ι΅?/span>εÖΞιî¹εQ?span class="hilite1" style="background-color: #ffff00; ">ReentrantLockεQâφ‰·δΗÄΩUçιÄ£εΫ£φ½†ι‰ΜεΓûγö³εê¨φ≠Ξφ€ΚεàΕψIJδΜΞεâçδΗÄ㦥η°ΛδΗΚε°Éφ‰·synchronizedγö³γ°Äεçïφ¦ΩδΜΘοΦ¨ηĨδΗîε°ûγéΑφ€ΚεàΕδΙüδΗçγ¦ΗεΖ°εΛΣηΩ€ψIJδΗç‰q΅φ€Ä‰qëε°ûηΖΒηΩ΅ΫE΄δΗ≠εèëγéΑε°ÉδΜ§δΙ΄ι½¥‰q‰φ‰·φ€âγùÄεΛ©εΘΛδΙ΄εàΪψÄ?/p>
δΜΞδΗ΄φ‰?a target="_blank" style="color: #006699; text-decoration: underline; ">ε°‰φ•Ιη·¥φ‰éεQöδΗÄδΗΣεè·ι΅çεÖΞγö³δΚ£φ•Ξιî¹ε°?LockεQ¨ε°ÉεÖδh€âδΗéδ΄…γî?synchronized φ•“é(gu®©)≥ï壨η·≠εèΞφâÄη°âK½°γö³ιöêεΦèγ¦ëηßÜεô®ιî¹ε°öγ¦Ηεê¨γö³δΗÄδΚ¦εüΚφ€§ηΓ¨δΗΚ壨η·≠δΙâεQ¨δΫÜεäüηÉΫφ¦¥εΦΚεΛßψÄ?span class="hilite1" style="background-color: #ffff00; ">ReentrantLock û°Üγî±φ€Ä‰qëφàêεäüηéΖεΨ½ιî¹ε°öοΦ¨ρqΕδΗî‰q‰φ≤Γφ€âι΅äφîΨη·Ξιî¹ε°öγö³γΚΩΫE΄φâÄφ΄Ξφ€âψIJεΫ™ιî¹ε°öφ≤Γφ€âηΔΪεèΠδΗÄδΗΣγΚΩΫE΄φâÄφ΄Ξφ€âφ½”ûΦ¨ηΑÉγî® lock γö³γΚΩΫE΄εΑÜφàêεäüηéΖεè•η·Ξιî¹ε°öεΤà‰qîε¦ûψIJεΠ²φû€εΫ™εâçγΚΩΫE΄εΖ≤Ψlèφ΄Ξφ€âη·Ξιî¹ε°öεQ¨φ≠Λφ•“é(gu®©)≥ïû°ÜγΪ΄εç¨ôΩîε¦ûψIJεè·δΜΞδ΄…γî?isHeldByCurrentThread() ε£?getHoldCount() φ•“é(gu®©)≥ïφùΞφΘÄφüΞφ≠ΛφÉÖεÜΒφ‰·εêΠεèëγîüψÄ?/p>
ε°ÉφèêδΨ¦δΚÜ(ji®Θn)lock()φ•“é(gu®©)≥ïεQ?br /> εΠ²φû€η·Ξιî¹ε°öφ≤Γφ€âηΔΪεèΠδΗÄδΗΣγΚΩΫE΄δΩùφ¨¹οΦ¨εàôηéΖεè•η·Ξιî¹ε°öρqΕγΪ΄εç¨ôΩîε¦ûοΦ¨û°Üιî¹ε°öγö³δΩùφ¨¹η°ΓφïΑη°³ΓΫ°δΗ?1ψÄ?br /> εΠ²φû€εΫ™εâçΨUΩγ®΄εΖ≤γΜèδΩùφ¨¹η·Ξιî¹ε°öοΦ¨εàôεΑÜδΩùφ¨¹η°ΓφïΑεä?1εQ¨εΤàδΗîη·Ξφ•“é(gu®©)≥ïγΪ΄εç≥‰qîε¦ûψÄ?br /> εΠ²φû€η·Ξιî¹ε°öηΔΪεèΠδΗÄδΗΣγΚΩΫE΄δΩùφ¨¹οΦ¨εàôε΅ΚδΚéγΚΩΫE΄ηΑÉεΚΠγö³γ¦°γö³εQ¨γΠ¹γî®εΫ™εâçγΚΩΫE΄οΦ¨ρqΕδΗîε€®ηéΖεΨ½ιî¹ε°öδΙ΄εâçοΦ¨η·ΞγΚΩΫE΄εΑÜδΗÄ㦥εΛ³δΚéδΦë〆γäΕφĹοΦ¨φ≠Λφ½Ειî¹ε°öδΩùφ¨¹η°ΓφïΑηΔΪη°ΨΨ|°δΊ™(f®¥) 1ψÄ?/p>
φ€Ä‰qëε€®γ†îγ©ΕJava concurrentδΗ≠εÖ≥δΚéδ™QεäΓηΑÉεΚΠγö³ε°ûγéΑφ½”ûΦ¨η·÷MΚÜ(ji®Θn)εΜΕηΩüι‰üεà½DelayQueueγö³δΗÄδΚ¦δΜΘγ†¹οΦ¨φ·îεΠ²take()ψIJη·Ξφ•“é(gu®©)≥ïγö³δΗΜηΠ¹εäüηÉΫφ‰·δΜéδΦ‰εÖàι‰üεà½οΦàPriorityQueueεQâεè•ε΅όZΗÄδΗΣφ€ÄεΚîη·ΞφâßηΓ¨γö³δ™QεäΓοΦàφ€ÄδΦ‰εÄϊ|Φâ(j®Σ)εQ¨εΠ²φû€η·ΞδΜ’däΓγö³ιΔ³η°ΔφâßηΓ¨φ½Ει½¥φ€ΣεàéΆΦ¨εàôι€ÄηΠ¹wait‰qôφ°Βφ½âô½¥εΖ°ψIJεèçδΙ΄οΦ¨εΠ²φû€φ½âô½¥εàνCΚÜ(ji®Θn)εQ¨εàô‰qîε¦ûη·Ξδ™QεäΓψIJηĨoffer()φ•“é(gu®©)≥ïφ‰·εΑÜδΗÄδΗΣδ™QεäΓφΖΜεä†εàΑη·Ξι‰üεà½δΗ≠ψÄ?/p>
εêéφùΞδΚßγîüδΚ?ji®Θn)δΗÄδΗΣγ•ëι½°οΦö(x®§)εΠ²φû€φ€ÄεΚîη·ΞφâßηΓ¨γö³δ™QεäΓφ‰·δΗÄδΗΣεΑèφ½ΕεêéφâßηΓ¨γö³οΦ¨ηĨφ≠Λφ½âô€ÄηΠ¹φèêδΚΛδΗÄδΗ?0ΩU£εêéφâßηΓ¨γö³δ™QεäΓοΦ¨δΦ?x®§)ε΅ΚγéνCΜÄδΙàγäΕεÜΒοΦü‰q‰φ‰·εÖà〴〴take()γö³φΚêδΜΘγ†¹εQ?/p>
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null) {
available.await();
} else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay > 0) {
long tl = available.awaitNanos(delay);
} else {
E x = q.poll();
assert x != null;
if (q.size() != 0)
available.signalAll(); // wake up other takers
return x;
}
}
}
} finally {
lock.unlock();
}
}
ηĨδΜΞδΗ΄φ‰·offer()γö³φΚêδΜΘγ†¹:
final ReentrantLock lock = this.lock;
lock.lock();
try {
E first = q.peek();
q.offer(e);
if (first == null || e.compareTo(first) < 0)
available.signalAll();
return true;
} finally {
lock.unlock();
}
}
εΠ²δΜΘγ†¹φâÄΫCΚοΦ¨take()壨offer()ιÉΫφ‰·lockδΚ?ji®Θn)ι΅çεÖΞιî¹ψIJεΠ²φû€φ¨âγÖßsynchronizedγö³φÄùγΜ¥εQàδ΄…γî®η·ΗεΠ²synchronized(obj)γö³φ•Ιφ≥ïοΦâ(j®Σ)εQ¨ηΩôδΗΛδΗΣφ•“é(gu®©)≥ïφ‰·δΚ£φ•Ξγö³ψIJε¦ûεàΑεàöφâçγö³γ•ëι½°εQ¨take()φ•“é(gu®©)≥ïι€ÄηΠ¹γ≠âεΨ?δΗΣεΑèφ½ΕφâçηÉΫηΩîε¦ûοΦ¨ηĨoffer()ι€ÄηΠ¹ι©§δΗäφèêδΚΛδΗÄδΗ?0ΩU£εêé‰qêηΓ¨γö³δ™QεäΓοΦ¨δΦ?x®§)δΗçδΦö(x®§)δΗÄ㦥γ≠âεΨÖtake()‰qîε¦ûεêéφâçηÉΫφèêδΚΛεëΔεQüγ≠îφΓàφ‰·εêΠε°öγö³οΦ¨ιÄöηΩ΅Ψ~•εÜôιΣ¨η·¹δΜΘγ†¹δΙüη·¥φ‰éδΚÜ(ji®Θn)‰qôδΗÄγ²èVIJηΩôη°©φàëε·öw΅çεÖΞιî¹φ€âδΚÜ(ji®Θn)φ¦¥εΛßγö³εÖ¥≠ëΘοΦ¨ε°ÉγΓ°ε°ûφ‰·δΗÄδΗΣφ½†ι‰’dΓûγö³ιî¹ψÄ?/p>
δΗ΄ιùΔγö³δΜΘγ†¹δΙüη°ΗηÉΫη·¥φ‰éι½°ιΔ‰εQöηΩêηΓ¨δΚÜ(ji®Θn)4δΗΣγΚΩΫE΄οΦ¨φ·èδΗÄ΄ΤΓηΩêηΓ¨εâçφâ™εçΑl(f®Γ)ockγö³εΫ™εâçγäΕφĹψIJηΩêηΓ¨εêéιÉΫηΠ¹Ϋ{âεΨÖ5ΩU£ι£üψÄ?/p>
final ExecutorService exec = Executors.newFixedThreadPool(4);
final ReentrantLock lock = new ReentrantLock();
final Condition con = lock.newCondition();
final int time = 5;
final Runnable add = new Runnable() {
public void run() {
System.out.println("Pre " + lock);
lock.lock();
try {
con.await(time, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("Post " + lock.toString());
lock.unlock();
}
}
};
for(int index = 0; index < 4; index++)
exec.submit(add);
exec.shutdown();
}
‰qôφ‰·ε°Éγö³ηΨ™ε΅ΚεQ?br />
Pre ReentrantLock@a59698[Unlocked] φ·èδΗÄδΗΣγΚΩΫE΄γö³ιî¹γäΕφĹιÉΫφ‰?#8220;Unlocked”,φâÄδΜΞιÉΫεè·δΜΞ‰qêηΓ¨ψIJδΫÜε€®φääcon.awaitφî“é(gu®©)àêThread.sleep(5000)φ½”ûΦ¨ηΨ™ε΅Κû°±εè‰φàêδΚÜ(ji®Θn)εQ?br />
Pre ReentrantLock@a59698[Unlocked] δΜΞδΗäγö³ε·Ιφ·îη·¥φ‰éγΚΩΫE΄ε€®Ϋ{âεΨÖφ½?con.await)εQ¨εΖ≤ΨlèδΗçε€®φ΄Ξφ€âοΦàkeepεQâη·Ξιî¹δΚÜ(ji®Θn)εQ¨φâÄδΜΞεÖΕδΜ•γΚΩΫE΄εΑ±εè·δΜΞηéΖεΨ½ι΅çεÖΞιî¹δΚÜ(ji®Θn)ψÄ?br />
φ€âεΩÖηΠ¹δΦö(x®§)‰q΅εΛ¥εÜç〴〴Javaε°‰φ•Ιγö³ηßΘι΅äοΦö(x®§)“εΠ²φû€η·Ξιî¹ε°öηΔΪεèΠδΗÄδΗΣγΚΩΫE΄δΩùφ¨¹οΦ¨εàôε΅ΚδΚéγΚΩΫE΄ηΑÉεΚΠγö³γ¦°γö³εQ¨γΠ¹γî®εΫ™εâçγΚΩΫE΄οΦ¨ρqΕδΗîε€®ηéΖεΨ½ιî¹ε°öδΙ΄εâçοΦ¨η·ΞγΚΩΫE΄εΑÜδΗÄ㦥εΛ³δΚéδΦë〆γäΕφÄ?#8221;ψIJφàëε·ΙηΩô顨γö³“δΩùφ¨¹”γö³γêÜηßΘφ‰·φ¨΅ιùûwaitγäΕφĹεΛ•γö³φâÄφ€âγäΕφĹοΦ¨φ·îεΠ²ΨUΩγ®΄SleepψĹforεΨΣγé·Ϋ{âδΗÄεà΅φ€âCPUεè²δΗéγö³φ¥Μεä®ψIJδΗÄφ½ΠγΚΩΫE΄ηΩ¦εÖΞwaitγäΕφĹεêéεQ¨ε°É?y®≠u)°ΉÉΗçεÜçkeep‰qôδΗΣιî¹δΚÜ(ji®Θn)εQ¨εÖΕδΜ•γΚΩΫE΄εΑ±εè·δΜΞηéΖεΨ½η·Ξιî¹εQ¦εΫ™η·ΞγΚΩΫE΄ηΔΪεîΛιÜ£εQàηßΠεèëδΩΓεèδhà•ηÄÖtimeoutεQâεêéεQ¨εΑ±φéΞγùÄφâßηΓ¨εQ¨δΦö(x®§)ι΅çφ•Α“δΩùφ¨¹”ιî¹οΦ¨εΫ™γ³ΕεâçφèêδΨùγ³Εφ‰·εÖΕδΜ•γΚΩΫE΄εΖ≤ΨlèδΗçεÜ?#8220;δΩùφ¨¹”δΚ?ji®Θn)η·Ξι΅çεÖΞιî¹ψÄ?/p>
φÄ»ùΜ™δΗÄεèΞη·ùεQöε·ΙδΚéι΅çεÖΞιî¹ηĨη®ÄεQ?lock"ε£?keep"φ‰·δΗΛδΗΣδΗçεê¨γö³φΠ²εΩΒψIJlockδΚ?ji®Θn)ιî¹εQ¨δΗçδΗÄε°ökeepιî¹οΦ¨δΫÜkeepδΚ?ji®Θn)ιî¹δΗÄε°öεΖ≤ΨlèlockδΚ?ji®Θn)ιî¹ψÄ?/p>
Pre ReentrantLock@a59698[Unlocked]
Pre ReentrantLock@a59698[Unlocked]
Pre ReentrantLock@a59698[Unlocked]
Post ReentrantLock@a59698[Locked by thread pool-1-thread-1]
Post ReentrantLock@a59698[Locked by thread pool-1-thread-2]
Post ReentrantLock@a59698[Locked by thread pool-1-thread-3]
Post ReentrantLock@a59698[Locked by thread pool-1-thread-4]
Pre ReentrantLock@a59698[Locked by thread pool-1-thread-1]
Pre ReentrantLock@a59698[Locked by thread pool-1-thread-1]
Pre ReentrantLock@a59698[Locked by thread pool-1-thread-1]
Post ReentrantLock@a59698[Locked by thread pool-1-thread-1]
Post ReentrantLock@a59698[Locked by thread pool-1-thread-2]
Post ReentrantLock@a59698[Locked by thread pool-1-thread-3]
Post ReentrantLock@a59698[Locked by thread pool-1-thread-4]
For information about ongoing work on the memory model, see Bill Pugh's Java Memory Model pages.
Consider the tiny class, defined without any synchronization:
final class SetCheck {
private int a = 0;
private long b = 0;
void set() {
a = 1;
b = -1;
}
boolean check() {
return ((b == 0) ||
(b == -1 && a == 1));
}
}
In a purely sequential language, the method check could never return false. This holds even though compilers, run-time systems, and hardware might process this code in a way that you might not intuitively expect. For example, any of the following might apply to the execution of method set:
- The compiler may rearrange the order of the statements, so b may be assigned before a. If the method is inlined, the compiler may further rearrange the orders with respect to yet other statements.
- The processor may rearrange the execution order of machine instructions corresponding to the statements, or even execute them at the same time.
- The memory system (as governed by cache control units) may rearrange the order in which writes are committed to memory cells corresponding to the variables. These writes may overlap with other computations and memory actions.
- The compiler, processor, and/or memory system may interleave the machine-level effects of the two statements. For example on a 32-bit machine, the high-order word of b may be written first, followed by the write to a, followed by the write to the low-order word of b.
- The compiler, processor, and/or memory system may cause the memory cells representing the variables not to be updated until sometime after (if ever) a subsequent check is called, but instead to maintain the corresponding values (for example in CPU registers) in such a way that the code still has the intended effect.
Things are different in concurrent programming. Here, it is entirely possible for check to be called in one thread while set is being executed in another, in which case the check might be "spying" on the optimized execution of set. And if any of the above manipulations occur, it is possible for check to return false. For example, as detailed below, check could read a value for the long b that is neither 0 nor -1, but instead a half-written in-between value. Also, out-of-order execution of the statements in set may cause check to read b as -1 but then read a as still 0.
In other words, not only may concurrent executions be interleaved, but they may also be reordered and otherwise manipulated in an optimized form that bears little resemblance to their source code. As compiler and run-time technology matures and multiprocessors become more prevalent, such phenomena become more common. They can lead to surprising results for programmers with backgrounds in sequential programming (in other words, just about all programmers) who have never been exposed to the underlying execution properties of allegedly sequential code. This can be the source of subtle concurrent programming errors.
In almost all cases, there is an obvious, simple way to avoid contemplation of all the complexities arising in concurrent programs due to optimized execution mechanics: Use synchronization. For example, if both methods in class SetCheck are declared as synchronized, then you can be sure that no internal processing details can affect the intended outcome of this code.
But sometimes you cannot or do not want to use synchronization. Or perhaps you must reason about someone else's code that does not use it. In these cases you must rely on the minimal guarantees about resulting semantics spelled out by the Java Memory Model. This model allows the kinds of manipulations listed above, but bounds their potential effects on execution semantics and additionally points to some techniques programmers can use to control some aspects of these semantics (most of which are discussed in εK?).
The Java Memory Model is part of The JavaTM Language Specification, described primarily in JLS chapter 17. Here, we discuss only the basic motivation, properties, and programming consequences of the model. The treatment here reflects a few clarifications and updates that are missing from the first edition of JLS.
The assumptions underlying the model can be viewed as an idealization of a standard SMP machine of the sort described in εK?.4:
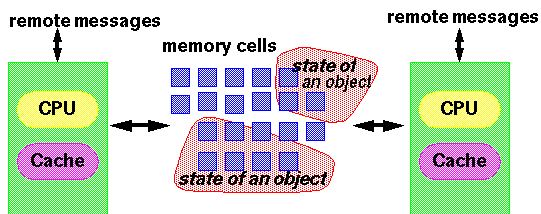
For purposes of the model, every thread can be thought of as running on a different CPU from any other thread. Even on multiprocessors, this is infrequent in practice, but the fact that this CPU-per-thread mapping is among the legal ways to implement threads accounts for some of the model's initially surprising properties. For example, because CPUs hold registers that cannot be directly accessed by other CPUs, the model must allow for cases in which one thread does not know about values being manipulated by another thread. However, the impact of the model is by no means restricted to multiprocessors. The actions of compilers and processors can lead to identical concerns even on single-CPU systems.
The model does not specifically address whether the kinds of execution tactics discussed above are performed by compilers, CPUs, cache controllers, or any other mechanism. It does not even discuss them in terms of classes, objects, and methods familiar to programmers. Instead, the model defines an abstract relation between threads and main memory. Every thread is defined to have a working memory (an abstraction of caches and registers) in which to store values. The model guarantees a few properties surrounding the interactions of instruction sequences corresponding to methods and memory cells corresponding to fields. Most rules are phrased in terms of when values must be transferred between the main memory and per-thread working memory. The rules address three intertwined issues:
- Atomicity
- Which instructions must have indivisible effects. For purposes of the model, these rules need to be stated only for simple reads and writes of memory cells representing fields - instance and static variables, also including array elements, but not including local variables inside methods.
- Visibility
- Under what conditions the effects of one thread are visible to another. The effects of interest here are writes to fields, as seen via reads of those fields.
- Ordering
- Under what conditions the effects of operations can appear out of order to any given thread. The main ordering issues surround reads and writes associated with sequences of assignment statements.
When synchronization is not used or is used inconsistently, answers become more complex. The guarantees made by the memory model are weaker than most programmers intuitively expect, and are also weaker than those typically provided on any given JVM implementation. This imposes additional obligations on programmers attempting to ensure the object consistency relations that lie at the heart of exclusion practices: Objects must maintain invariants as seen by all threads that rely on them, not just by the thread performing any given state modification.
The most important rules and properties specified by the model are discussed below.
Atomicity
Accesses and updates to the memory cells corresponding to fields of any type except long or double are guaranteed to be atomic. This includes fields serving as references to other objects. Additionally, atomicity extends to volatile long and double. (Even though non-volatile longs and doubles are not guaranteed atomic, they are of course allowed to be.)Atomicity guarantees ensure that when a non-long/double field is used in an expression, you will obtain either its initial value or some value that was written by some thread, but not some jumble of bits resulting from two or more threads both trying to write values at the same time. However, as seen below, atomicity alone does not guarantee that you will get the value most recently written by any thread. For this reason, atomicity guarantees per se normally have little impact on concurrent program design.
Visibility
Changes to fields made by one thread are guaranteed to be visible to other threads only under the following conditions:- A writing thread releases a synchronization lock and a reading thread subsequently acquires that same synchronization lock.
In essence, releasing a lock forces a flush of all writes from working memory employed by the thread, and acquiring a lock forces a (re)load of the values of accessible fields. While lock actions provide exclusion only for the operations performed within a synchronized method or block, these memory effects are defined to cover all fields used by the thread performing the action.
Note the double meaning of synchronized: it deals with locks that permit higher-level synchronization protocols, while at the same time dealing with the memory system (sometimes via low-level memory barrier machine instructions) to keep value representations in synch across threads. This reflects one way in which concurrent programming bears more similarity to distributed programming than to sequential programming. The latter sense of synchronized may be viewed as a mechanism by which a method running in one thread indicates that it is willing to send and/or receive changes to variables to and from methods running in other threads. From this point of view, using locks and passing messages might be seen merely as syntactic variants of each other.
- If a field is declared as volatile, any value written to it is flushed and made visible by the writer thread before the writer thread performs any further memory operation (i.e., for the purposes at hand it is flushed immediately). Reader threads must reload the values of volatile fields upon each access.
- The first time a thread accesses a field of an object, it sees either the initial value of the field or a value since written by some other thread.
Among other consequences, it is bad practice to make available the reference to an incompletely constructed object (see εK?.2). It can also be risky to start new threads inside a constructor, especially in a class that may be subclassed. Thread.start has the same memory effects as a lock release by the thread calling start, followed by a lock acquire by the started thread. If a Runnable superclass invokes new Thread(this).start() before subclass constructors execute, then the object might not be fully initialized when the run method executes. Similarly, if you create and start a new thread T and then create an object X used by thread T, you cannot be sure that the fields of X will be visible to T unless you employ synchronization surrounding all references to object X. Or, when applicable, you can create X before starting T.
- As a thread terminates, all written variables are flushed to main memory. For example, if one thread synchronizes on the termination of another thread using Thread.join, then it is guaranteed to see the effects made by that thread (see εK?.2).
The memory model guarantees that, given the eventual occurrence of the above operations, a particular update to a particular field made by one thread will eventually be visible to another. But eventually can be an arbitrarily long time. Long stretches of code in threads that use no synchronization can be hopelessly out of synch with other threads with respect to values of fields. In particular, it is always wrong to write loops waiting for values written by other threads unless the fields are volatile or accessed via synchronization (see εK?.6).
The model also allows inconsistent visibility in the absence of synchronization. For example, it is possible to obtain a fresh value for one field of an object, but a stale value for another. Similarly, it is possible to read a fresh, updated value of a reference variable, but a stale value of one of the fields of the object now being referenced.
However, the rules do not require visibility failures across threads, they merely allow these failures to occur. This is one aspect of the fact that not using synchronization in multithreaded code doesn't guarantee safety violations, it just allows them. On most current JVM implementations and platforms, even those employing multiple processors, detectable visibility failures rarely occur. The use of common caches across threads sharing a CPU, the lack of aggressive compiler-based optimizations, and the presence of strong cache consistency hardware often cause values to act as if they propagate immediately among threads. This makes testing for freedom from visibility-based errors impractical, since such errors might occur extremely rarely, or only on platforms you do not have access to, or only on those that have not even been built yet. These same comments apply to multithreaded safety failures more generally. Concurrent programs that do not use synchronization fail for many reasons, including memory consistency problems.
Ordering
Ordering rules fall under two cases, within-thread and between-thread:- From the point of view of the thread performing the actions in a method, instructions proceed in the normal as-if-serial manner that applies in sequential programming languages.
- From the point of view of other threads that might be "spying" on this thread by concurrently running unsynchronized methods, almost anything can happen. The only useful constraint is that the relative orderings of synchronized methods and blocks, as well as operations on volatile fields, are always preserved.
Note that the within-thread point of view is implicitly adopted in all other discussions of semantics in JLS. For example, arithmetic expression evaluation is performed in left-to-right order (JLS section 15.6) as viewed by the thread performing the operations, but not necessarily as viewed by other threads.
The within-thread as-if-serial property is helpful only when only one thread at a time is manipulating variables, due to synchronization, structural exclusion, or pure chance. When multiple threads are all running unsynchronized code that reads and writes common fields, then arbitrary interleavings, atomicity failures, race conditions, and visibility failures may result in execution patterns that make the notion of as-if-serial just about meaningless with respect to any given thread.
Even though JLS addresses some particular legal and illegal reorderings that can occur, interactions with these other issues reduce practical guarantees to saying that the results may reflect just about any possible interleaving of just about any possible reordering. So there is no point in trying to reason about the ordering properties of such code.
Volatile
In terms of atomicity, visibility, and ordering, declaring a field as volatile is nearly identical in effect to using a little fully synchronized class protecting only that field via get/set methods, as in:final class VFloat {
private float value;
final synchronized void set(float f) { value = f; }
final synchronized float get() { return value; }
}
Declaring a field as volatile differs only in that no locking is involved. In particular, composite read/write operations such as the "++'' operation on volatile variables are not performed atomically.
Also, ordering and visibility effects surround only the single access or update to the volatile field itself. Declaring a reference field as volatile does not ensure visibility of non-volatile fields that are accessed via this reference. Similarly, declaring an array field as volatile does not ensure visibility of its elements. Volatility cannot be manually propagated for arrays because array elements themselves cannot be declared as volatile.
Because no locking is involved, declaring fields as volatile is likely to be cheaper than using synchronization, or at least no more expensive. However, if volatile fields are accessed frequently inside methods, their use is likely to lead to slower performance than would locking the entire methods.
Declaring fields as volatile can be useful when you do not need locking for any other reason, yet values must be accurately accessible across multiple threads. This may occur when:
- The field need not obey any invariants with respect to others.
- Writes to the field do not depend on its current value.
- No thread ever writes an illegal value with respect to intended semantics.
- The actions of readers do not depend on values of other non-volatile fields.
εΛßεΛöφïΑγΦ•ΫE΄η·≠≠aÄγö³η·≠≠aÄηß³η¨ÉιÉΫδΗçδΦ?x®§)ηΑàεàΑγΚΩΫE΄ε£¨ρqΕεèëγö³ι½°ιΔ‰ο֦妆亙(f®¥)δΗÄ㦥δΜΞφùΞοΦ¨‰qôδΚ¦ι½°ιΔ‰ιÉΫφ‰·γïôγΜôρq¦_èΑφà•φ™çδΫ€γ≥ΜΨlüεéΜη·ΠγΜÜη·¥φ‰éγö³ψIJδΫÜφ‰·οΦ¨Java η·≠η®Äηß³η¨ÉεQàJLSεQâεç¥φ‰éγΓ°ε¨Öφ΄§δΗÄδΗΣγΚΩΫE΄φ®Γεû΄οΦ¨ρqΕφèêδΨ¦δΚÜ(ji®Θn)δΗÄδΚ¦η·≠≠aÄεÖÉ㥆δΨ¦εΦÄεèëδùhεë‰δ΄…γî®δΜΞδΩùη·¹δΜ•δΜ§ΫE΄εΚèγö³γΚΩΫE΄ε°âεÖ®ψÄ?/p>
ε·ΙγΚΩΫE΄γö³φ‰éγΓ°φî·φ¨¹φ€âεà©δΙüφ€âεΦäψIJε°ÉδΫΩεΨ½φàëδΜ§ε€®εÜôΫE΄εΚèφ½Εφ¦¥ε°“é(gu®©)‰™εà©γî®ΨUΩγ®΄γö³εäüηÉΫ壨δΨΩεà©εQ¨δΫÜεê¨φ½ΕδΙüφ³èεë≥γùÄφàëδΜ§δΗçεΨ½δΗçφ≥®φ³èφâÄεÜôγ±Μγö³γΚΩΫE΄ε°âεÖ®ο֨妆亙(f®¥)δΜ÷MΫïΨcΜιÉΫεΨàφ€âεè·ηÉΫηΔΪγî®ε€®δΗÄδΗΣεΛöΨUΩγ®΄γö³γé·εΔÉεÜÖψÄ?/p>
η°ΗεΛöγî®φàΖΫW§δΗÄ΄ΤΓεèëγéνCΜ•δΜ§δΗçεΨ½δΗçεé»ùêÜηßΘγΚΩΫE΄γö³φΠ²εΩΒγö³φ½ΕεÄôοΦ¨ρqΕδΗçφ‰·ε¦†δΗόZΜ•δΜ§ε€®εÜôεà¦εΜΚ壨ΫéΓγêÜΨUΩγ®΄γö³γ®΄εΚèοΦ¨ηĨφ‰·ε¦†δΊ™(f®¥)δΜ•δΜ§φ≠Θε€®γî®δΗÄδΗΣφ€§μwΪφ‰·εΛöγΚΩΫE΄γö³εΖΞεÖΖφà•φΓÜφûΕψIJδ™QδΫïγq?Swing GUI φΓÜφûΕφà•εÜô‰q΅εΑèφ€çεäΓΫE΄εΚèφà?JSP ôεκäö³εΦÄεèëδùhεë‰οΦàδΗçγ°Γφ€âφ≤Γφ€âφ³èη·ÜεàΑεQâιÉΫφ¦³ΓΜèηΔΪγΚΩΫE΄γö³εΛçφù²φÄßε¦ΑφâΑηΩ΅ψÄ?/p>
Java η°Ψη°ΓεΗàφ‰·φɦ_à¦εΜόZΗÄΩUçη·≠≠aÄεQ¨δ΄…δΙ΄ηÉΫεΛüεΨàεΞΫε€Α‰qêηΓ¨ε€®γéΑδΜΘγö³Φ΄§δögεQ¨ε¨Öφ΄§εΛöεΛ³γêÜεô®γ≥ΜΨlüδΗäψIJηΠ¹ηΨë÷àΑ‰qôδΗÄγ¦°γö³εQ¨γ°ΓγêÜγΚΩΫE΄ι½¥εçèηΑÉγö³εΖΞδΫ€δΗΜηΠ¹φé®ΨlôδΚÜ(ji®Θn)ηΫ·δögεΦÄεèëδùhεë‰οΦ¦ΫE΄εΚèεë‰εΩÖôεάL¨΅ε°öγΚΩΫE΄ι½¥εÖΉÉμnφïΑφç°γö³δΫçΨ|°ψÄ²ε€® Java ΫE΄εΚèδΗ≠οΦ¨γî®φùΞΫéΓγêÜΨUΩγ®΄ι½¥εçèηΑÉεΖΞδΫ€γö³δΗΜηΠ¹εΖΞεÖΖφ‰?synchronized εÖ≥ιî°ε≠½ψÄ²ε€®Ψ~ΚεΑëεê¨φ≠Ξγö³φÉÖεÜΒδΗ΄εQ¨JVM εè·δΜΞεΨàη΅Σγî±ε€Αε·ΙδΗçεê¨γΚΩΫE΄εÜÖφâßηΓ¨γö³φ™çδΫ€ηΩ¦ηΓ¨η°Γφ½Ε壨φé£εΚèψÄ²ε€®εΛßιÉ®εàÜφÉÖεÜΒδΗ΄εQ¨ηΩôφ≠Θφ‰·φàëδΜ§φɨôΠ¹γö³ο֨妆亙(f®¥)‰qôφ†Ζεè·δΜΞφèêιΪ‰φÄßηÉΫεQ¨δΫÜε°ÉδΙüΨlôγ®΄εΚèεë‰εΗΠφùΞδΚ?ji®Θn)ιΔùεΛ•γö³η¥üφ΄ÖεQ¨δΜ•δΜ§δΗçεΨ½δΗçη΅ΣεΖ±η·ÜεàΪδΜÄδΙàφ½ΕεÄôηΩôΩUçφÄßηÉΫγö³φèêιΪ‰δΦö(x®§)εç±εèä(qi®Δng)ΫE΄εΚèγö³φ≠ΘΦ΄°φÄßψÄ?/p>
synchronized γ€üφ≠Θφ³èεë≥γùÄδΜÄδΙàοΦü
εΛßιÉ®εà?Java ΫE΄εΚèεë‰ε·Ιεê¨φ≠Ξγö³εù½φà•φ•Ιφ≥ïγö³γêÜηßΘφ‰·ε°¨εÖ®φ†Ιφç°δ΄…γî®δΚ£φ•ΞοΦàδΚ£φ•ΞδΩΓεèΖι΅èοΦâ(j®Σ)φà•ε°öδΙâδΗÄδΗΣδèΆ(f®¥)γï¨φ°ΒεQàδΗÄδΗΣεΩÖôε’déüε≠êφÄßε€ΑφâßηΓ¨γö³δΜΘγ†¹εù½εQâψIJηôΫγ³?synchronized γö³η·≠δΙâδΗ≠Φ΄°ε°ûε¨Öφ΄§δΚ£φ•Ξ壨εéüε≠êφÄßοΦ¨δΫÜε€®ΫéΓγ®΄‰q¦εÖΞδΙ΄εâç壨倮ΫéΓγ®΄ιÄÄε΅όZΙ΄εêéεèëγîüγö³δΚ΄φÉÖηΠ¹εΛçφù²εΨ½εΛöψÄ?/p>
synchronized γö³η·≠δΙâγΓ°ε°ûδΩùη·¹δΚÜ(ji®Θn)δΗÄ΄ΤΓεèΣφ€âδΗÄδΗΣγΚΩΫE΄εè·δΜΞη°Ωι½°ηΔΪδΩùφäΛγö³ε¨Κ¨DΒοΦ¨δΫÜεê¨φ½ΕηΩ‰ε¨Öφ΄§εê¨φ≠ΞΨUΩγ®΄ε€®δΗΜε≠‰εÜÖδΚ£γ¦ΗδΫ€γî®γö³ηß³εàôψIJγêÜηß?Java εÜÖε≠‰φ®Γεû΄εQàJMMεQâγö³δΗÄδΗΣεΞΫφ•“é(gu®©)≥ïû°±φ‰·φääεê³δΗΣγΚΩΫE΄φÉ≥εÉèφàê‰qêηΓ¨ε€®γ¦ΗδΚ£εàÜΦ¦»ùö³εΛ³γêÜεô®δΗäεQ¨φâÄφ€âγö³εΛ³γêÜεô®ε≠‰εè•εê¨δΗÄεù½δΗΜε≠‰γ©Κι½Ώ_(d®Δ)Φ¨φ·èδΗΣεΛ³γêÜεô®φ€âη΅ΣεΖ±γö³γΦ™ε≠‰οΦ¨δΫÜηΩôδΚ¦γΦ™ε≠‰εè·ηÉΫεΤàδΗçφÄ’d£¨δΗ’d≠‰εê¨φ≠ΞψÄ²ε€®Ψ~ΚεΑëεê¨φ≠Ξγö³φÉÖεÜΒδΗ΄εQ¨JMM δΦ?x®§)εÖ¹η°φÄΗΛδΗΣγΚΩΫE΄ε€®εê¨δΗÄδΗΣεÜÖε≠‰ε€ΑεùÄδΗä〴εàνCΗçεê¨γö³εÄΙ{IJηĨεΫ™γî®δΗÄδΗΣγ°ΓΫE΄οΦàιî¹οΦâ(j®Σ)‰q¦ηΓ¨εê¨φ≠Ξγö³φ½ΕεÄôοΦ¨δΗÄφ½Πγî≥η·Ζεä†δΚ?ji®Θn)ιî¹εQ¨JMM û°ΉÉΦö(x®§)驧δΗäηΠ¹φ±²η·ΞγΦ™ε≠‰εΛ±φïàοΦ¨γ³Εεêéε€®ε°ÉηΔΪι΅äφîë÷âçε·Ιε°É‰q¦ηΓ¨εàδh•ΑεQàφääδΩ°φîΙ‰q΅γö³εÜÖε≠‰δΫçγΫ°εÜôε¦ûδΗ’d≠‰εQâψIJδΗçιö³Γ€΄ε΅όZΊ™(f®¥)δΜÄδΙàεê¨φ≠ΞδΦö(x®§)ε·Ιγ®΄εΚèγö³φÄßηÉΫεΫ±ε™ç‰qôδΙàεΛßοΦ¦ιΔëγΙ¹ε€ΑεàΖφ•ΑγΦ™ε≠‰δΜΘδΜΖδΦö(x®§)εΨàεΛßψÄ?/p>
|
δΫΩγî®δΗÄφùΓεΞΫγö³ηΩêηΓ¨ηΒ\ΨU?/span>
εΠ²φû€εê¨φ≠ΞδΗçιIJεΫ™εQ¨εêéφû€φ‰·εΨàδΗΞι΅çγö³εQöδΦö(x®§)ιĆφàêφïΑφç°φΖΖδΊï壨δΚâγî®φÉÖεÜΒοΦ¨ε·ΤD΅¥ΫE΄εΚè奩φΚÉεQ¨δώîγîüδΗçφ≠ΘγΓ°γö³γΜ™φû€οΦ¨φà•ηÄÖφ‰·δΗçεè·ιΔ³η°Γγö³ηΩêηΓ¨ψIJφ¦¥Ψpüγö³φ‰·οΦ¨‰qôδΚ¦φÉÖεÜΒεè·ηÉΫεΨàεΑëεèëγîüδΗîεÖΖφ€âε¹Εγ³ΕφÄßοΦàδΫΩεΨ½ι½°ιΔ‰εΨàιöΨηΔΪγ¦ë΄Ι΄ε£¨ι΅çγéΑεQâψIJεΠ²φû€φΒ΄η·ïγé·εΔÉ壨εΦÄεèëγé·εΔÉφ€âεΨàεΛßγö³δΗçεê¨οΦ¨φ½†η°Κφ‰·ιÖçΨ|°γö³δΗçεê¨εQ¨ηΩ‰φ‰·η¥üηçοL(f®Ξng)ö³δΗçεê¨εQ¨ιÉΫφ€âεè·ηÉΫδ΄…εΨ½ηΩôδΚ¦ι½°ιΔ‰ε€®΄Ι΄η·ïγé·εΔÉδΗ≠φ†Ιφ€§δΗçε΅ΚγéΑεQ¨δΜéηĨεΨ½ε΅Κιîôη··γö³Ψl™η°ΚεQöφàëδΜ§γö³ΫE΄εΚèφ‰·φ≠ΘΦ΄°γö³εQ¨ηĨδΚ΄ε°ûδΗä‰qôδΚ¦ι½°ιΔ‰εèΣφ‰·‰q‰φ≤Γε΅ΚγéΑηĨεΖ≤ψÄ?/p>
|
εèΠδΗÄφ•öwùΔεQ¨δΗçεΫ™φà•‰q΅εΚΠε€νC΄…γî®εê¨φ≠ΞδΦö(x®§)ε·ΤD΅¥εÖΕε°Éι½°ιΔ‰εQ¨φ·îεΠ²φÄßηÉΫεΨàεư壨φ≠Μιî¹ψIJεΫ™γ³?d®Αng)ûΦ¨φÄßηÉΫεΖ°ηôΫγ³ΕδΗçεΠ²φïΑφç°φΊ€δΙ±ι²ΘδΙàδΗΞι΅çοΦ¨δΫÜδΙüφ‰·δΗÄδΗΣδΗΞι΅çγö³ι½°ιΔ‰εQ¨ε¦†φ≠Λεê¨φ†ΖδΗçεè·εΩΫηßÜψIJγΦ•εÜôδΦ‰ΩUÄγö³εΛöΨUΩγ®΄ΫE΄εΚèι€ÄηΠ¹δ΄…γî®εΞΫγö³ηΩêηΓ¨ηΒ\ΨUΩοΦ¨≠ë¦_Λüγö³εê¨φ≠Ξεè·δΜΞδ΄…φ²(zh®®n)®γö³φïΑφç°δΗçεèëγîüφΊ€δΙ±οΦ¨δΫÜδΗçι€ÄηΠ¹φΜΞγî®εàΑεéάLâΩφ΄Öφ≠Μιî¹φà•δΗçεΩÖηΠ¹ε€ΑεâäεΦ±ΫE΄εΚèφÄßηÉΫγö³ιΘéιô©ψÄ?/p>
|
εê¨φ≠Ξγö³δΜΘδΜδh€âεΛöεΛßεQ?/span>
γîΉÉΚéε¨Öφ΄§Ψ~™ε≠‰εàδh•Α壨η°ΨΨ|°εΛ±φïàγö³‰q΅γ®΄εQ¨Java η·≠η®ÄδΗ≠γö³εê¨φ≠Ξεù½ιÄöεΗΗφ·îη°ΗεΛöεψ^εèΑφèêδΨ¦γö³δΗ¥γ﨨DΒη°ΨεΛ΅δΜΘδΜδh¦¥εΛßοΦ¨‰qôδΚ¦δΗ¥γ﨨DΒιÄöεΗΗφ‰·γî®δΗÄδΗΣεéüε≠êφÄßγö³“test and set bit”φ€Κεô®φ¨΅δΉo(h®¥)ε°ûγéΑγö³ψIJεç≥δΫΩδΗÄδΗΣγ®΄εΚèεèΣε¨Öφ΄§δΗÄδΗΣε€®εçïδΗÄεΛ³γêÜεô®δΗä‰qêηΓ¨γö³εçïΨUΩγ®΄εQ¨δΗÄδΗΣεê¨φ≠Ξγö³φ•“é(gu®©)≥ïηΑÉγî®δΜçηΠ¹φ·îιùûεê¨φ≠Ξγö³φ•Ιφ≥ïηΑÉγî®φÖΔψIJεΠ²φû€εê¨φ≠Ξφ½Ε‰q‰εèëγîüιî¹ε°öδΚâγî®οΦ¨ι²ΘδΙàφÄßηÉΫδΗäδΜ‰ε΅Κγö³δΜΘδ≠h(hu®Δn)δΦ?x®§)εΛßεΨ½εΛöεQ¨ε¦†δΗόZΦö(x®§)ι€ÄηΠ¹ε΅†δΗΣγΚΩΫE΄εà΅φçΔ壨Ψp»ùΜüηΑÉγî®ψÄ?/p>
ρqΗηΩêγö³φ‰·εQ¨ιöèγùÄφ·èδΗÄγâàγö³ JVM γö³δΗçφ•≠φîΙ‰q¦οΦ¨φ½ΔφèêιΪ‰δΚÜ(ji®Θn) Java ΫE΄εΚèγö³φÄ÷MΫ™φÄßηÉΫεQ¨εê¨φ½ΕδΙüγ¦Ηε·Ιε΅èεΑëδΚ?ji®Θn)εê¨φ≠Ξγö³δΜΘδ≠h(hu®Δn)εQ¨εΤàδΗîεΑÜφùΞηΩ‰εè·ηÉΫδΦ?x®§)φ€â‰q¦δΗÄφ≠Ξγö³φîΙηΩ¦ψIJφ≠ΛεΛ•οΦ¨εê¨φ≠Ξγö³φÄßηÉΫδΜΘδ≠h(hu®Δn)ΨlèεΗΗφ‰·ηΔΪεΛΗεΛßγö³ψIJδΗÄδΗΣηë½εêçγö³ηΒ³φ•ôφùΞφΚêû°±φ¦ΨΨlèεΦïη·¹η·¥δΗÄδΗΣεê¨φ≠Ξγö³φ•“é(gu®©)≥ïηΑÉγî®φ·îδΗÄδΗΣιùûεê¨φ≠Ξγö³φ•Ιφ≥ïηΑÉγî®φÖΔ 50 εÄçψIJηôΫγ³ΕηΩôεèΞη·ùφ€âεè·ηÉΫφ‰·γ€üγö³εQ¨δΫÜδΙüδΦö(x®§)δΚßγîüη··ε·ΦεQ¨ηĨδΗîεΖ≤γΜèε·ΤD΅¥δΚ?ji®Θn)η°ΗεΛöεΦÄεèëδùhεë‰εç≥δΫΩε€®ι€ÄηΠ¹γö³φ½ΕεÄôδΙüι¹ΩεÖçδΫΩγî®εê¨φ≠ΞψÄ?/p>
δΗΞφ†ΦδΨùγÖßγôë÷àÜφ·îη°ΓΫé½εê¨φ≠Ξγö³φÄßηÉΫφçüεΛ±ρqΕφ≤Γφ€âεΛöεΛßφ³èδΙâο֨妆亙(f®¥)δΗÄδΗΣφ½†δΚâγî®γö³εê¨φ≠ΞγΜôδΗÄδΗΣεù½φà•φ•Ιφ≥ïεΗΠφùΞγö³φ‰·ε¦Κε°öγö³φÄßηÉΫφçüεΛ±ψIJηĨηΩôδΗÄε¦Κε°öγö³εög‰qüεΗΠφùΞγö³φÄßηÉΫφçüεΛ±γôë÷àÜφ·îεè•εÜ≥δΚéε€®η·Ξεê¨φ≠Ξεù½εÜÖε¹öδΚÜ(ji®Θn)εΛöεΑëεΖΞδΫ€ψIJε·ΙδΗÄδΗ?em>ΫI?/em>φ•“é(gu®©)≥ïγö³εê¨φ≠ΞηΑÉγî®εè·ηÉΫηΠ¹φ·îε·ΙδΗÄδΗΣγ©Κφ•“é(gu®©)≥ïγö³ιùûεê¨φ≠ΞηΑÉγî®φÖ?20 εÄçοΦ¨δΫÜφàëδΜ§εΛöιïΩφ½Ει½¥φâçηΑÉγî®δΗÄ΄ΤΓγ©Κφ•“é(gu®©)≥ïεëΔοΦüεΫ™φàëδΜ§γî®φ¦¥φ€âδΜΘηΓ®φÄßγö³û°èφ•Ιφ≥ïφùΞηΓΓι΅èεê¨φ≠ΞφçüεΛ±φ½”ûΦ¨γôë÷àÜφïΑεΨàεΩΪεΑ±δΗ΄ιôçεàΑεè·δΜΞε°ΙεΩçγö³η¨É妥δΙ΄εÜÖψÄ?/p>
ηΓ?1 φääδΗÄδΚ¦ηΩôΩUçφïΑφç°φîΨε€®δΗÄηΒδhùΞ〴ψIJε°Éεà½δ΄DδΚ?ji®Θn)δΗÄδΚ¦δΗçεê¨γö³ε°ûδΨ΄εQ¨δΗçεê¨γö³ρq¦_èΑ壨δΗçεê¨γö³ JVM δΗ΄δΗÄδΗΣεê¨φ≠Ξγö³φ•“é(gu®©)≥ïηΑÉγî®γ¦Ηε·ΙδΚéδΗÄδΗΣιùûεê¨φ≠Ξγö³φ•Ιφ≥ïηΑÉγî®γö³φçüεΛ±ψÄ²ε€®φ·èδΗÄδΗΣε°ûδΨ΄δΗ΄εQ¨φàë‰qêηΓ¨δΗÄδΗΣγ°Äεçïγö³ΫE΄εΚèεQ¨φΒ΄ε°öεσ@γé·ηΑÉγî®δΗÄδΗΣφ•Ιφ≥?10εQ?00εQ?00 ΄ΤΓφâÄι€Äγö³ηΩêηΓ¨φ½Ει½Ώ_(d®Δ)Φ¨φàëηΑÉγî®δΚÜ(ji®Θn)εê¨φ≠Ξ壨ιùûεê¨φ≠ΞδΗΛδΗΣγâàφ€§εQ¨εΤàφ·îηΨÉδΚ?ji®Θn)γΜ™φû€ψIJηΓ®φ†ιgΗ≠γö³φïΑφç°φ‰·εê¨φ≠Ξγâàφ€§γö³ηΩêηΓ¨φ½Ει½¥γ¦Ηε·ΙδΚéιùûεê¨φ≠Ξγâàφ€§γö³‰qêηΓ¨φ½âô½¥γö³φ·îγé΅οΦ¦ε°Éφ‰ΨΫCόZΚÜ(ji®Θn)εê¨φ≠Ξγö³φÄßηÉΫφçüεΛ±ψIJφ·è΄ΤΓηΩêηΓ¨ηΑÉγî®γö³ιÉΫφ‰·φΗÖεçï 1 δΗ≠γö³ΫéÄεçïφ•Ιφ≥ïδΙ΄δΗÄψÄ?/p>
ηΓ®φ†Φ 1 δΗ≠φ‰ΨΫCόZΚÜ(ji®Θn)εê¨φ≠Ξφ•“é(gu®©)≥ïηΑÉγî®γ¦Ηε·ΙδΚéιùûεê¨φ≠Ξφ•“é(gu®©)≥ïηΑÉγî®γö³γ¦Ηε·“é(gu®©)ÄßηÉΫεQ¦δΊ™(f®¥)δΚ?ji®Θn)γî®Ψlùε·Ιγö³φ†΅ε΅ÜφΒ΄ε°öφÄßηÉΫφçüεΛ±εQ¨εΩÖôεΜηÄÉηôëεà?JVM ιÄüεΚΠφèêιΪ‰γö³ε¦†γ¥†οΦ¨‰qôεΤàφ≤Γφ€âε€®φïΑφç°δΗ≠δΫ™γéΑε΅ΚφùΞψÄ²ε€®εΛßεΛöφïΑφΒ΄η·ïδΗ≠εQ¨φ·èδΗ?JVM γö³φ¦¥ιΪ‰γâàφ€§ιÉΫδΦ?x®§)δ΄?JVM γö³φÄ÷MΫ™φÄßηÉΫεΨ½εàΑεΨàεΛßφèêιΪ‰εQ¨εΨàφ€âεè·ηÉ?1.4 γâàγö³ Java ηôöφ΄üφ€ΚεèëηΓ¨γö³φ½ΕεÄôοΦ¨ε°Éγö³φÄßηÉΫ‰q‰δΦö(x®§)φ€âηΩ¦δΗÄφ≠Ξγö³φèêιΪ‰ψÄ?/p>
ηΓ?1. φ½†δΚâγî®εê¨φ≠Ξγö³φÄßηÉΫφçüεΛ±
| JDK | staticEmpty | empty | fetch | hashmapGet | singleton | create |
| Linux / JDK 1.1 | 9.2 | 2.4 | 2.5 | n/a | 2.0 | 1.42 |
| Linux / IBM Java SDK 1.1 | 33.9 | 18.4 | 14.1 | n/a | 6.9 | 1.2 |
| Linux / JDK 1.2 | 2.5 | 2.2 | 2.2 | 1.64 | 2.2 | 1.4 |
| Linux / JDK 1.3 (no JIT) | 2.52 | 2.58 | 2.02 | 1.44 | 1.4 | 1.1 |
| Linux / JDK 1.3 -server | 28.9 | 21.0 | 39.0 | 1.87 | 9.0 | 2.3 |
| Linux / JDK 1.3 -client | 21.2 | 4.2 | 4.3 | 1.7 | 5.2 | 2.1 |
| Linux / IBM Java SDK 1.3 | 8.2 | 33.4 | 33.4 | 1.7 | 20.7 | 35.3 |
| Linux / gcj 3.0 | 2.1 | 3.6 | 3.3 | 1.2 | 2.4 | 2.1 |
| Solaris / JDK 1.1 | 38.6 | 20.1 | 12.8 | n/a | 11.8 | 2.1 |
| Solaris / JDK 1.2 | 39.2 | 8.6 | 5.0 | 1.4 | 3.1 | 3.1 |
| Solaris / JDK 1.3 (no JIT) | 2.0 | 1.8 | 1.8 | 1.0 | 1.2 | 1.1 |
| Solaris / JDK 1.3 -client | 19.8 | 1.5 | 1.1 | 1.3 | 2.1 | 1.7 |
| Solaris / JDK 1.3 -server | 1.8 | 2.3 | 53.0 | 1.3 | 4.2 | 3.2 |
φΗÖεçï 1. εüΚε΅Ü΄Ι΄η·ïδΗ≠γî®εàΑγö³ΫéÄεçïφ•Ιφ≥?/strong>
public void empty() { }
public Object fetch() { return field; }
public Object singleton() {
if (singletonField == null)
singletonField = new Object();
return singletonField;
}
public Object hashmapGet() {
return hashMap.get("this");
}
public Object create() {
return new Object();
}
‰qôδΚ¦û°èεüΚε΅ÜφΒ΄η·ïδΙüι‰êφ‰éδΚ?ji®Θn)ε≠‰ε€®εä®φĹγΦ•η·ëεô®γö³φÉÖεÜΒδΗ΄ηßΘι΅äφÄßηÉΫΨl™φû€φâÄιùΔδèΆ(f®¥)γö³φ¨ëφà‰ψIJε·ΙδΚ?1.3 JDK ε€®φ€â壨φ≤Γφ€?JIT φ½”ûΦ¨φïΑε≠½δΗäγö³εΖ®εΛßεΖ°εΦ²ι€ÄηΠ¹γΜôε΅όZΗÄδΚ¦ηßΘι΅äψIJε·Ιι²ΘδΚ¦ιùûεΗΗΫéÄεçïγö³φ•“é(gu®©)≥ïεQ?empty ε£?fetch εQâοΦ¨εüΚε΅Ü΄Ι΄η·ïγö³φ€§η¥®οΦàε°ÉεèΣφ‰·φâßηΓ¨δΗÄδΗΣ塆δΙéδΜÄδΙàδΙüδΗçε¹öγö³γ¥ßε΅ëγö³εΨΣγé·εQâδ΄…εΨ?JIT εè·δΜΞεä®φĹε€ΑΨ~•η·ëφï¥δΗΣεΨΣγé·εQ¨φää‰qêηΓ¨φ½âô½¥εé΄γΨÉεàΑ塆δΙéφ≤Γφ€âγö³ε€Αφ≠ΞψIJδΫÜε€®δΗÄδΗΣε°ûιôÖγö³ΫE΄εΚèδΗ≠οΦ¨JIT ηÉΫεêΠ‰qôφ†Ζε¹öεΑ±ηΠ¹εè•εÜ≥δΚéεΨàεΛö妆㥆δΚ?ji®Θn)οΦ¨φâÄδΜΞοΦ¨φ½?JIT γö³η°Γφ½ΕφïΑφç°εè·ηÉΫε€®ε¹öεÖ§ρq¦_·Ιφ·îφ½Εφ¦¥φ€âγî®δΗÄδΚ¦ψÄ²ε€®δΜ÷MΫïφÉÖεÜΒδΗ΄οΦ¨ε·ΙδΚéφ¦¥εÖÖε°ûγö³φ•“é(gu®©)≥ïεQ?create ε£?hashmapGet εQâοΦ¨JIT û°ΉÉΗçηÉΫη±Γε·“é(gu®©)¦¥ΫéÄεçïδΚ¦γö³φ•Ιφ≥ïι²Θφ†Ζδ΄…ιùûεê¨φ≠Ξγö³φÉÖεÜΒεΨ½εàΑεΖ®εΛßγö³φîΙ‰q¦ψIJεèΠεΛ•οΦ¨δΜéφïΑφç°δΗ≠〴δΗçε΅?JVM φ‰·εêΠηÉΫεΛüε·“é(gu®©)Β΄η·ïγö³ι΅çηΠ¹ιÉ®εà܉q¦ηΓ¨δ։娕ψIJεê¨φ†χPΦ¨ε€®εè·φ·îηΨÉγö?IBM ε£?Sun JDK δΙ΄ι½¥γö³εΖ°εΦ²εèçφ‰†δΚÜ(ji®Θn) IBM Java SDK εè·δΜΞφ¦¥εΛßΫE΄εΚΠε€νC։娕ιùûεê¨φ≠Ξγö³εσ@γé·οΦ¨ηĨδΗçφ‰·εê¨φ≠Ξγâàφ€§δΜΘδΜδh¦¥ιΪ‰ψIJηΩôε€®γΚ·η°Γφ½ΕφïΑφç°δΗ≠εè·δΜΞφ‰éφ‰ë÷€Α〴ε΅ΚεQàηΩô顨δΗçφèêδΨ¦εQâψÄ?/p>
δΜéηΩôδΚ¦φïΑε≠½δΗ≠φàëδΜ§εè·δΜΞεΨ½ε΅ΚδΜΞδΗ΄Ψl™η°ΚεQöε·ΙιùûδΚâγî®εê¨φ≠ΞηĨη®ÄεQ¨ηôΫγ³Εε≠‰ε€®φÄßηÉΫφçüεΛ±εQ¨δΫÜε€®ηΩêηΓ¨η°ΗεΛöδΗçφ‰·γâΙεàΪεΨ°û°èγö³φ•“é(gu®©)≥ïφ½”ûΦ¨φçüεΛ±εè·δΜΞιôçεàΑδΗÄδΗΣεêàγêÜγö³φΑ¥εψ^εQ¦εΛßεΛöφïΑφÉÖεÜΒδΗ΄φçüεΛ±εΛßφΠ²ε€® 10% εà?200% δΙ΄ι½¥εQàηΩôφ‰·δΗÄδΗΣγ¦Ηε·ΙηΨÉ?y®≠u)°èγö³φïΑγ¦°εQâψIJφâÄδΜΞοΦ¨ηôΫγ³Εεê¨φ≠Ξφ·èδΗΣφ•“é(gu®©)≥ïφ‰·δΗçφ‰éφôΚγö³οΦà‰qôδΙüδΦ?x®§)εΔûεä†φ≠Μιî¹γö³εè·ηÉΫφÄßοΦâ(j®Σ)εQ¨δΫÜφàëδΜ§δΙüδΗçι€ÄηΠ¹ηΩôδΙàε°≥φÄïεê¨φ≠ΞψIJηΩô顨䴅γî®γö³ΫéÄεçïφΒ΄η·ïφ‰·η·¥φ‰éδΗÄδΗΣφ½†δΚâγî®εê¨φ≠Ξγö³δΜΘδΜ·²Π¹φ·îεà¦εΜόZΗÄδΗΣε·Ιη±Γφà•φüΞφâΨδΗÄδΗ?code>HashMap γö³δΜΘδΜΖεΑèψÄ?/p>
γîΉÉΚéφ½©φ€üγö³δΙΠΨcç壨φ•΅γΪ†φö½γΛΚδΚ?ji®Θn)φ½†δΚâγî®εê¨φ≠ΞηΠ¹δΜ‰ε΅ΚεΖ®εΛßγö³φÄßηÉΫδΜΘδ≠h(hu®Δn)εQ¨η°ΗεΛöγ®΄εΚèεë‰û°όqΪ≠û°ΫεÖ®εä¦ι¹ΩεÖçεê¨φ≠ΞψIJηΩôΩUçφ¹êφÉßε·Φη΅¥δΚÜ(ji®Θn)η°ΗεΛöφ€âι½°ιΔ‰γö³φäÄφ€·ε΅ΚγééΆΦ¨φ·îεΠ²η·?double-checked lockingεQàDCLεQâψIJη°ΗεΛöεÖ≥δΚ?Java Ψ~•γ®΄γö³δΙΠ壨φ•΅γΪ†ιÉΫφé®ηçê DCLεQ¨ε°É〴δΗäεé»ù€üφ‰·ι¹ΩεÖçδΗçεΩÖηΠ¹γö³εê¨φ≠Ξγö³δΗÄΩUçη¹Σφ‰éγö³φ•“é(gu®©)≥ïεQ¨δΫÜε°ûιôÖδΗäε°Éφ†“é(gu®©)€§φ≤Γφ€âγî®οΦ¨εΚîη·Ξι¹ΩεÖçδΫΩγî®ε°ÉψIJDCL φ½†φïàγö³εéü妆εΨàεΛçφù²εQ¨εΖ≤≠ëÖε΅ΚδΚ?ji®Θn)φ€§φ•΅η°®η°Κγö³η¨É妥εQàηΠ¹φΖ±εÖΞδΚ?ji®Θn)ηßΘεQ¨η·Ζεè²ι‰Ö εè²ηÄÉηΒ³φ•?/a>顨γö³ι™ΨφéΞεQâψÄ?/p>
|
ε¹΅η°Ψεê¨φ≠ΞδΫΩγî®φ≠ΘγΓ°εQ¨η΄ΞΨUΩγ®΄γ€üφ≠Θεè²δΗéδΚâγî®εä†ιî¹εQ¨φ?zh®®n)®δΙüηÉΫφ³üεè½εàΑεê¨φ≠Ξε·Ιε°ûιôÖφÄßηÉΫγö³εΣ³(ji®Θng)ε™çψIJεΤàδΗîφ½†δΚâγî®εê¨φ≠Ξ壨δΚâγî®εê¨φ≠Ξι½¥γö³φÄßηÉΫφçüεΛ±εΖ°εàΪεΨàεΛßεQ¦δΗÄδΗΣγ°Äεçïγö³΄Ι΄η·ïΫE΄εΚèφ¨΅ε΅ΚδΚâγî®εê¨φ≠Ξφ·îφ½†δΚâγî®εê¨φ≠ΞφÖ?50 εÄçψIJφää‰qôδΗÄδΚ΄ε°û壨φàëδΜ§δΗäιùΔφäΫεè•γö³ηß²ε·üφïΑφç°Ψl™εêàε€®δΗÄηΒχPΦ¨εè·δΜΞ〴ε΅ΚδΫΩγî®δΗÄδΗΣδΚâγî®εê¨φ≠Ξγö³δΜΘδ≠h(hu®Δn)硦_Αëγ¦ΗεΫ™δΚéεà¦εΜ?50 δΗΣε·Ιη±ΓψÄ?/p>
φâÄδΜΞοΦ¨ε€®ηΑÉη·ïεΚîγî®γ®΄εΚèδΗ≠εê¨φ≠Ξγö³δ΄…γî®φ½ΕεQ¨φàëδΜ§εΚîη·ΞεäΣεä¦ε΅èû°ëε°ûιôÖδΚâγî®γö³φïΑγ¦°εQ¨ηĨφ†Ιφ€§δΗçφ‰·γ°Äεçïε€Αη·ïε¦Ψι¹ΩεÖçδΫΩγî®εê¨φ≠ΞψIJηΩôδΗΣγ≥Μεà½γö³ΫW?2 ιÉ®εàÜû°Üφääι΅çγ²Ιφîë÷€®ε΅èεΑëδΚâγî®γö³φäÄφ€·δΗäεQ¨ε¨Öφ΄§ε΅èû°èιî¹γö³γ≤£εΚΠψĹε΅èû°èεê¨φ≠Ξεù½γö³εΛßû°èδΜΞεè?qi®Δng)ε΅èû°èγΚΩΫE΄ι½¥εÖΉÉμnφïΑφç°γö³φïΑι΅èψÄ?/p>
|
ηΠ¹δ΄…φ²(zh®®n)®γö³ΫE΄εΚèΨUΩγ®΄ε°âεÖ®εQ¨ιΠ•εÖàεΩÖôε»ùΓ°ε°öε™ΣδΚ¦φïΑφç°εΑÜε€®γΚΩΫE΄ι½¥εÖΉÉμnψIJεΠ²φû€φ≠Θε€®εÜôγö³φïΑφç°δΜΞεêéεè·ηÉΫηΔΪεèΠδΗÄδΗΣγΚΩΫE΄η·ΜεàéΆΦ¨φà•ηÄÖφ≠Θε€®η·Μγö³φïΑφç°εè·ηÉΫεΖ≤ΨlèηΔΪεèΠδΗÄδΗΣγΚΩΫE΄εÜô‰q΅δΚÜ(ji®Θn)εQ¨ι²ΘδΙàηΩôδΚ¦φïΑφç°εΑ±φ‰·εÖ±δΚΪφïΑφç°οΦ¨εΩÖιΓΜ‰q¦ηΓ¨εê¨φ≠Ξε≠‰εè•ψIJφ€âδΚ¦γ®΄εΚèεë‰εè·ηÉΫδΦ?x®§)φÉäη°Εε€ΑεèëγéΑεQ¨ηΩôδΚ¦ηß³εàôε€®ΫéÄεçïε€Α΄²Ä(g®®)φüΞδΗÄδΗΣεÖ±δΚΪεΦïγî®φ‰·εêΠιùûΫIΚγö³φ½ΕεÄôδΙüγî®εΨ½δΗäψÄ?/p>
η°ΗεΛöδΚόZΦö(x®§)εèëγéΑ‰qôδΚ¦ε°öδΙâφÉäδùhε€νCΗΞφ†Ι{IJφ€âδΗÄΩUçφô°ι¹çγö³ηß²γ²Ιφ‰·οΦ¨εΠ²φû€εèΣφ‰·ηΠ¹η·ΜδΗÄδΗΣε·Ιη±Γγö³ε≠½φ°ΒεQ¨δΗçι€ÄηΠ¹η·Ζφ±²εä†ιî¹οΦ¨û°ΛεÖΕφ‰·ε€® JLS δΩùη·¹δΚ?32 δΫçη·Μφ™çδΫ€γö³εéüε≠êφÄßγö³φÉÖεÜΒδΗ΄οΦ¨ε°Éφ¦¥φ‰·εΠ²φ≠ΛψIJδΫÜδΗçεΙΗγö³φ‰·εQ¨ηΩôδΗΣηß²γ²“é(gu®©)‰·ιîôη··γö³ψIJιôΛιùûφâÄφ¨΅γö³ε≠½φ°ΒηΔΪεΘΑφ‰éδΊ™(f®¥) ε€®γΓ°ε°öδΚÜ(ji®Θn)ηΠ¹εÖ±δΚΪγö³φïΑφç°δΙ΄εêéεQ¨ηΩ‰ηΠ¹γΓ°ε°öηΠ¹εΠ²δΫïδΩùφäΛι²ΘδΚ¦φïΑφç°ψÄ²ε€®ΫéÄεçïφÉÖεÜΒδΗ΄εQ¨εèΣι€Äφääε°ÉδΜ§εΘΑφ‰éδΊ™(f®¥) ‰q‰φ€âδΗÄγ²ΙεÄΦεΨ½φ≥®φ³èγö³φ‰·εQ¨γ°Äεçïε€Αεê¨φ≠Ξε≠‰εè•εô®φ•Ιφ≥ïοΦàφà•εΘΑφ‰éδΗ΄ε±²γö³ε≠½φ°ΒδΗ?
εΠ²φû€δΗÄδΗΣηΑÉγî®ηÄÖφÉ≥ηΠ¹εΔûεä?
εΠ²φû€δΗΛδΗΣΨUΩγ®΄η·ïε¦Ψεê¨φ½ΕεΔûεä† δΜΞδΗäφÉÖεÜΒφ‰·δΗÄδΗΣεΨàεΞΫγö³ΫCόZΨ΄εQ¨η·¥φ‰éφàëδΜ§εΚîη·Ξφ≥®φ³èεΛöε±²φ§ΓΨ_£εΚΠγö³φïΑφç°ε°¨φï¥φÄßοΦ¦εê¨φ≠Ξε≠‰εè•εô®φ•Ιφ≥ïγΓ°δΩùηΑÉγî®ηÄÖηÉΫεΛüε≠‰εè•εàΑδΗÄη΅¥γö³ε£¨φ€Ä‰qëγâàφ€§γö³ε±ûφÄßεÄϊ|Φ¨δΫÜεΠ²φû€εΗ¨φ€¦ε±ûφÄßγö³û°ÜφùΞεÄιgΗéεΫ™εâçεÄιgΗÄη΅Ώ_(d®Δ)Φ¨φà•εΛöδΗΣε±ûφÄßι½¥γ¦φÄΚ£δΗÄη΅Ώ_(d®Δ)Φ¨φàëδΜ§û°±εΩÖôε’dê¨φ≠ΞεΛçεêàφ™çδΫ?βÄ?εè·ηÉΫφ‰·ε€®δΗÄδΗΣγ≤½Ψ_£εΚΠγö³ιî¹δΗäψÄ?/p>
volatile εQ¨εêΠεà?JMM δΗçδΦö(x®§)ηΠ¹φ±²δΗ΄ιùΔγö³εψ^εèΑφèêδΨ¦εΛ³γêÜεô®ι½¥γö³Ψ~™ε≠‰δΗÄη΅¥φÄß壨ôεΚεΚè‰qûη·èφÄßοΦ¨φâÄδΜΞεΨàφ€âεè·ηÉΫοΦ¨ε€®φüêδΚ¦εψ^εèνCΗäεQ¨φ≤Γφ€âεê¨φ≠ΞεΑ±δΦ?x®§)η·ΜεàΑιôàφ½ßγö³φïΑφç°ψIJφ€âεÖœx¦¥η·ΠγΜÜγö³δΩΓφ¹·οΦ¨η·Ζεè²ι‰?εè²ηÄÉηΒ³φ•?/a>ψÄ?/p>
volatile εç¦_è·δΩùφäΛφïΑφç°ε≠½φ°ΒεQ¦ε€®εÖΕε°ÉφÉÖεÜΒδΗ΄οΦ¨εΩÖιΓΜε€®η·Μφà•εÜôεÖΉÉμnφïΑφç°εâçη·Ζφ±²εä†ιî¹οΦ¨δΗÄδΗΣεΨàεΞΫγö³ΨlèιΣ¨φ‰·φ‰éΦ΄°φ¨΅ε΅όZ΄…γî®δΜÄδΙàιî¹φùΞδΩùφäΛγΜôε°öγö³ε≠½φ°Βφà•ε·Ιη±ΓοΦ¨ρqΕε€®δΫ†γö³δΜΘγ†¹ι΅¨φääε°Éη°ΑεΫïδΗ΄φùΞψÄ?/p>
volatile εQâεè·ηÉΫεΤàδΗçηÉωδΜΞδΩùφäΛδΗÄδΗΣεÖ±δΚΪε≠½¨Dϋc(di®Θn)IJεè·δΜΞηÄÉηôëδΗ΄ιùΔγö³γΛΚδΨ΄οΦö(x®§)
private int foo;
public synchronized int getFoo() { return foo; }
public synchronized void setFoo(int f) { foo = f; }foo ε±ûφÄßεÄϊ|Φ¨δΜΞδΗ΄ε°¨φàêη·ΞεäüηÉΫγö³δΜΘγ†¹û°ΉÉΗçφ‰·γΚΩΫE΄ε°âεÖ®γö³εQ?/p>
setFoo(getFoo() + 1);foo ε±ûφÄßεÄϊ|Φ¨Ψl™φû€εè·ηÉΫφ‰?#160;foo γö³εÄΦεΔûεä†δΚÜ(ji®Θn) 1 φà?2εQ¨ηΩôγîόp°Γφ½ΕεÜ≥ε°öψIJηΑÉγî®ηÄÖεΑÜι€ÄηΠ¹εê¨φ≠ΞδΗÄδΗΣιî¹εQ¨φâçηÉΫι‰≤φ≠ΔηΩôΩUçδΚâγî®φÉÖεÜΒοΦ¦δΗÄδΗΣεΞΫφ•“é(gu®©)≥ïφ‰·ε€® JavaDoc Ψc÷MΗ≠φ¨΅ε°öεê¨φ≠Ξε™ΣδΗΣιî¹οΦ¨‰qôφ†ΖΨc»ùö³ηΑÉγî®ηÄÖεΑ±δΗçι€ÄηΠ¹η΅ΣεΖόq¨€δΚ?ji®Θn)ψÄ?/p>
|
εΠ²φû€φÉÖεÜΒδΗçγΓ°ε°öοΦ¨ηÄÉηôëδΫΩγî®εê¨φ≠Ξε¨ÖηΘÖ
φ€âφ½ΕεQ¨ε€®εÜôδΗÄδΗΣγ±Μγö³φ½ΕεÄôοΦ¨φàëδΜ§ρqΕδΗçγüΞι¹™ε°Éφ‰·εêΠηΠ¹γî®ε€®δΗÄδΗΣεÖ±δΚΪγé·εΔÉ顨ψIJφàëδΜ§εΗ¨φ€¦φàëδΜ§γö³ΨcάL‰·ΨUΩγ®΄ε°âεÖ®γö³οΦ¨δΫÜφàëδΜ§εèàδΗçεΗ¨φ€¦γΜôδΗÄδΗΣφÄάL‰·ε€®εçïΨUΩγ®΄γé·εΔÉεÜÖδ΄…γî®γö³Ψc’dä†δΗäεê¨φ≠Ξγö³η¥üφ΄ÖεQ¨ηĨδΗîφàëδΜ§εè·ηÉΫδΙüδΗçγüΞι¹™δΫΩγqôδΗΣΨcάL½ΕεêàιIJγö³ιî¹γ≤£εΚΠφ‰·εΛöεΛßψIJεΙΗ‰qêγö³φ‰·οΦ¨ιÄöηΩ΅φèêδΨ¦εê¨φ≠Ξε¨ÖηΘÖεQ¨φàëδΜ§εè·δΜΞεê¨φ½ΕηΨΨεàνCΜΞδΗäδΗΛδΗΣγ¦°γö³ψIJCollections Ψc’dΑ±φ‰·ηΩôΩUçφäÄφ€·γö³δΗÄδΗΣεΨàεΞΫγö³ΫCόZΨ΄εQ¦ε°ÉδΜ§φ‰·ιùûεê¨φ≠Ξγö³εQ¨δΫÜε€®φΓÜφûΕδΗ≠ε°öδΙâγö³φ·èδΗΣφéΞεèΘιÉΫφ€âδΗÄδΗΣεê¨φ≠Ξε¨ÖηΘÖοΦàδΨ΄εΠ²εQ?#160;Collections.synchronizedMap() εQâοΦ¨ε°Éγî®δΗÄδΗΣεê¨φ≠Ξγö³γâàφ€§φùΞε¨ÖηΘÖφ·èδΗΣφ•Ιφ≥ïψÄ?/p>
|
ηôΫγ³Ε JLS ΨlôδΚÜ(ji®Θn)φàëδΜ§εè·δΜΞδΫΩφàëδΜ§γö³ΫE΄εΚèΨUΩγ®΄ε°âεÖ®γö³εΖΞεÖχPΦ¨δΫÜγΚΩΫE΄ε°âεÖ®δΙüδΗçφ‰·εΛ©δΗäφéâδΗ΄φùΞγö³ιΠÖιΞΦψÄ²δ΄…γî®εê¨φ≠ΞδΦö(x®§)η£ôεè½φÄßηÉΫφçüεΛ±εQ¨ηĨεê¨φ≠Ξδ΄…γî®δΗçεΫ™εèàδΦ?x®§)δ΄…φàëδΜ§φâΩφ΄ÖφïΑφç°φΖΖδΊïψĹγΜ™φû€δΗçδΗÄη΅¥φà•φ≠Μιî¹γö³ιΘéιô©ψIJεΙΗ‰qêγö³φ‰·οΦ¨ε€®ηΩ΅εé»ùö³ε΅†εΙ¥εÜ?JVM φ€âδΚÜ(ji®Θn)εΨàεΛßγö³φîΙ‰q¦οΦ¨εΛßεΛßε΅èεΑëδΚ?ji®Θn)δΗéφ≠ΘγΓ°δΫΩγî®εê¨φ≠Ξγ¦ΗεÖ≥γö³φÄßηÉΫφçüεΛ±ψIJιÄöηΩ΅δΜîγΜÜεàÜφûêε€®γΚΩΫE΄ι½¥εΠ²δΫïεÖΉÉμnφïΑφç°εQ¨ιIJεΫ™ε€Αεê¨φ≠Ξε·ΙεÖΉÉμnφïΑφç°γö³φ™çδΫ€οΦ¨εè·δΜΞδΫΩεΨ½φ²(zh®®n)®γö³ΫE΄εΚèφ½Δφ‰·ΨUΩγ®΄ε°âεÖ®γö³οΦ¨εèàδΗçδΦ?x®§)φâΩεè½ηΩ΅εΛöγö³φÄßηÉΫη¥üφ΄ÖψÄ?/p>
- φ²(zh®®n)®εè·δΜΞεè²ι‰Öφ€§φ•΅ε€® developerWorks εÖ®γêÉγΪôγ²ΙδΗäγö³ η΄±φ•΅εéüφ•΅.
- η·οL(f®Ξng)²Ιε΅?y®Δn)L•΅γΪ†ιΓΕιÉ®φà•εΚïιÉ®γö?#160;η°®η°Κ‰q¦εÖΞγî?Brian Goetz δΗάL¨¹γö³οΦ¨εÖ≥δΚé“Java ΨUΩγ®΄εQöφäÄεΖßψĹγΣç齮壨φäÄφ€?#8221;γö?#160;η°®η°Κη°Κεù¦ψÄ?#160;
- Jack Shirazi Ψ~•εÜôγö?#160;Java Performance Tuning εQàO'Reilly & Associates, 2000εQâεè·δΜΞδΊ™(f®¥)ε€?Java ρq¦_èΑδΗäηßΘεÜœxÄßηÉΫι½°ιΔ‰φèêδΨ¦φ¨΅ε·ΦψIJφ€§δΙΠεΦïγî®γö³δΗéφ€§δΙΠδΗÄηΒδhèêδΨ¦γö³εè²ηÄÉηΒ³φ•ôφèêδΨ¦δΚÜ(ji®Θn)εΨàεΞΫγö?#160;φÄßηÉΫηΑÉη·ïφäÄεΖ?/a>ψÄ?#160;
- Dov Bulka γö?#160;Java Performance and ScalabilityεQ¨γ§§ 1 εçχPΦö(x®§)Server-Side Programming Techniques εQàAddison-WesleyεQ?000εQâφèêδΨ¦δΚÜ(ji®Θn)εΛßι΅èγö³η°Ψη°ΓφäÄεΖß壨η·ÄΫHçοΦ¨εè·εΗ°εä©φ?zh®®n)®εΔûεΦΚη΅ΣεΖ±γö³εΚîγî®γ®΄εΚèγö³φÄßηÉΫψÄ?#160;
- Steve Wilson ε£?Jeff Kesselman γö?#160;Java Platform Performance: Strategies and Tactics εQàAddison-WesleyεQ?000εQâδΊ™(f®¥)φ€âγΜèιΣ¨γö³ Java ΫE΄εΚèεë‰φèêδΨ¦δΚÜ(ji®Θn)γîüφàêεΩΪιÄüψĹφ€âφïàγö³ Java δΜΘγ†¹γö³φäÄφ€·ψÄ?#160;
- Brian Goetz φ€Ä‰qëγö³ηë½δΫ€“ Double-checked locking: Clever, but broken”εQàJavaWorldεQ?001 ρq?2 φ€àοΦâ(j®Σ)η·ΠγΜÜφéΔγÉΠ(ch®≥)δΚ?JMM ρqΕφèè‰qνCΚÜ(ji®Θn)γâΙε°öφÉÖεÜΒδΗ΄δΗçδΫΩγî®εê¨φ≠Ξγö³φÉäδΚΚεêéφû€ψÄ?#160;
- εÖ§η°Λγö³εΛöΨUΩγ®΄φùÉε®¹ Allen Holub ε€®δΜ•γö³φ•΅γΪ?#8220; η≠ΠεëäεQöεΛöεΛ³γêÜεô®δΗ•γï¨δΗ≠γö³γΚΩΫE?/a>”εQàJavaWorldεQ?001 ρq?2 φ€àοΦâ(j®Σ)δΗ≠φè≠ΫCόZΚÜ(ji®Θn)δΗόZΜÄδΙàγî®δΚéε΅èû°ëεê¨φ≠Ξη¥üφ΄Öγö³εΛßεΛöφïΑφäÄεΖßιÉΫδΗçη™vδΫ€γî®ψÄ?#160;
- Peter Haggar φèèηΩΑδΚ?ji®Θn)φÄéφ†Ζ γî®ε¦Κε°öγö³εQ¨εσ@γé·γö³ôεΚεΚèηéΖεè•εΛöδΗΣιî¹ε°öδΜΞι¹ΩεÖçφ≠Μιî?/a>εQàdeveloperWorksεQ?000 ρq?9 φ€àοΦâ(j®Σ)ψÄ?#160;
- ε€®δΜ•γö³φ•΅γΪ?#8220; Ψ~•εÜôεΛöγΚΩΫE?Java εΚîγî®”εQàdeveloperWorksεQ?001 ρq?9 φ€àοΦâ(j®Σ)δΗ≠οΦ¨Alex Roetter δΜ΄γΜçδΚ?Java Thread APIεQ¨φΠ²φ΄§δΚÜ(ji®Θn)εΛöγΚΩΫE΄φΕâεè?qi®Δng)γö³ι½°ιΔ‰εQ¨εΤàδΗόZΗÄηà§φÄßγö³ι½°ιΔ‰φèêδΨ¦δΚ?ji®Θn)ηßΘεÜœx•ΙφΓàψÄ?#160;
- Doug Lea γö?#160;Concurrent Programming in JavaεQ¨γ§§ 2 γâ?/em> εQàAddison-WesleyεQ?999εQâφ‰·εÖ≥δΚé Java η·≠η®ÄδΗ≠εΛöΨUΩγ®΄Ψ~•γ®΄γö³φïèφ³üι½°ιΔ‰γö³φùÉε®¹δΙΠγ±çψÄ?#160;
- “ εê¨φ≠Ξε£?Java εÜÖε≠‰φ®Γεû΄”φë‰εΫïη΅?Doug Lea γö³εÖ≥δΚ?#160;
synchronizedγö³ε°ûιôÖφ³èδΙâγö³ηë½δΫ€ψÄ?#160;
- Bill Pugh γö?#160;Java εÜÖε≠‰φ®Γεû΄δΗΚφ?zh®®n)®ε≠ΠδΙ?f®Λn) JMM φèêδΨ¦δΚ?ji®Θn)δΗÄδΗΣεΨàεΞΫγö³ηΒοL(f®Ξng)²ΙψÄ?#160;
- “Double Checked Locking is Broken”εΘΑφ‰éφèèηΩΑδΚ?ji®Θn)δΊ?f®¥)δΜÄδΙ?DCL ε€®γî® Java η·≠η®Äε°ûγéΑφ½Εφ≤Γφ€âγî®ψÄ?#160;
- Bill JoyψĹGuy Steele ε£?James Gosling γö?#160;The Java Language SpecificationεQ¨γ§§ 2 γâ?/em> εQàAddison-WesleyεQ?000εQâγö³ΫW?17 γΪ†φèè‰qνCΚÜ(ji®Θn) Java εÜÖε≠‰φ®Γεû΄γö³φΖ±ε±²γΜÜηä²ι½°ιΔ‰ψÄ?#160;
- IBM T.J. Watson γ†îγ©ΕδΗ≠εΩÉ(j®©)φ€âδΗÄφï¥δΗΣôεΙγ¦°Ψl³φäïεÖΞεàΑ φÄßηÉΫΫéΓγêÜδΗ≠ψÄ?#160;
- η·Ζε€® developerWorks Java φäÄφ€·δΗ™ε¨?/a>φüΞφâΨφ¦¥εΛöγö³εè²ηÄÉηΒ³φ•ôψÄ?#160;
|
Brian Goetz φ‰·δΗÄεêçη YδΜâôΓΨι½°οΦ¨ρqΕδΗî‰q΅εéΜ 15 ρq¥φùΞδΗÄ㦥φ‰·δΗ™δΗöγö³η YδΜΕεΦÄεèëδùhεë‰ψIJδΜ•φ‰?#160;QuiotixεQ¨δΗÄε°ΕεùêηêΫε€® Los AltosεQ¨California γö³η YδΜΕεΦÄεèë壨壮η·ΔεÖ§εèΗγö³ιΠ•εΗ≠ιΓΨι½°ψIJη·ΖιÄöηΩ΅ brian@quiotix.com δΗ?Brian η¹îγ≥ΜψÄ?/p> |
||