想看點關于cluster的理論教材的,
看到Distributed Systems Concepts And Design,
而且書評也不錯,于是就買了.
沒想到講了一堆什么TCP/IP,ATM, 路由,轉換之類的,都是
我不感興趣的內容,好無聊嘎.雖然好像有章節講到cluster,
不過貌似在很后面和后面的樣子,要經過好多無聊的章節:(
放下書后又看了一下頁數,天:(,800多頁,那么每一章節都要是
又臭又長,有許多boring的內容了..
還有抱怨一句,可能是由于影印版的關系,里頭的每節的heading,
以及圖里頭的一些塊的顏色,都是淺色,根本看不清楚。我想原書
這些應該是來強調的吧,不過被影印了之后,反倒
需要更加費力的看,根本達不到強調的效果了。
另,可憐的blogdriver為什么上不去了,一連就成tomcat的默認頁面樣子?..
posted @
2006-06-25 23:18 femto 閱讀(380) |
評論 (0) |
編輯 收藏
以前用過一次Norton Goback,整個恢復時間持續兩小時,太慢了,要比Norton Ghost的恢復麻煩多了.
昨天機器慢,又想重裝,發現可以restore的時間點就剩下最近的兩個了,之前的都沒有了,
我的天,那不是沒有用么.
本來Norton Ghost,一個光驅+win98安裝盤就是一個完美的備份恢復解決方案,可惜的是
公司沒有光驅,導致這種方案不能用。
另外一種方案就是一個盤上裝上主操作系統如winxp,另一個盤裝上win98,雙啟動,
然后可以用win98進來作恢復。這種就是針對沒光驅的恢復方案,不過需要一開始
裝系統的時候就裝成這樣。
posted @
2006-02-19 15:19 femto 閱讀(559) |
評論 (0) |
編輯 收藏
explorer /select, $FilePath$
posted @
2006-02-08 11:48 femto 閱讀(432) |
評論 (0) |
編輯 收藏
(from webwork in action).webwork in action的源代碼建立了crudStack簡化crud編程,
而書中也提到了如何建立直接從ide跑resin.
Alternatively, you can set up a Servlet container’s main method to be executed
directly like any other application and pass it the configuration information it
needs to automatically pick up your web application. For example, to set up
Resin 2.1 from Caucho (
www.caucho.com) as a standalone application pointing
to a project-specific configuration file, you would set parameters as follows:
Setting up your environment 387
■ Main class—com.caucho.server.http.HttpServer
■ VM parameters—-Dresin.home=. -Xdebug -Xnoagent -Djava.compiler=NONE
-Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=12345
■ Program parameters—-conf resin.xml
■ Working directory—Root directory of your project
■ Classpath—Classpath of your project plus the Resin JARs
posted @
2006-02-08 11:36 femto 閱讀(466) |
評論 (0) |
編輯 收藏
Dontclick.it explores a clickfree environment. It wants to explore how and what
changes for the user and the interface once you can't rely on the habit of clicking.
An experimental interface by LXFX
posted @
2006-02-05 18:07 femto 閱讀(318) |
評論 (0) |
編輯 收藏
這幾天開始看薩姆爾森的經濟學,看到市場經濟 vs 指令經濟一節,呵呵,
比對碰到的iask情況和國內wiki情況,剛好胡言亂語一番。
iask就類似與市場經濟一般,用分數來鼓勵人們回答問題,在這種利益的驅策下,
用戶自然會積極回答問題,貢獻自己的智慧,所以iask實際上也是在被一個'看不見的手'
所驅動,由人們自己的利己心而達到的一個平衡。
反觀國內wiki現狀,大多發展不起來,不像國外,概因國人的利己心還相對過于嚴重,
往往懶得無私貢獻力量,這樣的話,僅靠少數無私的人,是很難撐起一個社區性質的平臺的,
所以國內wiki往往發展不起來。即便如javaeye的doc工程,也是發展緩慢,難見后效。
posted @
2006-01-23 18:11 femto 閱讀(445) |
評論 (0) |
編輯 收藏
偶爾跑書店,隨便瞅瞅,左一看右一看的,看到那本書吸引了注意,
就隨手拿起翻翻,諸多因素,比方書的頁面,書的書名,書的位置,
書的內容,自己的心情等等,都可能導致選擇一本書或者不選擇一本書。于是每每有一些隨機的收獲。
家里的藏書,每為通過各種方式買了回來,放在家里,有些買了就看,有些買了卻又不立即看,
僅是放在家里。偶爾有機會瞄見引起興致,說不定又拿起來看了,就象在書店
由于某種偶然因素導致隨機拿起一本書似的。
前面瞥見半年前買的<獵頭>(中國第一本系統揭示獵頭行業的書),
這是半年前買的,買回來就放下了,半年之前買了沒看,半年之來也跟不少獵頭打了交道,偶然瞥見家里有這本書,隨便拿起翻翻,挺感興趣。于是決定開始閱讀了,呵呵。
家書店,隨機閱讀,呵呵.
posted @
2006-01-18 20:12 femto 閱讀(321) |
評論 (0) |
編輯 收藏
發現hibernate source里頭的log配置,記下來,說不定有用呵呵
http://cvs.sourceforge.net/viewcvs.py/hibernate/Hibernate3/etc/log4j.properties?rev=1.7### direct log messages to stdout ###
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### direct messages to file hibernate.log ###
#log4j.appender.file=org.apache.log4j.FileAppender
#log4j.appender.file.File=hibernate.log
#log4j.appender.file.layout=org.apache.log4j.PatternLayout
#log4j.appender.file.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### set log levels - for more verbose logging change 'info' to 'debug' ###
log4j.rootLogger=warn, stdout
log4j.logger.org.hibernate=info
#log4j.logger.org.hibernate=debug
### log HQL query parser activity
#log4j.logger.org.hibernate.hql.ast.AST=debug
### log just the SQL
#log4j.logger.org.hibernate.SQL=debug
### log JDBC bind parameters ###
log4j.logger.org.hibernate.type=info
#log4j.logger.org.hibernate.type=debug
### log schema export/update ###
log4j.logger.org.hibernate.tool.hbm2ddl=debug
### log HQL parse trees
#log4j.logger.org.hibernate.hql=debug
### log cache activity ###
#log4j.logger.org.hibernate.cache=debug
### log transaction activity
#log4j.logger.org.hibernate.transaction=debug
### log JDBC resource acquisition
#log4j.logger.org.hibernate.jdbc=debug
### enable the following line if you want to track down connection ###
### leakages when using DriverManagerConnectionProvider ###
#log4j.logger.org.hibernate.connection.DriverManagerConnectionProvider=trace
posted @
2005-12-20 19:58 femto 閱讀(1445) |
評論 (1) |
編輯 收藏
原來用Newzcrawler訂閱blog的,好用是好用,但是一換機器,就啥都沒有了。
bloglines稍微試了一下,還不太習慣,而且因為是web程序,
點起來不能馬上有反應,不是很舒服.
so謹以本貼紀錄一些好的blog,免得再度丟了..
http://jroller.com/page/RickHigh/homeps:各位同志有什么好的方法么?
我覺得理想的應用應該是免安裝的,換一臺機器也能用的,
另外最好多人之間可以共享一些好的訂閱的,像這樣子的應用.
Updated:試了幾個在線的blogReader,
bloglines難看,reader.google.com難用,幾個blog都混在一起了,
最后還是live.com好用,而且界面也漂亮,只是blog下面沒有分類,這個以后訂閱多了
不太方便。
posted @
2005-12-20 19:34 femto 閱讀(391) |
評論 (0) |
編輯 收藏
強,寒一個...
posted @
2005-12-18 11:22 femto 閱讀(1174) |
評論 (4) |
編輯 收藏
中文鍵盤,好些鍵上面除了英文名,還有中文翻譯,
比如Esc上面寫推出,Tab上面寫制表,Ctrl寫控制,
Shift寫上檔,Alt是換檔,Backspace是回格,哈哈,真夠好玩的
posted @
2005-12-05 15:59 femto 閱讀(254) |
評論 (0) |
編輯 收藏
推論一,一個推論,任何東西過多,最后的贏家都是搜索引擎
推論二,web1.0的時代是搜索引擎和網站雙贏,那么web2.0時代就是搜索引擎和blogger雙贏(當然還有BSP)
posted @
2005-12-04 23:42 femto 閱讀(209) |
評論 (0) |
編輯 收藏
而jwebunit是對httpunit的封裝,當然也通不過。
再試了htmlunit,也是一樣報錯,
看來只能用apache的httpclient了
posted @
2005-11-23 00:15 femto 閱讀(1351) |
評論 (2) |
編輯 收藏People often criticize asynchronous messaging solutions as too complicated and cumbersome. Or, they believe distributed solutions cannot be successful unless they include a distributed transaction model. There is little doubt that asynchronous solutions require us to think in new ways as we have to deal with concurrency, out-of-sequence issues, correlation and other. However, the real world is full of examples of asynchronous processes that successfully with exactly the same issues. We don't have to go further than the local coffee shop...
Hotto Cocoa o Kudasai
I just returned from a 2 week trip to Japan. One of the more familiar sights was the ridiculous number of Starbucks (???????) coffee shops, especially around Shinjuku and Roppongi. While waiting for my "Hotto Cocoa" I started to think about how Starbucks processes drink orders. Starbucks, like most other businesses is primarily interested in maximizing throughput of orders. More orders equals more revenue. As a result they use asynchronous processing. When you place your order the cashier marks a coffee cup with your order and places it into the queue. The queue is quite literally a queue of coffee cups lined up on top of the espresso machine. This queue decouples cashier and barista and allows the cashier to keep taking orders even if the barista is backed up for a moment. It allows them to deploy multiple baristas in a Competing Consumer scenario if the store gets busy.
Correlation
By taking advantage of an asynchronous approach Starbucks also has to deal with the same challenges that asynchrony inherently brings. Take for example, correlation. Drink orders are not necessarily completed in the order they were placed. This can happen for two reasons. First, multiple baristas may be processing orders using different equipment. Blended drinks may take longer than a drip coffee. Second, baristas may make multiple drinks in one batch to optimize processing time. As a result, Starbucks has a correlation problem. Drinks are delivered out of sequence and need to be matched up to the correct customer. Starbucks solves the problem with the same "pattern" we use in messaging architectures -- they use a Correlation Identifier. In the US, most Starbucks use an explicit correlation identifier by writing your name on the cup and calling it out when the drink is complete. In other countries, you have to correlate by the type of drink.
Exception Handling
Exception handling in asynchronous messaging scenarios can be difficult. If the real world writes the best stories maybe we can learn something by watching how Starbucks deals with exceptions. What do they do if you can't pay? They will toss the drink if it has already been made or otherwise pull your cup from the "queue". If they deliver you a drink that is incorrect or nonsatisfactory they will remake it. If the machine breaks down and they cannot make your drink they will refund your money. Each of these scenarios describes a different, but common error handling strategy:
- Write-off - This error handling strategy is the simplest of all: do nothing. Or discard what you have done. This might seem like a bad plan but in the reality of business this option might be acceptable. If the loss is small it might be more expensive to build an error correction solution than to just let things be. For example, I worked for a number of ISP providers who would chose this approach when there was an error in the billing / provisioning cycle. As a result, a customer might end up with active service but would not get billed. The revenue loss was small enough to allow the business to operate in this way. Periodically, they would run reconciliation reports to detect the "free" accounts and close them.
- Retry - When some operations of a larger group (i.e. "transaction") fail, we have essentially two choices: undo the ones that are already done or retry the ones that failed. Retry is a plausible option if there is a realistic chance that the retry will actually succeed. For example, if a business rule is violated it is unlikely a retry will succeed. However, if an external system is not available a retry might well be successful. A special case is a retry with Idempotent Receiver. In this case we can simply retry all operations since the successful receivers will ignore duplicate messages.
- Compensating Action - The last option is to undo operations that were already completed to put the system back into a consistent state. Such "compensating actions" work well for example if we deal with monetary systems where we can recredit money that has been debited.
All of these strategies are different than a two-phase commit that relies on separate prepare and execute steps. In the Starbucks example, a two-phase commit would equate to waiting at the cashier with the receipt and the money on the table until the drink is finished. Then, the drink would be added to the mix. Finally the money, receipt and drink would change hands in one swoop. Neither the cashier nor the customer would be able to leave until the "transaction" is completed. Using such a two-phase-commit approach would certainly kill Starbucks' business because the number of customers they can serve within a certain time interval would decrease dramatically. This is a good reminder that a two-phase-commit is can make life a lot simpler but it can also hurt the free flow of messages (and therefore the scalability) because it has to maintain stateful transaction resources across the flow of multiple, asynchronous actions.
Conversations
The coffee shop interaction is also a good example of a simple, but common Conversation pattern. The interaction between two parties (customer and coffee shop) consists of a short synchronous interaction (ordering and paying) and a longer, asynchronous interaction (making and receiving the drink). This type of conversation is quite common in purchasing scenarios. For example, when placing an order on Amazon the short synchronous interaction assigns an order number and all subsequent steps (charging credit card, packaging, shipping) are done asynchronously. You are notified via e-mail (asynchronous) when the additional steps complete. If anything goes wrong, Amazon usually compensates (refund to credit card) or retries (resend lost goods).
In summary we can see that the real world is often asynchronous. Our daily lives consists of many coordinated, but asynchronous interactions (reading and replying to e-mail, buying coffee etc). This means that an asynchronous messaging architecture can often be a natural way to model these types of interactions. It also means that often we can look at daily life to help design successful messaging solutions. Domo arigato gozaimasu!
About the author
Gregor Hohpe Blog:
http://www.enterpriseintegrationpatterns.com/ramblings.html Gregor Hohpe leads the Enterprise Integration practice at ThoughtWorks, Inc., a specialized provider of application development and integration services. Gregor is a widely recognized thought leader on asynchronous messaging architectures and co-author of the seminal book "Enterprise Integration Patterns" (Addison-Wesley, 2004). Gregor speaks regularly at technical conferences around the world and maintains the Web site www.eaipatterns.com.
(from
http://www.theserverside.net/blogs/showblog.tss?id=TwoPhaseCommit)
看完之后,第一就是佩服的作者的水平
第二就是對Enterprise Integration patterns這本書產生了興趣
posted @
2005-11-18 21:43 femto 閱讀(815) |
評論 (0) |
編輯 收藏Web 2.0 的課什么時候開呀?
昨天在復旦,談起Web 2.0。問我怎么看。我講了個故事。
課
明天早上有節大課,
原本是8點鐘開課。
同學甲
聽說了有課,
3點鐘就去教室占座位,
并堅持認為5點鐘就會開課。
同學乙
雖然清醒的知道8點鐘才開課,
但看到3點鐘已經有人占座位了,
估計6點鐘再去沒位置了,
不得已3點鐘也去占座位。
同學丙和同學丁
4點鐘的時候,堅持認為5點鐘開課的同學丙可能把占到的座位賣給認為6點鐘會開課的同學丁。
同學戊
5點鐘的時候,同學戊叫著說,別等了,今天的課不上了,大家撤吧。
祝各位同學好運
同學甲需要堅持,我們不要打擊他,
因為他們推動了科技進步,
但做好準備,開課的時間比預料的晚了3個小時;
同學乙也需要堅持,
不過看來是帶著干糧來的,
有堅持的準備;
同學丙是聰明的人,
知道自己堅持不了多久,卻不想浪費知道有課這個消息;
同學丁在合適的時間進入,也不錯。
不要只聽同學甲的,因為熱情和干糧不見得耗得到8點鐘;
也不要只聽同學戊,課還是要上的,只不過不時5點鐘而已。
所以祝每位同學好運。
-------------------------------------------------------------------------------------------------
(來自http://home.wangjianshuo.com/cn/20051020_web_20_ceaeae.htm)
你是同學幾阿?
posted @
2005-11-18 16:59 femto 閱讀(252) |
評論 (0) |
編輯 收藏
微軟也是創新的。關于創新,它一直在微軟的血液里面。微軟內部的達爾文主義(物競天擇,適者生存),從Windows 95時代到現在,從來都沒有改變過。邁克爾-德拉蒙德所寫的《微軟帝國叛逆》就講述了OpenGL組里三個工程是堅持認為世界上有比OpenGL更適合Windows系統的圖形引擎,于是掀起了微軟內部的戰爭,秘密開發DirectX引擎。戰爭最終以更多的內部的部門采用更快更簡單得DirectX而不是OpenGL,并使OpenGL組最終轉變成為DirectX組而告終。這內部的種種創新的故事,已經有很多本書的記述了。
(來源于王建碩的blog)
posted @
2005-11-18 01:51 femto 閱讀(538) |
評論 (2) |
編輯 收藏
管理員,沒找到怎么用trackback阿?
posted @
2005-11-18 00:58 femto 閱讀(328) |
評論 (2) |
編輯 收藏其實很多功能吧,發明的人一開始并不一定都想到的,
比如一些軍用發明轉民用,你會驚訝的發現,
你的用戶會采用一些你意想不到的方式使用你的系統
posted @
2005-11-18 00:58 femto 閱讀(258) |
評論 (0) |
編輯 收藏 Google給每位工程師20%的自由支配時間。在私人時間里,大家反而創意勃發;誕
生了Gmail郵箱產品和人際網絡產品Orkut
嗯,20%的自由支配時間,真的很吸引人,google就是google,確有獨到之處。
事實上,人在比較free比較自由的時候,確實容易創意勃發,萌生很多想法
比如我的一些創意想法,就像下面這個曾經在論壇上發表過的想法
 google 20%的空余時間可以給世界 創造很有創意的想法 比如我現在覺得,電腦上的字典就很不好用,查一個單詞,還就給出 文字解釋,真是太原始了,應該充分發揮電腦的多媒體優勢, 在解釋一個單詞就給出圖片或者相關動畫,就像小孩子學單詞一樣,由本能 figure out what the word means. 不要文字,或者只在需要時再給出文字解釋。
google 20%的空余時間可以給世界 創造很有創意的想法 比如我現在覺得,電腦上的字典就很不好用,查一個單詞,還就給出 文字解釋,真是太原始了,應該充分發揮電腦的多媒體優勢, 在解釋一個單詞就給出圖片或者相關動畫,就像小孩子學單詞一樣,由本能 figure out what the word means. 不要文字,或者只在需要時再給出文字解釋。 還有以前發表的java應該動態化,POHP(Plain Old Html Page),都是在一些比較閑適,
比較隨意的時候,突然想法蹦到腦子里頭來的。
posted @
2005-11-17 23:53 femto 閱讀(266) |
評論 (0) |
編輯 收藏
山德勒銷售研究所(Sandler Sales Institute)曾作過關于推薦人如何影響銷售環節的研究,他們的結論如下:
●電話銷售的成功率只有1%~5%
●如果告訴客戶推件人姓名的話,銷售成功率為15%左右
●如果推薦人能給你的客戶打電話或發送電子郵件的話,銷售成功率就上升到50%
●如果推薦人能出現在你和客戶的會面或電話交談中,那么銷售的成功率就飆升至70%多,甚至超過80%
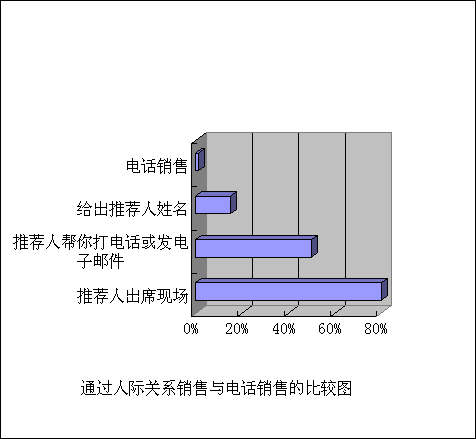
找工作也是類似的,呵呵,所以人脈很重要,呵呵
posted @
2005-11-17 14:39 femto 閱讀(323) |
評論 (1) |
編輯 收藏首頁充滿了技術的教學文章,看多了是不是會有點審美疲勞呢,呵呵,我來推薦超越技術之外的一些東西。
第一個就是joel on software,獲得jolt震撼大獎的,joel的水平可謂一流,書中充滿了睿智的想法和有趣的言論,絕對值的一讀,關于書的讀法,我并不是順序讀取的,而是按照感興趣的來,你們也可以像我一樣,
先看看介紹或者amazon上的書評,讀取感興趣的部分。有些章節絕對值得一看,比如冰川下的秘密,漏洞抽象定律(leaky abstraction),看完了會讓你對軟件開發有更深邃的思考。我希望推薦的是joel的文章和joel的風格。
第二個是2本書,
<User Interface Design for programmers>,講User Interface Design的,頭一條原則,研究表明,用戶的frustration是add up的,而不管每一個造成frustration的原因多大或多小,只是感受最重要,所以軟件應該盡可能的減少frustration,符合用戶的expectation.
<Don't Make me think> 講Web Usability的,頭一條rule就是Don't Make me think,也就是說,頁面的大部分應該用戶一看即懂。
User Interface Design和Web Usability這兩個話題其實focus基本一樣,主要都是圍繞如何設計出更好的讓用戶使用的軟件,這兩本書可以結合著看,觀點互相補充,互相印證。
posted @
2005-11-17 08:06 femto 閱讀(653) |
評論 (3) |
編輯 收藏