1 package com.potevio.telecom.mobilenet;
2
3 //жЦЗдЪgЊc?/span>
4 import java.io.File;
5
6 //жЦЗдЪgиЊУеЗЇЊc?/span>
7 import java.io.FileOutputStream;
8
9 //иіЯиі£иІ£жЮРзЪДз±ї
10 import javax.xml.parsers.DocumentBuilder;
11 import javax.xml.parsers.DocumentBuilderFactory;
12 //жШ†е∞ДЊc?/span>
13 import javax.xml.transform.Transformer;
14 import javax.xml.transform.TransformerFactory;
15
16 //xmlжШ†е∞ДиЊУеЕ•еТМиЊУеЗЇз±ї
17 import javax.xml.transform.dom.DOMSource;
18 import javax.xml.transform.stream.StreamResult;
19
20 //иКВзВєЊc?/span>
21 import org.w3c.dom.Document;
22 import org.w3c.dom.Element;
23
24 /**
25 * @description дљњзФ®DOMеИЫеЊПљОАеНХзЪДXML
26 *
27 * @author Zhou-Jingxian
28 *
29 * @date Jun 19, 2009
30 *
31 */
32 public class CreateRuleXML {
33
34 public static void main(String[] args) {
35
36 try{
37 //иІ£жЮРеЩ®еЈ•еОВз±ї
38 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
39
40 //иІ£жЮРеЩ?/span>
41 DocumentBuilder builder = factory.newDocumentBuilder();
42
43 //жУНдљЬзЪДDocumentеѓєи±°
44 Document document = builder.newDocument();
45
46 //иЃД°љЃXMLзЪДзЙИжЬ?/span>
47 document.setXmlVersion("1.0");
48
49 //еИЫеЊПж†єиКВзВ?/span>
50 Element root = document.createElement("MobileNet");
51
52 //ЮЃЖж†єиКВзВєжЈ’dК†еИ∞Documentеѓєи±°дЄ?/span>
53 document.appendChild(root);
54
55 /**the first page*/
56 //иЃД°љЃљWђдЄАдЄ™pageеЕГзі†еИ?/span>
57 Element pageElement = document.createElement("page");
58
59 //иЃД°љЃpageиКВзВєзЪДnameе±ЮжА?/span>
60 pageElement.setAttribute("name", "list.jsp");
61
62 /**method*/
63 //иЃД°љЃmethodиКВзВє
64 Element methodElement = document.createElement("method");
65
66 //ЊlЩmethodиЃД°љЃеА?/span>
67 methodElement.setTextContent("get");
68
69 //жЈ’dК†methodиКВзВєеИ∞pageиКВзВєеЖ?/span>
70 pageElement.appendChild(methodElement);
71
72 /**display*/
73 //иЃД°љЃmethodиКВзВє
74 Element displayElement = document.createElement("display");
75
76 //ЊlЩdisplayиЃД°љЃеА?/span>
77 displayElement.setTextContent("list");
78
79 //жЈ’dК†displayиКВзВєеИ∞pageиКВзВєеЖ?/span>
80 pageElement.appendChild(displayElement);
81
82 /**request_param*/
83 //иЃД°љЃrequest_paramиКВзВє
84 Element request_paramElement = document.createElement("request_param");
85
86 //ЊlЩrequest_paramиЃД°љЃеА?/span>
87 request_paramElement.setTextContent("request_param1|request_param2");
88
89 //жЈ’dК†request_paramиКВзВєеИ∞pageиКВзВєеЖ?/span>
90 pageElement.appendChild(request_paramElement);
91
92 //ЮЃЖpageМDµеК†дЇЇж†єиКВзВєеЖ?/span>
93 root.appendChild(pageElement);
94
95
96 /**the second page*/
97 //иЃД°љЃљWђдЇМдЄ™pageеЕГзі†еИ?/span>
98 pageElement = document.createElement("page");
99
100 //иЃД°љЃpageиКВзВєзЪДnameе±ЮжА?/span>
101 pageElement.setAttribute("name", "content.jsp");
102
103 /**method*/
104 //иЃД°љЃmethodиКВзВє
105 methodElement = document.createElement("method");
106
107 //ЊlЩmethodиЃД°љЃеА?/span>
108 methodElement.setTextContent("post");
109
110 //жЈ’dК†methodиКВзВєеИ∞pageиКВзВєеЖ?/span>
111 pageElement.appendChild(methodElement);
112
113 /**display*/
114 //иЃД°љЃmethodиКВзВє
115 displayElement = document.createElement("display");
116
117 //ЊlЩdisplayиЃД°љЃеА?/span>
118 displayElement.setTextContent("content");
119
120 //жЈ’dК†displayиКВзВєеИ∞pageиКВзВєеЖ?/span>
121 pageElement.appendChild(displayElement);
122
123 /**url_title*/
124 //иЃД°љЃurl_titleиКВзВє
125 Element url_titleElement = document.createElement("url_title");
126
127 //ЊlЩurl_titleиЃД°љЃеА?/span>
128 url_titleElement.setTextContent("title,publisher,published_calendar");
129
130 //жЈ’dК†url_titleиКВзВєеИ∞pageиКВзВєеЖ?/span>
131 pageElement.appendChild(url_titleElement);
132
133 //ЮЃЖpageМDµеК†дЇЇж†єиКВзВєеЖ?/span>
134 root.appendChild(pageElement);
135
136
137 //еЉАеІЛжККDocumentжШ†е∞ДеИ∞жЦЗдї?/span>
138 TransformerFactory transFactory = TransformerFactory.newInstance();
139 Transformer transFormer = transFactory.newTransformer();
140
141 //иЃД°љЃиЊУеЗЇЊlУжЮЬ
142 DOMSource domSource = new DOMSource(document);
143
144 //зФЯжИРxmlжЦЗдЪg
145 File file = new File("MobileNetRule.xml");
146
147 //еИ§жЦ≠жШѓеР¶е≠ШеЬ®,е¶ВжЮЬдЄНе≠ШеЬ?еИЩеИЫеї?/span>
148 if(!file.exists()){
149 file.createNewFile();
150 }
151
152 //жЦЗдЪgиЊУеЗЇЛє?/span>
153 FileOutputStream out = new FileOutputStream(file);
154
155 //иЃД°љЃиЊУеЕ•жЇ?/span>
156 StreamResult xmlResult = new StreamResult(out);
157
158 //иЊУеЗЇxmlжЦЗдЪg
159 transFormer.transform(domSource, xmlResult);
160
161 //ЛєЛиѓХжЦЗдЪgиЊУеЗЇзЪДиµ\еЊ?/span>
162 System.out.println(file.getAbsolutePath());
163
164 }catch(Exception e){
165 e.printStackTrace();
166
167 }finally{
168
169 }
170 }
171
172 }
173
2
3 //жЦЗдЪgЊc?/span>
4 import java.io.File;
5
6 //жЦЗдЪgиЊУеЗЇЊc?/span>
7 import java.io.FileOutputStream;
8
9 //иіЯиі£иІ£жЮРзЪДз±ї
10 import javax.xml.parsers.DocumentBuilder;
11 import javax.xml.parsers.DocumentBuilderFactory;
12 //жШ†е∞ДЊc?/span>
13 import javax.xml.transform.Transformer;
14 import javax.xml.transform.TransformerFactory;
15
16 //xmlжШ†е∞ДиЊУеЕ•еТМиЊУеЗЇз±ї
17 import javax.xml.transform.dom.DOMSource;
18 import javax.xml.transform.stream.StreamResult;
19
20 //иКВзВєЊc?/span>
21 import org.w3c.dom.Document;
22 import org.w3c.dom.Element;
23
24 /**
25 * @description дљњзФ®DOMеИЫеЊПљОАеНХзЪДXML
26 *
27 * @author Zhou-Jingxian
28 *
29 * @date Jun 19, 2009
30 *
31 */
32 public class CreateRuleXML {
33
34 public static void main(String[] args) {
35
36 try{
37 //иІ£жЮРеЩ®еЈ•еОВз±ї
38 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
39
40 //иІ£жЮРеЩ?/span>
41 DocumentBuilder builder = factory.newDocumentBuilder();
42
43 //жУНдљЬзЪДDocumentеѓєи±°
44 Document document = builder.newDocument();
45
46 //иЃД°љЃXMLзЪДзЙИжЬ?/span>
47 document.setXmlVersion("1.0");
48
49 //еИЫеЊПж†єиКВзВ?/span>
50 Element root = document.createElement("MobileNet");
51
52 //ЮЃЖж†єиКВзВєжЈ’dК†еИ∞Documentеѓєи±°дЄ?/span>
53 document.appendChild(root);
54
55 /**the first page*/
56 //иЃД°љЃљWђдЄАдЄ™pageеЕГзі†еИ?/span>
57 Element pageElement = document.createElement("page");
58
59 //иЃД°љЃpageиКВзВєзЪДnameе±ЮжА?/span>
60 pageElement.setAttribute("name", "list.jsp");
61
62 /**method*/
63 //иЃД°љЃmethodиКВзВє
64 Element methodElement = document.createElement("method");
65
66 //ЊlЩmethodиЃД°љЃеА?/span>
67 methodElement.setTextContent("get");
68
69 //жЈ’dК†methodиКВзВєеИ∞pageиКВзВєеЖ?/span>
70 pageElement.appendChild(methodElement);
71
72 /**display*/
73 //иЃД°љЃmethodиКВзВє
74 Element displayElement = document.createElement("display");
75
76 //ЊlЩdisplayиЃД°љЃеА?/span>
77 displayElement.setTextContent("list");
78
79 //жЈ’dК†displayиКВзВєеИ∞pageиКВзВєеЖ?/span>
80 pageElement.appendChild(displayElement);
81
82 /**request_param*/
83 //иЃД°љЃrequest_paramиКВзВє
84 Element request_paramElement = document.createElement("request_param");
85
86 //ЊlЩrequest_paramиЃД°љЃеА?/span>
87 request_paramElement.setTextContent("request_param1|request_param2");
88
89 //жЈ’dК†request_paramиКВзВєеИ∞pageиКВзВєеЖ?/span>
90 pageElement.appendChild(request_paramElement);
91
92 //ЮЃЖpageМDµеК†дЇЇж†єиКВзВєеЖ?/span>
93 root.appendChild(pageElement);
94
95
96 /**the second page*/
97 //иЃД°љЃљWђдЇМдЄ™pageеЕГзі†еИ?/span>
98 pageElement = document.createElement("page");
99
100 //иЃД°љЃpageиКВзВєзЪДnameе±ЮжА?/span>
101 pageElement.setAttribute("name", "content.jsp");
102
103 /**method*/
104 //иЃД°љЃmethodиКВзВє
105 methodElement = document.createElement("method");
106
107 //ЊlЩmethodиЃД°љЃеА?/span>
108 methodElement.setTextContent("post");
109
110 //жЈ’dК†methodиКВзВєеИ∞pageиКВзВєеЖ?/span>
111 pageElement.appendChild(methodElement);
112
113 /**display*/
114 //иЃД°љЃmethodиКВзВє
115 displayElement = document.createElement("display");
116
117 //ЊlЩdisplayиЃД°љЃеА?/span>
118 displayElement.setTextContent("content");
119
120 //жЈ’dК†displayиКВзВєеИ∞pageиКВзВєеЖ?/span>
121 pageElement.appendChild(displayElement);
122
123 /**url_title*/
124 //иЃД°љЃurl_titleиКВзВє
125 Element url_titleElement = document.createElement("url_title");
126
127 //ЊlЩurl_titleиЃД°љЃеА?/span>
128 url_titleElement.setTextContent("title,publisher,published_calendar");
129
130 //жЈ’dК†url_titleиКВзВєеИ∞pageиКВзВєеЖ?/span>
131 pageElement.appendChild(url_titleElement);
132
133 //ЮЃЖpageМDµеК†дЇЇж†єиКВзВєеЖ?/span>
134 root.appendChild(pageElement);
135
136
137 //еЉАеІЛжККDocumentжШ†е∞ДеИ∞жЦЗдї?/span>
138 TransformerFactory transFactory = TransformerFactory.newInstance();
139 Transformer transFormer = transFactory.newTransformer();
140
141 //иЃД°љЃиЊУеЗЇЊlУжЮЬ
142 DOMSource domSource = new DOMSource(document);
143
144 //зФЯжИРxmlжЦЗдЪg
145 File file = new File("MobileNetRule.xml");
146
147 //еИ§жЦ≠жШѓеР¶е≠ШеЬ®,е¶ВжЮЬдЄНе≠ШеЬ?еИЩеИЫеї?/span>
148 if(!file.exists()){
149 file.createNewFile();
150 }
151
152 //жЦЗдЪgиЊУеЗЇЛє?/span>
153 FileOutputStream out = new FileOutputStream(file);
154
155 //иЃД°љЃиЊУеЕ•жЇ?/span>
156 StreamResult xmlResult = new StreamResult(out);
157
158 //иЊУеЗЇxmlжЦЗдЪg
159 transFormer.transform(domSource, xmlResult);
160
161 //ЛєЛиѓХжЦЗдЪgиЊУеЗЇзЪДиµ\еЊ?/span>
162 System.out.println(file.getAbsolutePath());
163
164 }catch(Exception e){
165 e.printStackTrace();
166
167 }finally{
168
169 }
170 }
171
172 }
173
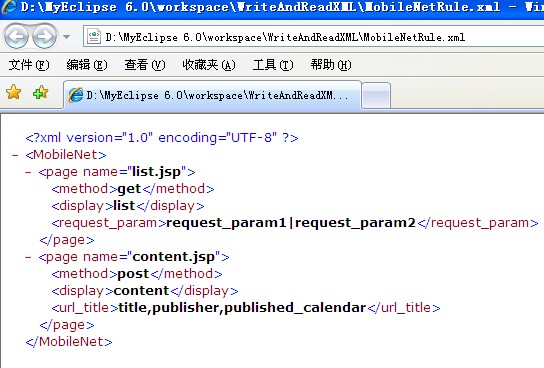
ШqРи°МжЙУеН∞зЪДеЬ∞еЭА:
D:\MyEclipse 6.0\workspace\WriteAndReadXML\MobileNetRule.xml
ЮЃЖдЄКйЭҐзЪДеЬ∞еЭАиЊУеЕ•еИ?IE)еЬ∞еЭАж†?еЊЧеИ∞е¶ВдЄЛжИ™еЫЊ:
]]>
1 package com.potevio.telecom;
2
3 //жЦЗдЪgЊc?/span>
4 import java.io.File;
5
6 //иіЯиі£иІ£жЮРзЪДз±ї
7 import javax.xml.parsers.DocumentBuilder;
8 import javax.xml.parsers.DocumentBuilderFactory;
9
10 //иКВзВєЊc?/span>
11 import org.w3c.dom.Document;
12 import org.w3c.dom.NodeList;
13
14 /**
15 * @description иІ£жЮР"еМЧдЇђеИ∞йХњж≤ЩзЪДљОАеНХеИЧиљ¶жЧґеИїи°®"дњ°жБѓ
16 *
17 * @author Zhou-Jingxian
18 *
19 * @date Jun 18, 2009
20 *
21 */
22 public class ParserXML {
23
24 public static void main(String[] args) {
25
26 try{
27 //йЬАи¶БиІ£жЮРзЪДжЦЗдЪg
28 File file = new File("еМЧдЇђеИ∞йХњж≤ЩзБЂиљ¶жЧґеИїи°®.xml");
29
30 //иІ£жЮРеЩ®еЈ•еОВз±ї
31 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
32
33 //иІ£жЮРеЩ?/span>
34 DocumentBuilder builder = factory.newDocumentBuilder();
35
36 //жУНдљЬзЪДDocumentеѓєи±°
37 Document document = builder.parse(file);
38
39 //иКВзВєеРНзІ∞
40 NodeList nodelist = document.getElementsByTagName("иљ¶жђ°");
41
42 //иІ£жЮРеЖЕеЃє
43 for(int i = 0; i<nodelist.getLength(); i++){
44 System.out.println("--------"+(i+1)+"---------");
45 System.out.println("иљ¶з±їеИ?"+document.getElementsByTagName("иљ¶жђ°").item(i).getAttributes().getNamedItem("Њc’dИЂ").getNodeValue());
46 System.out.println("иљ¶жђ°еП?"+document.getElementsByTagName("еРНе≠Ч").item(i).getFirstChild().getNodeValue());
47 System.out.println("еЉАиљ¶жЧґйЧ?"+document.getElementsByTagName("еЉАиљ¶жЧґйЧ?/span>").item(i).getFirstChild().getNodeValue());
48
49 }
50 }catch(Exception e){
51 e.printStackTrace();
52
53 }finally{
54
55 }
56 }
57 }
58
2
3 //жЦЗдЪgЊc?/span>
4 import java.io.File;
5
6 //иіЯиі£иІ£жЮРзЪДз±ї
7 import javax.xml.parsers.DocumentBuilder;
8 import javax.xml.parsers.DocumentBuilderFactory;
9
10 //иКВзВєЊc?/span>
11 import org.w3c.dom.Document;
12 import org.w3c.dom.NodeList;
13
14 /**
15 * @description иІ£жЮР"еМЧдЇђеИ∞йХњж≤ЩзЪДљОАеНХеИЧиљ¶жЧґеИїи°®"дњ°жБѓ
16 *
17 * @author Zhou-Jingxian
18 *
19 * @date Jun 18, 2009
20 *
21 */
22 public class ParserXML {
23
24 public static void main(String[] args) {
25
26 try{
27 //йЬАи¶БиІ£жЮРзЪДжЦЗдЪg
28 File file = new File("еМЧдЇђеИ∞йХњж≤ЩзБЂиљ¶жЧґеИїи°®.xml");
29
30 //иІ£жЮРеЩ®еЈ•еОВз±ї
31 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
32
33 //иІ£жЮРеЩ?/span>
34 DocumentBuilder builder = factory.newDocumentBuilder();
35
36 //жУНдљЬзЪДDocumentеѓєи±°
37 Document document = builder.parse(file);
38
39 //иКВзВєеРНзІ∞
40 NodeList nodelist = document.getElementsByTagName("иљ¶жђ°");
41
42 //иІ£жЮРеЖЕеЃє
43 for(int i = 0; i<nodelist.getLength(); i++){
44 System.out.println("--------"+(i+1)+"---------");
45 System.out.println("иљ¶з±їеИ?"+document.getElementsByTagName("иљ¶жђ°").item(i).getAttributes().getNamedItem("Њc’dИЂ").getNodeValue());
46 System.out.println("иљ¶жђ°еП?"+document.getElementsByTagName("еРНе≠Ч").item(i).getFirstChild().getNodeValue());
47 System.out.println("еЉАиљ¶жЧґйЧ?"+document.getElementsByTagName("еЉАиљ¶жЧґйЧ?/span>").item(i).getFirstChild().getNodeValue());
48
49 }
50 }catch(Exception e){
51 e.printStackTrace();
52
53 }finally{
54
55 }
56 }
57 }
58
ШqРи°МЊlУжЮЬе¶ВдЄЛ:
]]>
1 package com.potevio.telecom;
2
3 //жЦЗдЪgЊc?/span>
4 import java.io.File;
5 import java.io.FileNotFoundException;
6
7 //жЦЗдЪgиЊУеЗЇЊc?/span>
8 import java.io.FileOutputStream;
9 import java.io.IOException;
10
11 //иіЯиі£иІ£жЮРзЪДз±ї
12 import javax.xml.parsers.DocumentBuilder;
13 import javax.xml.parsers.DocumentBuilderFactory;
14 import javax.xml.parsers.ParserConfigurationException;
15
16 //жШ†е∞ДЊc?/span>
17 import javax.xml.transform.Transformer;
18 import javax.xml.transform.TransformerConfigurationException;
19 import javax.xml.transform.TransformerException;
20 import javax.xml.transform.TransformerFactory;
21
22 //xmlжШ†е∞ДиЊУеЕ•еТМиЊУеЗЇз±ї
23 import javax.xml.transform.dom.DOMSource;
24 import javax.xml.transform.stream.StreamResult;
25
26 //иКВзВєЊc?/span>
27 import org.w3c.dom.Comment;
28 import org.w3c.dom.Document;
29 import org.w3c.dom.Element;
30 import org.w3c.dom.Node;
31 import org.w3c.dom.NodeList;
32
33 /**
34 * @description жЮДйА†дЄАдЄ™еМЧдЇђеИ∞йХњж≤ЩзЪДзЃАеНХеИЧиљ¶жЧґеИїи°®.зФ®DOMзЪДжЦєеЉПеЃЮзО?
35 *
36 * @author Zhou-Jingxian
37 *
38 * @date Jun 18, 2009
39 *
40 */
41 public class CreateXMLContent {
42
43 public static void main(String args[]){
44
45 try {
46 //жЮДйА†зЪДеОЯеІЛжХ∞жНЃеѓєи±°
47 String train[] = {"T1Л∆?/span>","K185Л∆?/span>","Z17Л∆?/span>"};
48 String type[] = {"зЙєењЂ","жЩЃењЂ","зЫіиЊЊ"};
49 String startTime[] = {"15:45","11:47","18:10"};
50
51 //иІ£жЮРеЩ®еЈ•еОВз±ї
52 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
53
54 //иІ£жЮРеЩ?/span>
55 DocumentBuilder builder = factory.newDocumentBuilder();
56
57 //жУНдљЬзЪДDocumentеѓєи±°
58 Document document = builder.newDocument();
59
60 //иЃД°љЃXMLзЪДзЙИжЬ?/span>
61 document.setXmlVersion("1.0");
62
63 //жЈ’dК†ж≥®йЗК
64 Comment xmlComment = document.createComment("жЬђжЦЗж°£дЄ≠еЖЕеЃєдЄїи¶БзФ®дЇОЛєЛиѓХеQ?/span>");
65
66 //ЮЃЖж≥®йЗКжЈїеК†еИ∞xmlдЄ?/span>
67 document.appendChild(xmlComment);
68
69 //иЃД°љЃж†єиКВзВєеРНњU?/span>
70 Element traintimelist = document.createElement("зБЂиЮRжЧґеИїи°?/span>");
71
72 //жККиКВзВ“О(gu®©)ЈїеК†еИ∞ж†єиКВзВ?/span>
73 document.appendChild(traintimelist);
74
75 for(int k = 1; k <=train.length; k++){
76 traintimelist.appendChild(document.createElement("иљ¶жђ°"));
77 }
78
79 NodeList nodeList = document.getElementsByTagName("иљ¶жђ°");
80 int size = nodeList.getLength();
81 for(int k = 0; k<size; k++){
82 Node node = nodeList.item(k);
83 if(node.getNodeType() == Node.ELEMENT_NODE){
84 Element elementNode = (Element)node;
85 elementNode.setAttribute("Њc’dИЂ", type[k]);
86 elementNode.appendChild(document.createElement("еРНе≠Ч"));
87 elementNode.appendChild(document.createElement("еЉАиљ¶жЧґйЧ?/span>"));
88
89 }
90 }
91
92 nodeList = document.getElementsByTagName("еРНе≠Ч");
93 size = nodeList.getLength();
94 for(int k = 0; k<size; k++){
95 Node node = nodeList.item(k);
96 if(node.getNodeType() == Node.ELEMENT_NODE){
97 Element elementNode = (Element)node;
98 elementNode.appendChild(document.createTextNode(train[k]));
99
100 }
101 }
102
103 nodeList = document.getElementsByTagName("еЉАиљ¶жЧґйЧ?/span>");
104 size = nodeList.getLength();
105 for(int k = 0; k<size; k++){
106 Node node = nodeList.item(k);
107 if(node.getNodeType() == Node.ELEMENT_NODE){
108 Element elementNode = (Element)node;
109 elementNode.appendChild(document.createTextNode(startTime[k]));
110
111 }
112 }
113
114 //еЉАеІЛжККDocumentжШ†е∞ДеИ∞жЦЗдї?/span>
115 TransformerFactory transFactory = TransformerFactory.newInstance();
116 Transformer transformer = transFactory.newTransformer();
117
118 //иЃД°љЃиЊУеЗЇЊlУжЮЬ
119 DOMSource domSource = new DOMSource(document);
120
121 //зФЯжИРxmlжЦЗдЪg
122 File file = new File("еМЧдЇђеИ∞йХњж≤ЩзБЂиљ¶жЧґеИїи°®.xml");
123
124 //еИ§жЦ≠жШѓеР¶е≠ШеЬ®,е¶ВжЮЬдЄНе≠ШеЬ?еИЩеИЫеї?/span>
125 if(!file.exists()){
126 file.createNewFile();
127 }
128
129 //жЦЗдЪgиЊУеЗЇЛє?/span>
130 FileOutputStream out = new FileOutputStream(file);
131
132 //иЃД°љЃиЊУеЕ•жЇ?/span>
133 StreamResult xmlResult = new StreamResult(out);
134
135 //иЊУеЗЇxmlжЦЗдЪg
136 transformer.transform(domSource, xmlResult);
137
138 //ЛєЛиѓХжЦЗдЪgиЊУеЗЇзЪДиµ\еЊ?/span>
139 System.out.println(file.getAbsolutePath());
140
141 } catch (ParserConfigurationException e) {
142
143 e.printStackTrace();
144 } catch (TransformerConfigurationException e) {
145
146 e.printStackTrace();
147 } catch (FileNotFoundException e) {
148
149 e.printStackTrace();
150 } catch (TransformerException e) {
151
152 e.printStackTrace();
153 } catch (IOException e) {
154
155 e.printStackTrace();
156
157 }finally{
158
159 }
160
161 }
162 }
163
2
3 //жЦЗдЪgЊc?/span>
4 import java.io.File;
5 import java.io.FileNotFoundException;
6
7 //жЦЗдЪgиЊУеЗЇЊc?/span>
8 import java.io.FileOutputStream;
9 import java.io.IOException;
10
11 //иіЯиі£иІ£жЮРзЪДз±ї
12 import javax.xml.parsers.DocumentBuilder;
13 import javax.xml.parsers.DocumentBuilderFactory;
14 import javax.xml.parsers.ParserConfigurationException;
15
16 //жШ†е∞ДЊc?/span>
17 import javax.xml.transform.Transformer;
18 import javax.xml.transform.TransformerConfigurationException;
19 import javax.xml.transform.TransformerException;
20 import javax.xml.transform.TransformerFactory;
21
22 //xmlжШ†е∞ДиЊУеЕ•еТМиЊУеЗЇз±ї
23 import javax.xml.transform.dom.DOMSource;
24 import javax.xml.transform.stream.StreamResult;
25
26 //иКВзВєЊc?/span>
27 import org.w3c.dom.Comment;
28 import org.w3c.dom.Document;
29 import org.w3c.dom.Element;
30 import org.w3c.dom.Node;
31 import org.w3c.dom.NodeList;
32
33 /**
34 * @description жЮДйА†дЄАдЄ™еМЧдЇђеИ∞йХњж≤ЩзЪДзЃАеНХеИЧиљ¶жЧґеИїи°®.зФ®DOMзЪДжЦєеЉПеЃЮзО?
35 *
36 * @author Zhou-Jingxian
37 *
38 * @date Jun 18, 2009
39 *
40 */
41 public class CreateXMLContent {
42
43 public static void main(String args[]){
44
45 try {
46 //жЮДйА†зЪДеОЯеІЛжХ∞жНЃеѓєи±°
47 String train[] = {"T1Л∆?/span>","K185Л∆?/span>","Z17Л∆?/span>"};
48 String type[] = {"зЙєењЂ","жЩЃењЂ","зЫіиЊЊ"};
49 String startTime[] = {"15:45","11:47","18:10"};
50
51 //иІ£жЮРеЩ®еЈ•еОВз±ї
52 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
53
54 //иІ£жЮРеЩ?/span>
55 DocumentBuilder builder = factory.newDocumentBuilder();
56
57 //жУНдљЬзЪДDocumentеѓєи±°
58 Document document = builder.newDocument();
59
60 //иЃД°љЃXMLзЪДзЙИжЬ?/span>
61 document.setXmlVersion("1.0");
62
63 //жЈ’dК†ж≥®йЗК
64 Comment xmlComment = document.createComment("жЬђжЦЗж°£дЄ≠еЖЕеЃєдЄїи¶БзФ®дЇОЛєЛиѓХеQ?/span>");
65
66 //ЮЃЖж≥®йЗКжЈїеК†еИ∞xmlдЄ?/span>
67 document.appendChild(xmlComment);
68
69 //иЃД°љЃж†єиКВзВєеРНњU?/span>
70 Element traintimelist = document.createElement("зБЂиЮRжЧґеИїи°?/span>");
71
72 //жККиКВзВ“О(gu®©)ЈїеК†еИ∞ж†єиКВзВ?/span>
73 document.appendChild(traintimelist);
74
75 for(int k = 1; k <=train.length; k++){
76 traintimelist.appendChild(document.createElement("иљ¶жђ°"));
77 }
78
79 NodeList nodeList = document.getElementsByTagName("иљ¶жђ°");
80 int size = nodeList.getLength();
81 for(int k = 0; k<size; k++){
82 Node node = nodeList.item(k);
83 if(node.getNodeType() == Node.ELEMENT_NODE){
84 Element elementNode = (Element)node;
85 elementNode.setAttribute("Њc’dИЂ", type[k]);
86 elementNode.appendChild(document.createElement("еРНе≠Ч"));
87 elementNode.appendChild(document.createElement("еЉАиљ¶жЧґйЧ?/span>"));
88
89 }
90 }
91
92 nodeList = document.getElementsByTagName("еРНе≠Ч");
93 size = nodeList.getLength();
94 for(int k = 0; k<size; k++){
95 Node node = nodeList.item(k);
96 if(node.getNodeType() == Node.ELEMENT_NODE){
97 Element elementNode = (Element)node;
98 elementNode.appendChild(document.createTextNode(train[k]));
99
100 }
101 }
102
103 nodeList = document.getElementsByTagName("еЉАиљ¶жЧґйЧ?/span>");
104 size = nodeList.getLength();
105 for(int k = 0; k<size; k++){
106 Node node = nodeList.item(k);
107 if(node.getNodeType() == Node.ELEMENT_NODE){
108 Element elementNode = (Element)node;
109 elementNode.appendChild(document.createTextNode(startTime[k]));
110
111 }
112 }
113
114 //еЉАеІЛжККDocumentжШ†е∞ДеИ∞жЦЗдї?/span>
115 TransformerFactory transFactory = TransformerFactory.newInstance();
116 Transformer transformer = transFactory.newTransformer();
117
118 //иЃД°љЃиЊУеЗЇЊlУжЮЬ
119 DOMSource domSource = new DOMSource(document);
120
121 //зФЯжИРxmlжЦЗдЪg
122 File file = new File("еМЧдЇђеИ∞йХњж≤ЩзБЂиљ¶жЧґеИїи°®.xml");
123
124 //еИ§жЦ≠жШѓеР¶е≠ШеЬ®,е¶ВжЮЬдЄНе≠ШеЬ?еИЩеИЫеї?/span>
125 if(!file.exists()){
126 file.createNewFile();
127 }
128
129 //жЦЗдЪgиЊУеЗЇЛє?/span>
130 FileOutputStream out = new FileOutputStream(file);
131
132 //иЃД°љЃиЊУеЕ•жЇ?/span>
133 StreamResult xmlResult = new StreamResult(out);
134
135 //иЊУеЗЇxmlжЦЗдЪg
136 transformer.transform(domSource, xmlResult);
137
138 //ЛєЛиѓХжЦЗдЪgиЊУеЗЇзЪДиµ\еЊ?/span>
139 System.out.println(file.getAbsolutePath());
140
141 } catch (ParserConfigurationException e) {
142
143 e.printStackTrace();
144 } catch (TransformerConfigurationException e) {
145
146 e.printStackTrace();
147 } catch (FileNotFoundException e) {
148
149 e.printStackTrace();
150 } catch (TransformerException e) {
151
152 e.printStackTrace();
153 } catch (IOException e) {
154
155 e.printStackTrace();
156
157 }finally{
158
159 }
160
161 }
162 }
163
ШqРи°МзЪДжЙУеН∞еЬ∞еЭА:
D:\MyEclipse 6.0\workspace\WriteAndReadXML\еМЧдЇђеИ∞йХњж≤ЩзБЂиљ¶жЧґеИїи°®.xml
ЮЃЖдЄКйЭҐзЪДеЬ∞еЭАжФС÷И∞(IE)еЬ∞еЭАж†ПжШЊљCЇзЪДжХИжЮЬеЫЊдЄЛ:
]]>