import java.util.Iterator;
import java.util.List;
import java.util.Set;
import junit.framework.TestCase;
import org.hibernate.Criteria;
import org.hibernate.Hibernate;
import org.hibernate.HibernateException;
import org.hibernate.Query;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
import org.hibernate.criterion.Expression;
public class DurationOperator extends TestCase {
private SessionFactory sessionFactory = null;
private Session session = null;
/**
* εàùεß΄ε¨•ηΒ³φΚ?br /> */
protected void setUp() throws Exception {
try {
//εä†ηù≤ΨcΜηΒ\εΨ³δΗ΄γö³hibernate.cfg.xmlφ•΅δög
Configuration config = new Configuration().configure();
//εà¦εΨèsessionFactoryε·Ιη±Γ
sessionFactory = config.buildSessionFactory();
//εà¦εΨèsession
session = sessionFactory.openSession();
} catch (HibernateException e) {
e.printStackTrace();
}
}
/**
* load/getφ•“é≥ïεù΅εè·δΜΞφ†Ιφç°φ¨΅ε°öγö³ε°ûδΫ™Ψc’d£¨idδΜéφïΑφç°εΚ™η·’dè•η°ΑεΫïεQ¨εΤà‰qîε¦ûδΗéδΙ΄ε·ΙεΚîγö³ε°ûδΫ™ε·Ιη±ΓψÄ?br /> * ε¨ΚεàΪε€®δΚéεQ?br /> * 1ψĹεΠ²φû€φ€ΣεèëγéΑΫWΠεêàφùΓδögγö³η°ΑεΫïοΦ¨getφ•“é≥ï‰qîε¦ûnull,ηĨloadφ•“é≥ïφä¦ε΅ΚδΗÄδΗΣObjectNotFoundException
* 2ψĹloadφ•“é≥ïεè·δΜΞ‰qîε¦ûε°ûδΫ™γö³δΜΘγêÜγ±Με°ûδΨ΄εQ¨ηĨgetφ•“é≥ïφΑΗηـ㦥φéΞ‰qîε¦ûε°ûδΫ™ΨcÖRÄ?br /> * 3ψĹloadφ•“é≥ïεè·δΜΞεÖÖεàÜεà©γî®εÜÖιÉ®Ψ~™ε≠‰ε£¨δΚ¨ΨUßγΦ™ε≠‰δΗ≠γö³γéΑφ€âφïΑφç°οΦ¨ηĨgetφ•“é≥ïεàôδΜÖδΜÖε€®εÜÖιÉ®Ψ~™ε≠‰δΗ≠ηΩ¦ηΓ¨φïΑφç°φüΞφâΨοΦ¨εΠ²φû€
* φ≤Γφ€âεèëγéΑφïΑφç°εQ¨εΑÜ≠ëäηΩ΅δΚ¨γώîΨ~™ε≠‰εQ¨γ¦¥φéΞηΑÉγî®SQLε°¨φàêφïΑφç°η·’dè•ψÄ?br /> *
*/
public void loadOrGetData(){
TUser user = (TUser)session.load(TUser.class,new Integer(1));
}
/**
* φüΞη·ΔφÄßηÉΫεΨÄεΨÄφ‰·δΗÄΨp»ùΜüφÄßηÉΫηΓ®γéΑγö³δΗÄδΗΣι΅çηΠ¹φ•ΙιùΔψÄ?br /> * query.listφ•“é≥ïιÄöηΩ΅δΗÄφùΓselect SQLε°ûγéΑδΚÜφüΞη·Δφ™çδΫ€οΦ¨ηĨiterateφ•“é≥ïεQ¨εàôφâßηΓ¨δΚ?΄ΤΓselectSQLεQ¨γ§§δΗÄ΄ΤΓηéΖεè•δΚÜφâÄφ€âγ§ΠεêàφùΓδΜΕγö³η°ΑεΫï
* γö³id,δΙ΄εêéεQ¨ε€®φ†“éç°εê³δΗΣidδΜéεΚ™ηΓ®δΗ≠η·’dè•ε·ΙεΚîγö³ε™Πη°ΑεΫïεQ¨ηΩôφ‰·δΗÄδΗΣεÖΗεû΄γö³N+1΄ΤΓφüΞη·Δι½°ιΔ‰ψÄ?br /> *
* φàëδΜ§‰q¦ηΓ¨query.listφïΑφç°φüΞη·Δφ½”ûΦ¨εç≥δ΄…Ψ~™ε≠‰δΗ≠εΖ≤Ψlèφ€âδΗÄδΚ¦γ§ΠεêàφùΓδΜΕγö³ε°ûδΫ™ε·Ιη±Γε≠‰ε€®εQ¨φàëδΜ§δΙüφ½†φ≥ïδΩùη·¹‰qôδΚ¦φïΑφç°û°±φ‰·εΚ™ηΓ®δΗ≠φâÄφ€âγ§ΠεêàφùΓδΜΕγö³φïΑφç°ψÄ²ε¹΅η°?br /> * ΫW§δΗÄ΄ΤΓφüΞη·ΔφùΓδΜΕφ‰·age>25,ιöèεç≥Ψ~™ε≠‰δΗ≠εΑ±ε¨Öφ΄§δΚÜφâÄφ€âage>25γö³userφïΑφç°;ΫW§δΚ¨΄ΤΓφüΞη·ΔφùΓδΜΕδΊ™age>20,φ≠Λφ½ΕΨ~™ε≠‰δΗ≠ηôΫγ³Εε¨ÖεêΪδΚÜφΜΓηÉωage>25dγö?br /> * φïΑφç°εQ¨δΫ܉qôδΚ¦ρqΕδΗçφ‰·φΜΓ≠ëœxùΓδΜΕage>20γö³εÖ®ιÉ®φïΑφç?br /> * 妆φ≠ΛεQ¨query.listφ•“é≥ï‰q‰φ‰·ι€ÄηΠ¹φâßηΓ¨δΗÄ΄ΤΓselect sqlδΜΞδΩùη·¹φüΞη·ΔγΜ™φû€γö³ε°¨φï¥φÄ?iterateφ•“é≥ïιÄöηΩ΅ιΠ•εÖàφüΞη·ΔηéΖεè•φâÄφ€âγ§ΠεêàφùΓδΜΕη°ΑεΫïγö³id,δΜΞφ≠ΛδΩùη·¹
* φüΞη·ΔΨl™φû€γö³ε°¨φï¥φÄ?ψÄ?br /> * 妆φ≠ΛεQ¨query.listφ•“é≥ïε°ûιôÖδΗäφ½†φ≥ïεà©γî®γΦ™ε≠‰οΦ¨ε°Éε·ΙΨ~™ε≠‰εèΣεÜôδΗçη·ΜψIJηĨiterateφ•“é≥ïεàôεè·δΜΞεÖÖεàÜεèëφ¨ΞγΦ™ε≠‰εΗΠφùΞγö³δΦ‰εäΩεQ¨εΠ²φû€γ¦°φ†΅φïΑφç°εèΣη·άLà•ηÄÖη·Μεè•γ¦Ηε·?br /> * ηΨÉδΊ™ιΔëγΙ¹εQ¨ιÄöηΩ΅‰qôγßçφ€ΚεàΕεè·δΜΞεΛßεΛßε΅èεΑëφÄßηÉΫδΗäγö³φçüηĽψÄ?br /> */
public void queryForList(){
String hql = "from TUser where age>?";
Query query = session.createQuery(hql);
query.setInteger(1,1);
List list = query.list();
for(int i=0;i<list.size();i++){
TUser user = (TUser)list.get(i);
System.out.println("User age:"+user.getAge());
}
}
public void queryForIterate(){
String hql = "from TUser where age>?";
Query query = session.createQuery(hql);
query.setInteger(1,1);
Iterator it = query.iterate();
while(it.hasNext()){
TUser user = (TUser)it.next();
System.out.println("User age:"+user.getAge());
}
}
/**
* εΛßφïΑφç°ι΅èγö³φâΙι΅èη·Μεè?10Wφù?
* ηßΘεÜ≥φ•“éΓàεQöγΜ™εêàiterateφ•“é≥ï壨evictφ•“é≥ïιÄêφùΓε·Ιη°ΑεΫïηΩ¦ηΓ¨εΛ³γêÜοΦ¨û°ÜεÜÖε≠‰φΕàηĽδΩùφ¨¹ε€®εè·δΜΞφéΞεè½γö³η¨É妥δΙ΄εÜÖψÄ?br /> * ε€®ε°ûιôÖεΦÄεèëδΗ≠εQ¨ε·ΙδΚéεΛßφâöw΅èφïΑφç°εΛ³γêÜεQ¨ηΩ‰φ‰·φé®ηçêι΅΅γî®SQLφà•ε≠‰ε²®ηΩ΅ΫE΄ε°ûγééΆΦ¨δΜΞηéΖεΨ½ηΨÉιΪ‰γö³φÄßηÉΫεQ¨εΤàδΩùη·¹Ψp»ùΜüρqœxΜë‰qêηΓ¨ψÄ?br /> */
public void bigDataRead(){
String hql = "from TUser where age>?";
Query query = session.createQuery(hql);
query.setInteger("age", 1);
Iterator it = query.iterate();
while(it.hasNext()){
TUser user = (TUser)it.next();
//û°Üε·Ιη±ΓδΜéδΗÄΨUßγΦ™ε≠‰δΗ≠ΩUΜιôΛ
session.evict(user);
//δΚ¨γώîΨ~™ε≠‰εè·δΜΞη°ë÷°öφ€ÄεΛßφïΑφç°γΦ™ε≠‰φïΑι΅èοΦ¨ηΨë÷àΑε≥ΑεÄΦφ½ΕδΦöη΅Σεä®ε·ΙΨ~™ε≠‰δΗ≠γö³ηΨÉηĹφïΑφç°ηΩ¦ηΓ¨εΚüιôΛοΦ¨δΫÜφ‰·φàëδΜ§‰qô顨‰q‰φ‰·ιÄöηΩ΅
//Ψ~•γ†¹φ¨΅ε°öû°Üε·Ιη±ΓδΜéδΚ¨γώîΨ~™ε≠‰δΗ≠γßΜιôΛοΦ¨‰qôφ€âεä©δΩùφ¨¹γΦ™ε≠‰γö³φïΑφç°φ€âφïàφÄßψÄ?/span>
sessionFactory.evict(TUser.class,user.getId());
}
}
/**
* Query CacheεΦΞηΓΞδΚÜfindφ•“é≥ïγö³δΗç≠ëΜIΦ¨QueryCacheδΗ≠γΦ™ε≠‰γö³SQLεèäεÖΕΨl™φû€εèäεΤàιùûφΑΗ‰q€ε≠‰ε€®οΦ¨εΫ™HibernateεèëγéΑφ≠ΛSQLε·ΙεΚîγö³εΚ™ηΓ®εèëγîüεè‰εä®οΦ¨
* δΦöη΅Σεä®εΑÜQuery CacheδΗ≠ε·ΙεΚîηΓ®γö³SQLΨ~™ε≠‰εΚüιôΛψÄ²ε¦†φ≠ΛQuery CacheεèΣε€®γâΙε°öγö³φÉÖεÜΒδΗ΄δΚßγîüδΫ€γî®εQ?br /> * 1ψÄ¹ε°¨εÖ®γ¦Ηεê¨γö³select SQLι΅çεΛçφâßηΓ¨ψÄ?br /> * 2ψÄ¹ε€®2΄ΤΓφüΞη·ΔδΙ΄ι½Ώ_Φ¨φ≠Λselect SQLε·ΙεΚîγö³εΚ™ηΓ®φ≤Γφ€âεèëγîüηΩ΅φîΙεè‰ψÄ?br /> */
public void queryForQueryCache(){
String hql = "from TUser where age>?";
Query query = session.createQuery(hql);
query.setInteger(1, 1);
//ιôΛδΚÜε€®ηΩô顨η°ΨΨ|°QueryCacheεΛ•οΦ¨‰q‰ηΠ¹ε€®hibernate.cfg.xmlδΗ≠ηΩ¦ηΓ¨η°ΨΨ|?br /> //<property name="hibernate.cache.use_query_cache">true</property>
query.setCacheable(true);
List userList = query.list();
}
/**
* φâÄηΑ™εög‰qüεä†ηΫΫοΦ¨û°±φ‰·ε€®ι€ÄηΠ¹φïΑφç°γö³φ½ΕεÄôοΦ¨φâçγ€üφ≠ΘφâßηΓ¨φïΑφç°εä†ηΫΫφ™çδΫ€ψÄ?br /> * εΜΕηΩüεä†ηù≤ε°ûγéΑδΗΜηΠ¹ι£àε·ΙεQ?br /> * 1ψĹε°ûδΫ™ε·Ιη±?ιÄöηΩ΅classγö³lazyε±ûφÄßοΦ¨φàëδΜ§εè·δΜΞφâ™εΦÄε°ûδΫ™ε·Ιη±Γγö³εög‰qüεä†ηΫΫεäüηÉΫψÄ?br /> * 2ψĹι¦Üεê?br /> */
public void queryForEntityLazy(){
Criteria criteria = session.createCriteria(TUser.class);
criteria.add(Expression.eq("name","Erica"));
List userList = criteria.list();
TUser user = (TUser)userList.get(0);
//ηôΫγ³ΕδΫΩγî®δΚÜεög‰qüεä†ηΫΫοΦ¨δΫÜφ‰·φàëδΜ§εè·δΜΞιÄöηΩ΅hibernateγö³εàùεß΄ε¨•φ•“é≥ï‰q¦ηΓ¨εΦΚεàΕεä†ηù≤εQ¨ηΩôφ†Ζεç≥δΫΩsessionεÖ≥ι½≠δΙ΄εêéεQ¨εÖ≥η¹îγö³ε·Ιη±ΓδΜçη°©εè·δΜΞδΫΩγî®
Hibernate.initialize(user.getAddresses());
System.out.println("User name=>"+user.getAge());
Set hset =user.getAddresses();
TAddresses addr = (TAddresses)hset.toArray()[0];
System.out.println(addr.getAddress());
session.close();
}
/**
* εÖ≥ι½≠ηΒ³φΚê
*/
protected void tearDown() throws Exception {
try{
session.close();
}catch(HibernateException e){
e.printStackTrace();
}
}
}
]]>
1ψĹJSC
2ψĹEHCache->ιΜ‰η°Λγö³δΚ¨ΨUßCacheε°ûγéΑψÄ?-------net.sf.encache.hibernate.Provider
3ψĹOSCache-------------------------------net.sf.hibernate.cache.OSCacheProvider
4ψĹJBoss Cache->εàÜεΗÉεΦèγΦ™ε≠?--------------net.sf.hibernate.cache.TreeCacheProvider
5ψĹSwarmCache----------------------------net.sf.hibernate.cache.SwarmCacheProvider
γ¦Ηε·ΙδΚéJSCηĨη®ÄεQ¨EHCacheφ¦¥εä†ΫE¦_°öεQ¨εΤàεÖΖεΛ΅φ¦¥εΞΫγö³φΊ€ε≠‰ηΑÉεΚΠφÄßηÉΫεQ¨εÖΕΨ~ΚιôΖφ‰·γ¦°εâçηΩ‰φ½†φ≥ïε¹öεàΑεàÜεΗÉεΦèγΦ™ε≠‰ψÄ?br /> ιΠ•εÖàη°³ΓΫ°hibernate.cfg.xmlγ³Εεêéη°³ΓΫ°ehcache.xmlφ€Äεêéη°ΨΨ|°γΦ™ε≠‰γ≠•γïΞψÄ?br />
Ψ~™ε≠‰εê¨φ≠ΞΫ{•γïΞεܦ_°öδΚÜφïΑφç°ε·Ιη±Γε€®Ψ~™ε≠‰δΗ≠γö³ε≠‰εè•ηß³εàôψÄ²δΊ™δΚÜδ΄…εΨ½γΦ™ε≠‰ηΑÉεΚΠι¹ΒεΨΣφ≠ΘΦ΄°γö³εΚîγî®ΨUßδΚ΄γâ©ιöîΦ¦άL€Κεà”ûΦ¨φàëδΜ§εΩÖιΓΜδΗΚφ·èδΗΣε°ûδΫ™γ±Μφ¨΅ε°öγ¦ΗεΚîγö³γΦ™ε≠‰εê¨φ≠Ξγ≠•γïΞψIJHibernateφèêδΨ¦4ΩUçεÜÖΨ|°γö³Ψ~™ε≠‰εê¨φ≠ΞΫ{•γïΞεQ?br /> 1ψĹread-only:εèΣη·ΜψIJε·ΙδΚéδΗçδΦöεèëγîüφîΙεè‰γö³φïΑφç°εQ¨εè·δΫΩγî®εèΣη·Μεû΄γΦ™ε≠‰ψÄ?br /> 2ψĹnonstrict-read-write:εΠ²φû€ΫE΄εΚèε·ΙεΤàεèëη°Ωι½°δΗ΄γö³φïΑφç°εê¨φ≠ΞηΠ¹φ±²δΗçφ‰·ιùûεΗφÄΗΞφ†ϊ|Φ¨δΗîφïΑφç°φ¦¥φ•Αφ™çδΫ€ιΔëγé΅ηΨÉδΫéοΦ¨εè·δΜΞι΅΅γî®φ€§ιÄâιΓΙψÄ?br /> 3ψĹread-write:δΗΞφ†Φεè·η·ΜεÜôγΦ™ε≠‰ψÄ?br /> 4ψĹtransactional:δΚ΄εäΓεû΄γΦ™ε≠‰οΦ¨εΩÖιΓΜ‰qêηΓ¨ε€®JTAδΚ΄γâ©γé·εΔÉδΗ≠ψÄ?br />
JDBCδΚ΄γâ©γî±ConnectionΫéΓγêÜεQ¨δΙüû°±φ‰·η·Ώ_Φ¨δΚ΄εäΓΫéΓγêÜε°ûιôÖδΗäφ‰·ε€®JDBC ConnectionδΗ≠ε°ûγéΑψIJδΚ΄εäΓεë®φ€üιôêδΚéConnectionγö³γîüεëΫεë®φ€üδΙ΄ΨcÖRIJεê¨φ†χPΦ¨ε·ΙδΚéεüόZΚéJDBC Transactionγö³HibernateδΚ΄εäΓΫéΓγêÜφ€ΚεàΕηĨη®ÄεQ¨δΚ΄γâ©γ°ΓγêÜε€®SessionφâÄδΜΞφâ‰γö³JDBCConnectionδΗ≠ε°ûγééΆΦ¨δΚ΄εäΓεë®φ€üιôêδΚéSessionγö³γîüεëΫεë®φ€üψÄ?br /> JTAδΚ΄γâ©ΫéΓγêÜεàôγî±JTAε°Ιεô®ε°ûγéΑεQ¨JTAε°Ιεô®ε·ΙεΫ™εâçεä†εÖΞδΚ΄γâ©γö³δΦ½εΛöConnection‰q¦ηΓ¨ηΑÉεΚΠεQ¨ε°ûγéΑεÖΕδΚ΄εäΓφÄßηΠ¹φ±²ψIJJTAγö³δΚ΄γâ©εë®φ€üεè·φ®ΣηΖ®εΛöδΗΣJDBC ConnectinγîüεëΫεë®φ€üψIJεê¨φ†Ζε·ΙδΚéεüΚδΚéJTAδΚ΄εäΓγö³HibernateηĨη®ÄεQ¨JTAδΚ΄γâ©φ®ΣηΖ®εΛöδΗΣSession.
Hibernateφî·φ¨¹2ΩUçιî¹φ€ΚεàΕεQöεç≥ιÄöεΗΗφâÄη·¥γö³φ²≤ηß²ιî¹ε£¨δΙêηß²ιî¹ψÄ?br /> φ²≤ηß²ιî¹γö³ε°ûγéΑεQ¨εΨÄεΨÄδΨùιù†φïΑφç°εΚ™φèêδΨ¦γö³ιî¹φ€ΚεàΕψIJεÖΗεû΄γö³φ²≤ηß²ιî¹ηΑÉγî®οΦö
select * from account where name=="Erica" for update
import java.util.List;
import junit.framework.TestCase;
import org.hibernate.Criteria;
import org.hibernate.HibernateException;
import org.hibernate.LockMode;
import org.hibernate.Query;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
import org.hibernate.criterion.Expression;
public class LockOperator extends TestCase {
private Session session = null;
/**
* εàùεß΄ε¨•ηΒ³φΚ?br /> */
protected void setUp() throws Exception {
try {
//εä†ηù≤ΨcΜηΒ\εΨ³δΗ΄γö³hibernate.cfg.xmlφ•΅δög
Configuration config = new Configuration().configure();
//εà¦εΨèsessionFactoryε·Ιη±Γ
SessionFactory sessionFactory = config.buildSessionFactory();
//εà¦εΨèsession
session = sessionFactory.openSession();
} catch (HibernateException e) {
e.printStackTrace();
}
}
/**
* φ²≤ηß²ιî?br /> * Hibernateγö³εä†ιî¹φ®ΓεΦèφ€âεQ?br /> * 1ψĹLockMode.NONE:φ½†ιî¹φ€ΚεàΕ
* 2ψĹLockMode.WRITE:Hibernateε€®Insert壨Updateη°ΑεΫïγö³φ½ΕεÄôδΦöη΅Σεä®ηéΖεè•
* 3ψĹLockMode.READ:Hibernateε€®η·Μεè•η°ΑεΫïγö³φ½ΕεÄôδΦöη΅Σεä®ηéΖεè•
* δΗäηΩΑ3ΩUçιî¹φ€ΚεàΕδΗόZΚÜδΩùη·¹update‰q΅γ®΄δΗ≠ε·Ιη±ΓδΗçδΦöηΔΪεΛ•γï¨δΩ°φîΙεQ¨ε€®γ¦°φ†΅ε·Ιη±ΓδΗäεä†ιî¹οΦ¨δΗéφïΑφç°εΚ™φ½†εÖ≥
* 4ψĹLockMode.UPGRADE:εà©γî®φïΑφç°εΚ™γö³for updateε≠êεèΞεä†ιî¹
* 5ψĹLockMode.UPGRADE_NOWAIT:oracleγö³γâΙε°öε°ûγé?br /> * φ≥®φ³èεQöεèΣφ€âε€®φüΞη·ΔεΦÄεß΄δΙ΄εâçη°Ψε°öεä†ιî¹οΦ¨φâçδΦöγ€üφ≠ΘιÄöηΩ΅φïΑφç°εΚ™γö³ιî¹φ€ΚεàΕηΩ¦ηΓ¨εä†ιî¹εΛ³γêÜψÄ?br /> */
public void addPessimismLock(){
String hqlStr = "from TUser as user where user.name='Erica'";
Query query = session.createQuery(hqlStr);
query.setLockMode("user",LockMode.UPGRADE);//εΛöφâÄφ€âηΩîε¦ûγö³userε·Ιη±Γεä†ιî¹
List userList = query.list();//φâßηΓ¨φüΞη·Δ
}
/**
* δΙêηß²ιî?br /> * φïΑφç°γâàφ€§εQöεç≥δΗΚφïΑφç°εΔûεä†δΗÄδΗΣγâàφ€§φ†΅η·ÜοΦ¨ε€®εüΚδΚéφïΑφç°εΚ™ηΓ®γö³γâàφ€§ηßΘεÜ≥φ•“éΓàδΗ≠οΦ¨δΗÄηà§φ‰·ιÄöηΩ΅δΗΚφïΑφç°εΚ™ηΓ®εΔûεä†δΗÄδΗΣversionε≠½φ°ΒφùΞε°ûγéΑψÄ?br /> * η·’dè•ε΅ΚφïΑφç°φ½ΕεQ¨εΑÜφ≠Λγâàφ€§εèΖδΗÄεê¨η·Με΅ΚοΦ¨δΙ΄εêéφ¦¥φ•Αφ½”ûΦ¨ε·“é≠Λγâàφ€§εèΖεä†1.φ≠Λφ½ΕεQ¨εΑÜφèêδΚΛφïΑφç°γö³γâàφ€§φïΑφç°δΗéφïΑφç°εΚ™ε·ΙεΚîη°ΑεΫïγö³εΫ™εâçγâàφ€§δΩΓφ¹·
* ‰q¦ηΓ¨φ·îε·ΙεQ¨εΠ²φû€φèêδΚΛγö³φïΑφç°γâàφ€§εèΖεΛßδΚéφïΑφç°εΚ™ηΓ®εΫ™εâçγâàφ€§εèΖεQ¨εàôδΚàδΜΞφ¦¥φ•ΑεQ¨εêΠεàôη°ΛδΗΚφ‰·‰q΅φ€üφïΑφç°ψÄ?br /> *
* Hibernateε€®εÖΕφïΑφç°η°âK½°εΦïφ™éδΗ≠εÜÖΨ|°δΚÜδΙêηß²ιî¹ε°ûγéΑψIJεΠ²φû€δΗçηÄÉηôëεΛ•ιÉ®Ψp»ùΜüε·“éïΑφç°εΚ™γö³φ¦¥φ•Αφ™çδΫ€οΦ¨εà©γî®HibernateφèêδΨ¦γö³ιÄèφ‰é娕δΙêηß²ιî¹
* ε°ûγéΑεQ¨εΑÜεΛßεΛßφèêεç΅φàëδΜ§γö³γîüδΚßεä¦ψIJηß¹ιÖçγΫ°φ•΅δögT_USER.hbm.xml
* δΙêηß²ιî¹φ€Κεàâô¹ΩεÖçδΚÜιïΩδΚ΄εäΓδΗ≠γö³φïΑφç°εä†ιî¹εΦÄιîÄεQ¨εΛßεΛßφèêεç΅δΚÜεΛßεΤàεèëι΅èδΗ΄γö³Ψp»ùΜüφï¥δΫ™φÄßηÉΫηΓ®η±ΓψÄ?br /> *
*/
public void addOptimismLock(){
Criteria criteria = session.createCriteria(TUser.class);
criteria.add(Expression.eq("name","Erica"));
List userList = criteria.list();
TUser user = (TUser)userList.get(0);
Transaction tx = session.beginTransaction();
user.setVersion(1);
tx.commit();
}
/**
* εÖ≥ι½≠ηΒ³φΚê
*/
protected void tearDown() throws Exception {
try{
session.close();
}catch(HibernateException e){
e.printStackTrace();
}
}
}
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"httpεQ?/hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<!--
none:φ½†δΙêηß²ιî¹
version:ιÄöηΩ΅γâàφ€§φ€ΚεàΕε°ûγéΑδΙêηß²ιî?br /> dirty:ιÄöηΩ΅΄²ÄφüΞεèëγîüεè‰εä®ηΩ΅γö³ε±ûφÄßε°ûγéνCΙêηß²ιî¹
allιÄöηΩ΅΄²ÄφüΞφâÄφ€âε±ûφÄßε°ûγéνCΙêηß²ιî¹
-->
<class
name="org.hibernate.sample.TUSER"
table="t_user"
dynamic-update="true"
dynamic-insert="true"
optimistic-lock="version"
lazy="true"
>
<id
name="id"
column="id"
type="java.lang.Integer"
>
<generator class="native">
</generator>
</id>
<version name="version" column="version" type="java.lang.Integer">
</version>
<set name="addresses"
table="t_address"
lazy="true"
inverse="false"
cascade="all"
>
<key
column="user_id"
>
</key>
<one-to-many class=""/>
</set>
</class>
</hibernate-mapping>
]]>
VOδΗéPOγö³δΗΜηΠ¹ε¨ΚεàΪε€®δΚéοΦö
1ψĹVOφ‰·γ¦Ηε·Ι㴧γΪ΄γö³ε°ûδΫ™ε·Ιη±ΓεQ¨εΛ³δΚéιùûΫéΓγêÜγäΕφĹψÄ?br /> 2ψĹPOφ‰·γî±HibernateΨU¦_ÖΞεÖΕε°ûδΫ™γ°ΓγêÜε°Ιεô®γö³ε·Ιη±ΓεQ¨ε°ÉδΜΘηΓ®δΚÜδΗéφïΑφç°εΚ™δΗ≠φüêφùΓη°ΑεΫïε·ΙεΚîγö³Hibernateε°ûδΫ™εQ¨POγö³εè‰ε¨•ε€®δΚ΄εäΓφèêδΚΛφ½ΕεΑÜεèçφ‰†εàΑε°ûιôÖφïΑφç°εΚ™δΗ?br /> 3ψĹεΠ²φû€δΗÄδΗΣPOδΗéεÖΕε·ΙεΚîγö³Sessionε°ûδΨ΄εàÜγΠΜεQ¨ι²ΘδΙàφ≠Λφ½”ûΦ¨ε°ÉεèàδΦöεè‰φàêδΗÄδΗΣVOψÄ?br />
δΗçηΠÜ㦕equals/hashCodeφ•“é≥ïγö³φÉÖεÜΒδΗ΄φàëδΜ§ηΠ¹ιùΔε·Ιγö³ι½°ιΔ‰εQöε°ûδΫ™ε·Ιη±Γγö³ηΖ®sessionη·ÜεàΪψIJηßΘεܦ_äûφ≥ïδΗÄδΗΣφ‰·ε°ûγéΑφâÄηΑ™γö³εÄΦφ·îε·ΙοΦ¨εç¦_€®equals/hashCodeφ•“é≥ïδΗ≠οΦ¨ε·Ιε°ûδΫ™γ±Μγö³φâÄφ€âε±ûφÄßεÄΤDΩ¦ηΓ¨φ·îε·?ιôΛδΚÜεÄΦφ·îε·ΙοΦ¨‰q‰φ€âεèΠεΛ•δΗÄΩUçεüΚδΚéδΗöεäΓιÄΜηΨëγö³ε·Ιη±ΓεàΛε°öφ•ΙεΦèδΗöεäΓεÖ≥ιî°δΩΓφ¹·εàΛε°öψÄ?br />
tx.commint();φ•“é≥ïδΗ≠δΦöηΑÉγî®session.flush()φ•“é≥ïεQ¨ε€®flush()φ•“é≥ïδΗ≠δΦöφâßηΓ¨2δΗΣδΗΜηΠ¹δ™Qεä?br /> 1ψĹflushEverything();//εàδh•ΑφâÄφ€âφïΑφç?br /> 2ψĹexecute(0);//φâßηΓ¨φïΑφç°εΚ™SQLε°¨φàêφ¨¹δΙÖ娕εä®δΫ€ψÄ?br />
φïΑφç°Ψ~™ε≠‰εQöε€®γâΙε°öΦ΄§δögεüΚγΓÄδΗäγΦ™ε≠‰εΨÄεΨÄφ‰·φèêεç΅γ≥ΜΨlüφÄßηÉΫγö³εÖ≥ιî°ε¦†γ¥†ψIJγΦ™ε≠‰φ‰·φïΑφç°εΚ™φïΑφç°ε€®εÜÖε≠‰δΗ≠γö³δΗ¥φ½Εε°Ιεô®εQ¨ε°Éε¨ÖεêΪδΚÜεΚ™ηΓ®φïΑφç°ε€®εÜÖε≠‰δΗ≠γö³δΗ¥φ½Εφ΄·²¥ùεQ¨δΫçδΚéφïΑφç°εΚ™δΗéφïΑφç°η°Ωι½°ε±²δΙ΄ι½¥ψIJORMε€®ηΩ¦ηΓ¨φïΑφç°η·Μεè•φ½ΕεQ¨δΦöφ†“éç°εÖΕγΦ™ε≠‰γ°ΓγêÜγ≠•γïΞοΦ¨ιΠ•εÖàε€®γΦ™ε≠‰δΗ≠φüΞη·ΔεQ¨εΠ²φû€ε€®Ψ~™ε≠‰δΗ≠εèëγéΑφâÄι€ÄφïΑφç°εQ¨εàô㦥φéΞδΜΞφ≠ΛφïΑφç°δΫ€δΊ™φüΞη·ΔΨl™φû€εä†δΜΞεà©γî®εQ¨δΜéηĨι¹ΩεÖçδΚÜφïΑφç°εΚ™ηΑÉγî®γö³φÄßηÉΫεΦÄιîÄψÄ?br /> γ¦Ηε·ΙεÜÖε≠‰φ™çδΫ€ηĨη®ÄεQ¨φïΑφç°εΚ™ηΑÉγî®φ‰·δΗÄδΗΣδΜΘδΜΖιΪ‰φ‰²γö³‰q΅γ®΄εQ¨ε·ΙδΚéεÖΗεû΄δΦ¹δΗöεèäεΚîγî®Ψl™φû³εQ¨φïΑφç°εΚ™εΨÄεΨÄδΗéεΚîγî®φ€çεäΓεô®δΫçδΚéδΗçεê¨γö³γâ©γêÜφ€çεäΓεô®εQ¨ηΩôδΙüεΑ±φ³èεë≥γùÄφ·èφ§ΓφïΑφç°εΚ™η°Ωι½°ιÉΫφ‰·δΗÄ΄ΤΓηΩ€ΫE΄ηΑÉγî®οΦ¨Socketγö³εà¦εΜόZΗéιîÄφ·¹οΦ¨φïΑφç°γö³φâ™ε¨Öφ΄Üε¨ÖοΦ¨φïΑφç°εΚ™φâßηΓ¨φüΞη·ΔεëΫδΜΛοΦ¨Ψ|ëγΜ€δΦ†ηΨ™δΗäγö³εΜΕφ½ΕεQ¨ηΩôδΚ¦φΕàηĽιÉΫΨlôγ≥ΜΨlüφï¥δΫ™φÄßηÉΫιĆφàêδΚÜδΗΞι΅çεΣ³ε™çψÄ?br /> ORMγö³φïΑφç°γΦ™ε≠‰εΚîε¨ÖεêΪεΠ²δǴ塆δΗΣε±²φ§ΓεQ?br /> 1ψĹδΚ΄εäΓγώîΨ~™ε≠‰εQöδΚ΄εäΓγώîΨ~™ε≠‰φ‰·εüΚδΚéSessionγîüεëΫεë®φ€üε°ûγéΑγö³οΦ¨φ·èδΗΣSessionδΦöε€®εÜÖιÉ®Ψl¥φ¨¹δΗÄδΗΣφïΑφç°γΦ™ε≠‰οΦ¨φ≠ΛγΦ™ε≠‰ιöèγùÄSessionγö³εà¦εΜχôĨε≠‰ε€®ο֨妆φ≠ΛδΙüφàêδΗΚSession Level Cache(εÜÖιÉ®Ψ~™ε≠‰)
2ψĹεΚîγî®γώî/‰q¦γ®΄ΨUßγΦ™ε≠‰οΦöε€®φüêδΗΣεΚîγî®δΗ≠εQ¨φà•ηÄÖεΚîγî®δΗ≠φüêδΗΣ㴧γΪ΄φïΑφç°η°âK½°ε≠êι¦ÜδΗ≠γö³εÖΉÉμnΨ~™ε≠‰ψIJφ≠ΛΨ~™ε≠‰εè·γî±εΛöδΗΣδΚ΄γâ©εÖΉÉμnψÄ²ε€®HibernateδΗ≠οΦ¨εΚîγî®ΨUßγΦ™ε≠‰ε€®SessinFactoryε±²ε°ûγééΆΦ¨φâÄφ€âγî±φ≠ΛSessionFactoryεà¦εΨèγö³Sessionε°ûδΨ΄εÖΉÉμnφ≠ΛγΦ™ε≠‰ψIJεΛöε°ûδΨ΄ρqΕεèë‰qêηΓ¨γö³γé·εΔÉηΠ¹γâΙεàΪû°èεΩɉq¦γ®΄ΨUßγΦ™ε≠‰γö³ηΑÉγî®ψÄ?br /> 3ψĹεàÜεΗÉεΦèΨ~™ε≠‰εQöεàÜεΗÉεΦèΨ~™ε≠‰γî±εΛöδΗΣεΚîγî®γώîΨ~™ε≠‰ε°ûδΨ΄Ψl³φàêι¦ÜγΨΛεQ¨ιÄöηΩ΅φüêγßç‰q€γ®΄φ€ΚεàΕε°ûγéΑεê³δΗΣΨ~™ε≠‰ε°ûδΨ΄ι½¥γö³φïΑφç°εê¨φ≠ΞεQ¨δ™QδΫïδΗÄδΗΣε°ûδΨ΄γö³φïΑφç°δΩ°φîΙφ™çδΫ€εQ¨εΑÜε·ΤD΅¥φï¥δΗΣι¦ÜγΨΛι½¥γö³φïΑφç°γäΕφĹεê¨φ≠ΞψIJγî±δΚéεΛöδΗΣε°ûδΨ΄ι½¥γö³φïΑφç°εê¨φ≠Ξφ€Κεà”ûΦ¨φ·èδΗΣΨ~™ε≠‰ε°ûδΨ΄εèëγîüγö³εè‰εä®ιÉΫδΦöεΛçεàΕεàΑεÖΕδΫôφâÄφ€âηä²γ²ΙδΗ≠εQ¨ηΩôφ†οLö³‰q€γ®΄εê¨φ≠ΞεΦÄιîÄδΗçεè·εΩΫηßÜψÄ?br />
HibernateφïΑφç°Ψ~™ε≠‰εàÜδΊ™2δΗΣε±²΄ΤΓοΦ¨1ψĹεÜÖιÉ®γΦ™ε≠?ψĹδΚ¨ΨUßγΦ™ε≠‰hibernateδΗ≠οΦ¨Ψ~™ε≠‰û°Üε€®δΜΞδΗ΄φÉÖεÜΒδΗ≠εèëφ¨ΞδΫ€γî®οΦö
1ψĹιÄöηΩ΅IDεä†ηù≤φïΑφç°φ½?br /> ‰qôε¨Öφ΄§δΚÜφ†“éç°idφüΞη·ΔφïΑφç°γö³Session.loadφ•“é≥ïεQ¨δΜΞεèäSession.ierateΫ{âφâΙι΅èφüΞη·Δφ•Ιφ≥?br /> 2ψĹεög‰qüεä†ηΫ?br />
Sessionε€®ηΩ¦ηΓ¨φïΑφç°φüΞη·Δφ™çδΫ€φ½ΕεQ¨δΦöιΠ•εÖàε€®η΅ΣμwΪεÜÖιÉ®γö³δΗÄΨUßγΦ™ε≠‰δΗ≠‰q¦ηΓ¨φüΞφâΨεQ¨εΠ²φû€δΗÄΨUßγΦ™ε≠‰φ€ΣηÉΫεëΫδΗ≠οΦ¨εàôεΑÜε€®δΚ¨ΨUßγΦ™ε≠‰δΗ≠φüΞη·ΔεQ¨εΠ²φû€δΚ¨ΨUßγΦ™ε≠‰εëΫδΗ≠οΦ¨εàôδΜΞφ≠ΛφïΑφç°δΫ€δΗΚγΜ™φû€ηΩîε¦ûψÄ?br /> εΠ²φû€φïΑφç°φΜΓηÉωδΜΞδΗ΄φùΓδögεQ¨εàôεè·εΑÜεÖΕγΚ≥εÖΞγΦ™ε≠‰γ°Γγê?br /> 1ψĹφïΑφç°δΗçδΦöηΔΪΫW§δΗâφ•ΙεΚîγî®δΩ°φî?br /> 2ψĹφïΑφç°εΛßû°èε€®εè·φéΞεè½γö³η¨É妥δΙ΄εÜÖ
3ψĹφïΑφç°φ¦¥φ•ΑιΔëγé΅ηΨÉδΫ?br /> 4ψĹεê¨δΗÄφïΑφç°εè·ηÉΫδΦöηΔΪΨp»ùΜüιΔëγΙ¹εΦïγî®
5ψĹιùûεÖ≥ιî°φïΑφç°(εÖ≥ιî°φïΑφç°εQ¨εΠ²ι΅ëηûçη¥ΠφàΖφïΑφç°)
Hibernateφ€§ημnρqΕφ€ΣφèêδΨ¦δΚ¨γώîΨ~™ε≠‰γö³δώîε™¹ε¨•ε°ûγéΑ(εèΣφ‰·φèêδΨ¦δΚÜδΗÄδΗΣεüΚδΚéHashtableγö³γ°ÄεçïγΦ™ε≠‰δΜΞδΨ¦ηΑÉη·?εQ¨ηĨφ‰·δΗόZΦ½εΛöγö³ΫW§δΗâφ•ΙγΦ™ε≠‰γΜ³δΜΕφèêδΨ¦δΚÜφéΞεÖΞφéΞεèΘεQ¨φàëδΜ§εè·δΜΞφ†Ιφç°ε°ûιôÖφÉÖεÜΒιÄâφ΄©δΗçεê¨γö³γΦ™ε≠‰ε°ûγéΑγâàφ€§ψÄ?br />
]]>
equals:εè·δΜΞφ·îηΨÉεÜÖε°ΙεQ¨φ‰·2δΗΣε≠½ΫWΠδΗ≤εÜÖε°Ιγö³φ·îηΨÉψÄ?br /> ==εQöφïΑεÄΦφ·îηΨÉοΦ¨φ·îηΨÉγö³φ‰·εÜÖε≠‰ε€ΑεùÄγö³εÄΦφ‰·εêΠγ¦ΗΫ{âψÄ?br />
δΗÄδΗΣε≠½ΫWΠδΗ≤û°±φ‰·StringΨc»ùö³ε¨Ωεêçε·Ιη±ΓψÄ?br /> String name1 = new String("wyq");->εΦÄηΨüδΚÜ2δΗΣγ©Κι½Ώ_Φ¨εÖΕδΗ≠δΗÄδΗΣφ‰·εûÉε€ΨΫIΚι½¥ψÄ?br /> String name2 = "wyq";->εΦÄηΨüδΚÜδΗÄδΗΣγ©Κι½Ώ_Φ¨φâÄδΜΞεΚîη·ΞιÄâφ΄©ε°ÉψÄ?br />
Stringγö³εèΠδΗÄδΗΣγâΙ¨DäδΙ΄εΛ³οΦöStringδΫΩγî®δΚÜJavaδΗ≠γö³εÖΉÉμnφ®ΓεΦèεQ¨ε°ÉεèΣηΠ¹εèëγéΑε€®εÜÖε≠‰δΗ≠φ€âηΩôεù½φïΑφç°οΦ¨δΗçδΦöε€®εÜÖε≠‰δΗ≠ι΅çφ•ΑγîüφàêψÄ?br /> StringΨc÷MΗ≠γö³εÜÖε°ΙδΗÄφ½ΠεΘΑφ‰éεàôδΗçεè·φîΙεè‰ψÄ?br /> StringBufferδΗéStringγö³φ€§η¥®ε¨ΚεàΪοΦ¨ε€®δΚéStringBufferεè·δΜΞφîΙεè‰ψÄ?br />
thisεè·δΜΞηΑÉγî®φ€§γ±ΜδΗ≠γö³ε±ûφÄßοΦ¨δΙüεè·δΜΞηΑÉγî®φ€§Ψc÷MΗ≠γö³φ•Ιφ≥?εêΪφû³ιĆφ•Ιφ≥ïthis())ψÄ?br /> φ≥®φ³èεQöφû³ιĆφ•Ιφ≥ïφ€§μwΪεΩÖôε’d€®ιΠ•ηΓ¨ηΔΪδ΄…γî®οΦ¨δΗόZΚÜΨlôγ±ΜδΗ≠γö³ε±ûφÄßεàùεß΄ε¨•ψÄ?br /> thisηΑÉγî®ε±ûφÄßψĹφ€§ΨcάL•Ιφ≥ïψĹφû³ιĆφ•Ιφ≥ïηΩôδΗâγ²Ιφ‰·thisγö³εüΚφ€§εΚîγî®οΦ¨δΙüφ‰·φ€ÄεΗΗγî®γö³οΦ¨δΫÜφ‰·δΜΞδΗäδΗâγ²Ιε°ûιôÖδΗäεè·δΜΞγΜΦεêàφàêδΗÄγ²?--ηΓ®γΛΚεΫ™εâçε·Ιη±ΓψÄ?br /> thisηΓ®γΛΚεΫ™εâçε·Ιη±ΓδΗΜηΠ¹εΚîγî®ε€®δΗÄγ²ΙοΦöγî®δΚé‰q¦ηΓ¨ε·Ιη±Γγö³φ·îηΨÉψÄ?br />
 public boolean compare(Person p1){
public boolean compare(Person p1){

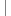 boolean flag = false; Person p2 = this; if(p1.name.equals(p2.name)&&p1.age==p2.age)
boolean flag = false; Person p2 = this; if(p1.name.equals(p2.name)&&p1.age==p2.age) {
{ flag = true;
flag = true;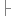 } return flag;
} return flag;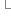 }
}]]>
Springε·Ιγ®΄εΚèφéßεàΕδΚ΄εäΓγ°ΓγêÜγö³φî·φ¨¹ε£¨EJBγö³φ€âεΨàεΛßδΗçεê¨ψIJEJBγö³δΚ΄εäΓγ°ΓγêÜ壨JTAε·ÜδΗçεè·εàÜεQ¨ε£¨EJBδΗçεê¨γö³φ‰·εQ¨SpringδΫΩγî®δΚÜδΗÄΩUçε¦ûηΑÉφ€Κεà”ûΦ¨φääγ€üε°ûγö³δΚ΄εäΓε°ûγéΑδΜéδΚ΄εäΓδΜΘγ†¹δΗ≠φäΫη±Γε΅ΚφùΞψIJιÄâφ΄©ΫE΄εΚèφéßεàΕδΚ΄εäΓΫéΓγê܉q‰φ‰·εΘΑφ‰éεΦèδΚ΄εäΓγ°ΓγêÜοΦ¨εΨàεΛßΫE΄εΚΠδΗäφ‰·ε€®γΜÜΨ_£εΚΠφéßεàΕδΗéγ°ÄδΨΩφ™çδΫ€δΙ΄ι½¥ε¹öε΅ΚεÜ≥ε°öψIJεΫ™δΫ†ε€®δΜΘγ†¹δΗ≠γΦ•εÜôδΚ΄εäΓφ½ΕεQ¨δΫ†ηÉΫγ≤ΨΦ΄°φéßεàΕδΚ΄εäΓγö³ηΨΙγï¨εQ¨ε€®δΫ†εΗ¨φ€¦γö³ε€Αφ•ΙΨ_³ΓΓ°γö³εΦÄεß΄ε£¨Ψl™φùüψIJεÖΗεû΄γö³φÉÖεÜΒδΗ΄οΦ¨δΫ†δΗçι€ÄηΠ¹γ®΄εΚèφéßεàΕδΚ΄εäΓφâÄφèêδΨ¦γö³γΜÜΨ_£εΚΠφéßεàΕεQ¨δΫ†δΦöιÄâφ΄©ε€®δΗäδΗ΄φ•΅ε°öδΙâφ•΅δögδΗ≠εΘΑφ‰éδΫ†γö³δΚ΄εäΓψÄ?/p>
Springε·ΙεΘΑφ‰éεΦèδΚ΄εäΓΫéΓγêÜγö³φî·φ¨¹φ‰·ιÄöηΩ΅ε°Éγö³AOPφΓÜφûΕε°ûγéΑγö³ψIJηΩôφ†Ζε¹öφ‰·ιùûεΗΗη΅Σγ³Εγö³εQ¨ε¦†δΗόZΚ΄εäΓφ‰·Ψp»ùΜüΨUßγö³εQ¨ε΅¨ι©ΨδΚéεΚîγî®γö³δΗΜηΠ¹εäüηÉΫδΙ΄δΗäγö³ψÄ?/p>
ε€®Spring顨οΦ¨δΚ΄εäΓε±ûφÄßφ‰·ε·ΙδΚ΄εäΓγ≠•γïΞεΠ²δΫïεΚîγî®εàΑφ•“é≥ïγö³φèè‰qΑψIJηΩôδΗΣφèè‰qΑε¨Öφ΄§οΦöδΦ†φ£≠ηΓ¨δΊ™ψĹιöîΦ¦»ùώîεàΪψĹεèΣη·άLèêΫCΚψĹδΚ΄εäΓηΕÖφ½âô½¥ιö?br /> δΦ†φ£≠ηΓ¨δΊ™εQ?br /> PROPAGATION_MANDATORY:ηΓ®γΛΚη·Ξφ•Ιφ≥ïεΩÖôεΜηΩêηΓ¨ε€®δΗÄδΗΣδΚ΄εäΓδΗ≠ψIJεΠ²φû€εΫ™εâçδΚ΄εäΓδΗçε≠‰ε€®εQ¨εΑÜφä¦ε΅ΚδΗÄδΗΣεΦ²εΗΗψÄ?br /> PROPAGATION_NESTED:ηΓ®γΛΚεΠ²φû€εΫ™εâçεΖ≤γΜèε≠‰ε€®δΗÄδΗΣδΚ΄εäΓοΦ¨εàôη·Ξφ•“é≥ïεΚîεΫ™‰qêηΓ¨ε€®δΗÄδΗΣεΒ¨εΞ½γö³δΚ΄εäΓδΗ≠ψIJηΔΪεΒ¨εΞ½γö³δΚ΄εäΓεè·δΜΞδΜéεΫ™εâçδΚ΄εäΓδΗ≠εçï㴧γö³φèêδΚΛφà•ε¦ûφΜöψIJεΠ²φû€εΫ™εâçδΚ΄εäΓδΗçε≠‰ε€®εQ¨ι²ΘδΙàε°É〴η™vφùΞ壨PROPAGATION_REQUIREDφ≤Γφ€âδΗΛφ†ΖψÄ?br /> PROPAGATION_NEVER:ηΓ®γΛΚεΫ™εâçγö³φ•Ιφ≥ïδΗçεΚîη·Ξ‰qêηΓ¨ε€®δΗÄδΗΣδΚ΄εäΓδΗäδΗ΄φ•΅δΗ≠ψIJεΠ²φû€εΫ™εâçε≠‰ε€®δΗÄδΗΣδΚ΄εäΓοΦ¨εàôδΦöφä¦ε΅ΚδΗÄδΗΣεΦ²εΗΗψÄ?br /> PROPAGATION_NOT_SUPPORTED:ηΓ®γΛΚη·Ξφ•Ιφ≥ïδΗçεΚîε€®δΚ΄εäΓδΗ≠ηΩêηΓ¨ψIJεΠ²φû€δΗÄδΗΣγéΑφ€âγö³δΚ΄εäΓφ≠Θε€®‰qêηΓ¨δΗ≠οΦ¨ε°ÉεΑÜε€®η·Ξφ•“é≥ïγö³ηΩêηΓ¨φ€üι½¥ηΔΪφ¨²η™vψÄ?br /> PROPAGATION_REQUIRED:ηΓ®γΛΚεΫ™εâçφ•“é≥ïεΩÖιΓΜ‰qêηΓ¨ε€®δΗÄδΗΣδΚ΄εäΓδΗ≠ψIJεΠ²φû€δΗÄδΗΣγéΑφ€âγö³δΚ΄εäΓφ≠Θε€®‰qêηΓ¨δΗ≠οΦ¨η·Ξφ•Ιφ≥ïεΑ܉qêηΓ¨ε€®ηΩôδΗΣδΚ΄εäΓδΗ≠ψIJεêΠεàôγö³η·ùοΦ¨ηΠ¹εΦÄεß΄δΗÄδΗΣφ•Αγö³δΚ΄εäΓψÄ?br /> PROPAGATION_REQUIRES_NEW:ηΓ®γΛΚεΫ™εâçφ•“é≥ïεΩÖιΓΜ‰qêηΓ¨ε€®ε°Éη΅ΣεΖ±γö³δΚ΄εäΓ顨ψIJε°Éû°Üεê·εä®δΗÄδΗΣφ•Αγö³δΚ΄εäΓψIJεΠ²φû€φ€âδΚ΄εäΓ‰qêηΓ¨γö³η·ùεQ¨εΑÜε€®ηΩôδΗΣφ•Ιφ≥ïηΩêηΓ¨φ€üι½¥ηΔΪφ¨²η™vψÄ?br /> PROPAGATION_SUPPORTS:ηΓ®γΛΚεΫ™εâçφ•“é≥ïδΗçι€ÄηΠ¹δΚ΄εäΓεΛ³γêÜγé·εΔÉοΦ¨δΫÜεΠ²φû€φ€âδΗÄδΗΣδΚ΄εäΓεΖ≤Ψlèε€®‰qêηΓ¨γö³η·ùεQ¨ηΩôδΗΣφ•Ιφ≥ïδΙüεè·δΜΞε€®ηΩôδΗΣδΚ΄εäΓ顨‰qêηΓ¨ψÄ?/p>
δΦ†φ£≠ηß³εàôε¦ûγ≠îδΚÜδΗÄδΗΣι½°ιΔ‰οΦöû°±φ‰·φ•Αγö³δΚ΄εäΓφ‰·εêΠηΠ¹ηΔΪεê·εä®φà•φ‰·ηΔΪφ¨²ηΒχPΦ¨φà•ηÄÖφ•Ιφ≥ïφ‰·εêΠηΠ¹ε€®δΚ΄εäΓγé·εΔÉδΗ≠‰qêηΓ¨ψÄ?/p>
ιöîγΠΜΨUßεàΪεQöε€®δΗÄδΗΣεÖΗεû΄γö³εΚîγî®δΗ≠οΦ¨εΛöδΗΣδΚ΄εäΓρqΕεèë‰qêηΓ¨εQ¨γΜèεΗφÄΦöφ™çδΫ€εê¨δΗÄδΗΣφïΑφç°φùΞε°¨φàêε°ÉδΜ§γö³δ™QεäΓψIJεΤàεèëοΦ¨ηôΫγ³Εφ‰·εΩÖôε»ùö³εQ¨δΫÜδΦöε·Φη΅¥δΗ΄ιùΔι½°ιΔ‰οΦö
1ψĹη³èη·ΜοΦöη³èη·Μεèëγîüε€®δΗÄδΗΣδΚ΄εäΓη·Μεè•δΚÜηΔΪεèΠδΗÄδΗΣδΚ΄εäΓφîΙεÜôδΫ܉q‰φ€ΣφèêδΚΛγö³φïΑφç°φ½ΕψIJεΠ²φû€ηΩôδΚ¦φîΙεè‰ε€®ΫEçεêéηΔΪε¦ûφΜöοΦ¨ι²ΘδΙàΫW§δΗÄδΗΣδΚ΄εäΓη·Μεè•γö³φïΑφç°û°±φ‰·φ½†φïàγö³ψÄ?br />
2ψĹδΗçεè·ι΅çεΛçη·ΜεQöδΗçεè·ι΅çεΛçη·Μεèëγîüε€®δΗÄδΗΣδΚ΄εäΓφâßηΓ¨γ¦Ηεê¨γö³φüΞη·Δ2΄ΤΓφà•2΄ΤΓδΜΞδΗäοΦ¨δΫÜφ·èδΗÄ΄ΤΓφüΞη·ΔγΜ™φû€ιÉΫδΗçεê¨φ½ΕψIJηΩôιÄöεΗΗφ‰·γî±δΚéεèΠδΗÄδΗΣεΤàεèëδΚ΄εäΓε€®2΄ΤΓφüΞη·ΔδΙ΄ι½¥φ¦¥φ•νCΚÜφïΑφç°ψÄ?br />
3ψĹεâρη·ΜοΦöρqΜη·Μ壨δΗçεè·ι΅çεΛçη·Μγ¦φÄΦΦψIJεΫ™δΗÄδΗΣδΚ΄εäΓη·Μεè•ε΅†ηΓ¨γΚΣεΫïεêéεQ¨εèΠδΗÄδΗΣεΤàεèëδΚ΄εäΓφè£εÖΞδΗÄδΚ¦η°ΑεΫïοΦ¨ρqΜη·Μû°±εèëγîüδΚÜψIJιöîΦ¦»ùώîεàΪφ€âεΠ²δǴ塆δΗΣεQ?br />
ISOLATION_DEFAULT:δΫΩγî®εêéγΪ·φïΑφç°εΚ™ιΜ‰η°Λγö³ιöîγΠΜΨUßεàΪ
ISOLATION_READ_UNCOMMITTED:εÖ¹η°ΗδΫ†η·Μεè•ηΩ‰φ€ΣφèêδΚΛγö³φîΙεè‰δΚÜγö³φïΑφç°εQ¨εè·ηÉΫε·Φη΅¥η³èη·ÖRĹεâρη·ÖRĹδΗçεè·ι΅çεΛçη·Μ
ISOLATION_READ_COMMITTED:εÖ¹η°Ηε€®εΤàεèëδΚ΄εäΓεΖ≤ΨlèφèêδΚΛεêéη·’dè•ψIJεè·ι‰≤φ≠Δη³èη·ΜεQ¨δΫÜρqΜη·Μ壨δΗçεè·ι΅çεΛçη·ΜδΜçεè·ηÉΫεèëγîüψÄ?br />
ISOLATION_REPEATABLE_READ:ε·Ιγ¦Ηεê¨ε≠½¨Dκäö³εΛöφ§Γη·’dè•γö³γΜ™φû€φ‰·δΗÄη΅¥γö³εQ¨ιôΛιùûφïΑφç°ηΔΪδΚ΄εäΓφ€§ημnφîΙεè‰ψIJεè·ι‰≤φ≠Δη³èη·Μ壨δΗçεè·ι΅çεΛçη·ΜεQ¨δΫÜρqΜη·ΜδΜçεè·ηÉΫεèëγîüψÄ?br />
ISOLATION_SERIALIZABLE:ε°¨εÖ®φ€çδΜéACIDγö³ιöîΦ¦»ùώîεàΪοΦ¨Φ΄°δΩùδΗçεèëγîüη³èη·ÖRĹδΗçεè·ι΅çεΛçη·Μ壨εâρη·ÖRIJηΩôε€®φâÄφ€âιöîΦ¦»ùώîεàΪδΗ≠δΙüφ‰·φ€ÄφÖΔγö³ψÄ?/p>
εèΣη·ΜεQöεΠ²φû€δΗÄδΗΣδΚ΄εäΓεèΣε·ΙεêéγΪ·φ‰·φç°εΚ™φâßηΓ¨η·άL™çδΫ€οΦ¨φïΑφç°εΚ™εΑ±εè·ηÉΫεà©γî®δΚ΄εäΓεèΣη·Μγö³γâΙφÄßοΦ¨δΫΩγî®φüêδΚ¦δ։娕φéΣφ•ΫψIJιÄöηΩ΅εΘΑφ‰éδΗÄδΗΣδΚ΄εäΓδΊ™εèΣη·ΜεQ¨δΫ†û°όqΜôδΚÜεêéγΪ·φïΑφç°εΚ™δΗÄδΗΣφ€ΚδΦöοΦ¨φùΞεΚîγî®ι²ΘδΚ¦ε°Éη°ΛδΊ™εêàιIJγö³δ։娕φéΣφ•ΫψÄ²ε¦†δΗΚεèΣη·»ùö³δ։娕φéΣφ•Ϋφ‰·ε€®δΚ΄εäΓεê·εä®φ½Εγî±εêéγΪ·φïΑφç°εΚ™ε°ûφ•Ϋγö³εQ¨φâÄδΜΞοΦ¨εèΣφ€âû°Üι²ΘδΚ¦εÖΖφ€âεè·ηÉΫεê·εä®φ•ΑδΚ΄εäΓγö³δΦ†φ£≠ηΓ¨δΗΚγö³φ•“é≥ïγö³δΚ΄εäΓφ†΅η°ΑφàêεèΣη·Μφâçφ€âφ³èδΙâ(PROPAGATION_REQUIRED,PROPAGATION_REQUIRES_NEW壨PROPAGATION_NESTED) TransactionProxyFactoryBeanεè²γÖßδΗÄδΗΣφ•Ιφ≥ïγö³δΚ΄εäΓε±ûφÄßοΦ¨εܦ_°öεΠ²δΫïε€®ι²ΘδΗΣφ•Ιφ≥ïδΗäφâßηΓ¨δΚ΄εäΓΫ{•γïΞψÄ?br />
 <?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd"> <bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean"> <property name="jndiName"> <value>java:comp/env/jdbc/myDatasource</value> </property> </bean> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource"> <ref bean="dataSource"/> </property> </bean> <!-- ‰qôδΗΣε·Ιη±Γφ€âδΗÄδΗΣεÄιgΊ™courseServiceγö³id.εΫ™εΚîγî®δΜéεΚîγî®δΗäδΗ΄φ•΅ι΅¨η·δh±²δΗÄδΗΣcourseServiceφ½”ûΦ¨ε°ÉεΑÜεΨ½εàΑδΗÄδΗΣηΔΪ TransactionProxyFactoryBeanε¨ÖηΘΙγö³ε°ûδΨ΄ψÄ?nbsp;--> <bean id="courseService" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean"> <!-- δΜΘγêÜφâÄε°ûγéΑγö³φéΞεè?nbsp;--> <property name="proxyInterfaces"> <list> <value> com.springinaction.training.service.CourseService </value> </list> </property> <!-- ηΔΪδΜΘγêÜγö³ε·Ιη±Γ --> <property name="target"> <ref bean="courseServiceTarget"/> </property> <!-- δΚ΄εäΓΫéΓγêÜεô?nbsp;--> <property name="transactionManager"> <ref bean="transactionManager"/> </property> <!-- δΚ΄εäΓγö³ε±ûφÄßφΚê --> <property name="transactionAttributeSource"> <ref bean="transactionAttributeSource"/> </property> </bean> <!-- ηΠ¹γüΞι¹™εΑΫΫéΓεè·δΜΞφîΙεè‰MatchAlwaysTransactionAttributeSourceγö³δΚ΄εäΓε±ûφÄßεè²φïéΆΦ¨δΫÜε°ÉφÄάL‰·‰qîε¦ûγ¦Ηεê¨γö³δΚ΄εäΓε±ûφÄßοΦ¨ηÄ?br />
δΗçεÖ≥εΩÉεè²δΗéδΚΛφ‰™γö³ε™ΣδΗÄδΗΣφ•Ιφ≥ïψIJεΫ™δΫ†φ€âδΗÄδΗΣγ¦Ηε·Ιγ°Äεçïγö³εΚîγî®εQ¨φääεê¨φ†Ζγö³δΚ΄εäΓγ≠•γïΞεΚîγî®εàΑφâÄφ€âφ•Ιφ≥ïιÉΫφ≤Γι½°ιΔ‰φ½ΕεQ¨δ΄…γî®MatchAlwaysT ransactionAttributeSourceû°όq¦ΗεΫ™εΞΫψIJδΫÜφ‰·οΦ¨ε€®ι²ΘδΚ¦φ¦¥δΗΚεΛçφù²γö³εΚîγî®δΗ≠οΦ¨δΫ†εΨàεè·ηÉΫι€ÄηΠ¹ε·ΙδΗçεê¨γö³φ•Ιφ≥ïεΚîγî®δΗçεê¨γö³δΚ΄εäΓΫ{•γïΞψÄ²ε€®ι²Θφ†Ζ φÉÖεÜΒδΗ΄οΦ¨δΫ†ι€ÄηΠ¹ε€®εΚîγî®δΫïγßçΫ{•γïΞγö³ι½°ιΔ‰δΗäε¹öφ¦¥εΛöγ≤ΨΦ΄°γö³φéßεàΕψÄ?nbsp;--> <bean id="transactionAttributeSource" class="org.springframework.transaction.interceptor.MatchAlwaysTransactionAttributeSource"> <property name="transactionAttribute"> <ref bean="myTransactionAttribute"/> </property> </bean> <!-- ε°öδΙâδΚ΄εäΓΫ{•γïΞ --> <bean id="myTransactionAttribute" class="org.springframework.transaction.interceptor.DefaultTransactionAttribute"> <!-- δΦ†φ£≠ηΓ¨δΊ™ --> <property name="propagationBehaviorName"> <value>PROPAGATION_REQUIRES_NEW</value> </property> <!-- ιöîγΠΜΨUßεàΪ --> <property name="isolationLevelName"> <value>ISOLATION_REPEATABLE_READ</value> </property> </bean></beans>
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd"> <bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean"> <property name="jndiName"> <value>java:comp/env/jdbc/myDatasource</value> </property> </bean> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource"> <ref bean="dataSource"/> </property> </bean> <!-- ‰qôδΗΣε·Ιη±Γφ€âδΗÄδΗΣεÄιgΊ™courseServiceγö³id.εΫ™εΚîγî®δΜéεΚîγî®δΗäδΗ΄φ•΅ι΅¨η·δh±²δΗÄδΗΣcourseServiceφ½”ûΦ¨ε°ÉεΑÜεΨ½εàΑδΗÄδΗΣηΔΪ TransactionProxyFactoryBeanε¨ÖηΘΙγö³ε°ûδΨ΄ψÄ?nbsp;--> <bean id="courseService" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean"> <!-- δΜΘγêÜφâÄε°ûγéΑγö³φéΞεè?nbsp;--> <property name="proxyInterfaces"> <list> <value> com.springinaction.training.service.CourseService </value> </list> </property> <!-- ηΔΪδΜΘγêÜγö³ε·Ιη±Γ --> <property name="target"> <ref bean="courseServiceTarget"/> </property> <!-- δΚ΄εäΓΫéΓγêÜεô?nbsp;--> <property name="transactionManager"> <ref bean="transactionManager"/> </property> <!-- δΚ΄εäΓγö³ε±ûφÄßφΚê --> <property name="transactionAttributeSource"> <ref bean="transactionAttributeSource"/> </property> </bean> <!-- ηΠ¹γüΞι¹™εΑΫΫéΓεè·δΜΞφîΙεè‰MatchAlwaysTransactionAttributeSourceγö³δΚ΄εäΓε±ûφÄßεè²φïéΆΦ¨δΫÜε°ÉφÄάL‰·‰qîε¦ûγ¦Ηεê¨γö³δΚ΄εäΓε±ûφÄßοΦ¨ηÄ?br />
δΗçεÖ≥εΩÉεè²δΗéδΚΛφ‰™γö³ε™ΣδΗÄδΗΣφ•Ιφ≥ïψIJεΫ™δΫ†φ€âδΗÄδΗΣγ¦Ηε·Ιγ°Äεçïγö³εΚîγî®εQ¨φääεê¨φ†Ζγö³δΚ΄εäΓγ≠•γïΞεΚîγî®εàΑφâÄφ€âφ•Ιφ≥ïιÉΫφ≤Γι½°ιΔ‰φ½ΕεQ¨δ΄…γî®MatchAlwaysT ransactionAttributeSourceû°όq¦ΗεΫ™εΞΫψIJδΫÜφ‰·οΦ¨ε€®ι²ΘδΚ¦φ¦¥δΗΚεΛçφù²γö³εΚîγî®δΗ≠οΦ¨δΫ†εΨàεè·ηÉΫι€ÄηΠ¹ε·ΙδΗçεê¨γö³φ•Ιφ≥ïεΚîγî®δΗçεê¨γö³δΚ΄εäΓΫ{•γïΞψÄ²ε€®ι²Θφ†Ζ φÉÖεÜΒδΗ΄οΦ¨δΫ†ι€ÄηΠ¹ε€®εΚîγî®δΫïγßçΫ{•γïΞγö³ι½°ιΔ‰δΗäε¹öφ¦¥εΛöγ≤ΨΦ΄°γö³φéßεàΕψÄ?nbsp;--> <bean id="transactionAttributeSource" class="org.springframework.transaction.interceptor.MatchAlwaysTransactionAttributeSource"> <property name="transactionAttribute"> <ref bean="myTransactionAttribute"/> </property> </bean> <!-- ε°öδΙâδΚ΄εäΓΫ{•γïΞ --> <bean id="myTransactionAttribute" class="org.springframework.transaction.interceptor.DefaultTransactionAttribute"> <!-- δΦ†φ£≠ηΓ¨δΊ™ --> <property name="propagationBehaviorName"> <value>PROPAGATION_REQUIRES_NEW</value> </property> <!-- ιöîγΠΜΨUßεàΪ --> <property name="isolationLevelName"> <value>ISOLATION_REPEATABLE_READ</value> </property> </bean></beans>
ιôΛδΚÜû°ÜtransactionAttributeSourceε·Ιη±ΓΨl΅εÖΞεàΑTransactionProxyFactoryBeanγö³transactionAttributeSourceε±ûφÄßδΗ≠εΛ•οΦ¨‰q‰φ€âδΗÄΩUçγ°Äεçïγö³φ•“é≥ïψIJεèëε±ïεàΑγéΑε€®εQ¨TransactionProxyFactoryBeanδΙüφ€âδΗÄδΗΣtransactionAttributesε±ûφÄßδΊ™transactionProperties.
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd"> <bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean"> <property name="jndiName"> <value>java:comp/env/jdbc/myDatasource</value> </property> </bean> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource"> <ref bean="dataSource"/> </property> </bean> <!-- ‰qôδΗΣε·Ιη±Γφ€âδΗÄδΗΣεÄιgΊ™courseServiceγö³id.εΫ™εΚîγî®δΜéεΚîγî®δΗäδΗ΄φ•΅ι΅¨η·δh±²δΗÄδΗΣcourseServiceφ½”ûΦ¨ε°ÉεΑÜεΨ½εàΑδΗÄδΗΣηΔΪ TransactionProxyFactoryBeanε¨ÖηΘΙγö³ε°ûδΨ΄ψÄ?nbsp;--> <bean id="courseService" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean"> <!-- δΜΘγêÜφâÄε°ûγéΑγö³φéΞεè?nbsp;--> <property name="proxyInterfaces"> <list> <value> com.springinaction.training.service.CourseService </value> </list> </property> <!-- ηΔΪδΜΘγêÜγö³ε·Ιη±Γ --> <property name="target"> <ref bean="courseServiceTarget"/> </property> <!-- δΚ΄εäΓΫéΓγêÜεô?nbsp;--> <property name="transactionManager"> <ref bean="transactionManager"/> </property> <!-- δΚ΄εäΓγö³ε±ûφÄßφΚê --> <property name="transactionAttributeSource"> <ref bean="transactionAttributeSource"/> </property> </bean> <!-- NameMatchTransactionAttributeSourceγö³propertiesε±ûφÄßφääφ•“é≥ïεêçφ‰†û°³εàΑδΚ΄εäΓε±ûφÄßφèè‰qΑεô®δΗäψIJφ≥®φ³èCourseException γî®δΗÄδΗΣη¥üεèδh†΅η°ΑψIJεΦ²εΗΗεè·δΜΞγî®η¥üεèΖφà•φ≠Θεèδh†΅η°éΆΦ¨εΫ™η¥üεèΖεΦ²εΗΗφä¦ε΅Κφ½ΕεQ¨εΑÜηßΠεèëε¦ûφΜö;γ¦Ηεèçγö³οΦ¨φ≠ΘεèΖεΦ²εΗΗηΓ®γΛΚδΚ΄εäΓδΜçεè·φèêδΚΛεQ¨εç≥δΫΩηΩôδΗΣεΦ²εΗΗφä¦ε΅?nbsp;--> <bean id="transactionAttributeSource" class="org.springframework.transaction.interceptor.NameMatchTransactionAttributeSource"> <property name="properties"> <props> <prop key="enrollStudentInCourse"> PROPAGATION_REQUIRES_NEW,ISOLATION_REPEATABLE_READ,readOnly, -CourseException </prop> <!-- ‰q‰εè·δΜΞδ΄…γî®ιÄöιÖçΫW?nbsp;--> <prop key="get*"> PROPAGATION_SUPPORTS </prop> </props> </property> </bean></beans>
]]>
package com.testproject.hibernate;import java.util.Iterator;import java.util.List;import org.hibernate.Query;import org.hibernate.Session;public class HibernateSqlQuery { Session session = null; public void querySql(){ String sql = "select {usr.*} from T_User usr"; List list = session.createSQLQuery(sql).addEntity("usr", TUser.class).list(); Iterator it = list.iterator(); while(it.hasNext()){ TUser user = (TUser)it.next(); } } public void queryMappingSql(){ Query query = session.getNamedQuery("queryUser"); query.setParameter("name","Erica"); Iterator it = query.list().iterator(); while(it.hasNext()){ TUser user = (TUser)it.next(); } }}
<?xml version="1.0"?><!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd"><hibernate-mapping> <class name="com.testproject.hibernate.TUser" table="T_USER"> <id name="id" column="id"> <generator class="native"></generator> </id> </class> <sql-query name="queryUser"> <![CDATA[ select {usr.*} from T_User usr where name=:name ]]> <return alias = "usr" class="com.testproject.hibernate.TUser"></return> </sql-query> <!-- εüόZΚéε≠‰ε²®‰q΅γ®΄φüΞη·Δ sql-queryηä²γ²Ιγö³callableε±ûφÄßη°Ψε°öδΊ™true,φ¨΅φ‰éεΫ™εâçφüΞη·ΔεüόZΚéε≠‰ε²®‰q΅γ®΄ε°öδΙâ--> <sql-query name="getUsersByAge" callable="true"> <return alias="user" class="com.testproject.hibernate.TUser"> <return-property name="id" column="ID"></return-property> <return-property name="name" column="NAME"></return-property> <return-property name="age" column="AGE"></return-property> </return> {?=call getUsersByAge(?)} </sql-query></hibernate-mapping>
δΗéHQLγ¦Ηεê¨εQ¨Native SQLδΙüεè·δΜΞε€®ε°ûδΫ™φ‰†εΑ³φ•΅δögδΗ≠ηΩ¦ηΓ¨ιÖçΨ|°οΦö
]]>
]]>
ε±ûφÄßφüΞη·ΔοΦöφ€âφ½ΕφàëδΜ§ρqΕδΗçι€ÄηΠ¹ηéΖεè•ε°¨φï¥γö³ε°ûδΫ™ε·Ιη±ΓεQ¨εèΣι€ÄηΠ¹γéΑε°ûιÉ®εàÜεà½εQ¨ιÄöηΩ΅HQLδΙüεè·δΜΞε¹öεàΑηΩôγ²ΙοΦ¨εΠ²οΦö"select user.name,user.age form TUser user"ηΓ®φ‰éφàëδΜ§ι€ÄηΠ¹η·Μεè•name壨ageε±ûφÄßγö³εÜÖε°ΙεQ¨ηĨφ≠Λφ½”ûΦ¨‰qîε¦ûγö³listφïΑφç°Ψl™φû³δΗ≠οΦ¨φ·èδΗΣφùΓγ¦°ιÉΫφ‰·δΗÄδΗΣε·Ιη±ΓφïΑΨl?Object[]),εÖΕδΗ≠δΗÄ΄ΤΓε¨ÖεêΪδΚÜφàëδΜ§φâÄηéΖεè•γö³ε±ûφÄßφïΑφç°ψÄ?br /> εΠ²φû€ηßâεΨ½‰qîε¦ûφïΑγΜ³γö³φ•ΙεΦèδΗçεΛüγ§ΠεêàιùΔεêëε·Ιη±Γγö³ιΘéφ†ΦεQ¨φàëδΜ§εè·δΜΞιÄöηΩ΅ε€®HQLδΗ≠εä®φĹφû³ιĆε·Ιη±Γε°ûδΨ΄γö³φ•“é≥ïε·ΙηΩôδΚ¦εψ^ιùΔ娕γö³φïΑφç°ηΩ¦ηΓ¨εΑ¹ηΘÖψÄ?select new TUser(user.name,user.age) from TUser user",φàëδΜ§ιÄöηΩ΅HQLηéΖεè•φïΑφç°γö³ιÉ®εàÜε±ûφÄßεÄϊ|Φ¨δΗéφ≠Λεê¨φ½ΕεQ¨φàëδΜ§δΙüεè·δΜΞε€®HQLγö³selectε≠½εèΞδΗ≠δ΄…γî®γΜüη°Γε΅ΫφïéΆΦ¨γîöη΅≥εéüγîüSQLε΅ΫφïΑεQ¨φà•ηÄÖεà©γî®distinctεÖ≥ιî°ε≠½οΦ¨εâîιôΛ‰qîε¦ûι¦ÜδΗ≠γö³ι΅çεΛçη°ΑεΫïψÄ?/p>
ε°ûδΫ™φ¦¥φ•ΑδΗéεà†ιôΛοΦöε€®Hibernate2δΗ≠οΦ¨HQLδΜÖδΜÖγî®δΚéφïΑφç°φüΞη·ΔεQ¨ηÄ¨ε€®Hibernate3δΗ≠οΦ¨HQLεÖΖεΛ΅δΚÜφ¦¥εä†εΦΚεΛßγö³εäüηÉΫψIJε°ûδΫ™φ¦¥φ•νCΗéεà†ιôΛû°±φ‰·εÖΕδΗ≠γö³δΗΜηΠ¹γâΙεΨ¹δΙ΄δΗÄψÄ?/p>
εàÜγ̳壨φé£εΚèοΦöδΗéSQLΨc÷MΦΦεQ¨HQLιÄöηΩ΅order byε≠êεèΞε°ûγéΑε·“éüΞη·ΔγΜ™φû€γö³φé£εΚèεQ¨order byε≠êεèΞεè·δΜΞφ¨΅ε°öεΛöδΗΣφé£εΚèφùΓδögεQ?from TUser user order by user.name ,user.age desc"ιÄöηΩ΅Group byε≠êεèΞεè·ηΩ¦ηΓ¨εàÜΨl³γΜüη°ΓψIJεΠ²εQ?select count(user),user.age from TUser user group by user.age",φàëδΜ§γüΞι¹™whereε≠êεèΞεè·δΜΞε·Ιη°ΑεΫïηΩ¦ηΓ¨γî³ιÄâψIJι²ΘδΙàοΦ¨ε·ΙδΚéGroup byε≠êεèΞηéΖεΨ½γö³γΜ™φû€ι¦ÜφàëδΜ§εè·δΜΞιÄöηΩ΅Havingε≠êεèΞ‰q¦ηΓ¨γî³ιÄâψIJδΨ΄εΠ²οΦö"select count(user),user.age from TUser user gourp by user.age having count(user)>10".
εè²φïΑΨlëε°öεQöγ±ΜδΦΦJDBCδΗ≠γö³SQLφ™çδΫ€εQ¨φàëδΜ§εè·δΜΞιÄöηΩ΅ôεΚεΚèεç†δΫçΫW??"ε·Ιεè²φïΑηΩ¦ηΓ¨φ†΅η·ÜοΦ¨ρqΕε€®δΙ΄εêéε·Ιεè²φïΑεÜÖε°ΙηΩ¦ηΓ¨εΓΪεÖÖψIJεΨèη°°δ΄…γî®QueryφéΞεèΘ"from TUser user where user.name=? and user.age>?",‰qô顨ιôΛδΚÜôεΚεΚèεç†δΫçΫWΠοΦ¨φàëδΜ§‰q‰εè·δΜΞδ΄…γî®εΦïγî®εç†δΫçγ§ΠεQ¨εΠ²εQ?from TUser where name=:name"εè²φïΑΨlëε°öφ€ΚεàΕεè·δΜΞδΫΩεΨ½φüΞη·Δη·≠φ≥ïδΗéεÖΖδΫ™εè²φïΑφïΑεÄΦγ¦Ηδʣ㴧γΪ΄ψIJηΩôφ†χPΦ¨ε·ΙδΚéεè²φïΑδΗçεê¨εQ¨φüΞη·Δη·≠φ≥ïγ¦Ηεê¨γö³φüΞη·Δφ™çδΫ€εQ¨φïΑφç°εΚ™εç¦_è·ε°ûφ•ΫφÄßηÉΫδ։娕Ϋ{•γïΞψIJεê¨φ½”ûΦ¨εè²φïΑΨlëε°öφ€ΚεàΕδΙüφù€ΨlùδΚÜεè²φïΑεÄΦε·ΙφüΞη·Δη·≠φ≥ïφ€§ημnγö³εΣ³ε™çψÄ?/p>
εΦïγî®φüΞη·ΔεQöSQLη·≠εèΞφΖδhù²ε€®δΜΘγ†¹δΙ΄ι½¥εΑÜㆥεùèδΜΘγ†¹γö³εè·η·άLÄßοΦ¨ρqΕδ΄…εΨ½γ≥ΜΨlüγö³εè·γΜ¥φäΛφÄßιôçδΫéψÄ²δΊ™δΚÜι¹ΩεÖçηΩôφ†οLö³φÉÖεÜΒε΅ΚγéΑεQ¨φàëδΜ§ιÄöεΗΗι΅΅εè•û°ÜSQLιÖçγ۰娕γö³φ•ΙεΦèεQ¨δΙüû°±φ‰·û°ÜSQLδΩùε≠‰ε€®ιÖçΨ|°φ•΅δΜΕδΗ≠εQ¨ι€ÄηΠ¹ηΑÉγî®γö³φ½ΕεÄôε€®‰q¦ηΓ¨η·’dè•ψÄ?br />
<query name="queryByName">
<![CDATA[
from TUser user where user.name=:name
]]>
</query>
δΙ΄εêéεQ¨φàëδΜ§εè·ιÄöηΩ΅session.getNamedQueryφ•“é≥ïδΜéιÖçΨ|°φ•΅δΜΕδΗ≠ηΑÉγî®εΦïγî®γö³HQL.
η¹îεêàφüΞη·ΔεQöinner join,left outer join,right outer join,full join
ε≠êφüΞη·ΔοΦöεΠ²οΦö"from TUser user where (select count(*) from user.addresses)>1"HQLδΗ≠οΦ¨ε≠êφüΞη·ΔεΩÖôε’d΅ΚγéΑε€®whereε≠êεèΞδΗ≠οΦ¨δΗîεΩÖôε÷MΜΞδΗÄε·Ιε€Üφ΄§εèΖε¨Ö妥ψÄ?br />
φïΑφç°εä†ηù≤φ•ΙεΦèεQöHibernateφî·φ¨¹δΜΞδǴ塆γßçφïΑφç°εä†ηù≤φ•ΙεΦèεQ?br />
1ψĹεç≥φ½Εεä†ηΫΫοΦöεΫ™ε°ûδΫ™εä†ηΫΫε°¨φ·ïεêéεQ¨γΪ΄εç¦_ä†ηΫΫεÖΕεÖ¨ô¹îφïΑφç°ψÄ?br />
2ψĹεög‰qüεä†ηΫΫοΦöε°ûδΫ™εä†ηù≤φ½”ûΦ¨εÖΕεÖ≥η¹îφïΑφç°εΤàιùûεç≥εàΜηéΖεè•οΦ¨ηĨφ‰·εΫ™εÖ≥η¹îφïΑφç°γ§§δΗÄ΄ΤΓηΔΪη°âK½°φ½ΕεÜç‰q¦ηΓ¨η·’dè•ψÄ?br />
3ψĹιΔ³εÖàεä†ηΫΫοΦöιΔ³εÖàεä†ηù≤φ½”ûΦ¨ε°ûδΫ™εèäεÖΕεÖ¨ô¹îε·Ιη±Γεê¨φ½Εη·’dè•εQ¨ηΩôδΗéεç≥φ½Εεä†ηΫΫγ±ΜδΦΙ{Ä?br />
4ψĹφâΙι΅èεä†ηΫΫοΦöε·ΙδΚéεçœx½Εεä†ηù≤壨εög‰qüεä†ηΫΫοΦ¨εè·δΜΞι΅΅γî®φâöw΅èεä†ηù≤φ•ΙεΦè‰q¦ηΓ¨φÄßηÉΫδΗäγö³δ։娕ψÄ?/p>
φ½Δγ³Ει€ÄηΠ¹εΑÜε°ûδΫ™Beanφ‰†εΑ³εàΑε≠‰ε²®φΚêδΗ≠οΦ¨εΚîγî®η²·ε°öι€ÄηΠ¹φèêδΨ¦φ™çδΫ€RDBMSγö³δΜΘγ†¹ψÄ?br /> BeanΫéΓγêÜφ¨¹δΙÖ娕ε°ûδΫ™Bean,φ‰·φâ΄εΖΞε°¨φàêφ¨¹δΙÖ娕ηΓ¨δΊ™γö³EJBΨc’dû΄ψIJφçΔεèΞη·ùφâÄεQ¨γΜ³δΜΕεΦÄεèëηÄÖεΩÖôε’dΦÄεèëδΜΘγ†¹οΦ¨δΜΞεΑÜεÜÖε≠‰δΗ≠γö³φ¨¹δΙÖ娕εüüε≠‰ε²®εàΑεΚïε±²ε≠‰ε²®φΚêδΗ≠ψIJηΩôΩUçφ•ΙεΦèφàêδΗΚBMPψÄ?br /> EJBηß³η¨É‰q‰φèêδΨ¦δΚÜBMPγö³φ¦ΩδΜΘγΜ³δΜΕγ±Μεû΄οΦöεÄüεä©δΚéEJBε°Ιεô®ε°¨φàêφïΑφç°γö³φ¨¹δΙÖ娕ψIJηΩôû°±φ‰·ε°Ιεô®ΫéΓγêÜφ¨¹δΙÖε¨?CMP)ψIJφ≠Λφ½”ûΦ¨ιÄöεΗΗιÉΫηΠ¹û°Üφ¨¹δΙÖ娕ιÄΜηΨëδΜéCMPδΗ≠εâΞΦ¦’d΅ΚφùΞψIJγ³ΕεêéεÄüεä©δΚéε°Ιεô®φèêδΨ¦γö³εΖΞεÖΖε°¨φàêφïΑφç°γö³η΅Σεä®φ¨¹δΙÖ娕ψIJφ€Äεê?EJBε°Ιεô®û°Üγîüφàêη°Ωι½°φïΑφç°εΚ™γö³δΜΘγ†¹ψIJφ≥®φ³èοΦ¨CMPφ‰·γ΄§γΪ΄δΚéδΜ÷MΫïO/RMappingφäÄφ€·γö³φïΑφç°ε·Ιη±ΓεQ¨ε¦†φ≠Λεè·δΜΞε€®εê³γßçδΦ¹δΗöγé·εΔÉδΗ≠ι΅çγî®CMPΨl³δögψÄ?br /> CMPφû¹εΛßε΅èεΑëδΚÜε°ûδΫ™Beanγö³δΜΘγ†¹ι΅èεQ¨ε¦†δΗόZΗçγî®γ¦¥φéΞγΦ•εÜôJDBCδΜΘγ†¹δΚÜψIJEJBε°Ιεô®û°ÜδΦöεΛ³γêÜφâÄφ€âγö³φ¨¹δΙÖ娕φ™çδΫ€οΦ¨‰qôφ‰·EJBεäΩηÉΫεΚîγî®γö³δΦ‰εäΩδΙ΄δΗÄψÄ?br /> ε€®φâßηΓ¨ejbCreate()φ•“é≥ïφ€üι½¥εQ¨εç≥ε€®εàùεß΄ε¨•εÜÖε≠‰δΗ≠γö³ε°ûδΫ™Beanφ½”ûΦ¨û°ÜδΦöε€®εΚïε±²RDBMSδΗ≠φè£εÖΞφ•Αγö³η°ΑεΫïοΦ¨ρqΕεΑ܉qôδΚ¦η°ΑεΫïεê¨ε°ûδΫ™Beanε°ûδΨ΄εΜΚγΪ΄ηΒδh‰†û°³εÖ≥ΨpÖRIJεΫ™ηΑÉγî®BMPε°ûδΫ™Beanγö³ejbCreate()φ½”ûΦ¨ε°ÉεΑÜη¥üη¥ΘγîüφàêRDBMSδΗ≠γö³φïΑφç°ψIJγ±ΜδΦΦγö³εQ¨εΫ™ηΑÉγî®BMPε°ûδΫ™Beanγö³ejbRemo()φ½”ûΦ¨ε°ÉεΑÜη¥üη¥ΘRDBMSδΗ≠φïΑφç°γö³εà†ιôΛψÄ?/p>
ε€®EJBιΔÜεüüδΗ≠οΦ¨ε°ΔφàΖρqΕφ≤Γφ€â㦥φéΞηΑÉγî®EJBε°ûδΨ΄εQ¨ε°ÉδΜ§δΜÖδΜÖηΑÉγî®δΚÜEJBε·Ιη±ΓδΜΘγêÜψIJεÄüεä©δΚéHomeε·Ιη±ΓηÉΫεΛüγîüφàêEJBε·Ιη±ΓψÄ²ε¦†φ≠ΛοΦ¨ε·ΙδΚéε°öδΙâε€®EJB BeanΨc÷MΗ≠γö³εê³δΗΣejbCreate()φ•“é≥ïεQ¨ε€®HomeφéΞεèΘδΗ≠δΙüû°Üε≠‰ε€®ε·Ιη±Γγö³create()φ•“é≥ïψIJεΫ™ε°ΔφàΖηΑÉγî®Homeε·Ιη±Γγö³create()φ•“é≥ïφ½”ûΦ¨ε°Ιεô®û°ÜφääηΑÉγî®η·δh±²εßîφ¥ΨΨlôejbCreate()φ•“é≥ïψÄ?br /> εΦÄεèëηÄÖεè·δΜΞιÄöηΩ΅εΛöγßçφ•ΙεΦèφüΞφâΨε°ûδΫ™Bean.ι€ÄηΠ¹ε€®ε°ûδΫ™Beanγö³HomeφéΞεèΘδΗ≠εà½δΗë÷΅Κ‰qôδΚ¦φüΞφâΨφ•“é≥ïψIJφàëδΜ§γßΑ‰qôδΚ¦φ•“é≥ïδΗ?finder"φ•“é≥ïψIJιôΛδΚÜφö¥ι€≤εà¦εΜΚψĹιîÄφ·¹ε°ûδΫ™Beanε°ûδΨ΄γö³φ•Ιφ≥ïεΛ•εQ¨HomeφéΞεèΘ‰q‰ι€Äφö¥ι€≤finderφ•“é≥ïψIJηΩôφ‰·ε°ûδΫ™Beanγö³HomeφéΞεèΘεê¨εÖΕδΜ•EJBΨc’dû΄δΗ≠γö³HomeφéΞεèΘγö³φ€Äφ‰éφ‰Ψε¨ΚεàΪψÄ?/p>
ε°ûδΫ™δΗäδΗ΄φ•΅οΦ¨φâÄφ€âγö³EJBΨl³δögιÉΫε≠‰ε€®δΗäδΗ΄φ•΅ε·Ιη±ΓδΨ¦γΜ³δΜΕη°Ωι½°εàΑε°Ιεô®γé·εΔÉδΫΩγî®ψIJηΩôδΚ¦δΗäδΗ΄φ•΅ε·Ιη±ΓεêΪφ€âEJBε°Ιεô®η°³ΓΫ°γö³γé·εΔÉδΩΓφ¹·ψÄ²ε¦†φ≠ΛEJBΨl³δögηÉΫεΛüη°âK½°εàνCΗäδΗ΄φ•΅εQ¨δΜéηĨηéΖεè•εê³ΩUçδΩΓφ¹·οΦ¨φ·îεΠ²δΚ΄εäΓεQ¨ε°âεÖ®φÄßδΩΓφ¹·ψIJε·ΙδΚéε°ûδΫ™BeanηĨη®ÄεQ¨ε≠‰ε€®javax.ejb.EntityContextδΗäδΗ΄φ•΅φéΞεèΘψIJε°ÉΨlßφâΩη΅ΣEJBContext
public interface javax.ejb.EntityContext extends javax.ejb.EJBContext{
public javax.ejb.EJBLocalObject getEJBLocalObject();
public javax.ejb.EJBObject getEJBObject();
public java.lang.Object getPrimarykey();
}
ιÄöηΩ΅ηΑÉγî®getEJBObject()φ•“é≥ïεQ¨εΫ™εâçε°Δφà·²ÉΫεΛüηéΖεΨ½φüêε°ûδΫ™Beanε°ûδΨ΄ε·ΙεΚîγö³EJBε·Ιη±ΓψIJε°Δφà·²ΑÉγî®γö³φ‰·EJBε·Ιη±ΓεQ¨ηĨδΗçφ‰·ε°ûδΫ™Beanε°ûδΨ΄φ€§ημnψÄ²ε¦†φ≠ΛοΦ¨ε°ΔφàΖηÉΫεΛüε€®εΚîγî®δΗ≠εΦïγqîε¦ûγö³EJBε·Ιη±ΓψÄ?br />
ε°ûδΫ™Beanε°ûδΨ΄ε·ΙεΚîγö³δΗΜιî°εè·δΜΞιÄöηΩ΅getPrimaryKey()φ•“é≥ïηéΖεΨ½ψIJδΗΜιî°εî·δΗÄφ†΅η·Üφüêε°ûδΫ™Beanε°ûδΨ΄ψIJεΫ™ε°ûδΫ™Beanε°ûδΨ΄ε≠‰ε²®εàΑε≠‰ε²®φΚêδΗ≠φ½ΕεQ¨εè·δΜΞδ΄…γî®δΗΜιî°ηéΖεΨ½εçïδΗΣε°ûδΫ™Beanε°ûδΨ΄ψIJγî±δΚéε€®RDBMSδΗ≠δΙüε≠‰ε€®δΗΜιî°εQ¨ε¦†φ≠ΛδΗΜιî°ηÉΫεΛüεî·δΗÄφ†΅η·ÜφüêδΗΣε°ûδΫ™Beanε°ûδΨ΄ψÄ?/p>
ε·ΙδΚéδΜ÷MΫïφàêγÜüγö³ψĹεüΚδΚéOOεΛöε±²ιÉ®γ÷vγö³δΦ¹δΗöεΚîγî®ηĨη®ÄεQ¨φÄ’dè·δΜΞεà£εàÜε΅Κ2ΩUçφàΣγ³ΕδΗçεê¨γö³Ψl³δögΨc’dû΄ψÄ?ψĹεΚîγî®ιÄΜηΨëΨl³δögεQ?ψĹφ¨¹δΙÖ娕φïΑφç°Ψl³δögψIJδΦöη·ùBean壨ε°ûδΫ™Beanγö³φ€ÄεΛßε¨ΚεàΪε€®δΚéε°ûδΫ™Beanφ‰·ε°ûδΫ™οΦ¨ε°ΔφàΖφ‰·εè·δΜΞ〴γö³εàΑγö³ψÄ²ε¦†φ≠Λε°ûδΫ™BeanηÉΫεΛü㴧γΪ΄δΚéε°ΔφàΖεΚîγî®γö³γîüεëΫεë®φ€üψIJε·ΙδΚéε°ûδΫ™BeanηĨη®ÄεQ¨ιÄöηΩ΅φ·îηΨÉε°ÉδΜ§εê³η΅ΣεêΪφ€âγö³φïΑφç°δΨΩηÉΫεΛüε¨ΚεàÜδΗçεê¨γö³ε°ûδΫ™Bean.‰qôφ³èεë≥γùÄε°ΔφàΖηÉΫεΛüεΦïγî®εçïδΗΣγö³ε°ûδΫ™Beanε°ûδΨ΄ρqΕεΑÜε°ÉδΦ†εÖΞεàΑεÖΕδΜ•εΚîγî®δΗ≠οΦ¨δΗçεê¨γö³ε°ΔφàΖεè·δΜΞεÖ±δΚΪεê¨φ†οLö³ε°ûδΫ™Beanε°ûδΨ΄εQ¨ηΩôε·ΙδΚéδΦöη·ùBeanφ‰·εäûδΗçεàΑγö³ψIJδΦöη·ùBeanεΜΚφ®Γ‰q΅γ®΄φà•ηÄÖεΖΞδΫ€φΒ¹ψIJε°ûδΫ™Beanφ€§ημnû°±φ‰·ε°ΔφàΖεQ¨ε°Éû°±φ‰·φ¨¹δΙÖ娕γäΕφĹε·Ιη±ΓψÄ?br /> ε°ûδΫ™Beanε°ûδΨ΄ε≠‰ε€®ε΅†φ•ΙιùΔγö³εêΪδΙâεQ?br /> 1ψĹφ¨¹δΙÖ娕φïΑφç°γö³JavaηΓ®γΛΚεQ¨εç≥ε°ÉηÉΫεΛüδΜéφ¨¹δΙÖ娕ε≠‰ε²®φΚêηΘÖηù≤φïΑφç°εàΑεÜÖε≠‰δΗ≠ψIJεê¨φ½”ûΦ¨ε°ûδΫ™Beanε°ûδΨ΄ηÉΫεΛüû°ÜηΘÖηΫΫεàΑγö³φïΑφç°ε≠‰ε²®εàΑε°ûδΨ΄γö³φàêεë‰εè‰ι΅èδΗ≠ψÄ?br /> 2ψĹιÄöηΩ΅δΩ°φîΙεÜÖε≠‰δΗ≠γö³Javaε·Ιη±Γεè·δΜΞφîΙεè‰φïΑφç°γö³εè•εÄΙ{Ä?br /> 3ψĹηΩ‰εè·δΜΞû°ÜδΩ°φîΙεêéγö³φïΑφç°δΩùε≠‰εàΑε≠‰ε²®φΚêφ±΅δΗ≠οΦ¨δΜéηĨφ¦¥φ•ΑRDBMSδΗ≠γö³γâ©γêÜφïΑφç°ψÄ?br /> ε°ûδΫ™Beanφ‰·φ¨¹δΙÖ娕ε·Ιη±ΓεQ¨ε°ÉηÉΫεΛüιïΩφ€üε≠‰ε€®ψIJεç≥δΫΩε΅ΚγéνCΚÜδΗçεè·φ¹ΔεΛçγö³εΛ±η¥ΞοΦ¨φ·îεΠ²εΚîγî®φ€çεäΓεô®γ‰Ϊγ½ΣψĹφïΑφç°εΚ™γ‰Ϊγ½ΣεQ¨ε°ûδΫ™Bean‰q‰φ‰·ηÉΫεΛüε≠‰φ¥Μγö³ψIJεéü妆倮δΚéε°ûδΫ™BeanεèΣφ‰·ε·ΙεΚïε±²εÖΖφ€âε°ΙιîôηΓ¨δΗΚγö³φ¨¹δΙÖ娕ε≠‰ε²®φΚêδΗ≠φïΑφç°γö³φ‰†εΑ³εQ¨ε¦†φ≠ΛοΦ¨εç≥δ΄…φû¹εÖΕγ‰Ϊγ½ΣεQ¨εÜÖε≠‰δΗ≠γö³ε°ûδΫ™Beanε°ûδΨ΄‰q‰εè·δΜΞι΅çφ•Αφû³εΜΚψÄ²ε€®φû¹εÖΕι΅çεê·εêéοΦ¨ε°ûδΫ™Beanε°ûδΨ΄ι€ÄηΠ¹δΜéεΚïε±²ε≠‰ε²®φΚêηΘÖηΫΫφïΑφç°οΦ¨ρqΕδ΄…γî®ηéΖεΨ½γö³φïΑφç°ε·Ιε°ûδΫ™Beanε°ûδΨ΄δΗ≠γö³εê³δΗΣεüüηΩ¦ηΓ¨setterφ™çδΫ€ψIJε°ûδΫ™Beanφ·îε°ΔφàΖδΦöη·ùγö³γîüεëΫεë®φ€üηΠ¹ιïΩψIJεè·δΜΞη°ΛδΗΚοΦ¨φïΑφç°εΚ™δΗ≠η°ΑεΫïε≠‰φ¥Μγö³φ½Ει½¥εÜ≥ε°öδΚÜε°ûδΫ™Beanε°ûδΨ΄γö³γîüεëΫεë®φ€üψÄ?br /> γ¦Ηεê¨φïΑφç°εΨÄεΨÄε≠‰ε€®εΛöεàÜγâ©γêÜφ΄·²¥ùεQ¨φ·îεΠ²εÜÖε≠‰δΗ≠γö³ε°ûδΫ™Beanε°ûδΨ΄ψĹε°ûδΫ™BeanφïΑφç°φ€§ημnεQ¨δΜ•δΜ§ιÉΫφ‰·ε·ΙRDBMSδΗ≠φïΑφç°γö³φ΄·²¥ùψÄ²ε¦†φ≠ΛοΦ¨EJBε°Ιεô®ι€ÄηΠ¹φèêδΨ¦φüêΩUçφ€ΚεàΕε°ûγéΑφïΑφç°ε€®Javaε·Ιη±Γ壨RDBMSι½¥γö³η΅Σεä®δΦ†ηΨ™ψIJε°ûδΫ™Beanγö³BeanΨc÷MΊ™φ≠ΛφèêδΨ¦δΚÜ2δΗΣγâΙ¨Däφ•Ιφ≥ïοΦö
ejbLoad():ε°ÉηÉΫεΛüδΜéφ¨¹δΙÖ娕ε≠‰ε²®φΚêδΗ≠η·Μεè•φïΑφç°οΦ¨ρqΕε≠‰ε²®εàΑε°ûδΫ™Beanε°ûδΨ΄γö³εüüδΗ≠ψÄ?br /> ejbStore():ε°ÉηÉΫεΛüεΑÜεΫ™εâçε°ûδΫ™Beanε°ûδΨ΄γö³εüüεÄιgΩùε≠‰εàΑεΚïε±²RDBMSδΗ≠ψÄ?br /> ι²ΘδΙàδΫïφ½Ει€ÄηΠ¹ε°¨φàêεÜÖε≠‰δΗ≠ε°ûδΫ™Beanε°ûδش壨RDBMSδΗ≠φïΑφç°γö³δΦ†ιÄ£ε£¨ηΫ§φçΔεQ¨εΦÄεèëηÄÖι€ÄηΠ¹γüΞι¹™φ‰·ηΑ¹ηΑÉγî®δΚÜejbLoad()壨ejbStore(),Ϋ{îφΓàφ‰·EJBε°Ιεô®ψIJε°ÉδΜ§φ‰·ε¦ûηΑÉφ•“é≥ïεQ¨δΨ¦EJBε°Ιεô®ηΑÉγî®ψIJEJBηß³η¨ÉηΠ¹φ±²φâÄφ€âγö³ε°ûδΫ™BeanΨl³δögεΩÖιΓΜφèêδΨ¦ε°ÉδΜ§ψIJη΅≥δΚéη·Μεè•φà•ε≠‰ε²®φïΑφç°γö³φ½Εφ€ΚοΦ¨γî±EJBε°Ιεô®εܦ_°öψIJδΨùφç°ε°ûδΫ™Beanε°ûδΨ΄εΫ™εâçγö³δΚ΄εäΓγäΕφĹοΦ¨EJBε°Ιεô®δΦöη΅Σεä®η°ΓΫé½ε΅Κι€ÄηΠ¹ηΑÉγî®ε°ûδΫ™Beanε°ûδΨ΄δΗ≠γö³ejbLoad()εQ¨ejbStore()φ•“é≥ïγö³φ½Εφ€ΚοΦ¨‰qôδΙüφ‰·δ΄…γî®ε°ûδΫ™BeanΨl³δögγö³δΦ‰εäΩδΙ΄δΗÄεQöεΦÄεèëηÄÖδΗçγî®ηÄÉηôëjavaε·Ιη±Γεê¨φ≠ΞεΚïε±²RDBMSγö³ι½°ιΔ‰ψÄ?/p>
δΗόZΚÜφΜΓηÉωεΛßι΅èρqΕεèëε°ΔφàΖη°âK½°εê¨δΗÄφïΑφç°γö³ηΠ¹φ±²οΦ¨φûΕφû³εΗàι€ÄηΠ¹εÄüεä©δΚéε°ûδΫ™Beanη°Ψη°Γε΅ΚιΪ‰φÄßηÉΫγö³η°Ωι½°γ≥ΜΨlüψIJεΠ²δΗ΄γΜôε΅όZΗÄΩUçηßΘεÜœx•ΙφΓàοΦöεÖ¹η°ΗεΛöδΗΣε°ΔφàΖεÖΉÉμnεê¨δΗÄε°ûδΫ™Beanε°ûδΨ΄ψÄ²ε¦†φ≠ΛοΦ¨ε°ûδΫ™Beanε°ûδΨ΄ηÉΫεΛüεê¨φ½Εφ€çεäΓεΛöδΗΣε°ΔφàΖψIJεΑΫΫéΓηΓ®ιùΔδΗä〴φ‰·εè·ηΓ¨γö³οΦ¨δΫÜφ‰·ε·ΙδΚéEJBηĨη®ÄεQ¨ηΩôφ‰·ηΓ¨δΗçιÄöγö³ψIJεéü妆φ€âδΚ°γ²ΙεQöεÖΕδΗÄεQ¨δΊ™ε°ûγéΑε°ûδΫ™Beanε°ûδΨ΄φ€çεäΓεΛöδΗΣρqΕεèëε°ΔφàΖεQ¨εΩÖôε÷MΩùη·¹ε°ûδΫ™Beanε°ûδΨ΄φ‰·γΚΩΫE΄ε°âεÖ®γö³εQ¨εΦÄεèëγΚΩΫE΄ε°âεÖ®γö³δΜΘγ†¹ρqΕδΗçφ‰·δΗÄδΜΕε°Ιφ‰™γö³εΖΞδΫ€εQ¨ηĨδΗîΨlèεΗΗδΦöε΅ΚγéνCΗÄε†ÜιîôφàëψIJεÖΕδΚ¨οΦ¨εΚïε±²δΚ΄εäΓΨp»ùΜü塆δΙéδΗçεè·ηÉΫφéßεàΕεΛöδΗΣγΚΩΫE΄γö³ρqΕεèëφâßηΓ¨εQ¨δΚ΄εäΓεΨÄεΨÄεê¨εÖΖδΫ™γö³ΨUΩγ®΄Ψlëε°öε€®δΗÄηΒ½ςÄ²ε¦†φ≠ΛοΦ¨εüόZΚéδΗäηΩΑγêÜγî±εQ¨εçïδΗΣε°ûδΫ™Beanε°ûδΨ΄εèΣηÉΫεΛüε€®εçïγΚΩΫE΄γé·εΔÉδΗ≠‰qêηΓ¨ψIJε·ΙδΚéφâÄφ€âγö³EJBΨl³δögηĨη®ÄεQ¨ε¨Öφ΄§δΦöη·ùBeanψĹφΕàφ¹·ι©±εä®BeanψĹε°ûδΫ™BeanεQ¨ε°ÉδΜ§ιÉΫφ‰·δΜΞεçïγΚΩΫE΄φ•ΙεΦèηΩêηΓ¨γö³ψÄ?br />
εΫ™γ³ΕεQ¨εΦΚεàΕηΠ¹φ±²εê³δΗΣε°ûδΫ™Beanε°ûδΨ΄εèΣηÉΫεê¨φ½Εφ€çεäΓεçïδΗΣε°ΔφàΖεQ¨εΑÜεΦïεÖΞφÄßηÉΫγ™âôΔàψIJγî±δΚéε°ûδΨ΄δΜΞεçïγΚΩΫE΄φ•ΙεΦèηΩêηΓ¨οΦ¨ε°ΔφàΖι€ÄηΠ¹φé£ι‰üγ≠âεÄôε°ûδΫ™Beanε°ûδΨ΄εQ¨δΜéηĨηéΖεΨ½ε·Ιε°ûδΫ™Beanε°ûδΨ΄γö³ηΑÉγî®οΦ¨‰qôε·ΙδΚéεΛßεû΄δΦ¹δΗöεΚîγî®ηĨη®ÄεQ¨φ‰·δΗçεÖ¹η°Ηε΅ΚγéΑγö³
δΗόZΚÜφèêδΨ¦Ψp»ùΜüφÄßηÉΫεQ¨EJBε°Ιεô®δΦöε°ûδش娕εê¨δΗÄε°ûδΫ™Beanγö³εΛöδΗΣε°ûδΨ΄ψIJηΩôδΫΩεΨ½εΛöδΗΣε°ΔφàΖηÉΫεΛüρqΕεèëεê¨δΗçεê¨ε°ûδΫ™Beanε°ûδΨ΄‰q¦ηΓ¨δΚΛδΚ£εQ¨ηĨηΩôδΚ¦ε°ûδΫ™Beanε°ûδΨ΄δΜΘηΓ®δΚÜεê¨δΗÄRDBMSφïΑφç°ψIJδΚ΄ε°ûδΗäεQ¨ηΩôû°±φ‰·EJBε°Ιεô®γö³ηΩêηΓ¨ηΓ¨δΗΚψÄ²ε¦†φ≠ΛοΦ¨ε°ΔφàΖεÜçδΙüδΗçγî®φé£ι‰üΫ{âεÄôε°ûδΫ™Beanε°ûδΨ΄εQ¨ε¦†δΗΚε≠‰ε€®εΛöδΗΣε°ûδΫ™Beanε°ûδΨ΄δΚÜψÄ?br />
δΗÄφ½ΠεΛöδΗΣε°ûδΫ™Beanε°ûδΨ΄δΜΘηΓ®δΚÜεê¨δΗÄRDBMSφïΑφç°εQ¨εàôεΦïεÖΞδΚÜεèΠεΛ•δΗÄδΗΣι½°ιΔ‰οΦöφïΑφç°γ‰Ϊγ½ΣψIJεΠ²φû€εΛöδΗΣε°ûδΫ™Beanε°ûδΨ΄δΜΘηΓ®γö³φïΑφç°φ‰·ιÄöηΩ΅Ψ~™ε≠‰ΫéΓγêÜγö³οΦ¨εàôι€ÄηΠ¹ε€®εÜÖε≠‰δΗ≠φ΄Ζη¥ùεΛöεàÜγΦ™ε≠‰δΗ≠γö³φïΑφç°ψIJφ‰Ψγ³”ûΦ¨φüêδΚ¦Ψ~™ε≠‰δΗ≠γö³φïΑφç°û°Üεè‰εΨ½ιôàφ½ßο֨妆φ≠ΛδΦöε΅ΚγéΑεΨàεΛöηΩ΅φ€üγö³φïΑφç°ψÄ?br />
δΗόZΚÜε°ûγéΑε°ûδΫ™Beanε°ûδΨ΄γö³γΦ™ε≠‰δΗÄη΅¥φÄßοΦ¨εê³δΗΣε°ûδΫ™Beanε°ûδΨ΄εΩÖιΓΜεê¨εΚïε±²ε≠‰ε²®εÖɉq¦ηΓ¨εê¨φ≠ΞψIJEJBε°Ιεô®û°ÜιÄöηΩ΅ηΑÉγî®ejbLoad(),ejbStore()φ•“é≥ïεê¨φ≠Ξ‰qôδΚ¦ε°ûδΫ™Beanε°ûδΨ΄ψÄ?br />
η΅≥δΚéε°ûδΫ™Beanε°ûδΨ΄εê¨εΚïε±²RDBMSφïΑφç°γö³εê¨φ≠ΞιΔëγé΅οΦ¨εàôεè•εÜ≥δΚéδΚ΄εäΓψIJδΚ΄εäΓεΑÜεê³δΗΣε°ΔφàΖη·δh±²ιöîγΠΜηΒδhùΞψIJεÄüεä©δΚéδΚ΄εäΓε°ûγéΑφïΑφç°εê¨φ≠ΞψÄ?/p>
EJBε°Ιεô®φèêδΨ¦γö³ε°ûδΨ΄φ±†φ‰·εΨàφ€âφ³èδΙâγö³ψIJεΫ™γ³”ûΦ¨ρqΕδΗçφ‰·εèΣφ€âε°ûδΫ™Beanφâçε≠‰ε€®ε°ûδΨ΄φ±†ψÄ²ε€®û°Üε°ûδΫ™Beanε°ûδΨ΄ι΅çφ•ΑεàÜιÖçΨlôδΗçεê¨EJBε·Ιη±Γφ½”ûΦ¨δΦöε≠‰ε€®δΗÄδΚ¦ι½°ιΔ‰οΦ¨ρqΕηΠ¹φ±²ε°Ιεô®εéΜηßΘεÜ≥ψIJφ·îεΠ²εΫ™ε°ûδΫ™Beanε°ûδΨ΄ηΔΪφ¨΅ε°öγΜôEJBε·Ιη±Γφ½”ûΦ¨ε°Éεè·ηÉΫηΩ‰φ¨¹φ€âηΒ³φΚê(φ·îεΠ²Socket‰qûφéΞ)ψIJεΠ²φû€εΑÜε°ûδΫ™Beanε°ûδΨ΄φî³ΓΫ°ε€®ε°ûδΨ΄φ±†δΗ≠οΦ¨Socket‰qûφéΞδΗçε€®ι€ÄηΠ¹ψÄ²ε¦†φ≠ΛδΊ™ε°ûγéΑηΒ³φΚêγö³ηéΖεè•ε£¨ι΅äφîΨεQ¨ε°ûδΫ™Beanγö³BeanΨcΜι€ÄηΠ¹ε°ûγéΑεΠ²δΗ?δΗΣε¦ûηΑÉφ•Ιφ≥ïοΦö
1ψĹejbActivate().ε€®εΑÜε°ûδΫ™Beanε°ûδΨ΄δΜéε°ûδΨ΄φ±†δΗ≠εè•ε΅ΚφùΞφ½”ûΦ¨EJBε°Ιεô®δΦöη΅Σεä®ηΑÉγî®ε°ÉψIJη·Ξ‰q΅γ®΄ΩUνCΙ΄δΗΚφΩÄ΄zÖRIJηΩ¦ηĨοΦ¨EJBε°Ιεô®δΦöεΑÜε°ûδΫ™Beanε°ûδΨ΄εàÜιÖçΨlôφüêEJBε·Ιη±ΓεQ¨εΤàεê¨φ½ΕηéΖεΨ½δΗΜιî°ε·Ιη±ΓψÄ²ε€®φâßηΓ¨ejbActivate()φ•“é≥ïφ€üι½¥εQ¨ε°ûδΨ΄ι€ÄηΠ¹ηéΖεΨ½φâÄι€Äγö³ηΒ³φΚêοΦ¨φ·îεΠ²Socke,εêΠεàôεQ¨ε€®û°Üε°ûδΫ™Beanε°ûδΨ΄εàÜιÖçΨlôφüêEJBε·Ιη±Γφ½”ûΦ¨φ½†φ≥ïε·ΙηΒ³φΚêηΩ¦ηΓ¨φ™çδΫ€ψÄ?br />
2ψĹejbPassivate().ε€®εΑÜε°ûδΫ™Beanε°ûδΨ΄φî³ΓΫ°εàΑε°ûδΨ΄φ±†δΗ≠φ½ΕεQ¨EJBε°Ιεô®δΦöηΑÉγî®ε°ÉψIJφ≥®φ³èοΦ¨ε°ÉδΙüφ‰·ε¦ûηΑÉφ•Ιφ≥ïψIJηΩôδΗĉq΅γ®΄ΩUνCΙ΄δΗΚφ¨²ηΒ½ςIJηΩ¦ηĨοΦ¨EJBε°Ιεô®ι€ÄηΠ¹δΜéφüêEJBε·Ιη±ΓδΗ≠εè•ε¦ûεàÜιÖçδΚéε°Éγö³ε°ûδΫ™Beanε°ûδΨ΄εQ¨εΤàû°Üε°ûδΨ΄γö³δΗΜιî°ε·Ιη±ΓδΙüφîΕε¦ûψÄ²ε€®φâßηΓ¨ejbPassivate()φ•“é≥ïφ€üι½¥εQ¨ι€ÄηΠ¹ι΅äφîΨejbActivate()φâßηΓ¨φ€üι½¥ηéΖεΨ½γö³γ¦ΗεÖ¨ôΒ³φΚêοΦ¨φ·îεΠ²εQöSocket.
δΗÄφ½Πε°ûδΫ™Beanε°ûδΨ΄ηΔΪφ¨²ηΒχPΦ¨δΗçδΫÜηΠ¹ι΅äφîë÷°Éφ¨¹φ€âγö³ηΒ³φΚêοΦ¨‰q‰εΑÜε°ûδΨ΄γö³γäΕφĹδΩΓφ¹·δΩùε≠‰η™vφùΞψÄ²ε¦†φ≠ΛοΦ¨ε°ûδΫ™Beanε°ûδΨ΄φ€Äφ•Αγö³γäΕφĹδΩΓφ¹·εè·δΜΞδΜéRDBMSδΗ≠φâΨεàνCΚÜψÄ²δΊ™δΚÜδΩùε≠‰ε°ûδΫ™Beanε°ûδΨ΄γö³εüüδΩΓφ¹·εàΑRDBMSδΗ≠οΦ¨ε°Ιεô®ηΠ¹ε€®φ¨²η™vε°ûδΨ΄εâçηΑÉγî®ejbStore()φ•“é≥ïψIJγ±ΜδΦΦγö³εQ¨δΗÄφ½Πε°ûδΫ™BeanηΔΪφΩÄ΄zΜοΦ¨δΗçδΫÜηΠ¹ηéΖεΨ½φâÄι€Äγö³ηΒ³φΚêοΦ¨‰q‰ηΠ¹δΜéRDBMSηΘÖηù≤φ€Äφ•Αγö³φïΑφç°εQ¨δΊ™δΚÜε°¨φàêφïΑφç°γö³η·’dè•εQ¨EJBε°Ιεô®û°Üε€®΄»Ä΄z’d°ûδΫ™Beanε°ûδΨ΄εêéηΑÉγî®ejbLoad()φ•“é≥ïψÄ?/p>
]]>