一直以來似乎都有一個錯覺,認為map跟其他的集合類一樣繼承自Collection,其實不然,Map和Collection在結構層次上是沒有任何關系的,通過查看源碼可以發現map所有操作都是基于key-value對,而不是單獨的元素。
下面以HashMap為例子,深入對Map的實現機制進行了解,在這個過程中,請打開jdk源碼。
Hash算法
HashMap使用Hash算法,所以在解剖HashMap之間,需要先簡單的了解Hash算法,Hash算法一般也成為散列算法,通過散列算法將任意的值轉化成固定的長度輸出,該輸出就是散列值,這是一種壓縮映射,也就是,散列值的空間遠遠小于輸入的值空間。
簡單的說,hash算法的意義在于提供了一種快速存取數據的方法,它用一種算法建立鍵值與真實值之間的對應關系,(每一個真實值只能有一個鍵值,但是一個鍵值可以對應多個真實值),這樣可以快速在數組等里面存取數據。
下面我們建立一個HashMap,然后往里面放入12對key-value,這個HashMap的默認數組長度為16,我們的key分別存放在該數組的格子中,每個格子下面存放的元素又是以鏈表的方式存放元素。
public static void main(String[] args) {
Map map = new HashMap();
map.put("What", "chenyz");
map.put("You", "chenyz");
map.put("Don't", "chenyz");
map.put("Know", "chenyz");
map.put("About", "chenyz");
map.put("Geo", "chenyz");
map.put("APIs", "chenyz");
map.put("Can't", "chenyz");
map.put("Hurt", "chenyz");
map.put("you", "chenyz");
map.put("google", "chenyz");
map.put("map", "chenyz");
map.put("hello", "chenyz");
}
當我們新添加一個元素時,首先我們通過Hash算法計算出這個元素的Hash值的hashcode,通過這個hashcode的值,我們就可以計算出這個新元素應該存放在這個hash表的哪個格子里面,如果這個格子中已經存在元素,那么就把新的元素加入到已經存在格子元素的鏈表中。
運行上面的程序,我們對HashMap源碼進行一點修改,打印出每個key對象的hash值
What-->hash值:8
You-->hash值:3
Don't-->hash值:7
Know-->hash值:13
About-->hash值:11
Geo-->hash值:12
APIs-->hash值:1
Can't-->hash值:7
Hurt-->hash值:1
you-->hash值:10
google-->hash值:3
map-->hash值:8
hello-->hash值:0
計算出來的Hash值分別代表該key應該存放在Hash表中對應數字的格子中,如果該格子已經有元素存在,那么該key就以鏈表的方式依次放入格子中
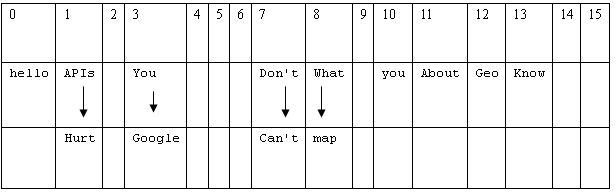
從上表可以看出,Hash表是線性表和鏈表的綜合所得,根據數據結構的定義,可以得出粗劣的結論,Hash算法的存取速度要比數組差一些,但是比起單純的鏈表,在查找和存取方面卻要好多。
如果要查找一個元素時,同樣的方式,通過Hash函數計算出這個元素的Hash值hashcode,然后通過這個hashcode值,直接找到跟這個hash值相對應的線性格子,進如該格子后,對這個格子存放的鏈表元素逐個進行比較,直到找到對應的hash值。
在簡單了解完Hash算法后,我們打開HashMap源碼
初始化HashMap
下面我們看看Map map = new HashMap();這段代碼究竟做了什么,發生了什么數據結構的變化。
HashMap中幾個重要的屬性
transient Entry[] table;
用來保存key-value的對象Entry數組,也就是Hash表
transient int size;
返回HashMap的鍵值對個數
final float loadFactor;
負載因子,用來決定Entry數組是否擴容的因子,HashMap默認是0.75f
int threshold;
重構因子,(capacity * load factor)負載因子與Entry[]數組容積的乘值
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
int threshold;
final float loadFactor;
transient Entry[] table;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int DEFAULT_INITIAL_CAPACITY = 16;
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
以public HashMap(int initialCapacity, float loadFactor)構造函數為例,另外兩個構造函數實際上也是以同種方式來構建HashMap.
首先是要確定hashMap的初始化的長度,這里使用的策略是循環查出一個大于initialCapacity的2的次方的數,例如initialCapacity的值是10,那么大于10的數是2的4次方,也就是16,capacity的值被賦予了16,那么實際上table數組的長度是16,之所以采用這樣的策略來構建Hash表的長度,是因為2的次方運算對于計算機來說是有相當的效率。
loadFactor,被稱為負載因子,HashMap的默認負載因子是0.75f
threshold,接下來是重構因子,由負載因子和容量的乘機組成,它表示當HashMap元素被存放了多少個之后,需要對HashMap進行重構。
通過這一系列的計算和定義后,初始化Entry[] table;
put(key,value)
接下來看一對key-value是如何被存放到HashMap中:put(key,value)
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
System.out.println(key+"-->hash值:"+i);//這就是剛才程序打印出來的key對應hash值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
這里是整個hash的關鍵,請打開源碼查看一步一步查看。
hash(key.hashCode()) 計算出key的hash碼 //對于hash()的算法,這里有一篇分析很透徹的文章<
HashMap hash方法分析>
indexFor(hash, table.length) 通過一個與算法計算出來,該key應在存放在Hash表的哪個格子中。
for (Entry<K,V> e = table[i]; e != null; e = e.next) 然后再遍歷table[i]格中的鏈表,判斷是否已經存在一樣的key,如果存在一樣的key值,那么就用新的value覆蓋舊的value,并把舊的value值返回。
addEntry(hash, key, value, i) 如果經過遍歷鏈表沒有發現同樣的key,那么進行addEntry函數的操作,增加當前key到hash表中的第i個格子中的鏈表中
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
Entry<K,V> e = table[bucketIndex]; 創建一個Entry對象來存放鍵值(ps:Entry對象是一個鏈表對象)
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); 將Entry對象添加到鏈表中
if (size++ >= threshold) resize(2 * table.length); 最后將size進行自增,判斷size值是否大于重構因子,如果大于那么就是用resize進行擴容重構。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
這里為什么是否需要擴容重構,其實是涉及到負載因子的性能問題
loadFactor負載因子
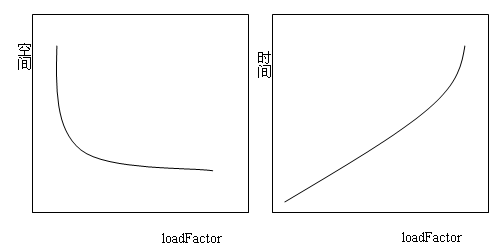
上面說過loadFactor是一個hashMap的決定性屬性,HashSet和HashMap的默認負載因子都是0.75,它表示,如果哈希表的容量超過3/4時,將自動成倍的增加哈希表的容量,這個值是權衡了時間和空間的成本,如果負載因子較高,雖然會減少對內存空間的需求,但也會增加查找數據的時間開銷,無論是put()和get()都涉及到對數據進行查找的動作,所以負載因子是不適宜設置過高
 get(key)
get(key)
接下來看看get(key)做了什么
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
這些動作似乎是跟put(key,value)相識,通過hash算法獲取key的hash碼,再通過indexFor定位出該key存在于table的哪一個下表,獲取該下標然后對下標中的鏈表進行遍歷比對,如果有符合就直接返回該key的value值。
keySet()
這里還涉及另一個問題,上面說了HashMap是跟set沒有任何親屬關系,但map也一樣實現了keySet接口,下面譜析一下keySet在hashMap中是如何實現的,這里給出部分代碼,請結合源碼查看
public K next() {
return nextEntry().getKey();
}
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
代碼很簡單,就是對每個格子里面的鏈表進行遍歷,也正是這個原因,當我們依次將key值put進hashMap中,但在使用map.entrySet().iterator()進行遍歷時候卻不是put時候的順序。
擴容
在前面說到put函數的時候,已經提過了擴容的問題
if (size++ >= threshold)
resize(2 * table.length);
這里一個是否擴容的判斷,當數據達到了threshold所謂的重構因子,而不是HashMap的最大容量,就進行擴容。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
transfer方法實際上是將所有的元素重新進行一些hash,這是因為容量變化了,每個元素相對應的hash值也會不一樣。
使用HashMap
1.不要再高并發中使用HashMap,HashMap是線程不安全,如果被多個線程共享之后,將可能發生不可預知的問題。
2.如果數據大小事固定的,最好在初始化的時候就給HashMap一個合理的容量值,如果使用new HashMap()默認構造函數,重構因子的值是16*0.75=12,當HashMap的容量超過了12后,就會進行一系列的擴容運算,重建一個原來成倍的數組,并且對原來存在的元素進行重新的hash運算,如果你的數據是有成千上萬的,那么你的成千上萬的數據也要跟這你的擴容不斷的hash,這將產生高額的內存和cpu的大量開銷。
當然啦,HashMap的函數還有很多,不過都是基于table的鏈表進行操作,當然也就是hash算法,Map & hashMap在平時我們的應用非常多,最重要的是我們要對每句代碼中每塊數據結構變化心中有數。
上面主要是參考了jdk源碼,數據結構和一些相關資料本著好記性不如爛博客的精神記錄下來,希望朋友們如果發覺哪里不對請指出來,虛心請教
----------------------------------------
by 陳于喆
QQ:34174409
Mail: dongbule@163.com