如題,前面已經有人整理過1.5版本的源代碼,但有些人回復說想要1.6的。
今天剛好試了一下各版本源代碼,運行良好。所以簡單的整理了一下下載連接和安裝方法。希望能用得上。
1.android下載
▼android-1.5的下載地址有如下
http://rgruet.free.fr/public/android-1.5-cupcake-src.zip (21.6MB)
http://www.mediafire.com/file/awnzktte2wy/android-1.5-cupcake-src.zip
▼android-1.6的下載地址有如下
http://rgruet.free.fr/public/android-1.6_r1-donut-src.zip (23MB)
http://sandos.se/~sandos/android-1.6_r1-donut-src.zip
http://www.droidnova.com/android-sdk-1-6-donut-sources,511.html
▼android-2.0的下載地址有如下
http://rgruet.free.fr/public/android-2.0-eclair-src.zip (24.4MB)
2.android安裝
▼在各個版本的sdk下面創建新文件夾sources,如下
android_sdk_installation_folder\platforms\android-1.5\sources
android_sdk_installation_folder\platforms\android-1.6\sources
android_sdk_installation_folder\platforms\android-2.0\sources
▼把下載后的zip解壓縮到上面的sources下面,重新啟動eclipse即可查看。
注:上面三個版本本人都測試過,都運行良好。
如果上面的鏈接下載不了的話,我可以把我下載好的打包上傳上來。你們先試一下吧。
]]>
當第一次啟動一個Android程序時,Android會自動創建一個稱為“main”主線程的線程。這個主線程(也稱為UI線程)很重要,因為它負責把事件分派到相應的控件,其中就包括屏幕繪圖事件,它同樣是用戶與Andriod控件交互的線程。比如,當你在屏幕上按下一個按鈕后,UI線程會把這個事件分發給剛按得那個按鈕,緊接著按鈕設置它自身為被按下狀態并向事件隊列發送一個無效(invalidate)請求。UI線程會把這個請求移出事件隊列并通知按鈕在屏幕上重新繪制自身。
單線程模型會在沒有考慮到它的影響的情況下引起Android應用程序性能低下,因為所有的任務都在同一個線程中執行,如果執行一些耗時的操作,如訪問網絡或查詢數據庫,會阻塞整個用戶界面。當在執行一些耗時的操作的時候,不能及時地分發事件,包括用戶界面重繪事件。從用戶的角度來看,應用程序看上去像掛掉了。更糟糕的是,如果阻塞應用程序的時間過長(現在大概是5秒鐘)Android會向用戶提示一些信息,即打開一個“應用程序沒有相應(application not responding)”的對話框。
如果你想知道這有多糟糕,寫一個簡單的含有一個按鈕的程序,并為按鈕注冊一個單擊事件,并在事件處理器中調用這樣的代碼Thread.sleep(2000)。在按下這個按鈕這后恢復按鈕的正常狀態之前,它會保持按下狀態大概2秒鐘。如果這樣的情況在你編寫的應用程序中發生,用戶的第一反應就是你的程序運行很慢。
現在你知道你應該避免在UI線程中執行耗時的操作,你很有可能會在后臺線程或工作者線程中執行這些耗時的任務,這樣做是否正確呢?讓我們來看一個例子,在這個例子中按鈕的單擊事件從網絡上下載一副圖片并使用ImageView來展現這幅圖片。代碼如下:
public void onClick( View v ) {
new Thread( new Runnable() {
public void run() {
Bitmap b = loadImageFromNetwork();
mImageView.setImageBitmap( b );
}
}).start();
}
這段代碼好像很好地解決了你遇到的問題,因為它不會阻塞UI線程。很不幸,它違背了單線程模型:Android UI操作并不是線程安全的并且這些操作必須在UI線程中執行。在這段代碼片段中,在一個工作者線程中使用ImageView的方法,這回引起一些很古怪的問題。查處這個問題并修復這個bug會很困難而且也很耗時。
Andriod提供了幾種在其他線程中訪問UI線程的方法。或許你已經對其中的一些方式很熟悉,但下面是一個更全面的列表:
- Activity.runOnUiThread( Runnable )
- View.post( Runnable )
- View.postDelayed( Runnable, long )
- Hanlder
上面的任何一個類或方法都可以修復我們前面代碼中出現的問題。
onClick( View v ) {
new Thread( new Runnable() {
public void run() {
final Bitmap b = loadImageFromNetwork();
mImageView.post( new Runnable() {
mImageView.setImageBitmap( b );
});
}
}).start();
}
很不幸的是這些類或方法同樣會使你的代碼很復雜很難理解。然而當你需要實現一些很復雜的操作并需要頻繁地更新UI時這會變得更糟糕。為了解決這個問題,Android 1.5提供了一個工具類:AsyncTask,它使創建需要與用戶界面交互的長時間運行的任務變得更簡單。
在Android 1.0和1.1中具有與AsyncTask相同功能的類UserTask。它提供了完全一樣的API,你需要做的只是把它的代碼拷貝的你的程序中。
AsyncTask的目標是替你管理你的線程。前面的代碼可以很容易地使用AsyncTask重寫。
public void onClick( View v ) {
new DownloadImageTask().execute( "http://example.com/image.png" );
}
private class DownloadImageTask extends AsyncTask {
protected Bitmap doInBackground( String... urls ) {
return loadImageFormNetwork( urls[0] );
}
protected void onPostExecute( Bitmap result ) {
mImageView.setImageBitmap( result );
}
}
正如你看到的,使用AsyncTask必須要繼承它。使用AsyncTask非常重要的是:AsyncTask的實例必須在UI線程中創建而且只能被使用一次。你可以使用預讀AsyncTask的文檔來來了解如何使用這個類,下面大概地了解一下它是如何工作的:
- 你可以使用泛型參數制定任務的參數、中間值(progress values)和任何的最終執行結果
- doInBackground()方法會自動地在工作者線程中執行
- onPreExecute()、onPostExecute()和onProgressUpdate()方法會在UI線程中被調用
- doInBackground()方法的返回值會被傳遞給onPostExecute()方法
- 在doInBackground()方法中你可以調用publishProgress()方法,每一次調用都會使UI線程執行一次onProgressUpdate()方法
- 你可以在任何時候任何線程中取消這個任務
除了官方的文檔,你可以閱讀Shelves和Photostream源代碼中的幾個復雜的示例。我強烈地推薦閱讀Shelves的源代碼,它會使你知道如何在配置更改之間持久化任務以及在activity被銷毀時正確的取消任務。
不管是否使用AsyncTask,始終記住以下兩個關于單線程模型的準則:不要阻塞UI線程以及一切Android UI操作都在UI線程中執行。AsyncTask僅僅是使你能夠更容易地遵守這兩條準則。
ApiDemos] Device API version is 3 (Android 1.5)
Q: AndroidManifest.xml中需指定users sdk <uses-sdk android:minSdkVersion="3"/>
A2: 模擬器設置上網代理
Q:啟動模擬器時使用: emulator -avd your_avd_name -http-proxy http://name:password@10.10.10.10:3128
或者參考這里: 只加一次每次可用
解決 Android 模擬器 無法上網問題 http://www.javaeye.com/topic/521023
關鍵就是執行
sqlite3 /data/data/com.android.providers.settings/databases/settings.db "INSERT INTO system VALUES(99,'http_proxy','10.193.xx.xx:1080')"
A3: Installation failed due to invalid APK file!
Q:在Eclipse中啟動某應用的時候,出現如上錯誤. Installation failed due to invalid APK file! LogCat提示如下錯誤如下:
01-26 07:59:28.466: ERROR/PackageParser(567): parsePackageName error: <manifest> specifies bad package name "com.android._ButtonStyle1": bad character '_'
01-26 07:59:28.466: ERROR/PackageManager(567): Couldn't find a package name in : /data/app/vmdl24363.tmp
按照上面的提示,修改包名即可.
A4: 啟動AVD的時候出現的問題:Failed to find an AVD compatible with target 'Android 1.6' ,no compatible AVDs with target.
Q:原因是AVD不在啟動路徑中,解決的辦法找到".android"文件夾拷貝到貝到C:\Documents and Settings\當前用戶下.修改下.android/avd里面以avd名命名的.ini文件中的path屬性,修改為avd文件所在的位置.重啟即可.
A5:Android出現Waiting for sdk to finish loading的解決辦法
Q:原因是:你的Java編譯環境和運行環境不對。
解決辦法:在WIndows下面使用統一的Java環境,我之前編譯是JDK1.6,運行是JRE1.5。都調整為1.6就好了。
A6:Android官方網站無法訪問,怎么辦?
Q:訪問官網鏡像: http://androidappdocs.appspot.com/sdk/index.html 即可.
A7:某些String.xml導入后出現如下錯誤提示:
Description Resource Path Location Type
error: Apostrophe not preceded by \ (in Search' Titles) strings.xml /WikiNotes/res/values line 30 Android AAPT Problem
Q:原因符號”' ”,在xml中需要轉義。只要將”' ” 修改為”\'”即可解決.
A8:Android訪問本地IP(localhost)
Q:Android模擬器啟動后,默認IP為localhost,而PC端loaclhost被映射為10.0.2.2.
]]>
1. 申請一張支持Visa 或者 Master的國際信用卡. 注冊Google checkout 需要使用到.
Visa的相關介紹:
2. 注冊Google賬號. 申請一個Google Mail賬號即可(大家都應該有了)
正式流程:
1. 注冊Google Checkout. http://checkout.google.com/. 注冊時Local可能沒有China,選擇Hongkong就好.
2.開通Android Market. 到 http://market.android.com/publish/signup 填寫基本信息,并通過你的CheckOut綁定信用卡支出25刀即可.Android Market是不需要審核的,申請成功即可發布應用了.
流程沒有想象的復雜,希望大家都能加入.
]]>
Q:你的設計一貫以「簡約」為基調。為什么相對于使用更多圖像的方式,你傾向于此?
A:我相信一個優秀的網頁介面應該是優雅含蓄的,從而將內容本身推向前臺。一名設計師必須牢記,多數情況下,用戶瀏覽一個網站并非為了欣賞你天馬行空的設計,而是做一件對他們有用的事。我很喜歡艾倫·庫珀的一句話:「無論你的介面有多酷,簡單一點總會更好」。
感悟: 任何事情都要找出真正的需要,而不要被表面的符號所迷惑.
Q:對于躊躇于事業發展的年輕設計師們,你有什么建議?
A:我建議他們做自己的項目。不要期待優質客戶讓你參與到好的項目中,這樣的事情基本輪不到年輕人。現在就動手自己做點什么,你會學到很多,也會得到很多。
感悟: 少點期待,多點實干,人生確是如此的.(自嘲:還沒老到要考慮養老吧!)
]]>
轉眼來深圳一年半了,和以前有了些變化,回顧并記錄之.
]]>
這段代碼是通過lightbox2.02的源代碼里面學習來的,主要要注意的地方是如果用overlayer包裹loadlayer層的話,loadlayer層會繼承overlayer層的透明屬性,而且這種繼承后的透明屬性很難屏蔽掉,比如在loadlayer上重新定義透明,新定義的透明不會有預期的效果.所以處理的時候必須要overlayer與loadbox分離來,單獨來處理就不會出現上面的情況了.
效果:

具體代碼如下:
1: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
2: <html xmlns="http://www.w3.org/1999/xhtml">
3: <head>
4: <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
5: <title>loading demo</title>
6: <script type="text/javascript">
7: function show(){
8: var loadbox =document.getElementById("loadlayer");
9: var overlayer = document.getElementById("overlayer");
10: loadbox.style.display = "block" ;
11: overlayer.style.display = "block" ;
12: }
13:
14: function hide(){
15: var loadbox =document.getElementById("loadlayer");
16: var overlayer = document.getElementById("overlayer");
17: loadbox.style.display = "none" ;
18: overlayer.style.display = "none" ;
19: }
20: </script>
21:
22: <style type="text/css">
23: #overlayer{
24: position: absolute;
25: top: 50px;
26: left: 0;
27: z-index: 90;
28: width: 100%;
29: height: 100%;
30: background-color: #000;
31: filter:alpha(opacity=60);
32: -moz-opacity: 0.6;
33: opacity: 0.6;
34: display:none;
35: }
36:
37: #loadbox{
38: position: absolute;
39: top: 40%;
40: left: 0;
41: width: 100%;
42: z-index: 100;
43: text-align: center;
44: }
45:
46: #loadlayer{
47: display:none;
48: }
49:
50: </style>
51: </head>
52: <body>
53: <div id="overlayer"></div>
54: <div id="loadbox" >
55: <div id="loadlayer">
56: <img src="loading.gif" />
57: </div>
58: </div>
59: <div id="containlayer">
60: <input type="button" value="show" onclick="show()" />
61: <input type="button" value="hide" onclick="hide()"/>
62: <br />
63: <br />
64: --------------------------------------------------------------------<br />
65: --------------------------------------------------------------------<br />
66: 具體的網頁內容.寫在這里,上面通過一個半透明層遮蔽下面的內容<br />
67: </div>
68: </body>
69: </html>
]]>
方法大致如下:
1、從主窗口中選擇“工具”選項,然后點擊“Java平臺控制器”。
2、在對話框的左面板中,選擇要添加JavaDoc的平臺。
3、在“JavaDoc”標簽中,單擊“添加ZIP/文件夾”,然后指定JavaDoc文件的位置。
4、關閉對話框。
這樣就算完成。當選擇對應的代碼,使用快捷鍵Alt+F1時,就可以在瀏覽器中打開對應的幫助信息了。
如果這樣能解決我也就不記在這里了.
我在Netbeans6.01下面嘗試導入javadoc和src都沒有成功.
最后成功導入的辦法記錄在下面.
1.從主窗口中選擇“工具”選項,然后點擊“庫”。
2.添加一個在對話框左面板中添加庫,右面板中依次添加 jar,src,javadoc.
3.關閉對話框.
這樣如果導入的內容沒有問題的話,應該就可以通過ctrl+shift+b查看相關方法的源代碼,通過Alt+F1查看相關方法的Javadoc了.
]]>
------引于郭士納《誰說大象不能跳舞》
]]>
一、XML
在十種技術中,最重要的一種技術我想應該非XML莫屬。這里不僅僅指XML規范本身,還包括一系列有關的基于XML的語言:主要有XHTML,XSLT,XSL,DTDs,XML Schema(XSD),XPath,XQuery和SOAP.如果你現在還對XML一無所知,那么趕快狂補吧。XML是包含類似于HTML標簽的一個文本文件,在這個文件中定義了一個樹型結構來描述它所保存的數據。
XML最大的優點是你既可以在這個文本文件中存儲結構化數據,也可以在其中存儲非結構化數據——也就是說,它能包含和描述"粗糙的"文檔數據,就象它描述"規則的"表格數據一樣。
XHTML是目前編寫HTML的首選方法;因為XHTML本身就是格式良好的XML,與通常畸形的HTML文檔相比, XHTML格式文檔更容易處理。
XSLT和XSL是對XML文檔進行轉換的語言。它們可以將XML文檔轉換成各種格式,比如另一個文本文件、PDF文件、HTML文件、逗號分割的文件,或者轉換成其它的XML文檔。
DTDs 和XML Schema用來描述XML文件所包含的數據內容的類型,使你不用編寫定制的代碼就能對XML文檔的內容進行"有效性"檢查,使內容強行遵守給出的規則。
XPath 和 XQuery是查詢語言,用它們可以從XML文檔中吸取單個的數據項或者數據項列表。XQuery的功能特別強大,因為它對XPath查詢進行了擴展。實際上,XQuery和XML的關系就像SQL之于關系數據庫一樣。
SOAP是Web services間進行通訊的標準協議。你不必知道SOAP協議的所有細節,但是你應該熟悉其常用規則及其工作原理,這樣你才能使用它。
二、Web Services
Web服務是XML流行后的直接產物。因為XML可以描述數據和對象,XML大綱可以保證XML文檔數據的有效性,因為XML的基于文本的規范,因而XML文檔極其適合于作為一種跨平臺通訊標準的基本格式。如果你還沒有接觸過Web服務,那么過不了多久你肯定會碰到它,所以必須熟練掌握Web服務,最好是精通它,因為它是迄今為止應用程序間跨不同種類機器、語言、平臺和位置通訊的最簡單的一種方式。不管你需不需要它,Web服務都會是將來互用性的主要趨勢。
XML工作組的John Bosak曾說過:"XML使得Java有事可做",那么,我們也可以說,Web服務使得所有語言都有事可做。Web服務讓運行在大型機上的COBOL應用程序與運行在手持設備上的應用程序相互溝通;讓Java小應用與。NET服務器相互通訊,讓桌面應用與Web服務器進行無縫交互,不但為商業數據處理,同時也為商業功能提供了方便的實現——并且這種實現與語言、平臺、和位置無關。
三、面向對象編程
許多程序員仍然認為OOP乃技術的象牙之塔,但是細細想一下過去十年里在面向對象領域里占據過統治地位的開發語言之后,你就不會這么認為了,OOP理念從Smalltalk開始,然后蔓延到C++和Pascal(Delphi),到Java成為真正的主流,幾年之后,VB.NET 和 C#的出現可以說是OOP發展到了登峰造極的地步。雖然使用這些語言不必了解OOP的概念,但如果你缺乏一些OOP的基本知識和方法,我想你很難在逐漸疲軟的就業市場中找到工作。
四、Java, C++, C#, VB.NET
如果你熱衷于技術,并且熱愛編程,那么我想你應該輕松玩轉這些高級語言,我說的玩轉并不一定要你成為超級編程高手。而是能看懂用這些語言編寫的代碼即可。如果你還有精力用它們編碼那就更好了。其實這種機會甚少。但是看代碼的機會很多,學習編程的最有效的一種方式就是看源代碼——浩如煙海的源代碼中很多都不是用你所鐘愛的開發語言編寫的。
在過去的幾年里,各個語言功能的發展基本上都差不多。現在你完全可以用VB.NET來寫Windows服務、Web應用或者命令行程序。即使你只用其中的一種語言寫程序。我認為也完全有必要學習另外一種語言,使自己能閱讀和理解它們現有的例子代碼,并且能將一種語言編寫的代碼轉換成你首選的編程語言代碼。這里列出的四種語言可謂是一個強大的開發語言工具箱,如果你掌握了它們,毫無疑問你一定是一個眾人仰慕的高手。這里我要聲明一下:那就是我并沒有要忽略和排除其它的高級語言,如:FORTRAN、COBOL、APL、ADA、Perl和Lisp等等,根據你所從事的領域不同,應該選擇適合的語言和工具。
五、JavaScript
Java 和JavaScript兩者的名字盡管很類似,但它們之間并沒有什么關系。為什么一種腳本語言會如此重要,以至于將它列入十種關鍵技術之一呢?仔細想一下就知道了,目前所有主流的瀏覽器都使用JavaScript.如果你要編寫Web應用程序,那么JavaScript不可或缺。此外,JavaScript還能作為一種服務器端的腳本語言,如將它嵌入在ASP、ASP.NET中,或者嵌入XSLT來擴展功能。目前JavaScript在Mozilla/Netscape中是激活基于XUL界面的首選語言,它派生出了ActionScript,成為Flash MX應用的編程語言。還有就是JavaScript極有可能成為未來新設備的腳本語言以及主流應用的宏語言。
相比之下,VBScript雖然在微軟的產品中得到很好的支持,但從長遠來看,沒有跡象表明它會有美好前途。微軟自己都趨向于用JavaScript(或者用由JavaScript派生的JScript)來編寫其客戶端腳本代碼。因此,如果你要選擇腳本語言,非JavaScript莫屬。
六、Regular Expressions
從所周知,關系數據庫的查詢使用SQL,搜索XML文檔用XPath 和XQuery,而正則表達式則用來搜索純文本。例如,你可以用一個命令來查找或刪除HTML格式文件中的注釋內容。大家都用過"IndexOf"、"InStr"以及"Like"這些內建在JavaScript或VB中的文本搜索函數,這些函數雖然很容易使用,但是它們的功能卻無法與正則表達式同日而語——現在每一種主流的開發語言都提供對正則表達式的存取。盡管有人認為正則表達式本身的讀寫艱澀難懂,但畢竟它的功能強大,使用它的領域也越來越多。
七、Design Patterns
就像OOP通過創建和分類對象來簡化編程一樣,設計模式將普通的對象交互分類成指定的模型,這是一個從一般到具體的過程。OOP的成分使用得越多,設計模式就顯得越有用武之地。所以你必須理解它們,跟上其總體理論的發展。
八、Flash MX
當你需要比HTML和CSS所能提供的更多的客戶端圖形和編程能力時,Flash是最佳選擇。在Flash中編程比用Java小應用或者。NET代碼來得快得多,也容易得多。
在最新版本中(MX),Flash不僅可以畫圖和進行動畫打包,它還是個高度的可編程應用環境。具備強大的與SOAP Web服務溝通的能力,可以調用運行在遠端服務器上的ColdFusion、Java或。NET代碼。可以說Flash幾乎無處不在,包括手持設備、置頂盒、甚至是新的平板電腦,你到處都可以見到它的身影,所以使用它實際上可以擴展和延伸你的應用程序使用領域。
九、Linux/Windows
這是當今PCs機操作系統的兩大陣容,如果你想在計算機行業里混,就一定要熟悉它們。對于Linux,最好能自己安裝,配置,下載它的圖形用戶界面以及一些應用程序。自己安裝Apache并會編寫Web應用程序。要清醒地認識到這個世界除了Windows之外,還有Linux的存在。并且這種局面將會長期存在。反過來,如果你是一個死忠的Linux開發者,不要再繼續對Windows的憎惡,要相互學習,取長補短,看看Windows有什么好的東東可以采納。記住Windows仍然是桌面之王。
誰也說不準你們公司什么時候會決定從Linux轉向Windows,或者從Windows轉向Linux.誰也說不準什么時候你會跳槽跑到另外一個使用不同平臺的公司上班——或者即便不跳槽,也有可能在不同平臺上開始另外一個殺手級項目——所以最好在每個平臺上都積累一些經驗,而不要在一棵樹上吊死。
十、SQL
盡管SQL在當今眾多的技術中已不是什么新東西,而且在未來的十年里它的作用很有可能被削弱,甚至整個被淘汰,但它仍然是一種基本技能——別看它是一種基本技能,至今仍有許多開發人員不懂什么是SQL或對它了解不多。不要指望基于圖形用戶界面的SQL構造器會幫你的忙,還是自己親手寫SQL查詢吧,確定你掌握了SQL的基本語法。現在理解了SQL,不僅對以后學習XQuery有所裨益,而且可以使你很快找到簡化或改進當前開發項目的途徑。
尾聲:培養對技術的好奇心
其實,不管技術的發展趨勢如何,每個人最重要的一個技能是好奇心。敢于面對挑戰,在你目前或未來的工作中,新語言或新技術可能很重要,也可能不怎么重要,你所學習的東西并不一定非要針對你的工作。不要怕失敗,任何新的技術對初學者來說都是困難的。大多數的失敗都可以歸咎于本身急功近利,希望速成。俗話說——千里之行,始于足下,應該腳踏實地,一步一個腳印地往前走。不要讓時間來左右你行動,而是要利用時間來關注、研究、測試新的開發技術和工具。
]]>
下面為轉貼,原帖在這里。
給各位觀眾簡單介紹一下青龍寺。
青龍寺建于隋文帝開皇二年(528年),原名靈感寺,唐睿宗時期(711年)改名為青龍寺。它是唐代著名的佛寺之一,也是日本佛教真言宗的祖庭。青龍寺是日本人心目中的圣寺,日本從9世紀初起,曾派遣大批留學僧人到唐朝求法,其中以空海最著名。空海在青龍寺師從于密宗大師惠果,后將其傳入日本,同時還把中國的文字書法,灌溉技術傳回日本,并根據漢字創造了日文中的“片假名”促進了中日間的經濟文化交流。青龍寺從宋代以后就已經蕩然無存了,解放后經過勘察發據,探出了門塔,殿堂和廊廡等七處遺址,同時出土了部分文物。
1982年,中日兩國在青龍寺遺址共同興建了空海紀念碑和空海紀念堂,以紀念和發揚這位友好使者的精神。1986年,青龍寺保管所又從日本引進了萬株櫻花。每年櫻花盛開的時候,這里格外吸引游人。(資料參考:《自游西安及周邊》)
走走走走走走,我們一同去郊游
青龍寺的浪漫櫻花海,還有一對新人在照婚紗照


我喜歡的楊貴妃近照(櫻花科系的一種)



我們登上了寺中閣樓


舊唐回廊里,偉大的惠果大師和空海大師也就是我們大唐與日本大和的故事。空海大師即使日本的“孔子”。

歷代有許多文人墨客很喜歡在青龍寺留下自己的詩跡,還記得李商隱(李義山)那首千古佳作《樂游原》嗎?
向晚意不適,驅車登古原。夕陽無限好,只是近黃昏。

“樂游原”即為此地。因漢宣帝曾在此地建造樂游苑,故又名樂游原。傳說唐代大詩人白居易,舒元輿等都曾在青龍寺北住過。白居易在《青龍寺早夏》里描繪青龍寺的地勢和風景日:“丹鳳樓當后,青龍寺在前。市街塵不到,宮樹影相連”。
再者,密宗的一些教徒喜歡到此地切磋密宗的咒語和幻術,青龍寺便成為密宗咒語幻術傳播的源泉。圖片是我永遠也看不懂的密語宗書。

再來就是白丁香下的小吃街,我們在大樹底下吃吃喝喝

寺里隨處可見的歷史遺跡,提醒我們中日兩個民族始終保持著友好的關系。
好了,到這里了,就到這里.
]]>
來個圖:

動作分解:
<傳言看源代碼理解的更細致,不過偶沒看,偶是根據文檔和下午的操作總結的,錯了請指正。>
1.創建空數據庫Webdb:
2.向Webdb中注入入口攫取地址:
3.根據Webdb中數據生成fetchlist,并生成相應的segment。
4.根據fetchlist攫取內容(fetched content)。
5.根據獲取內容更新Webdb
6.重復執行3-5.這個過程52se稱為“產生/抓取/更新”循環。
7.完成上面的循環后,根據Webdb中信息,如網頁評分和鏈接信息等,再次更新segment.
8.索引被攫取的頁面,生成鏈接。
9.去除indexes中重復的內容和鏈接。
10.依靠indexes合成單一的index文件。大功告成。
上面這些步驟都可以對應到Nutch給我們提供的CrawlTool中的命令上。
爬蟲忙完了,有了數據,我們就可以利用Nutch的search部分功能來查找內容了。
Introduction to Nutch, Part 1: Crawling
]]>
1.爬蟲工作的過程?
2.爬蟲獲取數據后,數據的存儲結構?
3.數據如何索引成Lucene設定的索引格式?
上午干工作耽誤了,下午得閑,看點資料。試簡單總結一下上面幾個問題的。
先回答2號問題,數據的存儲結構好了。
Nutch把爬蟲找回來的資料做成了放在一個文件夾里面,美其名曰Web database。其實里面分別就四個文件夾了事。依次道來:
- crawldb:存放需要抓取的的超鏈接地址;
- segments:存放依據crawldb中提供的地址抓取到的內容信息。segments中的每個子文件夾存儲fetcher根據crawldb抓取一次所得的內容。這些抓取的內容包括有content、crawl_fetch、crawl_generate、crawl_parse、parse_data、parse_text。其中content是抓取下來的網頁內容;crawl_generate根據crawldb最初生成;crawl_fetch、content在抓取時生成;crawl_parse、parse_data、parse_text在解析抓取的數據文件時生成。其中crawl_generate、crawl_fetch和crawl_parse是crawldb的部分url數據,它們格式一樣,不同的是抓取時間、狀態、簽名等有所變化。
- Index和indexes:Index是最終我們所需要得到的東西,而Index就是通過indexes合并的到的。
- Linkdb:linkdb中存放的是所有超鏈接及其每個鏈接的連入地址和錨文件。
好了這個存儲結構的問題完成了。
抽空先寫這么多,呆會有時間在繼續。
]]>
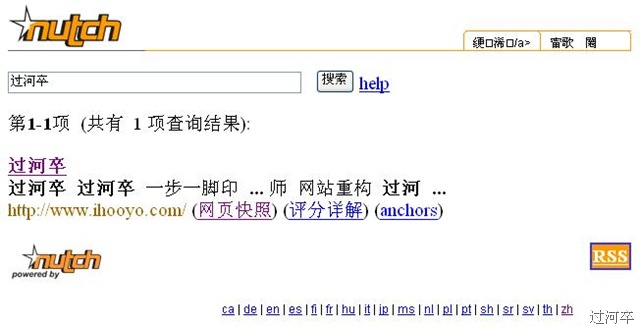
網絡上面介紹這個配置的比較多,我就不重復勞動了。
推薦文檔如下:Nutch Version 0.8x tutorial ,還有就是這里的篇日志。
我在這里記錄一下遇到的幾個錯誤和解決辦法,大家可能有用。
如執行如下命令:
./nutch crawl ../urls.txt -dir ../ihooyo -depth 5 -topN 100
參數說明:
-url 就是剛才我們創建的url文件,存放我們要抓取的網址
-dir 指定抓取內容所存放的目錄,如上存在mydir中
-threads 指定并發的線程數
-depth 表示以要抓取網站頂級網址為起點的爬行深度
-topN 表示獲取前多少條記錄,可省
可能錯誤1:
Generator: jobtracker is 'local', generating exactly one partition.
Generator: 0 records selected for fetching, exiting ...
Stopping at depth=0 - no more URLs to fetch.
No URLs to fetch - check your seed list and URL filters.
crawl finished: sina5
說明:指定要抓取的網址(url.txt)經過(crawl-urlfilters.xml)過濾后,已經沒有可抓取對象了,檢查兩者的匹配即可。
可能錯誤2:
Dedup: starting
Dedup: adding indexes in: ../ihooyo/indexes
Exception in thread "main" java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:604)
at org.apache.nutch.indexer.DeleteDuplicates.dedup(DeleteDuplicates.java:439)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:135)
說明:一般為./conf/nutch-site.xml文件配置有錯誤。請參考如下配置修改。
[xml]
<property>
<name>http.agent.name</name>
<value>ihooyo</value>
<description></description>
</property>
<property>
<name>http.agent.description</name>
<value>apersonblog</value>
<description></description>
</property>
<property>
<name>http.agent.url</name>
<value>www.ihooyo.com</value>
<description></description>
</property>
<property>
<name>http.agent.email</name>
<value>pjuneye@qq.com</value>
<description></description>
</property>
[/xml]
這種配置錯誤,在log日志中可找到提示。
可能錯誤3:
Injector: Converting injected urls to crawl db entries.
Exception in thread "main" java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:604)
at org.apache.nutch.crawl.Injector.inject(Injector.java:162)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:115)
說明:一般為crawl-urlfilters.txt中配置問題,比如過濾條件應為
+^http://www.ihooyo.com ,而配置成了 http://www.ihooyo.com 這樣的情況就引起如上錯誤。
好了寫完了。
]]>
搞明白的幾個問題:
1.Nutch到底是什么?
Nutch是一個開源的Java語言實現的搜索引擎。它通過完整功能的搜索系統。
2.Nutch和Lucene到底是什么關系?兩者如何取舍?
Nutch基于Lucene,Lucene為Nutch提供文本索引和搜索API。兩者的取舍問題在于Lucene不能夠為你抓取數據,所以如果在有數據源的情況下最好的方式是使用Lucene API來建立索引,完成搜索。如果需要抓取數據的話,那自然是選擇Nutch為好。
3.Nutch的基本安裝步驟?
這個問題有官方文檔。在這里。
PS:似乎網絡Nutch上最多的帖子就是關于這個的.其中比較有意思的就是擺脫Cgywin的一些方法,比如利用window批處理或者利用ant.個人還是覺得ant更通用.
4.Nutch的基本組成?
Nutch基本上兩部分組成:抓取部分和搜索部分。抓取程序抓取頁面并將抓取回來的數據做成反向索引;搜索程序則將反向索引搜索回答用戶的請求。兩者的關聯部分在于索引。
具體內容還需要仔細看文檔和介紹.
5.Nutch文檔集中地?
http://wiki.apache.org/nutch/
補充完成,今日繼續。愚人節快樂!
]]>