"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" 一般設定
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" 設定默認解碼
set fenc=utf-8
set fencs=utf-8,usc-bom,euc-jp,gb18030,gbk,gb2312,cp936
" 設置不與之前版本兼容
set nocompatible
" 查找結果高亮度顯示
set hlsearch
" 配色
colorscheme desert
" 顯示行號
set nu
" 檢測文件的類型
filetype on
" 設置當文件被改動時自動載入
set autoread
" 記錄歷史的行數
set history=80
" 設置語法高亮度
syntax on
" 在處理未保存或只讀文件的時候,彈出確認
set confirm
" 與windows共享剪貼板
set clipboard+=unnamed
" 載入文件類型插件
filetype plugin on
" 為特定文件類型載入相關縮進文件
filetype indent on
" 保存全局變量
set viminfo+=!
" 帶有如下符號的單詞不要被換行分割
set iskeyword+=_,$,@,%,#,-
" 設置鼠標一直可用
set mouse=a
" 高亮當前行
set cursorline
" 命令行高度
set cmdheight=1
" 啟動的時候不顯示那個援助索馬里兒童的提示
set shortmess=atI
" 設置幫助語言
if version >= 603
set helplang=cn
set encoding=utf-8
endif
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" 文件設置
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" 不要備份文件(根據自己需要取舍)
set nobackup
" 不要生成swap文件,當buffer被丟棄的時候隱藏它
setlocal noswapfile
set bufhidden=hide
" 字符間插入的像素行數目
set linespace=0
" 增強模式中的命令行自動完成操作
set wildmenu
" 在狀態行上顯示光標所在位置的行號和列號
set ruler
" 不讓vim發出討厭的滴滴聲
set noerrorbells
" 在被分割的窗口間顯示空白,便于閱讀
set fillchars=vert:\ ,stl:\ ,stlnc:\
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" 搜索和匹配
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" 高亮顯示匹配的括號
set showmatch
" 不要高亮被搜索的句子(phrases)
"set nohlsearch
" 在搜索時,輸入的詞句的逐字符高亮(類似firefox的搜索)
set incsearch
" 搜索時忽略大小寫
set ignorecase
" 不要閃爍
set novisualbell
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" 文本格式和排版
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" 自動格式化
set formatoptions=tcrqn
" 繼承前一行的縮進方式,特別適用于多行注釋
set autoindent
" 為C程序提供自動縮進
set smartindent
" 使用C樣式的縮進
set cindent
" 制表符為4
set tabstop=4
" 統一縮進為4
set softtabstop=4
set shiftwidth=4
" 不要用空格代替制表符
set noexpandtab
" 設置每行80個字符自動換行
set textwidth=80
" -------------------------------------------------------------------------------------------------
" set mapleader
let mapleader = ","
" platform
function! MySys()
if has("win32")
return "windows"
else
return "linux"
endif
endfunction
" if file not opened, create a new tab, or switch to the opened file
function! SwitchToBuf(filename)
" find in current tab
let bufwinnr = bufwinnr(a:filename)
if bufwinnr != -1
exec bufwinnr . "wincmd w"
return
else
" search each tab
tabfirst
let tb = 1
while tb <= tabpagenr("$")
let bufwinnr = bufwinnr(a:filename)
if bufwinnr != -1
exec "normal " . tb . "gt"
exec bufwinnr . "wincmd w"
return
endif
tabnext
let tb = tb +1
endwhile
" not exist, new tab
exec "tabnew " . a:filename
endif
endfunction
" fast edit .vimrc
if MySys() == 'linux'
" fast reloading of the .vimrc
map <silent> <leader>ss :source ~/.vimrc<cr>
" fast editing of the .vimrc
map <silent> <leader>ee :call SwitchToBuf("~/.vimrc")<cr>
" when .vimrc is edited, reload it
autocmd! bufwritepost .vimrc source ~/.vimrc
elseif MySys() == 'windows'
" Set helplang
set helplang=cn
"Fast reloading of the _vimrc
map <silent> <leader>ss :source ~/_vimrc<cr>
"Fast editing of _vimrc
map <silent> <leader>ee :call SwitchToBuf("~/_vimrc")<cr>
"When _vimrc is edited, reload it
autocmd! bufwritepost _vimrc source ~/_vimrc
endif
if MySys() == 'windows'
source $VIMRUNTIME/mswin.vim
behave mswin
endif
" quickfix模式
autocmd FileType c,cpp map <buffer> <leader><space> :w<cr>:make<cr>
nmap <leader>cn :cn<cr>
nmap <leader>cp :cp<cr>
nmap <leader>cw :cw 10<cr>
" vimgrep/lvimgrep(lv)
" 在當前文件中快速查找光標下的單詞, 并在窗口的位置列表中顯示
" 好像該功能有mark插件可以代勞:)
nmap <leader>lv :lv /<c-r>=expand("<cword>")<cr>/ %<cr>:lw<cr>
" omni completion(全能補全)
" 為支持C++的全能補全,需安裝插件: OmniCppComplete
" 并且生成tag文件的命令是(src為源文件目錄): ctags -R --c++-kinds=+p --fields=+iaS --extra=+q src
" 因為在對C++文件進行補全時,OmniCppComplete插件需要tag文件中包含C++的額外信息
" C++的補全連”CTRL-X CTRL-O“都不必輸入呵呵,測試通過
set completeopt=longest,menu " 只在下拉菜單中顯示匹配項目,并且會自動插入所有匹配項目的相同文本
inoremap <C-J> <C-X><C-O>
" generic completion(其他補全方式)
" 文件名補全
inoremap <C-F> <C-X><C-F>
" 宏定義補全
inoremap <C-D> <C-X><C-D>
" 整行補全
inoremap <C-L> <C-X><C-L>
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" Plugin
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
" CTags
set tags=tags " 當前目錄, 不知道為什么寫成./tags就無效
set tags+=../tags
" 為/usr/include目錄生成tags文件,缺點可能會導致自動完成的速度減慢,必要時去除
" 更好的辦法是需要時才加,例如/usr/include/gtk2.0/tags
" set tags+=/usr/include/tags
" Cscope
if has("cscope")
set csprg=/usr/bin/cscope
set csto=1
set cst
set nocsverb
" add any database in current directory
if filereadable("cscope.out")
cs add cscope.out
endif
set csverb
endif
nmap <C-@>s :cs find s <C-R>=expand("<cword>")<CR><CR>
nmap <C-@>g :cs find g <C-R>=expand("<cword>")<CR><CR>
nmap <C-@>c :cs find c <C-R>=expand("<cword>")<CR><CR>
nmap <C-@>t :cs find t <C-R>=expand("<cword>")<CR><CR>
nmap <C-@>e :cs find e <C-R>=expand("<cword>")<CR><CR>
nmap <C-@>f :cs find f <C-R>=expand("<cfile>")<CR><CR>
nmap <C-@>i :cs find i ^<C-R>=expand("<cfile>")<CR>$<CR>
nmap <C-@>d :cs find d <C-R>=expand("<cword>")<CR><CR>
" Tag List
" 按照名稱排序
let Tlist_Sort_Type = "name"
" 在右側顯示窗口
let Tlist_Use_Right_Window = 1
" 如果只有一個buffer,kill窗口也kill掉buffer
let Tlist_Exist_OnlyWindow = 1
" 使taglist只顯示當前文件tag,其它文件的tag都被折疊起來(同時顯示多個文件中的tag時)
let Tlist_File_Fold_Auto_Close = 1
" 不要顯示折疊樹
let Tlist_Enable_Fold_Column = 1
"不同時顯示多個文件的tag,只顯示當前文件的
let Tlist_Show_One_File = 1
" 鍵盤映射
nmap tl :TlistToggle<cr>
" Buf Explorer
let g:bufExplorerDefaultHelp=0 " Do not show default help.
let g:bufExplorerShowRelativePath=1 " Show relative paths.
let g:bufExplorerSortBy='mru' " Sort by most recently used.
let g:bufExplorerSplitRight=0 " Split left.
let g:bufExplorerSplitVertical=1 " Split vertically.
let g:bufExplorerSplitVertSize = 30 " Split width
let g:bufExplorerUseCurrentWindow=1 " Open in new window.
autocmd BufWinEnter \[Buf\ List\] setl nonumber
" Win Manager
let g:winManagerWindowLayout = "BufExplorer,FileExplorer|TagList"
let g:persistentBehaviour = 0
let g:winManagerWidth = 30
let g:defaultExplorer = 0
nmap <C-W><C-F> :FirstExplorerWindow<cr>
nmap <C-W><C-B> :BottomExplorerWindow<cr>
nmap wm :WMToggle<cr>
" Lookupfile
let g:LookupFile_MinPatLength = 2 "最少輸入2個字符才開始查找
let g:LookupFile_PreserveLastPattern = 0 "不保存上次查找的字符串
let g:LookupFile_PreservePatternHistory = 1 "保存查找歷史
let g:LookupFile_AlwaysAcceptFirst = 1 "回車打開第一個匹配項目
let g:LookupFile_AllowNewFiles = 0 "不允許創建不存在的文件
" 通過shell腳本: lookupfile_tag.sh生成當前目錄的filenametags文件
" 該腳本在~/.vim目錄下有備份
if filereadable("./filenametags") "設置tag文件的名字
let g:LookupFile_TagExpr = '"./filenametags"'
endif
nmap <silent> <leader>lk <Plug>LookupFile
nmap <silent> <leader>lb :LUBufs<cr>
nmap <silent> <leader>lw :LUWalk<cr>
" lookup file with ignore case
function! LookupFile_IgnoreCaseFunc(pattern)
let _tags = &tags
try
let &tags = eval(g:LookupFile_TagExpr)
let newpattern = '\c' . a:pattern
let tags = taglist(newpattern)
catch
echohl ErrorMsg | echo "Exception: " . v:exception | echohl NONE
return ""
finally
let &tags = _tags
endtry
" Show the matches for what is typed so far.
let files = map(tags, 'v:val["filename"]')
return files
endfunction
let g:LookupFile_LookupFunc = 'LookupFile_IgnoreCaseFunc'
" Mark
nmap <silent> <leader>hl <Plug>MarkSet
vmap <silent> <leader>hl <Plug>MarkSet
nmap <silent> <leader>hh <Plug>MarkClear
vmap <silent> <leader>hh <Plug>MarkClear
nmap <silent> <leader>hr <Plug>MarkRegex
vmap <silent> <leader>hr <Plug>MarkRegex
" SuperTab
" 記住上次的補全方式,直到按ESC退出插入模式為止
let g:SuperTabRetainCompletionType = 2
" 缺省的補全方式(設置為全能補全)
let g:SuperTabDefaultCompletionType = "<C-X><C-O>"
" DoxygenToolkit
let g:DoxygenToolkit_authorName="simplyzhao"
nmap da :DoxAuthor<cr>
nmap dx :Dox<cr>
nmap db :DoxBlock<cr>
花了點時間把svnbook看了遍,對于svn有了個比較好的認識。svn info時,修訂版和最后修改的修訂版總是讓我感覺很困惑。要搞明白這個需要對下面幾個關鍵字有所了解。
HEAD:版本庫中的最新版本。
COMMITED:文件最后提交生成的版本號。
PREV:文件倒數第二次提交生成的版本號。
BASE:目錄簽出或者簽入生成的版本號。
HEAD、COMMITED和PREV比較好理解,BASE比較難于理解。假設一個目錄下有兩個文件configure.ac和Makefile.am,第一次將它們check out出來時,會生成一個新的revision,這個便是BASE了。此時使用svn info configure.ac/Makefile.am可以發現它們的修訂版是一樣的,但是最后修改的修訂版不同。這里的修訂版對應其實就是BASE,而最后修改的修訂版則是COMMITED。插一句,很多人很容易誤解為啥修訂版號和最后修改的修訂版號不一致。
若將configure.ac修改并check in,這個時候會生成一個新的revision,configure.ac的BASE和COMMITED的值相當。而svn info Makefile.am,發現它的BASE和COMMITED沒有改變。svn up一下,發現Makefile.am的BASE會變成最新的,和configure.ac相同。
簽出代碼庫。
1 | [henshao@henshao ~/svn]$ svn co file:///Users/henshao/svn/dogg/learn_svn/ learn_svn2 |
2 | A learn_svn2/trunk |
3 | A learn_svn2/trunk/configure.ac |
4 | A learn_svn2/trunk/Makefile.am |
5 | Checked out revision 17. |
顯示修訂版(BASE)和最后修改的修訂版(COMMITED)。
01 | [henshao@henshao ~/svn/learn_svn2/trunk]$ svn st -v |
02 | 17 17 henshao . |
03 | 17 17 henshao configure.ac |
04 | 17 15 henshao Makefile.am |
05 | |
06 | [henshao@henshao ~/svn/learn_svn2/trunk]$ svn info Makefile.am |
07 | Path: Makefile.am |
08 | Name: Makefile.am |
09 | URL: file:///Users/henshao/svn/dogg/learn_svn/trunk/Makefile.am |
10 | Repository Root: file:///Users/henshao/svn/dogg |
11 | Repository UUID: 7ee338c4-a6e3-468b-b576-d1b767dd90e2 |
12 | Revision: 17 |
13 | Node Kind: file |
14 | Schedule: normal |
15 | Last Changed Author: henshao |
16 | Last Changed Rev: 15 |
17 | Last Changed Date: 2011-06-23 17:03:08 +0800 (四, 23 6 2011) |
18 | Text Last Updated: 2011-06-23 18:37:50 +0800 (四, 23 6 2011) |
19 | Checksum: 5b211a202b8ae001a86a557108d4989c |
修改Makefile.am并簽入看看。
01 | [henshao@henshao ~/svn/learn_svn2/trunk]$ svn ci Makefile.am -m "LD_ADD add ssl library" |
02 | Sending Makefile.am |
03 | Transmitting file data . |
04 | Committed revision 18. |
05 | |
06 | [henshao@henshao ~/svn/learn_svn2/trunk]$ svn info Makefile.am |
07 | Path: Makefile.am |
08 | Name: Makefile.am |
09 | URL: file:///Users/henshao/svn/dogg/learn_svn/trunk/Makefile.am |
10 | Repository Root: file:///Users/henshao/svn/dogg |
11 | Repository UUID: 7ee338c4-a6e3-468b-b576-d1b767dd90e2 |
12 | Revision: 18 |
13 | Node Kind: file |
14 | Schedule: normal |
15 | Last Changed Author: henshao |
16 | Last Changed Rev: 18 |
17 | Last Changed Date: 2011-06-23 18:41:41 +0800 (四, 23 6 2011) |
18 | Text Last Updated: 2011-06-23 18:41:31 +0800 (四, 23 6 2011) |
19 | Checksum: e4cc7bf424ff911c9619060a5f1c1030 |
20 | |
21 | [henshao@henshao ~/svn/learn_svn2/trunk]$ svn info configure.ac |
22 | Path: configure.ac |
23 | Name: configure.ac |
24 | URL: file:///Users/henshao/svn/dogg/learn_svn/trunk/configure.ac |
25 | Repository Root: file:///Users/henshao/svn/dogg |
26 | Repository UUID: 7ee338c4-a6e3-468b-b576-d1b767dd90e2 |
27 | Revision: 17 |
28 | Node Kind: file |
29 | Schedule: normal |
30 | Last Changed Author: henshao |
31 | Last Changed Rev: 17 |
32 | Last Changed Date: 2011-06-23 17:44:51 +0800 (四, 23 6 2011) |
33 | Text Last Updated: 2011-06-23 18:37:50 +0800 (四, 23 6 2011) |
34 | Checksum: 6b49ae8f3346120311e11843c23b0b00 |
svn update一下看看。
01 | [henshao@henshao ~/svn/learn_svn2/trunk]$ svn up |
02 | At revision 18. |
03 | |
04 | [henshao@henshao ~/svn/learn_svn2/trunk]$ svn info configure.ac |
05 | Path: configure.ac |
06 | Name: configure.ac |
07 | URL: file:///Users/henshao/svn/dogg/learn_svn/trunk/configure.ac |
08 | Repository Root: file:///Users/henshao/svn/dogg |
09 | Repository UUID: 7ee338c4-a6e3-468b-b576-d1b767dd90e2 |
10 | Revision: 18 |
11 | Node Kind: file |
12 | Schedule: normal |
13 | Last Changed Author: henshao |
14 | Last Changed Rev: 17 |
15 | Last Changed Date: 2011-06-23 17:44:51 +0800 (四, 23 6 2011) |
16 | Text Last Updated: 2011-06-23 18:37:50 +0800 (四, 23 6 2011) |
17 | Checksum: 6b49ae8f3346120311e11843c23b0b00 |
18 | |
19 | [henshao@henshao ~/svn/learn_svn2/trunk]$ svn st -v |
20 | 18 18 henshao . |
21 | 18 17 henshao configure.ac |
22 | 18 18 henshao Makefile.am |
svn一個版本庫的revision是全局的,不管是在trunk還是branch,也不管使用merge合并代碼還是消除修改,簽入和簽出都會生成一個新的revision。當項目中一個文件簽入時會導致別的文件的BASE暫時低于HEAD,但是一旦update,二者將保持一致。
]]>
unset LANGUAGE
export LANG="en"
cd /home/kingsoft
mkdir distcc
cd distcc
rpm包用:rpm -ivh ...
bz2包用:tar -xvf ...
進入distcc解壓后的目錄
./configure && make && make install
mkdir /usr/lib/distcc
mkdir /usr/lib/distcc/bin
cd /usr/lib/distcc/bin
ln -s /usr/local/bin/distcc gcc
ln -s /usr/local/bin/distcc cc
ln -s /usr/local/bin/distcc g++
ln -s /usr/local/bin/distcc c++
進入ccache解壓目錄
./configure && make && make install
mkdir /Data
mkdir /Data/Cache
mkdir /Data/Cache/CCache
cd /Data/Cache
touch /var/log/distccd.log
vim ~/.bash_profile
把 /usr/lib/distcc/bin 加到PATH
并添加下面內容
## ----- Distcc -----
#
DISTCC_HOSTS="localhost 192.168.1.1"
DISTCC_VERBOSE=1
DISTCC_LOG="/var/log/distcc.log"
export DISTCC_HOSTS PATH DISTCC_VERBOSE DISTCC_LOG
#
## ----- End -----
## ----- Ccache -----
#
# export CCACHE_DISABLE=1
CCACHE_DIR=/Data/Cache/CCache
CCACHE_LOGFILE=/Data/Cache/CCache.log
CCACHE_PREFIX="distcc"
CC="ccache gcc"
CXX="ccache g++"
export CCACHE_DIR CCACHE_LOGFILE CCACHE_PREFIX CC CXX
#
## ----- End -----
vim /etc/rc.local
distccd --daemon --allow 10.20.0.0/16
==========================================
啟動監控:distccd --daemon --allow 10.20.0.0/16
查看監控:distccmon-text 1
]]>
Nagle算法就是為了盡可能發送大塊數據,避免網絡中充斥著許多小數據塊。
Nagle算法的基本定義是任意時刻,最多只能有一個未被確認的小段。 所謂“小段”,指的是小于MSS尺寸的數據塊,所謂“未被確認”,是指一個數據塊發送出去后,沒有收到對方發送的ACK確認該數據已收到。
舉個例子,比如之前的blog中的實驗,一開始client端調用socket的write操作將一個int型數據(稱為A塊)寫入到網絡中,由于此時連接是空閑的(也就是說還沒有未被確認的小段),因此這個int型數據會被馬上發送到server端,接著,client端又調用write操作寫入‘\r\n’(簡稱B塊),這個時候,A塊的ACK沒有返回,所以可以認為已經存在了一個未被確認的小段,所以B塊沒有立即被發送,一直等待A塊的ACK收到(大概40ms之后),B塊才被發送。整個過程如圖所示:
這里還隱藏了一個問題,就是A塊數據的ACK為什么40ms之后才收到?這是因為TCP/IP中不僅僅有nagle算法,還有一個ACK延遲機制 。當Server端收到數據之后,它并不會馬上向client端發送ACK,而是會將ACK的發送延遲一段時間(假設為t),它希望在t時間內server端會向client端發送應答數據,這樣ACK就能夠和應答數據一起發送,就像是應答數據捎帶著ACK過去。在我之前的時間中,t大概就是40ms。這就解釋了為什么'\r\n'(B塊)總是在A塊之后40ms才發出。
如果你覺著nagle算法太搗亂了,那么可以通過設置TCP_NODELAY將其禁用 。當然,更合理的方案還是應該使用一次大數據的寫操作,而不是多次小數據的寫操作。
本文來自CSDN博客,轉載請標明出處:http://blog.csdn.net/historyasamirror/archive/2011/05/15/6423235.aspx
]]>
庫文件是一個包含了編譯后代碼、數據的文件,用于與程序其他代碼連編,它可以使得程序模塊化、編譯速度更快,并且易于更新。庫文件分為三種(實質為兩種,在隨后兩句話有解釋):靜態庫(在程序之前就已經裝載進其中了)、共享庫(在程序啟動之時加載進去,在程序直接共享)、動態加載庫(dynamically loaded,DL)(在程序運行中任何時候都可以被加載進程序中使用,事實上DL并非是一個完全不同的庫類型,共享庫可以用作DL而被動態加載(靜態庫在Linux貌似無法用dlopen加載)。注意有些人使用dynamically linked libraries (DLLs)來指代共享庫,有些人使用DLL這個詞來形容任何可以被用作DL的庫文件,這個請區分對待。
在具體使用中,我們應該多使用共享庫,這使得用戶可以獨立于使用該庫文件的程序而更新庫。DL的確非常有用,但有時候我們可能并不需要那些靈活性,而對于靜態庫,由于更新起來實在費勁,我們一般不使用。
2.靜態庫的建立
靜態庫就是一堆普通的目標文件(object file),習慣上靜態庫以.a為后綴,這是使用ar命令生成的。靜態庫允許用戶不用重新編譯代碼就可以鏈接程序,以節省重新編譯的時間,其實這個時間已經在強大的機器配置和快速的編譯器中顯得微不足道了,這個常常用來提供程序而不是源代碼。速度上,靜態ELF(Executable and Linking Format)庫文件比共享庫或者動態加載庫快1%-5%,但實際上常常因為其他因素而并不一定快。
我們寫主文件prog.c:
1: #include
2: void ctest1(int *);
3: void ctest2(int *);
4:
5: int main()
6: {
7: int x;
8: ctest1(&x);
9: printf("Valx=%d\n",x);
10:
11: return 0;
12: }
13: 然后寫這兩個函數的實現:
ctest1.c
1: void ctest1(int *i)
2: {
3: *i=5;
4: } ctest2.c
1: void ctest2(int *i)
2: {
3: *i=100;
4: }我們首先編譯這兩個函數實現的源文件:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/statics$ gcc -Wall -c ctest1.c ctest2.c
gnuhpc@gnuhpc-desktop:~/MyCode/lib/statics$ ls
ctest1.c ctest1.o ctest2.c ctest2.o prog.c
然后創建靜態庫libctest.a:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/statics$ ar -cvq libctest.a ctest1.o ctest2.o
a - ctest1.o
a - ctest2.o
我們查看一下這個庫中的文件:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/statics$ ar -t libctest.a
ctest1.o
ctest2.o
此時我們可以編譯我們的程序了,注意-l選項,后邊的參數是去掉lib和.a的部分,并且需要放在要編譯的文件名之后,否則會報錯。:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/statics$ gcc -o test prog.c -L./ –lctest
gnuhpc@gnuhpc-desktop:~/MyCode/lib/statics$ ls
ctest1.c ctest1.o ctest2.c ctest2.o libctest.a prog.c test
gnuhpc@gnuhpc-desktop:~/MyCode/lib/statics$ ./test
Valx=5
3.共享庫的建立
共享庫是在程序啟動時加載的庫文件。當共享庫加載完畢后所有啟動的起來的程序都將使用新的共享庫。在創建共享庫之前,還需要了解一些知識:
命名規則:
每一個共享庫都有一個soname,一般都形如libname.so.versionNumber,其中versionNumber每當接口發生改變時都要增加,一個完全的soname的前綴應該是它所在目錄,在一個實際系統中,一個完整的soname只是共享庫文件的real name的符號鏈接。程序運行時在內部列出所需的共享庫時使用的就是soname。
每一個共享庫也有一個real name,這是包含實際代碼的文件名,real name使用soname為前綴,并且在后邊添加一些信息,一般都形如soname.MinorNumber.ReleaseNumber。 最后的releaseNumber可有可無。這個是生成共享庫時實際文件的名稱。
同時,在編譯器要求使用一個共享庫時使用的名字稱為linker name,一般都是去掉版本號的soname,用于gcc中-lname這樣的選項的編譯。
這幾個名字的關系:你在創建實際庫文件中指定libreadline.so.3.0為real name ,并且使用符號鏈接創建soname ->libreadline.so.3和linker name-> /usr/lib/libreadline.so。
放置位置:
GNU標準推薦將所有默認的庫安裝在/usr/local/lib,這指的是開發者源代碼默認的位置。
FHS指出大多數的庫文件應該放在/usr/lib,而啟動所需的庫則應該放在/lib中,而非系統庫應該放在/usr/local/lib。這指的是發行版默認的位置,這兩個標準并沒有矛盾。
共享庫的主要有三個步驟:
創建目標代碼。
創建庫。
使用符號鏈接創建默認版本的共享庫(可選)。
現在我們舉個例子來說明,首先我們編譯源代碼,使用-fPIC選項生成共享庫所需的位置獨立代碼(position-independent code (PIC)):
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ gcc -Wall -fPIC -c *.c
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ ls
ctest1.c ctest1.o ctest2.c ctest2.o prog.c prog.o
然后我們創建庫文件:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ gcc -shared -Wl,-soname,libctest.so.1 -o libctest.so.1.0 *.o
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ ls
ctest1.c ctest1.o ctest2.c ctest2.o libctest.so.1.0 prog.c prog.o
-shared選項指明生成共享目標文件,-W1(注意是小寫L而不是一)指明傳入鏈接器的參數,在此我們設定了該庫的soname為libctest.so.1,-o則指明了生成的目標庫文件為libctest.so.1.0(這個就是real name)。
最后創建所需的符號鏈接:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ sudo mv libctest.so.1.0 /usr/local/lib/libctest.so.1.0
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ sudo ln -sf /usr/local/lib/libctest.so.1.0 /usr/local/lib/libctest.so.1
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ sudo ln -sf /usr/local/lib/libctest.so.1.0 /usr/local/lib/libctest.so
創建的libctest.so就是上面所謂linker name,用于編譯時-lctest選項。
創建的libctest.so.1就是soname,我們在上邊說過程序在運行時需要這個名字的符號鏈接。
此時我們的共享庫就建好了,接著我們編譯程序:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ gcc -Wall -L/usr/local/lib prog.c -lctest -o prog
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ ls
ctest1.c ctest1.o ctest2.c ctest2.o prog prog.c prog.o
我們編譯完畢,該庫并不會包含在可執行文件中,只有在執行時來會動態加載進來。我們可以通過ldd列出一個可執行程序所有的依賴,在我的系統中還找不到/usr/local/bin的路徑:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ ldd prog
linux-gate.so.1 => (0x00a5c000)
libctest.so.1 => not found
libc.so.6 => /lib/tls/i686/cmov/libc.so.6 (0x00a6f000)
/lib/ld-linux.so.2 (0x00451000)
此時,運行會報找不到庫的錯誤:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ ./prog
./prog: error while loading shared libraries: libctest.so.1: cannot open shared object file: No such file or directory
我們可以將所需庫的路徑加入到系統路徑中,有三種方法可以完成:
A.在/etc/ld.so.conf中加入所在路徑,然后執行ldconfig配置鏈接器運行時綁定配置。你也可以創建一個文件,將路徑寫入,然后使用ldconfig –f filename將配置寫入。
B.修改LD_LIBRARY_PATH環境變量(Linux下,AIX下為LIBPATH),在其中添加路徑。若你直接在.bashrc文件中配置則重啟后不失效,否則在shell中設置重啟后失效。
我們使用A方法中的-f選項:
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ vi libctest.conf
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ sudo ldconfig -f libctest.conf
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ ./prog
Valx=5
gnuhpc@gnuhpc-desktop:~/MyCode/lib/shared$ ldd prog
linux-gate.so.1 => (0x00f6f000)
libctest.so.1 => /usr/local/lib/libctest.so.1 (0x005d9000)
libc.so.6 => /lib/tls/i686/cmov/libc.so.6 (0x00718000)
/lib/ld-linux.so.2 (0x001e6000)
其中libctest.conf中寫入路徑:/usr/local/lib。程序運行正常。
4.動態加載庫的使用
動態加載庫是在非程序啟動時動態加載進入程序的庫,這對于實現插件或動態模塊有很大的幫助。在Linux中,動態加載庫的形式并不特殊,它使用上述兩種程序庫,使用提供的API在程序運行時動態加載。注意,在不同平臺上動態加載庫的API并不相同,所以可能會有移植問題出現。
我們可以通過nm命令先查看一下我們創建的庫里面有哪些symbol(可以理解為函數方法)供我們使用:
gnuhpc@gnuhpc-desktop:~/MyCode/lib$ nm /usr/local/lib/libctest.so
00001f18 a _DYNAMIC
00001ff4 a _GLOBAL_OFFSET_TABLE_
w _Jv_RegisterClasses
00001f08 d __CTOR_END__
00001f04 d __CTOR_LIST__
00001f10 d __DTOR_END__
00001f0c d __DTOR_LIST__
000005a0 r __FRAME_END__
00001f14 d __JCR_END__
00001f14 d __JCR_LIST__
00002014 A __bss_start
w __cxa_finalize@@GLIBC_2.1.3
00000540 t __do_global_ctors_aux
00000420 t __do_global_dtors_aux
00002010 d __dso_handle
w __gmon_start__
000004d7 t __i686.get_pc_thunk.bx
00002014 A _edata
0000201c A _end
00000578 T _fini
000003a0 T _init
00002014 b completed.7021
000004dc T ctest1
000004ec T ctest2
00002018 b dtor_idx.7023
000004a0 t frame_dummy
000004fc T main
U printf@@GLIBC_2.0
這個命令對靜態庫和共享庫都支持,第二列為symbol類型,小寫字母表示符號是本地的,大寫字母表示符號是全局(外部)的,幾個常見的字母含義如下:T為代碼段普通定義,D為已初始化數據段,B為未初始化數據段,U為未定義(用到該符號但是沒有在該庫中定義)。
我們創建ctest.h:
1: #ifndef CTEST_H
2: #define CTEST_H
3:
4: #ifdef __cplusplus
5: extern "C" {
6: #endif
7:
8: void ctest1(int *);
9: void ctest2(int *);
10:
11: #ifdef __cplusplus
12: }
13: #endif
14:
15: #endif這里使用extern C是為了使得該庫既可以用于C語言又可以用于C++。
我們動態加載庫進來:progdl.c
1: #include
2: #include
3: #include "ctest.h"
4:
5: int main(int argc, char **argv)
6: {
7: void *lib_handle;
8: double (*fn)(int *);
9: int x;
10: char *error;
11:
12: lib_handle = dlopen("/usr/local/lib/libctest.so", RTLD_LAZY);
13: if (!lib_handle)
14: {
15: fprintf(stderr, "%s\n", dlerror());
16: exit(1);
17: }
18:
19: fn = dlsym(lib_handle, "ctest1");
20: if ((error = dlerror()) != NULL)
21: {
22: fprintf(stderr, "%s\n", error);
23: exit(1);
24: }
25:
26: (*fn)(&x);
27: printf("Valx=%d\n",x);
28:
29: dlclose(lib_handle);
30: return 0;
31: }里面的方法解釋如下:
void * dlopen(const char *filename, int flag);
若filename為絕對路徑,那么dlopen就會試圖打開它而不搜索相關路徑,否則就現在環境變量LD_LIBRARY_PATH處搜索,然后在/etc/ld.so.cache以及/lib和/usr/lib搜索。flag我們只解釋兩個常用的選項:若為RTLD_LAZY則表示在動態庫執行時解決未定義符號問題,而RTLD_NOW則表示在dlopen返回前解決未定義符號問題。當你調試時你應該用RTLD_NOW,這個時候若存在未解決的引用程序還可以繼續進行。另外,RTLD_NOW選項可能會使打開庫的這個操作稍微慢一點,但是以后尋找函數時就會快一點。注意,若程序庫相互依賴則應該按依賴順序依次載入,比如X依賴Y,那么要先載入Y然后再載入X。返回的是一個句柄,若失敗則返回null.
char *dlerror(void);
報告任何上一次對加載庫操作的錯誤。兩次調用期間若有操作錯誤則第二次會報告, 否則第二次則返回null——它報告完錯誤就等待下一個錯誤的發生,上一次錯誤的情況一旦報告就不再提及。
void *dlsym(void *handle, const char *symbol);
尋找對應symbol的函數方法,handle就是dlopen返回的句柄。一般如下使用:
1: dlerror(); /* clear error code */
2: s = (actual_type) dlsym(handle, symbol_being_searched_for);
3: if ((err = dlerror()) != NULL) {
4: /* handle error, the symbol wasn't found */
5: } else {
6: /* symbol found, its value is in s */
7: }int dlclose(void *handle);
關閉一個動態加載庫。當一個動態庫被加載多次時,你需要用同樣次數dlclose該動態庫才可以deallocated.
我們編譯該代碼gcc -g -rdynamic -o progdl progdl.c -ldl,即可得到可執行文件(其中-g選項是為了gdb調試所用),其中的庫為動態加載后又關閉的。我們使用gdb看一下代碼:
(gdb) b main
Breakpoint 1 at 0x804878d: file progdl.c, line 12.
(gdb) r
Starting program: /home/gnuhpc/MyCode/lib/dynamic/progdl
Breakpoint 1, main (argc=1, argv=0xbffff4a4) at progdl.c:12
12 lib_handle = dlopen("/usr/local/lib/libctest.so", RTLD_LAZY);
(gdb) f
#0 main (argc=1, argv=0xbffff4a4) at progdl.c:12
12 lib_handle = dlopen("/usr/local/lib/libctest.so", RTLD_LAZY);
(gdb) s
13 if (!lib_handle)
(gdb) n
19 fn = dlsym(lib_handle, "ctest1");
(gdb)
20 if ((error = dlerror()) != NULL)
(gdb)
26 (*fn)(&x);
(gdb)
27 printf("Valx=%d\n",x);
(gdb) p x
$1 = 5
(gdb) p fn
$2 = (double (*)(int *)) 0x28c4dc
可以看到fn獲得了ctest1的地址。
參考文獻:
http://www.yolinux.com/TUTORIALS/LibraryArchives-StaticAndDynamic.html
http://www.linuxjournal.com/article/3687
http://www.dwheeler.com/program-library/Program-Library-HOWTO/
本文來自CSDN博客,轉載請標明出處:http://blog.csdn.net/gnuhpc/archive/2010/12/20/6086143.aspx
]]>
ldd查看應用程序鏈接了哪些動態庫。
nm列出目標文件中包含的符號信息。
size列出各個段的大小及總的大小。
strings列出文件中的字符串。
readelf讀取elf文件的完整結構。
objdump導出目標文件的相關信息(elf文件相關工具的源頭)。
gdb對文件的執行過程進行調試分析,設置斷點(b)、單步執行(n)、函數調用追蹤(bt)、反匯編(disassemble)。
strace跟蹤程序中的系統調用及信號處理信息。
LD_DEBUG通過設置這個環境變量,可以方便的看到 loader 的加載過程(包括庫的加載,符號解析等過程),使用【LD_DEBUG=help 可執行文件路徑】可查看使用幫助。
LD_PRELOAD環境變量指定的共享庫會被預先加載,如果出現重名的函數,預先加載的函數將會被調用,如在預先加載的庫中包含自定義的puts函數,則在執行程序時將使用自定義版本的puts函數,而不是libc庫中的puts函數。
proc文件系統中包含進程的地址空間映射關系,具體查看/proc/進程id/maps文件的內容。
valgrind工具對可執行程序文件進行內存檢查(還有cache模擬、調用過程跟蹤等功能),以避免內存泄露等問題。
addrline將可執行文件中的地址轉換為其在源文件中對應的位置(文件名:行號)。
]]>
]]>
處理器總處于以下狀態中的一種:
1、內核態,運行于進程上下文,內核代表進程運行于內核空間;
2、內核態,運行于中斷上下文,內核代表硬件運行于內核空間;
3、用戶態,運行于用戶空間。
用戶空間的應用程序,通過系統調用,進入內核空間。這個時候用戶空間的進程要傳遞很多變量、參數的值給內核,內核態運行的時候也要保存用戶進程的一些寄存器值、變量等。所謂的“進程上下文”,可以看作是用戶進程傳遞給內核的這些參數以及內核要保存的那一整套的變量和寄存器值和當時的環境等。
硬件通過觸發信號,導致內核調用中斷處理程序,進入內核空間。這個過程中,硬件的一些變量和參數也要傳遞給內核,內核通過這些參數進行中斷處理。所謂的“中斷上下文”,其實也可以看作就是硬件傳遞過來的這些參數和內核需要保存的一些其他環境(主要是當前被打斷執行的進程環境)。
關于進程上下文LINUX完全注釋中的一段話:
當一個進程在執行時,CPU的所有寄存器中的值、進程的狀態以及堆棧中的內容被稱為該進程的上下文。當內核需要切換到另一個進程時,它需要保存當前進程的所有狀態,即保存當前進程的上下文,以便在再次執行該進程時,能夠必得到切換時的狀態執行下去。在LINUX中,當前進程上下文均保存在進程的任務數據結構中。在發生中斷時,內核就在被中斷進程的上下文中,在內核態下執行中斷服務例程。但同時會保留所有需要用到的資源,以便中繼服務結束時能恢復被中斷進程的執行。
本文來自CSDN博客,轉載請標明出處:http://blog.csdn.net/eroswang/archive/2007/11/28/1905830.aspx
]]>
int send( SOCKET s, const char FAR *buf, int len, int flags );
不論是客戶還是服務器應用程序都用send函數來向TCP連接的另一端發送數據。
客戶程序一般用send函數向服務器發送請求,而服務器則通常用send函數來向客戶程序發送應答。
該函數的第一個參數指定發送端套接字描述符;
第二個參數指明一個存放應用程序要發送數據的緩沖區;
第三個參數指明實際要發送的數據的字節數;
第四個參數一般置0。
這里只描述同步Socket的send函數的執行流程。當調用該函數時,send先比較待發送數據的長度len和套接字s的發送緩沖的 長度,如果len大于s的發送緩沖區的長度,該函數返回SOCKET_ERROR;如果len小于或者等于s的發送緩沖區的長度,那么send先檢查協議是否正在發送s的發送緩沖中的數據,如果是就等待協議把數據發送完,如果協議還沒有開始發送s的發送緩沖中的數據或者s的發送緩沖中沒有數據,那么 send就比較s的發送緩沖區的剩余空間和len,如果len大于剩余空間大小send就一直等待協議把s的發送緩沖中的數據發送完,如果len小于剩余空間大小send就僅僅把buf中的數據copy到剩余空間里(注意并不是send把s的發送緩沖中的數據傳到連接的另一端的,而是協議傳的,send僅僅是把buf中的數據copy到s的發送緩沖區的剩余空間里)。如果send函數copy數據成功,就返回實際copy的字節數,如果send在copy數據時出現錯誤,那么send就返回SOCKET_ERROR;如果send在等待協議傳送數據時網絡斷開的話,那么send函數也返回SOCKET_ERROR。
要注意send函數把buf中的數據成功copy到s的發送緩沖的剩余空間里后它就返回了,但是此時這些數據并不一定馬上被傳到連接的另一端。如果協議在后續的傳送過程中出現網絡錯誤的話,那么下一個Socket函數就會返回SOCKET_ERROR。(每一個除send外的Socket函數在執行的最開始總要先等待套接字的發送緩沖中的數據被協議傳送完畢才能繼續,如果在等待時出現網絡錯誤,那么該Socket函數就返回 SOCKET_ERROR)
注意:在Unix系統下,如果send在等待協議傳送數據時網絡斷開的話,調用send的進程會接收到一個SIGPIPE信號,進程對該信號的默認處理是進程終止。
通過測試發現,異步socket的send函數在網絡剛剛斷開時還能發送返回相應的字節數,同時使用select檢測也是可寫的,但是過幾秒鐘之后,再send就會出錯了,返回-1。select也不能檢測出可寫了。
recv函數
int recv( SOCKET s, char FAR *buf, int len, int flags );
不論是客戶還是服務器應用程序都用recv函數從TCP連接的另一端接收數據。
該函數的第一個參數指定接收端套接字描述符;
第二個參數指明一個緩沖區,該緩沖區用來存放recv函數接收到的數據;
第三個參數指明buf的長度;
第四個參數一般置0。
這里只描述同步Socket的recv函數的執行流程。當應用程序調用recv函數時,recv先等待s的發送緩沖中的數據被協議傳送完畢,如果協議在傳送s的發送緩沖中的數據時出現網絡錯誤,那么recv函數返回SOCKET_ERROR,如果s的發送緩沖中沒有數據或者數據被協議成功發送完畢后,recv先檢查套接字s的接收緩沖區,如果s接收緩沖區中沒有數據或者協議正在接收數據,那么recv就一直等待,只到協議把數據接收完畢。當協議把數據接收完畢,recv函數就把s的接收緩沖中的數據copy到buf中(注意協議接收到的數據可能大于buf的長度,所以 在這種情況下要調用幾次recv函數才能把s的接收緩沖中的數據copy完。recv函數僅僅是copy數據,真正的接收數據是協議來完成的),recv函數返回其實際copy的字節數。如果recv在copy時出錯,那么它返回SOCKET_ERROR;如果recv函數在等待協議接收數據時網絡中斷了,那么它返回0。
注意:在Unix系統下,如果recv函數在等待協議接收數據時網絡斷開了,那么調用recv的進程會接收到一個SIGPIPE信號,進程對該信號的默認處理是進程終止。
]]>
作者聯系方式:李先靜 <xianjimli at hotmail dot com>
更新時間:2007-6-21
在正式進入Marvell-linux研究之前,我們介紹一點背景知識,讓沒有手機開發經驗的朋友有個概念。
1. 基帶(BaseBand)
基帶是傳統手機中最重要的功能,它直接與無線網絡交互,負責信號的發送和接收。所有編碼/解碼和網絡協議處理都是它負責的,這一部分也是最復雜,涉及專利最多的部分。所幸的是,大部分處理都集成在芯片里了,對于一般手機設計來說,至少在軟件方面是不用太關心的。
我們知道,交變電流在流經導體時會產生無線電波,無線電波可以經過空間傳播出去,這就是無線發送的原理。而無線電波又可以讓導體產生電流,電流信號可恢復為與發送時的一致信號,這就是無線接收的原理。
在無線電設備中,這里的導體就是天線,天線的長度是有要求的,它一般不能小于波長的一半,像耳朵能聽聲音頻率范圍是20Hz~20KHz,最敏感的部分在2500赫茲到3000赫茲之間。因為波長x頻率=光速,以3000赫茲的無線電波為例,它對應的波長是100公里,如果直接收/發這種電波,那么天線長度至少要50公里,我們當然不可能在手機上安裝一個50公里長的天線,怎么辦呢?
要縮短天線的長度,只能提高電波的頻率。發送時,把低頻信號調制在高頻信號上再發送出去,接收時,先得到高頻信號,然后從中解調出低頻信號。這里高頻信號稱為載波,一般GSM手機使用1800M或900M的載波,而CDMA使用800M或1900M的載波。當然這里的頻率指的是中心頻率,信號本身要占一定的帶寬,而且為了避免干擾,發送和接收所用的頻率也不一樣,以900M的載波來看,接收頻率為925M-960M,發送頻率為880M-915M。
高頻信號是真正在空間中傳播的無線信號,對高頻信號的處理也就是所謂的射頻(RF) 信號處理,高頻信號讓天線變短了,這是它的好處,同時也帶來了副作用,因為它的波長太短,它可能把印刷板上的導線都當作天線,在上面產生感應電流,原本兩根無關的導線,現在變得關系曖昧,加上無線電波的反射互相影響,使其中充滿太多不確定因素,導致射頻電路設計非常復雜。按照溫伯格的《系統化思維導論》里的說法,這是一個典型的中數系統,即不能采用小數系統中那樣的簡化,又不能采用大數系統中的概率統計。
手機的功率比較小,它不能直接與衛星建立通信,而是與基站(BS)之間通信,基站呈蜂窩狀布置,所以以前稱手機為蜂窩電話。
現在的手機都是數字信號,即使音頻信號也要進行數字編碼之后才能傳遞,任何通信都有一套通信協議,手機和基站之間的通信當然也不例外,多個手機共享基站,信道的建立,手機在基站之間的切換,如此等等,還有很多復雜的情況,所以整套協議非常復雜。
多個手機共享一個基站,如何共享,這就是所謂的多址問題。常見的有頻分多址(FDMA)、時分多址(TDMA)和碼分多址(CDMA)。在2G中通常使用頻分多址(FDMA)和時分多址(TDMA)的組合,而在3G中使用碼分多址(CDMA)。
2. 應用處理器(AP)
AP從邏輯上講是一個獨立的東西,在物理上可以獨立于基帶處理器,也可以從屬于基帶處理器。如果使用Marvell的Monahans系列芯片,那么可以肯定AP是獨立于基帶處理器的。
AP的功能是運行應用程序,我們常說的MMI就是在這上面運行,一般手機設計公司的主要工作就是開發這些應用程序。一個典型軟件(linux平臺)的分層視圖如下圖所示:
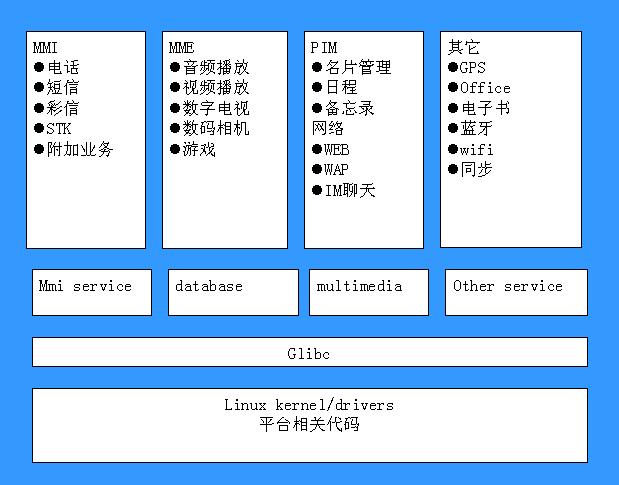
在Marvell-linux這個系列中,我們關注的主要是linux kernel中與平臺相關的部分。
3. BB與AP的橋梁
既然像電話這種通信類應用程序是在AP上跑的,而通信功能又是在BB上實現的,那么就一定會存在一個連接AP和BB的通道。
最常見的連接方式就是串口,在linux下,也就是tty設備。在AP這邊,用AT命令控制BB,來實現打電話和發短信等功能,在3GPP的《AT command set for User Equipment (UE)》文檔中定義標準的AT命令,各個模組廠家為了增加功能,在上面都做了些擴展,在使用AT時,要參考模組廠家的手冊。
AT命令是文本格式的,它經過串口發送到BB。它控制BB來完成打電話和發短信等傳統功能沒有問題,但是要通過BB無線上網(如GPRS),就遇到麻煩了,因為上網的數據是二進制的,如果和AT命令混在一起從串口傳輸,那就會亂成一團了。
為了解決AT命令和二進制數據共享串口的問題,3GPP制定了一個稱為多路復用的協議,它把一個物理串口虛擬成多個邏輯上的串口。應用程序使用各自獨立的虛擬串口而互不干擾。
有人會問GPRS數據和AT命令是通過多路復用協議經串口在AP和BB之間傳遞的,那么打電話時的語音數據呢,是不是也是走條通道呢?答案是否,因為那樣做效率太低了,所以對于下行語音數據,BB解碼后直接送到speaker,對上行的語音數據,從MIC采樣/處理后,直接通過BB發送出去。
本文來自CSDN博客,轉載請標明出處:http://blog.csdn.net/absurd/archive/2007/06/21/1661231.aspx
]]>
]]>