Microsoft SQL Server 2008 基本安裝說明
安裝SQL2008的過程與SQL2005的程序基本一樣,只不過在安裝的過程中部分選項有所改變,當然如果只熟悉SQL2000安裝的同志來說則是一個革命性的變動,
一、安裝前的準備
1. 需要.Net Framework 3.5,若在Vista或更高的OS上需要3.5 SP1的支持(在SQL2008安裝的前會自動更新安裝)
2. 需要Widnows PowerShell的支持,WPS是一個功能非常強大的Shell應用,命令與DOX/UNIX兼容并支持直接調用.NET模塊做行命令編輯,是非常值得深入研究的工具(在SQL2008安裝時會自動更新安裝)
3. 需要確保Windows Installer的成功啟動,需要4.5以上版本(需要檢查服務啟動狀態(tài)service.msc)
4. 需要MDAC2.8 sp1的支持(XP以上系統(tǒng)中已集成)
5. 若機器上已經(jīng)安裝Visual studio 2008則需要VS 2008 sp1以上版本的支持(需要自己從MS的網(wǎng)站上下載安裝http://www.microsoft.com/downloads/details.aspx?familyid=FBEE1648-7106-44A7-9649-6D9F6D58056E&displaylang=en)
二、安裝配置過程
1.進行SQL Server安裝中心,選擇"安裝"選項,在新的電腦上安裝SQL2008可以直接選擇“全新SQL Server獨立安裝或向現(xiàn)有安裝功能",將會安裝一個默認SQL實列,如下圖
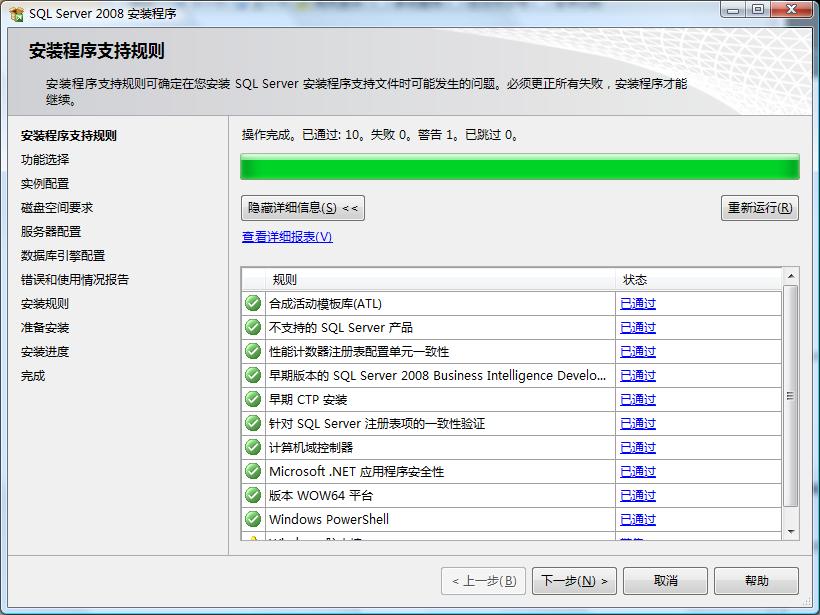
2.功能選擇,對于只安裝數(shù)據(jù)庫服務器來說,功能的選擇上可以按實際工作需要來制定,本人一般選擇:數(shù)據(jù)庫引擎服務、客戶端工具連接、SQL Server 聯(lián)機叢書、管理工具-基本、管理工具-完整
其中數(shù)據(jù)庫引擎服務是SQL數(shù)據(jù)庫的核心服務,Analysis及Reporting服務可按部署要求安裝,這兩個服務可能需要IIS的支持。如下圖
3.實列設置,可直接選擇默認實例進行安裝,或則若同一臺服務器中有多個數(shù)據(jù)服務實列可按不同實列名進行安裝。如圖
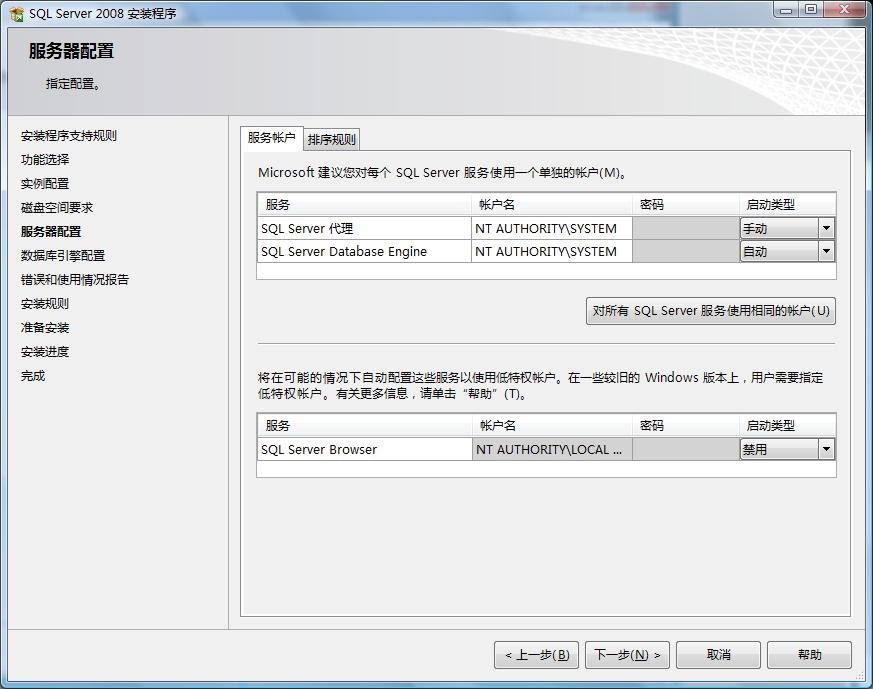
4.服務器配置,服務器配置主要是服務啟動帳戶的配置,服務的帳戶名推薦使用NT AUTHORITY\SYSTEM的系統(tǒng)帳戶,并指定當前選擇服務的啟動類型,如圖
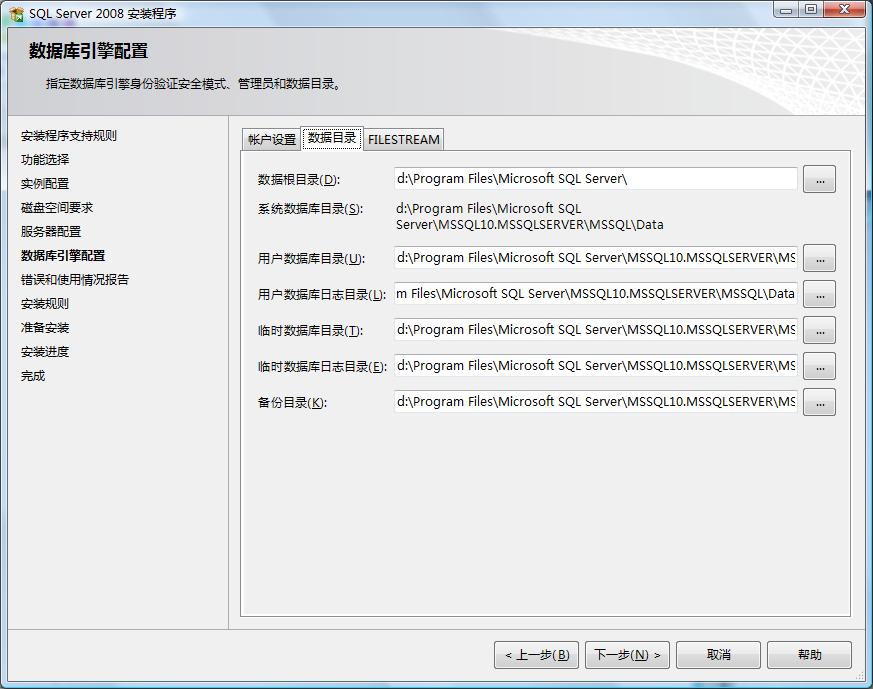
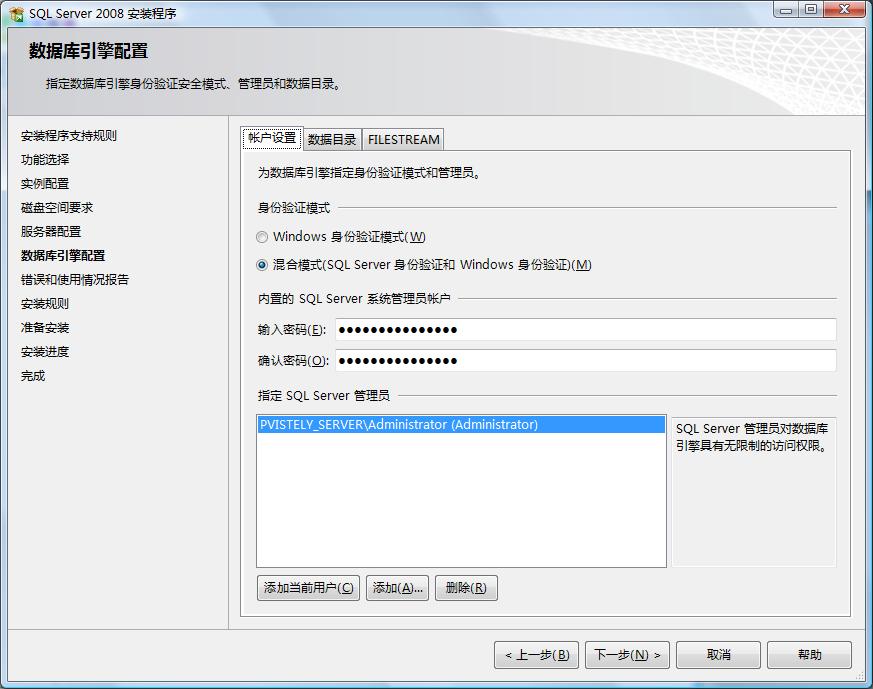
5.數(shù)據(jù)庫引擎配置,在當前配置中主要設置SQL登錄驗證模式及賬戶密碼,與SQL的數(shù)據(jù)存儲目錄,身份驗證模式推薦使用混合模式進行驗證,在安裝過程中內(nèi)置的SQL Server系統(tǒng)管理員帳戶(sa)的密碼比較特殊,SQL2008對SA的密碼強度要求相對比較高,需要有大小寫字母、數(shù)字及符號組成,否則將不允許你繼續(xù)安裝。在"指定Sql Server管理員"中最好指定本機的系統(tǒng)管理員administrator。如圖
線程 A 就會進入阻塞狀態(tài)來等待獲得叉,而線程 B 則阻塞來等待 A 所擁有的刀。
讓所有的線程按照同樣的順序獲得一組鎖。這種方法消除了 X 和 Y 的擁有者分別等待對方的資源的問題。
將多個鎖組成一組并放到同一個鎖下。前面死鎖的例子中,可以創(chuàng)建一個銀器對象的鎖。于是在獲得刀或叉之前都必須獲得這個銀器的鎖。
將那些不會阻塞的可獲得資源用變量標志出來。當某個線程獲得銀器對象的鎖時,就可以通過檢查變量來判斷是否整個銀器集合中的對象鎖都可獲得。如果是,它就可以獲得相關的鎖,否則,就要釋放掉銀器這個鎖并稍后再嘗試。
最重要的是,在編寫代碼前認真仔細地設計整個系統(tǒng)。多線程是困難的,在開始編程之前詳細設計系統(tǒng)能夠幫助你避免難以發(fā)現(xiàn)死鎖的問題。
摘要: oracle腳本:drop table t_student cascade constraints;Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->/*==================================================...
在Session的緩存中存放的是相互關聯(lián)的對象圖。默認情況下,當Hibernate從數(shù)據(jù)庫中加載Customer對象時,會同時加載所有關聯(lián)的 Order對象。以Customer和Order類為例,假定ORDERS表的CUSTOMER_ID外鍵允許為null
以下Session的find()方法用于到數(shù)據(jù)庫中檢索所有的Customer對象:
List customerLists=session.find("from Customer as c");
運行以上find()方法時,Hibernate將先查詢CUSTOMERS表中所有的記錄,然后根據(jù)每條記錄的ID,到ORDERS表中查詢有參照關系的記錄,Hibernate將依次執(zhí)行以下select語句:
select * from CUSTOMERS;
select * from ORDERS where CUSTOMER_ID=1;
select * from ORDERS where CUSTOMER_ID=2;
select * from ORDERS where CUSTOMER_ID=3;
select * from ORDERS where CUSTOMER_ID=4;
通過以上5條select語句,Hibernate最后加載了4個Customer對象和5個Order對象,在內(nèi)存中形成了一幅關聯(lián)的對象圖.
Hibernate在檢索與Customer關聯(lián)的Order對象時,使用了默認的立即檢索策略。這種檢索策略存在兩大不足:
(1) select語句的數(shù)目太多,需要頻繁的訪問數(shù)據(jù)庫,會影響檢索性能。如果需要查詢n個Customer對象,那么必須執(zhí)行n+1次select查詢語 句。這就是經(jīng)典的n+1次select查詢問題。這種檢索策略沒有利用SQL的連接查詢功能,例如以上5條select語句完全可以通過以下1條 select語句來完成:
select * from CUSTOMERS left outer join ORDERS
on CUSTOMERS.ID=ORDERS.CUSTOMER_ID
以上select語句使用了SQL的左外連接查詢功能,能夠在一條select語句中查詢出CUSTOMERS表的所有記錄,以及匹配的ORDERS表的記錄。
(2)在應用邏輯只需要訪問Customer對象,而不需要訪問Order對象的場合,加載Order對象完全是多余的操作,這些多余的Order對象白白浪費了許多內(nèi)存空間。
為了解決以上問題,Hibernate提供了其他兩種檢索策略:延遲檢索策略和迫切左外連接檢索策略。延遲檢索策略能避免多余加載應用程序不需要訪問的關聯(lián)對象,迫切左外連接檢索策略則充分利用了SQL的外連接查詢功能,能夠減少select語句的數(shù)目。
對數(shù)據(jù)庫訪問還是必須考慮性能問題的, 在設定了1 對多這種關系之后, 查詢就會出現(xiàn)傳說中的n +1 問題。
1 )1 對多,在1 方,查找得到了n 個對象, 那么又需要將n 個對象關聯(lián)的集合取出,于是本來的一條sql查詢變成了n +1 條
2)多對1 ,在多方,查詢得到了m個對象,那么也會將m個對象對應的1 方的對象取出, 也變成了m+1
怎么解決n +1 問題?
1 )lazy=true, hibernate3開始已經(jīng)默認是lazy=true了;lazy=true時不會立刻查詢關聯(lián)對象,只有當需要關聯(lián)對象(訪問其屬性,非id字段)時才會發(fā)生查詢動作。
2)二級緩存, 在對象更新,刪除,添加相對于查詢要少得多時, 二級緩存的應用將不怕n +1 問題,因為即使第一次查詢很慢,之后直接緩存命中也是很快的。
不同解決方法,不同的思路,第二條卻剛好又利用了n +1 。
3) 當然你也可以設定fetch=join(annotation : @ManyToOne() @Fetch(FetchMode.JOIN))