
(一)問題
項目中需要對文件做md5sum,分兩步走:1、對文件流的每個字節用md5實例進行update,然后進行digest。2、digest返回長度為16的byte數組,一般我們需要把byte數組轉成16進制字符串(很多開源的md5加密算法如此實現,真正的原因還不是很理解,可能是便于查看和傳輸)。具體的實現代碼如下:
/**
* 對文件進行md5 sum操作
* @param checkFile 要進行做md5 sum的文件
* @return
*/
public static String md5sum(File checkFile){
String md5sumResult = "";
if(checkFile == null || (!checkFile.exists())){
return md5sumResult;
}
MessageDigest digest = MessageDigest.getInstance("MD5");
InputStream is = new FileInputStream(checkFile);
byte[] buffer = new byte[8192];
int read = 0;
try {
while( (read = is.read(buffer)) > 0) {
digest.update(buffer, 0, read);
}
byte[] md5sum = digest.digest();
BigInteger bigInt = new BigInteger(1, md5sum);
md5sumResult = bigInt.toString(16);
}
catch(IOException e) {
throw new RuntimeException("Unable to process file for MD5", e);
}
finally {
try {
is.close();
}
catch(IOException e) {
throw new RuntimeException("Unable to close input stream for MD5 calculation", e);
}
}
return md5sumResult;
}
其中黃色背景色的轉換方式是有問題的。為什么用bigint轉16進制會有問題呢,原因是bigint進行16進制轉換的時候第一個0被自動去掉了.
(二)正確解決方式
那正確的方式是怎么樣的呢?下面有兩種不同的轉換方式,但是原理其實是一致的。
第一種正確的方式(由王建提供):
/**
* 將字節數組轉換為16進制字符串
*
* @param buffer
* @return
*/
public static String toHex(byte[] buffer) {
StringBuffer sb = new StringBuffer(buffer.length * 2);
for (int i = 0; i < buffer.length; i++) {
sb.append(Character.forDigit((buffer[i] & 240) >> 4, 16));
sb.append(Character.forDigit(buffer[i] & 15, 16));
}
return sb.toString();
}
第二種正確的方式:
public static String bytes2HexString(byte[] b) {
String ret = "";
for (int i = 0; i < b.length; i++) {
String hex = Integer.toHexString(b[i] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
ret += hex;
}
return ret;
}
(三)問題分析
Md5算法對任何長度的字符串進行編碼最后輸出是128位長整數,也就是長度為16的byte數組。我們項目調用的是jdk實現的md5算法,所以一般是沒問題的。
接下來我們要處理的事情,分別循環數組,把每個字節轉換成2個16進制字符,也就是說每4位轉成一個16進制字符。
上面正確的兩種方式也就是做了這樣的事情。
第一種方式:
Character.forDigit((buffer[i] & 240) >> 4, 16)把字節的高4位取出右移4位換算成int,然后通過forDigit轉換成16進制字符
Character.forDigit(buffer[i] & 15, 16)把字節的低4位取出換算成int,然后通過forDigit轉換成16進制字符
第二種方式:
Integer.toHexString(b[i] & 0xFF)把整個字節轉成int,然后toHexString也就是做高4位和低4位的運算。但是這個方法如果高四位是0的話就不輸出任何東西,
所以在輸出的字符前加0即可。
b[i] & 0xFF就是把byte轉成int,為什么用與oxff做與運算,是因為如果b[i]是負數的話,從8位變成32位會補1,所以需要與0xff做與運算,可以把前面的24位全部清零,又可以表示成原來的字節了。
附:
盡量使用開源提供的工具包,比如:
org.apache.commons.codec.digest.DigestUtils.md5Hex(InputStream data)來對文件流進行md5即可,更加方便,可靠。
早期的java程序員可能只要懂基本語法,還有少數的項目經驗就可以找到一份比較好的工作。Java和java社區的發展,更多的人了解它,深入它。現在java程序員了解一些語法我看還遠遠不夠了,對于jvm的了解和深入是非常重要的。網民的增多,網站的剛性需求,很多網站面臨高性能,高并發等等一系列的問題。沒有深入jvm的java程序員是很難寫出高質量高并發的代碼(也許一棒子打死所有人了,但我想絕大部分是肯定的)。
Osgi也許你并不陌生,但是他底層的實現機制你可能沒去了解過。如果你是個打破砂鍋問到底的人,你肯定會想知道osgi是如何做到的。但是你沒有了解jvm的類加載體系,你肯定很難理解osgi是如果做到類隔離等一系列的問題。不過想完整理解osgi還需要其他很多方面的知識,但是它基本的機制還是的了解jvm的類加載機制。
Java類庫有些包只是定義了一個標準,具體的實現都是由具體的供應商來提供。Java與數據庫連接就是一個很好的例子。Java.sql類庫只是定義了java與數據庫連接的標準,那么與mysql就需要msyql的驅動,oracle就需要oracle的驅動,而java.sql類庫是由bootstrap classloader加載,驅動包中的類是由system classloader來加載,不同類加載器加載的類是無法相互認識,所以自然也無法正常提供功能了。jvm又是提供了什么機制讓他們交互呢?如果你確實對這些問題毫無頭緒的話,那么我覺得你真的要好好理解下jvm類加載體系。
這篇文章主要是介紹下jvm類加載的機制基礎知識。關于其他相關涉及,有時間的話,我會單獨寫文章來介紹。
1、 java類加載器

1.1 Bootstrap classloader:sun jdk是用c++實現,所以在代碼中你是無法獲取此加載器的實例。此加載器主要負責加載$JAVA_HOME/jre/lib/rt.jar。java類中獲取結果為null,這里可以用一個例子跑下證明:
public class Test {
public static void main(String[] arg) throws Exception{
ClassLoader classloader = Test.class.getClassLoader();
System.out.println(classloader);
System.out.println(classloader.getParent());
System.out.println(classloader.getParent().getParent());
}
}
輸出結果:
sun.misc.Launcher$AppClassLoader@19821f
sun.misc.Launcher$ExtClassLoader@addbf1
null
最后輸出的null就是代表bootstrap classloader。
1.2 Extension classloader:主要加載擴展功能的jar,$JAVA_HOME/jre/lib/ext/*.jar。
1.3 System classloader:加載claspath中的jar包。
1.4自定義 classloader:主要加載你指定的目錄中的包和類。
2、 雙親委派模型
系統運行時,我們請求加載String類,此時System Classloader自己不找classpath中的包,把請求轉發給Extension Classloader,但它也不做查找,又轉發給Bootstrap Classloader,但是它發現自己沒有parent了。于是他在rt.jar包中找到String類并加載到jvm中提供使用。Jvm為什么要這么實現呢?其實和java安全體系有關。假設jvm不是這么實現,我們自定義一個String類,做一些破壞,那么運行jvm的機器肯定要受到損壞。具體例子:
public class String {
public static void main(String[] args) {
System.out.println("hello world");
}
}
我們運行自定義String類的時候報錯了,說沒有main方法,可我們定義的明明有的,嘿嘿,委派機制的緣故最后加載到的是由bootstrap classloader在rt.jar包中的String,那個類是沒有main方法,因此報錯了。

3、 類隔離
jvm中的類是:類加載器+包名+類名。比如:URLClassLoader1,URLClassLoader2分別加載com.test.Test的時候會加載兩次,因為每個classloader中的類對于其他classloader來說是隔離的,不認識的。例子:
import java.net.URL;
import java.net.URLClassLoader;
public class CustomClassloaderTest {
public static void main(String[] args) throws Exception {
URL url = new URL("file:/g:/");
URLClassLoader ucl = new URLClassLoader(new URL[]{url});
Class c = ucl.loadClass("Yang");
c.newInstance();
System.out.println(c.getClassLoader());
URLClassLoader ucl2 = new URLClassLoader(new URL[]{url});
Class c2 = ucl2.loadClass("Yang");
c2.newInstance();
System.out.println(c2.getClassLoader());
}
}
大家把Yang類存在g盤下。
public class Yang {
static {
System.out.println("Yang");
}
}
運行結果:
Yang
java.net.URLClassLoader@c17164
Yang
java.net.URLClassLoader@61de33
看到每次加載Yang類的時候都輸出Yang,說明Yang類被加載了兩次。
如果你不確信,可以修改下代碼,讓同一classloader加載Yang類兩次
import java.net.URL;
import java.net.URLClassLoader;
public class CustomClassloaderTest {
public static void main(String[] args) throws Exception {
URL url = new URL("file:/g:/");
URLClassLoader ucl = new URLClassLoader(new URL[]{url});
Class c = ucl.loadClass("Yang");
c.newInstance();
System.out.println(c.getClassLoader());
Class c2 = ucl.loadClass("Yang");
c2.newInstance();
System.out.println(c2.getClassLoader());
}
}
看看輸出結果:
Yang
java.net.URLClassLoader@c17164
java.net.URLClassLoader@c17164
結果中只輸出了一次Yang。因此可以證明我們最開始說的類隔離。
4、 線程上下文類加載器
我們理解了雙親委派模型,那么目前只有由下向上單向尋找類(system->extension->bootstrap)
。我們在最開始的時候說過,java.sql包中的類由bootstrap或extension classloader加載,而mysql驅動包是在classpath中由system來加載,但bootstrap中的類是無法找到system classloader中的類,此時靠線程上下文類加載器來解決。線程上下文類加載器主要就是能讓jvm類加載模型具有了向下尋找的可能,bootstrap->extension->system,如果不做任何設置,線程上下文類加載器默認是system classloader。本來這里想寫一個例子的,可是有點麻煩,所以下次單獨寫一篇關于這方面的知識。
以前我在小公司,完成項目功能是終極目標。開發人員很害怕需求變化,因為他們改怕了。那問題出在哪里呢?后來我仔細想想,是沒有做測試造成。那開發人員為什么如此害怕需求變化,我舉個例子,a服務給b服務和c服務調用,后來需求改變,導致a服務無法滿足b服務,能完成自身的功能是天大的事,于是沒有和別人溝通把a服務直接改了。項目上線,突然有一天客戶打電話說你們網站這里出問題,那里出問題,以前都不會的啊。你們怎么弄的。于是根據頁面錯誤信息,開發人員很快找到錯誤根源,原來a服務改動,導致b服務不正常。而d,e,f服務依賴于b,那么導致d,e,f相關功能都出錯了。立馬動手改,改完上線,能知道的問題都沒了,哈哈,真高興,可是不能高興太早哇,也許還有潛在bug。
軟件的bug是無法避免,但是我們可以盡量減少bug,不斷提升代碼質量。剛我也說過,上述問題造成的原因是沒有做測試。測試包括很多了,單元測試、集成測試和功能測試等等。既然測試如此重要,每完成一個類都能進行測試。
以前也許你比較糾結,沒有好的工具,現在java社區非常活躍,我們可以選擇的太多太多了:junit4,jmock,mockito,easymock,TestNg等等。如果你用過grails,那么你更清楚,此類快速開發框架已經幫我們集成好了。使用起來非常簡單。所以今天我主要講述下grails的單元測試。
假設需求:我們給每個用戶分配工作,每個人都要完成兩件事情,第一件事情:根據自己的用戶名返回歡迎信息;第二件事情:根據自己的地址返回國家地區。
詳細設計
用戶信息類:
package com.test.domian
class User {
int id
String name
String address
static constraints = {
}
}
工作服務接口:
package com.test.services
class WorkService {
/**
* 根據用戶名返回歡迎字符
* @param userName
* @return
*/
def processWorkOne(String userName) {
}
/**
* 根據地址返回地區
* @param address
* @return
*/
def processWorkTwo(String address){
}
}
用戶工作服務:
package com.test.services
import com.test.domian.User
class UserService {
def workService
def doWork() {
def userList = User.list()
userList.each {
it.name = workService.processWorkOne(it.name)
it.address = workService.processWorkTwo(it.address)
}
}
}
我們重點來看下測試類:
package com.test.services
import grails.test.*
import com.test.domian.User
class UserServiceTests extends GrailsUnitTestCase {
protected void setUp() {
super.setUp()
}
protected void tearDown() {
super.tearDown()
}
void testDoWork() {
//構造數據,類似于數據庫存在三條記錄
def user1 = new User(id:1, name:"lucy", address:"hangzhou")
def user2 = new User(id:2, name:"lily", address:"wenzhou")
def user3 = new User(id:3, name:"lilei", address:"beijing")
mockDomain User, [user1, user2, user3]
//mock WorkService接口的processWorkOne方法和processWorkTwo方法
def workControl = mockFor(WorkService)
def userCount = User.count()
while(userCount-- > 0){
workControl.demand.processWorkOne(1..1){String userName ->
return "hello world, " << userName
}
workControl.demand.processWorkTwo(1..1){String address ->
return "location in " << address
}
}
def workService = workControl.createMock()
//把構造好的workservice傳給userservice
UserService userService = new UserService()
userService.workService = workService
userService.doWork()
def user4 = User.findById(1)
assertEquals "hello world, lucy", user4.name
assertEquals "location in hangzhou", user4.address
}
}
以下著重來具體說明:
1、
mockDomain方法就是構造數據,包括domain類的動態方法都可以使用,比如:save(),list(),findby*()等。代碼中的User.count(); User.list();就是因為調用了mockDomain方法才可以正常使用。如果是集成測試的話,grails會幫我們構造好,可以直接使用。但這里是單元測試,所以需要自己mock。
2、mockFor方法就是給WorkService構造一個對象,然后給workControl對象的demand代理創建兩個UserService中用的processWorkOne和processWorkTwo方法,代碼中用到了1..1,表示mock對象只能調用這個方法一次,為什么要循環三次設置processWorkOne和processWorkTwo方法呢?因為我們在UserService是對三個對象分別進行調用處理這兩件事情。也許你會想,干嘛不直接把1..3(最少調用一次,最多調用三次)。是的,我最開始也是這么來處理,可是單元測試就是同不過。
如果把UserService類中的
workControl.demand.processWorkOne(1..1){String userName ->
return "hello world, " << userName
}
改成
workControl.demand.processWorkOne(1..3){String userName ->
return "hello world, " << userName
}
然后把
UserServiceTests類中的:
userList.each {
it.name = workService.processWorkOne(it.name)
it.address = workService.processWorkTwo(it.address)
}
改成
userList.each {
it.name = workService.processWorkOne(it.name)
it.name = workService.processWorkOne(it.name)
it.name = workService.processWorkOne(it.name)
it.address = workService.processWorkTwo(it.address)
}
單元測試可以通過,但是改成這樣
userList.each {
it.name = workService.processWorkOne(it.name)
it.name = workService.processWorkOne(it.name)
it.address = workService.processWorkTwo(it.address)
it.name = workService.processWorkOne(it.name)
}
單元測試通不過。
以上就是表明1..3的含義:這個方法要連續被調用至少一次,至多三次。
但是有的人說我在UserService中就要這么寫
userList.each {
it.name = workService.processWorkOne(it.name)
it.name = workService.processWorkOne(it.name)
it.address = workService.processWorkTwo(it.address)
it.name = workService.processWorkOne(it.name)
}
那我要怎么改單元測試才能通過?
我們把UserServiceTests的demand這段代碼
workControl.demand.processWorkOne(1..1){String userName ->
return "hello world, " << userName
}
workControl.demand.processWorkTwo(1..1){String address ->
return "location in " << address
}
改成
workControl.demand.processWorkOne(1..2){String userName ->
return "hello world, " << userName
}
workControl.demand.processWorkTwo(1..1){String address ->
return "location in " << address
}
workControl.demand.processWorkOne(1..1){String address ->
return "location in " << address
}
這樣就通過了。
以上就是說明構造出來的函數只能按照構造的順序調用。今天就是因為這個花了我好長時間啊,希望我理解是正確的。如有不對,請留言糾正。
Grails工程與maven集成
Grails其實也有自己的一些項目管理命令,如:grails package,grails test-app,grails war等。但是公司現在基本上都是用maven來管理項目,所以從管理上進行統一的目的,我們也讓grails工程由maven來管理。
Grails與maven集成是靠maven插件機制。
接下來描述下集成的步驟:
1、在$home/.m2/settings.xml中配置plugin group
<settings>
…
<pluginGroups>
<pluginGroup>org.grails</pluginGroup>
</pluginGroups>
</settings>
沒有配置之前,要運行grails:help命令要這樣寫:mvn org.grails:help,有了配置之后我們就可以這么寫:mvn grails:help。
2、我們創建一個maven管理的grails工程
Mvn org.apache.maven.plugins:maven-archetype-plugin:2.0-alpha-4:generate
-DarchetypeGroupId=org.grails
-DarchetypeArtifactId=grails-maven-archetype
-DarchetypeVersion=1.2.0
-DgroupId=example -DartifactId=my-app
grails-maven-archetype這里用的是1.2.0版本,好像maven3集成的版本比這個要新。
3、進入my-app當前目錄,運行mvn initialize
在運行過程中可能會出現如下問題:
Resolving plugin JAR dependencies …
:: problems summary ::
:::: WARNINGS
module not found: org.hibernate#hibernate-core;3.3.1.GA
那么你在application.properties文件中添加plugins.hibernate=1.3.2
plugins.tomcat=1.3.2兩個插件。最后運行mvn compile重新編譯工程。
4、我們是用springsource tool suite開發,導入工程。項目中需要對excel操作,我們采用jxl.jar開源包。在pom文件中配置如下內容:
<dependency>
<groupId>jxl</groupId>
<artifactId>jxl</artifactId>
<version>2.4.2</version>
</dependency>
重新編譯下工程,但是引用jxl包中類的文件還是報錯,說找不到類。這怎么回事呢?我也很納悶,一般maven工程都是這樣就可以。
后來在官方文檔上看到一句話:pom=true。只要把這句話加到conf/BuildConfig.groovy文件中的grails.project.dependency.resolution方法中。如圖:
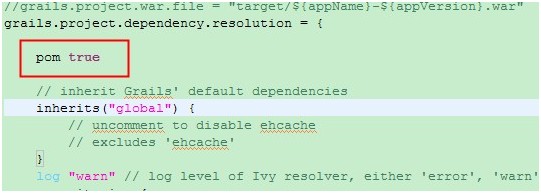
重新編譯,但是還是報錯。Ide還是無法引用jxl包中的類。后來發現在grails tools中找到了一個命令。
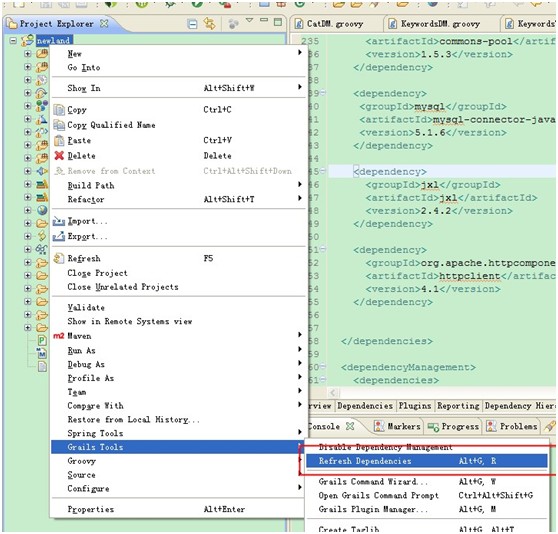
執行過后,已經加入到了grails dependencies中。
為什么會這樣呢,是因為有兩套機制造成的。
第一套機制:maven自身管理項目的機制。
第二套機制:grails也有自己的一套管理機制。
l 在絕大多數情況下maven通過grails的集成插件可以對工程進行打包,部署,運行測試等管理。
l Grails可以通過自己的grails war等命令進行打包,部署,運行測試等管理。
l Grails也可以通過配置pom=true讓grails那套管理機制用pom中的配置,不使用自己的管理機制。此時你就不用在conf/BuildConfig.groovy中管理依賴和資源庫等配置。
大學期間,我熱愛觀看央視“贏在中國”節目。學到了很多做事的方法和做人的方式,雖然對于什么是創業,在創業中會遇到什么問題等等一些都未知,但那份年輕人的沖動和對于創業的興奮已經被激發到極點。畢業找工作,我毅然選擇了一家從事旅游行業的創業型互聯網小公司。
面試階段,一個相互選擇的階段。在大學期間,我運用J2EE技術給某朋友成功建立一家從事游戲虛擬物品交易平臺,無形中已經培養了一定的需求溝通,需求挖掘,設計,項目管理等能力。加上我是一張“白紙”(價值觀等都未受到任何公司的影響)和對于創業的那份沖勁。老板理所當然的選擇了我,由我來負責一個項目的全部工作。公司給我提供我認為過得去的工資,也是我所喜好的創業型小公司,我認為很有前途(年少無知,不知后路的艱辛)。我也選擇了公司。這就是我第一家的公司。
工作階段,充當孫悟空的階段。最簡單的開發模式,最簡單的項目管理方式,最簡單的上線過程,最簡單的線上故障處理。一切都是那么簡單。簡單的讓我換第二份工作的時候讓人覺得這幾年的工作都毫無進步可言。
簡單的開發模式,老板一個概念的產生,沒有產品,直接拋到開發,開發要么模仿別人的網站要么自己捉摸該怎么實現,然后進入編碼,沒有代碼review,沒有單元測試,沒有回歸測試,不關注代碼風格,不注重代碼質量。功能實現了就算完了。后來改進,有產品分析設計產生prd,開發人員按照prd進行開發,有時進行部分重構,代碼質量也沒有太多的提升。
簡單的項目管理方式,概念出來,開發人員大致揣測出老板的意圖之后,開始分模塊,估算時間,分配人員功能模塊。老板看到項目時間需要3個月,老板對我們說,不可能需要這么長時間吧,給你們一個月半的時間給我完成吧,最后經過討價還價,老板說再加半個月,你們不能再說了,最后我們被老板“強奸”了。項目也有版本控制,但是沒有分支,只有主干,多個不同時間點的需求上線都在同一個主干上開發,導致有時候因為后面時間點的需求影響了前面時間點需求的上線。
最簡單的上線過程,開發人員自學linux系統管理,自己通過ftp把主干代碼上傳部署,而且都是老板訪問不了網站我們才知道出故障了,接著開發人員在主干上改bug,改完bug重新部署,發現之前的bug沒了,出現了新的4個bug。繼續修改bug,部署…無限循環。
最簡單的線上故障處理,數據庫負載過高、web服務器負載過高、服務器硬件壞了、網絡線路,機房斷電等等問題出現之后,唯一的辦法就是停止網站服務進行修復。
每周五下午例會,討論的問題都沒有積累下來,沒有被分享給其他團隊成員,更不可能分享給新員工。
上面的流程基本上都是由開發人員負責,開發人員此時就是多角色,類似孫悟空,需要不斷轉換角色。更重要的是,上述所有流程和項目管理都只是關注項目自身。沒有關注團隊知識的積累,人員的培訓。本質上就是不關注“成長”。我作為項目經理,我承認自己之前的不足,但值得慶幸的是我在離開之前做了一些比較有意義的事情,我讓部門開發人員每個星期輪流做分享,讓整個部門的人能夠學到更多的知識。
后來來到淘寶,在這里能學到很多東西,因為這里有完善的培訓體系,注重員工的個人成長。一個小插曲,我在新員工手冊里看到sprint這個單詞,我想在業內算比較牛的公司竟然還會把spring寫成sprint,后來接觸到了scrum敏捷開發,我才知道原來sprint是scrum的一個迭代周期。那個羞啊。哈哈。
來到淘寶,猛然有一種柳暗花明又一村的感覺,以前我做的事情都有涉及到,但在腦海中沒有一個成形的框架,零零散散。
下面來講講跟我之前不一樣的地方。
開發模式:
l 周五的雙周pk,產品排好需求優先級,項目經理根據團隊的人力資源pk需求,哪些可以完成,哪些人力不夠。這里要著重強調工時,每個人每天都是按照4小時來算,其他4小時主要學習,更好的完成工作。4個小時是根據團隊平時工作效率來計算的,也有可能是5或6個小時。不同時期不同項目每個人都有不同的變化曲線。
l Pk下來的需求,技術團隊在周一進行任務拆分,然后大家領取各自的任務。
l 每個團隊有自己的任務墻(故事墻),主要就是讓大家在每天的15分鐘晨會上列出各自的每天要完成的任務。
l 每天早上15分鐘的晨會,一個是讓大家都能在某個時間點之前趕到公司開會,另一個就是讓大家清楚自己今天要做什么。晨會主要描述:1 我昨天做了什么 2 我遇到了哪些問題,自己解決了可以簡單分享給同事,解決了不了可以讓團隊來幫忙一起解決。 3 今天我要做什么
l 每雙周要做回顧,看看出現了什么問題,哪些地方可以再改進。
l 最后就是分享,有技術分享,業務分享。
這個開發模式對比以前有以下幾個優點:
l 團隊資源的合理利用,不會出現老板說幾個月完成然后底下的人拼命的加班,讓大家對技術的興趣越來越高,工作的越來越快樂。成長也越來越快。
l 讓大家明確知道自己今天要做什么。
l 分享,不但自己是分享的參與者也會是分享的發起人。不管是哪種角色,你都能學到很多很多。通過分享,團隊的進步會非常快。
開發流程:
l 編碼、單元測試
l Findbugs
l Mvn test
l Code review(重構,然后從頭開始)
l 提交代碼到svn
這個開發流程主要關注的是代碼的提升,保證代碼的質量,通過代碼審查讓盡早發現不合理的地方。
上線流程:
l 提前一個星期申請上線
l 單元測試
l 提測給測試團隊
l 打包
l 發上線計劃,預發冒煙,發布生產環境
這個流程我不是很熟悉,所以不作評論了。
有了這些比較優秀的模式和流程,也需要工具的配合。
代碼版本控制:svn,并發開發的需求需要用到分支,主干代碼盡量保證隨時可以上線。
項目的管理:maven,開發模式,測試模式,生產模式配置的切換,也可以和hudson進行持續集成。
讓我最有感觸的就是淘寶非常注重知識的積累和員工的成長。在這里我感覺我真的成長了,有踏實的感覺,少了浮躁。這篇文章并不是說小公司不好,也是因為在之前那家公司接觸的面廣,所以來淘寶知道自己哪些對于自己更重要,但也并不鼓勵你畢業就去小公司,因為對你的成長不好。每個人的路都是唯一的,大家喜歡怎么走就看大家自己的了,每個選擇都是獨一無二的,這樣才能活出獨一無二的生活,絢爛的生活。
開發過程中遇到了一些數據傳輸安全性問題,一個很重要實際需求,客戶端加密的數據在服務端要解密回來還要進行一些處理。
腦中立馬跳出幾種解決方法:
1、直接使用MD5進行加密好了,可是MD5是不可逆的算法,而某些數據到達服務器端需要解密出來進行一些處理。看來不滿足實際需求。
2、那可以嘗試下DES,3DES或者AES等一些對稱算法加密處理,想想挺好的,對稱算法的效率也挺快。可是密鑰該怎么從服務端安全的傳遞到客戶端呢,這個問題不解決,加密還是如同虛設。
3、最后一種方案那就是使用RSA非對稱算法,這個算法的好處就是服務器端自己維護私鑰,把公鑰開放給客戶端,有人在網絡上監聽到公鑰和加密后的數
據也沒關系,因為加密的數據需要私鑰才能解的開。也許大家都熟悉https協議,其實這種協議就是用RSA非對稱算法來實現,但是大家肯定也有感受,用
https的時候網頁打開的速度會比http要慢很多。我也考慮到這點,于是做了一個基準測試,在服務端寫了個測試類,結果讓我大吃一驚,2g的cpu循
環100次用私鑰去解密竟然花了我50000多毫秒,那我循環10000次呢,靠,竟然花了幾分鐘。那如果采用這種方案去實現的話,應用程序的性能會被這
些解密動作所拉下。沒辦法哦,又只能放棄此類方案。
4、山重水復疑無路,柳暗花明又一村。突然腦中又蹦出另外一種想法,還是使用對稱算法,關于密鑰的傳遞可以采用DiffieHellman協議。
于是乎,上網查了一些資料,發現java類似的算法還是可以查的到,但是單有java也不行,我要在客戶端加密,java端進行解密,所以還需要有
JavaScript的類似算法。最后在enano-1.1.7這個php開源的電子商務網站內找到了相關信息。無意間發現這個開源程序的一篇wiki,
詳細介紹了一套安全解決方案(http://enanocms.org/News:Article/2008/02/20/Diffie_Hellman_key_exchange_implemented)。
以上只是我的思路,但還沒有寫個應用程序測試過。那么光有理論沒有實踐也不行,那就建個工程實現一下唄。嘿嘿。
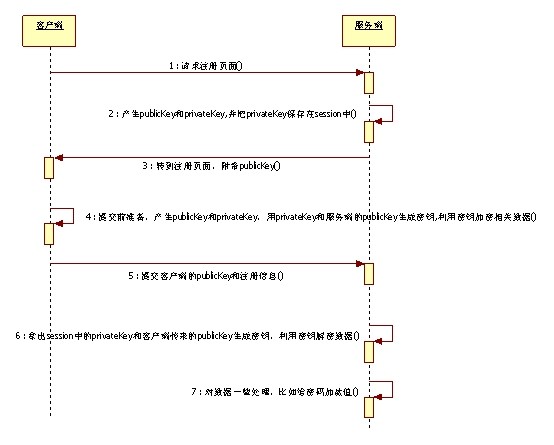
case:用戶注冊。
case描述:客戶在客戶端填寫一些信息,提交之前通過密鑰把用戶名和密碼進行加密,服務端需要把用戶名和密碼解密回來進行進行處理,一個很重要的
處理就是,給密碼加鹽值,然后進行MD5加密,也許你會問,為什么這個動作不能在客戶端做呢,其實也是可以的,但是為了不想讓黑客知道我密碼加密的體制所
以放到服務端進行。
case UML:
設計到的一些類和文件:

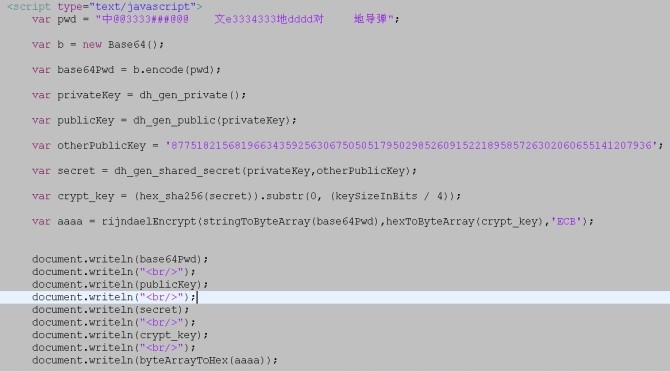
其中用到了base64,主要就是解決了中文亂碼問題。
實現過程中的一些總結:
1、對于安全算法等一些總結,我用到一些相關算法類都是可以單獨拿來用的。而jdk中也有支持的相關類,可以看看jca和jce。這兩個擴展包其實并沒有真正的實現,他們只是對這些安全問題的抽象。真正的實現有sunjce和Bouncy Castle。
2、對于算法本身定義的理解很重要,AES支持128,192,256位的密鑰,但每次被加密的一定要是128位的內容,一般我們被加密的都是超過此長度的,那可以這么來處理:
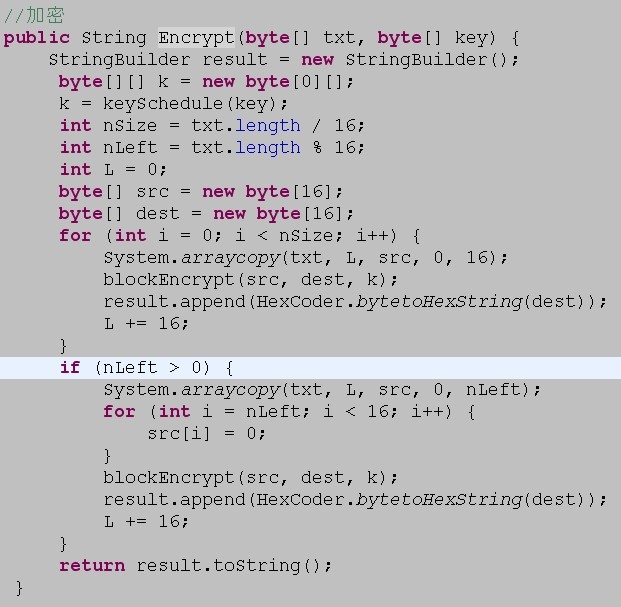
把要加密的內容進行分組處理。解密也是類似。
最后的總結:此次實踐只是模擬了一個場景,還可以運用很多場景中,OpenSSL,OpenID都可以運用。不是我說的,我也是看了找了相關的材
料,OpenSSL
java的項目還在建設中,php是有的,大家可以去找下,openid也是有用到的,這里推薦一個開源的項目openid4java,也可以去查查看,
有時間去看看里面的源碼還是不錯的。如果你也啥地方還不明白或者需要里面用到的一些代碼,可以和我溝通交
流,msn:yangpingyu@gmail.com.
fastdfs-apache-module主要作用就是配合sotrage存儲器以http方式下載文件,更重要的是解決了storage同步帶來的延遲。也許熟悉fastdfs的朋友們知道,以前通過tracker來跳轉也可以解決或其他方式也可以解決,舍取就要看大家的應用了。但是fishman(fastdfs作者)做過測試,性能絕對是fastdfs-apache-module要高。
生產環境中我肯定要用一些性能比較高的軟件嘍。因此把下載方式改成用fast-apache-module。以下是我的使用步驟和遇到的一些問題。前提條件:1、已經安裝好fastdfs,而且版本是
FastDFS_v2.02.tar.gz或以上。2、已經安裝好apache2.0或以上。
第一步,下載
fastdfs-apache-module。
第二步,編譯fastdfs-apache-module。分以下幾種情況。
1 、如果apache是你自己安裝的,并且apache文件目錄在/usr/local/apache2。那么你可以直接運行make,然后make install。
2、 如果apache是你自己安裝的,apache目錄在/opt/apache2,那么首先你得把Makefile文件的以下幾處地方修改。
第七行改成:top_srcdir=/opt/apache2
第八行改成:top_builddir=/opt/apache2
第九行改成:include /opt/apache2/build/special.mk
第十二行改成:APXS=/opt/apache2/bin/apxs
第十三行改成:APACHECTL=/opt/apache2/bin/apachectl
改完后,然后執行make和make install命令。
3、 如果是系統自帶的httpd,那么你就比較麻煩了。
3.1 首先安裝httpd-devel包。建議使用centos的yum進行安裝,souhu的源比較好用,速度挺快的。
3.2 類似的也要改Makefile文件了。
第七行改成:top_srcdir=/etc/httpd
第八行改成:top_builddir=/etc/httpd
第九行改成:include /etc/httpd/build/special.mk
第十二行改成:APXS=/usr/sbin/apxs
第十三行改成:APACHECTL=/usr/sbin/apachectl
保存。
3.3 ln -s /etc/httpd/build /usr/lib64/httpd/build(為了讓第九行找到special.mk)
3.4 make
3.5 make install
如果正常編譯的話,在/etc/fdfs目錄下多了一個mod_fastdfs.conf文件,在${apache安裝根目錄}/modules目錄下生成
mod_fastdfs.so文件。
第三步:修改httpd的配置文件httpd.conf。
1、LoadModule fastdfs_module modules/mod_fastdfs.so
2、
<Location /M00>
sethandler fastdfs
</Location>
3、設置DocumentRoot為:${fastdfs_base_path}/data
第四步:ln -s ${fastdfs_base_path}/data ${fastdfs_base_path}/data/M00
第五步:修改/etc/fdfs/mod_fastdfs.conf配置文件,文件中對每個設置字段都有注釋
第七步:重啟apache。
以上就是fastdfs-apache-module安裝的具體過程。僅供參考。
在介紹本文之前,我向大家介紹下一個非常棒的分布式文件系統fastdfs,關于她的具體介紹和優點我不做詳細介紹了,有關資料可以訪問:
http://linux.chinaunix.net/bbs/forum-75-1.html 。
web2.0海量小文件的存儲是所有系統架構師必須要面對的一個問題。
這幾天一直在忙著給公司部署分布式文件系統。也看了幾個大型公司的分布式文件系統的架構:flicker,taobao,拍拍網。深入理解各自應用的場景,弄明白了很多個為什么之后,自己將要為公司部署的分布式文件系統架構也慢慢浮出水面了。
架構隨著業務發展而逐步改變的,比如類似淘寶這樣的訪問量,可能需要cdn來加速靜態資源(js,css)和用戶上傳的業務相關的圖片而一般訪問量不是特別大的網站可以不用部署cdn,原因肯定很多,硬件成本和維護成本等等。
那么接下來我就分別介紹部署cdn的分布式文件系統架構和普通分布式文件系統架構。
(一)部署cdn的分布式文件系統架構:
涉及到的技術:lvs,haproxy(或nagix),squid,nagix(或apache),fastdfs。
有圖有真相,先畫個圖。
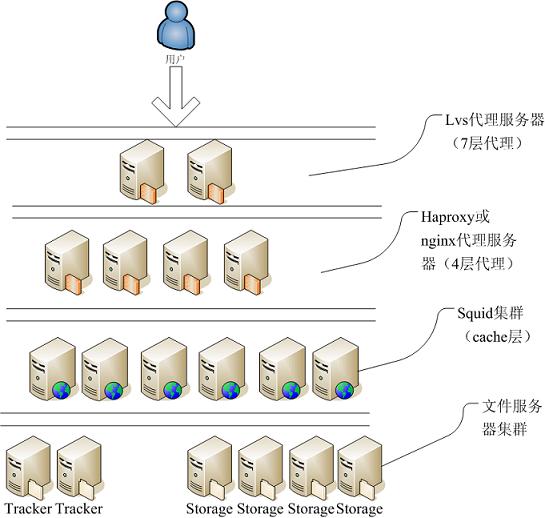
接下來我對每層設置的意義進行解釋下。
lvs7層代理:主要通過ip來找到自己合適的下層服務器。
haproxy或nginx4層代理:主要通過url hash找到合適的一臺squid。最主要功能就是為了提高squid緩存的命中率。
squid集群:緩存所有用戶訪問的對象。
文件服務器集群:1、tracker服務器,主要管理文件存儲的源storage等一些信息。 2、storage服務器就是實際文件的存儲位置。最近fishman(fastdfs的作者)開發了一個apache module解決了延遲問題,那么我們可以不用啟用tracker內嵌的服務器來跳轉了,直接把http服務器配置在storage服務器上。給我們帶來了很多方便。
(二)普通分布式文件系統架構:
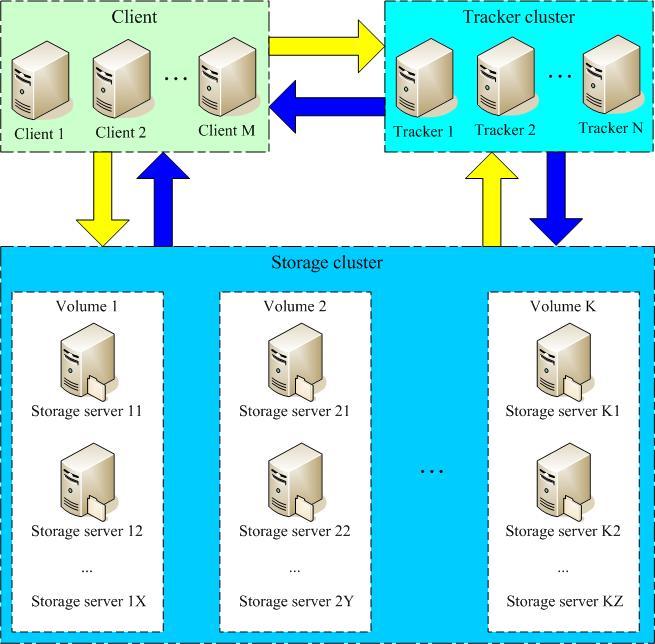
(圖片引自:
http://linux.chinaunix.net/bbs/thread-1062461-1-1.html)
這個架構沒有涉及到cdn的部署,相比起來應該更容易理解了。對于tracker和storage的作用類似于在部署cdn的分布式文件系統架構部分介紹的一樣。其中client我覺得有必要要解釋下,這里的client有兩層含義:1、相對于tracker和storage服務器來說,client是訪問這些服務器的客戶端。 2、應用程序的服務端。實際開發中,我們可以部署一臺圖片上傳服務器來作為應用程序的服務端,也可以把圖片上傳服務直接寫到應用程序中。
兩種架構都是基于fastdfs分布式文件系統。所以你們了解fastdfs軟件本身之后再看這篇文章也許會更有益。
兩個項目中都使用了spring security安全框架,很多資料都是介紹spring security具體使用。今天我如果還是寫這些東西就顯得多余了,那么我從不同的角度來總結自己對這個框架的一些認識。
首先看看兩個疑惑,然后我會逐步解釋這兩個疑惑。
第一個疑惑,spring security框架是spring的子框架,我就非常好奇spring security和spring是如何融合起來,確切的說,spring security定義的對象如何納入spring ioc 容器中管理。研究到最后其實都是spring自身的一些知識,比如:自定義擴展xml schema,spring ioc啟動。
第二個疑惑,spring security如何攔截用戶的請求。這部分可以解讀spring security源碼可以得到答案。
徹底搞明白第一個疑惑之后,也許你以后自己寫一個框架,就可以很方便的整合到spring中去了。對于框架開發工程師來說,開發新的框架之后能整合spring是必須的事情了,畢竟spring給我們所帶來的好處是可想而知的。這也是我要徹底了解清楚原理的動力所在。廢話一堆,進入主題吧~~~~

第一個疑惑最后涉及到兩個方面的知識,spring ioc啟動和spring可擴展xml schema。spring ioc有兩個非常重要的概念,beanfactory和applicationContext,后者提供了更多更強的功能。為了避免過多的細節直接解讀beanfactory的讀取過程,xmlbeanfactory讀取xml文件會經歷如下兩個過程:1、通過resource接口讀取xml文件,轉換成document。 2、從document中解析出bean的配置。具體詳細過程請參照文章:
spring讀取xml配置源代碼分析(這篇文章一定要先看懂,不然后面很難繼續)。看過我介紹大家看的那篇文章之后,其實也有所了解spring擴展xml schema機制了。如果還不是很清楚再結合這篇文章:
基于Spring可擴展Schema提供自定義配置支持。感覺有點東拼西湊的,呵呵,主要怕以后自己忘記了,所以才寫篇blog。
第二個疑惑我們就看源代碼吧。
<filter-mapping>
<filter-name>jcaptchaFilter</filter-name>
<url-pattern>/j_spring_security_check</url-pattern>
</filter-mapping>
<filter>
<filter-name>springSecurityFilterChain</filter-name>
<filter-class>com.busyCity.web.filter.DelegatingFilterProxy</filter-class>
</filter>
<filter-mapping>
<filter-name>springSecurityFilterChain</filter-name>
<url-pattern>/*</url-pattern>
<dispatcher>FORWARD</dispatcher>
<dispatcher>REQUEST</dispatcher>
</filter-mapping>
web.xml中配置了
DelegatingFilterProxy,DelegatingFilterProxy調用FilterChainProxy的doFilter
public void doFilter(ServletRequest request, ServletResponse response)throws IOException, ServletException
{
if(currentPosition == additionalFilters.size())
{
if(FilterChainProxy.logger.isDebugEnabled())
FilterChainProxy.logger.debug((new StringBuilder()).append(fi.getRequestUrl()).append(" reached end of additional filter chain; proceeding with original chain").toString());
fi.getChain().doFilter(request, response);
} else
{
currentPosition++;
Filter nextFilter = (Filter)additionalFilters.get(currentPosition - 1);
if(FilterChainProxy.logger.isDebugEnabled())
FilterChainProxy.logger.debug((new StringBuilder()).append(fi.getRequestUrl()).append(" at position ").append(currentPosition).append(" of ").append(additionalFilters.size()).append(" in additional filter chain; firing Filter: '").append(nextFilter).append("'").toString());
nextFilter.doFilter(request, response, this);
}
}
這個方法就是循環調用我們用http命名空間配置的那些過濾器。然后根據不同的過濾器處理不同的內容。
我描述的都很簡單,主要原因是做個記錄,以后忘記了可以根據這個思路重新找到答案。不需要重新開始研究。呵呵。
一直以來,看了很多東西自己知道就完了,而我覺得作為互聯網的一份子,應該懂得分享。
最近看了很多關于程立的一些演講,學習到了soa實踐中非常寶貴的經驗。
最開始支付寶架構是單應用系統,采用分層架構模式(展現層+業務層+持久層),用過分層架構模式的人都很清楚業務層是最關鍵的一層,也是最容易造成臃腫和龐大的一層,所以需要合理的分離。而最佳實踐應該是把業務層分為:facade層和業務邏輯層,也符合現在比較熱的領域模型驅動,業務邏輯層主要負責業務本身的實現,facade層區分產品功能和決策。對于中小型而且項目業務需求也不怎么變的應用來說,是比較合理的架構。無論從學習成本和人力成本來說,都相對較低。但是業務不斷擴張的應用來說,到最后開發成本和維護將會逐步提高。支付寶也是這個時候就開始著手對“對象”進行“組件”化,也就是接下來的第二個過程了。
從對象到組件化,我們首先要來看看組件這個概念。組件是功能職責相近類的集合。組件本身需要以下幾點功能:1、屬性 2、運行級別 3、引用 4、擴展 等。而那時比較符合支付寶這一思想的規范有osgi。具體關于osgi的相關內容可以自行google。如果用osgi會出現如下三個問題:
1、osgi平臺如何在tomcat,jboss下運行。(現在tomcat,jboss等應用服務器都已經支持了,以前需要自己來擴展tomcat)
2、osgi使用起來比較麻煩和復雜,如何跟spring整合起來使用也是需要解決的問題,不過spring就是spring,05左右好像就對這方面開始研究了,現在作為一個子項目(Spring Dynamic Modules)。
3、osgi規范沒有擴展這種功能,所以需要自己來對osgi的一些框架進行擴展,可以參照eclipse的一個osgi框架,或者也可以直接用此框架(Equinox)。
這些問題都解決了,那么“對象”進行“組件”過程就完成了。但是這個時候需要對企業內部的系統能夠配合起來,那么可以對業務層進行服務化。也就是第三個過程了。
把組件都以服務方式部署出來,同時也需要管理好這些服務,那么此時可以引入esb(企業服務總線)中間件了。商業的和開源的都有,支付寶用的是開源的mule,不過對于某些方面,支付寶進行改造過,為了確保消息能夠百分百不丟失,畢竟跟錢打交道嘛需要嚴謹。
其實這些基礎平臺搭建好后,還需要解決一個特別難的難題。功能服務化后,數據庫也不再是集中式了,本地事務也不能保證了。這個時候需要引入分布式事務,數據庫軟件本身也提供分布式事務,但是對于需要高訪問量和高性能的網站來說,可能需要換一種方式了。cap和base理論告訴我們可以適當放棄強一致性來達到其他兩項性能。ws-transaction是分布式中間件,但是完成一個事務需要很多消息來溝通,至少大大增大了事務的中間過程會被中斷掉。支付寶公司研究出了一些分布式事務模式,比如冪等性模式,補償性模式,tcc模式等等。每個模式都有不同的應用場景,大家可以根據自己的業務特點來進行選取。
以上即是我最近學習的一些總結。讓更多的人能學習好的技術和經驗。讓我們一起來分享吧。