摘要:本文主要介紹使用kettle 來建立一個Type 2的Slowly Changing Dimension 以及其中一些細節問題
1. Kettle 簡介
Kettle 是一個強大的,元數據驅動的ETL工具被設計用來填補商業和IT之前的差距,將你公司的數據變成可增長的利潤.
我們先來看看Kettle能做什么:
1. Data warehouse population with built-in support for slowly changing dimensions, junk dimensions and much, much more.
2. Export of database(s) to text-file(s) or other databases
3. Import of data into databases, ranging from text-files to excel sheets
4. Data migration between database applications
5. Exploration of data in existing databases. (tables, views, synonyms, )
6. Information enrichment by looking up data in various information stores (databases, text-files, excel sheets, )
7. Data cleaning by applying complex conditions in data transformations
8. Application integration
本系列文章主要介紹如下幾點:
1. 數據倉庫內建支持緩慢增長維SCD ,
2. 在數據轉換中使用復雜條件判斷來清理數據
3. 如何使用kettle 來處理增量更形
4. 將Kettle 集成到你的應用程序里
5. 使用kettle中應該注意的一些地方
2. Kettle 文檔
最好的kettle教程就在你身邊,我們下載的kettle-version. zip 文件里其實已經包括了非常多的示例和文檔,在你的kettle文件夾下,docs 文件夾下包含了所有的文檔,samples文件夾下包含了一些示例,后面的介紹中一部分示例都來自kettle自帶的這個示例文件夾下。docs里面最主要的是Spoon-version-User-Guide. zip ,里面記錄了kettle 的技術性文檔,包括支持的操作系統,數據庫平臺,文本格式,圖形化的界面,其中最重要的是所有的轉換對象(Transformation Core Objects) 和Job對象(Job Core Objects) 的解釋,包括截圖和每一個參數的解釋。
3. Kettle與Slowly Changing Dimension
我們使用kettle自帶的samples文件下的示例,來看kettle如何支持SCD的。
打開samples / jobs / Slowly Changing Dimension 文件夾,發現里面有三個文件,
create - populate - update slowly changing dimension.kjb
DimensionLookup - update dimension table 2.ktr
DimensionLookup - update dimension table.ktr
其中后綴以 .kjb 結尾的是kettle 的job 文件導出的格式,而以ktr 結尾的是kettle 的transformation 導出的格式,打開其中的DimensionLookup - update dimension table.ktr , 出現如下所示 :
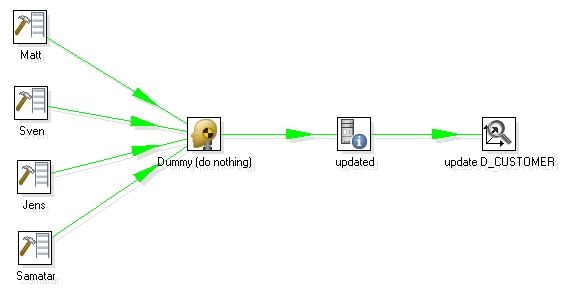
圖1
1. 最左邊的是產生測試數據,如果是實際環境的話應該是連接真實的數據庫,產生的真實數據格式打開如下:
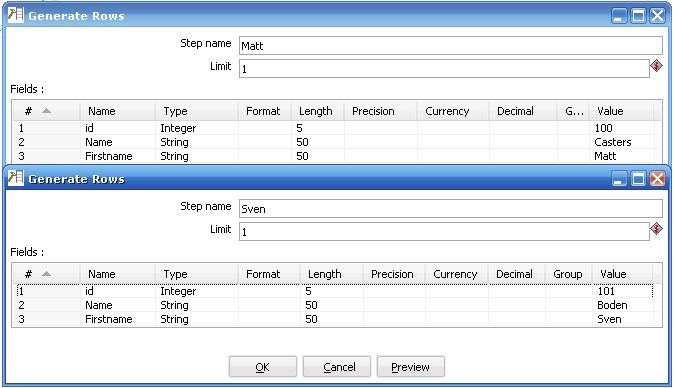
圖2
2 第二個步驟Dummy 就是把前面的數據合并起來,Dummy 步驟本身不做任何事情,不過由于前面有四個輸入指向它,所以它在第二步的作用等同于數據合并。
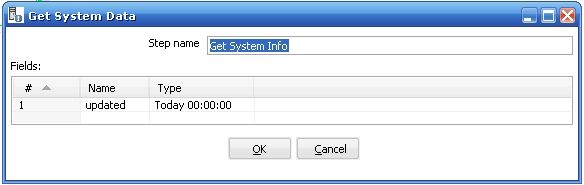
3 第三個步驟是取得系統參數(get system date) , 它取得當前系統時間的日期,并且格式是當天的 00:00:00 , 如圖所示
4. 最后一步是真正的重點,執行Dimension Lookup / Update 步驟來更新和插入數據,以此來實現Type 1 ,2 ,3 的不同Slowly Changing Dimension
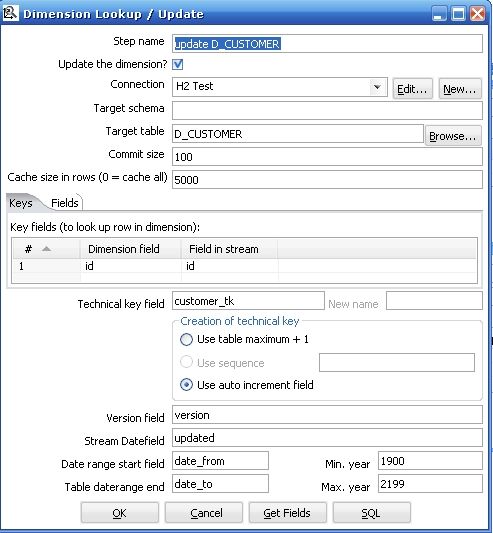
圖4
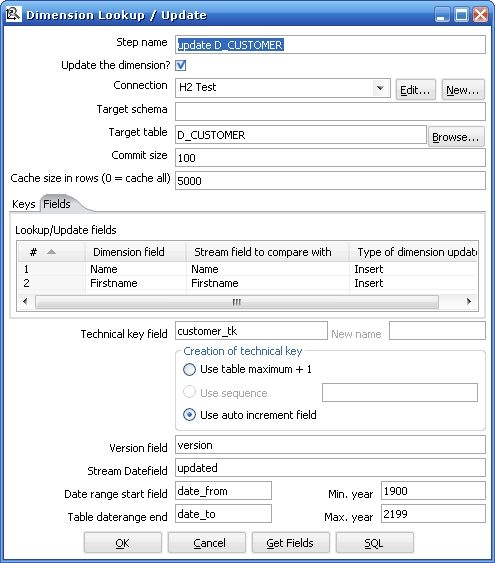
圖5
在開始介紹Dimension Lookup / Update 之前,先看看在執行這個步驟之前的輸入和輸入:
輸入:
|
字段名
|
數據類型
|
說明
|
|
id
|
int
|
前面步驟的輸入
|
|
name
|
Varchar(50)
|
前面步驟的輸入
|
|
firstname
|
Varchar(50)
|
前面步驟的輸入
|
|
updated
|
time
|
從第三步來的時間參數
|
輸出:
|
字段名
|
數據類型
|
說明
|
|
id
|
INT
|
來自輸入
|
|
name
|
varchar(50)
|
來自輸入
|
|
firstname
|
varchar(50)
|
來自輸入
|
|
customer_tk
|
BIGINT
|
代理主鍵
|
|
version
|
INT
|
版本變更號
|
|
Date_from
|
datetime
|
有效期起始日期
|
|
Date_to
|
Datetime
|
有效期失效日期
|
注意: 上圖中所使用的是mysql 5 數據庫做測試,所以數據類型一欄都是mysql 的數據類型,如果你使用其他數據庫,可能數據類型會有所不同,其中的datetime 的格式 yyyy/mon/day hh:mm:ss:sss
我們再來看看當我們第一次運行以后出現的數據輸出:

圖6
注意圖6中所有的 version 值都是 1
Date_from 都是 1900/01/01 00:00:00.000
Date_to 都是 2199/12/31 23:59:59.000 這兩列都是根據圖4下面部分定義的
Id , name , firstname 都是測試數據,從前面步驟來的.
然后我們修改圖1中generate row 的部分數據(一共兩條),并且只有測試數據變了的情況下,我們再次運行轉換,查看數據輸出:

圖7
注意到其中customer_tk 并沒有什么變化,仍然在產生類似序列的輸出
Version 的值中出現了 2 , 并且只有在我們改變的數據中
在出現了改變的行中的date_from 變成了2007/11/28/ 00:00:00.000
在出現了改變的行中原來數據的date_to 變成了 2007-11-28 00:00:00.000
Id 列沒有變化,(變化了也沒用,圖5中的中間部分 Field 選項卡沒有選id)
Name , firstname 有兩個值變了(我們手工改變的)
Dimension Lookup / Update 參數解釋
|
Step name
|
步驟的名稱,在一個轉換中必須是唯一的
|
|
Update the dimension?
|
當找到符合條件記錄的時候更新這條記錄,如果這個復選框沒有選擇,找到了符合條件記錄的時候就是插入新紀錄而不是更新
|
|
Connection
|
數據庫連接的名字
|
|
Target schema
|
|
|
Target table
|
要更新的維表的名稱
|
|
Commit size
|
批處理更新的記錄數
|
|
Cache size in rows
|
這是把維表的數據放在緩存中用來提高數據查找速度從而減少數據庫查詢的次數
注意只有最近一次的記錄會被放在緩存中,如果記錄數超過緩存大小,最有最有關的最近的最高版本號記錄會被放在緩存中
如果把cache size 設置成0 ,kettle會一直把記錄放在緩存中直到JVM沒有內存了,如果你這樣設置要確保維的記錄數不要太大
設置成 1 表示不使用緩存
|
|
Keys tab
|
設置在流中的主鍵和目標維表的業務主鍵,當兩個鍵相等時認為這條記錄匹配
|
|
Fields tab
|
設定要更新的字段,當主鍵記錄匹配的時候,只有設定更新的字段不一樣才認為是這條記錄是不一樣的,需要更新或者插入(注意圖5的中間部分,Fields tab 右邊設定的是Insert ,所以實現的是Type2 的SCD)
|
|
Technical key field
|
維的主鍵,也可以叫做代理主鍵(Surrogate Key)
|
|
Creation of technical key
|
指定技術主鍵的生成方式,對于你數據庫連接不適合的方式會自動被去掉,一共有三種:
1 .Use table maximum + 1 : 使用當前表最大記錄數加一的方式產生新主鍵,注意新的最大值會被緩存,所以不用每次需要產生新記錄的時候就計算
2 . Use sequence : 使用一個數據庫支持的序列來產生技術主鍵(比如Oracle ,你也可以看到圖4中這一條是灰色的因為使用的是mysql 數據庫)
3. Use auto increment field : 使用一個數據庫支持的自動增長來產生技術主鍵(比如DB2)
|
|
Version field
|
使用這個字段來儲存版本號
|
|
Stream Datafield
|
你可以指定維記錄最后一次被更改的時間,它能指定你要更新的維的精度,如果不指定,就會默認是系統時間
|
|
Date range start field
|
維記錄其實有效時間
|
|
Table daterange end
|
維記錄失效時間
|
|
Get Fields button
|
指定所有你想要更新的字段,除了你指定的主鍵
|
|
SQL button
|
產生sql 來創建維表
|
官方文檔中提到的注意事項:
1. Stream date field : 如果你不想每次都改變時間的范圍,你需要添加一個額外的這個字段,比如你打算每天的午夜來進行ETL過程,可以考慮加一個Join 步驟”Yesterday 23:59:59” 作為輸入的時間字段.
2. 這必須是一個Date 字段(不能是轉換后的字符串,即使他們有相同的格式也不行),我們(Kettle 的開發小組)把功能實現隔離出來,如果你需要的話自己要先轉換.
3. 對于Date range start and end fields : 你只能指定一個表示年的數據,而不是時間戳,如果你輸入YYYY(比如2100) ,這將會被當成一個時間戳來用: YYYY-01-01 00:00:00.000 ,(注意圖6中的格式)
另外需要注意的地方:
1. Technical key field : 其他一些ETL工具(比如OWB)也許叫做代理主鍵,只是名字上不同而已.
2. SQL Button : 當你在目標數據庫中還沒有建立維表的時候,你點擊SQL Button ,Kettle 會彈出如下對話框幫你建立維表,你會發現它默認幫你在代理主鍵和業務主鍵上建立索引。
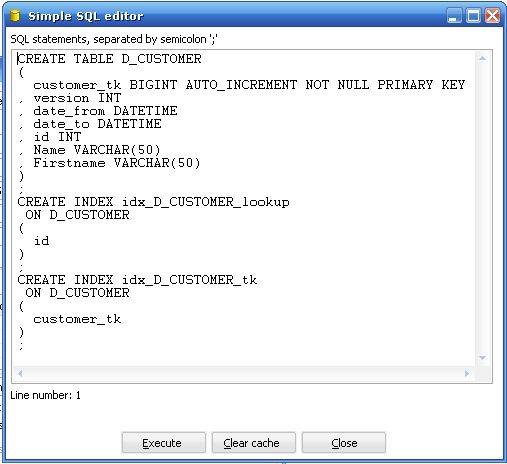
圖8
3 Creation of technical key : 在這個選項的第二種實現方式上,Use sequence ,這個要視你數據庫支持而定,mysql 就不支持,Oracle 支持sequence , 但是你要自己創建和管理這個sequence , 如果這個sequence 的值因某種外部因素改變了,你要自己確定sequence 產生的值處于何種狀態,如果可以的話盡量不要用,盡量用第一種:table maximum + 1 ,這種方式永遠不要擔心數據庫的不同和實現方式的不同,而且簡單易懂。
4 Stream Datefield
4.1 這個選項是用來控制時間的精度的,有的時候我們可能只是一個月進行一次ETL,這個時候Datefield 顯然沒有必要到秒的精度,而且這個選項嚴重影響你后面如果使用緩慢增長維的sql 的復雜度,因為你需要先把時間的精度調到你需要的精度,比如你使用的數據是到秒的精度,但是你實際需要的只是天的精度,你在sql 里面有大量的時間都浪費在toString( stream date field) ,然后把這個字符串substring() ,執行效率會低一些.
4.2 不要輕易改這個精度,一旦你確定了精度問題,不要嘗試改變它,尤其是當精度變細的時候,你可能會損失掉已經存在與數據庫中的數據的精度,如果你只是從 “Today 00:00:00.000” 改成 “Today 23.59.59.000” 的情況,需要手動處理好已經存在的數據格式問題.
4.3 執行ETL的時間可能決定這個值,如果你一天可能存在5次執行ETL過程(包括自動執行或者手工執行)那么你顯然不希望時間的精度是按天來計算的(比如Today 00.00.00這種格式)
4.4 精度的損失并不可怕:考慮一下你的應用場景,比如我們要做表,列出2006年11月份和2006年12月份的所有銷售總和,結合上圖中的customer 的例子,假設是按客戶聚合的, 我們對于customer 的精度要求只要求到月,沒有要求到天,如果我們執行ETL的過程是一個星期執行一次,可能一個客戶在一個星期內改變了三次他的名字(雖然不是個好例子,完全是為了配合上面的圖),而只有最后一次的改變被記錄了下來,這完全跟你執行ETL的頻度有關,但是考慮到用戶需求,只要精度到月就夠了,即使這種精度有數據損失也完全沒關系,所以你如何指定你的Stream date field 的精度主要是看用戶需求的精度。
4.5 如果以上四點你覺得只是一堆讓你頭疼的字符串,那你完全可以把stream date field 設置成空(默認的到時間戳的精度)
執行Type 2 SCD
1. “Update the dimension?” 選中
2. 在Field tabs 里面,對于每一個你想要保持全部記錄的字段都要選擇Insert 方式.
錯誤處理和依賴問題
如果你運行了這個轉換,你會發現你的輸出中有一條customer_tk為1,version為1的數據,你在圖6和圖7中沒有看到這條數據是因為我不想一開始把這條數據跟SCD的實現混在一起,SCD的實現本身并不會告訴你要添加這條數據,這完全是跟數據建模有關系,為了理解這個問題,我們看一下如下情況該如何處理:
一個產品銷售的記錄是作為一個立方體的主要事實表,它包括一個客戶維,現在因為某種原因客戶維需要刪除掉一部分數據,但是對映的產品銷售記錄卻要保存起來,該如何處理外鍵約束的問題?
SCD實現本身并不會考慮這個問題,因為它跟維表沒有什么關系,你要處理的是事實表里面那些引用了維表的記錄,如果你沒有這個空行(它唯一的一個值就是id ,而且是為了滿足主鍵約束,version那個字段有沒有值不重要),事實表中的記錄就不好處理這種情況,因為你把它賦予任何一個值都是不合適的。這種方法是為了處理像數據依賴(外鍵的關系)和錯誤處理比較常見的方法。