#
摘要: 背景
詳見《Hosts綁定新思路之DNS代理篇》
核心內容
1. DNS協議解析
2. 啟動UDP服務,監聽53端口
3. 根據DB或者文本,進行Hosts解析
DNS協議
DNS Protocol Overview (推薦)
非強詳細,但是不怎么看得懂的長篇大論
如果沒有耐心的同學,可以看看我通過wireshark分析之后制作的兩張gif圖片。大概能知道DNS協議的...
閱讀全文
前言
此文摘自2011年5月23日郵件分享,為《Hosts綁定新思路之HTTP代理篇》續集
電視有續集,電影也有續集,Hosts綁定思路同樣有續集.
我們先用一句話來回顧下,上集中關于Hosts綁定的思路:
原理:利用Http代理的方式,將分散在各個客戶端的Hosts綁定,集中綁定在Http代理服務器上
優點:集中管理
缺點:一臺Http代理服務器,只能綁定一組Hosts信息
(詳細內容,請見之前的郵件)
在當時描述方案郵件的時候,也意識到了方案存在的不足,所以一直在思考改進方案(詳見之前郵件中最后一節—改進方案思路).
經過一段時間的思考,改進方案有了大概的雛形: 將之前的HTTP代理方案 替換成 DNS代理方案
俗話說得好:有圖有真相.先貼上一張架構圖,之后再用文字慢慢解釋
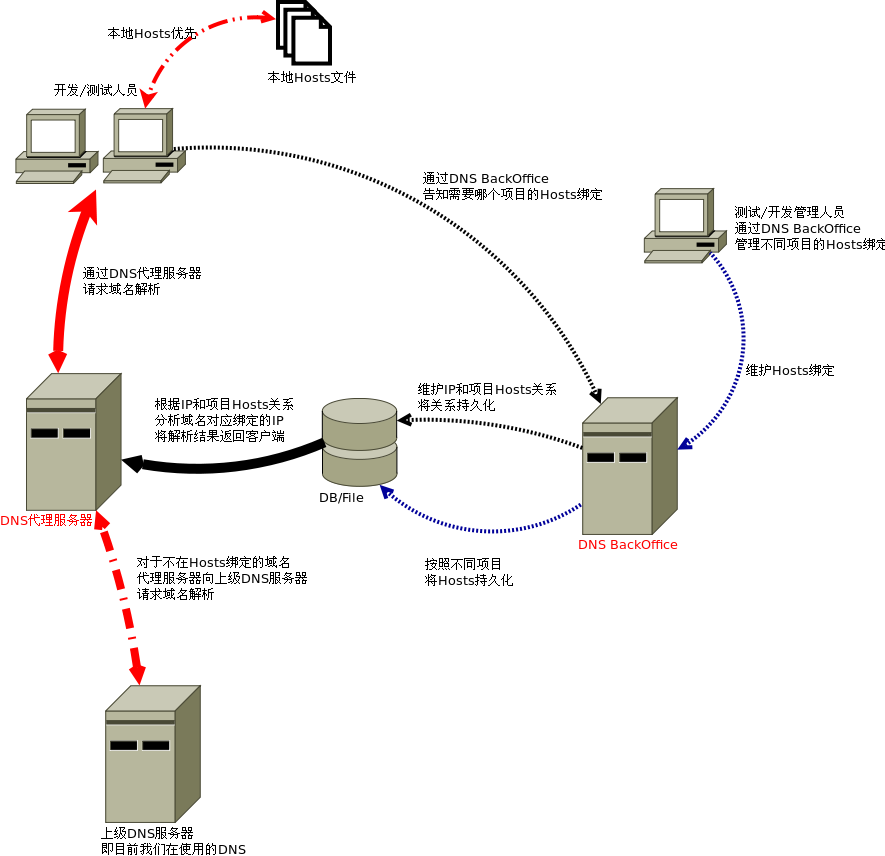
架構中核心組件是:DNS BackOffice服務器 和DNS代理服務器
DNS BackOffice服務器的作用有:
1. 開發/測試管理員通過BackOffice服務維護各自項目的綁定信息,BackOffice服務將之持久化 (圖中 藍色虛線)
2. 開發/測試人員通過BackOffice服務,告知需要哪個項目的綁定信息,BackOffice服務將之持久化 (圖中 黑色虛線)
DNS代理服務器的作用有:
1. 攔截Domain Name的解析.通過來源IP判斷需要綁定的Hosts信息,通過File/DB得到對應的IP,通過DNS協議返回 (圖中 紅色實線 和 黑色實線)
2. 如果不在綁定之列,則請求上級DNS服務器,返回其Response.
此方案的優勢:
1. 本地Hosts綁定優先.
只要本地Hosts有綁定IP,則不會請求DNS代理服務器.只請求本地Hosts文件.能滿足個性化需求.
2. DNS代理服務器支持多種綁定方式,如通配符,正則等
對于目前旺鋪,完全可以使用通配符,如 *.cn.alibaba.com,簡化配置工作量
3. 操作簡單
只要將DNS服務器設置成DNS代理服務器IP即可 (附錄中有詳細說明)
4. 有效利用現有成果
目前測試同學已經集中維護了Hosts綁定信息,只要部署DNS代理服務器,并做簡單的集成即可
5. DNS代理服務器代碼輕量小巧,易于修改擴展
目前一共只有212行代碼,其中DNS協議部分130行,DNS代理部分82行.
附錄
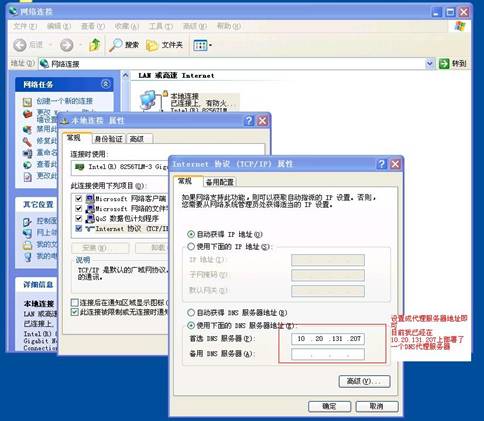
I. 客戶端如何設置DNS服務器
Windows用戶,見圖:
Linux用戶,見圖:
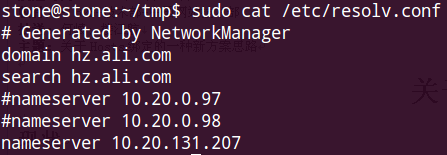
修改 /etc/resolv.conf文件即可
前言
此文摘自2011年3月22日郵件分享
現狀
平時開發,測試,功能預演階段,為了能夠正常訪問應用,需要做Hosts綁定.隨著應用數量的不斷增多,綁定量也是急劇上升.例如最近工作平臺三期項目,需要綁定的環境多達44個.一旦有變動,需要通知所有人員做本地Hosts的調整,維護成本那是相當地大.
用一張圖,來描述下目前我們的方案:
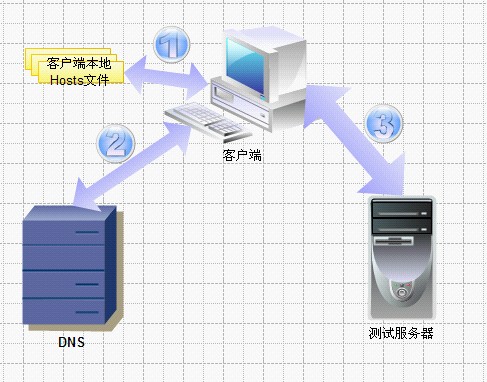
如果站在面向對象編程的角度,來思考這張圖,我們會發現.
1. 利用客戶端本地Hosts綁定來實現,并且客戶端數量不可控—利用客戶端解決需求,但客戶端維護不在可控范圍內
2. Hosts綁定是非常不穩定的—需求易變
這樣的設計,違反了”封裝變化”的設計原則,故一旦有變動,維護成本非常大.
新方案思路
按照”封裝變化”的設計原則,我們就應該把”域名綁定”這個易變需求,進行統一管理.
看上圖,我們會發現,DNS的職責就是做域名解析的,并且DNS管理比較可控.
于是第一反應,我們可以使用內部域名解析服務器來綁定這些域名.
但是問題又來了,DNS來做測試環境域名解析,太重量級了.同一個域名,對應測試服務器IP有多個,綁定哪一個好呢?并且域名對應IP不斷變化,IT DNS負責人不被我們累死啊?
既然DNS上做文章不可行,又需要統一管理的地方,那么我們只能再抽象出一個新的概念來.
同樣,我們利用一張圖,來描述下整體架構.
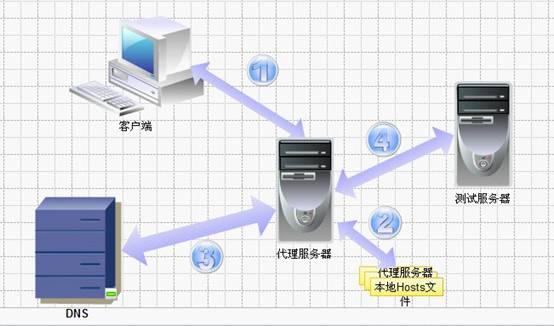
與上圖相對,此圖多了一個”代理服務器”的概念,即Hosts綁定動作在此概念上完成.
流程如下:
1. 客戶端瀏覽器設置代理服務器,將所有請求發送到代理服務器上
2. 代理服務器檢查本地Hosts綁定,如綁定則直接解析,反之進入流程3
3. 代理服務器通過內部域名服務器解析域名
4. 代理服務器發送請求到測試服務器上,并且將響應內容返回給客戶端
具體嘗試性實施方案如下(在XX項目過程中有成功案例)
1. 利用squid搭建代理服務器 (代理地址: 10.20.131.207:3128)
備注:
Squid配置介紹見附錄I
2. 瀏覽器配置代理
全局代理: 代理服務器上,直接填寫 10.20.131.207 3128
局部代理: 通過pac實現,選擇”使用自動配置腳本”,腳本格式內容如下:
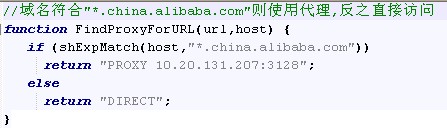
備注:
Pac腳本詳細介紹見附錄II
為了防止將配置工作帶給PD,銷售等,我們可以使用配置好的綠色瀏覽器提供直接使用.
推薦一款:GreenBrowser: http://www.morequick.com/indexen.htm
IE具體配置,見下圖:

Firefox同樣支持代理和pac腳本
Chrome需要安裝proxy switchy插件來支持.
改進方案思路
上述的方案中,有兩個比較大的缺陷
1. 代理服務器沒有多實例概念
代理服務器通過hosts綁定.hosts是全局性的,意味著一臺代理服務器只能服務一組需求.而事實上,我們不同的項目需要的綁定都是不一樣的.
2. 特性化需求不能滿足
綁定全在代理服務器上做了,客戶端本地個性化需求無法支持
所以,我理想中整體架構是這樣的,見圖:
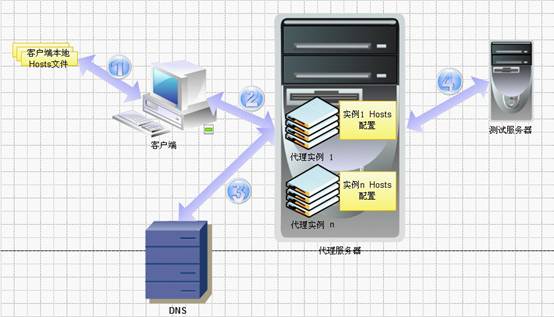
1. 優先查看本地hosts文件
2. 代理服務器支持多實例部署,不同實例有不同的hosts綁定配置.
目前具體實現方案,還在構思中.歡迎大家提供實現方案思路.
附錄I
Squid權威指南(中文版): http://home.arcor.de/pangj/squid/chap01.html
附錄II
Pac介紹: http://en.wikipedia.org/wiki/Proxy_auto-config
Pac函數介紹: http://findproxyforurl.com/pac_functions_explained.html
前段時間替朋友做了一個物業管理系統,使用了python+django技術,對django有了一些了解。
作為一個一直來使用java的人來說,初次使用django,真正體會到了簡單美學。(一共13個功能,不到500行代碼)
此文,主要總結下django框架的一些擴展點:
MIDDLEWARE_CLASSES
在request請求之前,或者response請求之后,做攔截,允許自定義邏輯。有些類似J2EE Servlet中的Filter概念。
TEMPLATE_CONTEXT_PROCESSORS
進入模板渲染之前,允許放入一組用于模板渲染的Key-Value屬性。
TEMPLATE FILTER
模板中的管道語法,通過自定義行為,添加用于顯示的一些邏輯。
TEMPLATE TAG
模板tag,添加一組行為。有些類似Velocity中的ToolSet功能。
模板tag+指定模板,充當頁面組件(widgets)功能
middleware演示
1 from django.db import connection
2 from django.http import HttpResponseRedirect
3
4 #攔截response請求之后,打印請求中的所有sql
5 class SqlLogMiddleware(object):
6 def process_response(self, req, res):
7 for sql in connection.queries:
8 print sql
9 return res
10
11 #攔截request請求之前,做權限校驗
12 class Auth(object):
13 def process_request(self, req):
14 if req.path == '/admin/':
15 return
16 if not req.user.is_authenticated():
17 return HttpResponseRedirect('/admin/')
18
1 MIDDLEWARE_CLASSES = (
2 'django.middleware.common.CommonMiddleware',
3 'django.contrib.sessions.middleware.SessionMiddleware',
4 'django.contrib.auth.middleware.AuthenticationMiddleware',
5 'finance.middleware.SqlLogMiddleware',
6 'finance.middleware.Auth',
7 )
template context processor演示
1 def version(request):
2 return {'name':'Stone.J',
3 'version':'1.0-beata',
4 'date':'2011-03-20'}
1 TEMPLATE_CONTEXT_PROCESSORS = (
2 'django.core.context_processors.request',
3 'django.core.context_processors.auth',
4 'django.core.context_processors.debug',
5 'django.core.context_processors.i18n',
6 'django.core.context_processors.media',
7 'finance.example.context_processors.version',
8 )
template filter演示
1 def row(value):
2 if not value:
3 return 'row1'
4 if value % 2 == 1:
5 return 'row1'
6 else:
7 return 'row2'
8
9 def math_mul(value, num):
10 return value * num
11
12 def math_add(value, num):
13 return value + num
14
15 register = template.Library()
16 register.filter('row', row)
17 register.filter('math_add', math_add)
18 register.filter('math_mul', math_mul)
1 {% load my_filter %}
2 {% for c in page.object_list %}
3 <tr class="{{ forloop.counter|row }}">
4 <td>{{ c.amount | math_add:c.amount2}}</td>
5 <td>{{ c.amount | math_mul:12}}</td>
6 </tr>
7 {% endfor %}
通過約定的方式,在任意一個app下,建立一個templatetags目錄,會自動尋找到。(不過沒有命名空間,是一個比較猥瑣的事情,容易造成不同app下的沖突)
template tag演示
1 register = template.Library()
2
3 class AccountNode(template.Node):
4 def __init__(self, name):
5 self.name = name
6
7 def render(self, context):
8 context[self.name] = Account.objects.get()
9 return ''
10
11 def get_account(parser, token):
12 try:
13 tag_name, name = token.split_contents()
14 except ValueError:
15 raise template.TemplateSyntaxError, "%s tag requires argument" % tag_name
16 return AccountNode(name)
17
18 register.tag('get_account', get_account)
1 {% load my_tag %}
2 {% get_account account %}<!-- 通過tag取到內容賦值給account變量 -->
3 {{ account.amount }}
template tag + template file演示
1 from django import template
2 register = template.Library()
3
4 def version(context):
5 return {'name':'Stone.J',
6 'version':'1.0-beata',
7 'date':'2011-03-20'}
8
9 register.inclusion_tag('example/version.html', takes_context=True)(version)
1 <!-- 這份內容可以被當成widget復用 -->
2 <table>
3 <tr>
4 <td>{{ name }}</td>
5 <td>{{ version }}</td>
6 <td>{{ data }}</td>
7 </tr>
8 </table>
9
tag尋找模式等同于filter。
接上文,繼續show下我命令行下的工具--翻譯腳本
(利用了google 翻譯 json api:
http://translate.google.cn/translate_a/t?client=t&text=%s&hl=zh-CN&sl=%s&tl=%s)
特性:
1. 自動識別中翻英/英翻中
2. 翻譯
涉及技術:
1. python
2. urllib
3. json
4. re
截圖:
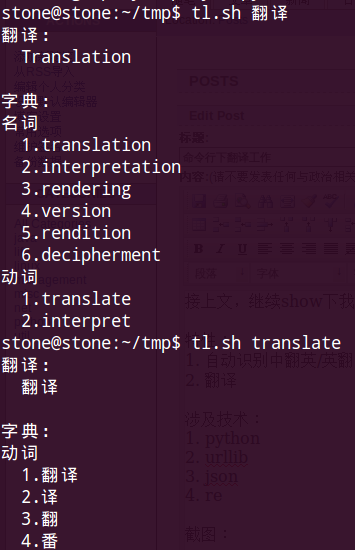
對應代碼:
1 '''
2 Created on 2010-11-28
3
4 @author: stone
5 '''
6 import json
7 import re
8 import sys
9 import urllib2
10 import types
11
12 res = 'http://translate.google.cn/translate_a/t?client=t&text=%s&hl=zh-CN&sl=%s&tl=%s'
13 agent = 'Mozilla / 5.0 (X11; U; Linux i686; en - US) AppleWebKit / 534.7 (KHTML, like Gecko) Chrome / 7.0.517.44 Safari / 534.7'
14
15 def get_data(text, sl='en', tl='zh-CN'):
16 req = urllib2.Request(res % (urllib2.quote(text), sl, tl))
17 req.add_header('user-agent', agent)
18 content = urllib2.urlopen(req).read()
19 return json.loads(to_standard_json(content))
20
21 def show(data):
22 #step1
23 print u'翻譯:\n %s' % (data[4][0][0])
24 #step2
25 if types.ListType == type(data[1]):
26 print u'\n字典:'
27 for word in data[1]:
28 print word[0]
29 if len(word) > 1:
30 for i, w in enumerate(word[1]):
31 print ' %s.%s' % (i + 1, w)
32
33 def to_standard_json(json):
34 p = re.compile(r',([,\]])')
35 while(p.search(json)):
36 json = p.sub(lambda m:',null%s' % (m.group(1)), json)
37 return json
38
39 def contains_cn(text):
40 for c in text:
41 if ord(c) > 127:
42 return True
43 return False
44
45 if __name__ == '__main__':
46 if not len(sys.argv) == 2 or not sys.argv[1].strip():
47 print 'Useage:translate.py word'
48 sys.exit()
49 word = sys.argv[1].strip()
50 if contains_cn(word):
51 show(get_data(word, 'zh-CN', 'en'))
52 else:
53 show(get_data(word, 'en', 'zh-CN'))
按照同事的話說,我是一個十足的命令控。
利用最近項目通宵發布的空閑時間中,寫了一個命令行下的音樂播放器,以滿足我在linux命令下的需求。
播放器利用技術:
Python+GST(
http://gstreamer.freedesktop.org/modules/gst-python.html)+Console解析
播放器自持操作:
1. 播放
2. 下一首
3. 上一首
4. 暫停
5. 查看播放列表信息
6. 查看當前播放信息
7. 停止(退出)
看一張截圖:
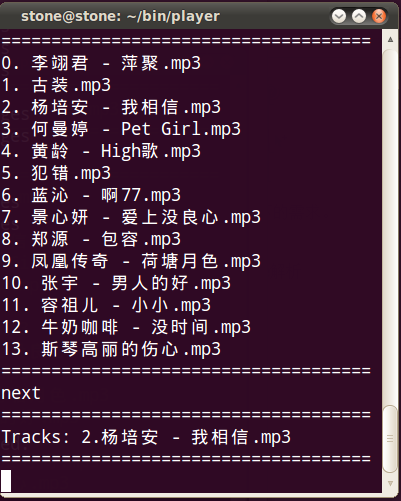
通過分析meliae dump出來的內存信息,差不做占用2.5M內存,算的上比較小巧了。
對應代碼:(需要安裝py-gst,ubuntu下:sudo apt-get install python-gst0.10)
1 #!/usr/bin/env python
2
3 import gst
4 import gobject
5 import sys
6 #to avoid eclipse'warning
7 eval('gobject.threads_init()')
8 from threading import Thread
9
10 class AudioPlayer:
11
12 EVENT_PLAY_NEW = 1
13
14 def __init__(self, advisor):
15 self.main = gobject.MainLoop()
16 self.player = gst.element_factory_make('playbin', 'player')
17 self.index = -1
18 self.list = None
19 self.advisor = advisor
20
21 bus = self.player.get_bus()
22 bus.add_signal_watch()
23 bus.connect('message', self.on_message)
24
25 Thread(target=self.main.run).start()
26
27 def add_list(self , list=[]):
28 if list is None:
29 list = []
30 self.list = [(i, l.strip(), l[l.rfind('/') + 1:]) for (i, l) in enumerate(list)]
31
32 def play(self, index=None):
33 #play specified tracks
34 if 0 <= index < len(self.list):
35 self.index = index
36 self.player.set_state(gst.STATE_NULL)
37 self.player.set_property('uri', self.list[index][1])
38 self.player.set_state(gst.STATE_PLAYING)
39 if self.advisor:
40 self.advisor.on_message(AudioPlayer.EVENT_PLAY_NEW, (self.index, self.get_title()))
41 #resume playing
42 if index is None:
43 if self.index > -1:
44 self.player.set_state(gst.STATE_PLAYING)
45
46 def pause(self):
47 self.player.set_state(gst.STATE_PAUSED)
48
49 def stop(self):
50 self.player.set_state(gst.STATE_NULL)
51 self.main.quit()
52
53 def get_title(self):
54 if self.index == -1 or len(self.list) == 0:
55 return None
56 return self.list[self.index][2]
57
58 def get_previous(self):
59 if self.index == -1 or len(self.list) == 0:
60 return - 1
61 if self.index == 0:
62 return 0
63 return self.index - 1
64
65 def get_next(self):
66 if len(self.list) == 0:
67 return - 1
68 if self.index + 1 == len(self.list):
69 return 0
70 return self.index + 1
71
72 def on_message(self, bus, message):
73 t = message.type
74 if t == gst.MESSAGE_ERROR:
75 self.play(self.get_next())
76 elif t == gst.MESSAGE_EOS:
77 self.play(self.get_next())
78
79 class Console:
80
81 def __init__(self, list):
82 self.player = AudioPlayer(self)
83 self.player.add_list(list)
84 self.player.play(0)
85
86 Thread(target=self.run).start()
87
88 def run(self):
89 while(True):
90 self.on_cmd(raw_input())
91
92 def on_cmd(self, cmd):
93 if cmd is None:
94 return
95 if cmd.startswith('play'):
96 self.player.play()
97 elif cmd.startswith('next'):
98 self.player.play(self.player.get_next())
99 elif cmd.startswith('previous'):
100 self.player.play(self.player.get_previous())
101 elif cmd.startswith('pause'):
102 self.player.pause()
103 elif cmd.startswith('list'):
104 print '====================================='
105 for info in self.player.list:
106 print '%s. %s' % (info[0], info[2])
107 print '====================================='
108 elif cmd.startswith('info'):
109 print '====================================='
110 print '%s. %s' % (self.player.index, self.player.get_title())
111 print '====================================='
112 elif cmd.startswith('stop'):
113 self.player.stop()
114 sys.exit(0)
115 elif cmd.startswith('dump'):
116 from meliae import scanner
117 scanner.dump_all_objects('./dump.txt')
118 else:
119 print '''=====================================
120 Usage:
121 play
122 next
123 previous
124 pause
125 list
126 info
127 stop
128 dump
129 ====================================='''
130
131 def on_message(self, event, info):
132 if event == AudioPlayer.EVENT_PLAY_NEW:
133 print '====================================='
134 print 'Tracks: %s.%s' % (info[0], info[1])
135 print '====================================='
136
137
138 if len(sys.argv) != 2:
139 print 'player.py mp3.list'
140 sys.exit(-1)
141 list = [l.strip() for l in open(sys.argv[1]).readlines() if l.strip() != '']
142 Console(list)
下載
推薦一個eclipse插件--全屏插件(顯示器整個屏幕)。
發覺這個東東還是挺不錯的,尤其對于本本的同學,特別實用。
在我自己的本本上,發現一旦使用全屏,能多顯示8行代碼,多了21%左右,挺可觀的。
插件地址:http://code.google.com/p/eclipse-fullscreen/
給個圖:
HttpClient使用過程中的安全隱患,這個有些標題黨。因為這本身不是HttpClient的問題,而是使用者的問題。
安全隱患場景說明:
一旦請求大數據資源,則HttpClient線程會被長時間占有。即便調用了org.apache.commons.httpclient.HttpMethod#releaseConnection()方法,也無濟于事。
如果請求的資源是應用可控的,那么不存在任何問題。可是恰恰我們應用的使用場景是,請求資源由用戶自行輸入,于是乎,我們不得不重視這個問題。
我們跟蹤releaseConnection代碼發現:
org.apache.commons.httpclient.HttpMethodBase#releaseConnection()
1 public void releaseConnection() {
2 try {
3 if (this.responseStream != null) {
4 try {
5 // FYI - this may indirectly invoke responseBodyConsumed.
6 this.responseStream.close();
7 } catch (IOException ignore) {
8 }
9 }
10 } finally {
11 ensureConnectionRelease();
12 }
13 }
org.apache.commons.httpclient.ChunkedInputStream#close()
1 public void close() throws IOException {
2 if (!closed) {
3 try {
4 if (!eof) {
5 exhaustInputStream(this);
6 }
7 } finally {
8 eof = true;
9 closed = true;
10 }
11 }
12 }
org.apache.commons.httpclient.ChunkedInputStream#exhaustInputStream(InputStream inStream)
1 static void exhaustInputStream(InputStream inStream) throws IOException {
2 // read and discard the remainder of the message
3 byte buffer[] = new byte[1024];
4 while (inStream.read(buffer) >= 0) {
5 ;
6 }
7 }
看到了吧,所謂的丟棄response,其實是讀完了一次請求的response,只是不做任何處理罷了。
想想也是,HttpClient的設計理念是重復使用HttpConnection,豈能輕易被強制close呢。
怎么辦?有朋友說,不是有time out設置嘛,設置下就可以下。
我先來解釋下Httpclient中兩個time out的概念:
1.public static final String CONNECTION_TIMEOUT = "http.connection.timeout";
即創建socket連接的超時時間:java.net.Socket#connect(SocketAddress endpoint, int timeout)中的timeout
2.public static final String SO_TIMEOUT = "http.socket.timeout";
即read data過程中,等待數據的timeout:java.net.Socket#setSoTimeout(int timeout)中的timeout
而在我上面場景中,這兩個timeout都不滿足,確實是由于資源過大,而占用了大量的請求時間。
問題總是要解決的,解決思路如下:
1.利用DelayQueue,管理所有請求
2.利用一個異步線程監控,關閉超長時間的請求
演示代碼如下:
1 public class Misc2 {
2
3 private static final DelayQueue<Timeout> TIMEOUT_QUEUE = new DelayQueue<Timeout>();
4
5 public static void main(String[] args) throws Exception {
6 new Monitor().start(); // 超時監控線程
7
8 new Request(4).start();// 模擬第一個下載
9 new Request(3).start();// 模擬第二個下載
10 new Request(2).start();// 模擬第三個下載
11 }
12
13 /**
14 * 模擬一次HttpClient請求
15 *
16 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> 2011-4-9
17 */
18 public static class Request extends Thread {
19
20 private long delay;
21
22 public Request(long delay){
23 this.delay = delay;
24 }
25
26 public void run() {
27 HttpClient hc = new HttpClient();
28 GetMethod req = new GetMethod("http://www.python.org/ftp/python/2.7.1/Python-2.7.1.tgz");
29 try {
30 TIMEOUT_QUEUE.offer(new Timeout(delay * 1000, hc.getHttpConnectionManager()));
31 hc.executeMethod(req);
32 } catch (Exception e) {
33 System.out.println(e);
34 }
35 req.releaseConnection();
36 }
37
38 }
39
40 /**
41 * 監工:監控線程,通過DelayQueue,阻塞得到最近超時的對象,強制關閉
42 *
43 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> 2011-4-9
44 */
45 public static class Monitor extends Thread {
46
47 @Override
48 public void run() {
49 while (true) {
50 try {
51 Timeout timeout = TIMEOUT_QUEUE.take();
52 timeout.forceClose();
53 } catch (InterruptedException e) {
54 System.out.println(e);
55 }
56 }
57 }
58
59 }
60
61 /**
62 * 使用delay queue,對Delayed接口的實現 根據請求當前時間+該請求允許timeout時間,和當前時間比較,判斷是否已經超時
63 *
64 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> 2011-4-9
65 */
66 public static class Timeout implements Delayed {
67
68 private long debut;
69 private long delay;
70 private HttpConnectionManager manager;
71
72 public Timeout(long delay, HttpConnectionManager manager){
73 this.debut = System.currentTimeMillis();
74 this.delay = delay;
75 this.manager = manager;
76 }
77
78 public void forceClose() {
79 System.out.println(this.debut + ":" + this.delay);
80 if (manager instanceof SimpleHttpConnectionManager) {
81 ((SimpleHttpConnectionManager) manager).shutdown();
82 }
83 if (manager instanceof MultiThreadedHttpConnectionManager) {
84 ((MultiThreadedHttpConnectionManager) manager).shutdown();
85 }
86 }
87
88 @Override
89 public int compareTo(Delayed o) {
90 if (o instanceof Timeout) {
91 Timeout timeout = (Timeout) o;
92 if (this.debut + this.delay == timeout.debut + timeout.delay) {
93 return 0;
94 } else if (this.debut + this.delay > timeout.debut + timeout.delay) {
95 return 1;
96 } else {
97 return -1;
98 }
99 }
100 return 0;
101 }
102
103 @Override
104 public long getDelay(TimeUnit unit) {
105 return debut + delay - System.currentTimeMillis();
106 }
107
108 }
109
110 }
本來還想詳細講下DelayQueue,但是發現同事已經有比較纖細的描述,就加個鏈接吧 (人懶,沒辦法)
http://agapple.iteye.com/blog/916837
http://agapple.iteye.com/blog/947133
備注:
HttpClient3.1中,SimpleHttpConnectionManager才有shutdown方法,3.0.1中還存在 :)
最近的項目中,使用到了HtmlParser(1.5版本).在使用過程中(如訪問url為:
http://athena2002.vip.china.alibaba.com/
),遇到了異常:
Exception in thread "main" java.lang.IllegalArgumentException: invalid cookie name: Discard
at org.htmlparser.http.Cookie.<init>(Cookie.java:136)
at org.htmlparser.http.ConnectionManager.parseCookies(ConnectionManager.java:1126)
at org.htmlparser.http.ConnectionManager.openConnection(ConnectionManager.java:621)
at org.htmlparser.http.ConnectionManager.openConnection(ConnectionManager.java:792)
at org.htmlparser.Parser.<init>(Parser.java:251)
at org.htmlparser.Parser.<init>(Parser.java:261)
檢查代碼,發現:
org.htmlparser.http.Cookie
1 public Cookie (String name, String value)
2 {
3 if (!isToken (name) || name.equalsIgnoreCase ("Comment") // rfc2019
4 || name.equalsIgnoreCase ("Discard") // 2019++
5 || name.equalsIgnoreCase ("Domain")
6 || name.equalsIgnoreCase ("Expires") // (old cookies)
7 || name.equalsIgnoreCase ("Max-Age") // rfc2019
8 || name.equalsIgnoreCase ("Path")
9 || name.equalsIgnoreCase ("Secure")
10 || name.equalsIgnoreCase ("Version"))
11 throw new IllegalArgumentException ("invalid cookie name: " + name);
12 mName = name;
13 mValue = value;
14 mComment = null;
15 mDomain = null;
16 mExpiry = null; // not persisted
17 mPath = "/";
18 mSecure = false;
19 mVersion = 0;
20 }
一旦發現name值為“Discard”,則拋異常。
而在org.htmlparser.http.ConnectionManager.parseCookies (URLConnection connection) 解析cookie的代碼中,見代碼片段
if (key.equals ("domain"))
cookie.setDomain (value);
else
if (key.equals ("path"))
cookie.setPath (value);
else
if (key.equals ("secure"))
cookie.setSecure (true);
else
if (key.equals ("comment"))
cookie.setComment (value);
else
if (key.equals ("version"))
cookie.setVersion (Integer.parseInt (value));
else
if (key.equals ("max-age"))
{
Date date = new Date ();
long then = date.getTime () + Integer.parseInt (value) * 1000;
date.setTime (then);
cookie.setExpiryDate (date);
}
else
{ // error,? unknown attribute,
// maybe just another cookie not separated by a comma
cookie = new Cookie (name, value); //出問題的地方
cookies.addElement (cookie);
}
沒有對Discard做特殊處理。
無奈之下,覆寫了此方法,加上對Discard的處理--直接continue :)
今天在寫blog的時候,拿了1.6的代碼測試,發現沒有問題,分析代碼后發現
1. ConnectionManager parserCookie之前,加了條件判斷
if (getCookieProcessingEnabled ())
parseCookies (ret);
默認情況下,條件為false
2. parserCookie的時候,catch了異常
1 // error,? unknown attribute,
2 // maybe just another cookie
3 // not separated by a comma
4 try
5 {
6 cookie = new Cookie (name,
7 value);
8 cookies.addElement (cookie);
9 }
10 catch (IllegalArgumentException iae)
11 {
12 // should print a warning
13 // for now just bail
14 break;
15 }
雖然解決了問題,但是明顯還沒有意識到Discard的問題。
從我的理解看,最合理的解決方案是:
1. org.htmlparser.http.Cookie中添加 boolean discard方法
2. org.htmlparser.http.ConnectionManager parserCookies()方法,對Discard做處理,如有值,則設置cookie.discard=true
關于discard的解釋,見
http://www.faqs.org/rfcs/rfc2965.html:
Discard
OPTIONAL. The Discard attribute instructs the user agent to
discard the cookie unconditionally when the user agent terminates