]]>
关键�?Keys
命��o(h��)Commands
���时旉��� Expiration times
错误信息 Error strings
存储命��o(h��) Storage commands
��d��命��o(h��) Retrieval command
删除 Deletion
增加/减少 Increment/Decrement
�l�计 Statistics
多用途统�?nbsp;General-purpose statistics
其他命��o(h��) Other commands
UDP协议 UDP protocol
协议
memcached的客��L(f��ng)��通过TCP�q�接与服务器通信�Q?/span>UDP协议的接口也可以使用�Q�详�l�说明请参�?/span>”UDP 协议”部分�Q�。一个给定的�q�行中的memcached服务器在某个�Q�可配置的)端口上监听连接;客户端连接该端口�Q�发送命令给服务器,��d��反馈�Q�最后关闭连接�?/span>
没有必要发送一个专门的命��o(h��)�ȝ��束会(x��)话。客��L(f��ng)��可以在不需要该�q�接的时候就关闭它。注意:(x��)我们鼓励客户端缓存它们与服务器的�q�接�Q�而不是每�ơ要存储或读取数据的时候再�ơ重新徏立与服务器的�q�接�?/span>memcache同时打开很多�q�接不会(x��)�Ҏ(gu��)��能造成到大的媄响,�q�是因�ؓ(f��)memcache在设计之处,���p��设计成即使打开了很多连接(数百或者需要时上千个连接)也可以高效的�q�行。缓存连接可以节省与服务器徏�?/span>TCP�q�接的时间开销�Q�于此相比,在服务器�D��ؓ(f��)建立一个新的连接所做准备的开销可以忽略不计�Q��?/span>
memcache通信协议有两�U�类型的数据�Q�文本行和非�l�构化数 据。文本行用来发送从客户端到服务器的命��o(h��)以及(qi��ng)从服务器回送的反馈信息。非�l�构化的数据用在客户端希望存储或者读取数据时。服务器�?x��)以字符���的形式严格�? ���的�q�回相应数据在存储时存储的数据。服务器不关注字节序�Q�它也不知道字节序的存在�?/span>memcahce寚w���l�构化数据中的字�W�没有�Q何限�Ӟ��可以是�Q意的字符�Q�读取数据时�Q�客��L(f��ng)��可以在前�ơ返回的文本行中���切的知道接下来的数据块的长度�?/span>
文本行通常�?#8220;"r"n”�l�束。非�l�构化数据通常也是�?#8220;"r"n”�l�束�Q�尽��?/span>"r�?/span>"n或者其他�Q�?/span>8位字�W�可以出现在数据块中。所以当客户端从服务器读取数据时�Q�必���M��用前面提供的数据块的长度�Q�来���定数据���的�l�束�Q�二不是依据跟随在字�W�流���N���?#8220;"r"n”来确定数据流的结束,���管实际上数据流格式如此�?/span>
关键�?/span> Keys
memcached使用关键字来区分存储不同的数据。关键字是一个字�W�串�Q�可以唯一标识一条数据。当前关键字的长度限制是250个字�W�(当然目前客户端似乎没有需求用�q�么长的关键字)�Q�关键字一�?span style="color: red;">不能包含控制字符�?span style="color: red;">�I�格�?/span>
命��o(h��)Commands
memcahe�?/span>3�U�类型的命��o(h��)�Q?/span>
l 存储命��o(h��)�?span style="font-family: 宋体;">�Q?/span>3个命令:(x��)set�?/span>add�?/span>replace�Q�要求服务器安装关键字存储数据。客��L(f��ng)��发送一个命令行�Q�然后一个数据块�Q�命令执行后客户端等待一行反馈,用来表示命��o(h��)执行成功与否�?/span>
l ��d��命��o(h��)-- �Q�只�?/span>1个命令:(x��)get�Q? 要求服务器根据一�l�关键字��d��数据�Q�在一个请求��d��以包含一个或多个关键字)。客��L(f��ng)��发送一个包含请求关键字的命令行�Q�命令传递到服务器后�Q�服务器���查�? 每一个关键字下的数据�Q�然户将数据�?#8220;一个关键字数据�Q�一个反馈信息行跟着一个数据块”的格式回送数据,直到服务器发�?#8220;END”的反馈行�?/span>
l 其他命��o(h��)�Q�如flush_all�Q?/span>version�{�。这些命令不使用非结构化的数据。对于这些命令,客户端发送一个文本的命��o(h��)行,�Ҏ(gu��)��命��o(h��)的特性等待一行数据或者在最后一行以“END“�l�尾的几行反馈信息�?/span>
所有的命��o(h��)行��L��以命令的名字开始,紧接着是以�I�格分割的参数。命令名�U�都是小写,�q�且是大���写敏感的�?/span>
���时旉��� Expiration times
一些发送到服务器的命��o(h��)包含���时旉����Q�该���时旉���对应于:(x��)数据��保存时��_(d��)��客户端操作限�Ӟ��。在�q�些例子中,被发送的真实旉���要么�?/span>UNIX旉���戻I���?/span>1970�q?/span>1�?/span>1�?/span>零时��L(f��ng)���U�数数��|���Q�或者从当前旉���开始算��L(f��ng)���U�数。对于后一�U�情况,�U�数的数��g��能超�q?/span>60*60*24*30�Q?/span>30天的�U�数�Q�;如果�U�数的数值大于了�q�个数��|��服务器会(x��)认�ؓ(f��)该数值是UNIX旉���戻I��而不是自当前旉���开始的�U�数偏移倹{�?/span>
错误信息 Error strings
每个命��o(h��)都有可能被反馈以一个错误消息。这些错误消息有以下三个�c�d���Q?/span>
l “ERROR"r"n”
意味着客户端发送了一个在协议中不存在的命令�?/span>
l "CLIENT_ERROR <error>"r"n"
表示客户端输入的命��o(h��)行上存在某种错误�Q�输入不�W�合协议规定�?/span><error>是一个�h工可读(human-readable�Q�的错误注释�?/span>
l "SERVER_ERROR <error>"r"n"
表示服务器在执行命��o(h��)时发生了某些错误�Q�致使服务器无法执行下去�?/span><error>也是一个�h工可读(human-readable�Q�的错误注释。在一些情况下�Q�错误导致服务器不能再�ؓ(f��)客户端服务(�q�样的情况很���发生)�Q�服务器��׃��(x��)在发生错误消息后��d��关闭�q�接�?span style="color: red;">�q�也是服务器��d��关闭到客��L(f��ng)���q�接的唯一情况�?/span>
后箋�U�数各种命��o(h��)的时候,我们不再赘述错误消息的情况,当我们要清楚错误是存在的�Q�不可忽略�?/span>
存储命��o(h��) Storage commands
首先�Q�客��L(f��ng)��发生如下�q�样的命令:(x��)
|
<command name> <key> <flags> <exptime> <bytes>"r"n <data block>"r"n |
其中�Q?/span>
<command name> �?/span> set�?/span>add或�?/span>replace�?/span>set表示存储该数据;add表示如果服务器没有保存该关键字的情况下,存储该数据;replace表示在服务器已经拥有该关键字的情况下�Q�替换原有内宏V�?/span>
<key>是客��L(f��ng)��要求服务器存储数据的关键字�?/span>
<flags>是一�?/span>16位的无符��h��敎ͼ�服务器将它和数据一起存储�ƈ且当该数据被���索时一赯���回。客��L(f��ng)��可能使用该数��g����Z��个位图来存储�Ҏ(gu��)��数据信息�Q�这个字�D�对服务器不是透明的�?/span>
<exptime>是超时时间。如果��gؓ(f��)0表示该数据项永远不超�Ӟ��但有时候该数据��可能被删除以�ؓ(f��)其他数据腑և��I�间�Q�;如果��g���?/span>0�Q�可能是�l�对�?/span>UNIX旉����Q�也可能是自现在开始的偏移��|��它保证客��h��在这个超时时间到辑��Q�客��L(f��ng)�����取不到该数据项�?/span>
<bytes>是随后数据的字节敎ͼ�不包括终�l�符”"r"n”�?/span><bytes>有可能是0�Q�它后面���是一个空的数据块�?/span>
<data block>是真正要存储数据����?/span>
发送命令行和数据后�Q�客��L(f��ng)���{�待反馈�Q�可以是如下几种情况�Q?/span>
l "STORED"r"n" 表示存储数据成功�?/span>
l "NOT_STORED"r"n" 表示发送的数据没有存储�Q�但�q�不因�ؓ(f��)错误�Q�而是发生�?/span>add或�?/span>replace命��o(h��)不能满��条�g�Ӟ��或者数据项正处于要删除的队列中�?/span>
l 错误消息
��d��命��o(h��) Retrieval command:
��d��命��o(h��)如下所�C�:(x��)
|
get <key>*"r"n |
<key>*表示一个或多个使用�I�格分割的关键字字符丌Ӏ?/span>
发送命令后�Q�客��L(f��ng)���{�待�q�回一个或多个数据��,每个数据��的格式是一个文本行�Q�后跟着一个数据块。当所有的数据��发送完毕后�Q�服务器发送字�W�串”END"r"n”表示服务器反馈数据的�l�束�?/span>
�q�回数据��的格式如下�Q?/span>
|
VALUE <key> <flags> <bytes>"r"n <data block>"r"n |
<key>是发生数据项的关键字�?/span>
<flags>是存储该数据��Ҏ(gu��)���Q�客��L(f��ng)��命��o(h��)中的标志字段�?/span>
<bytes>是紧跟文本行后数据块的长度,不包括终�l�符”"r"n”�?/span>
<data block>是数据项的数据部分�?/span>
如果��h��命��o(h��)行中的有些关键字对应的数据项没有被返回,�q�意味着服务器没有该关键字标�C�Z��的数据项�Q�有可能是从来没有被存储�q�,或者存储过但被删除掉以腑և�内存�I�间�Q�或者数据项���时了,再或者它被某个客��L(f��ng)��删除了)�?/span>
删除 Deletion
删除命��o(h��)允许直接删除数据��,命��o(h��)格式如下�Q?/span>
|
delete <key> <time>"r"n |
<key>是客��L(f��ng)��希望服务器删除数据项的关键字
<time>是客��L(f��ng)��希望服务器阻�?/span>add�?/span>replace命��o(h��)使用该关键字数据��的�U�数�Q�可以是相对旉���也可以是UNIX的绝�Ҏ(gu��)��间。在�q�段旉���内,数据��被攑օ�一个删除队列,它不能被get命��o(h��)��d���Q�在其上使用add�?/span>replace也会(x��)��p�|�Q�但使用set命��o(h��)可以成功。当�q�个旉����q�去后,数据��从服务器的内存中真正的删除。该参数是可选参敎ͼ�如果不存在默认�ؓ(f��)0�Q�这意味着立即从服务器上删除�?/span>
服务器返回信息:(x��)
l "DELETED"r"n" 表示数据��删除成�?/span>
l "NOT_FOUND"r"n" 表示该关键字指定的数据项在服务器上没有找�?/span>
l 其他错误消息
下面�?/span>flush_all命��o(h��)使得所有存在的数据��立卛_��效�?/span>
增加/减少 Increment/Decrement
“incr”�?/span>”decr”命��o(h��)用来修改以及(qi��ng)存在的数据项的内容,增加或者减���它。该数据被当�?/span>32位无�W�号整数处理。如果当前数据非此类数据�Q�则�l�将该内容当�?/span>0来处理。另外在其上施加incr/decr命��o(h��)的数据项必须是业已存在的�Q�对于不存在的数据项不会(x��)���它作�ؓ(f��)0对待�Q�而是以错误结束�?/span>
客户端发送命令行如下格式�Q?/span>
|
incr <key> <value>"r"n 或�?/span> decr <key> <value>"r"n |
<key>是客��L(f��ng)��要修�Ҏ(gu��)��据项的关键字
<value>是对该数据行�q�行增加或者减���的操作数。它是一�?/span>32位的无符��h��数�?/span>
反馈信息有如下几�U�:(x��)
l "NOT_FOUND"r"n"
表明在服务器上没有找到该数据��V�?/span>
l "<value>"r"n "
value是执行完增加/减少命��o(h��)后,该数据项新的数倹{�?/span>
l 错误信息�?/span>
注意�?#8220;decr”命��o(h��)的下溢问题,如果客户端尝试减���的数量���于0�Q�其�l�果�?/span>0�?#8220;incr”命��o(h��)的溢出问题没有检查。另外减���一个数据而��它减���了长度�Q�但不保证减���它�q�回时的长度。该数字可能是附加空格的数字�Q�但�q�只是实现的优化�Q�所以你不能�怿�它�?/span>
�l�计 Statistics
“stats”命��o(h��)用来查询服务器的�q�行情况和其他内部数据。它有两�U�情况,以有无参数来区分�Q?/span>
|
stats"r"n 或�?/span> stats <args>"r"n |
�W�一�U�情况它��D��服务器输��Z��般统计信息以�?qi��ng)设�|�信息和文档化内宏V�?/span>
�W�二�U�情冉|���?/span><args>具体的参敎ͼ�服务器发送各�U�内部数据。这部分没有在协议中文档化,因�ؓ(f��)�?/span>memcache的开发者有兛_��可能是随时变化的�?/span>
多用途统�?/span> General-purpose statistics
当接收到没有带参数的“stats”命��o(h��)后,服务器发送许多类��g��如下格式的文本行�Q?/span>
|
STAT <name> <value>"r"n |
当类似的文本行全部发送完毕后�Q�服务器发送如下的文本行结束反馈信息:(x��)
|
END"r"n |
在所�?/span>STAT文本行中�Q?/span><name>是该�l�计��目的名�U�ͼ�<value>是其数据。下面是一�?/span>stats命��o(h��)反馈的所有统计项目的列表�Q�后面跟着其值的数据�c�d��。在数据�c�d��列中�Q?/span>”32u”表示一�?/span>32位无�W�号整数�Q?/span>”64u”表示一�?/span>64位无�W�号整数�Q?/span>”32u:32u”表示是两个用冒号分割�?/span>32位无�W�号整数�?/span>
|
名称 |
值类�?/span> |
含义 |
|
pid |
32u |
服务器进�E�的�q�程�?/span> |
|
uptime |
32u |
服务器自�q�行以来的秒�?/span> |
|
time |
32u |
当前服务器上�?/span>UNIX旉��� |
|
version |
string |
服务器的版本字符�?/span> |
|
rusage_user |
32u:32u |
服务器进�E�积累的用户旉����Q�秒:微妙�Q?/span> |
|
rusage_system |
32u:32u |
服务器进�E�积累的�pȝ��旉����Q�秒:微妙�Q?/span> |
|
curr_items |
32u |
当前在服务器上存储的数据��的个数 |
|
total_items |
32u |
在服务器上曾�l�保存过的数据项的个�?/span> |
|
bytes |
64u |
当前服务器上保存数据的字节数 |
|
curr_connections |
32u |
处于打开状态的�q�接数目 |
|
total_connections |
32u |
曄���打开�q�的所有连接的数目 |
|
connection_structures |
32u |
服务器分配的�q�接�l�构体的个数 |
|
cmd_get |
64u |
get命��o(h��)��h��的次�?/span> |
|
cmd_set |
64u |
存储命��o(h��)��h��的次�?/span> |
|
get_hits |
64u |
关键字获取命中的�ơ数 |
|
get_misses |
64u |
关键字获取没有命中的�ơ数 |
|
evictions |
64u |
所有因���时而被替换出内存的数据��的个数 |
|
bytes_read |
64u |
服务器从�|�络上读取到的字节数 |
|
bytes_write |
64u |
服务器向�|�络上写的字节数 |
|
limit_maxbytes |
64u |
服务器允许存储数据的最大�?/span> |
其他命��o(h��) Other commands
"flush_all"是一个带有可选数字参数的命��o(h��)�Q�它的执行��L��成功的,服务器��L��响应�?/span>"OK"r"n"字符丌Ӏ�它的作用是使得所有的数据��立卻I��默认�Q�或者经�q�一个指定的���时旉���后全部失效。在�|�数据项失效后,对于��d��命��o(h��)���不�?x��)返回�Q何内容,除非在失效后�q�些数据再次被存储�?/span>flush_all�q�没有真正的释放�q�些存在�q�的数据��占用的内存�I�间�Q�数据空间真实被占用的情况发生在使用新的数据��覆盖老的数据��Ҏ(gu��)��。该命��o(h��)作用最准确的定义是�Q�它��D��所有更新时间早于该命��o(h��)讑֮�的时间点的数据项�Q�在被检索时被忽略,其表现就像已被删除了一栗��?/span>
使用带有延时flush_all命��o(h��)的目的是�Q�当你有�?/span>memcached服务器池�Q�需要刷新所有的内容�Ӟ��但不能在同一旉�����h��所有的服务器,�q�样���可能因为所有的服务器突焉���要重新徏立数据内容,而导致数据库压力的颠���。�g旉���项允许你设�|�他们隔10�U�失效(讄����W�一个�g时�ؓ(f��)0�Q�第二个10�U�,�W�三�?/span>20�U�等�{�)�?/span>
"version"是一个没有参数的命��o(h��)�Q�命令格式如下:(x��)
|
version"r"n |
服务器发回的反馈信息如下�Q?/span>
l "VERSION <version>"r"n"
<version>是从服务器返回的版本字符丌Ӏ?/span>
l 错误消息�?/span>
"verbosity"是一个带有数字参数的命��o(h��)。它的执行��L��成功的,服务器反馈以"OK"r"n"表示执行完成。它用来讄���日志输出的详�l�等�U��?/span>
"quit"是一个没有参数的命��o(h��)。其格式如下�Q?/span>
|
quit"r"n |
当服务器接受到此命��o(h��)后,���关闭与该客��L(f��ng)���q�接。不���怎样�Q�客��L(f��ng)��可以在�Q意不需要该�q�接的时��d��闭它�Q�而不需要发送该命��o(h��)�?/span>
UDP协议 UDP protocol
当基�?/span>TCP协议的连接数���过TCP�q�接的上限时�Q�我们可以���?/span>UDP协议来替代。但�?/span>UDP协议接口不提供可靠的传输�Q�所以多用在不严��D��求成功的操作上;典型�?/span>get��h���?x��)因为缓存的问题�Q�引起丢失或者不完整的传输�?/span>
每个UDP数据包包含一个简单的帧头�Q�接着���是�?/span>TCP协议描述的数据格式的数据���。在当前的实��C���Q�请求必���d��含在一个单独的UDP数据包中�Q�但�q�回可能分散在多个数据包中。(唯一的可以拆分请求数据包的是大的多关键字get��h���?/span>set��h���Q�鉴于可靠性相比而言他们更适合�?/span>TCP传输。)
帧头�?/span>8字节长,如下是其格式�Q�所有的数字都是16位网�l�字节序整�Ş�Q�高位在前)�Q?/span>
0 - 1 ��h��ID
2 - 3 序列�?/span>
4 - 5 在当前的消息中含有的数据包的个数
6-7 保留以后使用�Q�当前必���Mؓ(f��)0
��h��ID由客��L(f��ng)��提供。它的典型值是一个从随机�U�子开始递增��|��实际上客��L(f��ng)��可以使用��L��的请�?/span>ID。服务器的反馈信息中包含了和��h��命��o(h��)中一��L(f��ng)����h��ID。客��L(f��ng)��凭借这个请�?/span>ID区分来自于同一服务器的反馈。每一个包含未知请�?/span>ID的数据包�Q�可能是�׃��延时反馈造成�Q�这些数据包都应该抛弃不用�?/span>
序列号从0�?/span>n-1�Q?/span>n是消息中�ȝ��数据包的个数。客��L(f��ng)��按照序列��h��序重�l�数据包�Q�结果序列中包含了一个完整的�?/span>TCP协议一��h��式的反馈信息�Q�包含了“"r"n”�ȝ��字符�Ԍ���?/span>
]]>
前言
首先�Q�介�l�一下我�Q�作者)自己使用Cache的背景,以便读者更清楚��C��解我下面要讲�q�哪些内宏V�?
我主要是一个Cache实现者,而不是��用者。�ؓ(f��)了给一些ORM�Q�比如JPA实现�Q�提供Cache支持�Q�我需要包装其它的Open Source Cache�Q��ƈ考察它们的特性�?
我对�q�些Open Source Cache的一些工作原理,了解得比较多。具体配�|�和使用�l�节�Q�了解的比较?y��u)���?
本文主要讲述的也是Cache的特性和工作原理�Q�而不是一个安装、配�|�、��用的入门手册�?
本文����q�Cache的一般特性,详述Cache的高�U�特性,比如�Q�分布式Cache�Q�关联对象的Cache�Q�POJO Cache�{��?
阅读本文需要具备基本的Cluster知识�Q�ORM知识�Q�数据库事务知识。本文不解释�q�些基本概念�?
-------------------------------------------------------
Cache Features
首先�Q�我们来���览一下常见的Cache�?
�q�个链接�l�出了常用的Java Open Source Cache�?
http://java-source.net/open-source/cache-solutions
memcached�Q�JBoss Cache�Q�SwarmCache�Q�OSCache�Q�JCS�Q�EHCache�{�开源项目的出镜率和��x��率比较高�?
memcached和其他几个不同,后面�?x��)详�q��?
JBoss Cache的特�Ҏ(gu��)���Q�功能大而全�Q�可���是Cache集大成者,几乎什么都支持�?
其余的几个都很轻量。SwarmCache�Q�OSCache�Q�JCS支持Cluster。EHCache不支持Cluster�?
下面列出Cache的基本特性�?
1. 旉���记录
数据�q�入Cache的时间�?
2. timeout�q�期旉���
Cache里面的数据多久过�?
3. Eviction Policy 清除�{�略
Cache满了之后�Q�根据什么策略,应该清除哪些数据�?
比如�Q�最不经常被讉K��的数据,最久没有访问到的数据�?
4. 命中�?
Cache的数据被选中的比�?
5. 分��Cache
有些Cache有分�U�的概念。比如,几乎所有的Cache都支持Region分区的概��c(di��n)��可以指定某一�cȝ��数据存放在特定的Region里面。JBoss Cache可以支持更多的��别�?
6. 分布式Cache
分布在不同计���机上的Cache
7. 锁,事务�Q�数据同�?
一些Cache提供了完善的锁,事务支持�?
以上�Ҏ(gu��)��,大部分Cache都有相应的API支持。这些API很直观,也很���单,本文不打���展开讲述�?
本文下面主要介绍�Q�memcached和JBoss Cache�q�两个具有代表意义的Cache的高�U�特性,包括分布式Cache的支持�?
-------------------------------------------------------
memcached
http://www.danga.com/memcached/
memcached是一个Client Server�l�构的远�E�Cache实现�?
Server是用C写的�Q�提供了多种语言的客��L(f��ng)��API�Q�包括Java, C#, Ruby, Python, PHP, Perl, C�{�多�U�语�a��?
memcached主要使用在Shared Nothing Architecture中。应用程序通过客户端API�Q�从memcached server存取数据�?
典型的应用,比如�Q�用memcached作�ؓ(f��)数据库缓存�?
也常有这��L(f��ng)��用法�Q�用memcached存放HTTP Session的数据。具体做法是包装Session Interface�Q�截获setAttribute(), getAttribute()�Ҏ(gu��)���?
MemcachedSessionWrapper {
Object getAttribute( key ){
return memcachedClient.get (session.getId() + key);
}
void setAttribute( key, value ){
memcachedClient.setObject(session.getId() + key, value);
}
}
不同计算��Z��的应用程序通过一个IP地址来访问memcahced Server�?
同一个key对应的数据,只存在于一台memcached server的一份内存中�?
memcached server也可以部�|�在多台计算��Z��。Memcached通过key的hashcode来判断从哪台memcached server上存取数据数据。我们可以看刎ͼ�同一个key对应的数据,�q�是只存在于一台memcached server的一份内存中�?
所以,memcached不存在数据同步的问题。这个特性很关键�Q�我们后面讲到Cluster Cache的时候,��׃��(x��)涉及(qi��ng)到数据同步的问题�?
memcached�׃��是远�E�Cache�Q�要求放到Cache的Key和Value都是Serializable�?
�q�程Cache�Q�最令�h担心的网�l�通信开销。据有经验的������Q�memcached�|�络通信开销很小�?
memcached的API设计也是�q�程通信友好的,提供了getMulti()�{�高�_�度的调用方法,能够扚w��获取数据�Q�从而减���网�l�通信�ơ数�?
-------------------------------------------------------
JBoss Cache
http://www.jboss.org/products/jbosscache
有一个商业Cluster Cache�Q�叫做tangosol�?
JBoss Cache是我唯一知道的能够和tangosol媲美的开源Cache�?
Cluster Cache的数据同步,需要网�l�通信�Q�这���p��求放到Cache的数据是Serializable�?
JBoss Cache提出了POJO Cache的概念,意思是数据不是Serializable�Q�一栯���够在Cluster中同步�?
JBoss POJO Cache通过AOP机制�Q�支持对象同步,支持对象属性的同步�Q�支持关联对象的Cache�Q�支持��承,集合�Q�Query�Q��ƈ支持不同�U�别的事务,俨然一个小型内存数据库�U�别的数据存储系�l��?
下面�q�行解释�?
最令�h�q�h��不解的是�q�个POJO的Cluster同步如何实现�?
JBoss POJO Cache采用AOP来照���了POJO的通信和传播工作。天下没有免费的午餐�Q�POJO不支持序列化�Q�框架本�w�就要做�q�个工作——Marshal and Unmarshal�Q�比如通过把Java对象���译成XML�Q�传播出去,�Ҏ(gu��)��收到XML�Q�再���译成Java对象�?
上面说了�Q�JBoss POJO Cache很像一个小型存储容器,JBoss POJO Cache的对象管理也非常�c�M��Hibernate�Q�JDO�Q�JPA�{�ORM工具�Q�同��h��Detach和Attach的概��c(di��n)�?
Attach���是put�Q�把对象攑օ�到Cache中。Detach���是remove�Q�把对象从Cache中删除。�ؓ(f��)啥要多�v个名�Q?
原因是,put的时候,放进�ȝ��是个�q�干净净的POJO�Q�出来的时候,���是Enhanced Object�Q�里面夹杂了很多Interceptor代码�Q�监听对象的�Ҏ(gu��)���?
你操作这个对象的时候,JBoss AOP框架���p��得了相应的通知�Q�能够做出相应的反应�Q�比如数据同步等�?
JBoss POJO Cache支持寚w��合类型的AOP。同样需要把集合Attach�Q�Put�Q�进Cache�Q�然后get出来�Q�然后对集合�q�行操作�Q�就可以被JBoss AOP截获了�?
JBoss POJO Cache的基���是JBoss Tree Cache。这个Tree Cache�c�M��于一个XML DOM�?w��i)�Ş数据�l�构�?
JBoss Cache采用Full Qualified Name作�ؓ(f��)Cache Key�Q�类��g��XPath。比如,a/b/c/d�?
当你删除a/b的时候,a/b/c�Q�a/b/c/d�{�所有属于a/b的Key和对应数据,都被删除�?
JBoss Cache的findObjects�Ҏ(gu��)��能够扑և�一串对象。比如,findObjects�Ҏ(gu��)��a(ch��n)/b/c/d能够扑և�a,b,c,d�{?个对象,攑֜�一个Map中返回�?
具体用法要参见API详细说明�Q�因为JBoss POJO Cache提供了很多行为模式�?
�q�种分��的Cache功能很有用,实现��h��也不难。只是,我觉得,�q�是不够强大。既然支持了�c�M��于XPath的Key�Q�不如烦性支持XPath�? 条�g查询。比如,a[name=”n”]/b/c。当�Ӟ��实现�q�种功能的代价非常大�Q�需要遍历整个Cache Tree�Q�正如XPath需要遍历整个DOM节点一栗��?
最后,JBoss Cache和tangosol一��P��都支持了一个我认�ؓ(f��)如同鸡肋一般的功能�Q�锁机制和事务支持。这个事务支持的意思是�Q�Cache本��n实现了类��g��数据库的4�U�事务隔��ȝ�别�?
在我看来�Q�这�U�支持无疑是��Z��赚取眼球。Cache不当做Cache来用�Q�搞些歪门邪道,大而不当。想当作数据库来用,那还不如把主要功夫花在上�q�提到的那种�_����扚w��查询功能上�?
-------------------------------------------------------
Cluster同步
Cluster之间的Cache同步有多�U�实现方法。比如,JMS�Q�RMI�Q�Client Server Socket�{�方法,用的最多的�Q�支持最�q�的�Ҏ(gu��)��是JGroups开源项目实现的Multicast。配�|�Cluster Cache�Q�通常���q��当于配置JGroups�Q�需要阅读JGroups配置文档�?
Cache的操作通常�?个,get�Q�put�Q�remove�Q�clear�?
对于Cluster Cache来说�Q�读操作�Q�get�Q�肯定是Local�Ҏ(gu��)���Q�只需要从本台计算机内存中获取数据。Remove/clear两个写操作,肯定是Remote�? 法,需要和Cluster其他计算�����行同步。Put�q�个写方法,可以是Local�Q�也可以是Remote的�?
Remote Put�Ҏ(gu��)��的场景是�q�样�Q�一台计���机把数据放到Cache里面�Q�这个数据就�?x��)被传播到Cluster其他计算��Z��。这个做法的好处是Cluster各台计算机的Cache数据可以�?qi��ng)时得到补充�Q�坏处是传播的数据量比较大,�q�个代�h(hu��n)比较�?
Local Put�Ҏ(gu��)��的场景是�q�样�Q�一台计���机把数据放到Cache里面�Q�这个数据不�?x��)被传播到Cluster其他计算��Z��。这个做法的好处是不需要传播数据,坏处 是Cluster各台计算机的Cache数据不能�?qi��ng)时得到补充�Q�这个不是很明显的问题,从Cache中得不到数据�Q�从数据库获取数据是很正常的现象�?
Local Put比�vRemote Put的优势很明显�Q�所以,通常的Cluster Cache都采用Local Put的策略。各Cache一般都提供了Local Put的配�|�选项�Q�如果你没有看到�q�个支持�Q�那么请换一个Cache�?D
-------------------------------------------------------
Center vs Cluster
Memcached可以看作是Center Cache�?
Center Cache和Cluster Cache的特性比较如下:(x��)
Center Cache没有同步问题�Q�所以,remove/clear的时候,比较有优势,不需要把通知发送到好几个计���机上�?
但是�Q�Center Cache的所有操作,get/put/remove/clear都是Remote操作。而Cluster Cache的get/put都是Local操作�Q�所以,Cluster Cache在get/put操作上具有优�ѝ�?
Local get/put在关联对象的�l�装和分拆方面,优势比较明显�?
兌���对象的分拆是�q�个意思�?
比如�Q�有一个Topic对象�Q�下面有几个Post对象�Q�每个Post对象都有一个User对象�?
Topic对象存放到Cache中的时候,下面的关联对象都要拆开来,分成各自的Entity Region来存放�?
Topic Region -> Topic ID -> Topic Object
Post Region -> Post ID -> Post Object
User Region -> User ID -> User Object
�q�个时候,put的动作可能发生多�ơ。Remote Put的开销���比较大�?
Get的过�E�类��|��也需要get多次�Q�才能拼装成一个完整的Topic对象�?
-------------------------------------------------------
�q�期数据
Cache可以用在��M��地方�Q�比如,��面�~�存。但Cache的最常用场景是用在ORM中,比如�Q�Hibernate�Q�JDO�Q�JPA中�?
ORM Cache的��用方法有个原则——不要把没有Commit的修�Ҏ(gu��)��据放入到�~�存中。这是�ؓ(f��)了防止Read Dirty�?
数据库事务分��Z���U�,一�U�是��M��务,不修�Ҏ(gu��)��据,一�U�是写事务,修改数据�?
写事务的操作���程如下�Q?
db.commt();
cache.remove(key); // �q�一步操作,清除了Cache数据�Q�也记录了一个时间removeTime�?
��M��务的操作���程如下�Q?
readTime = current time;
data = cache.get(key);
if(data is null){
data = db.load(key);
cache.put(key, data, readTime); // �q�里要readTime传进�?
}
�q�里需要注意的是put的时候,需要readTime�q�个参数�?
�q�个readTime要和上一�ơ的removeTime�q�行比较�?
如果readTime > removeTime�Q�这个put才能成功�Q�数据才能够�q�入�~�存�?
�q�是��Z��保证不把�q�期数据攑օ�到Cache中,�?qi��ng)时反映数据库的变化�?
另外�Q�需要注意的是,cache.remove(key); �q�个事�g需要传播到Cluster其他计算机,通知它们清理�~�存�?
��Z��么需要这个通知�Q?
一定要注意�Q�这不是��Z��避免�q�发修改冲突。�ƈ发修改冲�H�的避免需要引入乐观锁版本控制机制�?
有可能存在这��L(f��ng)��误解�Q�认为有了乐观锁版本控制机制�Q�就不需要Cache.remove通知了。这是不对的�?
Cache.remove通知的主要目的是�Q�保证缓存能够及(qi��ng)时清理过期数据,反映数据的变化,保证大部分时间内�Q�应用程序显�C�给用户的不是过期数据�?
另外�Q�db.commt(); cache.remove(key); �q�两步调用之��_(d��)��有很���的可能发生另外的事务。这�D�|�����的旉���内,可能无法保证Read Committed�Q�可能出现很短期的过期数据�?
��Z��么说很短期,因�ؓ(f��)紧接着的Cache.remove��׃��(x��)清理�q�期数据�?
如果偏执到这�U�程度,�q�么短期的几乎不可能发生的小概率事�g�Q�都不能容忍�Q�那么可以,db.commt()之前�Q�给C(j��)ache加一个�?zh��n)�观锁�Q�不让别的事务,把数据Put�q�入Cache�Q�就可以防止�q�个���概率、微影响的事件�?
JBoss Cache和Tangosol���提供了�q�类鸡肋一般的�(zh��n)�观锁机制。典型的开发资源配�|�不当,有用的需要的不做�Q�没用的功能使劲做�?
ORM Query Cache
ORM Cache一般分��Z���U�。一�U�是ID Cache�Q�ORM文档中称��Z���U�Cache�Q�,用来存放Entity ID对应的Entity对象�Q�一�U�是Query Cache�Q�用来存放一条查询语句对应的查询�l�果集�?
ID Cache非常直观�Q�如同上�q�讲�q�的�Q�一般是一个Entity Class对应一个Region�Q�Entity存放到对应的Region里面�?
Query Cache比较复杂�Q�而且潜在作用很大�Q�值得仔细讲解�?
现有的ORM对Query Cache的支持�ƈ不是很理惟�?
比如�Q�Hibernate把整个结果集直接攑֜�Query Cache中。这��P��有�Q何风吹草动,发生了�Q何数据库的写操作�Q�Query Cache都需要清�I��?
有一�U�比较好的做法,把ID List存放在Query Cache中,每次获取的时候,先获取ID List�Q�然后根据ID List获取Entity List。Query Cache�Ҏ(gu��)��Query涉及(qi��ng)到的Table Name来进行清理,一旦发生对�q�些Table Name的修�Ҏ(gu��)��作,���可以根据不同情况,清理Query Cache�?
比如�Q�select t2.* from t1, t2 where t1.id = t2.foreign_id and t1.name = ‘a’
那么insert into t1, delete from t1, insert into t2, delete from t2都会(x��)清除�q�条Query Cache�?
同样�?update t1 set name = … �q�样的语句也�?x��)清除这条Query Cache�?
Hibernate��Z��么不�q�么做,因�ؓ(f��)Query Cache的情冉|��较复杂。也�?d��ng)R��择的结果集�q�不是只有一个Entity�c�d���Q�也许只是几个字�D�c(di��n)�?
�q�个地方�Q�如果细分,�q�是有很多功夫可以做的。而且也很值得花功夫做�Q�因为Query Cache对于性能的提高,有很大作用�?
-------------------------------------------------------
ORM Query Cache
Cache可以用在��M��地方�Q�比如,��面�~�存。但Cache的最常用场景是用在ORM中,比如�Q�Hibernate�Q�JDO�Q�JPA中�?
ORM Cache一般分��Z���U�。一�U�是ID Cache�Q�ORM文档中称��Z���U�Cache�Q�,用来存放Entity ID对应的Entity对象�Q�一�U�是Query Cache�Q�用来存放一条查询语句对应的查询�l�果集�?
ID Cache非常直观�Q�如同上�q�讲�q�的�Q�一般是一个Entity Class对应一个Region�Q�Entity存放到对应的Region里面�?
Query Cache比较复杂�Q�而且潜在作用很大�Q�值得仔细讲解�?
现有的ORM对Query Cache的支持�ƈ不是很理惟�?
比如�Q�Hibernate把整个结果集直接攑֜�Query Cache中。这��P��有�Q何风吹草动,发生了�Q何数据库的写操作�Q�Query Cache都需要清�I��?
有一�U�比较好的做法,把ID List存放在Query Cache中,每次获取的时候,先获取ID List�Q�然后根据ID List获取Entity List。Query Cache�Ҏ(gu��)��Query涉及(qi��ng)到的Table Name来进行清理,一旦发生对�q�些Table Name的修�Ҏ(gu��)��作,���可以根据不同情况,清理Query Cache�?
比如�Q�select t2.* from t1, t2 where t1.id = t2.foreign_id and t1.name = ‘a’
那么insert into t1, delete from t1, insert into t2, delete from t2都会(x��)清除�q�条Query Cache�?
同样�?update t1 set name = … �q�样的语句也�?x��)清除这条Query Cache�?
Hibernate��Z��么不�q�么做,因�ؓ(f��)Query Cache的情冉|��较复杂。也�?d��ng)R��择的结果集�q�不是只有一个Entity�c�d���Q�也许只是几个字�D�c(di��n)�?
�q�个地方�Q�如果细分,�q�是有很多功夫可以做的。而且也很值得花功夫做�Q�因为Query Cache对于性能的提高,有很大作用�?
-----------------------------------------------------------
Query Key
Query Cache的性能需要考虑几个斚w��。比如,Query Key。Query Key一般由2个部分组成:(x��)Query String部分�Q�SQL, HQL, EQL, or OQL�Q�参数部分�?
��L��Query Key的对应数据的时候,Query Key的比较有两个步骤�Q�先hash�Q�然后equals。所以,Query Key的hashcode和equals两个�Ҏ(gu��)��很重要。尤其是equals�Ҏ(gu��)���?
equals�Ҏ(gu��)��需要比较很长的Query String。如果没有命中,Query String不相�{�,那么开销很小�Q�因为通常来说�Q�不相等的String长度都不同,或者前面的字符串都不相同。开销最大的是命中的时候,Query String相等�Q�那么需要把String从头比到����?
我们可以采取一些方法来提高String的比较速度。比如,大部分的情况属于静态查询,我们可以采用Singleton String。相同reference的String之间的比较速度很快。对于ORM来说�Q�最好直接��用最外面的HQL, EQL, OQL作�ؓ(f��)Query Key�Q�而不是采用生成的SQL�l�果。因为生成的SQL�l�果每次都是一个新String�Q�具有不同的reference�Q�Cache命中的时候,需要比�? 整个字符丌Ӏ?
动态拼装的Query String的性能提高比较隑֊�。因为最�l�的�l�果�Q�都是一个新String。我采用的一�U�方式是�Q�动态拼装的�l�果是一个String[]。两�? String[]如果相等�Q�那么里面的元素String的reference都是相等的,�q�是由JVM对一个Class内部的String帔R���q�行优化�? �l�果�?
比如�Q?
String[] a = {
“select * from t where”
“a = 1”
“and b = 2”
};
String[] b = {
“select * from t where”
“a = 1”
“and b = 2”
};
那么a和b的比较只需�?�ơString reference的比较�?
]]>
发表日:(x��)2008/7/30
作者:(x��)镉K��雅广(Masahiro Nagano)
原文链接�Q?a >http://gihyo.jp/dev/feature/01/memcached/0005
我是Mixi的长野。memcached的连载终于要�l�束了。到上次为止�Q�我们介�l�了与memcached直接相关的话题,本次介绍一些mixi的案例和实际应用上的话题�Q��ƈ介绍一些与memcached兼容的程序�?
mixi案例研究
mixi在提供服务的初期阶段��׃��用了memcached。随着�|�站讉K��量的急剧增加�Q�单�U��ؓ(f��)数据库添加slave已无法满���需要,因此引入了memcached。此外,我们也从增加可扩展性的斚w���q�行了验证,证明了memcached的速度和稳定性都能满���需要。现在,memcached已成为mixi服务中非帔R��要的�l�成部分�?/p>

�? 现在的系�l�组�?/p>
服务器配�|�和数量
mixi使用了许许多多服务器�Q�如数据库服务器、应用服务器、图片服务器、反向代理服务器�{�。单单memcached���有���近200台服务器在运行�?memcached服务器的典型配置如下�Q?/p>
- CPU�Q�Intel Pentium 4 2.8GHz
- 内存�Q?GB
- ���盘�Q?46GB SCSI
- 操作�pȝ���Q�Linux�Q�x86_64�Q?/li>
�q�些服务器以前曾用于数据库服务器�{�。随着CPU性能提升、内存�h(hu��n)��g��降,我们�U�极地将数据库服务器、应用服务器�{�换成了性能更强大、内存更多的服务器。这��P��可以抑制mixi整体使用的服务器数量的急剧增加�Q�降低管理成本。由于memcached服务器几乎不占用CPU�Q�就���换下来的服务器用作memcached服务器了�?/p>
memcached�q�程
每台memcached服务器仅启动一个memcached�q�程。分配给memcached的内存�ؓ(f��)3GB�Q�启动参数如下:(x��)
/usr/bin/memcached -p 11211 -u nobody -m 3000 -c 30720
�׃��使用了x86_64的操作系�l�,因此能分�?GB以上的内存�?2位操作系�l�中�Q�每个进�E�最多只能���?GB内存。也曄���考虑�q�启动多个分�?GB以下内存的进�E�,但这样一台服务器上的TCP�q�接数就�?x��)成倍增加,���理上也变得复杂�Q�所以mixi���q��一使用�?4位操作系�l��?/p>
另外�Q�虽然服务器的内存�ؓ(f��)4GB�Q�却仅分配了3GB�Q�是因�ؓ(f��)内存分配量超�q�这个��|�����有可能��D��内存交换(swap)。连载的�W?��?/a>中前坂讲解过了memcached的内存存�?#8220;slab allocator”�Q�当时说�q�,memcached启动时指定的内存分配量是memcached用于保存数据的量�Q�没有包�?#8220;slab allocator”本��n占用的内存、以�?qi��ng)��?f��)了保存数据而设�|�的���理�I�间。因此,memcached�q�程的实际内存分配量要比指定的容量要大,�q�一点应当注意�?/p>
mixi保存在memcached中的数据大部分都比较?y��u)��。这��P���q�程的大���要比指定的定w��大很多。因此,我们反复改变内存分配量进行验证,���认�?GB的大���不�?x��)引发swap�Q�这���是现在应用的数倹{�?/p>
现在�Q�mixi的服务将200台左右的memcached服务器作��Z��个pool使用。每台服务器的容量�ؓ(f��)3GB�Q�那么全体就有了���近600GB的巨大的内存数据库。客��L(f��ng)���E�序库��用了本连载中多次提到车的Cache::Memcached::Fast�Q�与服务器进行交互。当�Ӟ���~�存的分布式���法使用的是 �W?��?/a>介绍�q�的 Consistent Hashing���法�?/p>
应用层上memcached的��用方法由开发应用程序的工程师自行决定�ƈ实现。但是,��Z��防止车轮再造、防止Cache::Memcached::Fast上的教训再次发生�Q�我们提供了Cache::Memcached::Fast的wrap模块�q���用�?/p>
Cache::Memcached的情况下�Q�与memcached的连接(文�g句柄�Q�保存在Cache::Memcached包内的类变量中。在mod_perl和FastCGI�{�环境下�Q�包内的变量不会(x��)像CGI那样随时重新启动�Q�而是在进�E�中一直保持。其�l�果���是不会(x��)断开与memcached的连接,减少了TCP�q�接建立时的开销�Q�同时也能防止短旉���内反复进行TCP�q�接、断开而导致的TCP端口资源枯竭�?/p>
但是�Q�Cache::Memcached::Fast没有�q�个功能�Q�所以需要在模块之外���Cache::Memcached::Fast对象保持在类变量中,以保证持久连接�?/p>
上面的例子中�Q�Cache::Memcached::Fast对象保存到类变量$fast中�?/p>
诸如mixi的主��上的新闻这��L(f��ng)��所有用户共享的�~�存数据、设�|�信息等数据�Q�会(x��)占用许多��,讉K���ơ数也非常多。在�q�种条�g下,讉K��很容易集中到某台memcached服务器上。访问集中本�w��ƈ不是问题�Q�但是一旦访问集中的那台服务器发生故障导致memcached无法�q�接�Q�就�?x��)��生巨大的问题�?/p>
�q�蝲�?a >�W?��?/a> 中提刎ͼ�Cache::Memcached拥有rehash功能�Q�即在无法连接保存数据的服务器的情况下,�?x��)再�ơ计���hash��|���q�接其他的服务器�?/p>
但是�Q�Cache::Memcached::Fast没有�q�个功能。不�q�,它能够在�q�接服务器失败时�Q�短旉���内不再连接该服务器的功能�?/p>
在failure_timeout�U�内发生max_failures以上�ơ连接失败,��׃��再连接该memcached服务器。我们的讄����?�U�钟3�ơ以上�?/p>
此外�Q�mixi�q��ؓ(f��)所有用户共享的�~�存数据的键名设�|�命名规则,�W�合命名规则的数据会(x��)自动保存到多台memcached服务器中�Q�取得时从中仅选取一台服务器。创�����函数库后�Q�就可以使memcached服务器故障不再��生其他媄响�?/p>
到此为止介绍了memcached内部构造和函数库,接下来介�l�一些其他的应用�l�验�?/p>
通常情况下memcached�q�行得相当稳定,但mixi现在使用的最新版1.2.5 曄���发生�q�几�ơmemcached�q�程��L��的情��c(di��n)��架构上保证了即使有几台memcached故障也不�?x��)媄响服务,不过对于memcached�q�程��L��的服务器�Q�只要重新启动memcached�Q�就可以正常�q�行�Q�所以采用了监视memcached�q�程�q�自动启动的�Ҏ(gu��)��。于是��用了daemontools�?/p>
daemontools是qmail的作者DJB开发的UNIX服务���理工具集,其中名�ؓ(f��)supervise的程序可用于服务启动、停止的服务重启�{��?/p>
�q�里不介�l�daemontools的安装了。mixi使用了以下的run脚本来启动memcached�?/p>
mixi使用了名�?#8220;nagios”的开源监视��Y件来监视memcached�?/p>
在nagios中可以简单地开发插�Ӟ��可以详细地监视memcached的get、add�{�动作。不�q�mixi仅通过stats命��o(h��)来确认memcached的运行状态�?/p>
此外�Q�mixi���stats目录的结果通过rrdtool转化成图形,�q�行性能监视�Q��ƈ���每天的内存使用量做成报表,通过邮�g与开发者共享�?/p>
�q�蝲中已介绍�q�,memcached的性能十分优秀。我们来看看mixi的实际案例。这里介�l�的图表是服务所使用的访问最为集中的memcached服务器�?/p>
�? ��h���?/p>
�? ���量 �? TCP�q�接�?/p>
从上至下依次�����求数、流量和TCP�q�接数。请求数最大�ؓ(f��)15000qps�Q�流量达�?00Mbps�Q�这时的�q�接数已���过�?0000个。该服务器没有特别的����g�Q�就是开头介�l�的普通的memcached服务器。此时的CPU利用率�ؓ(f��)�Q?/p>
�? CPU利用�?/p>
可见�Q�仍然有idle的部分。因此,memcached的性能非常高,可以作�ؓ(f��)Web应用�E�序开发者放心地保存临时数据或缓存数据的地方�?/p>
memcached的实现和协议都十分简单,因此有很多与memcached兼容的实现。一些功能强大的扩展可以���memcached的内存数据写到磁盘上�Q�实现数据的持久性和冗余。连�?a >�W?��?/a> 介绍�q�,以后的memcached的存储层���变成可扩展的(pluggable�Q�,逐渐支持�q�些功能�?/p>
�q�里介绍几个与memcached兼容的应用程序�?/p>
mixi使用了上�q�兼容应用程序中的Tokyo Tyrant。Tokyo Tyrant是��^林开发的 Tokyo Cabinet DBM的网�l�接口。它有自��q��协议�Q�但也拥有memcached兼容协议�Q�也可以通过HTTP�q�行数据交换。Tokyo Cabinet虽然是一�U�将数据写到���盘的实玎ͼ�但速度相当快�?/p>
mixi�q�没有将Tokyo Tyrant作�ؓ(f��)�~�存服务器,而是���它作�ؓ(f��)保存键值对�l�合的DBMS来��用。主要作为存储用户上�ơ访问时间的数据库来使用。它与几乎所有的mixi服务都有养I��每次用户讉K����面旉���要更新数据,因此负荷相当高。MySQL的处理十分笨重,单独使用memcached保存数据又有可能�?x��)丢失数据,所以引入了Tokyo Tyrant。但无需重新开发客��L(f��ng)���Q�只需原封不动��C��用Cache::Memcached::Fast卛_���Q�这也是优点之一。关于Tokyo Tyrant的详�l�信息,请参考本公司的开发blog�?/p>
到本�ơ�ؓ(f��)止,“memcached全面剖析”�p�d�����q��束了。我们介�l�了memcached的基���、内部结构、分散算法和应用�{�内宏V��读完后如果�(zh��n)�能对memcached产生兴趣�Q�就是我们的荣幸。关于mixi的系�l�、应用方面的信息�Q�请参考本公司�?a >开发blog ��Z��方便阅读�Q�现���原来的���译�l�果打包成PDF文档�Q?a >下蝲memcached使用�Ҏ(gu��)��和客��L(f��ng)��
通过Cache::Memcached::Fast�l�持�q�接
package Gihyo::Memcached;
use strict;
use warnings;
use Cache::Memcached::Fast;
my @server_list = qw/192.168.1.1:11211 192.168.1.1:11211/;
my $fast; ## 用于保持对象
sub new {
my $self = bless {}, shift;
if ( !$fast ) {
$fast = Cache::Memcached::Fast->new({ servers => \@server_list });
}
$self->{_fast} = $fast;
return $self;
}
sub get {
my $self = shift;
$self->{_fast}->get(@_);
}公共数据的处理和rehash
my $fast = Cache::Memcached::Fast->new({
max_failures => 3,
failure_timeout => 1
});memcached应用�l�验
通过daemontools启动
#!/bin/sh
if [ -f /etc/sysconfig/memcached ];then
. /etc/sysconfig/memcached
fi
exec 2>&1
exec /usr/bin/memcached -p $PORT -u $USER -m $CACHESIZE -c $MAXCONN $OPTIONS监视
define command {
command_name check_memcached
command_line $USER1$/check_tcp -H $HOSTADDRESS$ -p 11211 -t 5 -E -s 'stats\r\nquit\r\n' -e 'uptime' -M crit
}memcached的性能




兼容应用�E�序
Tokyo Tyrant案例
�ȝ��
]]>
发表日:(x��)2008/7/23
作者:(x��)镉K��雅广(Masahiro Nagano)
原文链接�Q?a >http://gihyo.jp/dev/feature/01/memcached/0004
我是Mixi的长野�?�W?��?/a>�?�W?��?/a> 由前坂介�l�了memcached的内部情��c(di��n)��本�ơ不再介�l�memcached的内部结构,开始介�l�memcached的分布式�?/p>
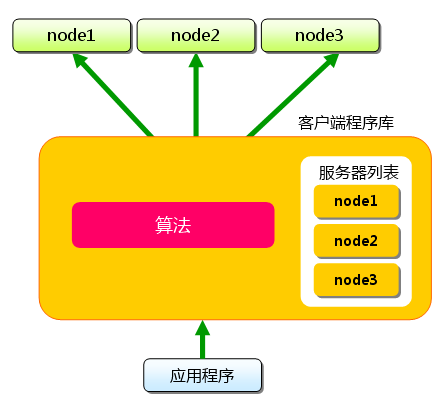
正如�W?��?/a>中介�l�的那样�Q?memcached虽然�U�Cؓ(f��)“分布�?#8221;�~�存服务器,但服务器端�ƈ没有“分布�?#8221;功能。服务器端仅包括 �W?��?/a>�?�W?��?/a> 前坂介绍的内存存储功能,其实现非常简单。至于memcached的分布式�Q�则是完全由客户端程序库实现的。这�U�分布式是memcached的最大特炏V�?/p>
�q�里多次使用�?#8220;分布�?#8221;�q�个词,但�ƈ未做详细解释。现在开始简单地介绍一下其原理�Q�各个客��L(f��ng)��的实现基本相同�?/p>
下面假设memcached服务器有node1~node3三台�Q�应用程序要保存键名�?#8220;tokyo”“kanagawa”“chiba”“saitama”“gunma” 的数据�?/p>
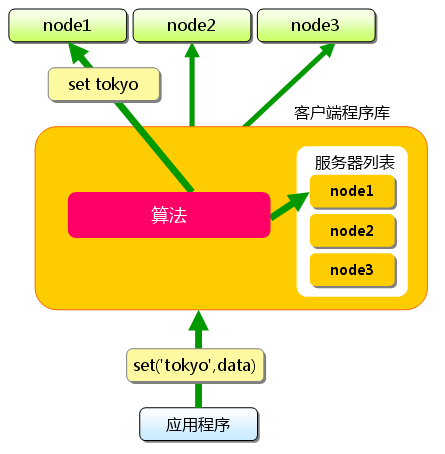
�? 分布式简介:(x��)准备 首先向memcached中添�?#8220;tokyo”。将“tokyo”传给客户端程序库后,客户端实现的���法��׃��(x��)�Ҏ(gu��)��“�?#8221;来决定保存数据的memcached服务器。服务器选定后,卛_��令它保存“tokyo”�?qi��ng)其倹{�?/p>
�? 分布式简介:(x��)��d���?/p>
同样�Q?#8220;kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存�?/p>
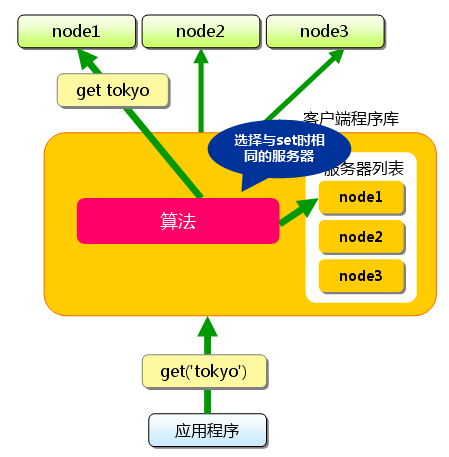
接下来获取保存的数据。获取时也要���要获取的键“tokyo”传递给函数库。函数库通过与数据保存时相同的算法,�Ҏ(gu��)��“�?#8221;选择服务器。��用的���法相同�Q�就能选中与保存时相同的服务器�Q�然后发送get命��o(h��)。只要数据没有因为某些原因被删除�Q�就能获得保存的倹{�?/p>
�? 分布式简介:(x��)获取�?/p>
�q�样�Q�将不同的键保存��C��同的服务器上�Q�就实现了memcached的分布式�?memcached服务器增多后�Q�键��׃��(x��)分散�Q�即使一台memcached服务器发生故障无法连接,也不�?x��)媄响其他的�~�存�Q�系�l�依然能�l�箋�q�行�?/p>
接下来介�l?a >�W?��?/a> 中提到的Perl客户端函数库Cache::Memcached实现的分布式�Ҏ(gu��)���?/p>
Perl的memcached客户端函数库Cache::Memcached�?memcached的作者Brad Fitzpatrick的作品,可以说是原装的函数库了�?/p>
该函数库实现了分布式功能�Q�是memcached标准的分布式�Ҏ(gu��)���?/p>
Cache::Memcached的分布式�Ҏ(gu��)�����单来��_(d��)�����是“�Ҏ(gu��)��服务器台数的余数�q�行分散”。求得键的整数哈希��|��再除以服务器台数�Q�根据其余数来选择服务器�?/p>
下面���Cache::Memcached���化成以下的Perl脚本来进行说明�?/p>
Cache::Memcached在求哈希值时使用了CRC�?/p>
首先求得字符串的CRC��|���Ҏ(gu��)��该值除以服务器节点数目得到的余数决定服务器。上面的代码执行后输入以下结果:(x��) �Ҏ(gu��)��该结果,“tokyo”分散到node2�Q?#8220;kanagawa”分散到node3�{�。多说一句,当选择的服务器无法�q�接�Ӟ��Cache::Memcached�?x��)将�q�接�ơ数��d��到键之后�Q�再�ơ计���哈希值�ƈ���试�q�接。这个动作称为rehash。不希望rehash时可以在生成Cache::Memcached对象时指�?#8220;rehash => 0”选项�?/p>
余数计算的方法简单,数据的分散性也相当优秀�Q�但也有其缺炏V��那���是当添加或�U�除服务器时�Q�缓存重�l�的代�h(hu��n)相当巨大。添加服务器后,余数��׃��(x��)产生巨变�Q�这样就无法获取与保存时相同的服务器�Q�从而媄响缓存的命中率。用Perl写段代码来验证其代�h(hu��n)�?/p>
�q�段Perl脚本演示了将“a”�?#8220;z”的键保存到memcached�q�访问的情况。将其保存�ؓ(f��)mod.pl�q�执行�?/p>
首先�Q�当服务器只有三台时�Q?/p>
�l�果如上�Q�node1保存a、c、d、e……�Q�node2保存g、i、k……�Q�每台服务器都保存了8个到10个数据�?/p>
接下来增加一台memcached服务器�?/p>
��d��了node4。可见,只有d、i、k、p、r、y命中了。像�q�样�Q�添加节点后键分散到的服务器�?x��)发生巨大变化�?6个键中只有六个在讉K��原来的服务器�Q�其他的全都�U�d��了其他服务器。命中率降低�?3%。在Web应用�E�序中��用memcached�Ӟ��在添加memcached服务器的瞬间�~�存效率�?x��)大�q�度下降�Q�负载会(x��)集中到数据库服务器上�Q�有可能�?x��)发生无法提供正常服务的情况�?/p>
mixi的Web应用�E�序�q�用中也有这个问题,��D��无法��d��memcached服务器。但�׃��使用了新的分布式�Ҏ(gu��)���Q�现在可以轻而易丑֜���d��memcached服务器了。这�U�分布式�Ҏ(gu��)���U�Cؓ(f��) Consistent Hashing�?/p>
关于Consistent Hashing的思想�Q�mixi株式�?x��)社的开发blog�{�许多地斚w��介绍�q�,�q�里只简单地说明一下�?/p>
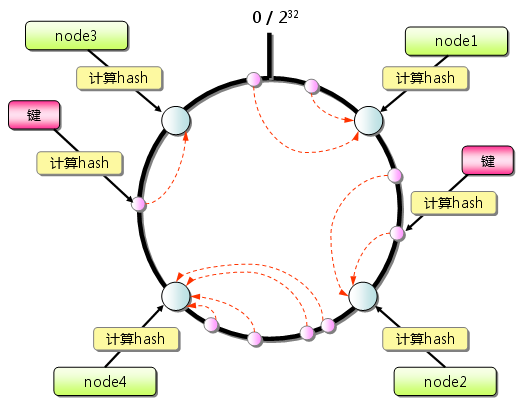
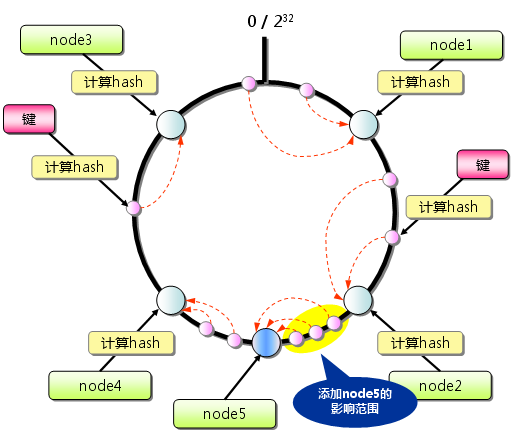
Consistent Hashing如下所�C�:(x��)首先求出memcached服务器(节点�Q�的哈希��|���q�将光����|�到0�?32的圆�Q�continuum�Q�上。然后用同样的方法求出存储数据的键的哈希��|���q�映���到圆上。然后从数据映射到的位置开始顺旉���查找�Q�将数据保存到找到的�W�一个服务器上。如果超�q?32仍然找不到服务器�Q�就�?x��)保存到�W�一台memcached服务器上�?/p>
�? Consistent Hashing�Q�基本原�?/p>
从上囄���状态中��d��一台memcached服务器。余数分布式���法�׃��保存键的服务器会(x��)发生巨大变化而媄响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地炚w��时针方向的�W�一台服务器上的键会(x��)受到影响�?/p>
�? Consistent Hashing�Q�添加服务器 因此�Q�Consistent Hashing最大限度地抑制了键的重新分布。而且�Q�有的Consistent Hashing的实现方法还采用了虚拟节点的思想。��用一般的hash函数的话�Q�服务器的映���地点的分布非常不均匀。因此,使用虚拟节点的思想�Q��ؓ(f��)每个物理节点�Q�服务器�Q�在continuum上分�?00�?00个点。这样就能抑制分布不均匀�Q�最大限度地减小服务器增减时的缓存重新分布�?/p>
通过下文中介�l�的使用Consistent Hashing���法的memcached客户端函数库�q�行���试的结果是�Q�由服务器台敎ͼ�n�Q�和增加的服务器台数�Q�m�Q�计���增加服务器后的命中率计���公式如下:(x��) (1 - n/(n+m)) * 100 本连载中多次介绍的Cache::Memcached虽然不支持Consistent Hashing�Q�但已有几个客户端函数库支持了这�U�新的分布式���法。第一个支持Consistent Hashing和虚拟节点的memcached客户端函数库是名为libketama的PHP库,由last.fm开发�?/p>
至于Perl客户端,�q�蝲�?a >�W?��?/a> 中介�l�过的Cache::Memcached::Fast和Cache::Memcached::libmemcached支持 Consistent Hashing�?/p>
两者的接口都与Cache::Memcached几乎相同�Q�如果正在��用Cache::Memcached�Q�那么就可以方便地替换过来。Cache::Memcached::Fast重新实现了libketama�Q���用Consistent Hashing创徏对象时可以指定ketama_points选项�?/p>
另外�Q�Cache::Memcached::libmemcached 是一个��用了Brain Aker开发的C函数库libmemcached的Perl模块�?libmemcached本��n支持几种分布式算法,也支持Consistent Hashing�Q�其Perl�l�定也支持Consistent Hashing�?/p>
本次介绍了memcached的分布式���法�Q�主要有memcached的分布式是由客户端函数库实现�Q�以�?qi��ng)高效率地分散数据的Consistent Hashing���法。下�ơ将介绍mixi在memcached应用斚w��的一些经验,和相关的兼容应用�E�序�?/p>
memcached的分布式
memcached的分布式是什么意思?
Cache::Memcached的分布式�Ҏ(gu��)��
�Ҏ(gu��)��余数计算分散
use strict;
use warnings;
use String::CRC32;
my @nodes = ('node1','node2','node3');
my @keys = ('tokyo', 'kanagawa', 'chiba', 'saitama', 'gunma');
foreach my $key (@keys) {
my $crc = crc32($key); # CRC�?br />
my $mod = $crc % ( $#nodes + 1 );
my $server = $nodes[ $mod ]; # �Ҏ(gu��)��余数选择服务�?br />
printf "%s => %s\n", $key, $server;
}tokyo => node2
kanagawa => node3
chiba => node2
saitama => node1
gunma => node1�Ҏ(gu��)��余数计算分散的缺�?/h3>
use strict;
use warnings;
use String::CRC32;
my @nodes = @ARGV;
my @keys = ('a'..'z');
my %nodes;
foreach my $key ( @keys ) {
my $hash = crc32($key);
my $mod = $hash % ( $#nodes + 1 );
my $server = $nodes[ $mod ];
push @{ $nodes{ $server } }, $key;
}
foreach my $node ( sort keys %nodes ) {
printf "%s: %s\n", $node, join ",", @{ $nodes{$node} };
}$ mod.pl node1 node2 nod3
node1: a,c,d,e,h,j,n,u,w,x
node2: g,i,k,l,p,r,s,y
node3: b,f,m,o,q,t,v,z$ mod.pl node1 node2 node3 node4
node1: d,f,m,o,t,v
node2: b,i,k,p,r,y
node3: e,g,l,n,u,w
node4: a,c,h,j,q,s,x,zConsistent Hashing
Consistent Hashing的简单说�?/h3>
支持Consistent Hashing的函数库
my $memcached = Cache::Memcached::Fast->new({
servers => ["192.168.0.1:11211","192.168.0.2:11211"],
ketama_points => 150
});�ȝ��
]]>
下面是《memcached全面剖析》的�W�三部分�?/p>
发表日:(x��)2008/7/16
作者:(x��)前坂�?Toru Maesaka)
原文链接�Q?a >http://gihyo.jp/dev/feature/01/memcached/0003
memcached是缓存,所以数据不�?x��)永久保存在服务器上�Q�这是向�pȝ��中引入memcached的前提�? 本次介绍memcached的数据删除机�Ӟ��以及(qi��ng)memcached的最新发展方向——二�q�制协议�Q�Binary Protocol�Q? 和外部引擎支持�?/p>
memcached在数据删除方面有效利用资�?/h2>
数据不会(x��)真正从memcached中消�?/h3>
上次介绍�q�, memcached不会(x��)释放已分配的内存。记录超时后�Q�客��L(f��ng)�����无法再看见该记录(invisible�Q�透明�Q�, 其存储空间即可重复��用�?/p>
Lazy Expiration
memcached内部不会(x��)监视记录是否�q�期�Q�而是在get时查看记录的旉���戻I�����查记录是否过期�? �q�种技术被�U�Cؓ(f��)lazy�Q�惰性)expiration。因此,memcached不会(x��)在过期监视上耗费CPU旉����?/p>
LRU�Q�从�~�存中有效删除数据的原理
memcached�?x��)优先��用已���时的记录的�I�间�Q�但即��如此�Q�也�?x��)发生追加新记录时空间不���的情况�Q? 此时���p��使用名�ؓ(f��) Least Recently Used�Q�LRU�Q�机制来分配�I�间�? ���思义�Q�这是删�?#8220;最�q�最������?#8221;的记录的机制�? 因此�Q�当memcached的内存空间不���x���Q�无法从slab class 获取到新的空间时�Q�,��׃��最�q�未被��用的记录中搜索,�q�将其空间分配给新的记录�? 从缓存的实用角度来看�Q�该模型十分理想�?/p>
不过�Q�有些情况下LRU机制反倒会(x��)造成�ȝ��。memcached启动旉���过“-M”参数可以���止LRU�Q�如下所�C�:(x��)
$ memcached -M -m 1024
启动时必���L��意的是,���写�?#8220;-m”选项是用来指定最大内存大���的。不指定具体数值则使用默认�?4MB�?/p>
指定“-M”参数启动后,内存用尽时memcached�?x��)返回错误�? 话说回来�Q�memcached毕竟不是存储器,而是�~�存�Q�所以推荐��用LRU�?/p>
memcached的最新发展方�?/h2>
memcached的roadmap上有两个大的目标。一个是二进制协议的�{�划和实玎ͼ�另一个是外部引擎的加载功能�?/p>
关于二进制协�?/h3>
使用二进制协议的理由是它不需要文本协议的解析处理�Q���得原本高速的memcached的性能更上一层楼�Q? �q�能减少文本协议的漏�z�。目前已大部分实玎ͼ�开发用的代码库中已包含了该功能�? memcached的下载页面上有代码库的链接�?/p>
二进制协议的格式
协议的包�?4字节的���Q�其后面是键和无�l�构数据�Q�Unstructured Data�Q��? 实际的格式如下(引自协议文档�Q�:(x��)
Byte/ 0 | 1 | 2 | 3 |
/ | | | |
|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|
+---------------+---------------+---------------+---------------+
0/ HEADER /
/ /
/ /
/ /
+---------------+---------------+---------------+---------------+
24/ COMMAND-SPECIFIC EXTRAS (as needed) /
+/ (note length in th extras length header field) /
+---------------+---------------+---------------+---------------+
m/ Key (as needed) /
+/ (note length in key length header field) /
+---------------+---------------+---------------+---------------+
n/ Value (as needed) /
+/ (note length is total body length header field, minus /
+/ sum of the extras and key length body fields) /
+---------------+---------------+---------------+---------------+
Total 24 bytes
如上所�C�,包格式十分简单。需要注意的是,占据�?6字节的头�?HEADER)分�ؓ(f��) ��h����_(d��)��Request Header�Q�和响应��_(d��)��Response Header�Q�两�U��? 头部中包含了表示包的有效性的Magic字节、命令种�c�R��键长度、值长度等信息�Q�格式如下:(x��)
Request Header
Byte/ 0 | 1 | 2 | 3 |
/ | | | |
|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|
+---------------+---------------+---------------+---------------+
0| Magic | Opcode | Key length |
+---------------+---------------+---------------+---------------+
4| Extras length | Data type | Reserved |
+---------------+---------------+---------------+---------------+
8| Total body length |
+---------------+---------------+---------------+---------------+
12| Opaque |
+---------------+---------------+---------------+---------------+
16| CAS |
| |
+---------------+---------------+---------------+---------------+
Response Header
Byte/ 0 | 1 | 2 | 3 |
/ | | | |
|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|
+---------------+---------------+---------------+---------------+
0| Magic | Opcode | Key Length |
+---------------+---------------+---------------+---------------+
4| Extras length | Data type | Status |
+---------------+---------------+---------------+---------------+
8| Total body length |
+---------------+---------------+---------------+---------------+
12| Opaque |
+---------------+---------------+---------------+---------------+
16| CAS |
| |
+---------------+---------------+---------------+---------------+
如希望了解各个部分的详细内容�Q�可以checkout出memcached的二�q�制协议的代码树(w��i)�Q? 参考其中的docs文�g夹中的protocol_binary.txt文档�?/p>
HEADER中引人注目的地方
看到HEADER格式后我的感��x���Q�键的上限太大了�Q�现在的memcached规格中,键长度最大�ؓ(f��)250字节�Q? 但二�q�制协议中键的大���用2字节表示。因此,理论上最大可使用65536字节�Q?<sup>16</sup>�Q�长的键�? ���管250字节以上的键�q�不�?x��)太常用�Q�二�q�制协议发布之后���可以��用巨大的键了�?/p>
二进制协议从下一版本1.3�p�d��开始支持�?/p>
外部引擎支持
我去�q�曾�l�试验性地���memcached的存储层攚w��成了可扩展的(pluggable�Q��?/p>
MySQL的Brian Aker看到�q�个攚w��之后,���将代码发到了memcached的邮件列表�?
memcached的开发者也十分感兴���,���放��C��roadmap中。现在由我和
memcached的开发者Trond Norbye协同开发(规格设计、实现和���试�Q��?
和国外协同开发时时差是个大问题,但抱着相同的愿景,
最后终于可以将可扩展架构的原型公布了�?
代码库可以从memcached的下载页�?/a>
上访问�?/p>
世界上有许多memcached的派生��Y�Ӟ��其理由是希望�怹�保存数据、实现数据冗余等�Q?
即��牺牲一些性能也在所不惜。我在开发memcached之前�Q�在mixi的研发部也曾�l?
考虑�q�重新发明memcached�?/p>
外部引擎的加载机制能���装memcached的网�l�功能、事件处理等复杂的处理�?
因此�Q�现阶段通过强制手段或重新设计等方式使memcached和存储引擎合作的困难
��׃��(x��)烟消云散�Q�尝试各�U�引擎就�?x��)变得轻而易举了�?/p>
该项目中我们最重视的是API设计。函数过多,�?x��)��引擎开发者感到麻烦;
�q�于复杂�Q�实现引擎的门槛��׃��(x��)�q�高。因此,最初版本的接口函数只有13个�?
具体内容限于���幅�Q�这里就省略了,仅说明一下引擎应当完成的操作�Q?/p>
对详�l�规格有兴趣的读者,可以checkout engine��目的代码,阅读器中的engine.h�?/p>
memcached支持外部存储的难�Ҏ(gu��)���Q�网�l�和事�g处理相关的代码(核心服务器)�?
内存存储的代码紧密关联。这�U�现象也�U�Cؓ(f��)tightly coupled�Q�紧密耦合�Q��?
必须���内存存储的代码从核心服务器中独立出来,才能灉|��地支持外部引擎�?
因此�Q�基于我们设计的API�Q�memcached被重构成下面的样子:(x��) 重构之后�Q�我们与1.2.5版、二�q�制协议支持版等�q�行了性能�Ҏ(gu��)���Q�证实了它不�?x��)造成性能影响�?/p>
在考虑如何支持外部引擎加蝲�Ӟ��让memcached�q�行�q�行控制�Q�concurrency control�Q�的�Ҏ(gu��)��是最为容易的�Q?
但是对于引擎而言�Q��ƈ行控制正是性能的真谛,因此我们采用了将多线�E�支持完全交�l�引擎的设计�Ҏ(gu��)���?/p>
以后的改�q�,�?x��)��得memcached的应用范围更为广泛�?/p>
本次介绍了memcached的超时原理、内部如何删除数据等�Q�在此之上又介绍了二�q�制协议�?
外部引擎支持�{�memcached的最新发展方向。这些功能要�?.3版才�?x��)支持,敬请期待�Q?/p>
�q�是我在本连载中的最后一���。感谢大安�����L��的文章! 下次由长野来介绍memcached的应用知识和应用�E�序兼容性等内容�?/p>
外部引擎支持的必要�?/h3>
���单API设计的成功的关键
重新审视现在的体�p?/h3>

�ȝ��
]]>
���译一���技术评论社的文章,是讲memcached的连载�?a >fcicq同学说这个东西很有用�Q�希望大家喜�Ƣ�?/p>
发表日:(x��)2008/7/2
作者:(x��)镉K��雅广(Masahiro Nagano)
原文链接�Q?a >http://gihyo.jp/dev/feature/01/memcached/0001
我是mixi株式�?x��)�?/a>开发部�pȝ���q�营�l�的镉K���?
日常负责�E�序的运营。从今天开始,���分几次针对最�q�在Web应用的可扩展性领�?
的热门话题memcached�Q�与我公司开发部研究开发组的前坂一��P��
说明其内部结构和使用�?/p>
memcached
是以LiveJournal
旗下Danga Interactive
公司�?a >Brad Fitzpatricmemcached是什么?
许多Web应用都将数据保存到RDBMS中,应用服务器从中读取数据�ƈ在浏览器中显�C��? 但随着数据量的增大、访问的集中�Q�就�?x��)出现RDBMS的负担加重、数据库响应恶化�? �|�站昄���延迟�{�重大媄响�?/p>
�q�时���p��memcached大显�w�手了。memcached是高性能的分布式内存�~�存服务器�? 一般的使用目的是,通过�~�存数据库查询结果,减少数据库访问次敎ͼ�以提高动态Web应用的速度�? 提高可扩展性�?/p>

�? 一般情况下memcached的用�?/p>
memcached的特�?/h2>
memcached作�ؓ(f��)高速运行的分布式缓存服务器�Q�具有以下的特点�?/p>
- 协议����?/li>
- ��Z��libevent的事件处�?/li>
- 内置内存存储方式
- memcached不互盔R��信的分布式
协议����?/h3>
memcached的服务器客户端通信�q�不使用复杂的XML�{�格式, 而��用简单的��Z��文本行的协议。因此,通过telnet 也能在memcached上保存数据、取得数据。下面是例子�?/p>
$ telnet localhost 11211
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
set foo 0 0 3 �Q�保存命令)
bar �Q�数据)
STORED �Q�结果)
get foo �Q�取得命令)
VALUE foo 0 3 �Q�数据)
bar �Q�数据)
协议文档位于memcached的源代码内,也可以参考以下的URL�?/p>
��Z��libevent的事件处�?/h3>
libevent是个�E�序库,它将Linux的epoll、BSD�c�L��作系�l�的kqueue�{�事件处理功�? ���装成统一的接口。即使对服务器的�q�接数增加,也能发挥O(1)的性能�? memcached使用�q�个libevent库,因此能在Linux、BSD、Solaris�{�操作系�l�上发挥光���性能�? 关于事�g处理�q�里��׃��再详�l�介�l�,可以参考Dan Kegel的The C10K Problem�?/p>
- libevent: http://www.monkey.org/~provos/libevent/
- The C10K Problem: http://www.kegel.com/c10k.html
内置内存存储方式
��Z��提高性能�Q�memcached中保存的数据都存储在memcached内置的内存存储空间中�? �׃��数据仅存在于内存中,因此重启memcached、重启操作系�l�会(x��)��D��全部数据消失�? 另外�Q�内容容量达到指定��g��后,���基于LRU(Least Recently Used)���法自动删除不��用的�~�存�? memcached本��n是�ؓ(f��)�~�存而设计的服务器,因此�q�没有过多考虑数据的永久性问题�? 关于内存存储的详�l�信息,本连载的�W�二讲以后前坂会(x��)�q�行介绍�Q�请届时参考�?/p>
memcached不互盔R��信的分布式
memcached���管�?#8220;分布�?#8221;�~�存服务器,但服务器端�ƈ没有分布式功能�? 各个memcached不会(x��)互相通信以共享信息。那么,怎样�q�行分布式呢�Q? �q�完全取决于客户端的实现。本�q�蝲也将介绍memcached的分布式�?/p>

�? memcached的分布式
接下来简单介�l�一下memcached的��用方法�?/p>
安装memcached
memcached的安装比较简单,�q�里�E�加说明�?/p>
memcached支持许多�q�_���?/p>
- Linux
- FreeBSD
- Solaris (memcached 1.2.5以上版本)
- Mac OS X
另外也能安装在Windows上。这里��用Fedora Core 8�q�行说明�?/p>
memcached的安�?/h3>
�q�行memcached需要本文开头介�l�的libevent库。Fedora 8中有现成的rpm包, 通过yum命��o(h��)安装卛_���?/p>
$ sudo yum install libevent libevent-devel
memcached的源代码可以从memcached�|�站上下载。本文执�W�时的最新版本�ؓ(f��)1.2.5�? Fedora 8虽然也包含了memcached的rpm�Q�但版本比较老。因为源代码安装�q�不困难�Q? �q�里��׃��使用rpm了�?/p>
- 下蝲memcached�Q?a >http://www.danga.com/memcached/download.bml
memcached安装与一般应用程序相同,configure、make、make install���p��了�?/p>
$ wget http://www.danga.com/memcached/dist/memcached-1.2.5.tar.gz
$ tar zxf memcached-1.2.5.tar.gz
$ cd memcached-1.2.5
$ ./configure
$ make
$ sudo make install
默认情况下memcached安装�?usr/local/bin下�?/p>
memcached的启�?/h3>
从终端输入以下命令,启动memcached�?/p>
$ /usr/local/bin/memcached -p 11211 -m 64m -vv
slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
中间省略
slab class 38: chunk size 391224 perslab 2
slab class 39: chunk size 489032 perslab 2
<23 server listening
<24 send buffer was 110592, now 268435456
<24 server listening (udp)
<24 server listening (udp)
<24 server listening (udp)
<24 server listening (udp)
�q�里昄���了调试信息。这样就在前台启动了memcached�Q�监听TCP端口11211 最大内存��用量�?4M。调试信息的内容大部分是关于存储的信息, 下次�q�蝲时具体说明�?/p>
作�ؓ(f��)daemon后台启动�Ӟ��只需
$ /usr/local/bin/memcached -p 11211 -m 64m -d
�q�里使用的memcached启动选项的内容如下�?/p>
| 选项 | 说明 |
| -p | 使用的TCP端口。默认�ؓ(f��)11211 |
| -m | 最大内存大���。默认�ؓ(f��)64M |
| -vv | 用very vrebose模式启动�Q�调试信息和错误输出到控制台 |
| -d | 作�ؓ(f��)daemon在后台启�?/td> |
上面四个是常用的启动选项�Q�其他还有很多,通过
$ /usr/local/bin/memcached -h
命��o(h��)可以昄���。许多选项可以改变memcached的各�U�行为, 推荐��M��诅R�?/p>
用客��L(f��ng)���q�接
许多语言都实��C���q�接memcached的客��L(f��ng)���Q�其中以Perl、PHP��Z���? 仅仅memcached�|�站上列出的语言���有
- Perl
- PHP
- Python
- Ruby
- C#
- C/C++
- Lua
�{�等�?/p>
- memcached客户端API�Q?a >http://www.danga.com/memcached/apis.bml
�q�里介绍通过mixi正在使用的Perl库链接memcached的方法�?/p>
使用Cache::Memcached
Perl的memcached客户端有
- Cache::Memcached
- Cache::Memcached::Fast
- Cache::Memcached::libmemcached
�{�几个CPAN模块。这里介�l�的Cache::Memcached是memcached的作者Brad Fitzpatric的作品, 应该���是memcached的客��L(f��ng)��中应用最为广泛的模块了�?/p>
- Cache::Memcached - search.cpan.org: http://search.cpan.org/dist/Cache-Memcached/
使用Cache::Memcached�q�接memcached
下面的源代码为通过Cache::Memcached�q�接刚才启动的memcached的例子�?/p>
use strict;
use warnings;
use Cache::Memcached;
my $key = "foo";
my $value = "bar";
my $expires = 3600; # 1 hour
my $memcached = Cache::Memcached->new({
servers => ["127.0.0.1:11211"],
compress_threshold => 10_000
});
$memcached->add($key, $value, $expires);
my $ret = $memcached->get($key);
print "$ret"n";
在这里,为Cache::Memcached指定了memcached服务器的IP地址和一个选项�Q�以生成实例�? Cache::Memcached常用的选项如下所�C��?/p>
| 选项 | 说明 |
| servers | 用数�l�指定memcached服务器和端口 |
| compress_threshold | 数据压羃时��用的�?/td> |
| namespace | 指定��d��到键的前�~� |
另外�Q�Cache::Memcached通过Storable模块可以���Perl的复杂数据序列化之后再保存, 因此散列、数�l�、对象等都可以直接保存到memcached中�?/p>
保存数据
向memcached保存数据的方法有
- add
- replace
- set
它们的��用方法都相同�Q?/p>
my $add = $memcached->add( '�?, '�?, '期限' );
my $replace = $memcached->replace( '�?, '�?, '期限' );
my $set = $memcached->set( '�?, '�?, '期限' );
向memcached保存数据时可以指定期�?�U?。不指定期限�Ӟ��memcached按照LRU���法保存数据�? �q�三个方法的区别如下�Q?/p>
| 选项 | 说明 |
| add | 仅当存储�I�间中不存在键相同的数据时才保存 |
| replace | 仅当存储�I�间中存在键相同的数据时才保�?/td> |
| set | 与add和replace不同�Q�无��Z��旉���保存 |
获取数据
获取数据可以使用get和get_multi�Ҏ(gu��)���?/p>
my $val = $memcached->get('�?);
my $val = $memcached->get_multi('�?', '�?', '�?', '�?', '�?');
一�ơ取得多条数据时使用get_multi。get_multi可以非同步地同时取得多个键��|�� 光���度要比循环调用get快数十倍�?/p>
删除数据
删除数据使用delete�Ҏ(gu��)���Q�不�q�它有个独特的功能�?/p>
$memcached->delete('�?, '��d��旉���(�U?');
删除�W�一个参数指定的键的数据。第二个参数指定一个时间��|��可以���止使用同样的键保存新数据�? 此功能可以用于防止缓存数据的不完整。但是要注意�Q?strong>set函数忽视该阻塞,照常保存数据
增一和减一操作
可以���memcached上特定的键��g�������数器使用�?/p>
my $ret = $memcached->incr('�?);
$memcached->add('�?, 0) unless defined $ret;
增一和减一是原子操作,但未讄���初始值时�Q�不�?x��)自动赋�?。因此, 应当�q�行错误���查,必要时加入初始化操作。而且�Q�服务器端也不会(x��)�? ���过2<sup>32</sup>时的行�ؓ(f��)�q�行���查�?/p>
�ȝ��
�q�次���单介�l�了memcached�Q�以�?qi��ng)它的安装方法、Perl客户端Cache::Memcached的用法�? 只要知道�Q�memcached的��用方法十分简单就���_��了�?/p>
下次由前坂来说明memcached的内部结构。了解memcached的内部构造, ���p��知道如何使用memcached才能使Web应用的速度更上一层楼�? �Ƣ迎�l�箋阅读下一章�?/p>
]]>
]]>