下:
#
tar -cjf all.
tar.bz2 *.jpg
這條命令是將所有.jpg的文件打成一個
tar包,并且將其用bzip2壓縮,生成一個bzip2壓縮過的包,包名為all.
tar.bz2
#
tar -xjf all.
tar.bz2
這條命令是將上面產生的包解開。
3)
tar調用compress
compress也是一個壓縮程序,但是好象使用compress的人不如gzip和bzip2的人多。.Z結尾的文件就是bzip2壓縮的結果。與compress相對的解壓程序是uncompress。
tar中使用-Z這個參數來調用gzip。下面來舉例說明一下:
#
tar -cZf all.
tar.Z *.jpg
這條命令是將所有.jpg的文件打成一個
tar包,并且將其用compress壓縮,生成一個uncompress壓縮過的包,包名為all.
tar.Z
#
tar -xZf all.
tar.Z
這條命令是將上面產生的包解開
有了上面的知識,你應該可以解開多種壓縮文件了,下面對于
tar系列的壓縮文件作一個小結:
1)對于.
tar結尾的文件
tar -xf all.
tar
2)對于.gz結尾的文件
gzip -d all.gz
gunzip all.gz
3)對于.tgz或.
tar.gz結尾的文件
tar -xzf all.
tar.gz
tar -xzf all.tgz
4)對于.bz2結尾的文件
bzip2 -d all.bz2
bunzip2 all.bz2
5)對于
tar.bz2結尾的文件
tar -xjf all.
tar.bz2
6)對于.Z結尾的文件
uncompress all.Z
7)對于.
tar.Z結尾的文件
tar -xZf all.
tar.z
另外對于Window下的常見壓縮文件.zip和.rar,Linux也有相應的方法來解壓它們:
1)對于.zip
linux下提供了zip和unzip程序,zip是壓縮程序,unzip是解壓程序。它們的參數選項很多,這里只做簡單介紹,依舊舉例說明一下其用法:
# zip all.zip *.jpg
這條命令是將所有.jpg的文件壓縮成一個zip包
# unzip all.zip
這條命令是將all.zip中的所有文件解壓出來
2)對于.rar
要在linux下處理.rar文件,需要安裝RAR for Linux,可以從網上下載,但要記住,RAR for Linux
不是免費的;然后安裝:
#
tar -xzpvf rarlinux-3.2.0.
tar.gz
# cd rar
# make
這樣就安裝好了,安裝后就有了rar和unrar這兩個程序,rar是壓縮程序,unrar是解壓程序。它們的參數選項很多,這里只做簡單介紹,依舊舉例說明一下其用法:
# rar a all *.jpg
這條命令是將所有.jpg的文件壓縮成一個rar包,名為all.rar,該程序會將.rar 擴展名將自動附加到包名后。
# unrar e all.rar
這條命令是將all.rar中的所有文件解壓出來
到此為至,我們已經介紹過linux下的
tar、gzip、gunzip、bzip2、bunzip2、compress、uncompress、zip、unzip、rar、unrar等程式,你應該已經能夠使用它們對.
tar、.gz、.
tar.gz、.tgz、.bz2、.
tar.bz2、.Z、.
tar.Z、.zip、.rar這10種壓縮文件進行解壓了,以后應該不需要為下載了一個軟件而不知道如何在Linux下解開而煩惱了。而且以上方法對于Unix也基本有效。
本文介紹了linux下的壓縮程式
tar、gzip、gunzip、bzip2、bunzip2、compress、uncompress、zip、unzip、rar、unrar等程式,以及如何使用它們對.
tar、.gz、.
tar.gz、.tgz、.bz2、.
tar.bz2、.Z、.
tar.Z、.zip、.rar這10種壓縮文件進行操作。
posted @
2009-01-21 20:17 Stephen 閱讀(290) |
評論 (0) |
編輯 收藏
偶用金山毒霸的殺毒套裝,今天無意中發現金山網鏢中有一個訪問網絡的請求是C:\System32\Safeabc.exe請求的,這個文件根本不是我安裝的,又不認識,豪不猶豫的禁止了,上網一查,果然是病毒,而且現在并沒有殺毒工具可以查殺這個病毒,而且任務管理器也無法使用了,無論是按ctrl+shift+del還是還是在任務欄點右鍵,還是運行“taskmgr”都沒有辦法掉出任務管理器,麻煩來了。
上網查相關資料,這個病毒好像還會自動下載木馬病毒,很危險的說,好在金山毒霸還能用,查了一下,內存里有三個木馬,先殺掉。
金山毒霸安全百寶箱里有一個進程管理器,居然還能調用,運行發現果然有一個safeabc.exe的進程,先結束掉這個進程,然后去刪除這個文件,系統提示禁止刪除,找到金山毒霸的文件粉碎器,強行刪除,然后將啟動項里面可疑的啟動項刪掉,好像是叫loveHebeAA的,然后查毒殺毒,
重啟,病毒是沒有了,但是任務管理器還是不能用,郁悶了,上網找了好多資料,試了都不行,后來病急亂投醫,在金山的修復工具里檢測一下,居然發現好多的劫持,如圖:
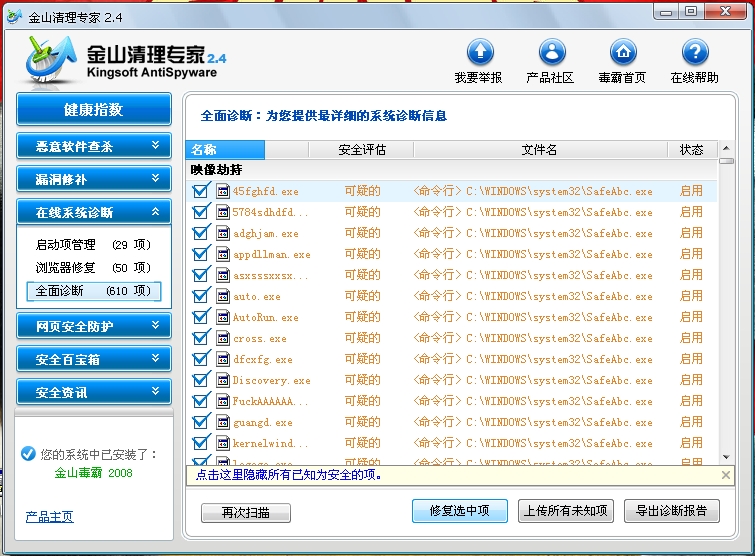
TNND,修復之,任務管理器就可以用了,
阿門,應該是解決了,不知道這病毒還有沒有其他的影響。。。
P.S. 此文不是給金山打廣告,別的工具應該也可以做到的,比如進程管理器,文件粉碎器,劫持修復等等,很多工具都可以做到,只是本人手頭上恰好有金山而已,:P
posted @
2008-06-24 22:10 Stephen 閱讀(478) |
評論 (0) |
編輯 收藏
使用Windows操作系統的朋友對Excel(電子表格)一定不會陌生,但是要使用Java語言來操縱Excel文件并不是一件容易的事。在Web應用日益盛行的今天,通過Web來操作Excel文件的需求越來越強烈,目前較為流行的操作是在JSP或Servlet 中創建一個CSV (comma separated values)文件,并將這個文件以MIME,text/csv類型返回給瀏覽器,接著瀏覽器調用Excel并且顯示CSV文件。這樣只是說可以訪問到Excel文件,但是還不能真正的操縱Excel文件,本文將給大家一個驚喜,向大家介紹一個開放源碼項目??Java Excel API,使用它大家就可以方便地操縱Excel文件了。
JAVA EXCEL API簡介
Java Excel是一開放源碼項目,通過它Java開發人員可以讀取Excel文件的內容、創建新的Excel文件、更新已經存在的Excel文件。使用該API非Windows操作系統也可以通過純Java應用來處理Excel數據表。因為是使用Java編寫的,所以我們在Web應用中可以通過JSP、Servlet來調用API實現對Excel數據表的訪問。 現在發布的穩定版本是V2.0,提供以下功能:
? 從Excel 95、97、2000等格式的文件中讀取數據;
? 讀取Excel公式(可以讀取Excel 97以后的公式);
? 生成Excel數據表(格式為Excel 97);
? 支持字體、數字、日期的格式化;
? 支持單元格的陰影操作,以及顏色操作;
? 修改已經存在的數據表;
? 現在還不支持以下功能,但不久就會提供了:
? 不能夠讀取圖表信息;
可以讀,但是不能生成公式,任何類型公式最后的計算值都可以讀出;
應用示例
從Excel文件讀取數據表
Java Excel API既可以從本地文件系統的一個文件(.xls),也可以從輸入流中讀取Excel數據表。讀取Excel數據表的第一步是創建Workbook(術語:工作薄),下面的代碼片段舉例說明了應該如何操作:(完整代碼見ExcelReading.java)
import java.io.*;
import jxl.*;
… … … …
try
{
//構建Workbook對象, 只讀Workbook對象
//直接從本地文件創建Workbook
//從輸入流創建Workbook
InputStream is = new FileInputStream(sourcefile);
jxl.Workbook rwb = Workbook.getWorkbook(is);
}
catch (Exception e)
{
e.printStackTrace();
}
一旦創建了Workbook,我們就可以通過它來訪問Excel Sheet(術語:工作表)。參考下面的代碼片段:
//獲取第一張Sheet表
Sheet rs = rwb.getSheet(0);
我們既可能通過Sheet的名稱來訪問它,也可以通過下標來訪問它。如果通過下標來訪問的話,要注意的一點是下標從0開始,就像數組一樣。
一旦得到了Sheet,我們就可以通過它來訪問Excel Cell(術語:單元格)。參考下面的代碼片段:
//獲取第一行,第一列的值
Cell c00 = rs.getCell(0, 0);
String strc00 = c00.getContents();
//獲取第一行,第二列的值
Cell c10 = rs.getCell(1, 0);
String strc10 = c10.getContents();
//獲取第二行,第二列的值
Cell c11 = rs.getCell(1, 1);
String strc11 = c11.getContents();
System.out.println("Cell(0, 0)" + " value : " + strc00 + "; type : " +
c00.getType());
System.out.println("Cell(1, 0)" + " value : " + strc10 + "; type : " +
c10.getType());
System.out.println("Cell(1, 1)" + " value : " + strc11 + "; type : " +
c11.getType());
如果僅僅是取得Cell的值,我們可以方便地通過getContents()方法,它可以將任何類型的Cell值都作為一個字符串返回。示例代碼中Cell(0, 0)是文本型,Cell(1, 0)是數字型,Cell(1,1)是日期型,通過getContents(),三種類型的返回值都是字符型。
如果有需要知道Cell內容的確切類型,API也提供了一系列的方法。參考下面的代碼片段:
String strc00 = null;
double strc10 = 0.00;
Date strc11 = null;
Cell c00 = rs.getCell(0, 0);
Cell c10 = rs.getCell(1, 0);
Cell c11 = rs.getCell(1, 1);
if(c00.getType() == CellType.LABEL)
{
LabelCell labelc00 = (LabelCell)c00;
strc00 = labelc00.getString();
}
if(c10.getType() == CellType.NUMBER)
{
NmberCell numc10 = (NumberCell)c10;
strc10 = numc10.getValue();
}
if(c11.getType() == CellType.DATE)
{
DateCell datec11 = (DateCell)c11;
strc11 = datec11.getDate();
}
System.out.println("Cell(0, 0)" + " value : " + strc00 + "; type : " +
c00.getType());
System.out.println("Cell(1, 0)" + " value : " + strc10 + "; type : " +
c10.getType());
System.out.println("Cell(1, 1)" + " value : " + strc11 + "; type : " +
c11.getType());
在得到Cell對象后,通過getType()方法可以獲得該單元格的類型,然后與API提供的基本類型相匹配,強制轉換成相應的類型,最后調用相應的取值方法getXXX(),就可以得到確定類型的值。API提供了以下基本類型,與Excel的數據格式相對應。
每種類型的具體意義,請參見Java Excel API Document。
當你完成對Excel電子表格數據的處理后,一定要使用close()方法來關閉先前創建的對象,以釋放讀取數據表的過程中所占用的內存空間,在讀取大量數據時顯得尤為重要。參考如下代碼片段:
//操作完成時,關閉對象,釋放占用的內存空間
rwb.close();
Java Excel API提供了許多訪問Excel數據表的方法,在這里我只簡要地介紹幾個常用的方法,其它的方法請參考附錄中的Java Excel API Document。
? Workbook類提供的方法
1. int getNumberOfSheets()
獲得工作薄(Workbook)中工作表(Sheet)的個數,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
int sheets = rwb.getNumberOfSheets();
2. Sheet[] getSheets()
返回工作薄(Workbook)中工作表(Sheet)對象數組,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
Sheet[] sheets = rwb.getSheets();
3. String getVersion()
返回正在使用的API的版本號,好像是沒什么太大的作用。
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
String apiVersion = rwb.getVersion();
? Sheet接口提供的方法
1. String getName()
獲取Sheet的名稱,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
String sheetName = rs.getName();
2. int getColumns()
獲取Sheet表中所包含的總列數,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
int rsColumns = rs.getColumns();
3. Cell[] getColumn(int column)
獲取某一列的所有單元格,返回的是單元格對象數組,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
Cell[] cell = rs.getColumn(0);
4. int getRows()
獲取Sheet表中所包含的總行數,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
int rsRows = rs.getRows();
5. Cell[] getRow(int row)
獲取某一行的所有單元格,返回的是單元格對象數組,示例子:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
Cell[] cell = rs.getRow(0);
6. Cell getCell(int column, int row)
獲取指定單元格的對象引用,需要注意的是它的兩個參數,第一個是列數,第二個是行數,這與通常的行、列組合有些不同。
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
Cell cell = rs.getCell(0, 0);
生成新的Excel工作薄
下面的代碼主要是向大家介紹如何生成簡單的Excel工作表,在這里單元格的內容是不帶任何修飾的(如:字體,顏色等等),所有的內容都作為字符串寫入。(完整代碼見ExcelWriting.java)
與讀取Excel工作表相似,首先要使用Workbook類的工廠方法創建一個可寫入的工作薄(Workbook)對象,這里要注意的是,只能通過API提供的工廠方法來創建Workbook,而不能使用WritableWorkbook的構造函數,因為類WritableWorkbook的構造函數為protected類型。示例代碼片段如下:
import java.io.*;
import jxl.*;
import jxl.write.*;
… … … …
try
{
//構建Workbook對象, 只讀Workbook對象
//Method 1:創建可寫入的Excel工作薄
jxl.write.WritableWorkbook wwb = Workbook.createWorkbook(new File(targetfile));
//Method 2:將WritableWorkbook直接寫入到輸出流
/*
OutputStream os = new FileOutputStream(targetfile);
jxl.write.WritableWorkbook wwb = Workbook.createWorkbook(os);
*/
}
catch (Exception e)
{
e.printStackTrace();
}
API提供了兩種方式來處理可寫入的輸出流,一種是直接生成本地文件,如果文件名不帶全路徑的話,缺省的文件會定位在當前目錄,如果文件名帶有全路徑的話,則生成的Excel文件則會定位在相應的目錄;另外一種是將Excel對象直接寫入到輸出流,例如:用戶通過瀏覽器來訪問Web服務器,如果HTTP頭設置正確的話,瀏覽器自動調用客戶端的Excel應用程序,來顯示動態生成的Excel電子表格。
接下來就是要創建工作表,創建工作表的方法與創建工作薄的方法幾乎一樣,同樣是通過工廠模式方法獲得相應的對象,該方法需要兩個參數,一個是工作表的名稱,另一個是工作表在工作薄中的位置,參考下面的代碼片段:
file://創建Excel工作表
jxl.write.WritableSheet ws = wwb.createSheet("Test Sheet 1", 0);
"這鍋也支好了,材料也準備齊全了,可以開始下鍋了!",現在要做的只是實例化API所提供的Excel基本數據類型,并將它們添加到工作表中就可以了,參考下面的代碼片段:
file://1.添加Label對象
jxl.write.Label labelC = new jxl.write.Label(0, 0, "This is a Label cell");
ws.addCell(labelC);
//添加帶有字型Formatting的對象
jxl.write.WritableFont wf = new jxl.write.WritableFont(WritableFont.TIMES, 18,
WritableFont.BOLD, true);
jxl.write.WritableCellFormat wcfF = new jxl.write.WritableCellFormat(wf);
jxl.write.Label labelCF = new jxl.write.Label(1, 0, "This is a Label Cell", wcfF);
ws.addCell(labelCF);
//添加帶有字體顏色Formatting的對象
jxl.write.WritableFont wfc = new jxl.write.WritableFont(WritableFont.ARIAL, 10,
WritableFont.NO_BOLD, false,
UnderlineStyle.NO_UNDERLINE, jxl.format.Colour.RED);
jxl.write.WritableCellFormat wcfFC = new jxl.write.WritableCellFormat(wfc);
jxl.write.Label labelCFC = new jxl.write.Label(1, 0, "This is a Label Cell", wcfFC);
ws.addCell(labelCF);
//2.添加Number對象
jxl.write.Number labelN = new jxl.write.Number(0, 1, 3.1415926);
ws.addCell(labelN);
//添加帶有formatting的Number對象
jxl.write.NumberFormat nf = new jxl.write.NumberFormat("#.##");
jxl.write.WritableCellFormat wcfN = new jxl.write.WritableCellFormat(nf);
jxl.write.Number labelNF = new jxl.write.Number(1, 1, 3.1415926, wcfN);
ws.addCell(labelNF);
//3.添加Boolean對象
jxl.write.Boolean labelB = new jxl.write.Boolean(0, 2, false);
ws.addCell(labelB);
//4.添加DateTime對象
jxl.write.DateTime labelDT = new jxl.write.DateTime(0, 3, new java.util.Date());
ws.addCell(labelDT);
//添加帶有formatting的DateFormat對象
jxl.write.DateFormat df = new jxl.write.DateFormat("dd MM yyyy hh:mm:ss");
jxl.write.WritableCellFormat wcfDF = new jxl.write.WritableCellFormat(df);
jxl.write.DateTime labelDTF = new jxl.write.DateTime(1, 3, new java.util.Date(), wcfDF);
ws.addCell(labelDTF);
這里有兩點大家要引起大家的注意。第一點,在構造單元格時,單元格在工作表中的位置就已經確定了。一旦創建后,單元格的位置是不能夠變更的,盡管單元格的內容是可以改變的。第二點,單元格的定位是按照下面這樣的規律(column, row),而且下標都是從0開始,例如,A1被存儲在(0, 0),B1被存儲在(1, 0)。
最后,不要忘記關閉打開的Excel工作薄對象,以釋放占用的內存,參見下面的代碼片段:
file://寫入Exel工作表
wwb.write();
//關閉Excel工作薄對象
wwb.close();
這可能與讀取Excel文件的操作有少少不同,在關閉Excel對象之前,你必須要先調用write()方法,因為先前的操作都是存儲在緩存中的,所以要通過該方法將操作的內容保存在文件中。如果你先關閉了Excel對象,那么只能得到一張空的工作薄了。
拷貝、更新Excel工作薄
接下來簡要介紹一下如何更新一個已經存在的工作薄,主要是下面二步操作,第一步是構造只讀的Excel工作薄,第二步是利用已經創建的Excel工作薄創建新的可寫入的Excel工作薄,參考下面的代碼片段:(完整代碼見ExcelModifying.java)
file://創建只讀的Excel工作薄的對象
jxl.Workbook rw = jxl.Workbook.getWorkbook(new File(sourcefile));
//創建可寫入的Excel工作薄對象
jxl.write.WritableWorkbook wwb = Workbook.createWorkbook(new File(targetfile), rw);
//讀取第一張工作表
jxl.write.WritableSheet ws = wwb.getSheet(0);
//獲得第一個單元格對象
jxl.write.WritableCell wc = ws.getWritableCell(0, 0);
//判斷單元格的類型, 做出相應的轉化
if(wc.getType() == CellType.LABEL)
{
Label l = (Label)wc;
l.setString("The value has been modified.");
}
//寫入Excel對象
wwb.write();
//關閉可寫入的Excel對象
wwb.close();
//關閉只讀的Excel對象
rw.close();
之所以使用這種方式構建Excel對象,完全是因為效率的原因,因為上面的示例才是API的主要應用。為了提高性能,在讀取工作表時,與數據相關的一些輸出信息,所有的格式信息,如:字體、顏色等等,是不被處理的,因為我們的目的是獲得行數據的值,既使沒有了修飾,也不會對行數據的值產生什么影響。唯一的不利之處就是,在內存中會同時保存兩個同樣的工作表,這樣當工作表體積比較大時,會占用相當大的內存,但現在好像內存的大小并不是什么關鍵因素了。
一旦獲得了可寫入的工作表對象,我們就可以對單元格對象進行更新的操作了,在這里我們不必調用API提供的add()方法,因為單元格已經于工作表當中,所以我們只需要調用相應的setXXX()方法,就可以完成更新的操作了。
盡單元格原有的格式化修飾是不能去掉的,我們還是可以將新的單元格修飾加上去,以使單元格的內容以不同的形式表現。
新生成的工作表對象是可寫入的,我們除了更新原有的單元格外,還可以添加新的單元格到工作表中,這與示例2的操作是完全一樣的。
最后,不要忘記調用write()方法,將更新的內容寫入到文件中,然后關閉工作薄對象,這里有兩個工作薄對象要關閉,一個是只讀的,另外一個是可寫入的。
下面是在一個Excel表格中創建一個矩陣的簡單例子:
import org.apache.poi.hssf.usermodel.*;
import java.io.FileOutputStream;
// code run against the jakarta-poi-1.5.0-FINAL-20020506.jar.
public class PoiTest {
static public void main(String[] args) throws Exception {
FileOutputStream fos = new FileOutputStream("foo.xls");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet s = wb.createSheet();
wb.setSheetName(0, "Matrix");
for(short i=0; i<50; i++) {
HSSFRow row = s.createRow(i);
for(short j=0; j<50; j++) {
HSSFCell cell = row.createCell(j);
cell.setCellValue(""+i+","+j);
}
}
wb.write(fos);
fos.close();
}
}
這段代碼首先創建一個Workbook,從該Workbook中得到一個表格、命名,然后繼續寫入一個50x50的矩陣。最后輸出到一個名為foo.xls的Excel文件,甚至在Apple Mac機上也可以打開。
POI項目是Java應用的令人興奮的一步,為用戶提供了Windows文檔集成的新功能,允許Java開發人員方便地擴展其產品的功能。
posted @
2008-05-17 13:18 Stephen 閱讀(418) |
評論 (1) |
編輯 收藏DBCC DBREINDEX重建索引提高SQL Server性能
大多數SQL Server表需要索引來提高數據的訪問速度,如果沒有索引,SQL Server 要進行表格掃描讀取表中的每一個記錄才能找到索要的數據。索引可以分為簇索引和非簇索引,簇索引通過重排表中的數據來提高數據的訪問速度,而非簇索引則通過維護表中的數據指針來提高數據的索引。
1. 索引的體系結構
為什么要不斷的維護表的索引?首先,簡單介紹一下索引的體系結構。SQL Server在硬盤中用8KB頁面在數據庫文件內存放數據。缺省情況下這些頁面及其包含的數據是無組織的。為了使混亂變為有序,就要生成索引。生成索引后,就有了索引頁和數據頁,數據頁保存用戶寫入的數據信息。索引頁存放用于檢索列的數據值清單(關鍵字)和索引表中該值所在紀錄的地址指針。索引分為簇索引和非簇索引,簇索引實質上是將表中的數據排序,就好像是字典的索引目錄。非簇索引不對數據排序,它只保存了數據的指針地址。向一個帶簇索引的表中插入數據,當數據頁達到100%時,由于頁面沒有空間插入新的的紀錄,這時就會發生分頁,SQL Server 將大約一半的數據從滿頁中移到空頁中,從而生成兩個半的滿頁。這樣就有大量的數據空間。簇索引是雙向鏈表,在每一頁的頭部保存了前一頁、后一頁地址以及分頁后數據移動的地址,由于新頁可能在數據庫文件中的任何地方,因此頁面的鏈接不一定指向磁盤的下一個物理頁,鏈接可能指向了另一個區域,這就形成了分塊,從而減慢了系統的速度。對于帶簇索引和非簇索引的表來說,非簇索引的關鍵字是指向簇索引的,而不是指向數據頁的本身。
為了克服數據分塊帶來的負面影響,需要重構表的索引,這是非常費時的,因此只能在需要時進行。可以通過DBCC SHOWCONTIG來確定是否需要重構表的索引。
2. DBCC SHOWCONTIG用法
下面舉例來說明DBCC SHOWCONTIG和DBCC REDBINDEX的使用方法。以應用程序中的Employee數據表作為例子,在 SQL Server的Query analyzer輸入命令:
use database_name
declare @table_id int
set @table_id=object_id('Employee')
dbcc showcontig(@table_id)
輸出結果:
DBCC SHOWCONTIG scanning 'Employee' table...
Table: 'Employee' (1195151303); index ID: 1, database ID: 53
TABLE level scan performed.
- Pages Scanned................................: 179
- Extents Scanned..............................: 24
- Extent Switches..............................: 24
- Avg. Pages per Extent........................: 7.5
- Scan Density [Best Count:Actual Count].......: 92.00% [23:25]
- Logical Scan Fragmentation ..................: 0.56%
- Extent Scan Fragmentation ...................: 12.50%
- Avg. Bytes Free per Page.....................: 552.3
- Avg. Page Density (full).....................: 93.18%
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
通過分析這些結果可以知道該表的索引是否需要重構。如下描述了每一行的意義:
信息 描述
Pages Scanned 表或索引中的長頁數
Extents Scanned 表或索引中的長區頁數
Extent Switches DBCC遍歷頁時從一個區域到另一個區域的次數
Avg. Pages per Extent 相關區域中的頁數
Scan Density[Best Count:Actual Count]
Best Count是連續鏈接時的理想區域改變數,Actual Count是實際區域改變數,Scan Density為100%表示沒有分塊。
Logical Scan Fragmentation 掃描索引頁中失序頁的百分比
Extent Scan Fragmentation 不實際相鄰和包含鏈路中所有鏈接頁的區域數
Avg. Bytes Free per Page 掃描頁面中平均自由字節數
Avg. Page Density (full) 平均頁密度,表示頁有多滿
從上面命令的執行結果可以看的出來,Best count為23 而Actual Count為25這表明orders表有分塊需要重構表索引。下面通過DBCC DBREINDEX來重構表的簇索引。
3. DBCC DBREINDEX 用法
重建指定數據庫中表的一個或多個索引。
語法
DBCC DBREINDEX
( [ 'database.owner.table_name'
[ , index_name
[ , fillfactor ]
]
]
)
參數
'database.owner.table_name'
是要重建其指定的索引的表名。數據庫、所有者和表名必須符合標識符的規則。有關更多信息,請參見使用標識符。如果提供 database 或 owner 部分,則必須使用單引號 (') 將整個 database.owner.table_name 括起來。如果只指定 table_name,則不需要單引號。
index_name
是要重建的索引名。索引名必須符合標識符的規則。如果未指定 index_name 或指定為 ' ',就要對表的所有索引進行重建。
fillfactor
是創建索引時每個索引頁上要用于存儲數據的空間百分比。fillfactor 替換起始填充因子以作為索引或任何其它重建的非聚集索引(因為已重建聚集索引)的新默認值。如果 fillfactor 為 0,DBCC DBREINDEX 在創建索引時將使用指定的起始 fillfactor。
同樣在Query Analyzer中輸入命令:
dbcc dbreindex('database_name.dbo.Employee','',90)
然后再用DBCC SHOWCONTIG查看重構索引后的結果:
DBCC SHOWCONTIG scanning 'Employee' table...
Table: 'Employee' (1195151303); index ID: 1, database ID: 53
TABLE level scan performed.
- Pages Scanned................................: 178
- Extents Scanned..............................: 23
- Extent Switches..............................: 22
- Avg. Pages per Extent........................: 7.7
- Scan Density [Best Count:Actual Count].......: 100.00% [23:23]
- Logical Scan Fragmentation ..................: 0.00%
- Extent Scan Fragmentation ...................: 0.00%
- Avg. Bytes Free per Page.....................: 509.5
- Avg. Page Density (full).....................: 93.70%
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
通過結果我們可以看到Scan Denity為100%。
******
原文鏈接:《如何提高SQL SERVER的性能》
http://www.csdn.com.cn/database/1142.htm
作者:unknown
posted @
2008-05-17 11:47 Stephen 閱讀(335) |
評論 (0) |
編輯 收藏4月30日,因某些原因需要在上班時間重啟下應用,
結果重啟后就報錯無法使用,從下午4點多一直到下班系統都無法使用,
由于系統報的錯誤始終是spring的applicationContext加載失敗,一直在找配置文件的原因,
其中嘗試還原備份,切換應用等等好多操作,都沒有辦法,
開始反饋系統出錯的電話很多,頭腦一直是亂的,等到下班以后才靜下心來找原因,
后來發現本地測試的應用也無法啟動,
最后發現是hibernata的tld文件的下載地址失效了,原來的那個地址在網絡上突然已經無法訪問,
通過其他方式找到TLD文件,打到hibernate 包里面,問題解決.
此事的教訓:
1,TLD文件一定要改為從本地取,不能用默認的從網絡讀取的;
2,遇事要冷靜,不要著急,慌亂,每次都這么說,但每次都著急,需要改進.
posted @
2008-05-17 11:36 Stephen 閱讀(407) |
評論 (0) |
編輯 收藏
顯示器: AOC 193FW (19'液晶) 1480元
CPU: AMD AM2 Athlon 64 X2 5000+(90nm) 800元
主板: 微星 K9N Neo-F 699元
顯卡: 雙敏 無極HD3690玩家版 890元
內存: 金士頓 DDRII800 1G 250元
硬盤: 希捷 酷魚7200.9/ST3250824AS 250G 465元
機箱+電源: 金河田 300元左右(可選金河田、愛國者,機箱溫度低為好)
鼠標+鍵盤: 150左右(不用買好的,經常會換)
光驅: DVD光驅 170(先鋒、三星、索尼都行)
網卡聲卡板載
-------------------------------------------------------------------------------
合計:5204
我的機器又落后了。。555555555
posted @
2008-03-23 23:02 Stephen 閱讀(203) |
評論 (0) |
編輯 收藏posted @
2007-06-25 21:22 Stephen 閱讀(237) |
評論 (0) |
編輯 收藏
8月了,大半年過去了,
回想今年,3-6月收獲還可以,
7,8兩個月進步較慢,都是混日子;
這樣下去不行啊。。。。。。
今年剩下的日子:
1、重心不能偏移:學技術是重中之重;不和無聊的人勾心斗角;
2、堅持學English:每天學,時間總是有的;
3、自己寫出一款軟件
posted @
2006-08-15 22:30 Stephen 閱讀(368) |
評論 (1) |
編輯 收藏