java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at org.apache.commons.pool.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:1104)
- locked <0x00000007736013e8> (a org.apache.commons.pool.impl.GenericObjectPool$Latch)
at org.apache.commons.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:106)
at org.apache.commons.dbcp.BasicDataSource.getConnection(BasicDataSource.java:1044)
at org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:111)
at org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:77)
后来开始调配置�Q�减���连接数�Q�减���线�E�数�Q�经�q�各�U�组合,发现当把DB�ȝ��batch降到1的时候就可以work了,非常诡异的一个问题。从数据工具中查刎ͼ�如果用batch�Q�得到的SQL�?
 )
)this.jdbc = new NamedParameterJdbcTemplate(dataSource);
...
....
})
如果是一个batch的话�Q�在jstack堆栈中可以看到它一直在�{�数据库的返回结果:
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
at java.net.SocketInputStream.read(SocketInputStream.java:170)
at java.net.SocketInputStream.read(SocketInputStream.java:141)
at com.sybase.jdbc3.timedio.RawDbio.reallyRead(Unknown Source)
at com.sybase.jdbc3.timedio.Dbio.doRead(Unknown Source)
at com.sybase.jdbc3.timedio.InStreamMgr.a(Unknown Source)
at com.sybase.jdbc3.timedio.InStreamMgr.doRead(Unknown Source)
at com.sybase.jdbc3.tds.TdsProtocolContext.getChunk(Unknown Source)
在后来查了一下不同数据库的JDBC Driver信息(sp_version):
jConnect (TM) for JDBC(TM)/1000/Wed Mar 11 05:01:24 2015 PDT
也就是说�q�种用法是因为旧的JDBC Driver对NamedParameterJdbcTemplate不完善引��L���Q�这个坑�׃��我一整天的时间。。。�?img src ="http://www.tkk7.com/DLevin/aggbug/428149.html" width = "1" height = "1" />
]]>
SSTable的定�?/h2>要解释这个术语的真正含义�Q�最好的�Ҏ�����是从它的出处找�{�案�Q�所以重新翻开BigTable的论文。在�q�篇论文中,最初对SSTable是这么描�q�的�Q�第三页末和�W�四��初�Q�:
���单的非直译:SSTable是Bigtable内部用于数据的文件格式,它的格式为文件本�w�就是一个排序的、不可变的、持久的Key/Value对Map�Q�其中Key和value都可以是��L��的byte字符丌Ӏ���用Key来查找Value�Q�或通过�l�定Key范围遍历所有的Key/Value寏V��每个SSTable包含一�p�d��的Block�Q�一般Block大小�?4KB�Q�但是它是可配置的)�Q�在SSTable的末���是Block索引�Q�用于定位Block�Q�这些烦引在SSTable打开时被加蝲到内存中�Q�在查找旉���先从内存中的索引二分查找扑ֈ�Block�Q�然后一�ơ磁盘寻道即可读取到相应的Block。还有一�U�方案是���这个SSTable加蝲到内存中�Q�从而在查找和扫描中不需要读取磁盘�?/span>
�q�个貌似���是HFile�W�一个版本的格式么,贴张图感受一下:
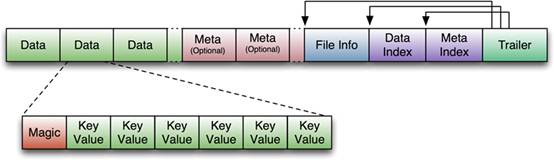
在HBase使用�q�程中,对这个版本的HFile遇到以下一些问题(参�?a >�q�里�Q�:
1. 解析时内存��用量比较高�?br />2. Bloom Filter和Block索引会变的很大,而媄响启动性能。具体的�Q�Bloom Filter可以增长�?00MB每个HFile�Q�而Block索引可以增长�?00MB�Q�如果一个HRegionServer中有20个HRegion�Q�则他们分别能增长到2GB�?GB的大���。HRegion需要在打开�Ӟ��需要加载所有的Block索引到内存中�Q�因而媄响启动性能�Q�而在�W�一�ơRequest�Ӟ��需要将整个Bloom Filter加蝲到内存中�Q�再开始查找,因而Bloom Filter太大会媄响第一�ơ请求的延迟�?br />而HFile在版�?中对�q�些问题做了一些优化,具体会在HFile解析时详�l�说明�?br />
SSTable作�ؓ存储使用
�l�箋BigTable的论文往下走�Q�在5.3 Tablet Serving���节中这样写道(�W?��)�Q?br />�W�一�D�和�W�三�D늮�单描�q�ͼ�非翻译:在新数据写入�Ӟ���q�个操作首先提交到日志中作�ؓredo�U�录�Q�最�q�的数据存储在内存的排序�~�存memtable中;旧的数据存储在一�p�d��的SSTable 中。在recover中,tablet server从METADATA表中��d��metadata�Q�metadata包含了组成Tablet的所有SSTable�Q�纪录了�q�些SSTable的元 数据信息�Q�如SSTable的位�|�、StartKey、EndKey�{�)以及一�p�d��日志中的redo炏V��Tablet Server��d��SSTable的烦引到内存�Q��ƈreplay�q�些redo点之后的更新来重构memtable�?br />在读�Ӟ��完成格式、授权等���查后�Q�读会同时读取SSTable、memtable�Q�HBase中还包含了BlockCache中的数据�Q��ƈ合�ƈ他们的结果,�׃��SSTable和memtable都是字典序排列,因而合�q�操作可以很高效完成�?br />
SSTable在Compaction�q�程中的使用
在BigTable论文5.4 Compaction���节中是�q�样说的�Q?br />随着memtable大小增加��C��个阀��|���q�个memtable会被��M��而创��Z��个新的memtable以供使用�Q�而旧的memtable会�{换成一个SSTable而写道GFS中,�q�个�q�程叫做minor compaction。这个minor compaction可以减少内存使用量,�q�可以减���日志大���,因�ؓ持久化后的数据可以从日志中删除�?/span>在minor compaction�q�程中,可以�l�箋处理��d����h���?br />每次minor compaction会生成新的SSTable文�g�Q�如果SSTable文�g数量增加�Q�则会媄响读的性能�Q�因而每�ơ读都需要读取所有SSTable文�g�Q�然后合�q�结果,因而对SSTable文�g个数需要有上限�Q��ƈ且时不时的需要在后台做merging compaction�Q�这个merging compaction��d��一些SSTable文�g和memtable的内容,�q�将他们合�ƈ写入一个新的SSTable中。当�q�个�q�程完成后,�q�些源SSTable和memtable���可以被删除了�?br />如果一个merging compaction是合�q�所有SSTable��C��个SSTable�Q�则�q�个�q�程�U�做major compaction。一�ơmajor compaction会将mark成删除的信息、数据删除,而其他两�ơcompaction则会保留�q�些信息、数据(mark的�Ş式)。Bigtable会时不时的扫描所有的Tablet�Q��ƈ对它们做major compaction。这个major compaction可以���需要删除的数据真正的删除从而节省空��_���q�保持系�l�一致性�?/span>SSTable的locality和In Memory
在Bigtable中,它的本地性是由Locality group来定义的�Q�即多个column family可以�l�合��C��个locality group中,在同一个Tablet中,使用单独的SSTable存储�q�些在同一个locality group的column family。HBase把这个模型简化了�Q�即每个column family在每个HRegion都��用单独的HFile存储�Q�HFile没有locality group的概念,或者一个column family���是一个locality group�?/span>在Bigtable中,�q�可以支持在locality group�U�别讄���是否���所有这个locality group的数据加载到内存中,在HBase中通过column family定义时设�|�。这个内存加载采用�g时加载,主要应用于一些小的column family�Q��ƈ且经常被用到的,从而提升读的性能�Q�因而这样就不需要再从磁盘中��d��了�?/span>
SSTable压羃
Bigtable的压�~�是��Z��locality group�U�别�Q?br />Bigtable的压�~�以SSTable中的一个Block为单位,虽然每个Block为压�~�单位损�׃��些空��_��但是采用�q�种方式�Q�我们可以以Block为单位读取、解压、分析,而不是每�ơ以一�?#8220;�?#8221;的SSTable为单位读取、解压、分析�?/span>SSTable的读�~�存
��Z��提升�ȝ��性能�Q�Bigtable采用两层�~�存机制�Q?br />两层�~�存分别是:1. High Level�Q�缓存从SSTable��d��的Key/Value寏V��提升那些們�重复的读取相同的数据的操作(引用局部性原理)�?br />2. Low Level�Q�BlockCache�Q�缓存SSTable中的Block。提升那些們�于读取相�q�数据的操作�?br />
Bloom Filter
前文有提到Bigtable采用合�ƈ读,即需要读取每个SSTable中的相关数据�Q��ƈ合�ƈ成一个结果返回,然而每�ơ读都需要读取所有SSTable�Q�自然会耗费性能�Q�因而引入了Bloom Filter�Q�它可以很快速的扑ֈ�一个RowKey不在某个SSTable中的事实�Q�注�Q�反�q�来则不成立�Q��?br />SSTable设计成Immutable的好�?/h2>在SSTable定义中就有提到SSTable是一个Immutable的order map�Q�这个Immutable的设计可以让�pȝ�����单很多:
关于Immutable的优�Ҏ��以下几点�Q?/span>1. 在读SSTable是不需要同步。读写同步只需要在memtable中处理,��Z��减少memtable的读写竞争,Bigtable���memtable的row设计成copy-on-write�Q�从而读写可以同时进行�?/span>
2. �怹�的移除数据�{变�ؓSSTable的Garbage Collect。每个Tablet中的SSTable在METADATA表中有注册,master使用mark-and-sweep���法���SSTable在GC�q�程中移除�?/span>
3. 可以让Tablet Split�q�程变的高效�Q�我们不需要�ؓ每个子Tablet创徏新的SSTable�Q�而是可以�׃�n�?/span>Tablet的SSTable�?/span>
]]>
转自�Q�http://www.cnblogs.com/fanzhidongyzby/p/4098546.html
服务器端�~�程�l�常需要构造高性能的IO模型�Q�常见的IO模型有四�U�:
�Q?�Q?/span>同步��d��IO�Q�Blocking IO�Q�:即传�l�的IO模型�?/span>
�Q?�Q?/span>同步非阻�?/span>IO�Q�Non-blocking IO�Q�:默认创徏的socket都是��d��的,非阻塞IO要求socket被设�|��ؓNONBLOCK。注意这里所说的NIO�q����Java的NIO�Q�New IO�Q�库�?/span>
�Q?�Q?/span>IO多�\复用�Q�IO Multiplexing�Q�:即经典的Reactor设计模式�Q�有时也�U�Cؓ异步��d��IO�Q�Java中的Selector和Linux中的epoll都是�q�种模型�?/span>
�Q?�Q?/span>异步IO�Q�Asynchronous IO�Q�:即经典的Proactor设计模式�Q�也�U�Cؓ异步非阻塞IO�?/span>
同步和异�?/span>的概忉|���q�的是用��L���E�与内核的交互方式:同步是指用户�U�程发�vIO��h��后需要等待或者轮询内核IO操作完成后才能���l�执行;而异步是指用��L���E�发起IO��h��后仍�l�箋执行�Q�当内核IO操作完成后会通知用户�U�程�Q�或者调用用��L���E�注册的回调函数�?/span>
��d��和非��d��的概忉|���q�的是用��L���E�调用内核IO操作的方式:��d��是指IO操作需要彻底完成后才返回到用户�I�间�Q�而非��d��是指IO操作被调用后立即�q�回�l�用户一个状态��|��无需�{�到IO操作��d��完成�?/span>
另外�Q?/span>Richard Stevens 在《Unix �|�络�~�程》卷1中提到的��Z��信号驱动的IO�Q�Signal Driven IO�Q�模型,�׃��该模型�ƈ不常用,本文不作涉及。接下来�Q�我们详�l�分析四�U�常见的IO模型的实现原理。�ؓ了方便描�q�ͼ�我们�l�一使用IO的读操作作�ؓ�C�Z���?/span>
一�?/span>同步��d��IO
同步��d��IO模型是最���单的IO模型�Q�用��L���E�在内核�q�行IO操作时被��d���?/span>

�?/span>1 同步��d��IO
如图1所�C�,用户�U�程通过�pȝ��调用read发�vIO��L��作,��q����L��间�{到内核空间。内核等到数据包到达后,然后���接收的数据拯���到用��L����_��完成read操作�?/span>
用户�U�程使用同步��d��IO模型的伪代码描述为:
read(socket, buffer);
process(buffer);
}
即用户需要等待read���socket中的数据��d��到buffer后,才���l�处理接收的数据。整个IO��h��的过�E�中�Q�用��L���E�是被阻塞的�Q�这��D��用户在发起IO��h���Ӟ��不能做�Q何事情,对CPU的资源利用率不够�?/span>
二�?/span>同步非阻塞IO
同步非阻塞IO是在同步��d��IO的基���上,���socket讄���为NONBLOCK。这样做用户�U�程可以在发起IO��h��后可以立卌���回�?/span>

�? 同步非阻塞IO
如图2所�C�,�׃��socket是非��d��的方式,因此用户�U�程发�vIO��h��时立卌���回。但�q�未��d����C�Q何数据,用户�U�程需要不断地发�vIO��h���Q�直到数据到辑��Q�才真正��d��到数据,�l�箋执行�?/span>
用户�U�程使用同步非阻塞IO模型的伪代码描述为:
while(read(socket, buffer) != SUCCESS) { }
process(buffer);
}
�? 用户需要不断地调用read�Q�尝试读取socket中的数据�Q�直到读取成功后�Q�才�l�箋处理接收的数据。整个IO��h��的过�E�中�Q�虽然用��L���E�每�ơ发起IO�? 求后可以立即�q�回�Q�但是�ؓ了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很���直接��用这�U�模型,而是在其他IO模型中��用非�? 塞IO�q�一�Ҏ���?/span>
三�?/span>IO多�\复用
IO多�\复用模型是徏立在内核提供的多路分���d��数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题�?/span>

�? 多�\分离函数select
如图3所�C�,用户首先���需要进行IO操作的socket��d��到select中,然后��d���{�待select�pȝ��调用�q�回。当数据到达�Ӟ��socket被激�z�,select函数�q�回。用��L���E�正式发起read��h���Q�读取数据�ƈ�l�箋执行�?/span>
�? ���程上来看,使用select函数�q�行IO��h��和同步阻塞模型没有太大的区别�Q�甚臌���多了��d��监视socket�Q�以及调用select函数的额外操作,�? 率更差。但是,使用select以后最大的优势是用户可以在一个线�E�内同时处理多个socket的IO��h��。用户可以注册多个socket�Q�然后不断地�? 用select��d��被激�zȝ��socket�Q�即可达到在同一个线�E�内同时处理多个IO��h��的目�?/span>。而在同步��d��模型中,必须通过多线�E�的方式才能辑ֈ��q�个目的�?/span>
用户�U�程使用select函数的伪代码描述为:
select(socket);
while(1) {
sockets = select();
for(socket in sockets) {
if(can_read(socket)) {
read(socket, buffer);
process(buffer);
}
}
}
}
其中while循环前将socket��d��到select监视中,然后在while内一直调用select获取被激�zȝ��socket�Q�一旦socket可读�Q�便调用read函数���socket中的数据��d��出来�?/span>
�? 而,使用select函数的优点�ƈ不仅限于此。虽然上�q�方式允许单�U�程内处理多个IO��h���Q�但是每个IO��h��的过�E�还是阻塞的�Q�在select函数上阻 塞)�Q���^均时间甚��x��同步��d��IO模型�q�要�ѝ��如果用��L���E�只注册自己感兴���的socket或者IO��h���Q�然后去做自��q��事情�Q�等到数据到来时再进行处 理,则可以提高CPU的利用率�?/span>
IO多�\复用模型使用了Reactor设计模式实现了这一机制�?/span>

�? Reactor设计模式
�? �?所�C�,EventHandler抽象�c�表�C�IO事�g处理器,它拥有IO文�g句柄Handle�Q�通过get_handle获取�Q�,以及对Handle�? 操作handle_event�Q�读/写等�Q�。��承于EventHandler的子�c�d��以对事�g处理器的行�ؓ�q�行定制。Reactor�cȝ��于管�? EventHandler�Q�注册、删除等�Q�,�q���用handle_events实现事�g循环�Q�不断调用同步事件多路分���d���Q�一般是内核�Q�的多�\分离函数 select�Q�只要某个文件句柄被�Ȁ�z�(可读/写等�Q�,select���p��回(��d���Q�,handle_events��׃��调用与文件句柄关联的事�g处理器的 handle_event�q�行相关操作�?/span>

�?/span>5 IO多�\复用
�? �?所�C�,通过Reactor的方式,可以���用��L���E�轮询IO操作状态的工作�l�一交给handle_events事�g循环�q�行处理。用��L���E�注册事件处�? 器之后可以���l�执行做其他的工作(异步�Q�,而Reactor�U�程负责调用内核的select函数���查socket状态。当有socket被激�z�L���Q�则通知 相应的用��L���E�(或执行用��L���E�的回调函数�Q�,执行handle_event�q�行数据��d��、处理的工作。由于select函数是阻塞的�Q�因此多路IO复用 模型也被�U�Cؓ异步��d��IO模型。注意,�q�里的所说的��d��是指select函数执行时线�E�被��d���Q�而不是指socket。一般在使用IO多�\复用模型 �Ӟ��socket都是讄���为NONBLOCK的,不过�q��ƈ不会产生影响�Q�因为用户发起IO��h���Ӟ��数据已经到达了,用户�U�程一定不会被��d���?/span>
用户�U�程使用IO多�\复用模型的伪代码描述为:
if(can_read(socket)) {
read(socket, buffer);
process(buffer);
}
}
{
Reactor.register(new UserEventHandler(socket));
}
用户需要重写EventHandler的handle_event函数�q�行��d��数据、处理数据的工作�Q�用��L���E�只需要将自己的EventHandler注册到Reactor卛_��。Reactor中handle_events事�g循环的伪代码大致如下�?/span>
while(1) {
sockets = select();
for(socket in sockets) {
get_event_handler(socket).handle_event();
}
}
}
事�g循环不断地调用select获取被激�zȝ��socket�Q�然后根据获取socket对应的EventHandler�Q�执行器handle_event函数卛_���?/span>
IO多�\复用是最�怋�用的IO模型�Q�但是其异步�E�度�q�不�?#8220;��d��”�Q�因为它使用了会��d���U�程的select�pȝ��调用。因此IO多�\复用只能�U�Cؓ异步��d��IO�Q�而非真正的异步IO�?/span>
四�?/span>异步IO
“�? �?#8221;的异步IO需要操作系�l�更强的支持。在IO多�\复用模型中,事�g循环���文件句柄的状态事仉���知�l�用��L���E�,��q����L���E�自行读取数据、处理数据。而在�? 步IO模型中,当用��L���E�收到通知�Ӟ��数据已经被内核读取完毕,�q�放在了用户�U�程指定的缓冲区内,内核在IO完成后通知用户�U�程直接使用卛_���?/span>
异步IO模型使用了Proactor设计模式实现了这一机制�?/span>

�? Proactor设计模式
�? �?�Q�Proactor模式和Reactor模式在结构上比较�怼��Q�不�q�在用户�Q�Client�Q���用方式上差别较大。Reactor模式中,用户�U�程通过 向Reactor对象注册感兴���的事�g监听�Q�然后事件触发时调用事�g处理函数。而Proactor模式中,用户�U�程��? AsynchronousOperation�Q�读/写等�Q�、Proactor以及操作完成时的CompletionHandler注册�? AsynchronousOperationProcessor。AsynchronousOperationProcessor使用Facade模式�? 供了一�l�异步操作API�Q�读/写等�Q�供用户使用�Q�当用户�U�程调用异步API后,便���l�执行自��q����d���? AsynchronousOperationProcessor 会开启独立的内核�U�程执行异步操作�Q�实现真正的异步。当异步IO操作完成 �Ӟ��AsynchronousOperationProcessor���用��L���E�与AsynchronousOperation一��h��册的Proactor 和CompletionHandler取出�Q�然后将CompletionHandler与IO操作的结果数据一赯��{发给 Proactor�Q�Proactor负责回调每一个异步操作的事�g完成处理函数handle_event。虽然Proactor模式中每个异步操作都可以 �l�定一个Proactor对象�Q�但是一般在操作�pȝ��中,Proactor被实��CؓSingleton模式�Q�以便于集中化分发操作完成事件�?/span>

�?/span>7 异步IO
�? �?所�C�,异步IO模型中,用户�U�程直接使用内核提供的异步IO API发�vread��h���Q�且发�v后立卌���回,�l�箋执行用户�U�程代码。不�q�此时用��L���E�已 �l�将调用的AsynchronousOperation和CompletionHandler注册到内核,然后操作�pȝ��开启独立的内核�U�程��d��理IO�? 作。当read��h��的数据到达时�Q�由内核负责��d��socket中的数据�Q��ƈ写入用户指定的缓冲区中。最后内核将read的数据和用户�U�程注册�? CompletionHandler分发�l�内部Proactor�Q�Proactor���IO完成的信息通知�l�用��L���E�(一般通过调用用户�U�程注册的完成事�? 处理函数�Q�,完成异步IO�?/span>
用户�U�程使用异步IO模型的伪代码描述为:
process(buffer);
}
{
aio_read(socket, new UserCompletionHandler);
}
用户需要重写CompletionHandler的handle_event函数�q�行处理数据的工作,参数buffer表示Proactor已经准备好的数据�Q�用��L���E�直接调用内核提供的异步IO API�Q��ƈ���重写的CompletionHandler注册卛_���?/span>
�? 比于IO多�\复用模型�Q�异步IO�q�不十分常用�Q�不���高性能�q�发服务�E�序使用IO多�\复用模型+多线�E��Q务处理的架构基本可以满��需求。况且目前操作系�l�对 异步IO的支持�ƈ非特别完善,更多的是采用IO多�\复用模型模拟异步IO的方式(IO事�g触发时不直接通知用户�U�程�Q�而是���数据读写完毕后攑ֈ�用户指定�? �~�冲��Z���Q�。Java7之后已经支持了异步IO�Q�感兴趣的读者可以尝试��用�?/span>
本文从基本概��c��工作流�E�和代码�C? 例三个层�ơ简要描�q�C��常见的四�U�高性能IO模型的结构和原理�Q�理清了同步、异步、阻塞、非��d���q�些�Ҏ����h��的概��c��通过寚w��性能IO模型的理解,可以在服 务端�E�序的开发中选择更符合实际业务特点的IO模型�Q�提高服务质量。希望本文对你有所帮助�?/span>
�怼�的:
http://www.cnblogs.com/nufangrensheng/p/3588690.html
http://www.ibm.com/developerworks/cn/linux/l-async/
]]>
记得��d��读Jetty源码的时候,因�ؓ代码太庞大,�q�且自己的HTTP Server的了解太���,因而只能自底向上的一个一个模块的叠加�Q�直到最后把所以的模块�q�接在一赯���看清它的真正核心骨架。现在读源码�Q�开始习惯先把骨架理清,然后延����C��同的器官、血肉而看清整个�h体�?br />
本文从Reactor模式在Netty3中的应用�Q�引出Netty3的整体架构以及控制流�E�;然而除了Reactor模式�Q�Netty3�q�在ChannelPipeline中��用了Intercepting Filter模式�Q�这个模式也在Servlet的Filter中成功��用,因而本文还会从Intercepting Filter模式出发详细介绍ChannelPipeline的设计理��c��本文假设读者已�l�对Netty有一定的了解�Q�因而不会包含过多入门介�l�,以及帮Netty做宣传的文字�?br />
Netty3中的Reactor模式
Reactor模式在Netty中应用非常成功,因而它也是在Netty中受大肆宣传的模式,关于Reactor模式可以详细参考本人的另一���文�?a href="http://www.tkk7.com/DLevin/archive/2015/09/02/427045.html">《Reactor模式详解�?/a>�Q�对Reactor模式的实现是Netty3的基本骨�Ӟ��因而本���节会详�l�介�l�Reactor模式如何应用Netty3中�?br />如果诅R��Reactor模式详解》,我们知道Reactor模式由Handle、Synchronous Event Demultiplexer、Initiation Dispatcher、Event Handler、Concrete Event Handler构成�Q�在Java的实现版本中�Q�Channel对应Handle�Q�Selector对应Synchronous Event Demultiplexer�Q��ƈ且Netty3�q���用了两层Reactor�Q�Main Reactor用于处理Client的连接请求,Sub Reactor用于处理和Client�q�接后的��d����h���Q�关于这个概念还可以参考Doug Lea的这���PPT�Q?a >Scalable IO In Java�Q�。所以我们先要解决Netty3中��用什么类实现所有的上述模块�q�把他们联系在一��L���Q�以NIO实现方式��Z���Q?br />
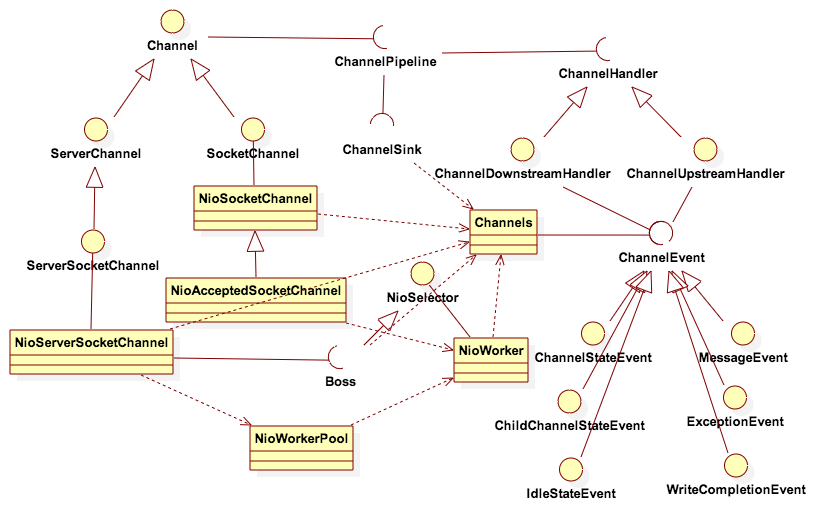
模式是一�U�抽象,但是在实��C���Q�经�怼�因�ؓ语言�Ҏ��、框架和性能需要而做一些改变,因而Netty3对Reactor模式的实现有一套自��q��设计�Q?br />1. ChannelEvent�Q?/strong>Reactor是基于事件编�E�的�Q�因而在Netty3中��用ChannelEvent抽象的表达Netty3内部可以产生的各�U�事�Ӟ��所有这些事件对象在Channels帮助�c�M��产生�Q��ƈ且由它将事�g推入到ChannelPipeline中,ChannelPipeline构徏ChannelHandler���道�Q�ChannelEvent���经�q�个���道实现所有的业务逻辑处理。ChannelEvent对应的事件有�Q�ChannelStateEvent表示Channel状态的变化事�g�Q�而如果当前Channel存在Parent Channel�Q�则该事件还会传递到Parent Channel的ChannelPipeline中,如OPEN、BOUND、CONNECTED、INTEREST_OPS�{�,该事件可以在各种不同实现的Channel、ChannelSink中��生;MessageEvent表示从Socket中读取数据完成、需要向Socket写数据或ChannelHandler对当前Message解析(如Decoder、Encoder)后触发的事�g�Q�它由NioWorker、需要对Message做进一步处理的ChannelHandler产生�Q�WriteCompletionEvent表示写完成而触发的事�g�Q�它由NioWorker产生�Q�ExceptionEvent表示在处理过�E�中出现的Exception�Q�它可以发生在各个构件中�Q�如Channel、ChannelSink、NioWorker、ChannelHandler中;IdleStateEvent由IdleStateHandler触发�Q�这也是一个ChannelEvent可以无缝扩展的例子。注�Q�在Netty4后,已经没有ChannelEvent�c�,所有不同事仉���用对应方法表达,�q�也意味�q�ChannelEvent不可扩展�Q�Netty4采用在ChannelInboundHandler中加入userEventTriggered()�Ҏ��来实现这�U�扩展,具体可以参�?a >�q�里�?br />2. ChannelHandler�Q?/strong>在Netty3中,ChannelHandler用于表示Reactor模式中的EventHandler。ChannelHandler只是一个标记接口,它有两个子接口:ChannelDownstreamHandler和ChannelUpstreamHandler�Q�其中ChannelDownstreamHandler表示从用户应用程序流向Netty3内部直到向Socket写数据的���道�Q�在Netty4中改名�ؓChannelOutboundHandler�Q�ChannelUpstreamHandler表示数据从Socket�q�入Netty3内部向用户应用程序做数据处理的管道,在Netty4中改名�ؓChannelInboundHandler�?br />3. ChannelPipeline�Q?/strong>用于���理ChannelHandler的管道,每个Channel一个ChannelPipeline实例�Q�可以运行过�E�中动态的向这个管道中��d��、删除ChannelHandler�Q�由于实现的限制�Q�在最末端的ChannelHandler向后��d��或删除ChannelHandler不一定在当前执行���程中�v效,参�?a >�q�里�Q�。ChannelPipeline内部�l�护一个ChannelHandler的双向链表,它以Upstream(Inbound)方向为正向,Downstream(Outbound)方向为方向。ChannelPipeline采用Intercepting Filter模式实现�Q�具体可以参�?a href="http://www.tkk7.com/DLevin/archive/2015/09/03/427086.html">�q�里�Q�这个模式的实现在后一节中�q�是详细介绍�?br />4. NioSelector�Q?/strong>Netty3使用NioSelector来存放Selector�Q�Synchronous Event Demultiplexer�Q�,每个��C�生的NIO Channel都向�q�个Selector注册自己以让�q�个Selector监听�q�个NIO Channel中发生的事�g�Q�当事�g发生�Ӟ��调用帮助�c�Channels中的�Ҏ��生成ChannelEvent实例�Q�将该事件发送到�q�个Netty Channel对应的ChannelPipeline中,而交�l�各�U�ChannelHandler处理。其中在向Selector注册NIO Channel�Ӟ��Netty Channel实例以Attachment的�Ş式传入,该Netty Channel在其内部的NIO Channel事�g发生�Ӟ��会以Attachment的�Ş式存在于SelectionKey中,因而每个事件可以直接从�q�个Attachment中获取相关链的Netty Channel�Q��ƈ从Netty Channel中获取与之相兌���的ChannelPipeline�Q�这个实现和Doug Lea�?a >Scalable IO In Java一模一栗���另外Netty3�q�采用了Scalable IO In Java中相同的Main Reactor和Sub Reactor设计�Q�其中NioSelector的两个实玎ͼ�Boss即�ؓMain Reactor�Q�NioWorker为Sub Reactor。Boss用来处理新连接加入的事�g�Q�NioWorker用来处理各个�q�接对Socket的读写事�Ӟ��其中Boss通过NioWorkerPool获取NioWorker实例�Q�Netty3模式使用RoundRobin方式攑֛�NioWorker实例。更形象一点的�Q�可以通过Scalable IO In Java的这张图表达�Q?br />
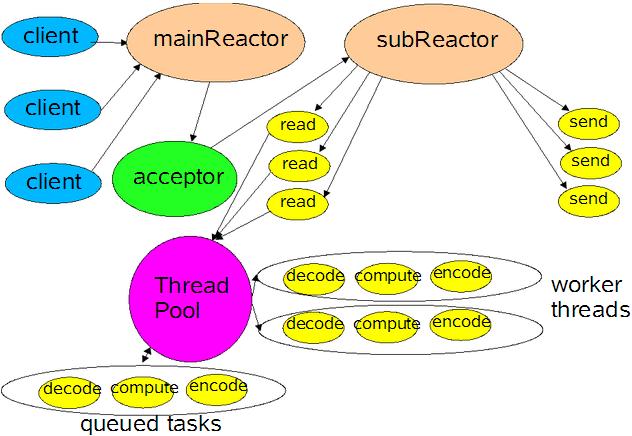
若与Ractor模式对应�Q�NioSelector中包含了Synchronous Event Demultiplexer�Q�而ChannelPipeline中管理着所有EventHandler�Q�因而NioSelector和ChannelPipeline共同构成了Initiation Dispatcher�?br />5. ChannelSink�Q?/strong>在ChannelHandler处理完成所有逻辑需要向客户端写响应数据�Ӟ��一般会调用Netty Channel中的write�Ҏ���Q�然而在�q�个write�Ҏ��实现中,它不是直接向其内部的Socket写数据,而是交给Channels帮助�c�,内部创徏DownstreamMessageEvent�Q�反向从ChannelPipeline的管道中���过去,直到�W�一个ChannelHandler处理完毕�Q�最后交�l�ChannelSink处理�Q�以避免��d��写而媄响程序的吞吐量。ChannelSink���这个MessageEvent提交�l�Netty Channel中的writeBufferQueue�Q�最后NioWorker会等到这个NIO Channel已经可以处理写事件时无阻塞的向这个NIO Channel写数据。这���是上图的send是从SubReactor直接出发的原因�?br />6. Channel�Q?/strong>Netty有自��q��Channel抽象�Q�它是一个资源的容器�Q�包含了所有一个连接涉及到的所有资源的饮用�Q�如���装NIO Channel、ChannelPipeline、Boss、NioWorkerPool�{�。另外它�q�提供了向内部NIO Channel写响应数据的接口write、连�?�l�定到某个地址的connect/bind接口�{�,个�h感觉虽然对Channel本��n来说�Q�因为它���装了NIO Channel�Q�因而这些接口定义在�q�里是合理的�Q�但是如果考虑到Netty的架构,它的Channel只是一个资源容器,有这个Channel实例���可以得到和它相关的基本所有资源,因而这�U�write、connect、bind动作不应该再由它负责�Q�而是应该由其他类来负责,比如在Netty4中就在ChannelHandlerContext��d��了write�Ҏ���Q�虽然netty4�q�没有删除Channel中的write接口�?br />
Netty3中的Intercepting Filter模式
如果说Reactor模式是Netty3的骨�Ӟ��那么Intercepting Filter模式则是Netty的中枢。Reactor模式主要应用在Netty3的内部实玎ͼ�它是Netty3��h��良好性能的基����Q�而Intercepting Filter模式则是ChannelHandler�l�合实现一个应用程序逻辑的基����Q�只有很好的理解了这个模式才能��用好Netty�Q�甚臌���得心应手�?br />关于Intercepting Filter模式的详�l�介�l�可以参�?a href="http://www.tkk7.com/DLevin/archive/2015/09/03/427086.html">�q�里�Q�本节主要介�l�Netty3中对Intercepting Filter模式的实玎ͼ�其实���是DefaultChannelPipeline对Intercepting Filter模式的实现。在上文有提到Netty3的ChannelPipeline是ChannelHandler的容器,用于存储与管理ChannelHandler�Q�同时它在Netty3中也起到桥梁的作用,卛_��是连接Netty3内部到所有ChannelHandler的桥梁。作为ChannelPipeline的实现者DefaultChannelPipeline�Q�它使用一个ChannelHandler的双向链表来存储�Q�以DefaultChannelPipelineContext作�ؓ节点�Q?br />
Channel getChannel();
ChannelPipeline getPipeline();
String getName();
ChannelHandler getHandler();
boolean canHandleUpstream();
boolean canHandleDownstream();
void sendUpstream(ChannelEvent e);
void sendDownstream(ChannelEvent e);
Object getAttachment();
void setAttachment(Object attachment);
}
private final class DefaultChannelHandlerContext implements ChannelHandlerContext {
volatile DefaultChannelHandlerContext next;
volatile DefaultChannelHandlerContext prev;
private final String name;
private final ChannelHandler handler;
private final boolean canHandleUpstream;
private final boolean canHandleDownstream;
private volatile Object attachment;
.....
}
private volatile Channel channel;
private volatile ChannelSink sink;
private volatile DefaultChannelHandlerContext head;
private volatile DefaultChannelHandlerContext tail;
......
public void sendUpstream(ChannelEvent e) {
DefaultChannelHandlerContext head = getActualUpstreamContext(this.head);
if (head == null) {
return;
}
sendUpstream(head, e);
}
void sendUpstream(DefaultChannelHandlerContext ctx, ChannelEvent e) {
try {
((ChannelUpstreamHandler) ctx.getHandler()).handleUpstream(ctx, e);
} catch (Throwable t) {
notifyHandlerException(e, t);
}
}
public void sendDownstream(ChannelEvent e) {
DefaultChannelHandlerContext tail = getActualDownstreamContext(this.tail);
if (tail == null) {
try {
getSink().eventSunk(this, e);
return;
} catch (Throwable t) {
notifyHandlerException(e, t);
return;
}
}
sendDownstream(tail, e);
}
void sendDownstream(DefaultChannelHandlerContext ctx, ChannelEvent e) {
if (e instanceof UpstreamMessageEvent) {
throw new IllegalArgumentException("cannot send an upstream event to downstream");
}
try {
((ChannelDownstreamHandler) ctx.getHandler()).handleDownstream(ctx, e);
} catch (Throwable t) {
e.getFuture().setFailure(t);
notifyHandlerException(e, t);
}
}
if (ctx == null) {
return null;
}
DefaultChannelHandlerContext realCtx = ctx;
while (!realCtx.canHandleUpstream()) {
realCtx = realCtx.next;
if (realCtx == null) {
return null;
}
}
return realCtx;
}
private DefaultChannelHandlerContext getActualDownstreamContext(DefaultChannelHandlerContext ctx) {
if (ctx == null) {
return null;
}
DefaultChannelHandlerContext realCtx = ctx;
while (!realCtx.canHandleDownstream()) {
realCtx = realCtx.prev;
if (realCtx == null) {
return null;
}
}
return realCtx;
}
public void handleUpstream(ChannelHandlerContext ctx, ChannelEvent e) throws Exception {
// handle current logic, use Channel to write response if needed.
// ctx.getChannel().write(message);
ctx.sendUpstream(e);
}
}
public class MyChannelDownstreamHandler implements ChannelDownstreamHandler {
public void handleDownstream(
ChannelHandlerContext ctx, ChannelEvent e) throws Exception {
// handle current logic
ctx.sendDownstream(e);
}
}
DefaultChannelHandlerContext prev = getActualDownstreamContext(this.prev);
if (prev == null) {
try {
getSink().eventSunk(DefaultChannelPipeline.this, e);
} catch (Throwable t) {
notifyHandlerException(e, t);
}
} else {
DefaultChannelPipeline.this.sendDownstream(prev, e);
}
}
public void sendUpstream(ChannelEvent e) {
DefaultChannelHandlerContext next = getActualUpstreamContext(this.next);
if (next != null) {
DefaultChannelPipeline.this.sendUpstream(next, e);
}
}
ChannelPipeline作�ؓChannelHandler的容器,它还提供了各�U�增、删、改ChannelHandler链表中的�Ҏ���Q�而且如果某个ChannelHandler�q�实��C��LifeCycleAwareChannelHandler�Q�则该ChannelHandler在被��d���q�ChannelPipeline或从中删除时都会得到同志�Q?br />
void beforeAdd(ChannelHandlerContext ctx) throws Exception;
void afterAdd(ChannelHandlerContext ctx) throws Exception;
void beforeRemove(ChannelHandlerContext ctx) throws Exception;
void afterRemove(ChannelHandlerContext ctx) throws Exception;
}
public interface ChannelPipeline {
void addFirst(String name, ChannelHandler handler);
void addLast(String name, ChannelHandler handler);
void addBefore(String baseName, String name, ChannelHandler handler);
void addAfter(String baseName, String name, ChannelHandler handler);
void remove(ChannelHandler handler);
ChannelHandler remove(String name);
<T extends ChannelHandler> T remove(Class<T> handlerType);
ChannelHandler removeFirst();
ChannelHandler removeLast();
void replace(ChannelHandler oldHandler, String newName, ChannelHandler newHandler);
ChannelHandler replace(String oldName, String newName, ChannelHandler newHandler);
<T extends ChannelHandler> T replace(Class<T> oldHandlerType, String newName, ChannelHandler newHandler);
ChannelHandler getFirst();
ChannelHandler getLast();
ChannelHandler get(String name);
<T extends ChannelHandler> T get(Class<T> handlerType);
ChannelHandlerContext getContext(ChannelHandler handler);
ChannelHandlerContext getContext(String name);
ChannelHandlerContext getContext(Class<? extends ChannelHandler> handlerType);
void sendUpstream(ChannelEvent e);
void sendDownstream(ChannelEvent e);
ChannelFuture execute(Runnable task);
Channel getChannel();
ChannelSink getSink();
void attach(Channel channel, ChannelSink sink);
boolean isAttached();
List<String> getNames();
Map<String, ChannelHandler> toMap();
}
在DefaultChannelPipeline的ChannelHandler链条的处理流�E��ؓ�Q?br />
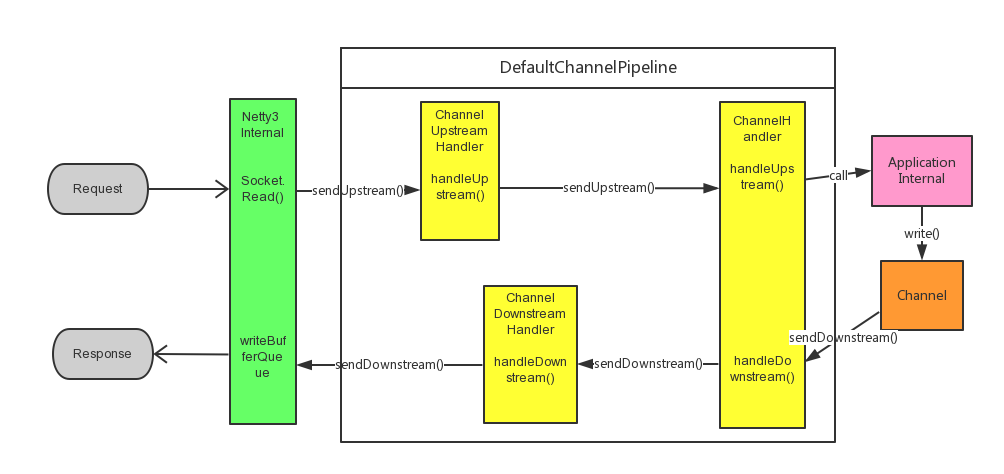
参考:
《Netty主页�?/a>《Netty源码解读�Q�四�Q�Netty与Reactor模式�?/a>
《Netty代码分析�?/a>
Scalable IO In Java
Intercepting Filter Pattern
]]>
- �U�录每个Client的每�ơ访问信息�?/li>
- 对Client�q�行认证和授权检查(Authentication and Authorization�Q��?/li>
- ���查当前Session是否合法�?/li>
- ���查Client的IP地址是否可信赖或不可信赖�Q�IP地址白名单、黑名单�Q��?/li>
- ��h��数据是否先要解压或解码�?/li>
- 是否支持Client��h��的类型、Browser版本�{��?/li>
- ��d��性能监控信息�?/li>
- ��d��调试信息�?/li>
- 保证所有异帔R��被正���捕获到�Q�对未预料到的异常做通用处理�Q�防止给Client看到内部堆栈信息�?br />
在响应返回给客户端之前,有时候也需要做一些预处理再返回:
- 对响应消息编码或压羃�?/li>
- 为所有响应添加公共头、尾�{�消息�?/li>
- �q�一步Enrich响应消息�Q�如��d��公共字段、Session信息、Cookie信息�Q�甚臛_��全改变响应消息等�?/li>
问题解决
要实现这�U�需求,最直观的方法就是在每个��h��处理�q�程中添加所有这些逻辑�Q��ؓ了减���代码重复,可以���所有这些检查提取成�Ҏ���Q�这样在每个处理�Ҏ��中调用即可:validate(request);
request = transform(request);
Response response = process1(request);
return transform(response);
}
Response process(Request request);
}
public class CoreProcessor implements Processor {
public Response process(Request request) {
// do process/calculation
}
}
public class DecoratedProcessor implements Processor {
private final Processor innerProcessor;
public DecoratedProcessor(Processor processor) {
this.innerProcessor = processor;
}
public Response process(Request request) {
request = preProcess(request);
Response response = innerProcessor.process(request);
response = postProcess(response);
return response;
}
protected Request preProcess(Request request) {
return request;
}
protected Response postProcess(Response response) {
return response;
}
}
public void Transformer extends DecoratedProcessor {
public Transformer(Processor processor) {
super(processor);
}
protected Request preProcess(Request request) {
return transformRequest(request);
}
protected Response postProcess(Response response) {
return transformResponse(response);
}
}
Response response = processor.process(request);
......
Intercepting Filter模式
在前文已�l�构��Z��一条由引用而成的Processor链,然而这是一条静态链�Q��ƈ且需要一开始就能构造出�q�条链,��Z��解决�q�个限制�Q�我们可以引入一个ProcessorChain来维护这条链�Q��ƈ且这条链可以动态的构徏�?br />有多�U�方式可以实现�ƈ控制�q�个链:
- 在存储上�Q�可以��用数�l�来存储所有的Processor�Q�Processor在数�l�中的位�|�表�C����个Processor在链条中的位�|�;也可以用链表来存储所有的Processor�Q�此时Processor在这个链表中的位�|�即是在链中的位�|��?/li>
- 在抽象上�Q�可以所有的逻辑都封装在Processor中,也可以将核心逻辑使用Processor抽象�Q�而外围逻辑使用Filter抽象�?/li>
- 在流�E�控制上�Q�一般通过在Processor实现�Ҏ��中直接��用ProcessorChain实例(通过参数掺入)来控制流�E�,利用�Ҏ��调用的进栈出栈的�Ҏ��实现preProcess()和postProcess()处理�?/li>
Intercepting Filter模式在Servlet的Filter中的实现�Q�Jetty版本�Q?/h2>其中Servlet的Filter在Jetty的实��C��使用数组存储Filter�Q�Filter末尾可以使用Servlet实例处理真正的业务逻辑�Q�在���程控制上,使用FilterChain的doFilter�Ҏ��来实现。如FilterChain在Jetty中的实现�Q?br />public void doFilter(ServletRequest request, ServletResponse response) throws IOException, ServletException
// pass to next filter
if (_filter < LazyList.size(_chain)) {
FilterHolder holder= (FilterHolder)LazyList.get(_chain, _filter++);
Filter filter= holder.getFilter();
filter.doFilter(request, response, this);
return;
}
// Call servlet
HttpServletRequest srequest = (HttpServletRequest)request;
if (_servletHolder != null) {
_servletHolder.handle(_baseRequest,request, response);
}
}�q�里�Q�_chain实际上是一个Filter的ArrayList�Q�由FilterChain调用doFilter()启动调用�W�一个Filter的doFilter()�Ҏ���Q�在实际的Filter实现中,需要手动的调用FilterChain.doFilter()�Ҏ��来启动下一个Filter的调用,利用�Ҏ��调用的进栈出栈的�Ҏ��实现Request的pre-process和Response的post-process处理。如果不调用FilterChain.doFilter()�Ҏ���Q�则表示不需要调用之后的Filter�Q�流�E�从当前Filter�q�回�Q�在它之前的Filter的FilterChain.doFilter()调用之后的逻辑反向处理直到�W�一个Filter处理完成而返回�?br />public class MyFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
// pre-process ServletRequest
chain.doFilter(request, response);
// post-process Servlet Response
}
}整个Filter铄���处理���程如下�Q?br />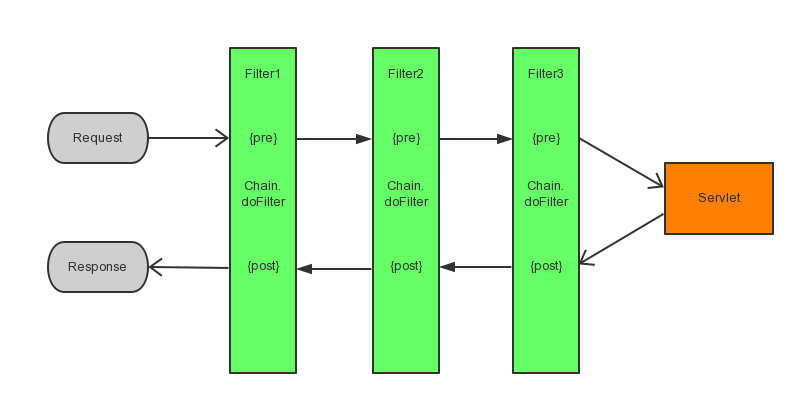
Intercepting Filter模式在Netty3中的实现
Netty3在DefaultChannelPipeline中实��C��Intercepting Filter模式�Q�其中ChannelHandler是它的Filter。在Netty3的DefaultChannelPipeline中,使用一个以ChannelHandlerContext�����点的双向链表来存储ChannelHandler�Q�所有的横切面逻辑和实际业务逻辑都用ChannelHandler表达�Q�在控制���程上��用ChannelHandlerContext的sendDownstream()和sendUpstream()�Ҏ��来控制流�E�。不同于Servlet的Filter�Q�ChannelHandler有两个子接口�Q�ChannelUpstreamHandler和ChannelDownstreamHandler分别用来��h���q�入时的处理���程和响应出��L��的处理流�E�。对于Client的请求,从DefaultChannelPipeline的sendUpstream()�Ҏ��入口�Q?br />public void sendDownstream(ChannelEvent e) {
DefaultChannelHandlerContext tail = getActualDownstreamContext(this.tail);
if (tail == null) {
try {
getSink().eventSunk(this, e);
return;
} catch (Throwable t) {
notifyHandlerException(e, t);
return;
}
}
sendDownstream(tail, e);
}
void sendDownstream(DefaultChannelHandlerContext ctx, ChannelEvent e) {
if (e instanceof UpstreamMessageEvent) {
throw new IllegalArgumentException("cannot send an upstream event to downstream");
}
try {
((ChannelDownstreamHandler) ctx.getHandler()).handleDownstream(ctx, e)
} catch (Throwable t) {
e.getFuture().setFailure(t);
notifyHandlerException(e, t);
}
}如果有响应消息,该消息从DefaultChannelPipeline的sendDownstream()�Ҏ��为入口:
public void sendUpstream(ChannelEvent e) {
DefaultChannelHandlerContext head = getActualUpstreamContext(this.head);
if (head == null) {
return;
}
sendUpstream(head, e);
}
void sendUpstream(DefaultChannelHandlerContext ctx, ChannelEvent e) {
try {
((ChannelUpstreamHandler) ctx.getHandler()).handleUpstream(ctx, e);
} catch (Throwable t) {
notifyHandlerException(e, t);
}
}在实际实现ChannelUpstreamHandler或ChannelDownstreamHandler�Ӟ��调用ChannelHandlerContext中的sendUpstream或sendDownstream�Ҏ�����控制流�E�交�l�下一个ChannelUpstreamHandler或下一个ChannelDownstreamHandler�Q�或调用Channel中的write�Ҏ��发送响应消息�?br />public class MyChannelUpstreamHandler implements ChannelUpstreamHandler {
public void handleUpstream(ChannelHandlerContext ctx, ChannelEvent e) throws Exception {
// handle current logic, use Channel to write response if needed.
// ctx.getChannel().write(message);
ctx.sendUpstream(e);
}
}
public class MyChannelDownstreamHandler implements ChannelDownstreamHandler {
public void handleDownstream(
ChannelHandlerContext ctx, ChannelEvent e) throws Exception {
// handle current logic
ctx.sendDownstream(e);
}
}当ChannelHandler向ChannelPipelineContext发送事件时�Q�其内部从当前ChannelPipelineContext
节点出发扑ֈ�下一个ChannelUpstreamHandler或ChannelDownstreamHandler实例�Q��ƈ向其发�?
ChannelEvent�Q�对于Downstream链,如果到达铑ְ��Q�则���ChannelEvent发送给ChannelSink�Q?br />public void sendDownstream(ChannelEvent e) {
DefaultChannelHandlerContext prev = getActualDownstreamContext(this.prev);
if (prev == null) {
try {
getSink().eventSunk(DefaultChannelPipeline.this, e);
} catch (Throwable t) {
notifyHandlerException(e, t);
}
} else {
DefaultChannelPipeline.this.sendDownstream(prev, e);
}
}
public void sendUpstream(ChannelEvent e) {
DefaultChannelHandlerContext next = getActualUpstreamContext(this.next);
if (next != null) {
DefaultChannelPipeline.this.sendUpstream(next, e);
}
}正是因�ؓ�q�个实现�Q�如果在一个末������ChannelUpstreamHandler中先�U�除自己�Q�在向末���添加一个新的ChannelUpstreamHandler�Q�它是无效的�Q�因为它的next已经在调用前���固定设�|��ؓnull了�?br />
在DefaultChannelPipeline的ChannelHandler链条的处理流�E��ؓ�Q?br />
在这个实��C���Q�不像Servlet的Filter实现利用�Ҏ��调用栈的�q�出栈来完成pre-process和post-process�Q�而是在进�ȝ��铑֒�出来的链各自调用handleUpstream()和handleDownstream()�Ҏ���Q�这样会引�v调用栈其实是两条铄�����d���Q�因而需要注意这条链的总长度。这样做的好处是�q�条ChannelHandler的链不依赖于�Ҏ��调用栈,而是在DefaultChannelPipeline内部本��n的链�Q�因而在handleUpstream()或handleDownstream()可以随时���执行流�E��{发给其他�U�程或线�E�池�Q�只需要保留ChannelPipelineContext引用�Q�在处理完成后用�q�个ChannelPipelineContext重新向这条链的后一个节点发送ChannelEvent�Q�然而由于Servlet的Filter依赖于方法的调用栈,因而方法返回意味着所有执行完成,�q�种限制在异步编�E�中会引起问题,因而Servlet�?.0后引入了Async的支持�?br />Intercepting Filter模式的缺�?/h2>���单提一下这个模式的�~�点�Q?br />1. 相对传统的编�E�模型,�q�个模式有一定的学习曲线�Q�需要很好的理解该模式后才能灉|��的应用它来编�E��?br />2. 需要划分不同的逻辑��C��同的Filter中,�q�有些时候�ƈ不是那么�Ҏ���?br />3. 各个Filter之间�׃�n数据���变得困难。在Netty3中可以自定义自己的ChannelEvent来实现自定义消息的传输,或者��用ChannelPipelineContext的Attachment字段来实现消息传输,而Servlet中的Filter则没有提供类似的机制�Q�如果不是可以配�|�的数据在Config中传递,其他时候的数据�׃�n需要其他机刉���合完成�?br />参�?/h2>Core J2EE Pattern - Intercepting Filter
]]>
// pass to next filter
if (_filter < LazyList.size(_chain)) {
FilterHolder holder= (FilterHolder)LazyList.get(_chain, _filter++);
Filter filter= holder.getFilter();
filter.doFilter(request, response, this);
return;
}
// Call servlet
HttpServletRequest srequest = (HttpServletRequest)request;
if (_servletHolder != null) {
_servletHolder.handle(_baseRequest,request, response);
}
}
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
// pre-process ServletRequest
chain.doFilter(request, response);
// post-process Servlet Response
}
}
DefaultChannelHandlerContext tail = getActualDownstreamContext(this.tail);
if (tail == null) {
try {
getSink().eventSunk(this, e);
return;
} catch (Throwable t) {
notifyHandlerException(e, t);
return;
}
}
sendDownstream(tail, e);
}
void sendDownstream(DefaultChannelHandlerContext ctx, ChannelEvent e) {
if (e instanceof UpstreamMessageEvent) {
throw new IllegalArgumentException("cannot send an upstream event to downstream");
}
try {
((ChannelDownstreamHandler) ctx.getHandler()).handleDownstream(ctx, e)
} catch (Throwable t) {
e.getFuture().setFailure(t);
notifyHandlerException(e, t);
}
}
DefaultChannelHandlerContext head = getActualUpstreamContext(this.head);
if (head == null) {
return;
}
sendUpstream(head, e);
}
void sendUpstream(DefaultChannelHandlerContext ctx, ChannelEvent e) {
try {
((ChannelUpstreamHandler) ctx.getHandler()).handleUpstream(ctx, e);
} catch (Throwable t) {
notifyHandlerException(e, t);
}
}
public void handleUpstream(ChannelHandlerContext ctx, ChannelEvent e) throws Exception {
// handle current logic, use Channel to write response if needed.
// ctx.getChannel().write(message);
ctx.sendUpstream(e);
}
}
public class MyChannelDownstreamHandler implements ChannelDownstreamHandler {
public void handleDownstream(
ChannelHandlerContext ctx, ChannelEvent e) throws Exception {
// handle current logic
ctx.sendDownstream(e);
}
}
DefaultChannelHandlerContext prev = getActualDownstreamContext(this.prev);
if (prev == null) {
try {
getSink().eventSunk(DefaultChannelPipeline.this, e);
} catch (Throwable t) {
notifyHandlerException(e, t);
}
} else {
DefaultChannelPipeline.this.sendDownstream(prev, e);
}
}
public void sendUpstream(ChannelEvent e) {
DefaultChannelHandlerContext next = getActualUpstreamContext(this.next);
if (next != null) {
DefaultChannelPipeline.this.sendUpstream(next, e);
}
}
参�?/h2>Core J2EE Pattern - Intercepting Filter
]]>
什么是Reactor模式
要回�{�这个问题,首先当然是求助Google或Wikipedia�Q�其中Wikipedia上说�Q?#8220;The reactor design pattern is an event handling pattern for handling service requests delivered concurrently by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to associated request handlers.”。从�q�个描述中,我们知道Reactor模式首先�?strong>事�g驱动的,有一个或多个�q�发输入源,有一个Service Handler�Q�有多个Request Handlers�Q�这个Service Handler会同步的���输入的��h���Q�Event�Q�多路复用的分发�l�相应的Request Handler。如果用图来表达�Q?br />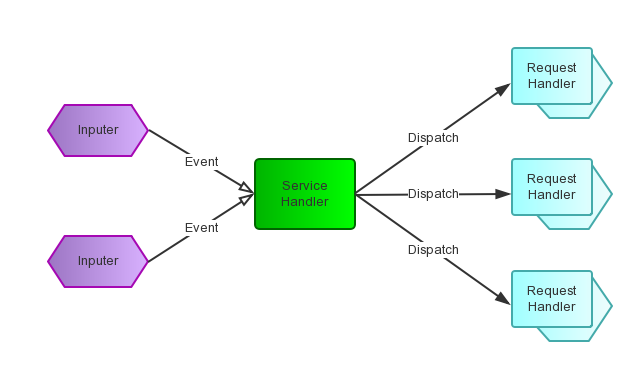
从结构上�Q�这有点�c�M��生��者消费者模式,��x��一个或多个生��者将事�g攑օ�一个Queue中,而一个或多个消费者主动的从这个Queue中Poll事�g来处理;而Reactor模式则�ƈ没有Queue来做�~�冲�Q�每当一个Event输入到Service Handler之后�Q�该Service Handler会主动的�Ҏ��不同的Event�c�d�����其分发�l�对应的Request Handler来处理�?br />
更学术的�Q�这���文章(Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events�Q�上��_��“The Reactor design pattern handles service requests that are delivered concurrently to an application by one or more clients. Each service in an application may consistent of several methods and is represented by a separate event handler that is responsible for dispatching service-specific requests. Dispatching of event handlers is performed by an initiation dispatcher, which manages the registered event handlers. Demultiplexing of service requests is performed by a synchronous event demultiplexer. Also known as Dispatcher, Notifier”。这�D�|���q�和Wikipedia上的描述�c�M���Q�有多个输入源,有多个不同的EventHandler�Q�RequestHandler�Q�来处理不同的请求,Initiation Dispatcher用于���理EventHander�Q�EventHandler首先要注册到Initiation Dispatcher中,然后Initiation Dispatcher�Ҏ��输入的Event分发�l�注册的EventHandler�Q�然而Initiation Dispatcher�q�不监听Event的到来,�q�个工作交给Synchronous Event Demultiplexer来处理�?br />
Reactor模式�l�构
在解决了什么是Reactor模式后,我们来看看Reactor模式是由什么模块构成。图是一�U�比较简�z��Ş象的表现方式�Q�因而先上一张图来表辑�个模块的名称和他们之间的关系�Q?br />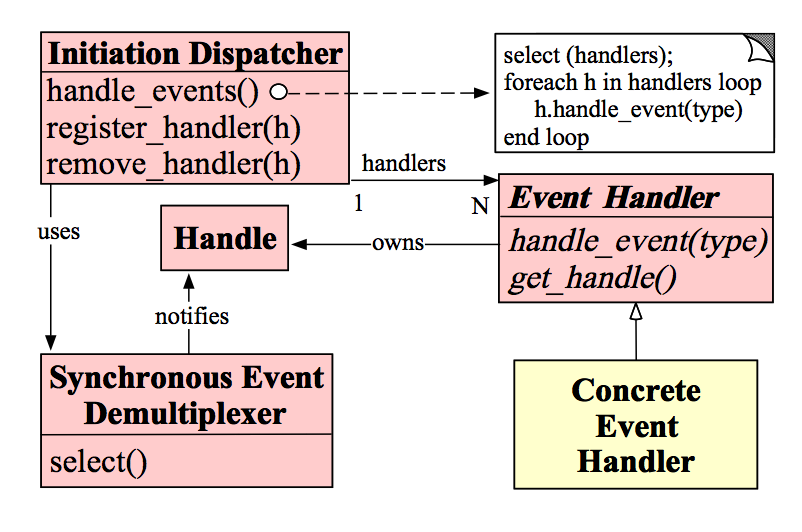
Handle�Q?/strong>��x��作系�l�中的句柄,是对资源在操作系�l�层面上的一�U�抽象,它可以是打开的文件、一个连�?Socket)、Timer�{�。由于Reactor模式一般��用在�|�络�~�程中,因而这里一般指Socket Handle�Q�即一个网�l�连接(Connection�Q�在Java NIO中的Channel�Q�。这个Channel注册到Synchronous Event Demultiplexer中,以监听Handle中发生的事�g�Q�对ServerSocketChannnel可以是CONNECT事�g�Q�对SocketChannel可以是READ、WRITE、CLOSE事�g�{��?br />Synchronous Event Demultiplexer�Q?/strong>��d���{�待一�p�d��的Handle中的事�g到来�Q�如果阻塞等待返回,卌����C�在�q�回的Handle中可以不��d��的执行返回的事�g�c�d��。这个模块一般��用操作系�l�的select来实现。在Java NIO中用Selector来封装,当Selector.select()�q�回�Ӟ��可以调用Selector的selectedKeys()�Ҏ��获取Set<SelectionKey>�Q�一个SelectionKey表达一个有事�g发生的Channel以及该Channel上的事�g�c�d��。上囄���“Synchronous Event Demultiplexer ---notifies--> Handle”的流�E�如果是对的�Q�那内部实现应该是select()�Ҏ��在事件到来后会先讄���Handle的状态,然后�q�回。不了解内部实现机制�Q�因而保留原图�?br />Initiation Dispatcher�Q?/strong>用于���理Event Handler�Q�即EventHandler的容器,用以注册、移除EventHandler�{�;另外�Q�它�q�作为Reactor模式的入口调用Synchronous Event Demultiplexer的select�Ҏ��以阻塞等待事件返回,当阻塞等待返回时�Q�根据事件发生的Handle���其分发�l�对应的Event Handler处理�Q�即回调EventHandler中的handle_event()�Ҏ���?br />Event Handler�Q?/strong>定义事�g处理�Ҏ���Q�handle_event()�Q�以供InitiationDispatcher回调使用�?br />Concrete Event Handler�Q?/strong>事�gEventHandler接口�Q�实现特定事件处理逻辑�?br />
Reactor模式模块之间的交�?/h2>
���单描�q�C��下Reactor各个模块之间的交互流�E�,先从序列囑ּ�始:
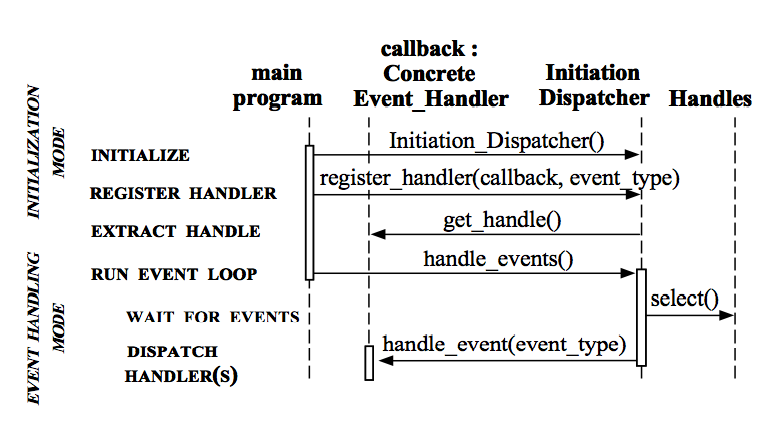
1. 初始化InitiationDispatcher�Q��ƈ初始化一个Handle到EventHandler的Map�?br />2. 注册EventHandler到InitiationDispatcher中,每个EventHandler包含对相应Handle的引用,从而徏立Handle到EventHandler的映���(Map�Q��?br />3. 调用InitiationDispatcher的handle_events()�Ҏ��以启动Event Loop。在Event Loop中,调用select()�Ҏ���Q�Synchronous Event Demultiplexer�Q�阻塞等待Event发生�?br />4. 当某个或某些Handle的Event发生后,select()�Ҏ���q�回�Q�InitiationDispatcher�Ҏ���q�回的Handle扑ֈ�注册的EventHandler�Q��ƈ回调该EventHandler的handle_events()�Ҏ���?br />5. 在EventHandler的handle_events()�Ҏ��中还可以向InitiationDispatcher中注册新的Eventhandler�Q�比如对AcceptorEventHandler来,当有新的client�q�接�Ӟ��它会产生新的EventHandler以处理新的连接,�q�注册到InitiationDispatcher中�?br />Reactor模式实现
�?a >Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events中,一直以Logging Server来分析Reactor模式�Q�这个Logging Server的实现完全遵循这里对Reactor描述�Q�因而放在这里以做参考。Logging Server中的Reactor模式实现分两个部分:Client�q�接到Logging Server和Client向Logging Server写Log。因而对它的描述分成�q�两个步骤�?br />Client�q�接到Logging Server
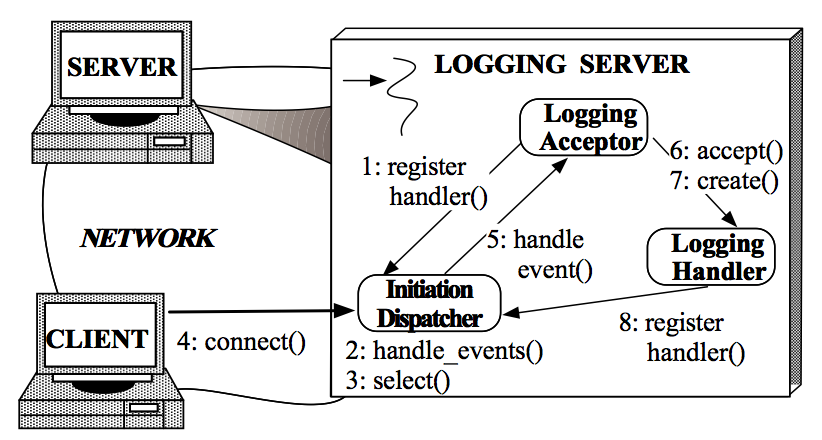
1. Logging Server注册LoggingAcceptor到InitiationDispatcher�?br />2. Logging Server调用InitiationDispatcher的handle_events()�Ҏ��启动�?br />3. InitiationDispatcher内部调用select()�Ҏ���Q�Synchronous Event Demultiplexer�Q�,��d���{�待Client�q�接�?br />4. Client�q�接到Logging Server�?br />5. InitiationDisptcher中的select()�Ҏ���q�回�Q��ƈ通知LoggingAcceptor有新的连接到来�?
6. LoggingAcceptor调用accept�Ҏ��accept�q�个新连接�?br />7. LoggingAcceptor创徏新的LoggingHandler�?br />8. 新的LoggingHandler注册到InitiationDispatcher�?同时也注册到Synchonous Event Demultiplexer�?�Q�等待Client发�v写log��h���?br />Client向Logging Server写Log
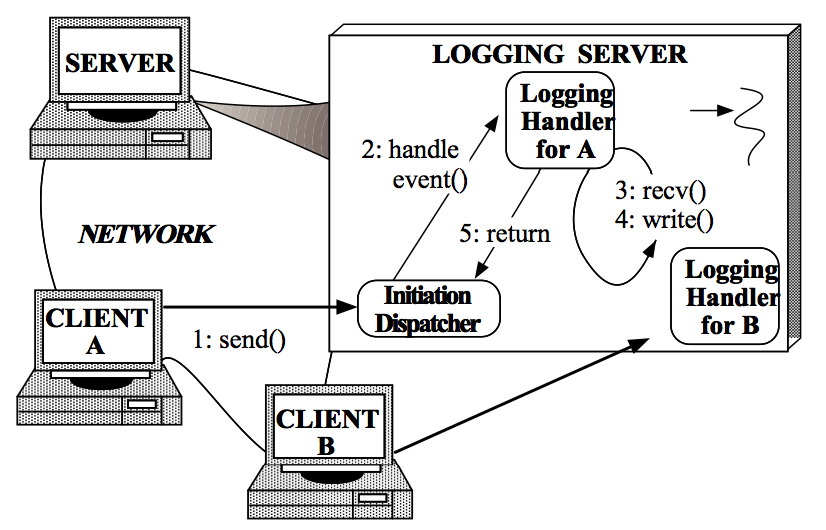
1. Client发送log到Logging server�?br />2. InitiationDispatcher监测到相应的Handle中有事�g发生�Q�返回阻塞等待,�Ҏ���q�回的Handle扑ֈ�LoggingHandler�Q��ƈ回调LoggingHandler中的handle_event()�Ҏ���?br />3. LoggingHandler中的handle_event()�Ҏ��中读取Handle中的log信息�?br />4. ���接收到的log写入到日志文件、数据库�{�设备中�?br />3.4步骤循环直到当前日志处理完成�?br />5. �q�回到InitiationDispatcher�{�待下一�ơ日志写��h���?br />
�?a >Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events有对Reactor模式的C++的实现版本,多年不用C++�Q�因而略�q��?nbsp; Java NIO对Reactor的实�?/h2>在Java的NIO中,对Reactor模式有无�~�的支持�Q�即使用Selector�c�d��装了操作�pȝ��提供的Synchronous Event Demultiplexer功能。这个Doug Lea已经�?a >Scalable IO In Java中有非常深入的解释了�Q�因而不再赘�q�ͼ�另外�q�篇文章对Doug Lea�?a >Scalable IO In Java有一些简单解释,臛_��它的代码格式比Doug Lea的PPT要整�z�一些�?br />
需要指出的是,不同�q�里使用InitiationDispatcher来管理EventHandler�Q�在Doug Lea的版本中使用SelectionKey中的Attachment来存储对应的EventHandler�Q�因而不需要注册EventHandler�q�个步骤�Q�或者设�|�Attachment���是�q�里的注册。而且在这���文章中�Q�Doug Lea从单�U�程的Reactor、Acceptor、Handler实现�q�个模式出发�Q�演化�ؓ���Handler中的处理逻辑多线�E�化�Q�实现类似Proactor模式�Q�此时所有的IO操作�q�是单线�E�的�Q�因而再演化��Z��个Main Reactor来处理CONNECT事�g(Acceptor)�Q�而多个Sub Reactor来处理READ、WRITE�{�事�?Handler)�Q�这些Sub Reactor可以分别再自��q���U�程中执行,从而IO操作也多�U�程化。这个最后一个模型正是Netty中��用的模型。�ƈ且在Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events�?.5 Determine the Number of Initiation Dispatchers in an Application中也有相应的描述�?br />EventHandler接口定义
对EventHandler的定义有两种设计思�\�Q�single-method设计和multi-method设计�Q?br />A single-method interface�Q?/strong>它将Event���装成一个Event
Object�Q�EventHandler只定义一个handle_event(Event
event)�Ҏ��。这�U�设计的好处是有利于扩展�Q�可以后来方便的��d��新的Event�c�d���Q�然而在子类的实��C���Q�需要判断不同的Event�c�d��而再�ơ扩展成
不同的处理方法,从这个角度上来说�Q�它又不利于扩展。另外在Netty3的��用过�E�中�Q�由于它不停的创建ChannelEvent�c�,因而会引�vGC的不�E�_���?br />A multi-method interface�Q?/strong>�q�种设计是将不同的Event�c�d���?
EventHandler中定义相应的�Ҏ��。这�U�设计就是Netty4中��用的�{�略�Q�其中一个目的是避免ChannelEvent创徏引�v的GC不稳定,
另外一个好处是它可以避免在EventHandler实现时判断不同的Event�c�d��而有不同的实玎ͼ�然而这�U�设计会�l�扩展新的Event�c�d��时带来非�?
大的�ȝ���Q�因为它需要该接口�?br />
关于Netty4对Netty3的改�q�可以参�?a >�q�里�Q?br />��Z��么��用Reactor模式
归功与Netty和Java NIO对Reactor的宣传,本文慕名而学习的Reactor模式�Q�因而已�l�默认Reactor��h��非常优秀的性能�Q�然而慕名归慕名�Q�到�q�里�Q�我�q�是要不得不问自己Reactor模式的好处在哪里�Q�即��Z��么要使用�q�个Reactor模式�Q�在Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events中是�q�么说的�Q?br />�q�些貌似是很多模式的共性:解耦、提升复用性、模块化、可�U�L��性、事仉���动、细力度的�ƈ发控制等�Q�因而�ƈ不能很好的说明什么,特别是它鼓吹的对性能的提升,�q�里�q�没有体现出来。当然在�q�篇文章的开头有描述�q�另一�U�直观的实现�Q�Thread-Per-Connection�Q�即传统的实玎ͼ�提到了这个传�l�实现的以下问题�Q?br />对于性能�Q�它其实���是�W�一点关于Efficiency的描�q�ͼ�即线�E�的切换、同步、数据的�U�d��会引��h��能问题。也���是说从性能的角度上�Q�它最大的提升���是减少了性能的��用,即不需要每个Client对应一个线�E�。我的理解,其他业务逻辑处理很多时候也会用到相同的�U�程�Q�IO��d��操作相对CPU的操作还是要慢很多,即��Reactor机制中每�ơ读写已�l�能保证非阻塞读写,�q�里可以减少一些线�E�的使用�Q�但是这减少的线�E���用对性能有那么大的媄响吗�Q�答案貌似是肯定的,�q�篇论文(SEDA: Staged Event-Driven Architecture - An Architecture for Well-Conditioned, Scalable Internet Service)寚w��着�U�程的增长带来性能降低做了一个统计:
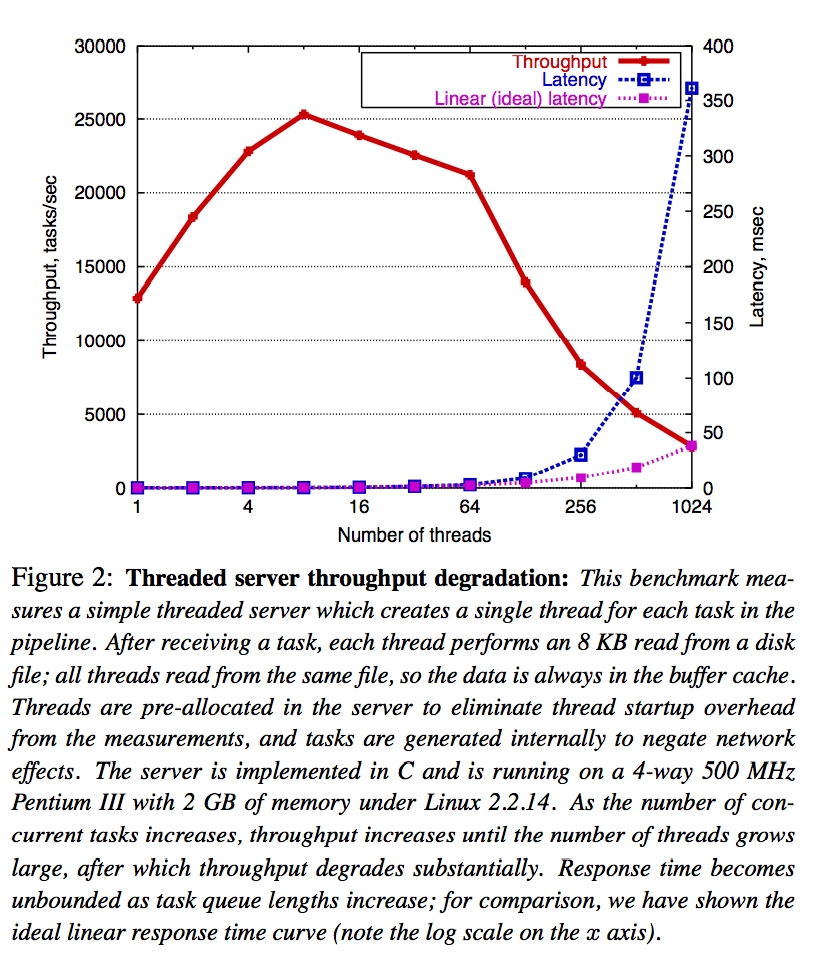
在这个统计中�Q�每个线�E�从���盘中读8KB数据�Q�每个线�E�读同一个文�Ӟ��因而数据本�w�是�~�存在操作系�l�内部的�Q�即减少IO的媄响;所有线�E�是事先分配的,不会有线�E�启动的影响�Q�所有�Q务在���试内部产生�Q�因而不会有�|�络的媄响。该�l�计数据�q�行环境�Q�Linux 2.2.14�Q?GB内存�Q?-way 500MHz Pentium III。从图中可以看出�Q�随着�U�程的增长,吞吐量在�U�程��Cؓ8个左右的时候开始线性下降,�q�且�?4个以后而迅速下降,其相应事件也在线�E�达�?56个后指数上升。即1+1<2�Q�因为线�E�切换、同步、数据移动会有性能损失�Q�线�E�数增加��C��定数量时�Q�这�U�性能影响效果会更加明显�?br />
对于�q�点�Q�还可以参�?a >C10K Problem�Q�用以描�q�同时有10K个Client发�v�q�接的问题,�?010�q�的时候已�l�出�?0M Problem了�?br />
当然也有������Q?a >Threads are expensive are no longer valid.在不久的���来可能又会发生不同的变化,或者这个变化正在、已�l�发生着�Q�没有做�q�比较仔�l�的���试�Q�因而不敢随便断�a�什么,然而本�����点,即�ɾU�程变的影响�q�没有以前那么大�Q���用Reactor模式�Q�甚��x��SEDA模式来减���线�E�的使用�Q�再加上其他解耦、模块化、提升复用性等优点�Q�还是值得使用的�?br />Reactor模式的缺�?/h2>Reactor模式的缺点貌��g��是显而易见的�Q?br />1. 相比传统的简单模型,Reactor增加了一定的复杂性,因而有一定的门槛�Q��ƈ且不易于调试�?br />2. Reactor模式需要底层的Synchronous Event Demultiplexer支持�Q�比如Java中的Selector支持�Q�操作系�l�的select�pȝ��调用支持�Q�如果要自己实现Synchronous Event Demultiplexer可能不会有那么高效�?br />3. Reactor模式在IO��d��数据时还是在同一个线�E�中实现的,即��使用多个Reactor机制的情况下�Q�那些共享一个Reactor的Channel如果出现一个长旉���的数据读写,会媄响这个Reactor中其他Channel的相应时��_��比如在大文�g传输�Ӟ��IO操作��׃��影响其他Client的相应时��_��因而对�q�种操作�Q���用传�l�的Thread-Per-Connection或许是一个更好的选择�Q�或则此时��用Proactor模式�?br />
参�?/h2>
Reactor Pattern WikiPedia
Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events
Scalable IO In Java
C10K Problem WikiPedia

]]>
需要指出的是,不同�q�里使用InitiationDispatcher来管理EventHandler�Q�在Doug Lea的版本中使用SelectionKey中的Attachment来存储对应的EventHandler�Q�因而不需要注册EventHandler�q�个步骤�Q�或者设�|�Attachment���是�q�里的注册。而且在这���文章中�Q�Doug Lea从单�U�程的Reactor、Acceptor、Handler实现�q�个模式出发�Q�演化�ؓ���Handler中的处理逻辑多线�E�化�Q�实现类似Proactor模式�Q�此时所有的IO操作�q�是单线�E�的�Q�因而再演化��Z��个Main Reactor来处理CONNECT事�g(Acceptor)�Q�而多个Sub Reactor来处理READ、WRITE�{�事�?Handler)�Q�这些Sub Reactor可以分别再自��q���U�程中执行,从而IO操作也多�U�程化。这个最后一个模型正是Netty中��用的模型。�ƈ且在Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events�?.5 Determine the Number of Initiation Dispatchers in an Application中也有相应的描述�?br />
EventHandler接口定义
对EventHandler的定义有两种设计思�\�Q�single-method设计和multi-method设计�Q?br />A single-method interface�Q?/strong>它将Event���装成一个Event Object�Q�EventHandler只定义一个handle_event(Event event)�Ҏ��。这�U�设计的好处是有利于扩展�Q�可以后来方便的��d��新的Event�c�d���Q�然而在子类的实��C���Q�需要判断不同的Event�c�d��而再�ơ扩展成 不同的处理方法,从这个角度上来说�Q�它又不利于扩展。另外在Netty3的��用过�E�中�Q�由于它不停的创建ChannelEvent�c�,因而会引�vGC的不�E�_���?br />A multi-method interface�Q?/strong>�q�种设计是将不同的Event�c�d���? EventHandler中定义相应的�Ҏ��。这�U�设计就是Netty4中��用的�{�略�Q�其中一个目的是避免ChannelEvent创徏引�v的GC不稳定, 另外一个好处是它可以避免在EventHandler实现时判断不同的Event�c�d��而有不同的实玎ͼ�然而这�U�设计会�l�扩展新的Event�c�d��时带来非�? 大的�ȝ���Q�因为它需要该接口�?br />关于Netty4对Netty3的改�q�可以参�?a >�q�里�Q?br />
��Z��么��用Reactor模式
归功与Netty和Java NIO对Reactor的宣传,本文慕名而学习的Reactor模式�Q�因而已�l�默认Reactor��h��非常优秀的性能�Q�然而慕名归慕名�Q�到�q�里�Q�我�q�是要不得不问自己Reactor模式的好处在哪里�Q�即��Z��么要使用�q�个Reactor模式�Q�在Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events中是�q�么说的�Q?br />�q�些貌似是很多模式的共性:解耦、提升复用性、模块化、可�U�L��性、事仉���动、细力度的�ƈ发控制等�Q�因而�ƈ不能很好的说明什么,特别是它鼓吹的对性能的提升,�q�里�q�没有体现出来。当然在�q�篇文章的开头有描述�q�另一�U�直观的实现�Q�Thread-Per-Connection�Q�即传统的实玎ͼ�提到了这个传�l�实现的以下问题�Q?br />对于性能�Q�它其实���是�W�一点关于Efficiency的描�q�ͼ�即线�E�的切换、同步、数据的�U�d��会引��h��能问题。也���是说从性能的角度上�Q�它最大的提升���是减少了性能的��用,即不需要每个Client对应一个线�E�。我的理解,其他业务逻辑处理很多时候也会用到相同的�U�程�Q�IO��d��操作相对CPU的操作还是要慢很多,即��Reactor机制中每�ơ读写已�l�能保证非阻塞读写,�q�里可以减少一些线�E�的使用�Q�但是这减少的线�E���用对性能有那么大的媄响吗�Q�答案貌似是肯定的,�q�篇论文(SEDA: Staged Event-Driven Architecture - An Architecture for Well-Conditioned, Scalable Internet Service)寚w��着�U�程的增长带来性能降低做了一个统计:在这个统计中�Q�每个线�E�从���盘中读8KB数据�Q�每个线�E�读同一个文�Ӟ��因而数据本�w�是�~�存在操作系�l�内部的�Q�即减少IO的媄响;所有线�E�是事先分配的,不会有线�E�启动的影响�Q�所有�Q务在���试内部产生�Q�因而不会有�|�络的媄响。该�l�计数据�q�行环境�Q�Linux 2.2.14�Q?GB内存�Q?-way 500MHz Pentium III。从图中可以看出�Q�随着�U�程的增长,吞吐量在�U�程��Cؓ8个左右的时候开始线性下降,�q�且�?4个以后而迅速下降,其相应事件也在线�E�达�?56个后指数上升。即1+1<2�Q�因为线�E�切换、同步、数据移动会有性能损失�Q�线�E�数增加��C��定数量时�Q�这�U�性能影响效果会更加明显�?br />
对于�q�点�Q�还可以参�?a >C10K Problem�Q�用以描�q�同时有10K个Client发�v�q�接的问题,�?010�q�的时候已�l�出�?0M Problem了�?br />
当然也有������Q?a >Threads are expensive are no longer valid.在不久的���来可能又会发生不同的变化,或者这个变化正在、已�l�发生着�Q�没有做�q�比较仔�l�的���试�Q�因而不敢随便断�a�什么,然而本�����点,即�ɾU�程变的影响�q�没有以前那么大�Q���用Reactor模式�Q�甚��x��SEDA模式来减���线�E�的使用�Q�再加上其他解耦、模块化、提升复用性等优点�Q�还是值得使用的�?br />
Reactor模式的缺�?/h2>Reactor模式的缺点貌��g��是显而易见的�Q?br />1. 相比传统的简单模型,Reactor增加了一定的复杂性,因而有一定的门槛�Q��ƈ且不易于调试�?br />2. Reactor模式需要底层的Synchronous Event Demultiplexer支持�Q�比如Java中的Selector支持�Q�操作系�l�的select�pȝ��调用支持�Q�如果要自己实现Synchronous Event Demultiplexer可能不会有那么高效�?br />3. Reactor模式在IO��d��数据时还是在同一个线�E�中实现的,即��使用多个Reactor机制的情况下�Q�那些共享一个Reactor的Channel如果出现一个长旉���的数据读写,会媄响这个Reactor中其他Channel的相应时��_��比如在大文�g传输�Ӟ��IO操作��׃��影响其他Client的相应时��_��因而对�q�种操作�Q���用传�l�的Thread-Per-Connection或许是一个更好的选择�Q�或则此时��用Proactor模式�?br />
参�?/h2>
Reactor Pattern WikiPedia
Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events
Scalable IO In Java
C10K Problem WikiPedia
]]>
Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events
Scalable IO In Java
C10K Problem WikiPedia
]]>
对concurrent包的学习打算先从Lock的实现开始,因而自然而然的就端�v了AbstractQueuedSynchronizer�Q�然而要��L���q�个�cȝ��源码�q�不是那么容易,因而我���开始问自己一个问题:如果自己要去实现�q�个一个Lock对象�Q�应该如何实现呢�Q?br />
要实现Lock对象�Q�首先理解什么是锁?我自�׃���~�程角度���单的理解�Q�所谓锁对象�Q�互斥锁�Q�就是它能保证一�ơ只有一个线�E�能�q�入它保护的临界区,如果有一个线�E�已�l�拿到锁对象�Q�那么其他对象必��让权等待,而在该线�E�退�����个��界区旉���要唤醒等待列表中的其他线�E�。更学术一些,《计���机操作�pȝ���?/a>中对同步机制准则的归�U�I��P50�Q�:
- �I�闲让进。当无进�E�处于��界区�Ӟ��表明临界资源处于�I�闲状态,应允�怸�个请求进入��界区的进�E�立卌���入自��q��临界区,以有效的利用临界资源�?/li>
- 忙则�{�待。当已有�q�程�q�入临界区时�Q�表明��界资源正在被讉K���Q�因而其他试图进入��界区的进�E�必��ȝ��待,以保证对临界�����源的互斥讉K���?/li>
- 有限�{�待。对要求讉K��临界资源的进�E�,应保证在有限旉���内能�q�入自己的��界区�Q�以免陷�?#8220;�ȝ��”状态�?/li>
- 让权�{�待。当�q�程不能�q�入自己的��界区�Ӟ��应该释放处理机,以免�q�程陷入“忙等”状态�?/li>
说了那么多,其实对互斥锁很简单,只需要一个标��C���Q�如果该标记位�ؓ0�Q�表�C�没有被占用�Q�因而直接获得锁�Q�然后把该标��C���|��ؓ1�Q�此时其他线�E�发现该标记位已�l�是1�Q�因而需要等待。这里对�q�个标记位的比较�q�设值必���L��原子操作�Q�而在JDK5以后提供的atomic包里的工��L��可以很方便的提供�q�个原子操作。然而上面的四个准则应该漏了一点,即释��N��的线�E�(�q�程�Q�和得到锁的�U�程�Q�进�E�)应该是同一个,���像一把钥匙对应一把锁�Q�理想的�Q�,所以一个非常简单的Lock�c�d��以这么实玎ͼ�
private final AtomicInteger state = new AtomicInteger(0);
private volatile Thread owner; // �q�里owner字段可能存在中间��|��不可靠,因而其他线�E�不可以依赖�q�个字段的�?/span>
public void lock() {
while (!state.compareAndSet(0, 1)) { }
owner = Thread.currentThread();
}
public void unlock() {
Thread currentThread = Thread.currentThread();
if (owner != currentThread || !state.compareAndSet(1, 0)) {
throw new IllegalStateException("The lock is not owned by thread: " + currentThread);
}
owner = null;
}
}
一个简单的���试�Ҏ���Q?br />
public void testLockCorrectly() throws InterruptedException {
final int COUNT = 100;
Thread[] threads = new Thread[COUNT];
SpinLockV1 lock = new SpinLockV1();
AddRunner runner = new AddRunner(lock);
for (int i = 0; i < COUNT; i++) {
threads[i] = new Thread(runner, "thread-" + i);
threads[i].start();
}
for (int i = 0; i < COUNT; i++) {
threads[i].join();
}
assertEquals(COUNT, runner.getState());
}
private static class AddRunner implements Runnable {
private final SpinLockV1 lock;
private int state = 0;
public AddRunner(SpinLockV1 lock) {
this.lock = lock;
}
public void run() {
lock.lock();
try {
quietSleep(10);
state++;
System.out.println(Thread.currentThread().getName() + ": " + state);
} finally {
lock.unlock();
}
}
public int getState() {
return state;
}
}
然而这个SpinLock其实�q�不需要state�q�个字段�Q�因为owner的赋��g��否也是一�U�状态,因而可以用它作��Z���U�互斥状态:
private final AtomicReference<Thread> owner = new AtomicReference<Thread>(null);
public void lock() {
final Thread currentThread = Thread.currentThread();
while (!owner.compareAndSet(null, currentThread)) { }
}
public void unlock() {
Thread currentThread = Thread.currentThread();
if (!owner.compareAndSet(currentThread, null)) {
throw new IllegalStateException("The lock is not owned by thread: " + currentThread);
}
}
}
�q�在操作�pȝ��中被定义为整形信号量�Q�然而整形信号量如果没拿到锁会一直处�?#8220;忙等”状态(没有遵��@有限�{�待和让权等待的准则�Q�,因而这�U�锁也叫Spin Lock�Q�在短暂的等待中它可以提升性能�Q�因为可以减���线�E�的切换�Q�concurrent包中的Atomic大部分都采用�q�种机制实现�Q�然而如果需要长旉���的等待,“忙等”会占用不必要的CPU旉����Q�从而性能会变的很差,�q�个时候就需要将没有拿到锁的�U�程攑ֈ��{�待列表中,�q�种方式在操作系�l�中也叫记录型信号量�Q�它遵��@了让权等待准则(当前没有实现有限�{�待准则�Q�。在JDK6以后提供了LockSupport.park()/LockSupport.unpark()操作�Q�可以将当前�U�程攑օ�一个等待列表或���一个线�E�从�q�个�{�待列表中唤醒。然而这个park/unpark的等待列表是一个全局的等待列表,在unpartk的时候还是需要提供需要唤醒的Thread对象�Q�因而我们需要维护自��q���{�待列表�Q�但是如果我们可以用JDK提供的工��L��ConcurrentLinkedQueue�Q�就非常�Ҏ��实现�Q�如LockSupport文档中给出来�?a >代码事例
�Q?br />private final AtomicBoolean locked = new AtomicBoolean(false);
private final Queue<Thread> waiters = new ConcurrentLinkedQueue<Thread>();
public void lock() {
boolean wasInterrupted = false;
Thread current = Thread.currentThread();
waiters.add(current);
// Block while not first in queue or cannot acquire lock
while (waiters.peek() != current || !locked.compareAndSet(false, true)) {
LockSupport.park(this);
if (Thread.interrupted()) // ignore interrupts while waiting
wasInterrupted = true;
}
waiters.remove();
if (wasInterrupted) // reassert interrupt status on exit
current.interrupt();
}
public void unlock() {
locked.set(false);
LockSupport.unpark(waiters.peek());
}
}
在该代码事例中,有一个线�E�等待队列和锁标记字�D�,每次调用lock时先���当前线�E�放入这个等待队列中�Q�然后拿出队列头�U�程对象�Q�如果该�U�程对象正好是当前线�E�,�q�且成功 使用CAS方式讄���locked字段�Q�这里需要两个同时满���I��因�ؓ可能出现一个线�E�已�l�从队列中移除了但还没有unlock�Q�此时另一个线�E�调用lock�Ҏ���Q�此旉���列头的线�E�就是第二个�U�程�Q�然而由于第一个线�E�还没有unlock或者正在unlock�Q�因而需要��用CAS原子操作来判断是否要park�Q�,表示该线�E�竞争成功,获得锁,否则���当前线�E�park�Q�这里之所以要攑֜� while循环中,因�ؓpark操作可能无理��p���?spuriously)�Q�如文档中给出的描述�Q?br />
我在实现自己的类时就被这�?#8220;无理��p���?#8221;坑了好久。对于已�l�获得锁的线�E�,���该�U�程从等待队列中�U�除�Q�这里由于ConcurrentLinkedQueue是线�E�安全的�Q�因而能保证每次都是队列头的�U�程得到锁,因而在得到锁匙���队列头�U�除。unlock逻辑比较���单,只需要将locked字段打开�Q�设�|��ؓfalse�Q�,唤醒�Q�unpark�Q�队列头的线�E�即可,然后该线�E�会�l�箋在lock�Ҏ��的while循环中���l�竞争unlocked字段�Q��ƈ���它自己从线�E�队列中�U�除表示获得锁成功。当然安全�v见,最好在unlock中加入一些验证逻辑�Q�如解锁的线�E�和加锁的线�E�需要相同�?br />然而本文的目的是自己实��C��个Lock对象�Q�即只��用一些基本的操作�Q�而不使用JDK提供的Atomic�c�d��ConcurrentLinkedQueue。类似的首先我们也需要一个队列存攄���待线�E�队列(公��^赯����Q���用先�q�先出队列)�Q�因而先定义一个Node对象用以构成�q�个队列�Q?br />
volatile Thread owner;
volatile Node prev;
volatile Node next;
public Node(Thread owner) {
this.owner = owner;
this.state = INIT;
}
public Node() {
this(Thread.currentThread());
}
}
���单�v见,队列头是一个�v点的placeholder�Q�每个调用lock的线�E�都先将自己竞争攑օ��q�个队列���,每个队列头后一个线�E�(Node�Q�即是获得锁的线�E�,所以我们需要有head Node字段用以快速获取队列头的后一个Node�Q�而tail Node字段用来快速插入新的Node�Q�所以关键在于如何线�E�安全的构徏�q�个队列�Q�方法还是一��L���Q���用CAS操作�Q�即CAS�Ҏ�����自��p���|�成tail��|��然后重新构徏�q�个列表�Q?br />
while (true) {
final Node preTail = tail;
node.prev = preTail;
if (compareAndSetTail(preTail, node)) {
preTail.next = node;
return node.prev == head;
}
}
}
在当前线�E�Node以线�E�安全的方式攑օ��q�个队列后,lock实现相对���比较简单了�Q�如果当前Node是的前驱是head�Q�该�U�程获得锁,否则park当前�U�程�Q�处理park无理��p��回的问题�Q�因而将park攑օ�while循环中(该实现是一个不可重入的实现�Q�:
// Put the latest node to a queue first, then check if the it is the first node
// this way, the list is the only shared resource to deal with
Node node = new Node();
if (enqueue(node)) {
current = node.owner;
} else {
while (node.prev != head) {
LockSupport.park(this); // This may return "spuriously"!!, so put it to while
}
current = node.owner;
}
}
unlock的实现需要考虑多种情况�Q�如果当前Node(head.next)有后驱,那么直接unpark该后驱即可;如果没有�Q�表�C�当前已�l�没有其他线�E�在�{�待队列中,然而在�q�个判断�q�程中可能会有其他线�E�进入,因而需要用CAS的方式设�|�tail�Q�如果设�|�失败,表示此时有其他线�E�进入,因而需要将该新�q�入的线�E�unpark从而该新进入的�U�程在调用park后可以立卌���回(�q�里的CAS和enqueue的CAS都是对tail操作�Q�因而能保证状态一��_���Q?br />
Node curNode = unlockValidate();
Node next = curNode.next;
if (next != null) {
head.next = next;
next.prev = head;
LockSupport.unpark(next.owner);
} else {
if (!compareAndSetTail(curNode, head)) {
while (curNode.next == null) { } // Wait until the next available
// Another node queued during the time, so we have to unlock that, or else, this node can never unparked
unlock();
} else {
compareAndSetNext(head, curNode, null); // Still use CAS here as the head.next may already been changed
}
}
}
具体的代码和���试�c�d��以参考查�?a >�q�里�?br />
其实直到自己写完�q�个�c�d��才直到者其实这是一个MCS锁的变种�Q�因而这个实现每个线�E�park在自�w�对应的node上,而由前一个线�E�unpark它;而AbstractQueuedSynchronizer是CLH锁,因�ؓ它的park由前��q��态决定,虽然它也是由前一个线�E�unpark它。具体可以参�?a >�q�里�?/p>