Java WeakHashMap 到底Weak在哪里,它真的很弱吗�Q?em>WeakHashMap 的适用场景是什么,使用旉���要注意些什么?弱引用和强引用对Java GC有什么不同媄响?本文���给出清晰而简�z�的介绍�?/p>
��M��介绍
在Java集合框架�p�d��文章的最后,�W�者打���介�l�一个特�D�的成员�Q?em>WeakHashMap�Q�从名字可以看出它是某种 Map。它的特�D�之处在�?WeakHashMap 里的entry可能会被GC自动删除�Q�即使程序员没有调用remove()或�?code>clear()�Ҏ���?/p>
更直观的��_��当���?WeakHashMap �Ӟ��即��没有昄���的添加或删除��M��元素�Q�也可能发生如下情况�Q?/p>
- 调用两次
size()�Ҏ���q�回不同的��|��- 两次调用
isEmpty()�Ҏ���Q�第一�ơ返�?code>false�Q�第二次�q�回true�Q?/li>- 两次调用
containsKey()�Ҏ���Q�第一�ơ返�?code>true�Q�第二次�q�回false�Q�尽���两�ơ��用的是同一�?code>key�Q?/li>- 两次调用
get()�Ҏ���Q�第一�ơ返回一�?code>value�Q�第二次�q�回null�Q�尽���两�ơ��用的是同一个对象�?/li>
遇到�q�么奇葩的现象,你是不是觉得使用者一定会疯掉�Q�其实不�Ӟ��WeekHashMap 的这个特点特别适用于需要缓存的场景。在�~�存场景下,�׃��内存是有限的�Q�不能缓存所有对象;对象�~�存命中可以提高�pȝ��效率�Q�但�~�存MISS也不会造成错误�Q�因为可以通过计算重新得到�?/p>
要明�?WeekHashMap 的工作原理,�q�需要引入一个概念:弱引用(WeakReference�Q?/strong>。我们都知道Java中内存是通过GC自动���理的,GC会在�E�序�q�行�q�程中自动判断哪些对象是可以被回收的�Q��ƈ在合适的时机�q�行内存释放。GC判断某个对象是否可被回收的依据是�Q?strong>是否有有效的引用指向该对�?/strong>。如果没有有效引用指向该对象�Q�基本意味着不存在访问该对象的方式)�Q�那么该对象���是可回收的。这里的“有效引用”�q�不包括弱引�?/strong>。也���是��_��虽然弱引用可以用来访问对象,但进行垃圑֛�收时弱引用�ƈ不会被考虑在内�Q�仅有弱引用指向的对象仍然会被GC回收�?/p> WeakHashMap 内部是通过弱引用来���理 关于强引用,弱引用等概念以后再具体讲解,�q�里只需要知道Java中引用也是分�U�类的,�q�且不同�U�类的引用对GC的媄响不同就够了�?/p> WeakHashMap的存储结构类��g��HashMap�Q�读者可自行参考前�?/a>�Q�这里不再赘�q��?/p> 关于强弱引用的管理方式,博主���会另开专题单独讲解�?/p> 如果你看�q�前几篇关于 Map �?Set 的讲解,一定会问:既然�?WeekHashMap�Q�是否有 WeekHashSet 呢?�{�案是没�?( 。不�q�Java Collections工具�cȝ����Z��解决�Ҏ���Q?code>Collections.newSetFromMap(Map<E,Boolean> map)�Ҏ��可以����Q�?Map包装成一�?em>Set。通过如下方式可以快速得��C���?Weak HashSet�Q?br /> 不出你所料, ��x��深入Java集合框架(Java Collections Framework Internals)�p�d��已经全部讲解完毕�Q�希望这几篇���短的博文能够帮助各位读者对Java容器框架建立基本的理解。通过�q�里可以�q�回本系列文章目�?/a>�?/p> 如果对各位有哪怕些微的帮助�Q�博��d��感到非常高兴�Q�如果博文中有�Q何的�U�漏和谬误,�Ƣ迎各位博友指正�?/p>entry的,弱引用的�Ҏ��对应到 WeakHashMap 上意味着什么呢�Q?strong>���一�?code>key, value攑օ��?WeakHashMap 里�ƈ不能避免�?code>key��D��GC回收�Q�除非在 WeakHashMap 之外�q�有对该key的强引用具体实现
Weak HashSet?
Set<Object> weakHashSet = Collections.newSetFromMap(
new WeakHashMap<Object, Boolean>());newSetFromMap()�Ҏ��只是对传入的 Map做了���单包装:
public static <E> Set<E> newSetFromMap(Map<E, Boolean> map) {
return new SetFromMap<>(map);
}
private static class SetFromMap<E> extends AbstractSet<E>
implements Set<E>, Serializable
{
private final Map<E, Boolean> m; // The backing map
private transient Set<E> s; // Its keySet
SetFromMap(Map<E, Boolean> map) {
if (!map.isEmpty())
throw new IllegalArgumentException("Map is non-empty");
m = map;
s = map.keySet();
}
public void clear() { m.clear(); }
public int size() { return m.size(); }
public boolean isEmpty() { return m.isEmpty(); }
public boolean contains(Object o) { return m.containsKey(o); }
public boolean remove(Object o) { return m.remove(o) != null; }
public boolean add(E e) { return m.put(e, Boolean.TRUE) == null; }
public Iterator<E> iterator() { return s.iterator(); }
public Object[] toArray() { return s.toArray(); }
public <T> T[] toArray(T[] a) { return s.toArray(a); }
public String toString() { return s.toString(); }
public int hashCode() { return s.hashCode(); }
public boolean equals(Object o) { return o == this || s.equals(o); }
public boolean containsAll(Collection<?> c) {return s.containsAll(c);}
public boolean removeAll(Collection<?> c) {return s.removeAll(c);}
public boolean retainAll(Collection<?> c) {return s.retainAll(c);}
// addAll is the only inherited implementation

}�l�语
Java LinkedHashMap�?em>HashMap有什么区别和联系�Q��ؓ什�?em>LinkedHashMap会有着更快的�P代速度�Q?em>LinkedHashSet�?em>LinkedHashMap有着怎样的内在联�p�?本文从数据结构和���法层面�Q�结合生动图解�ؓ读者一一解答�?/p>
��M��介绍
如果你已看过前面关于HashSet�?em>HashMap�Q�以�?em>TreeSet�?em>TreeMap的讲解,一定能够想到本文将要讲解的LinkedHashSet�?em>LinkedHashMap其实也是一回事�?em>LinkedHashSet�?em>LinkedHashMap在Java里也有着相同的实玎ͼ�前者仅仅是对后者做了一层包装,也就是说LinkedHashSet里面有一�?em>LinkedHashMap�Q�适配器模式)。因此本文将重点分析LinkedHashMap�?/p>
LinkedHashMap实现�?em>Map接口�Q�即允许攑օ�key�?code>null的元素,也允许插�?code>value�?code>null的元素。从名字上可以看�����容器�?em>linked list�?em>HashMap的�合体�Q�也���是说它同时满��HashMap�?em>linked list的某些特性�?strong>可将LinkedHashMap看作采用linked list增强�?em>HashMap�?/strong>
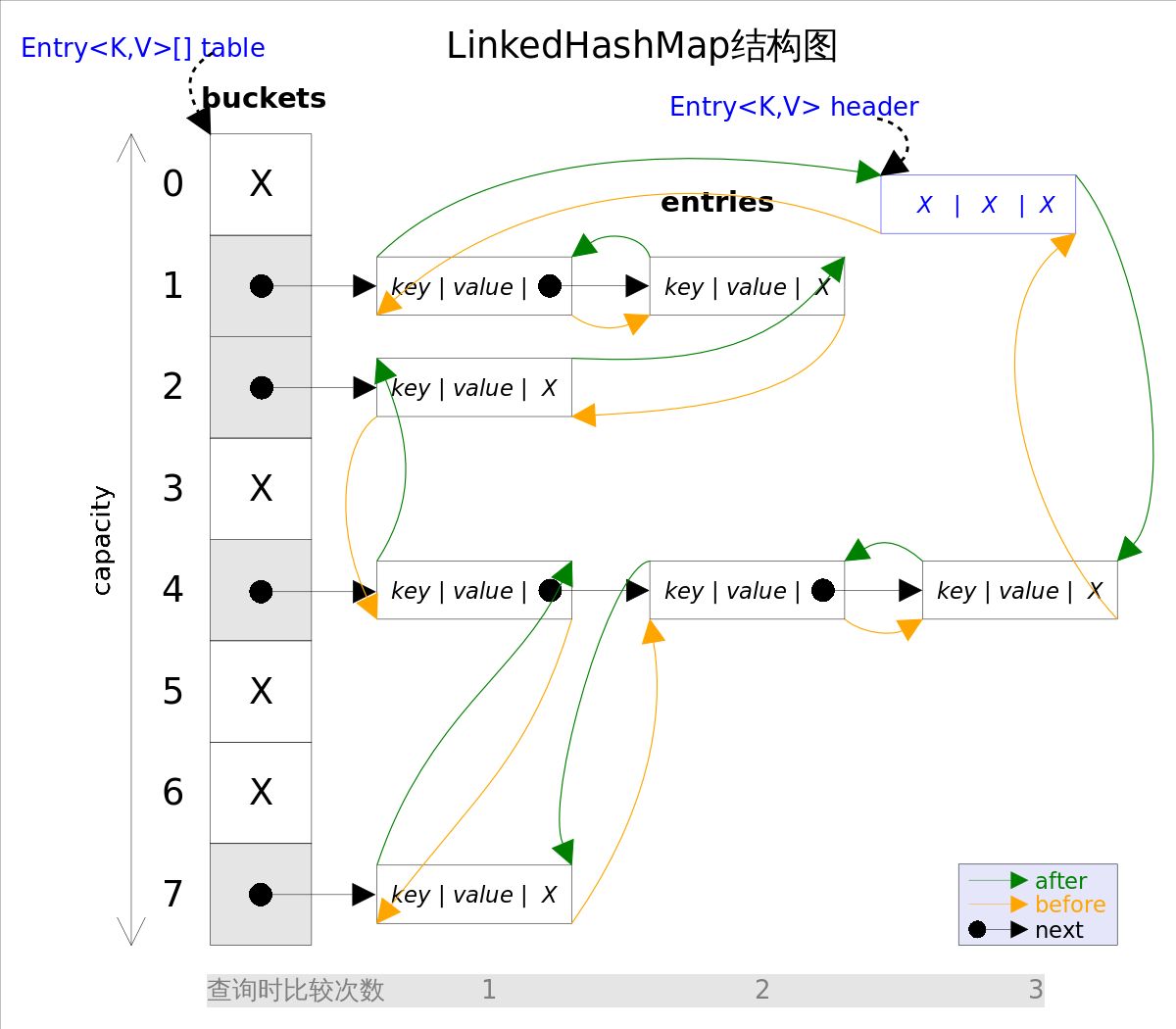
事实�?em>LinkedHashMap�?em>HashMap的直接子�c�,二者唯一的区别是LinkedHashMap�?em>HashMap的基���上,采用双向链表�Q�doubly-linked list�Q�的形式���所�?code>entry�q�接��h���Q�这��h����Z��证元素的�q�代��序跟插入顺序相�?/strong>。上囄�����Z��LinkedHashMap的结构图�Q�主体部分跟HashMap完全一��P��多了 除了可以保�P代历��序�Q�这�U�结构还有一个好处:�q�代LinkedHashMap时不需要像HashMap那样遍历整个 有两个参数可以媄�?em>LinkedHashMap的性能�Q�初始容量(inital capacity�Q�和负蝲�p�L���Q�load factor�Q�。初始容量指定了初始 ���对象放入到LinkedHashMap�?em>LinkedHashSet中时�Q�有两个�Ҏ��需要特别关心: 通过如下方式可以得到一个跟�?em>Map�q�代��序一��L��LinkedHashMap�Q?br /> ��Z��性能原因�Q?em>LinkedHashMap是非同步的(not synchronized�Q�,如果需要在多线�E�环境��用,需要程序员手动同步�Q�或者通过如下方式��?em>LinkedHashMap包装成(wrapped�Q�同步的�Q?/p> 注意�Q�这里的插入有两重含�?/strong>�Q?/p> 上述代码中用��C�� 上述代码只是���单修改相�?code>entry的引用而已�?/p> 注意�Q�这里的删除也有两重含义�Q?/p> 前面已经说过LinkedHashSet是对LinkedHashMap的简单包装,�?em>LinkedHashSet的函数调用都会�{换成合适的LinkedHashMap�Ҏ���Q�因�?em>LinkedHashSet的实现非常简单,�q�里不再赘述�?br />header指向双向链表的头部(是一个哑元)�Q?strong>该双向链表的�q�代��序���是entry的插入顺�?/strong>�?/p>table�Q�而只需要直接遍�?code>header指向的双向链表即�?/strong>�Q�也���是�?em>LinkedHashMap的�P代时间就只跟entry的个数相养I��而跟table的大���无兟�?/p>table的大���,负蝲�p�L��用来指定自动扩容的��界倹{��当entry的数量超�q?code>capacity*load_factor�Ӟ��容器���自动扩容�ƈ重新哈希。对于插入元素较多的场景�Q�将初始定w��讑֤�可以减少重新哈希的次数�?/p>hashCode()�?code>equals()�?strong>hashCode()�Ҏ��军_��了对象会被放到哪�?code>bucket里,当多个对象的哈希值冲�H�时�Q?code>equals()�Ҏ��军_��了这些对象是否是“同一个对�?#8221;hashCode()�?code>equals()�Ҏ���?/p>
Map copy = new LinkedHashMap(m);
}Map m = Collections.synchronizedMap(new LinkedHashMap(...));�Ҏ��剖析
get()
get(Object key)�Ҏ���Ҏ��指定�?code>key��D��回对应的value。该�Ҏ���?code>HashMap.get()�Ҏ��的流�E�几乎完全一��P��读者可自行参考前�?/a>�Q�这里不再赘�q��?/p>put()
put(K key, V value)�Ҏ��是将指定�?code>key, value�Ҏ��加到map里。该�Ҏ��首先会对map做一�ơ查找,看是否包含该元组�Q�如果已�l�包含则直接�q�回�Q�查找过�E�类��g��get()�Ҏ���Q�如果没有找刎ͼ�则会通过addEntry(int hash, K key, V value, int bucketIndex)�Ҏ��插入新的entry�?/p>entry插入到冲�H�链表的头部�?/li>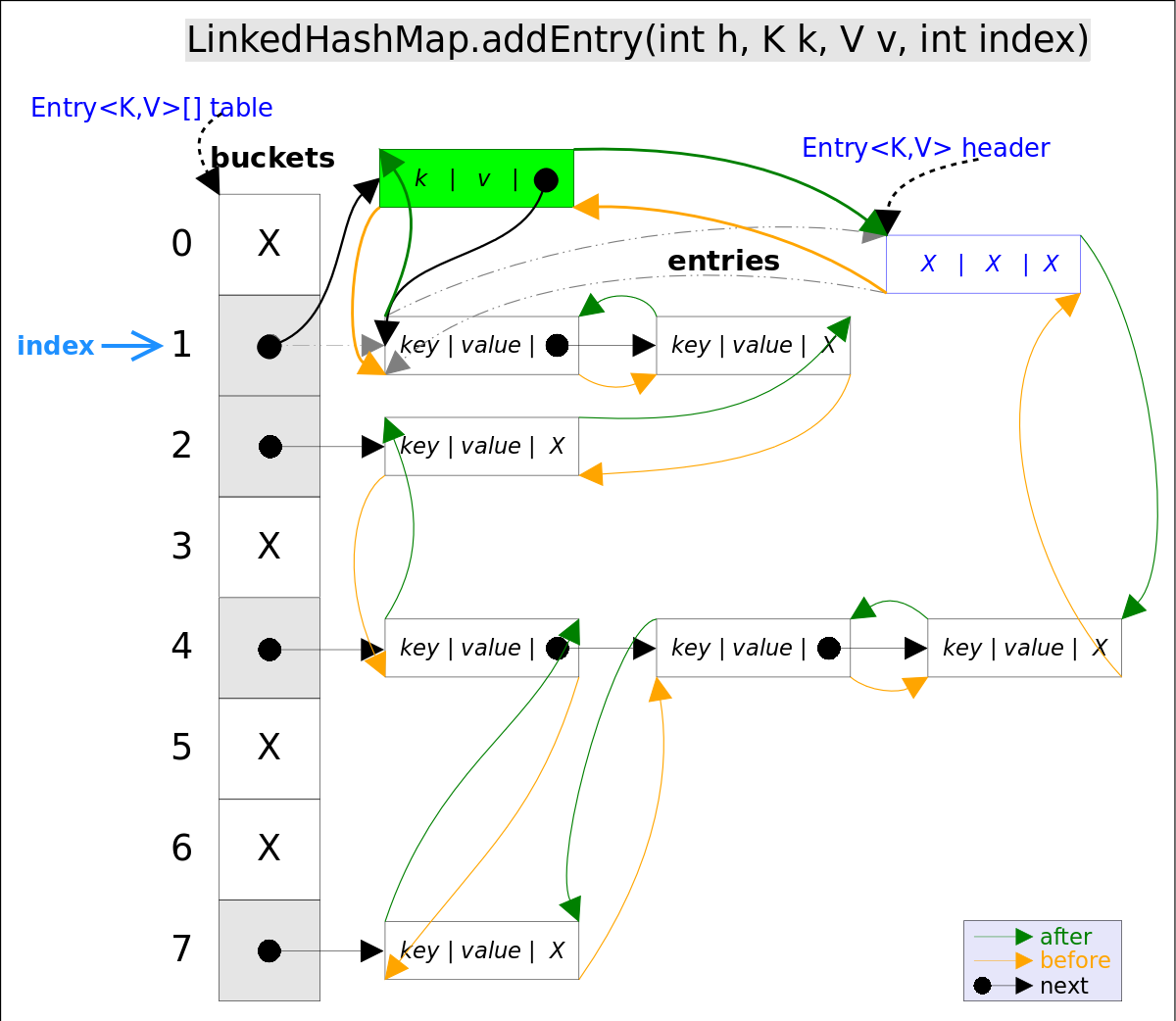
addEntry()代码如下�Q?br />
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容�Q��ƈ重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲�H�链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的���N��插入新的entry
e.addBefore(header);
size++;
}addBefore()�Ҏ�����新entry e插入到双向链表头引用header的前面,�q�样e���成为双向链表中的最后一个元素�?code>addBefore()的代码如下:
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}remove()
remove(Object key)的作用是删除key值对应的entry�Q�该�Ҏ��的具体逻辑是在removeEntryForKey(Object key)里实现的�?code>removeEntryForKey()�Ҏ��会首先找�?code>key值对应的entry�Q�然后删除该entry�Q�修攚w��表的相应引用�Q�。查找过�E�跟get()�Ҏ���c�M���?/p>bucket里删除,如果对应的冲�H�链表不�I�,需要修改冲�H�链表的相应引用�?/li>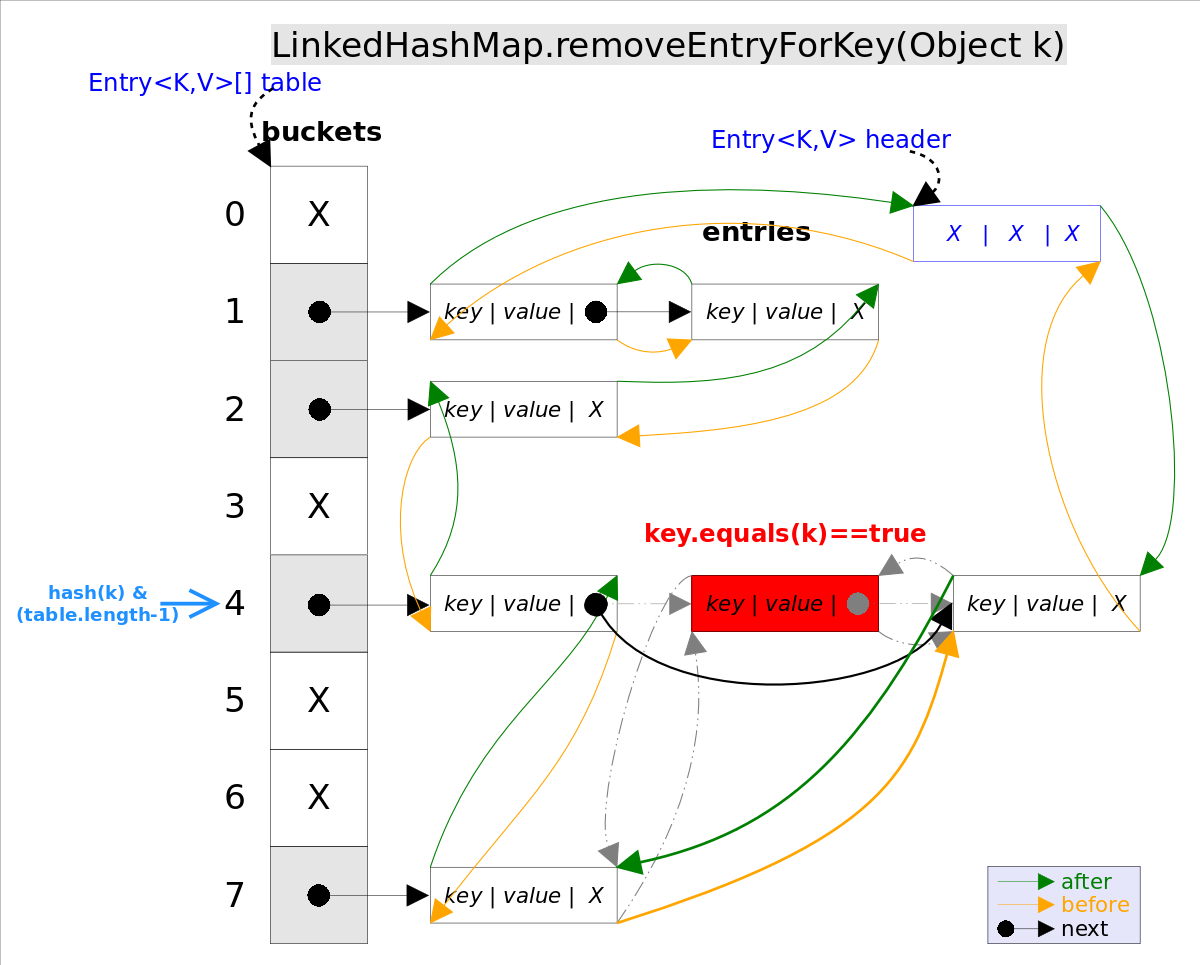
removeEntryForKey()对应的代码如下:
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 扑ֈ�要删除的entry
modCount++; size--;
// 1. ���e从对应bucket的冲�H�链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. ���e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}LinkedHashSet
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public boolean add(E e) {//���单的�Ҏ��转换
return map.put(e, PRESENT)==null;
}
}
ArrayDeque
前言
Java里有一个叫�?em>Stack的类�Q�却没有叫做Queue的类�Q�它是个接口名字�Q�。当需要��用栈�Ӟ��Java已不推荐使用Stack�Q�而是推荐使用更高效的ArrayDeque�Q�既�?em>Queue只是一个接口,当需要��用队列时也就首�?em>ArrayDeque了(�ơ选是LinkedList�Q��?/p>
��M��介绍
要讲栈和队列�Q�首先要�?em>Deque接口�?em>Deque的含义是“double ended queue”�Q�即双端队列�Q�它既可以当作栈使用�Q�也可以当作队列使用。下表列��Z��Deque�?em>Queue相对应的接口�Q?/p>
| Queue Method | Equivalent Deque Method | 说明 |
|---|---|---|
add(e) |
addLast(e) |
向队���插入元素,��p�|则抛出异�?/td> |
offer(e) |
offerLast(e) |
向队���插入元素,��p�|则返�?code>false |
remove() |
removeFirst() |
获取�q�删除队首元素,��p�|则抛出异�?/td> |
poll() |
pollFirst() |
获取�q�删除队首元素,��p�|则返�?code>null |
element() |
getFirst() |
获取但不删除队首元素�Q�失败则抛出异常 |
peek() |
peekFirst() |
获取但不删除队首元素�Q�失败则�q�回null |
下表列出�?em>Deque�?em>Stack对应的接口:
| Stack Method | Equivalent Deque Method | 说明 |
|---|---|---|
push(e) |
addFirst(e) |
向栈��插入元素,��p�|则抛出异�?/td> |
| �?/td> | offerFirst(e) |
向栈��插入元素,��p�|则返�?code>false |
pop() |
removeFirst() |
获取�q�删除栈��元素,��p�|则抛出异�?/td> |
| �?/td> | pollFirst() |
获取�q�删除栈��元素,��p�|则返�?code>null |
peek() |
peekFirst() |
获取但不删除栈顶元素�Q�失败则抛出异常 |
| �?/td> | peekFirst() |
获取但不删除栈顶元素�Q�失败则�q�回null |
上面两个表共定义�?em>Deque�?2个接口。添加,删除�Q�取值都有两套接口,它们功能相同�Q�区别是对失败情�늚�处理不同�?strong>一套接口遇到失败就会抛出异常,另一套遇到失败会�q�回�Ҏ����|��false�?code>null�Q?/strong>。除非某�U�实现对定w��有限�Ӟ��大多数情况下�Q�添加操作是不会��p�|的�?strong>虽然Deque的接口有12个之多,但无非就是对容器的两端进行操作,或添加,或删除,或查�?/strong>。明白了�q�一点讲解�v来就会非常简单�?/p>
ArrayDeque�?em>LinkedList�?em>Deque的两个通用实现�Q�由于官�Ҏ��推荐使用AarryDeque用作栈和队列�Q�加之上一���已�l�讲解过LinkedList�Q�本文将着重讲�?em>ArrayDeque的具体实现�?/p>
从名字可以看�?em>ArrayDeque底层通过数组实现�Q��ؓ了满���_��以同时在数组两端插入或删除元素的需求,该数�l�还必须是��@环的�Q�即循环数组�Q�circular array�Q?/strong>�Q�也���是说数�l�的��M��一炚w��可能被看作�v�Ҏ��者终炏V�?em>ArrayDeque是非�U�程安全的(not thread-safe�Q�,当多个线�E�同时��用的时候,需要程序员手动同步�Q�另外,该容器不允许攑օ� 上图中我们看刎ͼ� 实际需要考虑�Q?.�I�间是否够用�Q�以�?.下标是否���界的问题。上图中�Q�如�?code>head�?code>0之后接着调用 下标���界的处理解册��v来非常简单,null元素�?/p>
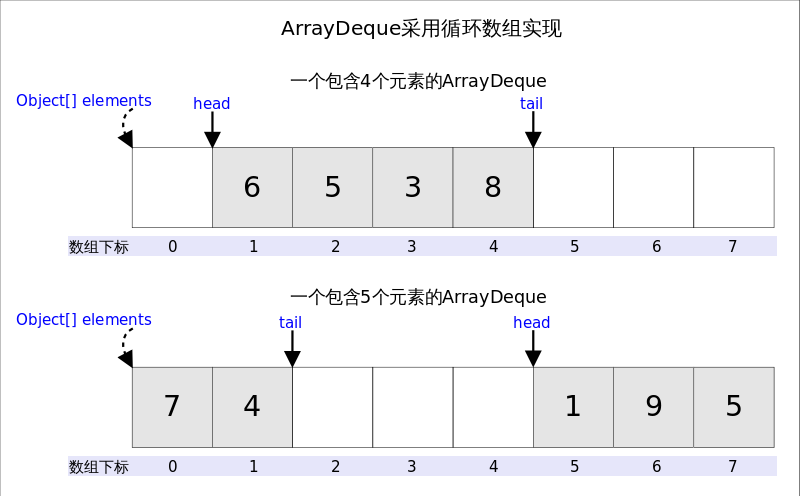
head指向首端�W�一个有效元素,tail指向�������W�一个可以插入元素的�I�Z��。因为是循环数组�Q�所�?code>head不一定�ȝ���?�Q?code>tail也不一定��L���?code>head大�?/p>
�Ҏ��剖析
addFirst()
addFirst(E e)的作用是�?em>Deque的首端插入元素,也就是在head的前面插入元素,在空间��够且下标没有���界的情况下�Q�只需要将elements[--head] = e卛_���?/p>
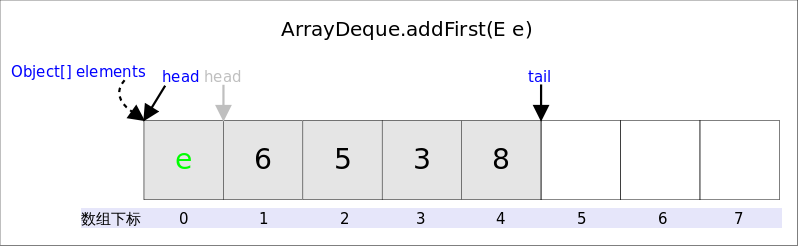
addFirst()�Q�虽然空余空间还够用�Q�但head�?code>-1�Q�下标越界了。下列代码很好的解决了这两个问题�?br />
public void addFirst(E e) {
if (e == null)//不允许放入null
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;//2.下标是否���界
if (head == tail)//1.�I�间是否够用
doubleCapacity();//扩容
}上述代码我们看到�Q?/span>�I�间问题是在插入之后解决�?/strong>�Q�因�?/span>
tail��L��指向下一个可插入的空位,也就意味着elements数组臛_��有一个空位,所以插入元素的时候不用考虑�I�间问题�?/span>head = (head - 1) & (elements.length - 1)���可以了�Q?strong>�q�段代码相当于取余,同时解决�?code>head�����值的情况elements - 1���是二进制低位全1�Q�跟head - 1�怸�之后���p�v��C��取模的作用,如果head - 1�����敎ͼ�其实只可能是-1�Q�,则相当于对其取相对于elements.length的补码�?/p>
下面再说说扩容函�?code>doubleCapacity()�Q�其逻辑是申请一个更大的数组�Q�原数组的两倍)�Q�然后将原数�l�复制过厅R��过�E�如下图所�C�:
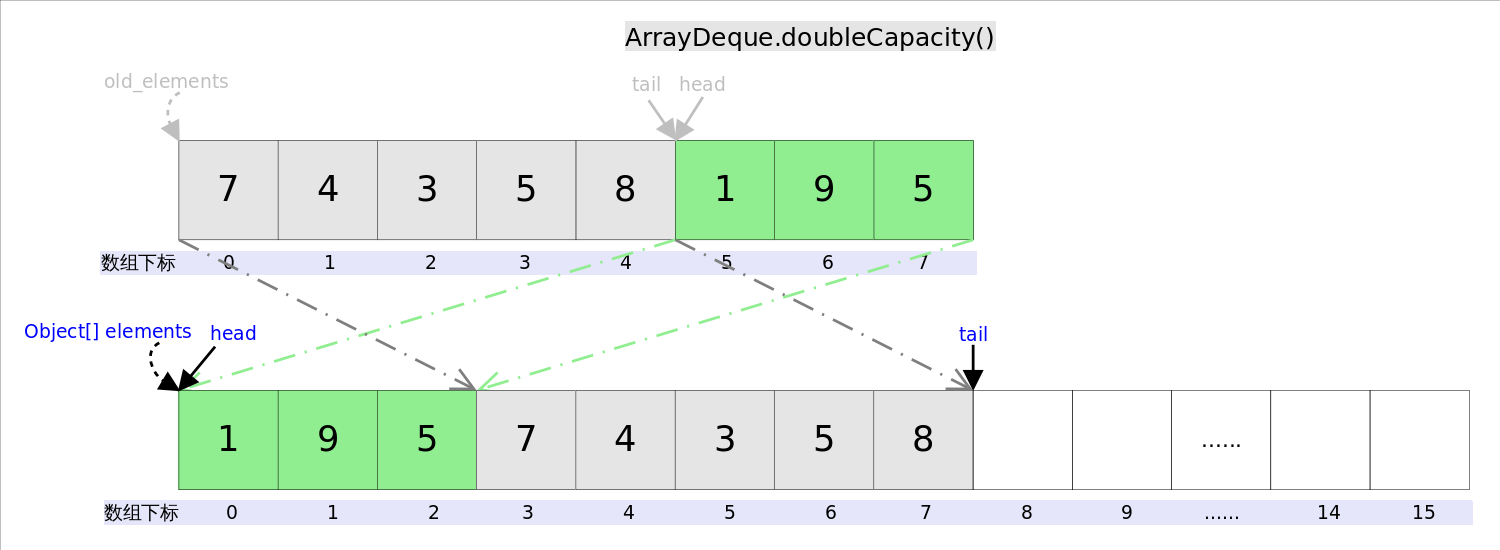
图中我们看到�Q�复制分两次�q�行�Q�第一�ơ复�?code>head双���的元素,�W�二�ơ复�?code>head左边的元素�?br />
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // head双���元素的个�?/span>
int newCapacity = n << 1;//原空间的2�?/span>
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);//复制叛_��部分�Q�对应上图中�l�色部分
System.arraycopy(elements, 0, a, r, p);//复制左半部分�Q�对应上图中灰色部分
elements = (E[])a;
head = 0;
tail = n;
}
addLast()
addLast(E e)的作用是�?em>Deque的尾端插入元素,也就是在tail的位�|�插入元素,�׃��tail��L��指向下一个可以插入的�I�Z���Q�因此只需�?code>elements[tail] = e;卛_��。插入完成后再检查空��_��如果�I�间已经用光�Q�则调用doubleCapacity()�q�行扩容�?/p>

if (e == null)//不允许放入null
throw new NullPointerException();
elements[tail] = e;//赋�?/span>
if ( (tail = (tail + 1) & (elements.length - 1)) == head)//下标���界处理
doubleCapacity();//扩容
}
下标���界处理方式addFirt()中已�l�讲�q�,不再赘述�?/span>
pollFirst()
pollFirst()的作用是删除�q�返�?em>Deque首端元素�Q�也��x��head位置处的元素。如果容器不�I�,只需要直接返�?code>elements[head]卛_���Q�当然还需要处理下标的问题。由�?code>ArrayDeque中不允许攑օ�null�Q�当elements[head] == null�Ӟ��意味着容器为空�?br />
E result = elements[head];
if (result == null)//null值意味着deque为空
return null;
elements[h] = null;//let GC work
head = (head + 1) & (elements.length - 1);//下标���界处理
return result;
}
pollLast()
pollLast()的作用是删除�q�返�?em>Deque������元素�Q�也��x��tail位置前面的那个元素�?br />
int t = (tail - 1) & (elements.length - 1);//tail的上一个位�|�是最后一个元�?/span>
E result = elements[t];
if (result == null)//null值意味着deque为空
return null;
elements[t] = null;//let GC work
tail = t;
return result;
}
peekFirst()
peekFirst()的作用是�q�回但不删除Deque首端元素�Q�也��x��head位置处的元素�Q�直接返�?code>elements[head]卛_���?br />
return elements[head]; // elements[head] is null if deque empty
}
peekLast()
peekLast()的作用是�q�回但不删除Deque������元素�Q�也��x��tail位置前面的那个元素�?br />
return elements[(tail - 1) & (elements.length - 1)];
}
��M��介绍
LinkedList同时实现�?em>List接口�?em>Deque接口�Q�也���是说它既可以看作一个顺序容器,又可以看作一个队列(Queue�Q�,同时又可以看作一个栈�Q?em>Stack�Q�。这��L��来,LinkedList���直就是个全能冠军。当你需要��用栈或者队列时�Q�可以考虑使用LinkedList�Q�一斚w��是因为Java官方已经声明不徏议���?em>Stack�c�,更遗憄���是,Java里根本没有一个叫�?em>Queue的类�Q�它是个接口名字�Q�。关于栈或队列,现在的首选是ArrayDeque�Q�它有着�?em>LinkedList�Q�当作栈或队列��用时�Q�有着更好的性能�?/p>
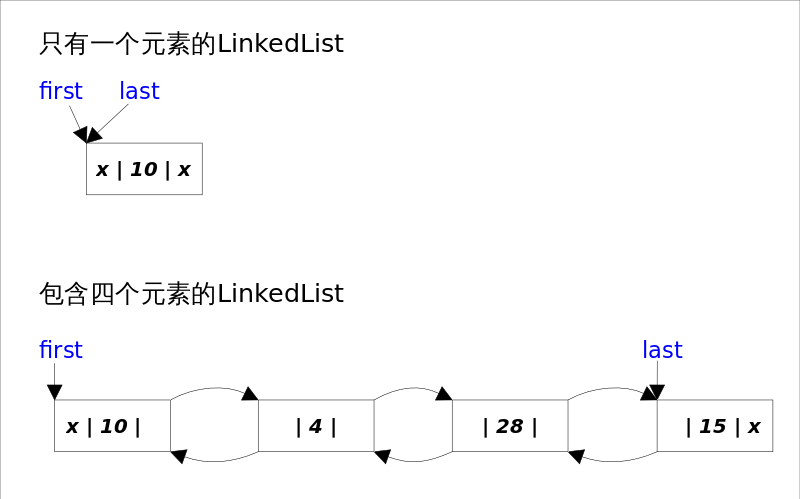
LinkedList底层通过双向链表实现�Q�本节将着重讲解插入和删除元素时双向链表的�l�护�q�程�Q�也��x��之间解跟List接口相关的函敎ͼ�而将Queue�?em>Stack以及Deque相关的知识放在下一节讲。双向链表的每个节点用内部类Node表示�?em>LinkedList通过first�?code>last引用分别指向链表的第一个和最后一个元素。注意这里没有所谓的哑元�Q�当链表为空的时�?code>first�?code>last都指�?code>null�?br />
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList的实现方式决定了所有跟下标相关的操作都是线性时��_��而在首段或者末���ֈ�除元素只需要常数时间。�ؓ�q�求效率LinkedList没有实现同步�Q�synchronized�Q�,如果需要多个线�E��ƈ发访问,可以先采�?code>Collections.synchronizedList()�Ҏ��对其�q�行包装�?/p>
�Ҏ��剖析
add()
add()�Ҏ��有两个版本,一个是add(E e)�Q�该�Ҏ���?em>LinkedList的末���插入元素,因�ؓ�?code>last指向链表末尾�Q�在末尾插入元素的花�Ҏ��常数旉���。只需要简单修改几个相兛_��用即可;另一个是add(int index, E element)�Q�该�Ҏ��是在指定下表处插入元素,需要先通过�U�性查找找到具体位�|�,然后修改相关引用完成插入操作�?/p>
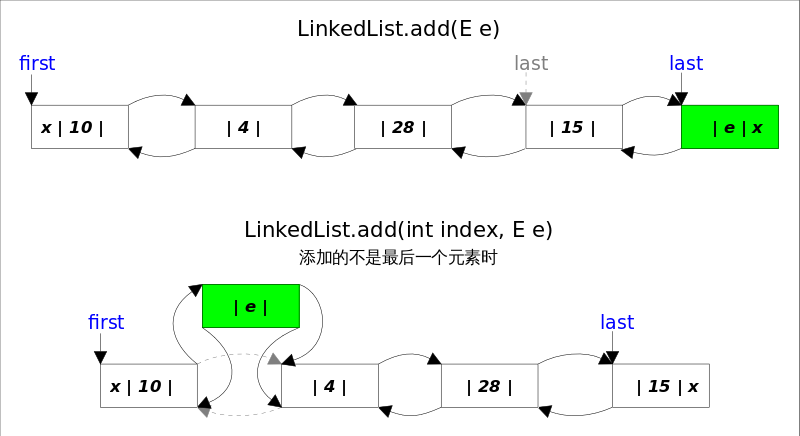
�l�合上图�Q�可以看�?code>add(E e)的逻辑非常���单�?br />
public boolean add(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;//原来链表为空�Q�这是插入的�W�一个元�?/span>
else
l.next = newNode;
size++;
return true;
}
add(int index, E element)
public void add(int index, E element) {
checkPositionIndex(index);//index >= 0 && index <= size;
if (index == size)//插入位置是末���,包括列表为空的情�?/span>
add(element);
else{
Node<E> succ = node(index);//1.先根据index扑ֈ�要插入的位置
//2.修改引用�Q�完成插入操作�?/span>
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)//插入位置�?
first = newNode;
else
pred.next = newNode;
size++;
}
}
上面代码中的node(int index)函数有一点小���的trick�Q�因为链表双向的�Q�可以从开始往后找�Q�也可以从结���־�前找�Q�具体朝那个方向扑֏�决于条�gindex < (size >> 1)�Q�也��x��index是靠�q�前端还是后端�?/p>
remove()
remove()�Ҏ��也有两个版本�Q�一个是删除跟指定元素相�{�的�W�一个元�?code>remove(Object o)�Q�另一个是删除指定下标处的元素remove(int index)�?/p>
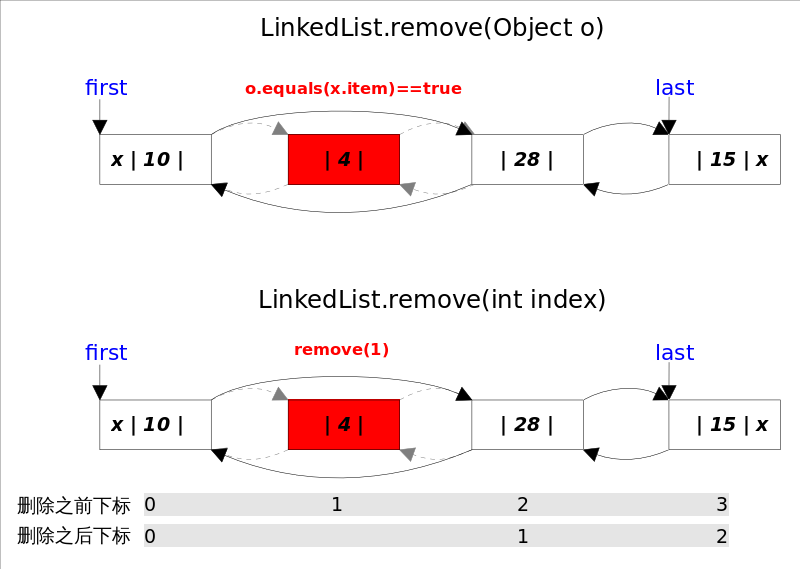
两个删除操作都要1.先找到要删除元素的引用,2.修改相关引用�Q�完成删除操作。在��L��被删元素引用的时�?code>remove(Object o)调用的是元素�?code>equals�Ҏ���Q��?code>remove(int index)使用的是下标计数�Q�两�U�方式都是线性时间复杂度。在步骤2中,两个revome()�Ҏ��都是通过unlink(Node<E> x)�Ҏ��完成的。这里需要考虑删除元素是第一个或者最后一个时的边界情��c�?br />
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {//删除的是�W�一个元�?/span>
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {//删除的是最后一个元�?/span>
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;//let GC work
size--;
return element;
}
get()
get(int index)得到指定下标处元素的引用�Q�通过调用上文中提到的node(int index)�Ҏ��实现�?br />
checkElementIndex(index);//index >= 0 && index < size;
return node(index).item;
}
set()
set(int index, E element)�Ҏ�����指定下标处的元素修�Ҏ��指定��|��也是先通过node(int index)扑ֈ�对应下表元素的引用,然后修改Node�?code>item的倹{�?br />
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;//替换新�?/span>
return oldVal;
}