./Middleware_BI.5/instances/instance1/bin/opmnctl status
]]>
夜归西二旗�?
]]>
�q�次先从最基础的开�?-树的遍历。本文��用了两种极常用的�Ҏ��来遍历树中的所有节�?-递归�Q��P代,但它们实现的都是深度优先(Depth-First)���法�?br>1. 树节点与数据
先定义树节点及数�?用户对象)�Q��ƈ创徏���试用的数据�?br>TreeNode是树节点的定义�?
/**
* 树节点的定义�?br>*/
public interface TreeNode {
/**
* 获取指定下标处的子节炏V�?br> *
* @param index
* 下标�?br> * @return 子节炏V�?br>*/
public TreeNode getChildAt(int index);
/**
* �q�回指定子节点的下标�?br> *
* @param index
* 下标�?br> * @return 子节炏V�?br>*/
public int getChildIndex(TreeNode index);
/**
* 获取子节点的数量�?br> *
* @return 子节点的数量�?br>*/
public int getChildCount();
/**
* �q�回父节炏V�?br> *
* @return 父节炏V�?br>*/
public TreeNode getParent();
/**
* 讄���父节炏V��注�Q�此处不需要改变父节点中的子节点元素�?br> *
* @param parent
* 父节炏V�?br>*/
public void setParent(TreeNode parent);
/**
* 获取所有的子节炏V�?br> *
* @return 子节点的集合�?br>*/
public List<?> getChildren();
/**
* 是否为叶节点�?br> *
* @return 是叶节点�Q�返回true�Q�否则,�q�回false�?br>*/
public boolean isLeaf();
}
GenericTreeNode是一个通用的树节点实现�?
public class GenericTreeNode<T> implements TreeNode {
private T userObject = null;
private TreeNode parent = null;
private List<GenericTreeNode<T>> children = new ArrayList<GenericTreeNode<T>>();
public GenericTreeNode(T userObject) {
this.userObject = userObject;
}
public GenericTreeNode() {
this(null);
}
/**
* ��d��子节炏V�?br> *
* @param child
*/
public void addChild(GenericTreeNode<T> child) {
children.add(child);
child.setParent(this);
}
/**
* 删除指定的子节点�?br> *
* @param child
* 子节炏V�?br>*/
public void removeChild(TreeNode child) {
removeChildAt(getChildIndex(child));
}
/**
* 删除指定下标处的子节炏V�?br> *
* @param index
* 下标�?br>*/
public void removeChildAt(int index) {
TreeNode child = getChildAt(index);
children.remove(index);
child.setParent(null);
}
public TreeNode getChildAt(int index) {
return children.get(index);
}
public int getChildCount() {
return children.size();
}
public int getChildIndex(TreeNode child) {
return children.indexOf(child);
}
public List<GenericTreeNode<T>> getChildren() {
return Collections.unmodifiableList(children);
}
public void setParent(TreeNode parent) {
this.parent = parent;
}
public TreeNode getParent() {
return parent;
}
/**
* 是否为根节点�?br> *
* @return 是根节点�Q�返回true�Q�否则,�q�回false�?br>*/
public boolean isRoot() {
return getParent() == null;
}
public boolean isLeaf() {
return getChildCount() == 0;
}
/**
* 判断指定的节�Ҏ��否�ؓ当前节点的子节点�?br> *
* @param node
* 节点�?br> * @return 是当前节点的子节点,�q�回true�Q�否则,�q�回false�?br>*/
public boolean isChild(TreeNode node) {
boolean result;
if (node == null) {
result = false;
} else {
if (getChildCount() == 0) {
result = false;
} else {
result = (node.getParent() == this);
}
}
return result;
}
public T getUserObject() {
return userObject;
}
public void setUserObject(T userObject) {
this.userObject = userObject;
}
@Override
public String toString() {
return userObject == null ? "" : userObject.toString();
}
}
UserObject是节点上的用户对象,相当于是数据�?
public class UserObject {
private String name = null;
private Integer value = Integer.valueOf(0);
public UserObject() {
}
public UserObject(String code, Integer value) {
this.name = code;
this.value = value;
}
public String getName() {
return name;
}
public void setName(String code) {
this.name = code;
}
public Integer getValue() {
return value;
}
public void setValue(Integer value) {
this.value = value;
}
@Override
public String toString() {
StringBuilder result = new StringBuilder();
result.append("[name=").append(name).append(", value=").append(value).append("]");
return result.toString();
}
}
TreeUtils是用于创建树的工��L���?
public class TreeUtils {
public static GenericTreeNode<UserObject> buildTree() {
GenericTreeNode<UserObject> root = new GenericTreeNode<UserObject>();
root.setUserObject(new UserObject("ROOT", Integer.valueOf(0)));
GenericTreeNode<UserObject> node1 = new GenericTreeNode<UserObject>();
node1.setUserObject(new UserObject("1", Integer.valueOf(0)));
GenericTreeNode<UserObject> node2 = new GenericTreeNode<UserObject>();
node2.setUserObject(new UserObject("2", Integer.valueOf(0)));
GenericTreeNode<UserObject> node3 = new GenericTreeNode<UserObject>();
node3.setUserObject(new UserObject("3", Integer.valueOf(5)));
root.addChild(node1);
root.addChild(node2);
root.addChild(node3);
GenericTreeNode<UserObject> node11 = new GenericTreeNode<UserObject>();
node11.setUserObject(new UserObject("11", Integer.valueOf(0)));
GenericTreeNode<UserObject> node21 = new GenericTreeNode<UserObject>();
node21.setUserObject(new UserObject("21", Integer.valueOf(0)));
node1.addChild(node11);
node2.addChild(node21);
GenericTreeNode<UserObject> node111 = new GenericTreeNode<UserObject>();
node111.setUserObject(new UserObject("111", Integer.valueOf(3)));
GenericTreeNode<UserObject> node112 = new GenericTreeNode<UserObject>();
node112.setUserObject(new UserObject("112", Integer.valueOf(9)));
GenericTreeNode<UserObject> node211 = new GenericTreeNode<UserObject>();
node211.setUserObject(new UserObject("211", Integer.valueOf(6)));
GenericTreeNode<UserObject> node212 = new GenericTreeNode<UserObject>();
node212.setUserObject(new UserObject("212", Integer.valueOf(3)));
node11.addChild(node111);
node11.addChild(node112);
node21.addChild(node211);
node21.addChild(node212);
return root;
}
}
2. 递归�?/strong> private static void recursiveTravel(GenericTreeNode<UserObject> node) { 大家肯定知道�Q�系�l�在执行递归�Ҏ��(对于其它�Ҏ��也是如此)时是使用�q�行时栈。对�Ҏ��的每一�ơ调用,在栈中都会创��Z��份此�ơ调用的�z�d��记录--包括�Ҏ��的参敎ͼ�局部变量,�q�回地址�Q�动态链接库�Q�返回值等�?br>既然�pȝ��能够隐式��C��用栈��L��行递归�Ҏ���Q�那么我们就可以昑ּ���C��用栈来执行上�q�递归�E�序�Q�这也是���递归�E�序转化����P代程序的常用思想。下面的iterativeTravel�Ҏ�����p��用了�q�一思想�?br>3. �q�代�?/strong> private static void iterativeTravel(GenericTreeNode<UserObject> node) { 与递归法相比,�q�代法的代码略多了几行,但仍然很���单�?br> 原文位置�Q?a title="http://www.tkk7.com/jiangshachina/archive/2009/04/01/263241.html" href="http://www.tkk7.com/jiangshachina/archive/2009/04/01/263241.html">http://www.tkk7.com/jiangshachina/archive/2009/04/01/263241.html
使用递归法的最大好处就�?-���单,但一般地�Q�我们都认�ؓ递归的效率不高�?
travelNode(node); // 讉K��节点�Q�仅仅只是打印该节点�|�了�?br> List<GenericTreeNode<UserObject>> children = node.getChildren();
for (int i = 0; i < children.size(); i++) {
recursiveTravel(children.get(i)); // 递归地访问当前节点的所有子节点�?br> }
}
Stack<GenericTreeNode<UserObject>> nodes = new Stack<GenericTreeNode<UserObject>>();
nodes.push(node); // ���当前节点压入栈中�?br>while (!nodes.isEmpty()) {
GenericTreeNode<UserObject> bufNode = nodes.pop(); // 从栈中取��Z��个节炏V�?br> travelNode(bufNode); // 讉K��节点�?br>if (!bufNode.isLeaf()) { // 如果该节点�ؓ分枝节点�Q�则���它的子节点全部加入栈中�?br> nodes.addAll(bufNode.getChildren());
}
}
}
4. ���结
�׃��上述两种�Ҏ���?隐式或显式地)使用了运行栈�Q�所以此处的�q�代法�ƈ不能提高整个�E�序的效率。相反地�Q�由于在应用�E�序中显式地使用�?java.util.Stack)�Q�iterativeTravel�Ҏ��的效率可能反而更低。但iterativeTravel的最大好处是�Q�能够有效地避免�q�行时栈溢出(java.lang.StackOverflowError)�?br>如果树的层次不太深,每层的子节点��C��太多�Q�那么��用递归法应该是没有问题的。毕竟,����z�地�E�序会提供更多的好处�?
]]>
1、在菜单中选择Weblog�Q�然后选择Another Weblog Service&�?
2、在Weblog Homepage URL中输入你的Blog主页地址�?br>3、输入用户名与密码�?br>4、在Type of weblog that you are using中选择Metaweblog API�?br>5、Remote posting URL for your weblog中输�?a href="http://www.tkk7.com/Blog">http://www.tkk7.com/Blog�?services/metaweblog.aspx�?
使用注意�Q�用Windows Live Writer发布之后�Q�Windows Live Writer�q�不改变当前�H�口的状�?也没有明昄���提示)�Q�在当前�H�口中会���刚发布的随�W�处于编辑状态,如果修改�q�发布,会直接修改刚发布的随�W�内宏V�?/p>
1.下蝲所需软�g
1.1SVN服务�?svn-1.4.3-setup.exe)
http://subversion.tigris.org/project_packages.html
1.2把SVN讄���成window服务(SVNService.exe)
我没有下载地址,如有需�?留下你的email
1.3Eclipse的SVN插�g(用Eclipse插�g下蝲):
2.配置服务�?/strong>
2.1安装svn-1.4.3-setup.exe
2.2开�?>�q�行->cmd->�q�入SVN服务端的安装目录下面的bin目录
2.3cmd下运行svnadmin create SVN库的位置(�?D:\SVN_PRJ)
2.4复制SVNService.exe到SVN服务端安装目录下的bin目录
2.5cmd下运行SVNService -install -d -r D:\SVN_PRJ(SVN库的位置)
2.6如果��x��消掉后台服务,则运行SVNService -remove
2.7�q�入D:\SVN_PRJ\conf目录下编辑svnserve.conf,内容如下(切记下面几行字前不能有空�?�Q?br />
[general]
anon-access = read #匿名讉K��权限,取��gؓread,write,none
auth-access = write #认证用户的权�?br />
password-db = passwd #认证用户数据�?卛_��许连到SVN的用�?当前目录下的passwd文�g中存攄���用户及密�?
realm = TESTING #在用戯���证界面上出现的提�C�����?br />
2.8�~�辑D:\SVN_PRJ\conf\passwd文�g,内容如下
[users]
test = password #�q�时你连接SVN的时候可以��用用户名为test密码为password来连接SVN
2.9开�?>讄���->控制面板->���理工具->服务->启动SVNService服务
3.Eclipse下配�|�SVN插�g
3.1帮助->软�g更新->查找�q�安�?>搜烦要安装的新功能部�?>新徏�q�程站点->输入一个�Q意的名称->URL输入
http://subclipse.tigris.org/update_1.2.x->���定->选中你刚才添加的�q�程站点->完成->选中Subclipse->执行安装操作
3.2�H�口->打开透视�?>SVN资源库研�I?>右键->新徏->资源库位�|?>URL中输入svn://127.0.0.1/->输入2.7定义的用户名test和密�?br />
password
4.提交工程
4.1叛_��工程->���组->�׃�n��目->选择SVN->选择svn://127.0.0.1(如果没有,则创��Z��个新的资源库)->下一�?>完成
5.下蝲工程
5.1在SVN资源库透视图下,点开svn://127.0.0.1,会显�C�出现在本机SVN上的所有工�E?叛_��你想下蝲的工�E?>�����Zؓ->下一�?>完成
6.基本操作
6.1同步
在MyEclipse J2EE透视图下,叛_��你要同步的工�E?>���组->与资源库同步->�q�时会进入同步透视�?会显�C�出本机与SVN上内�Ҏ��不同的文�?双击文�g�?会显�C�出两个文�g中哪里不�?
6.2提交
在同步透视图下�?灰色向右的箭�?表示你本��Z��改过",叛_��该文�?可以选择提交操作;
6.3覆盖/更新
在同步透视图下�?蓝色向左的箭�?表示你本��Z��改过",叛_��该文�?可以选择覆盖/更新操作;
7.图标说明
7.1灰色向右���头:本地修改�q?br />
7.2蓝色向左���头:SVN上修改过
7.3灰色向右且中间有个加��L�����头:本地比SVN上多出的文�g
7.4蓝色向左且中间有个加��L�����头:SVN上比本地多出的文�?br />
7.5灰色向右且中间有个减��L�����头:本地删除�?而SVN上未删除的文�?br />
7.6蓝色向左且中间有个减��L�����头:SVN上删除了,而本地未删除的文�?br />
7.7�U�色双向���头:SVN上修改过,本地也修改过的文�?br />
8.一些我遇到的出错信�?/strong>
8.1在上面讲�?.2步输入URL(svn://127.0.0.1)点下一步出�?svnserve.conf:12: Option expected"错误
你打开svnserve.conf文�g中的�W?2�?该错误是�׃��该行的前面有�I�格引�v�?把左边多出的�I�格删除掉即�?
8.2在上面讲�?.2步输入URL(svn://127.0.0.1/SVN_PRJ)点下一步出�?svn://127.0.0.1/SVN_PRJ non-existent in revision '7'"错误
URL错了,应该输入svn://127.0.0.1卛_��
9.SVN服务端自带的��Z��命��o行的操作语句
9.1讄���SVN服务端安装目录下�?bin到环境变量中;
9.2在命令行下运行svn import c:/test svn://127.0.0.1/test -m "initial import" --username test --password passwd可进行上传操�?br />
9.3�q�入你要���出的目录,在命令行下运行svn checkout svn://127.0.0.1/test --username test -password passwd 可进行检出工�E�的操作
9.4在命令行下运行svn commit test.txt -m "modified" --username test -password passwd 可进行提交操�?br />
9.5在命令行下运行svn update -r HEAD test.txt --username test -password passwd 可进行更新操�?br />
�?上面讲的127.0.0.1可以换成外网IP,或者局域网IP皆可(�?在家里创��Z��个SVN服务�?卛_��在公司去讉K��安���的SVN)
]]>
我们要做��C��但会写SQL,�q�要做到写出性能优良的SQL,以下为笔者学习、摘录、�ƈ汇总部分资料与大家分��n�Q?
�Q?�Q?nbsp; 选择最有效率的表名��序 ( 只在��Z��规则的优化器中有�?) �Q?
ORACLE 的解析器按照从右到左的顺序处�?FROM 子句中的表名�Q?FROM 子句中写在最后的�?( 基础�?driving table) ���被最先处理,�?FROM 子句中包含多个表的情况下 , 你必��选择记录条数最���的表作为基���表。如果有 3 个以上的表连接查�?, 那就需要选择交叉�?(intersection table) 作�ؓ基础�?, 交叉表是指那个被其他表所引用的表 .
�Q?�Q?nbsp; WHERE 子句中的�q�接��序�Q�:
ORACLE 采用自下而上的顺序解�?WHERE 子句 , �Ҏ���q�个原理 , 表之间的�q�接必须写在其他 WHERE 条�g之前 , 那些可以�q���o掉最大数量记录的条�g必须写在 WHERE 子句的末��?.
�Q?�Q?nbsp; SELECT 子句中避免���?‘ * ‘ �Q?
ORACLE 在解析的�q�程�?, 会将 '*' 依次转换成所有的列名 , �q�个工作是通过查询数据字典完成�?, �q�意味着���耗费更多的时�?
�Q?�Q?nbsp; 减少讉K��数据库的�ơ数�Q?
ORACLE 在内部执行了许多工作 : 解析 SQL 语句 , 估算索引的利用率 , �l�定变量 , ��L��据块�{�;
�Q?�Q?nbsp; �?SQL*Plus , SQL*Forms �?Pro*C 中重新设�|?ARRAYSIZE 参数 , 可以增加每次数据库访问的���索数据量 , �������gؓ 200
�Q?�Q?nbsp; 使用 DECODE 函数来减���处理时��_��
使用 DECODE 函数可以避免重复扫描相同记录或重复连接相同的�?.
�Q?�Q?nbsp; 整合����?, 无关联的数据库访问:
如果你有几个���单的数据库查询语�?, 你可以把它们整合��C��个查询中 ( 即��它们之间没有关系 )
�Q?�Q?nbsp; 删除重复记录 �Q?
最高效的删除重复记录方�?( 因�ؓ使用�?ROWID) 例子�Q?
DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID)
FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
�Q?�Q?nbsp; �?TRUNCATE 替代 DELETE �Q?
当删除表中的记录�?, 在通常情况�?, 回滚�D?(rollback segments ) 用来存放可以被恢复的信息 . 如果你没�?COMMIT 事务 ,ORACLE 会将数据恢复到删除之前的状�?( 准确地说�?恢复到执行删除命令之前的状况 ) 而当�q�用 TRUNCATE �?, 回滚�D�不再存放�Q何可被恢复的信息 . 当命令运行后 , 数据不能被恢�?. 因此很少的资源被调用 , 执行旉���也会很短 . ( 译者按 : TRUNCATE 只在删除全表适用 ,TRUNCATE �?DDL 不是 DML)
�Q?0�Q?nbsp; ���量多���?COMMIT �Q?
只要有可�?, 在程序中���量多���?COMMIT, �q�样�E�序的性能得到提高 , 需求也会因�?COMMIT 所释放的资源而减��?:
COMMIT 所释放的资�?:
a. 回滚�D�上用于恢复数据的信�?.
b. 被程序语句获得的�?
c. redo log buffer 中的�I�间
d. ORACLE 为管理上�q?3 �U�资源中的内部花�?
�Q?1�Q?nbsp; �?Where 子句替换 HAVING 子句�Q?
避免使用 HAVING 子句 , HAVING 只会在检索出所有记录之后才对结果集�q�行�q���o . �q�个处理需要排�?, 总计�{�操�?. 如果能通过 WHERE 子句限制记录的数�?, 那就能减���这斚w��的开销 . ( �?oracle �?) on �?where �?having �q�三个都可以加条件的子句中, on 是最先执行, where �ơ之�Q?having 最后,因�ؓ on 是先把不�W�合条�g的记录过滤后才进行统计,它就可以减少中间�q�算要处理的数据�Q�按理说应该速度是最快的�Q?where 也应该比 having 快点的,因�ؓ它过滤数据后才进�?sum �Q�在两个表联接时才用 on 的,所以在一个表的时候,���剩�?where �?having 比较了。在�q�单表查询统计的情况下,如果要过滤的条�g没有涉及到要计算字段�Q�那它们的结果是一��L���Q�只�?where 可以使用 rushmore 技术,�?having ��׃��能,在速度上后者要慢如果要涉及到计���的字段�Q�就表示在没计算之前�Q�这个字�D늚�值是不确定的�Q�根据上���写的工作流�E�, where 的作用时间是在计���之前就完成的,�?having ���是在计���后才�v作用的,所以在�q�种情况下,两者的�l�果会不同。在多表联接查询�Ӟ�� on �?where 更早起作用。系�l�首先根据各个表之间的联接条�Ӟ��把多个表合成一个��时表后,再由 where �q�行�q���o�Q�然后再计算�Q�计���完后再�?having �q�行�q���o。由此可见,要想�q���o条�g起到正确的作用,首先要明白这个条件应该在什么时候�v作用�Q�然后再军_��攑֜�那里
�Q?2�Q?nbsp; 减少对表的查询:
在含有子查询�?SQL 语句�?, 要特别注意减���对表的查询 . 例子�Q?
SELECT TAB_NAME FROM TABLES WHERE (TAB_NAME,DB_VER) = ( SELECT
TAB_NAME,DB_VER FROM TAB_COLUMNS WHERE VERSION = 604)
�Q?3�Q?nbsp; 通过内部函数提高 SQL 效率 . �Q?
复杂�?SQL 往往牺牲了执行效�?. 能够掌握上面的运用函数解决问题的�Ҏ��在实际工作中是非常有意义�?
�Q?4�Q?nbsp; 使用表的别名 (Alias) �Q?
当在 SQL 语句中连接多个表�?, 请��用表的别名�ƈ把别名前�~�于每�?Column �?. �q�样一�?, ���可以减���解析的旉����q�减���那些由 Column 歧义引�v的语法错�?.
�Q?5�Q?nbsp; �?EXISTS 替代 I N �?�?NOT EXISTS 替代 NOT IN �Q?
在许多基于基���表的查询�?, ��Z��满��一个条�?, 往往需要对另一个表�q�行联接 . 在这�U�情况下 , 使用 EXISTS( �?NOT EXISTS) 通常���提高查询的效率 . 在子查询�?,NOT IN 子句���执行一个内部的排序和合�q?. 无论在哪�U�情况下 ,NOT IN 都是最低效�?( 因�ؓ它对子查询中的表执行了一个全表遍�?). ��Z��避免使用 NOT IN , 我们可以把它改写成外�q�接 (Outer Joins) �?NOT EXISTS.
例子�Q?
�Q?高效 �Q?SELECT * FROM EMP ( 基础�?) WHERE EMPNO > 0 AND EXISTS ( SELECT ‘X' FROM DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO AND LOC = ‘MELB')
( 低效 ) SELECT * FROM EMP ( 基础�?) WHERE EMPNO > 0 AND DEPTNO IN (SELECT DEPTNO FROM DEPT WHERE LOC = ‘MELB' )
�Q?6�Q?nbsp; 识别 ' 低效执行 ' �?SQL 语句�Q?
虽然目前各种关于 SQL 优化的图形化工具层出不穷 , 但是写出自己�?SQL 工具来解决问题始�l�是一个最好的�Ҏ���Q?
SELECT EXECUTIONS , DISK_READS, BUFFER_GETS,
ROUND ((BUFFER_GETS-DISK_READS)/BUFFER_GETS,2 ) Hit_radio,
ROUND (DISK_READS/EXECUTIONS,2) Reads_per_run,
SQL_TEXT
FROM V$SQLAREA
WHERE EXECUTIONS>0
AND BUFFER_GETS > 0
AND (BUFFER_GETS-DISK_READS)/BUFFER_GETS < 0.8
ORDER BY 4 DESC ;
�Q?7�Q?nbsp; 用烦引提高效率:
索引是表的一个概念部�?, 用来提高���索数据的效率�Q?ORACLE 使用了一个复杂的自��^�?B-tree �l�构 . 通常 , 通过索引查询数据比全表扫描要�?. �?ORACLE 扑և�执行查询�?Update 语句的最佌��\径时 , ORACLE 优化器将使用索引 . 同样在联�l�多个表时��用烦引也可以提高效率 . 另一个��用烦引的好处�?, 它提供了主键 (primary key) 的唯一性验�?. 。那�?LONG �?LONG RAW 数据�c�d�� , 你可以烦引几乎所有的�?. 通常 , 在大型表中��用烦引特别有�?. 当然 , 你也会发�?, 在扫描小表时 , 使用索引同样能提高效�?. 虽然使用索引能得到查询效率的提高 , 但是我们也必���L��意到它的代�h . 索引需要空间来存储 , 也需要定期维�?, 每当有记录在表中增减或烦引列被修�Ҏ�� , 索引本��n也会被修�?. �q�意味着每条记录�?INSERT , DELETE , UPDATE ����ؓ此多付出 4 , 5 �ơ的���盘 I/O . 因�ؓ索引需要额外的存储�I�间和处�?, 那些不必要的索引反而会使查询反应时间变�?. 。定期的重构索引是有必要�?. �Q?
ALTER INDEX <INDEXNAME> REBUILD <TABLESPACENAME>
�Q?8�Q?nbsp; �?EXISTS 替换 DISTINCT �Q?
当提交一个包含一对多表信�?( 比如部门表和雇员�?) 的查询时 , 避免�?SELECT 子句中���?DISTINCT. 一般可以考虑�?EXIST 替换 , EXISTS 使查询更������?, 因�ؓ RDBMS 核心模块���在 子查询的条�g一旦满���_�� , 立刻�q�回�l�果 . 例子�Q?
( 低效 ):
SELECT DISTINCT DEPT_NO,DEPT_NAME FROM DEPT D , EMP E
WHERE D.DEPT_NO = E.DEPT_NO
( 高效 ):
SELECT DEPT_NO,DEPT_NAME FROM DEPT D WHERE EXISTS ( SELECT ‘X'
FROM EMP E WHERE E.DEPT_NO = D.DEPT_NO ) ;
�Q?9�Q?nbsp; sql 语句用大写的 �Q�因�?oracle ��L��先解�?sql 语句�Q�把���写的字母�{换成大写的再执行
�Q?0�Q?nbsp; �?java 代码中尽量少用连接符“�Q?#8221;�q�接字符�Ԍ��
�Q?1�Q?nbsp; 避免在烦引列上���?NOT 通常 �Q�
我们要避免在索引列上使用 NOT, NOT 会��生在和在索引列上使用函数相同�?影响 . �?ORACLE” 遇到 ”NOT, 他就会停止��用烦引�{而执行全表扫�?.
�Q?2�Q?nbsp; 避免在烦引列上��用计���.
WHERE 子句中,如果索引列是函数的一部分�Q�优化器���不使用索引而��用全表扫描.
举例 :
低效�Q?
SELECT … FROM DEPT WHERE SAL * 12 > 25000;
高效 :
SELECT … FROM DEPT WHERE SAL > 25000/12;
�Q?3�Q?nbsp; �?>= 替代 >
高效 :
SELECT * FROM EMP WHERE DEPTNO >=4
低效 :
SELECT * FROM EMP WHERE DEPTNO >3
两者的区别在于 , 前�?DBMS ���直接蟩到第一�?DEPT �{�于 4 的记录而后者将首先定位�?DEPTNO=3 的记录�ƈ且向前扫描到�W�一�?DEPT 大于 3 的记�?.
�Q?4�Q?nbsp; �?UNION 替换 OR ( 适用于烦引列 )
通常情况�?, �?UNION 替换 WHERE 子句中的 OR ���会起到较好的效�?. 对烦引列使用 OR ���造成全表扫描 . 注意 , 以上规则只针对多个烦引列有效 . 如果�?column 没有被烦�?, 查询效率可能会因��Z��没有选择 OR 而降�?. 在下面的例子�?, LOC_ID �?REGION 上都建有索引 .
高效 :
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10
UNION
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE REGION = “MELBOURNE”
低效 :
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10 OR REGION = “MELBOURNE”
如果你坚持要�?OR, 那就需要返回记录最���的索引列写在最前面 .
�Q?5�Q?nbsp; �?IN 来替�?OR
�q�是一条简单易记的规则�Q�但是实际的执行效果�q�须���验,�?ORACLE8i 下,两者的执行路径��g��是相同的�Q�
低效 :
SELECT …. FROM LOCATION WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30
高效
SELECT … FROM LOCATION WHERE LOC_IN IN (10,20,30);
�Q?6�Q?nbsp; 避免在烦引列上���?IS NULL �?IS NOT NULL
避免在烦引中使用��M��可以为空的列�Q?ORACLE ���无法��用该索引 �Q�对于单列烦引,如果列包含空��|��索引中将不存在此记录 . 对于复合索引�Q�如果每个列都�ؓ�I�,索引中同样不存在此记�?. 如果臛_��有一个列不�ؓ�I�,则记录存在于索引中. 举例 : 如果唯一性烦引徏立在表的 A 列和 B 列上 , �q�且表中存在一条记录的 A,B ��gؓ (123,null) , ORACLE ���不接受下一条具有相�?A,B ��|�� 123,null �Q�的记录 ( 插入 ). 然而如�?所有的索引列都为空�Q?ORACLE ���认为整个键��gؓ�I����空不等于空 . 因此你可以插�?1000 条具有相同键值的记录 , 当然它们都是�I?! 因�ؓ�I���g��存在于烦引列�?, 所�?WHERE 子句中对索引列进行空值比较将�?ORACLE 停用该烦�?.
低效 : ( 索引失效 )
SELECT … FROM DEPARTMENT WHERE DEPT_CODE IS NOT NULL ;
高效 : ( 索引有效 )
SELECT … FROM DEPARTMENT WHERE DEPT_CODE >= 0;
�Q?7�Q?nbsp; ��L��使用索引的第一个列 �Q?
如果索引是徏立在多个列上 , 只有在它的第一个列 (leading column) �?where 子句引用�?, 优化器才会选择使用该烦�?. �q�也是一条简单而重要的规则�Q�当仅引用烦引的�W�二个列�?, 优化器��用了全表扫描而忽略了索引
�Q?8�Q?nbsp; �?UNION-ALL 替换 UNION ( 如果有可能的�?) �Q?
�?SQL 语句需�?UNION 两个查询�l�果集合�?, �q�两个结果集合会�?UNION-ALL 的方式被合�ƈ , 然后在输出最�l�结果前�q�行排序 . 如果�?UNION ALL 替代 UNION, �q�样排序��׃��是必要了 . 效率��׃��因此得到提高 . 需要注意的�?�Q?UNION ALL ���重复输��Z��个结果集合中相同记录 . 因此各位�q�是 要从业务需求分析���?UNION ALL 的可行�?. UNION ���对�l�果集合排序 , �q�个操作会��用到 SORT_AREA_SIZE �q�块内存 . 对于�q?块内存的优化也是相当重要�?. 下面�?SQL 可以用来查询排序的消耗量
低效�Q?
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
UNION
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
高效 :
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
UNION ALL
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
�Q?9�Q?nbsp; �?WHERE 替代 ORDER BY �Q?
ORDER BY 子句只在两种严格的条件下使用索引 .
ORDER BY 中所有的列必���d��含在相同的烦引中�q�保持在索引中的排列��序 .
ORDER BY 中所有的列必���d��义�ؓ非空 .
WHERE 子句使用的烦引和 ORDER BY 子句中所使用的烦引不能�ƈ�?.
例如 :
�?DEPT 包含以下�?:
DEPT_CODE PK NOT NULL
DEPT_DESC NOT NULL
DEPT_TYPE NULL
低效 : ( 索引不被使用 )
SELECT DEPT_CODE FROM DEPT ORDER BY DEPT_TYPE
高效 : ( 使用索引 )
SELECT DEPT_CODE FROM DEPT WHERE DEPT_TYPE > 0
�Q?0�Q?nbsp; 避免改变索引列的�c�d�� .:
当比较不同数据类型的数据�?, ORACLE 自动对列�q�行���单的�c�d��转换 .
假设 EMPNO 是一个数值类型的索引�?.
SELECT … FROM EMP WHERE EMPNO = ‘123'
实际�?, �l�过 ORACLE �c�d��转换 , 语句转化�?:
SELECT … FROM EMP WHERE EMPNO = TO_NUMBER(‘123')
�q�运的是 , �c�d��转换没有发生在烦引列�?, 索引的用途没有被改变 .
现在 , 假设 EMP_TYPE 是一个字�W�类型的索引�?.
SELECT … FROM EMP WHERE EMP_TYPE = 123
�q�个语句�?ORACLE 转换�?:
SELECT … FROM EMP WHERE TO_NUMBER(EMP_TYPE)=123
因�ؓ内部发生的类型�{�?, �q�个索引���不会被用到 ! ��Z��避免 ORACLE 对你�?SQL �q�行隐式的类型�{�?, 最好把�c�d��转换用显式表现出�?. 注意当字�W�和数值比较时 , ORACLE 会优先�{换数值类型到字符�c�d��
�Q?1�Q?nbsp; 需要当心的 WHERE 子句 :
某些 SELECT 语句中的 WHERE 子句不��用烦�?. �q�里有一些例�?.
在下面的例子�?, (1) ‘!=' ���不使用索引 . ��C�� , 索引只能告诉你什么存在于表中 , 而不能告诉你什么不存在于表�?. (2) ‘||' �?字符�q�接函数 . ���p��其他函数那样 , 停用了烦�?. (3) ‘+' 是数学函�?. ���p��其他数学函数那样 , 停用了烦�?. (4) 相同的烦引列不能互相比较 , �q�将会启用全表扫�?.
�Q?2�Q?nbsp; a. 如果���索数据量���过 30% 的表中记录数 . 使用索引���没有显著的效率提高 .
b. 在特定情况下 , 使用索引也许会比全表扫描�?, 但这是同一个数量��上的区别 . 而通常情况�?, 使用索引比全表扫描要块几倍乃臛_��千�?!
�Q?3�Q?nbsp; 避免使用耗费资源的操�?:
带有 DISTINCT,UNION,MINUS,INTERSECT,ORDER BY �?SQL 语句会启�?SQL 引擎
执行耗费资源的排�?(SORT) 功能 . DISTINCT 需要一�ơ排序操�?, 而其他的臛_��需要执行两�ơ排�?. 通常 , 带有 UNION, MINUS , INTERSECT �?SQL 语句都可以用其他方式重写 . 如果你的数据库的 SORT_AREA_SIZE 调配得好 , 使用 UNION , MINUS, INTERSECT 也是可以考虑�?, 毕竟它们的可��L��很�?
�Q?4�Q?nbsp; 优化 GROUP BY:
提高 GROUP BY 语句的效�?, 可以通过���不需要的记录�?GROUP BY 之前�q���o�?. 下面两个查询�q�回相同�l�果但第二个明显���快了许�?.
低效 :
SELECT JOB , AVG(SAL)
FROM EMP
GROUP JOB
HAVING JOB = ‘PRESIDENT'
OR JOB = ‘MANAGER'
高效 :
SELECT JOB , AVG(SAL)
FROM EMP
WHERE JOB = ‘PRESIDENT'
OR JOB = ‘MANAGER'
GROUP JOB
]]>
]]>
声明一下,我博客中所有的文章仅供本�h学习之用�Q�最�q�有人对我的文章评论�q�激�Q�在此我希望您不要耽搁旉���在我的博客中。如果文章中有什么不对之处,我欢�q�大家指出,但是我希望您珍惜自己的言行�?br />
开发环境:
Web服务器:apache-tomcat-6.0.18
Struts版本�Q?/span>struts-2.0.14
JDK版本�Q?/span>JDK1.5.0_12
Eclipse版本�Q�eclipse-jee-ganymede-SR1-win32 也就是eclipse的开发JEE版本�Q�很多�h都��用myeclipse�Q�但是由于myeclipse是商业版本,所以觉得eclipse-jee-ganymede对于开发JEE的项目已�l�很不错了,所以我觉得没必要用myEclipse��d��发�?br />Struts2需要的jar包:
臛_��需要如下五个包
struts2-core-2.0.11.1.jar
xwork-2.0.4.jar
commons-logging-1.0.4.jar
freemarker-2.3.8.jar
ognl-2.6.11.jar
在这个简单的例子中,我们���会完成以下步骤�Q?br />
1.配置web.xml
2.�~�写jsp
3.�~�写Action实现�c?br />
4.配置Action
5.发布�q�行
1.配置web.xml
Struts2的入口点是一�?/span>Filter,需要将�q�个入口炚w���|�到web.xml�Q?br />
 <?xml version="1.0" encoding="UTF-8"?><web-app id="WebApp_ID" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd"> <display-name>HelloWorld</display-name> <welcome-file-list> <welcome-file>index.jsp</welcome-file> </welcome-file-list> <filter> <filter-name>struts2</filter-name> <filter-class>org.apache.struts2.dispatcher.FilterDispatcher</filter-class> </filter> <filter-mapping> <filter-name>struts2</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> </web-app>
<?xml version="1.0" encoding="UTF-8"?><web-app id="WebApp_ID" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd"> <display-name>HelloWorld</display-name> <welcome-file-list> <welcome-file>index.jsp</welcome-file> </welcome-file-list> <filter> <filter-name>struts2</filter-name> <filter-class>org.apache.struts2.dispatcher.FilterDispatcher</filter-class> </filter> <filter-mapping> <filter-name>struts2</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> </web-app>
2. �~�写jsp
在这个例子中需要两个jsp�Q�一个是index.jsp, 用于输入用户的名字。第二个jsp是welcome.jsp�Q�用于向用户问候�?br />
在Struts2中只需要一个标�{�ֺ�/struts-tags。这里面包含了所有的Struts2标签。但使用Struts2的标�{�֤�家要注意一下。在<s::form>中最好都使用Struts2标签�Q�尽量不要用HTML或普通文�?
index.jsp如下�Q?br />
 <%@ page language="java" contentType="text/html; charset=ISO-8859-1" pageEncoding="ISO-8859-1"%>
<%@ page language="java" contentType="text/html; charset=ISO-8859-1" pageEncoding="ISO-8859-1"%> <%@ taglib prefix="s" uri="/struts-tags" %><!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"><html><head><meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1"><title>HelloWorld</title></head><body> <s:form action="Hello"> <s:textfield name="name" label="Please Input Your Name:"></s:textfield> <s:submit value="Hello"></s:submit> </s:form></body></html>
<%@ taglib prefix="s" uri="/struts-tags" %><!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"><html><head><meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1"><title>HelloWorld</title></head><body> <s:form action="Hello"> <s:textfield name="name" label="Please Input Your Name:"></s:textfield> <s:submit value="Hello"></s:submit> </s:form></body></html>welcome.jsp如下�Q?br />
<%@ page language="java" contentType="text/html; charset=ISO-8859-1" pageEncoding="ISO-8859-1"%><%@ taglib prefix="s" uri="/struts-tags" %><!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"><html><head><meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1"><title>HelloWorld</title></head><body> Hello <s:property value="name"/></body></html>
3.�~�写Action�c?br />
Struts2.x的Action需要从com.opensymphony.xwork2.ActionSupport�cȝ���ѝ��而且Action中已�l�包含了Struts1中的ActionForm�c�M��息,所以不需要再写ActionForm�c�R�?br />
在这个例子中只编写了一个HelloWorld.java�c�:
package com.struts2.action;import com.opensymphony.xwork2.ActionSupport;public class HelloWorld extends ActionSupport {
 private static final long serialVersionUID = -2567455771246284511L; private String name;
private static final long serialVersionUID = -2567455771246284511L; private String name;  public String getName() {
public String getName() { return name;
return name; } public void setName(String name) { this.name = name; } public String execute() throws Exception { setName(getName()); return SUCCESS; }
} public void setName(String name) { this.name = name; } public String execute() throws Exception { setName(getName()); return SUCCESS; } }
}
4.配置Action�c�:
�?span style="font-size: 10.5pt; font-family: 'Times New Roman'">struts2.x中的配置文�g一般�ؓstruts.xml�Q�放�?/span>WEB-INF"classes目录中。下面是�?/span>struts.xml中配�|�动作类的代码:
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE struts PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 2.0//EN" "http://struts.apache.org/dtds/struts-2.0.dtd"><struts> <package name="default" extends="struts-default"> <action name="Hello" class="com.struts2.action.HelloWorld"> <result name="success">/welcome.jsp</result> </action> </package></struts>
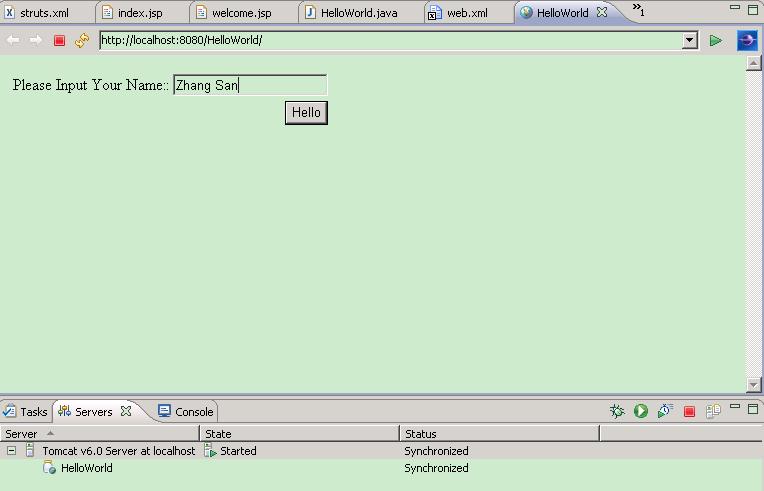
5.发布�Q?br />
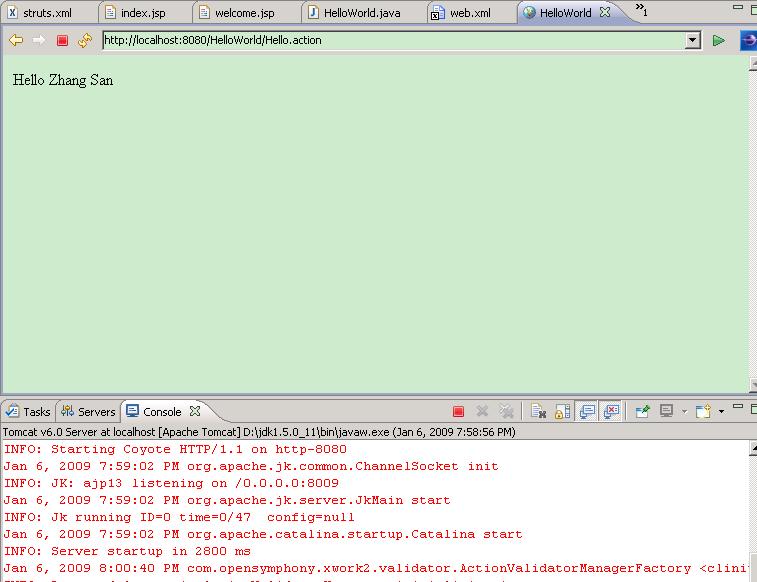
在eclipse-jee-ganymede下配�|�tomcat服务器,很简单�?br />
Windows->Performance->Server->Runntime Environment->Add.随着向导���可以增加tomcat服务器了�?br />
然后鼠标右键点击��目的根目录�Q�选择菜单的Run As->Run on Server���可以发布启动你的项目了。而且�q�有eclipse自带的浏览器�Q�感觉很不错咯�?br />
]]>