]]>
]]>
1.TheServerside.com? 依然是地位無可動搖的CCTV1。
2.InfoQ.com Floyd Marinescu 在離開 TSS 后另起爐灶,2006年中最重要推薦。視野不再局限于Java 而是包括Java,.Net, Ruby ,SOA, Agile方法等熱門話題。
3.JDJ的電子雜志?在JDJ首頁的最底處訂閱,文章質量不低于5-7的傳統三強。
4.SWik.net? 收集了大量OpenSource Project的資源聚合。其中如Spring,Hibernate的更新度非常高,出現什么和Spring有關的blog,article,project都會馬上被聚合。
5.IBM DeveloperWorks?傳統、穩定的Java文章來源地。
6.JavaWorld 傳統、穩定的Java文章來源地。
7.OnJava? 傳統、穩定的Java文章來源地。
8.Artima.com?類似于TSS而略遜,其中Spotlight 文章值得關注,而Java News是聚合了所有其他Java站點的大聚合。
9.JavaLobby? 站內的Announcements?是大大小小Java? Project的發布聲明區,Trips and Tricks?有很多的Tips。
10. No Fluff Just Stuff 的Blogs 聚合 一直缺一個所有優秀Java Blogger的rss總聚合,NFJS這里勉強算一個。
]]>
這里討論下 新手學習,高手指教 一起研究下
(以 tomcat mysql 做例子 我推薦所有的編碼采用utf-8)
1 工程
工程內所有的 .java .jsp .xml .txt 都有默認的編碼 默認的是系統環境的編碼
我們中文系統通常是GBK 推薦都采用utf-8
utf-8 的時候 你編譯 生成doc 可能會遇到亂碼(特別是采用ant 的時候,生成doc你幾乎100%會遇到)
解決方法 以ant 為例子
編譯 注意 encoding 參數
<target name="build" >
? ? ? ?<mkdir dir="${build.dir}" />
? ? ? ?<javac encoding="utf-8" destdir="${build.dir}" target="1.3" debug="true" deprecation="false" optimize="false" failonerror="true">
? ? ? ? ? ?<src path="${src.dir}" />
? ? ? ? ? ?<classpath refid="master-classpath" />
? ? ? ?</javac>
? ?</target>
生成doc 注意 encoding 和 charset
<target name="doc">
<mkdir dir="doc" />
<javadoc charset="utf-8" encoding="utf-8" packagenames="${packages}" sourcepath="src" destdir="doc" author="true" version="true" use="true" splitindex="true" >
<classpath refid="master-classpath" />
</javadoc>
</target>
這里 的encoding 就是指的你 java 文件的編碼格式 javac 和javadoc 都有這個參數
charset 指的是 生成 doc 后的編碼方式 javadoc 的參數
2 數據庫
mysql 的編碼最復雜 從4以后 mysql 號稱支持多編碼 它更靈活了 我們也更麻煩了
mysql 有4個級別的編碼
系統級
庫級
表級
sql語句級
請保持采用統一的編碼 推薦utf-8
其它數據庫要簡單的多 一般都是一種編碼
3 web server
tomcat 為例
tomcat server.xml 中一個參數
<Connectorport="8080" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" URIncoding="utf-8"/>
經測試 這個URIncoding 參數主要是 get 方法中采用編碼
4 jsp 顯示層
第1條中說明了 jsp 文件本身的格式
很多朋友采用eclipse +myeclipse 生成jsp
它自動生成一個頭<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
不要誤解 這句話不能保證你在ie里看到的不是亂碼
pageEncoding它的意思是 這個頁面本身采用的是 utf-8 (似乎只在eclipse 里有效果 ,我不確定)
為了在ie 里不亂碼 ?你還得加一句 <%@ page contentType="text/html; charset=UTF-8"%>
它不能在(myeclispe)自動生成 ?推薦修改 myeclipse的模板 在下邊的目錄里
MyEclipse\eclipse\plugins\com.genuitec.eclipse.wizards_4.0.1\Templates
里邊的jsp模版 你加上<%@ page contentType="text/html; charset=${encoding}"%>
5 filter
自從tomcat 4 以后 網上就流傳了一個SetCharacterEncodingFilter 過濾器 搜一下有很多
很好用 web.xml 中加入
<filter>
<filter-name>Set Character Encoding</filter-name>
<filter-class>filters.SetCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>utf-8</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>Set Character Encoding</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
6 資源文件
首先保證 文件本身是utf-8
然后部署的時候用 native2ascii 轉換
這里給出 ant 里的例子
<native2ascii encoding="utf-8" dest="${web.dir}/WEB-INF/classes" src="${src.dir}" includes="**/*.properties" />
總結
到這里 你應該徹底解決了亂碼了 嘿嘿
寫的有點亂 還請高手們多指點
]]>
]]>
訪問次數: 次????加入時間:2005-01-19
| 如何利用JDBC發送SQL語句? Statement對象用于將SQL語句發送到數據庫中。實際上有三種Statement對象,它們都作為在給定連接上執行SQL語句的包容器:Statement、PreparedStatement(它從Statement繼承而來)和CallableStatement(它從PreparedStatement繼承而來)。它們都專用于發送特定類型的SQL語句:Statement對象用于執行不帶參數的簡單SQL語句;PreparedStatement對象用于執行帶或不帶IN參數的預編譯SQL語句;CallableStatement對象用于執行對數據庫已存儲過程的調用。 Statement接口提供了執行語句和獲取結果的基本方法;PreparedStatement接口添加了處理IN參數的方法;而CallableStatement添加了處理OUT參數的方法。 1. 創建Statement對象 建立了到特定數據庫的連接之后,就可用該連接發送SQL語句。Statement對象用Connection的方法createStatement創建,如下列代碼段中所示: Connection con = DriverManager.getConnection(url,"sunny",""); Statement stmt = con.createStatement(); 為了執行Statement對象,被發送到數據庫的SQL語句將被作為參數提供給Statement的方法: ResultSet rs = stmt.executeQuery("SELECT a,b,c FROM Table2"); 2. 使用Statement對象執行語句 Statement接口提供了三種執行SQL語句的方法:executeQuery、executeUpdate和execute。使用哪一個方法由SQL語句所產生的內容決定。 方法executeQuery用于產生單個結果集的語句,例如SELECT語句。方法executeUpdate用于執行INSERT、UPDATE或DELETE語句以及SQL DDL(數據定義語言)語句,例如CREATE TABLE和DROP TABLE。INSERT、UPDATE或DELETE語句的效果是修改表中零行或多行中的一列或多列。executeUpdate的返回值是一個整數,指示受影響的行數(即更新計數)。對于CREATE TABLE或DROP TABLE等不操作行的語句,executeUpdate的返回值總為零。 執行語句的所有方法都將關閉所調用的Statement對象的當前打開結果集(如果存在)。這意味著在重新執行Statement對象之前,需要完成對當前ResultSet對象的處理。應注意,繼承了Statement接口中所有方法的PreparedStatement接口都有自己的executeQuery、executeUpdate和execute方法。Statement對象本身不包含SQL語句,因而必須給Statement.execute方法提供SQL語句作為參數。PreparedStatement對象并不需要SQL語句作為參數提供給這些方法,因為它們已經包含預編譯SQL語句。 CallableStatement對象繼承這些方法的PreparedStatement形式。對于這些方法的PreparedStatement或CallableStatement版本,使用查詢參數將拋出SQLException。 3. 語句完成 當連接處于自動提交模式時,其中所執行的語句在完成時將自動提交或還原。語句在已執行且所有結果返回時,即認為已完成。對于返回一個結果集的executeQuery方法,在檢索完ResultSet對象的所有行時該語句完成。對于方法executeUpdate,當它執行時語句即完成。但在少數調用方法execute的情況中,在檢索所有結果集或它生成的更新計數之后語句才完成。 有些DBMS將已存儲過程中的每條語句視為獨立的語句;而另外一些則將整個過程視為一個復合語句。在啟用自動提交時,這種差別就變得非常重要,因為它影響什么時候調用commit方法。在前一種情況中,每條語句單獨提交;在后一種情況中,所有語句同時提交。 4. 關閉Statement對象 Statement對象將由Java垃圾收集程序自動關閉。而作為一種好的編程風格,應在不需要Statement對象時顯式地關閉它們。這將立即釋放DBMS資源,有助于避免潛在的內存問題。 5. 使用方法execute execute方法應該僅在語句能返回多個ResultSet對象、多個更新計數或ResultSet對象與更新計數的組合時使用。當執行某個已存儲過程或動態執行未知SQL字符串(即應用程序程序員在編譯時未知)時,有可能出現多個結果的情況,盡管這種情況很少見。例如,用戶可能執行一個已存儲過程,并且該已存儲過程可執行更新,然后執行選擇,再進行更新,再進行選擇,等等。通常使用已存儲過程的人應知道它所返回的內容。 因為方法execute處理非常規情況,所以獲取其結果需要一些特殊處理并不足為怪。例如,假定已知某個過程返回兩個結果集,則在使用方法execute執行該過程后,必須調用方法getResultSet獲得第一個結果集,然后調用適當的getXXX方法獲取其中的值。要獲得第二個結果集,需要先調用getMoreResults方法,然后再調用getResultSet方法。如果已知某個過程返回兩個更新計數,則首先調用方法getUpdateCount,然后調用getMoreResults,并再次調用getUpdateCount。 對于不知道返回內容,則情況更為復雜。如果結果是ResultSet對象,則方法execute返回true;如果結果是Javaint,則返回false。如果返回int,則意味著結果是更新計數或執行的語句是DL命令。在調用方法execute之后要做的第一件事情是調用getResultSet或getUpdateCount。調用方法getResultSet可以獲得兩個或多個ResultSet對象中第一個對象;或調用方法getUpdateCount可以獲得兩個或多個更新計數中第一個更新計數的內容。 當SQL語句的結果不是結果集時,則方法getResultSet將返回null。這可能意味著結果是一個更新計數或沒有其它結果。在這種情況下,判斷null真正含義的唯一方法是調用方法getUpdateCount,它將返回一個整數。這個整數為調用語句所影響的行數;如果為-1則表示結果是結果集或沒有結果。如果方法getResultSet已返回null(表示結果不是ResultSet對象),則返回值-1表示沒有其它結果。也就是說,當下列條件為真時表示沒有結果(或沒有其它結果): ((stmt.getResultSet()==null)&&(stmt.getUpdateCount()==-1)) 如果已經調用方法getResultSet并處理了它返回的ResultSet對象,則有必要調用方法getMoreResults以確定是否有其它結果集或更新計數。如果getMoreResults返回true,則需要再次調用getResultSet來檢索下一個結果集。如上所述,如果getResultSet返回null,則需要調用getUpdateCount來檢查null是表示結果為更新計數還是表示沒有其它結果。 當getMoreResults返回false時,它表示該SQL語句返回一個更新計數或沒有其它結果。因此需要調用方法getUpdateCount來檢查它是哪一種情況。在這種情況下,當下列條件為真時表示沒有其它結果: ((stmt.getMoreResults()==false)&&(stmt.getUpdateCount()==-1)) 下面的代碼演示了一種方法用來確認已訪問調用方法execute所產生的全部結果集和更新計數: stmt.execute(queryStringWithUnknownResults); while(true){ introwCount=stmt.getUpdateCount(); if(rowCount>0){//它是更新計數 System.out.println("Rows changed="+count); stmt.getMoreResults(); continue; } if(rowCount==0){//DDL命令或0個更新 System.out.println("No rows changed or statement was DDL command"); stmt.getMoreResults(); continue; } //執行到這里,證明有一個結果集 //或沒有其它結果 ResultSet rs=stmt.getResultSet(); if(rs!=null){ ...//使用元數據獲得關于結果集列的信息 while(rs.next()){ ...//處理結果 stmt.getMoreResults(); continue; } break;//沒有其它結果 |
]]>
訪問次數: 次????加入時間:2005-01-19
| JDBC驅動管理內幕是怎么樣的? DriverManager 類是 JDBC 的管理層,作用于用戶和驅動程序之間。它跟蹤可用的驅動程序,并在數據庫和相應驅動程序之間建立連接。另外,DriverManager類也處理諸如驅動程序登錄時間限制及登錄和跟蹤消息的顯示等事務。 對于簡單的應用程序,一般程序員需要在此類中直接使用的唯一方法是DriverManager.getConnection。正如名稱所示,該方法將建立與數據庫的連接。JDBC允許用戶調用DriverManager的方法getDriver、getDrivers和registerDriver及Driver的方法connect。但多數情況下,讓DriverManager類管理建立連接的細節為上策。 1. 跟蹤可用驅動程序 DriverManager類包含一列Driver類,它們已通過調用方法DriverManager.registerDriver對自己進行了注冊。所有Driver類都必須包含有一個靜態部分。它創建該類的實例,然后在加載該實例時DriverManager類進行注冊。這樣,用戶正常情況下將不會直接調用DriverManager.registerDriver;而是在加載驅動程序時由驅動程序自動調用。加載Driver類,然后自動在DriverManager中注冊的方式有兩種: (1)調用方法Class.forName 這將顯式地加載驅動程序類。由于這與外部設置無關,因此推薦使用這種加載驅動程序的方法。以下代碼加載類acme.db.Driver:Class.forName("acme.db.Driver")。 如果將acme.db.Driver編寫為加載時創建實例,并調用以該實例為參數的DriverManager.registerDriver(本該如此),則它在DriverManager的驅動程序列表中,并可用于創建連接。 (2)將驅動程序添加到Java.lang.System的屬性jdbc.drivers中 這是一個由DriverManager類加載的驅動程序類名的列表,由冒號分隔:初始化DriverManager類時,它搜索系統屬性jdbc.drivers,如果用戶已輸入了一個或多個驅動程序,則DriverManager類將試圖加載它們。以下代碼說明程序員如何在~/.hotJava/properties中輸入三個驅動程序類(啟動時,HotJava將把它加載到系統屬性列表中): jdbc.drivers=foo.bah.Driver:wombat.sql.Driver:bad.test.ourDriver; 對DriverManager方法的第一次調用將自動加載這些驅動程序類。注意:加載驅動程序的第二種方法需要持久的預設環境。如果對這一點不能保證,則調用方法Class.forName顯式地加載每個驅動程序就顯得更為安全。這也是引入特定驅動程序的方法,因為一旦DriverManager類被初始化,它將不再檢查jdbc.drivers屬性列表。 在以上兩種情況中,新加載的Driver類都要通過調用DriverManager.registerDriver類進行自我注冊。如上所述,加載類時將自動執行這一過程。 由于安全方面的原因,JDBC管理層將跟蹤哪個類加載器提供哪個驅動程序。這樣,當DriverManager類打開連接時,它僅使用本地文件系統或與發出連接請求的代碼相同的類加載器提供的驅動程序。 2. 建立連接 加載Driver類并在DriverManager類中注冊后,它們即可用來與數據庫建立連接。當調用DriverManager.getConnection方法發出連接請求時,DriverManager將檢查每個驅動程序,查看它是否可以建立連接。 有時可能有多個JDBC驅動程序可以與給定的URL連接。例如,與給定遠程數據庫連接時,可以使用JDBC-ODBC橋驅動程序、JDBC到通用網絡協議驅動程序或數據庫廠商提供的驅動程序。在這種情況下測試驅動程序的順序至關重要,因為DriverManager將使用它所找到的第一個可以成功連接到給定URL的驅動程序。 首先DriverManager試圖按注冊的順序使用每個驅動程序(jdbc.drivers中列出的驅動程序總是先注冊)。它將跳過代碼不可信任的驅動程序,除非加載它們的源與試圖打開連接的代碼的源相同。它通過輪流在每個驅動程序上調用方法Driver.connect,并向它們傳遞用戶開始傳遞給方法DriverManager.getConnection的URL來對驅動程序進行測試,然后連接第一個認出該URL的驅動程序。這種方法初看起來效率不高,但由于不可能同時加載數十個驅動程序,因此每次連接實際只需幾個過程調用和字符串比較。 以下代碼是通常情況下用驅動程序(例如JDBC-ODBC橋驅動程序)建立連接所需所有步驟的示例: Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");//加載驅動程序 String url = "jdbc:odbc:fred"; DriverManager.getConnection(url,"userID","passwd"); |
]]>
訪問次數: 次????加入時間:2005-01-19
| 綜述:Java數據庫連接體系結構是用于Java應用程序連接數據庫的標準方法。JDBC對Java程序員而言是API,對實現與數據庫連接的服務提供商而言是接口模型。作為API,JDBC為程序開發提供標準的接口,并為數據庫廠商及第三方中間件廠商實現與數據庫的連接提供了標準方法。JDBC使用已有的SQL標準并支持與其它數據庫連接標準,如ODBC之間的橋接。JDBC實現了所有這些面向標準的目標并且具有簡單、嚴格類型定義且高性能實現的接口。 如何選擇合適的JDBC產品? 有關JDBC最新的信息,有興趣的讀者可以查閱JDBC的官方網站--即JavaSoft的主頁,其URL為:http://Java.sun.com/products/jdbc 1. JavaSoft框架 JavaSoft提供三種JDBC產品組件,它們是Java開發工具包(JDK)的組成部份:JDBC驅動程序管理器、JDBC驅動程序測試工具包和JDBC-ODBC橋。 JDBC驅動程序管理器是JDBC體系結構的支柱。它實際上很小,也很簡單;其主要作用是把Java應用程序連接到正確的JDBC驅動程序上,然后即退出。 JDBC驅動程序測試工具包為使JDBC驅動程序運行您的程序提供一定的可信度。只有通過JDBC驅動程序測試的驅動程序才被認為是符合JDBC標準TM的。 JDBC-ODBC橋使ODBC驅動程序可被用作JDBC驅動程序。它的實現為JDBC的快速發展提供了一條途徑,其長遠目標提供一種訪問某些不常見的DBMS(如果對這些不常見的DBMS未實現JDBC)的方法。 2. JDBC驅動程序的類型 目前比較常見的JDBC驅動程序可分為以下四個種類: (1)JDBC-ODBC橋加ODBC驅動程序 JavaSoft橋產品利用ODBC驅動程序提供JDBC訪問。注意,必須將ODBC二進制代碼(許多情況下還包括數據庫客戶機代碼)加載到使用該驅動程序的每個客戶機上。因此,這種類型的驅動程序最適合于企業網(這種網絡上客戶機的安裝不是主要問題),或者是用Java編寫的三層結構的應用程序服務器代碼。 (2)本地API 這種類型的驅動程序把客戶機API上的JDBC調用轉換為Oracle、Sybase、Informix、DB2或其它DBMS的調用。注意,象橋驅動程序一樣,這種類型的驅動程序要求將某些二進制代碼加載到每臺客戶機上。 (3)JDBC網絡純Java驅動程序 這種驅動程序將JDBC轉換為與DBMS無關的網絡協議,之后這種協議又被某個服務器轉換為一種DBMS協議。這種網絡服務器中間件能夠將它的純Java客戶機連接到多種不同的數據庫上。所用的具體協議取決于提供者。通常,這是最為靈活的JDBC驅動程序。有可能所有這種解決方案的提供者都提供適合于Intranet用的產品。為了使這些產品也支持Internet訪問,它們必須處理Web所提出的安全性、通過防火墻的訪問等方面的額外要求。幾家提供者正將JDBC驅動程序加到他們現有的數據庫中間件產品中。 (4)本地協議純Java驅動程序 這種類型的驅動程序將JDBC調用直接轉換為DBMS所使用的網絡協議。這將允許從客戶機機器上直接調用DBMS服務器,是Intranet訪問的一個很實用的解決方法。由于許多這樣的協議都是專用的,因此數據庫提供者自己將是主要來源,有幾家提供者已在著手做這件事了。 據專家預計第(3)、(4)類驅動程序將成為從JDBC訪問數據庫的首方法。第(1)、(2)類驅動程序在直接的純Java驅動程序還沒有上市前會作為過渡方案來使用。對第(1)、(2)類驅動程序可能會有一些變種,這些變種要求有連接器,但通常這些是更加不可取的解決方案。第(3)、(4)類驅動程序提供了Java的所有優點,包括自動安裝(例如,通過使用JDBC驅動程序的appletapplet來下載該驅動程序)。 3. JDBC驅動程序的獲取 目前已有幾十個(1)類的驅動程序,即可與Javasoft橋聯合使用的ODBC驅動程序的驅動程序。有大約十多個屬于種類(2)的驅動程序是以DBMS的本地API為基礎編寫的。只有幾個屬于種類(3)的驅動程序,其首批提供者是SCO、OpenHorizon、Visigenic和WebLogic。此外,JavaSoft和數據庫連接的領先提供者Intersolv還合作研制了JDBC-ODBC橋和JDBC驅動程序測試工具包。 |
]]>
訪問次數: 次????加入時間:2005-01-19
| 如何建立JDBC連接? Connection 對象代表與數據庫的連接。連接過程包括所執行的 SQL 語句和在該連接上所返回的結果。一個應用程序可與單個數據庫有一個或多個連接,或者可與許多數據庫有連接。 1. 打開連接 與數據庫建立連接的標準方法是調用DriverManager.getConnection方法。該方法接受含有某個URL的字符串。DriverManager類(即所謂的JDBC管理層)將嘗試找到可與那個URL所代表的數據庫進行連接的驅動程序。DriverManager類存有已注冊的Driver類的清單。當調用方法getConnection時,它將檢查清單中的每個驅動程序,直到找到可與URL中指定的數據庫進行連接的驅動程序為止。Driver的方法connect使用這個URL來建立實際的連接。 用戶可繞過JDBC管理層直接調用Driver方法。這在以下特殊情況下將很有用:當兩個驅動器可同時連接到數據庫中,而用戶需要明確地選用其中特定的驅動器。但一般情況下,讓DriverManager類處理打開連接這種事將更為簡單。 下述代碼顯示如何打開一個與位于URL"jdbc:odbc:wombat"的數據庫的連接。所用的用戶標識符為"freely",口令為"ec": String url = "jdbc:odbc:wombat"; Connection con = DriverManager.getConnection(url, "freely", "ec"); 2. 一般用法的URL 由于URL常引起混淆,我們將先對一般URL作簡單說明,然后再討論JDBCURL。URL(統一資源定位符)提供在Internet上定位資源所需的信息。可將它想象為一個地址。URL的第一部份指定了訪問信息所用的協議,后面總是跟著冒號。常用的協議有"ftp"(代表"文件傳輸協議")和"http"(代表"超文本傳輸協議")。如果協議是"file",表示資源是在某個本地文件系統上而非在Internet上(下例用于表示我們所描述的部分;它并非URL的組成部分)。 ftp://Javasoft.com/docs/JDK-1_apidocs.zip http://Java.sun.com/products/jdk/CurrentRelease file:/home/haroldw/docs/books/tutorial/summary.html URL的其余部份(冒號后面的)給出了數據資源所處位置的有關信息。如果協議是file,則URL的其余部份是文件的路徑。對于ftp和http協議,URL的其余部份標識了主機并可選地給出某個更詳盡的地址路徑。例如,以下是JavaSoft主頁的URL。該URL只標識了主機:http://Java.sun.com。從該主頁開始瀏覽,就可以進到許多其它的網頁中,其中之一就是JDBC主頁。JDBC主頁的URL更為具體,它具體表示為: http://Java.sun.com/products/jdbc 3. JDBC URL JDBC URL提供了一種標識數據庫的方法,可以使相應的驅動程序能識別該數據庫并與之建立連接。實際上,驅動程序編程員將決定用什么JDBC URL來標識特定的驅動程序。用戶不必關心如何來形成JDBC URL;他們只須使用與所用的驅動程序一起提供的URL即可。JDBC的作用是提供某些約定,驅動程序編程員在構造他們的JDBC URL時應該遵循這些約定。 由于JDBC URL要與各種不同的驅動程序一起使用,因此這些約定應非常靈活。首先,它們應允許不同的驅動程序使用不同的方案來命名數據庫。例如,odbc子協議允許(但并不是要求)URL含有屬性值。 其次,JDBC URL應允許驅動程序編程員將一切所需的信息編入其中。這樣就可以讓要與給定數據庫對話的applet打開數據庫連接,而無須要求用戶去做任何系統管理工作。 最后,JDBC URL應允許某種程度的間接性。也就是說,JDBC URL可指向邏輯主機或數據庫名,而這種邏輯主機或數據庫名將由網絡命名系統動態地轉換為實際的名稱。這可以使系統管理員不必將特定主機聲明為JDBC名稱的一部份。網絡命名服務(例如DNS、NIS和DCE)有多種,而對于使用哪種命名服務并無限制。 JDBC URL的標準語法如下所示。它由三部分組成,各部分間用冒號分隔: jdbc:<子協遙荊海甲用?稱??br> JDBC URL的三個部分可分解如下: (1)jdbc協議:JDBC URL中的協議總是jdbc。 (2)<子協議>:驅動程序名或數據庫連接機制(這種機制可由一個或多個驅動程序支持)的名稱。子協議名的典型示例是"odbc",該名稱是為用于指定ODBC風格的數據資源名稱的URL專門保留的。例如,為了通過JDBC-ODBC橋來訪問某個數據庫,可以用如下所示的URL:jdbc:odbc:book。本例中,子協議為"odbc",子名稱"book"是本地ODBC數據資源。如果要用網絡命名服務(這樣JDBC URL中的數據庫名稱不必是實際名稱),則命名服務可以作為子協議。例如,可用如下所示的URL:jdbc:dcenaming:accounts。本例中,該URL指定了本地DCE命名服務應該將數據庫名稱"accounts"解析為更為具體的可用于連接真實數據庫的名稱。 (3)<子名稱>:種標識數據庫的方法。子名稱可以依不同的子協議而變化。它還可以有子名稱的子名稱(含有驅動程序編程員所選的任何內部語法)。使用子名稱的目的是為定位數據庫提供足夠的信息。前例中,因為ODBC將提供其余部份的信息,因此用"book"就已足夠。然而,位于遠程服務器上的數據庫需要更多的信息。例如,如果數據庫是通過Internet來訪問的,則在JDBC URL中應將網絡地址作為子名稱的一部份包括進去,且必須遵循如下所示的標準URL命名約定://主機名:端口/子協議。 假設"dbnet"是個用于將某個主機連接到Internet上的協議,則JDBC URL應為:jdbc:dbnet://wombat:356/fred。 4. "odbc"子協議 子協議odbc是一種特殊情況。它是為用于指定ODBC風格的數據資源名稱的URL而保留的,并具有下列特性:允許在子名稱(數據資源名稱)后面指定任意多個屬性值。odbc子協議的完整語法為: jdbc:odbc:<數據資源名稱>[;<屬性名>=<屬性值>],因此,以下都是合法的jdbc:odbc名稱: jdbc:odbc:qeor7 jdbc:odbc:wombat jdbc:odbc:wombat;CacheSize=20;ExtensionCase=LOWER jdbc:odbc:qeora;UID=kgh;PWD=fooey 5. 注冊子協議 驅動程序編程員可保留某個名稱以將之用作JDBC URL的子協議名。當DriverManager類將此名稱加到已注冊的驅動程序清單中時,為之保留該名稱的驅動程序應能識別該名稱并與它所標識的數據庫建立連接。例如,odbc是為JDBC-ODBC橋而保留的。假設有個Miracle公司,它可能會將"miracle"注冊為連接到其Miracle DBMS上的JDBC驅動程序的子協議,從而使其他人都無法使用這個名稱。 JavaSoft目前作為非正式代理負責注冊JDBC子協議名稱。要注冊某個子協議名稱,請發送電子郵件到下述地址:jdbc@wombat.eng.sun.com。 6. 發送SQL語句 連接一旦建立,就可用來向它所涉及的數據庫傳送SQL語句。JDBC對可被發送的SQL語句類型不加任何限制。這就提供了很大的靈活性,即允許使用特定的數據庫語句或甚至于非SQL語句。然而,它要求用戶自己負責確保所涉及的數據庫可以處理所發送的SQL語句,否則將自食其果。例如,如果某個應用程序試圖向不支持儲存程序的DBMS發送儲存程序調用,就會失敗并將拋出異常。JDBC要求驅動程序應至少能提供ANSI SQL-2 Entry Level功能才可算是符合JDBC標準TM的。這意味著用戶至少可信賴這一標準級別的功能。 JDBC提供了三個類,用于向數據庫發送SQL語句。Connection接口中的三個方法可用于創建這些類的實例。下面列出這些類及其創建方法: (1)Statement:由方法createStatement所創建。Statement對象用于發送簡單的SQL語句。 (2)PreparedStatement:由方法prepareStatement所創建。PreparedStatement對象用于發送帶有一個或多個輸入參數(IN參數)的SQL語句。PreparedStatement擁有一組方法,用于設置IN參數的值。執行語句時,這些IN參數將被送到數據庫中。PreparedStatement的實例擴展了Statement,因此它們都包括了Statement的方法。PreparedStatement對象有可能比Statement對象的效率更高,因為它已被預編譯過并存放在那以供將來使用。 (3)CallableStatement:由方法prepareCall所創建。CallableStatement對象用于執行SQL儲存程序─一組可通過名稱來調用(就象函數的調用那樣)的SQL語句。CallableStatement對象從PreparedStatement中繼承了用于處理IN參數的方法,而且還增加了用于處理OUT參數和INOUT參數的方法。 不過通常來說createStatement方法用于簡單的SQL語句(不帶參數)、prepareStatement方法用于帶一個或多個IN參數的SQL語句或經常被執行的簡單SQL語句,而prepareCall方法用于調用已儲存過程。 7. 事務 事務由一個或多個這樣的語句組成:這些語句已被執行、完成并被提交或還原。當調用方法commit或rollback時,當前事務即告就結束,另一個事務隨即開始。缺省情況下,新連接將處于自動提交模式。也就是說,當執行完語句后,將自動對那個語句調用commit方法。這種情況下,由于每個語句都是被單獨提交的,因此一個事務只由一個語句組成。如果禁用自動提交模式,事務將要等到commit或rollback方法被顯式調用時才結束,因此它將包括上一次調用commit或rollback方法以來所有執行過的語句。對于第二種情況,事務中的所有語句將作為組來提交或還原。 方法commit使SQL語句對數據庫所做的任何更改成為永久性的,它還將釋放事務持有的全部鎖。而方法rollback將棄去那些更改。有時用戶在另一個更改生效前不想讓此更改生效。這可通過禁用自動提交并將兩個更新組合在一個事務中來達到。如果兩個更新都是成功,則調用commit方法,從而使兩個更新結果成為永久性的;如果其中之一或兩個更新都失敗了,則調用rollback方法,以將值恢復為進行更新之前的值。 大多數JDBC驅動程序都支持事務。事實上,符合JDBC的驅動程序必須支持事務。DatabaseMetaData給出的信息描述DBMS所提供的事務支持水平。 8. 事務隔離級別 如果DBMS支持事務處理,它必須有某種途徑來管理兩個事務同時對一個數據庫進行操作時可能發生的沖突。用戶可指定事務隔離級別,以指明DBMS應該花多大精力來解決潛在沖突。例如,當事務更改了某個值而第二個事務卻在該更改被提交或還原前讀取該值時該怎么辦。 假設第一個事務被還原后,第二個事務所讀取的更改值將是無效的,那么是否可允許這種沖突?JDBC用戶可用以下代碼來指示DBMS允許在值被提交前讀取該值("dirty讀取"),其中con是當前連接: con.setTransactionIsolation(TRANSACTION_READ_UNCOMMITTED); 事務隔離級別越高,為避免沖突所花的精力也就越多。Connection接口定義了五級,其中最低級別指定了根本就不支持事務,而最高級別則指定當事務在對某個數據庫進行操作時,任何其它事務不得對那個事務正在讀取的數據進行任何更改。通常,隔離級別越高,應用程序執行的速度也就越慢(由于用于鎖定的資源耗費增加了,而用戶間的并發操作減少了)。在決定采用什么隔離級別時,開發人員必須在性能需求和數據一致性需求之間進行權衡。當然,實際所能支持的級別取決于所涉及的DBMS的功能。 當創建Connection對象時,其事務隔離級別取決于驅動程序,但通常是所涉及的數據庫的缺省值。用戶可通過調用setIsolationLevel方法來更改事務隔離級別。新的級別將在該連接過程的剩余時間內生效。要想只改變一個事務的事務隔離級別,必須在該事務開始前進行設置,并在該事務結束后進行復位。我們不提倡在事務的中途對事務隔離級別進行更改,因為這將立即觸發commit方法的調用,使在此之前所作的任何更改變成永久性的。 |
]]>
 你插入數據的時候,用
你插入數據的時候,用
 /**?*/
/**
/**?*/
/**
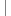 *?轉變字符串的亂碼函數*?
@param
?str*?
@return
*?轉變字符串的亂碼函數*?
@param
?str*?
@return
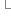 */
public
?String?getStr(String?str)
*/
public
?String?getStr(String?str)
 {
{
 try
{String?temp_p?
=
?str;
byte
?[]?temp_t?
=
?temp_p.getBytes(
"
ISO8859-1
"
);String?temp?
=
?
new
?String(temp_t);
return
?temp;
try
{String?temp_p?
=
?str;
byte
?[]?temp_t?
=
?temp_p.getBytes(
"
ISO8859-1
"
);String?temp?
=
?
new
?String(temp_t);
return
?temp;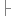 }
catch
(Exception?e)
{
return
?
"
null
"
;}
}
?
//
向bean里面賦值
public
?
void
?setAction(String?action)?
{
this
.action?
=
?getStr(action);}
public
?
void
?setAddmanagerid(String?addmanagerid)?
{
this
.addmanagerid?
=
?getStr(addmanagerid);}
轉換一下,看看可以嗎,我的數據庫是ORACLE沒問題。
}
catch
(Exception?e)
{
return
?
"
null
"
;}
}
?
//
向bean里面賦值
public
?
void
?setAction(String?action)?
{
this
.action?
=
?getStr(action);}
public
?
void
?setAddmanagerid(String?addmanagerid)?
{
this
.addmanagerid?
=
?getStr(addmanagerid);}
轉換一下,看看可以嗎,我的數據庫是ORACLE沒問題。
]]>
環境安裝配置:
TOMCAT的配置
http://download.chinaitlab.com/soft/10791.htm
JAVA配置文件編寫說明文檔
http://download.chinaitlab.com/soft/10010.htm
一步一步學會配置Kjava開發環境
http://download.chinaitlab.com/soft/9483.htm
Weblogic7開發EJB的配置
http://download.chinaitlab.com/soft/4938.htm
圖解JSP環境安裝配置
http://download.chinaitlab.com/soft/2157.htm
Tomcat配置方法
http://download.chinaitlab.com/soft/931.htm
全程指導Linux下JAVA環境配置
http://download.chinaitlab.com/soft/11272.htm
學習方法:
通過JB4學習JAVA
http://download.chinaitlab.com/soft/7589.htm
10步學習 JavaScript
http://download.chinaitlab.com/soft/6492.htm
Java Sctipt學習不求人
http://download.chinaitlab.com/soft/6361.htm
JSP學習指南
http://download.chinaitlab.com/soft/6152.htm
JAVA學習文檔
http://download.chinaitlab.com/soft/6114.htm
J2EE學習筆記
http://download.chinaitlab.com/soft/6048.htm
JavaScript學習
http://download.chinaitlab.com/soft/3029.htm
Java2 學習指南
http://download.chinaitlab.com/soft/2743.htm
Juniper學習指南
http://download.chinaitlab.com/soft/2227.htm
J2EE學習資料
http://download.chinaitlab.com/soft/1618.htm
JSP由淺入深
http://download.chinaitlab.com/soft/1315.htm
面向對象編程:
Java面向對象編程指南
http://download.chinaitlab.com/soft/9792.htm
JAVA的核心技術:面向對象編程
http://download.chinaitlab.com/soft/9093.htm
Java 與 UML 面向對象程序設計
http://download.chinaitlab.com/soft/6053.htm
Java 2 編程21天自學通
http://download.chinaitlab.com/soft/10507.htm
J2EE編程起步
http://download.chinaitlab.com/soft/10506.htm
Java面向對象編程指南
http://download.chinaitlab.com/soft/9792.htm
Java專業編程指南
http://download.chinaitlab.com/soft/9791.htm
Java服務器高級編程
http://download.chinaitlab.com/soft/9790.htm
J2EE EAI編程指南
http://download.chinaitlab.com/soft/9784.htm
J2MEMIDP無線設備編程指南
http://download.chinaitlab.com/soft/9765.htm
JAVA編程思想 中文版
http://download.chinaitlab.com/soft/9481.htm
Java XML編程指南
http://download.chinaitlab.com/soft/9097.htm
Java 數據庫編程寶典
http://download.chinaitlab.com/soft/9095.htm
JAVA的核心技術:面向對象編程
http://download.chinaitlab.com/soft/9093.htm
JDBC API數據庫編程實作教材
http://download.chinaitlab.com/soft/9087.htm
核心 JSF 編程
http://download.chinaitlab.com/soft/7946.htm
JAVA 2應用編程150例
http://download.chinaitlab.com/soft/6815.htm
JAVA數據庫編程JDBC
http://download.chinaitlab.com/soft/6113.htm
深入掌握J2EE編程技術
http://download.chinaitlab.com/soft/6030.htm
實用J2EE設計模式編程指南
http://download.chinaitlab.com/soft/5033.htm
Java for Internet編程技術
http://download.chinaitlab.com/soft/4198.htm
Java安全性編程指南
http://download.chinaitlab.com/soft/3773.htm
J2ME無線設備編程
http://download.chinaitlab.com/soft/3669.htm
J2EE EJB編程實例
http://download.chinaitlab.com/soft/3141.htm
Java編程思想 第三版
http://download.chinaitlab.com/soft/2982.htm
Java 極限編程
http://download.chinaitlab.com/soft/1707.htm
Java2編程詳解
http://download.chinaitlab.com/soft/1705.htm
網絡編程:
J2EE網絡編程標準教程
http://download.chinaitlab.com/soft/9100.htm
Java網絡編程實例
http://download.chinaitlab.com/soft/9090.htm
Java P2P網絡編程技術
http://download.chinaitlab.com/soft/6333.htm
Java網絡編程
http://download.chinaitlab.com/soft/3871.htm
網絡編程基礎篇之 Java Script
http://download.chinaitlab.com/soft/3618.htm
Solaris Shell 編程
http://download.chinaitlab.com/soft/6426.htm
SUN Solaris管理手冊
http://download.chinaitlab.com/soft/5732.htm
Solaris性能管理
http://download.chinaitlab.com/soft/11247.htm
Solaris9安裝指南
http://download.chinaitlab.com/soft/5022.htm
SOLARIS高級系統管理員指南
http://download.chinaitlab.com/soft/3726.htm
Solaris操作環境安全
http://download.chinaitlab.com/soft/1500.htm
Solaris GNOME2.0桌面用戶指南
http://download.chinaitlab.com/soft/1488.htm
Solaris 9 12/03 安裝指南
http://download.chinaitlab.com/soft/1484.htm
Solaris管理員指南
http://download.chinaitlab.com/soft/1475.htm
中文Solaris9 系統管理員指南
http://download.chinaitlab.com/soft/1463.htm
Solaris安全性專題指導
http://download.chinaitlab.com/soft/746.htm
XML系列:
Java XML編程指南
http://download.chinaitlab.com/soft/9097.htm
Java程序設計EJB、XML與數據庫
http://download.chinaitlab.com/soft/9094.htm
XML 終極教程
http://download.chinaitlab.com/soft/9057.htm
Java&XML應用
http://download.chinaitlab.com/soft/6211.htm
XML_JAVA指南
http://download.chinaitlab.com/soft/6163.htm
JDBC:
JDBC API數據庫編程實作教材
http://download.chinaitlab.com/soft/9087.htm
JAVA數據庫編程JDBC
http://download.chinaitlab.com/soft/6113.htm
JDBC API 參考教程第三版
http://download.chinaitlab.com/soft/6057.htm
JDBC與Java數據庫程序設計
http://download.chinaitlab.com/soft/6018.htm
Java語言SQL接口 JDBCprogram
http://download.chinaitlab.com/soft/5938.htm
JSP應用程序開發指南
http://download.chinaitlab.com/soft/1546.htm
用 JDBC 管理數據庫連接
http://download.chinaitlab.com/soft/935.htm
JDO:
全面了解JDO數據庫編程
http://download.chinaitlab.com/soft/7992.htm
Struts:
Struts中文手冊
http://download.chinaitlab.com/soft/10516.htm
Struts架構指導
http://download.chinaitlab.com/soft/7529.htm
精通struts技術
http://download.chinaitlab.com/soft/6801.htm
Struts 學習起歩問答
http://download.chinaitlab.com/soft/6156.htm
Hibernate:
Hibernate2.1.2參考手冊中文版
http://download.chinaitlab.com/soft/8919.htm
JAVA與模式\J2EE模式:
J2EE 核心模式
http://download.chinaitlab.com/soft/9785.htm
Java 企業設計模式
http://download.chinaitlab.com/soft/9096.htm
Java簡單工廠創立性模式介紹
http://download.chinaitlab.com/soft/7398.htm
EJB設計模式
http://download.chinaitlab.com/soft/6135.htm
JAVA設計模式
http://download.chinaitlab.com/soft/6112.htm
實用J2EE設計模式編程指南
http://download.chinaitlab.com/soft/5033.htm
Java與模式
http://download.chinaitlab.com/soft/3073.htm
設計模式Java版
http://download.chinaitlab.com/soft/1723.htm
JBuilder開發Servlet及JSP:
精通JBuilder
http://download.chinaitlab.com/soft/10565.htm
JBuilder速成資料
http://download.chinaitlab.com/soft/9714.htm
Jbuilder7和weblogic7整合開發手
http://download.chinaitlab.com/soft/9664.htm
JBUILDER9 軟件開發項目實踐
http://download.chinaitlab.com/soft/9089.htm
JbuilderX開發指南
http://download.chinaitlab.com/soft/9088.htm
Jbuilder x 指南
http://download.chinaitlab.com/soft/7984.htm
JBuilder4開發人員指南
http://download.chinaitlab.com/soft/5939.htm
JBuilder7 Weblogic7整和開發培訓手冊
http://download.chinaitlab.com/soft/4727.htm
JBuilder開發數據庫應用程序
http://download.chinaitlab.com/soft/1701.htm
Java開發指南--Servlets和JSP篇
http://download.chinaitlab.com/soft/9793.htm
Java Servlets 編程指南
http://download.chinaitlab.com/soft/9098.htm
Oreilly Java Servlet
http://download.chinaitlab.com/soft/6522.htm
Java Servlet開發與實例
http://download.chinaitlab.com/soft/6029.htm
深入Java Servlet 網絡編程
http://download.chinaitlab.com/soft/9783.htm
用JSP_Servlet構建三層式管理信息系統
http://download.chinaitlab.com/soft/6034.htm
Java Servlet幫助文檔
http://download.chinaitlab.com/soft/2981.htm
JSP網站編程教程
http://download.chinaitlab.com/soft/11256.htm
JSP語法分析
http://download.chinaitlab.com/soft/11257.htm
JSP實用教程
http://download.chinaitlab.com/soft/10792.htm
JSP語法(1)--HTML注釋
http://download.chinaitlab.com/soft/10790.htm
JSP應用開發詳解
http://download.chinaitlab.com/soft/10025.htm
JSP技術揭秘
http://download.chinaitlab.com/soft/9387.htm
JSP技術大全
http://download.chinaitlab.com/soft/9388.htm
JSP網上書店實例詳解
http://download.chinaitlab.com/soft/9386.htm
JSP動態網頁新技術
http://download.chinaitlab.com/soft/8920.htm
JSP 技術大全
http://download.chinaitlab.com/soft/7782.htm
JSP高級開發與應用
http://download.chinaitlab.com/soft/7633.htm
JSP 完全探索
http://download.chinaitlab.com/soft/7546.htm
JSP 高級開發與應用
http://download.chinaitlab.com/soft/7116.htm
JSP編程技巧
http://download.chinaitlab.com/soft/7114.htm
JSP速成教程
http://download.chinaitlab.com/soft/6882.htm
JSP網絡編程技術
http://download.chinaitlab.com/soft/6880.htm
JSP程序設計指南
http://download.chinaitlab.com/soft/6690.htm
最新JSP入門與應用
http://download.chinaitlab.com/soft/6697.htm
JSP快速入門
http://download.chinaitlab.com/soft/6636.htm
JSP網頁編程
http://download.chinaitlab.com/soft/6527.htm
JSP 實用教程
http://download.chinaitlab.com/soft/6334.htm
JSP入門與提高
http://download.chinaitlab.com/soft/6326.htm
JSP語法
http://download.chinaitlab.com/soft/6116.htm
掌握自定義JSP標簽
http://download.chinaitlab.com/soft/6096.htm
JSP 動態網站技術入門與提高
http://download.chinaitlab.com/soft/6019.htm
JSP實例入門
http://download.chinaitlab.com/soft/4377.htm
JSP教程之與數據庫通信
http://download.chinaitlab.com/soft/3673.htm
如何成為優秀的JSP 程序員
http://download.chinaitlab.com/soft/3002.htm
JSP數據庫編程指南
http://download.chinaitlab.com/soft/2946.htm
JSP 高級編程
http://download.chinaitlab.com/soft/2635.htm
JSP實用編程實例集錦
http://download.chinaitlab.com/soft/2154.htm
JSP程序設計精彩實例
http://download.chinaitlab.com/soft/2151.htm
JSP即時應用
http://download.chinaitlab.com/soft/1547.htm
JSP程序設計精彩實例
http://download.chinaitlab.com/soft/1543.htm
JSP實用編程實例集錦
http://download.chinaitlab.com/soft/1537.htm
JSP基礎
http://download.chinaitlab.com/soft/894.htm
Eclipse開發Servlet及JSP:
Eclipse+Tomcat集成開發servle
http://download.chinaitlab.com/soft/6134.htm
J2EE Jboss Ejb With Eclipse 2003
http://download.chinaitlab.com/soft/6045.htm
]]>
這些細節包括:
1、導入jdbc包
2、注冊oracle jdbc驅動程序
3、打開數據庫連接
4、執行sql dml語句在數據庫表中獲取、添加、修改和刪除行
一、jdbc驅動程序
共有有4種
1、thin驅動程序
thin驅動程序是所有驅動程序中資源消耗最小的,而且完全用java編寫的。
該驅動程序只使用tcp/ip且要求oracle net。被稱為第4類驅動程序。
它使用ttc協議與oracle數據庫進行通信。能夠在applet、application中使用。
2、oci驅動程序
oci驅動比thin需要資源要多,但性能通常好一點。oci驅動適合于部署在
中間層的軟件,如web服務器。不能在applet中使用oci驅動。是第2類驅動程序。
不完全用java寫的,還包含了c代碼。該驅動有許多附加的性能增強特性,
包括高級的連接緩沖功能。
注意:oci驅動要求在客戶計算機上安裝它。
3、服務器內部驅動程序
服務器內部驅動程序提供對數據庫的直接訪問,oracle jvm使用它與數據庫進行通信。
oracle jvm是與數據庫集成的java virtual machine,可以使用oracle jvm將
java類裝載進數據庫,然后公布和運行這個類中包含的方法。
4、服務器thin驅動程序
服務器端thin驅動程序也是由oracle jvm使用的,它提供對遠程數據庫的訪問。
也是完全用java編寫的。
二、導入jdbc包
三、注冊oracle jdbc驅動程序
必須先向java程序注冊oracle jdbc驅動程序,然后才能打開數據庫連接。
有兩種注冊oracle jdbc驅動程序的辦法。
1、使用java.lang.class的forname()方法
例子:class.forname(oracle.jdbc.oracledriver);
2、使用jdbc drivermanager類的registerdriver()方法。
例子:drivermanager.registerdriver(new oracle.jdbc.oracledriver());
如果使用oracle8i jdbc驅動程序,那么需要導入oracle.jdbc.driver.oracledriver類,
然后注冊這個類的實例。
例子:
import oracle.jdbc.driver.oracledriver;
drivermanager.registerdriver(new oracle.jdbc.oracledriver());
注意:從jdbc2.0開始,只用jdbc驅動程序的更標準辦法是通過數據源。
四、打開數據庫連接
必須先打開數據庫連接,然后才能在java程序中執行sql語句。打開數據庫連接
的主要辦法。
1、drivermanager類的getconnection()方法。
drivermanager.getconnection(url,username,passwrod);
url:程序要連接的數據庫,以及要使用的jdbc驅動程序
url的結構依賴于jdbc驅動程序的生產商。對于oracle jdbc驅動程序,數據庫url的結構:
driver_name是程序使用的oracle jdbc驅動程序的名稱。如:
jdbc:oracle:thin oracle jdbc thin驅動程序
jdbc:oracle:oci oracle jdbc oci驅動程序
jdbc:oracle:oci8 oracle jdbc oci驅動程序
driver_information是連接數據庫所需的驅動程序特有的信息。這依賴于使用的驅動程序。
對于oracle jdbc thin驅動程序,可以用
host_name:port:database_sid 或者 oracle net關鍵字-值對
(description=(address=(host=host_name)(protocol=tcp)(port=port()
(connect_data=(sid=database_sid)))
host_name: 運行數據庫的機器的名稱
port: net數據庫監聽器等待這個端口上的請求,默認是1521
database_sid: 要連接的數據庫實例的oracle sid。
username: 程序連接數據庫時使用的數據庫用戶名
passwrod: 用戶名的口令
例子:
connection myconnection=drivermanager.getconnection(
jdbc:oracle:thin:@localhost:1521:orcl,
store_user,
store_password);
connection myconnection=drivermanager.getconnection(
jdbc:oracle:oci:@(description=(address=(host=localhost)
(protocol=tcp)(port=1521))(connect_data=(sid=orcl))),
store_user,
store_password);
2、使用oracle數據源對象,必須先創建這個對象,然后連接它。使用這種方法
采用了一種設置數據庫連接信息的標準化方式,oracle數據源對象可以與
java naming and directory interface(java名字與目錄接口,jndi)一起使用。
]]>
* By metaphy 2005-11-12
* Version: 0.01
* 注:題目答案來源于metaphy過去的知識或網絡,metaphy不能保證其正確或完整性,僅供參考
**/
一、基礎問答
1.下面哪些類可以被繼承?
java.lang.Thread (T)
java.lang.Number (T)
java.lang.Double (F)
java.lang.Math (F)
java.lang.Void (F)
java.lang.Class (F)
java.lang.ClassLoader (T)
2.抽象類和接口的區別
(1)接口可以被多重implements,抽象類只能被單一extends
(2)接口只有定義,抽象類可以有定義和實現
(3)接口的字段定義默認為:public static final, 抽象類字段默認是"friendly"(本包可見)
3.Hashtable的原理,并說出HashMap與Hashtable的區別
HashTable的原理:通過節點的關鍵碼確定節點的存儲位置,即給定節點的關鍵碼k,通過一定的函數關系H(散列函數),得到函數值H(k),將此值解釋為該節點的存儲地址.
HashMap 與Hashtable很相似,但HashMap 是非同步(unsynchronizded)和可以以null為關鍵碼的.
4.forward和redirect的區別
forward: an internal transfer in servlet
redirect: 重定向,有2次request,第2次request將丟失第一次的attributs/parameters等
5.什么是Web容器?
實現J2EE規范中web協議的應用.該協議定義了web程序的運行時環境,包括:并發性,安全性,生命周期管理等等.
6.解釋下面關于J2EE的名詞
(1)JNDI:Java Naming & Directory Interface,JAVA命名目錄服務.主要提供的功能是:提供一個目錄系統,讓其它各地的應用程序在其上面留下自己的索引,從而滿足快速查找和定位分布式應用程序的功能.
(2)JMS:Java Message Service,JAVA消息服務.主要實現各個應用程序之間的通訊.包括點對點和廣播.
(3)JTA:Java Transaction API,JAVA事務服務.提供各種分布式事務服務.應用程序只需調用其提供的接口即可.
(4)JAF: Java Action FrameWork,JAVA安全認證框架.提供一些安全控制方面的框架.讓開發者通過各種部署和自定義實現自己的個性安全控制策略.
(5)RMI:Remote Method Interface,遠程方法調用
7.EJB是基于哪些技術實現的?并說 出SessionBean和EntityBean的區別,StatefulBean和StatelessBean的區別.
EJB包括Session Bean、Entity Bean、Message Driven Bean,基于JNDI、RMI、JAT等技術實現.
SessionBean在J2EE應用程序中被用來完成一些服務器端的業務操作,例如訪問數據庫、調用其他EJB組件.EntityBean被用來代表應用系統中用到的數據.對于客戶機,SessionBean是一種非持久性對象,它實現某些在服務器上運行的業務邏輯;EntityBean是一種持久性對象,它代表一個存儲在持久性存儲器中的實體的對象視圖,或是一個由現有企業應用程序實現的實體.
Session Bean 還可以再細分為 Stateful Session Bean 與 Stateless Session Bean .這兩種的 Session Bean都可以將系統邏輯放在 method之中執行,不同的是 Stateful Session Bean 可以記錄呼叫者的狀態,因此通常來說,一個使用者會有一個相對應的 Stateful Session Bean 的實體.Stateless Session Bean 雖然也是邏輯組件,但是他卻不負責記錄使用者狀態,也就是說當使用者呼叫 Stateless Session Bean 的時候,EJB Container 并不會找尋特定的 Stateless Session Bean 的實體來執行這個 method.換言之,很可能數個使用者在執行某個 Stateless Session Bean 的 methods 時,會是同一個 Bean 的 Instance 在執行.從內存方面來看, Stateful Session Bean 與 Stateless Session Bean 比較, Stateful Session Bean 會消耗 J2EE Server 較多的內存,然而 Stateful Session Bean 的優勢卻在于他可以維持使用者的狀態.
8.XML的解析方法
Sax,DOM,JDOM
9.什么是Web Service?
Web Service就是為了使原來各孤立的站點之間的信息能夠相互通信、共享而提出的一種接口。
Web Service所使用的是Internet上統一、開放的標準,如HTTP、XML、SOAP(簡單對象訪問協議)、WSDL等,所以Web Service可以在任何支持這些標準的環境(Windows,Linux)中使用。
注:SOAP協議(Simple Object Access Protocal,簡單對象訪問協議),它是一個用于分散和分布式環境下網絡信息交換的基于XML的通訊協議。在此協議下,軟件組件或應用程序能夠通過標準的HTTP協議進行通訊。它的設計目標就是簡單性和擴展性,這有助于大量異構程序和平臺之間的互操作性,從而使存在的應用程序能夠被廣泛的用戶訪問。
優勢:
(1).跨平臺。
(2).SOAP協議是基于XML和HTTP這些業界的標準的,得到了所有的重要公司的支持。
(3).由于使用了SOAP,數據是以ASCII文本的方式而非二進制傳輸,調試很方便;并且由于這樣,它的數據容易通過防火墻,不需要防火墻為了程序而單獨開一個“漏洞”。
(4).此外,WebService實現的技術難度要比CORBA和DCOM小得多。
(5).要實現B2B集成,EDI比較完善與比較復雜;而用WebService則可以低成本的實現,小公司也可以用上。
(6).在C/S的程序中,WebService可以實現網頁無整體刷新的與服務器打交道并取數。
缺點:
(1).WebService使用了XML對數據封裝,會造成大量的數據要在網絡中傳輸。
(2).WebService規范沒有規定任何與實現相關的細節,包括對象模型、編程語言,這一點,它不如CORBA。
10.多線程有幾種實現方法,都是什么?同步有幾種實現方法,都是什么?
答:多線程有兩種實現方法,分別是繼承Thread類與實現Runnable接口
同步的實現方面有兩種,分別是synchronized,wait與notify
11.JSP中動態INCLUDE與靜態INCLUDE的區別?
動態INCLUDE用jsp:include動作實現
<jsp:include page="included.jsp" flush="true"/>
它總是會檢查所含文件中的變化,適合用于包含動態頁面,并且可以帶參數
靜態INCLUDE用include偽碼實現,定不會檢查所含文件的變化,適用于包含靜態頁面
<%@ include file="included.htm" %>
]]>
import java.io.File;import java.awt.image.BufferedImage;import java.awt.Image;import java.awt.image.AffineTransformOp;import javax.imageio.ImageIO;import java.awt.geom.AffineTransform;public class UploadImg { String fromdir; // fromdir 圖片的原始目錄 String todir; // todir 處理后的圖片存放目錄 String imgfile; // imgfile 原始圖片 String sysimgfile; // sysimgfile 處理后的圖片文件名前綴 UploadImg( String fromdirNow, String todirNow, String imgfileNow, String sysimgfileNow ){ fromdir = fromdirNow; todir = todirNow; imgfile = imgfileNow; sysimgfile = sysimgfileNow; } public boolean CreateThumbnail() throws Exception { // fileExtNmae是圖片的格式 gif JPG 或png // String fileExtNmae=""; double Ratio = 0.0; File F = new File(fromdir,imgfile); if ( !F.isFile() ) throw new Exception(F+" is not image file error in CreateThumbnail!"); //首先判斷上傳的圖片是gif還是JPG ImageIO只能將gif轉換為png // if (isJpg(imgfile)){ // fileExtNmae="jpg"; // } //else{ // fileExtNmae="png"; // } File ThF = new File( todir, sysimgfile + ".jpg" ); BufferedImage Bi = ImageIO.read(F); //假設圖片寬 高 最大為120 120 Image Itemp = Bi.getScaledInstance (120,120,Bi.SCALE_SMOOTH); if ((Bi.getHeight()>120) || (Bi.getWidth()>120)){ if (Bi.getHeight()>Bi.getWidth()) Ratio = 120.0/Bi.getHeight(); else Ratio = 120.0/Bi.getWidth(); } AffineTransformOp op = new AffineTransformOp(AffineTransform.getScaleInstance(Ratio, Ratio), null); Itemp = op.filter(Bi, null); try { ImageIO.write((BufferedImage)Itemp, "jpg", ThF); } catch (Exception ex) { throw new Exception(" ImageIo.write error in CreatThum.: "+ex.getMessage()); } return (true); } public static void main(String[] args) { UploadImg UI; boolean ss = false; try{ UI = new UploadImg( "d:\\javalearn", "d:\\javalearn", "ps_high.jpg", "ps_low" ); ss = UI.CreateThumbnail(); if ( ss ) { System.out.println( "Success" ); } else{ System.out.println( "Error" ); } } catch(Exception e){ System.out.print(e.toString()); } }} ]]>
首先我選擇在Preferences里設置KeyMapping為Emacs,因為Emacs有更多方便的功能。我們一般使用CUA,最常用的就是CTRL+C功能了,但是我們有理由舍棄它。
首先說編輯Java最常用的快捷鍵,這幾個在幾種Keymapping下是一樣的。
Ctrl+h : member-insight,就是我們輸了一半代碼時,敲這個,編輯器生成提示,也可以在“.”號之后用,然后選擇回車。這時候如果選擇了Emacs我們就可以用更方便的上下選擇,而不用去找上下鍵。在Emacs里向下是Ctrl+n,向上時Ctrl+p,n代表Next,P代表Previos。在出現member-insight,這兩個快捷鍵還好用,大大方便了輸入。
Ctrl+j :expand-template,我們寫程序經常要寫System.out.println("");,在Jbuilder里我們只需要這樣輸入Ctrl+j out,然后回車,還有許多其他的,包括main就寫Ctrl+j main,這兩個個快捷鍵在兩種模式下都可用,在選擇的時候也可以用上面說的快捷鍵上下選擇。在Preferences->template中我們還可以訂制自己的模版,比如寫一段常用版權聲明,然后賦一個值.
Ctrl+Shift+j:enter-sync-edit-mode,選中一段代碼,然后按下這個鍵,就進入了sync-edit-mode,這時對這段代碼的一個變量的更改,所有這段代碼對應的部分都會改變,很有用,這樣不會因為做的亂了,漏了改變某個變量名.
Ctrl+Enter:find-definition,Ctrl+Shift+Enter:find-references,對于第一個,如果光標在變量上,這樣按會跑到變量生命的地方,如果是方法且有源代碼會跑到方法定義處,若是類且有源代碼則跑到類定義處.第二個類似,他是找引用的地方。這兩個的好處很明顯,尤其面對一個不熟悉的系統時,只有這樣去查看代碼。
Ctrl+Shift+space.光標移到方法的括號里,然后輸入,這時會顯示參數的提示。
有一個功能通常很有用,就是注釋掉一段代碼,在CUA里才有,是Ctrl+/,由于Emacs里有別的用處,所以默認的沒有設置,所以我通常在設置里改為Ctrl+Shife+/。
以上是最常用的了,然后是emacs特有的內容。
移動光標。上面已經提到了幾個,還有以下很有用。
Ctrl+b 后退光標
Ctrl+f 前進光標
Ctrl+v 下一屏
Alt+v 上一屏
Ctrl+e 一行的結尾
Ctrl+a 一行的開頭
Alt+m 一行第一個非空格字符之前。
Ctrl+x g 移到指定行。
相信有了這些鍵之后,手就不很需要移到END,HOME和鼠標上了。
還有是拷貝粘貼,畢竟Ctrl+c,Ctrl+v,Ctrl+x用的太多了,不用總是覺得麻煩,所以我定義了這幾個,只是加上了Shift。Emacs本身也有很多類似的功能。
Ctrl+k:剪切一行,Ctrl+y:粘貼回來,而且如果你用了多次Ctrl+k,點Ctrl+y之后可以再選Alt+y,這樣可以把以前剪切的內容粘貼回來。
結合這兩種模式的拷貝粘貼,可以實現更加靈活的編輯。
再就是查詢,先按Ctrl+s,然后輸入查詢內容,你會發現這是增量查詢,你可以馬上看到結果。再按Ctrl+s,可以找下一個,Ctrl+r可以找前一個,如果不輸入內容,輸入兩遍Ctrl+s,會查找上一詞的內容.
其他的還有的比較需要,像Ctrl+z沒有了,要用Ctrl+shift+-。保存要Ctrl+x Ctrl+s,注意,是分別按,按Ctrl+x之后Jbulider左下角會顯示,然后再按后一個。Ctrl+x 1,Ctrl+x 2,Ctrl+x 3,看看是干什么的。還有一個就是Ctrl+x Ctrl+u這樣可以將選中的代碼全部轉化為大寫。
常用就這些了,還有很多記不住了,看JBuilder設置就知道了。希望大家不要怕麻煩練習一下,以后就會發現提高效率很高,說不定以后用Emacs會更快上手。
]]>
作者:jackliu
e-mail:suntoday@eyou.com
Java語言定義了public、protected、private、abstract、static和final這6常用修飾
詞外還定義了5個不太常用的修飾詞,下面是對這11個Java修飾詞的介紹:
1.public
使用對象:類、接口、成員
介紹:無論它所處在的包定義在哪,該類(接口、成員)都是可訪問的
2.private
使用對象:成員
介紹:成員只可以在定義它的類中被訪問
3.static
使用對象:類、方法、字段、初始化函數
介紹:成名為static的內部類是一個頂級類,它和包含類的成員是不相關的。靜態方法
是類方法,
是被指向到所屬的類而不是類的實例。靜態字段是類字段,無論該字段所在的類創建了
多少實例,該字
段只存在一個實例被指向到所屬的類而不是類的實例。初始化函數是在裝載類時執行
的,而不是在創建
實例時執行的。
4.final
使用對象:類、方法、字段、變量
介紹:被定義成final的類不允許出現子類,不能被覆蓋(不應用于動態查詢),字段值
不允許被
修改。
5.abstract
使用對象:類、接口、方法
介紹:類中包括沒有實現的方法,不能被實例化。如果是一個abstract方法,則方法體
為空,該方
法的實現在子類中被定義,并且包含一個abstract方法的類必須是一個abstract類
6.protected
使用對象:成員
介紹:成員只能在定義它的包中被訪問,如果在其他包中被訪問,則實現這個方法的類
必須是該成
員所屬類的子類。
7.native
使用對象:成員
介紹:與操作平臺相關,定義時并不定義其方法,方法的實現被一個外部的庫實現。
8.strictfp
使用對象:類、方法
介紹:strictfp修飾的類中所有的方法都隱藏了strictfp修飾詞,方法執行的所有浮點
計算遵守
IEEE 754標準,所有取值包括中間的結果都必須表示為float或double類型,而不能利用
由本地平臺浮
點格式或硬件提供的額外精度或表示范圍。
9.synchronized
使用對象:方法
介紹:對于一個靜態的方法,在執行之前jvm把它所在的類鎖定;對于一個非靜態類的方
法,執行
前把某個特定對象實例鎖定。
10.volatile
使用對象:字段
介紹:因為異步線程可以訪問字段,所以有些優化操作是一定不能作用在字段上的。
volatile有時
可以代替synchronized。
11.transient
使用對象:字段
介紹:字段不是對象持久狀態的一部分,不應該把字段和對象一起串起。
]]>
|
將Java應用程序本地編譯為EXE的幾種方法 | |
|
1. 從www.towerj.com獲得一個TowerJ編譯器,該編譯器可以將你的CLASS文件編譯成EXE文件。 2. 利用微軟的SDK-Java 4.0所提供的jexegen.exe創建EXE文件,這個軟件可以從微軟的網站免費下載,地址如下: http://www.microsoft.com/java/download/dl_sdk40.htm jexegen的語法如下: jexegen /OUT:exe_file_name /MAIN:main_class_name main_class_file_name.class [and other classes] 3. Visual Cafe提供了一個能夠創建EXE文件的本地編譯器。你需要安裝該光盤上提供的EXE組件。 4. 使用InstallAnywhere創建安裝盤。 5. 使用IBM AlphaWorks提供的一個高性能Java編譯器,該編譯器可以從下面的地址獲得: http://www.alphaworks.ibm.com/tech/hpc 6. JET是一個優秀的Java語言本地編譯器。該編譯器可以從這個網站獲得一個測試版本: http://www.excelsior-usa.com/jet.html 7. Instantiations公司的JOVE http://www.instantiations.com/jove/...ejovesystem.htm JOVE公司合并了以前的SuperCede,一個優秀的本地編譯器,現在SuperCede 已經不復存在了。 8. JToEXE Bravo Zulu Consulting, Inc開發的一款本地編譯器,本來可以從該公司的網頁上免費下載的,不過目前在該公司的主頁上找不到了。 主頁:http://www.bravozulu.com/ 根據精華區中的資料,下面這個FTP上曾經有過這個軟件,不知道現在是不是還在: ftp://race.dlut.edu.cn/pub/java/tools/jet 注:本文的主要內容來自如下網站,本人對其中的技術性內容進行了確認并補 充了一小部分內容。 (tack) http://www.artima.com/legacy/answer...ssages/190.html |
]]>
方法一:public static String Conversion(String s)throws IOException{String s1 = new String();String s2 = new String();byte abyte0[] = s.getBytes("Unicode");for(int j = 2; j < abyte0.length; j += 2){String s3 = Integer.toHexString(abyte0[j + 1]);int i = s3.length();if(i < 2)s1 = s1 + "&#x" + "0" + s3;elses1 = s1 + "&#x" + s3.substring(i - 2);s3 = Integer.toHexString(abyte0[j]);i = s3.length();if(i < 2)s1 = s1 + "0" + s3 + ";";elses1 = s1 + s3.substring(i - 2) + ";";}return s1;}方法二:public static String enCode(String str) { if(str==null)return ""; String hs=""; try { byte b[]=str.getBytes("UTF-16"); //System.out.println(byte2hex(b)); for (int n=0;n<b.length;n++) { str=(java.lang.Integer.toHexString(b[n] & 0XFF)); if (str.length()==1) hs=hs+"0"+str; else hs=hs+str; if (n<b.length-1)hs=hs+""; } //去除第一個標記字符 str= hs.toUpperCase().substring(4); //System.out.println(str); char[] chs=str.toCharArray(); str=""; for(int i=0;i<chs.length;i=i+4) { str+="&#x"+chs[i]+chs[i+1]+chs[i+2]+chs[i+3]+";"; } return str; } catch(Exception e) { System.out.print(e.getMessage()); } return str; }]]>
問題一:我聲明了什么!
String s = "Hello world!";
許多人都做過這樣的事情,但是,我們到底聲明了什么?回答通常是:一個String,內容是“Hello world!”。這樣模糊的回答通常是概念不清的根源。如果要準確的回答,一半的人大概會回答錯誤。
這個語句聲明的是一個指向對象的引用,名為“s”,可以指向類型為String的任何對象,目前指向"Hello world!"這個String類型的對象。這就是真正發生的事情。我們并沒有聲明一個String對象,我們只是聲明了一個只能指向String對象的引用變量。所以,如果在剛才那句語句后面,如果再運行一句:
String string = s;
我們是聲明了另外一個只能指向String對象的引用,名為string,并沒有第二個對象產生,string還是指向原來那個對象,也就是,和s指向同一個對象。
問題二:"=="和equals方法究竟有什么區別?
==操作符專門用來比較變量的值是否相等。比較好理解的一點是:
int a=10;
int b=10;
則a==b將是true。
但不好理解的地方是:
String a=new String("foo");
String b=new String("foo");
則a==b將返回false。
根據前一帖說過,對象變量其實是一個引用,它們的值是指向對象所在的內存地址,而不是對象本身。a和b都使用了new操作符,意味著將在內存中產生兩個內容為"foo"的字符串,既然是“兩個”,它們自然位于不同的內存地址。a和b的值其實是兩個不同的內存地址的值,所以使用"=="操作符,結果會是false。誠然,a和b所指的對象,它們的內容都是"foo",應該是“相等”,但是==操作符并不涉及到對象內容的比較。
對象內容的比較,正是equals方法做的事。
看一下Object對象的equals方法是如何實現的:
boolean equals(Object o){
return this==o;
}
Object對象默認使用了==操作符。所以如果你自創的類沒有覆蓋equals方法,那你的類使用equals和使用==會得到同樣的結果。同樣也可以看出,Object的equals方法沒有達到equals方法應該達到的目標:比較兩個對象內容是否相等。因為答案應該由類的創建者決定,所以Object把這個任務留給了類的創建者。
看一下一個極端的類:
Class Monster{
private String content;
...
boolean equals(Object another){ return true;}
}
我覆蓋了equals方法。這個實現會導致無論Monster實例內容如何,它們之間的比較永遠返回true。
所以當你是用equals方法判斷對象的內容是否相等,請不要想當然。因為可能你認為相等,而這個類的作者不這樣認為,而類的equals方法的實現是由他掌握的。如果你需要使用equals方法,或者使用任何基于散列碼的集合(HashSet,HashMap,HashTable),請察看一下java doc以確認這個類的equals邏輯是如何實現的。
問題三:String到底變了沒有?
沒有。因為String被設計成不可變(immutable)類,所以它的所有對象都是不可變對象。請看下列代碼:
String s = "Hello";
s = s + " world!";
s所指向的對象是否改變了呢?從本系列第一篇的結論很容易導出這個結論。我們來看看發生了什么事情。在這段代碼中,s原先指向一個String對象,內容是"Hello",然后我們對s進行了+操作,那么s所指向的那個對象是否發生了改變呢?答案是沒有。這時,s不指向原來那個對象了,而指向了另一個String對象,內容為"Hello world!",原來那個對象還存在于內存之中,只是s這個引用變量不再指向它了。
通過上面的說明,我們很容易導出另一個結論,如果經常對字符串進行各種各樣的修改,或者說,不可預見的修改,那么使用String來代表字符串的話會引起很大的內存開銷。因為String對象建立之后不能再改變,所以對于每一個不同的字符串,都需要一個String對象來表示。這時,應該考慮使用StringBuffer類,它允許修改,而不是每個不同的字符串都要生成一個新的對象。并且,這兩種類的對象轉換十分容易。
同時,我們還可以知道,如果要使用內容相同的字符串,不必每次都new一個String。例如我們要在構造器中對一個名叫s的String引用變量進行初始化,把它設置為初始值,應當這樣做:
public class Demo {
private String s;
...
public Demo {
s = "Initial Value";
}
...
}
而非
s = new String("Initial Value");
后者每次都會調用構造器,生成新對象,性能低下且內存開銷大,并且沒有意義,因為String對象不可改變,所以對于內容相同的字符串,只要一個String對象來表示就可以了。也就說,多次調用上面的構造器創建多個對象,他們的String類型屬性s都指向同一個對象。
上面的結論還基于這樣一個事實:對于字符串常量,如果內容相同,Java認為它們代表同一個String對象。而用關鍵字new調用構造器,總是會創建一個新的對象,無論內容是否相同。
至于為什么要把String類設計成不可變類,是它的用途決定的。其實不只String,很多Java標準類庫中的類都是不可變的。在開發一個系統的時候,我們有時候也需要設計不可變類,來傳遞一組相關的值,這也是面向對象思想的體現。不可變類有一些優點,比如因為它的對象是只讀的,所以多線程并發訪問也不會有任何問題。當然也有一些缺點,比如每個不同的狀態都要一個對象來代表,可能會造成性能上的問題。所以Java標準類庫還提供了一個可變版本,即StringBuffer。
問題四:final關鍵字到底修飾了什么?
final使得被修飾的變量"不變",但是由于對象型變量的本質是“引用”,使得“不變”也有了兩種含義:引用本身的不變,和引用指向的對象不變。
引用本身的不變:
final StringBuffer a=new StringBuffer("immutable");
final StringBuffer b=new StringBuffer("not immutable");
a=b;//編譯期錯誤
引用指向的對象不變:
final StringBuffer a=new StringBuffer("immutable");
a.append(" broken!"); //編譯通過
可見,final只對引用的“值”(也即它所指向的那個對象的內存地址)有效,它迫使引用只能指向初始指向的那個對象,改變它的指向會導致編譯期錯誤。至于它所指向的對象的變化,final是不負責的。這很類似==操作符:==操作符只負責引用的“值”相等,至于這個地址所指向的對象內容是否相等,==操作符是不管的。
理解final問題有很重要的含義。許多程序漏洞都基于此----final只能保證引用永遠指向固定對象,不能保證那個對象的狀態不變。在多線程的操作中,一個對象會被多個線程共享或修改,一個線程對對象無意識的修改可能會導致另一個使用此對象的線程崩潰。一個錯誤的解決方法就是在此對象新建的時候把它聲明為final,意圖使得它“永遠不變”。其實那是徒勞的。
問題五:到底要怎么樣初始化!
本問題討論變量的初始化,所以先來看一下Java中有哪些種類的變量。
1. 類的屬性,或者叫值域
2. 方法里的局部變量
3. 方法的參數
對于第一種變量,Java虛擬機會自動進行初始化。如果給出了初始值,則初始化為該初始值。如果沒有給出,則把它初始化為該類型變量的默認初始值。
int類型變量默認初始值為0
float類型變量默認初始值為0.0f
double類型變量默認初始值為0.0
boolean類型變量默認初始值為false
char類型變量默認初始值為0(ASCII碼)
long類型變量默認初始值為0
所有對象引用類型變量默認初始值為null,即不指向任何對象。注意數組本身也是對象,所以沒有初始化的數組引用在自動初始化后其值也是null。
對于兩種不同的類屬性,static屬性與instance屬性,初始化的時機是不同的。instance屬性在創建實例的時候初始化,static屬性在類加載,也就是第一次用到這個類的時候初始化,對于后來的實例的創建,不再次進行初始化。這個問題會在以后的系列中進行詳細討論。
對于第二種變量,必須明確地進行初始化。如果再沒有初始化之前就試圖使用它,編譯器會抗議。如果初始化的語句在try塊中或if塊中,也必須要讓它在第一次使用前一定能夠得到賦值。也就是說,把初始化語句放在只有if塊的條件判斷語句中編譯器也會抗議,因為執行的時候可能不符合if后面的判斷條件,如此一來初始化語句就不會被執行了,這就違反了局部變量使用前必須初始化的規定。但如果在else塊中也有初始化語句,就可以通過編譯,因為無論如何,總有至少一條初始化語句會被執行,不會發生使用前未被初始化的事情。對于try-catch也是一樣,如果只有在try塊里才有初始化語句,編譯部通過。如果在catch或finally里也有,則可以通過編譯。總之,要保證局部變量在使用之前一定被初始化了。所以,一個好的做法是在聲明他們的時候就初始化他們,如果不知道要出事化成什么值好,就用上面的默認值吧!
其實第三種變量和第二種本質上是一樣的,都是方法中的局部變量。只不過作為參數,肯定是被初始化過的,傳入的值就是初始值,所以不需要初始化。
問題六:instanceof是什么東東?
instanceof是Java的一個二元操作符,和==,>,<是同一類東東。由于它是由字母組成的,所以也是Java的保留關鍵字。它的作用是測試它左邊的對象是否是它右邊的類的實例,返回boolean類型的數據。舉個例子:
String s = "I AM an Object!";
boolean isObject = s instanceof Object;
我們聲明了一個String對象引用,指向一個String對象,然后用instancof來測試它所指向的對象是否是Object類的一個實例,顯然,這是真的,所以返回true,也就是isObject的值為True。
instanceof有一些用處。比如我們寫了一個處理賬單的系統,其中有這樣三個類:
public class Bill {//省略細節}
public class PhoneBill extends Bill {//省略細節}
public class GasBill extends Bill {//省略細節}
在處理程序里有一個方法,接受一個Bill類型的對象,計算金額。假設兩種賬單計算方法不同,而傳入的Bill對象可能是兩種中的任何一種,所以要用instanceof來判斷:
public double calculate(Bill bill) {
if (bill instanceof PhoneBill) {
//計算電話賬單
}
if (bill instanceof GasBill) {
//計算燃氣賬單
}
...
}
這樣就可以用一個方法處理兩種子類。
然而,這種做法通常被認為是沒有好好利用面向對象中的多態性。其實上面的功能要求用方法重載完全可以實現,這是面向對象變成應有的做法,避免回到結構化編程模式。只要提供兩個名字和返回值都相同,接受參數類型不同的方法就可以了:
public double calculate(PhoneBill bill) {
//計算電話賬單
}
public double calculate(GasBill bill) {
//計算燃氣賬單
}
所以,使用instanceof在絕大多數情況下并不是推薦的做法,應當好好利用多態。
]]>
almost all there with examples
Free, good, and official Java tutorial:
http://java.sun.com/docs/books/tutorial/
Thinking in Java 3rd Edition,中文版 + English version
http://java.galesoft.com/
Code Conventions for the JavaTM Programming Language
http://java.sun.com/docs/codeconv/html/CodeConvTOC.doc.html
Java API doc
http://java.sun.com/j2se/1.4.2/docs/api/index.html
http://java.sun.com/j2se/1.5.0/docs/api/index.html
api 中文版 and many others
See links in 『 Java新技術,新聞,應用與資源等 』
Excellent article about Runtime from JavaWorld!
http://www.javaworld.com/javaworld/jw-12-2000/jw-1229-traps.html
]]>
轉載至http://blog.csdn.net/jollyant/archive/2005/09/22/487072.aspx
【收藏】Java開發者必去的技術網站
英文網站
http://www.javaalmanac.com - Java開發者年鑒一書的在線版本. 要想快速查到某種Java技巧的用法及示例代碼, 這是一個不錯的去處.
http://www.onjava.com - O'Reilly的Java網站. 每周都有新文章.
http://java.sun.com - 官方的Java開發者網站 - 每周都有新文章發表.
http://www.developer.com/java - 由Gamelan.com 維護的Java技術文章網站.
http://www.java.net - Sun公司維護的一個Java社區網站.
http://www.builder.com - Cnet的Builder.com網站 - 所有的技術文章, 以Java為主.
http://www.ibm.com/developerworks/java - IBM的Developerworks技術網站; 這是其中的Java技術主頁.
http://www.javaworld.com - 最早的一個Java站點. 每周更新Java技術文章.
http://www.devx.com/java - DevX維護的一個Java技術文章網站.
http://www.fawcette.com/javapro - JavaPro在線雜志網站.
http://www.sys-con.com/java - Java Developers Journal的在線雜志網站.
http://www.javadesktop.org - 位于Java.net的一個Java桌面技術社區網站.
http://www.theserverside.com - 這是一個討論所有Java服務器端技術的網站.
http://www.jars.com - 提供Java評論服務. 包括各種framework和應用程序.
http://www.jguru.com - 一個非常棒的采用Q&A形式的Java技術資源社區.
http://www.javaranch.com - 一個論壇,得到Java問題答案的地方,初學者的好去處。
http://www.ibiblio.org/javafaq/javafaq.html - comp.lang.java的FAQ站點 - 收集了來自comp.lang.java新聞組的問題和答案的分類目錄.
http://java.sun.com/docs/books/tutorial/ - 來自SUN公司的官方Java指南 - 對于了解幾乎所有的java技術特性非常有幫助.
http://www.javablogs.com - 互聯網上最活躍的一個Java Blog網站.
http://java.about.com/ - 來自About.com的Java新聞和技術文章網站.
http://www.objectlearn.com/index.jsp
中文網站
http://www-900.ibm.com/developerWorks/cn/java/index.shtml
http://diy.ccidnet.com/pub/article/c317_a71330_p1.html 賽迪網J2EE專題
http://www.javaresearch.org/ Java研究組織
http://www.jdon.com/ J道-Java和J2EE解決之道
http://community.csdn.net/expert/forum.asp CSDN技術社區
]]>
http://bbs.chinaunix.net/forum/viewtopic.php?t=176605&show_type=new
]]>
為了解決對共享存儲區的訪問沖突,Java 引入了同步機制,現在讓我們來考察多個線程對共享資源的訪問,顯然同步機制已經不夠了,因為在任意時刻所要求的資源不一定已經準備好了被訪問,反過來,同一時刻準備好了的資源也可能不止一個。為了解決這種情況下的訪問控制問題,Java 引入了對阻塞機制的支持。
阻塞指的是暫停一個線程的執行以等待某個條件發生(如某資源就緒),學過操作系統的同學對它一定已經很熟悉了。Java 提供了大量方法來支持阻塞,下面讓我們逐一分析。
1. sleep() 方法:sleep() 允許 指定以毫秒為單位的一段時間作為參數,它使得線程在指定的時間內進入阻塞狀態,不能得到CPU 時間,指定的時間一過,線程重新進入可執行狀態。
典型地,sleep() 被用在等待某個資源就緒的情形:測試發現條件不滿足后,讓線程阻塞一段時間后重新測試,直到條件滿足為止。
2. suspend() 和 resume() 方法:兩個方法配套使用,suspend()使得線程進入阻塞狀態,并且不會自動恢復,必須其對應的resume() 被調用,才能使得線程重新進入可執行狀態。典型地,suspend() 和 resume() 被用在等待另一個線程產生的結果的情形:測試發現結果還沒有產生后,讓線程阻塞,另一個線程產生了結果后,調用 resume() 使其恢復。
3. yield() 方法:yield() 使得線程放棄當前分得的 CPU 時間,但是不使線程阻塞,即線程仍處于可執行狀態,隨時可能再次分得 CPU 時間。調用 yield() 的效果等價于調度程序認為該線程已執行了足夠的時間從而轉到另一個線程。
4. wait() 和 notify() 方法:兩個方法配套使用,wait() 使得線程進入阻塞狀態,它有兩種形式,一種允許 指定以毫秒為單位的一段時間作為參數,另一種沒有參數,前者當對應的 notify() 被調用或者超出指定時間時線程重新進入可執行狀態,后者則必須對應的 notify()被調用。
初看起來它們與 suspend() 和 resume() 方法對沒有什么分別,但是事實上它們是截然不同的。區別的核心在于,前面敘述的所有方法,阻塞時都不會釋放占用的鎖(如果占用了的話),而這一對方法則相反。 上述的核心區別導致了一系列的細節上的區別。
首先,前面敘述的所有方法都隸屬于 Thread 類,但是這一對卻直接隸屬于 Object 類,也就是說,所有對象都擁有這一對方法。初看起來這十分不可思議,但是實際上卻是很自然的,因為這一對方法阻塞時要釋放占用的鎖,而鎖是任何對象都具有的,調用任意對象的 wait() 方法導致線程阻塞,并且該對象上的鎖被釋放。而調用 任意對象的notify()方法則導致因調用該對象的 wait() 方法而阻塞的線程中隨機選擇的一個解除阻塞(但要等到獲得鎖后才真正可執行)。
其次,前面敘述的所有方法都可在任何位置調用,但是這一對方法卻必須在 synchronized 方法或塊中調用,理由也很簡單,只有在synchronized 方法或塊中當前線程才占有鎖,才有鎖可以釋放。同樣的道理,調用這一對方法的對象上的鎖必須為當前線程所擁有,這樣才有鎖可以釋放。因此,這一對方法調用必須放置在這樣的 synchronized 方法或塊中,該方法或塊的上鎖對象就是調用這一對方法的對象。若不滿足這一條件,則程序雖然仍能編譯,但在運行時會出現IllegalMonitorStateException 異常。
wait() 和 notify() 方法的上述特性決定了它們經常和synchronized 方法或塊一起使用,將它們和操作系統的進程間通信機制作一個比較就會發現它們的相似性:synchronized方法或塊提供了類似于操作系統原語的功能,它們的執行不會受到多線程機制的干擾,而這一對方法則相當于 block 和wakeup 原語(這一對方法均聲明為 synchronized)。它們的結合使得我們可以實現操作系統上一系列精妙的進程間通信的算法(如信號量算法),并用于解決各種復雜的線程間通信問題。
關于 wait() 和 notify() 方法最后再說明兩點:
第一:調用 notify() 方法導致解除阻塞的線程是從因調用該對象的 wait() 方法而阻塞的線程中隨機選取的,我們無法預料哪一個線程將會被選擇,所以編程時要特別小心,避免因這種不確定性而產生問題。
第二:除了 notify(),還有一個方法 notifyAll() 也可起到類似作用,唯一的區別在于,調用 notifyAll() 方法將把因調用該對象的wait() 方法而阻塞的所有線程一次性全部解除阻塞。當然,只有獲得鎖的那一個線程才能進入可執行狀態。
談到阻塞,就不能不談一談死鎖,略一分析就能發現,suspend() 方法和不指定超時期限的 wait() 方法的調用都可能產生死鎖。遺憾的是,Java 并不在語言級別上支持死鎖的避免,我們在編程中必須小心地避免死鎖。
以上我們對 Java 中實現線程阻塞的各種方法作了一番分析,我們重點分析了 wait() 和 notify() 方法,因為它們的功能最強大,使用也最靈活,但是這也導致了它們的效率較低,較容易出錯。實際使用中我們應該靈活使用各種方法,以便更好地達到我們的目的。
七:守護線程
守護線程是一類特殊的線程,它和普通線程的區別在于它并不是應用程序的核心部分,當一個應用程序的所有非守護線程終止運行時,即使仍然有守護線程在運行,應用程序也將終止,反之,只要有一個非守護線程在運行,應用程序就不會終止。守護線程一般被用于在后臺為其它線程提供服務。
可以通過調用方法 isDaemon() 來判斷一個線程是否是守護線程,也可以調用方法 setDaemon() 來將一個線程設為守護線程。
八:線程組
線程組是一個 Java 特有的概念,在 Java 中,線程組是類ThreadGroup 的對象,每個線程都隸屬于唯一一個線程組,這個線程組在線程創建時指定并在線程的整個生命期內都不能更改。你可以通過調用包含 ThreadGroup 類型參數的 Thread 類構造函數來指定線程屬的線程組,若沒有指定,則線程缺省地隸屬于名為 system 的系統線程組。
在 Java 中,除了預建的系統線程組外,所有線程組都必須顯式創建。在 Java 中,除系統線程組外的每個線程組又隸屬于另一個線程組,你可以在創建線程組時指定其所隸屬的線程組,若沒有指定,則缺省地隸屬于系統線程組。這樣,所有線程組組成了一棵以系統線程組為根的樹。
Java 允許我們對一個線程組中的所有線程同時進行操作,比如我們可以通過調用線程組的相應方法來設置其中所有線程的優先級,也可以啟動或阻塞其中的所有線程。
Java 的線程組機制的另一個重要作用是線程安全。線程組機制允許我們通過分組來區分有不同安全特性的線程,對不同組的線程進行不同的處理,還可以通過線程組的分層結構來支持不對等安全措施的采用。Java 的 ThreadGroup 類提供了大量的方法來方便我們對線程組樹中的每一個線程組以及線程組中的每一個線程進行操作。
九:總結
在本文中,我們講述了 Java 多線程編程的方方面面,包括創建線程,以及對多個線程進行調度、管理。我們深刻認識到了多線程編程的復雜性,以及線程切換開銷帶來的多線程程序的低效性,這也促使我們認真地思考一個問題:我們是否需要多線程?何時需要多線程?
多線程的核心在于多個代碼塊并發執行,本質特點在于各代碼塊之間的代碼是亂序執行的。我們的程序是否需要多線程,就是要看這是否也是它的內在特點。
假如我們的程序根本不要求多個代碼塊并發執行,那自然不需要使用多線程;假如我們的程序雖然要求多個代碼塊并發執行,但是卻不要求亂序,則我們完全可以用一個循環來簡單高效地實現,也不需要使用多線程;只有當它完全符合多線程的特點時,多線程機制對線程間通信和線程管理的強大支持才能有用武之地,這時使用多線程才是值得的
]]>
多線程是這樣一種機制,它允許在程序中并發執行多個指令流,每個指令流都稱為一個線程,彼此間互相獨立。 線程又稱為輕量級進程,它和進程一樣擁有獨立的執行控制,由操作系統負責調度,區別在于線程沒有獨立的存儲空間,而是和所屬進程中的其它線程共享一個存儲空間,這使得線程間的通信遠較進程簡單。
多個線程的執行是并發的,也就是在邏輯上“同時”,而不管是否是物理上的“同時”。如果系統只有一個CPU,那么真正的“同時”是不可能的,但是由于CPU的速度非常快,用戶感覺不到其中的區別,因此我們也不用關心它,只需要設想各個線程是同時執行即可。多線程和傳統的單線程在程序設計上最大的區別在于,由于各個線程的控制流彼此獨立,使得各個線程之間的代碼是亂序執行的,由此帶來的線程調度,同步等問題,將在以后探討。
二:在Java中實現多線程
我們不妨設想,為了創建一個新的線程,我們需要做些什么?很顯然,我們必須指明這個線程所要執行的代碼,而這就是在Java中實現多線程我們所需要做的一切!
真是神奇!Java是如何做到這一點的?通過類!作為一個完全面向對象的語言,Java提供了類 java.lang.Thread 來方便多線程編程,這個類提供了大量的方法來方便我們控制自己的各個線程,我們以后的討論都將圍繞這個類進行。
那么如何提供給 Java 我們要線程執行的代碼呢?讓我們來看一看 Thread 類。Thread 類最重要的方法是 run() ,它為Thread 類的方法start() 所調用,提供我們的線程所要執行的代碼。為了指定我們自己的代碼,只需要覆蓋它!
方法一:繼承 Thread 類,覆蓋方法 run(),我們在創建的 Thread 類的子類中重寫 run() ,加入線程所要執行的代碼即可。下面是一個
例子:
public class MyThread extends Thread {
int count= 1, number;
public MyThread(int num) {
number = num;
System.out.println("創建線程 " + number);
}
public void run() {
while(true) {
System.out.println("線程 " + number + ":計數 " + count);
if(++count== 6) return;
}
}
public static void main(String args[]) {
for(int i = 0; i < 5; i++) new MyThread(i+1).start();
}
}
這種方法簡單明了,符合大家的習慣,但是,它也有一個很大的缺點,那就是如果我們的類已經從一個類繼承(如小程序必須繼承自Applet 類),則無法再繼承 Thread 類,這時如果我們又不想建立一個新的類,應該怎么辦呢?
我們不妨來探索一種新的方法:我們不創建 Thread 類的子類,而是直接使用它,那么我們只能將我們的方法作為參數傳遞給 Thread 類的實例,有點類似回調函數。但是 Java 沒有指針,我們只能傳遞一個包含這個方法的類的實例。那么如何限制這個類必須包含這一方法呢?當然是使用接口!(雖然抽象類也可滿足,但是需要繼承,而我們之所以要采用這種新方法,不就是為了避免繼承帶來的限制嗎?) Java 提供了接口 java.lang.Runnable 來支持這種方法。
方法二:實現 Runnable 接口
Runnable 接口只有一個方法 run(),我們聲明自己的類實現 Runnable 接口并提供這一方法,將我們的線程代碼寫入其中,就完成了這一部分的任務。但是 Runnable 接口并沒有任何對線程的支持,我們還必須創建 Thread 類的實例,這一點通過 Thread 類的構造函數public
Thread(Runnable target);來實現。下面是一個例子:
public class MyThread implements Runnable {
int count= 1, number;
public MyThread(int num) {
number = num;
System.out.println("創建線程 " + number);
}
public void run() {
while(true) {
System.out.println("線程 " + number + ":計數 " + count);
if(++count== 6) return;
}
}
public static void main(String args[]) {
for(int i = 0; i < 5; i++) new Thread(new MyThread(i+1)).start();
}
}
嚴格地說,創建 Thread 子類的實例也是可行的,但是必須注意的是,該子類必須沒有覆蓋 Thread 類的 run 方法,否則該線程執行的將是子類的 run 方法,而不是我們用以實現Runnable 接口的類的 run 方法,對此大家不妨試驗一下。
使用 Runnable 接口來實現多線程使得我們能夠在一個類中包容所有的代碼,有利于封裝,它的缺點在于,我們只能使用一套代碼,若想創建多個線程并使各個線程執行不同的代碼,則仍必須額外創建類,如果這樣的話,在大多數情況下也許還不如直接用多個類分別繼承 Thread
來得緊湊。
綜上所述,兩種方法各有千秋,大家可以靈活運用。
下面讓我們一起來研究一下多線程使用中的一些問題。
三:線程的四種狀態
1. 新狀態:線程已被創建但尚未執行(start() 尚未被調用)。
2. 可執行狀態:線程可以執行,雖然不一定正在執行。CPU 時間隨時可能被分配給該線程,從而使得它執行。
3. 死亡狀態:正常情況下 run() 返回使得線程死亡。調用 stop()或 destroy() 亦有同樣效果,但是不被推薦,前者會產生異常,后者是強制終止,不會釋放鎖。
4. 阻塞狀態:線程不會被分配 CPU 時間,無法執行。
四:線程的優先級
線程的優先級代表該線程的重要程度,當有多個線程同時處于可執行狀態并等待獲得 CPU 時間時,線程調度系統根據各個線程的優先級來決定給誰分配 CPU 時間,優先級高的線程有更大的機會獲得 CPU 時間,優先級低的線程也不是沒有機會,只是機會要小一些罷了。
你可以調用 Thread 類的方法 getPriority() 和setPriority()來存取線程的優先級,線程的優先級界于1(MIN_PRIORITY)和10(MAX_PRIORITY)之間,缺省是5(NORM_PRIORITY)。
五:線程的同步
由于同一進程的多個線程共享同一片存儲空間,在帶來方便的同時,也帶來了訪問沖突這個嚴重的問題。Java語言提供了專門機制以解決這種沖突,有效避免了同一個數據對象被多個線程同時訪問。
由于我們可以通過 private 關鍵字來保證數據對象只能被方法訪問,所以我們只需針對方法提出一套機制,這套機制就是 synchronized關鍵字,它包括兩種用法:synchronized 方法和 synchronized 塊。
1. synchronized 方法:通過在方法聲明中加入 synchronized關鍵字來聲明 synchronized 方法。如:
public synchronized void accessVal(int newVal);
synchronized 方法控制對類成員變量的訪問:每個類實例對應一把鎖,每個 synchronized 方法都必須獲得調用該方法的類實例的鎖方能執行,否則所屬線程阻塞,方法一旦執行,就獨占該鎖,直到從該方法返回時才將鎖釋放,此后被阻塞的線程方能獲得該鎖,重新進入可執行狀態。這種機制確保了同一時刻對于每一個類實例,其所有聲明為 synchronized 的成員函數中至多只有一個處于可執行狀態(因為至多只有一個能夠獲得該類實例對應的鎖),從而有效避免了類成員變量的訪問沖突(只要所有可能訪問類成員變量的方法均被聲明為 synchronized)。
在 Java 中,不光是類實例,每一個類也對應一把鎖,這樣我們也可將類的靜態成員函數聲明為 synchronized ,以控制其對類的靜態成員變量的訪問。
synchronized 方法的缺陷:若將一個大的方法聲明為synchronized 將會大大影響效率,典型地,若將線程類的方法 run() 聲明為synchronized ,由于在線程的整個生命期內它一直在運行,因此將導致它對本類任何 synchronized 方法的調用都永遠不會成功。當然我們可以通過將訪問類成員變量的代碼放到專門的方法中,將其聲明為 synchronized ,并在主方法中調用來解決這一問題,但是 Java 為我們提供了更好的解決辦法,那就是 synchronized 塊。
2. synchronized 塊:通過 synchronized關鍵字來聲明synchronized 塊。語法如下:
synchronized(syncObject) {
//允許訪問控制的代碼
}
synchronized 塊是這樣一個代碼塊,其中的代碼必須獲得對象 syncObject (如前所述,可以是類實例或類)的鎖方能執行,具體機制同前所述。由于可以針對任意代碼塊,且可任意指定上鎖的對象,故靈活性較高。
]]>
2.線程的狀態有'Ready', 'Running', 'Sleeping', 'Blocked', 和 'Waiting'幾個狀態,
'Ready' 表示線程正在等待CPU分配允許運行的時間。
3.線程運行次序并不是按照我們創建他們時的順序來運行的,CPU處理線程的順序是不確定的,如果需要確定,那么必須手工介入,使用setPriority()方法設置優先級。
4.我們無從知道一個線程什么時候運行,兩個或多個線程在訪問同一個資源時,需要synchronized
5. 每個線程會注冊自己,實際某處存在著對它的引用,因此,垃圾回收機制對它就“束手無策”了。
6. Daemon線程區別一般線程之處是:主程序一旦結束,Daemon線程就會結束。
7. 一個對象中的所有synchronized方法都共享一把鎖,這把鎖能夠防止多個方法對通用內存同時進行的寫操作。synchronized static方法可在一個類范圍內被相互間鎖定起來。
8. 對于訪問某個關鍵共享資源的所有方法,都必須把它們設為synchronized,否則就不能正常工作。
9. 假設已知一個方法不會造成沖突,最明智的方法是不要使用synchronized,能提高些性能。
10. 如果一個"同步"方法修改了一個變量,而我們的方法要用到這個變量(可能是只讀),最好將自己的這個方法也設為 synchronized。
11. synchronized不能繼承, 父類的方法是synchronized,那么其子類重載方法中就不會繼承“同步”。
12. 線程堵塞Blocked有幾個原因造成:
(1)線程在等候一些IO操作
(2)線程試圖調用另外一個對象的“同步”方法,但那個對象處于鎖定狀態,暫時無法使用。
13.原子型操作(atomic), 對原始型變量(primitive)的操作是原子型的atomic. 意味著這些操作是線程安全的, 但是大部分情況下,我們并不能正確使用,來看看 i = i + 1 , i是int型,屬于原始型變量:
(1)從主內存中讀取i值到本地內存.
(2)將值從本地內存裝載到線程工作拷貝中.
(3)裝載變量1.
(4)將i 加 1.
(5)將結果給變量i.
(6)將i保存到線程本地工作拷貝中.
(7)寫回主內存.
注意原子型操作只限于第1步到第2步的讀取以及第6到第7步的寫, i的值還是可能被同時執行i=i+1的多線程中斷打擾(在第4步)。
double 和long 變量是非原子型的(non-atomic)。數組是object 非原子型。
14. 由于13條的原因,我們解決辦法是:
class xxx extends Thread{
//i會被經常修改
private int i;
public synchronized int read(){ return i;}
public synchronized void update(){ i = i + 1;}
..........
}
15. Volatile變量, volatile變量表示保證它必須是與主內存保持一致,它實際是"變量的同步", 也就是說對于volatile變量的操作是原子型的,如用在long 或 double變量前。
16. 使用yield()會自動放棄CPU,有時比sleep更能提升性能。
17. sleep()和wait()的區別是:wait()方法被調用時會解除鎖定,但是我們能使用它的地方只是在一個同步的方法或代碼塊內。
18. 通過制造縮小同步范圍,盡可能的實現代碼塊同步,wait(毫秒數)可在指定的毫秒數可退出wait;對于wait()需要被notisfy()或notifyAll()踢醒。
19. 構造兩個線程之間實時通信的方法分幾步:
(1). 創建一個PipedWriter和一個PipedReader和它們之間的管道;
PipedReader in = new PipedReader(new PipedWriter())
(2). 在需要發送信息的線程開始之前,將外部的PipedWriter導向給其內部的Writer實例out
(3). 在需要接受信息的線程開始之前,將外部的PipedReader導向給其內部的Reader實例in
(4). 這樣放入out的所有東西度可從in中提取出來。
20. synchronized帶來的問題除性能有所下降外,最大的缺點是會帶來死鎖DeadLock,只有通過謹慎設計來防止死鎖,其他毫無辦法,這也是線程難以馴服的一個原因。不要再使用stop() suspend() resume()和destory()方法
21. 在大量線程被堵塞時,最高優先級的線程先運行。但是不表示低級別線程不會運行,運行概率小而已。
22. 線程組的主要優點是:使用單個命令可完成對整個線程組的操作。很少需要用到線程組。
23. 從以下幾個方面提升多線程的性能:
檢查所有可能Block的地方,盡可能的多的使用sleep或yield()以及wait();
盡可能延長sleep(毫秒數)的時間;
運行的線程不用超過100個,不能太多;
不同平臺linux或windows以及不同JVM運行性能差別很大。
24. 推薦幾篇相關英文文章:
Use Threading Tricks to Improve Programs
]]>
1.Java沒有全局變量;
2.Java 的線程之間的通信比較差,C++提供了多種通信方式;
3.Java的數據同步是通過synchronized來實現,但是基本上等于交給了虛擬機來完成,
而C++有很多種:臨界區、互斥體等。
4. Java的多線程run方法沒有返回值,因此如何能得到子線程的反饋信息,確實令人頭疼。
5.Java的多線程是協作式,這樣等于操作系統放棄了對線程的控制;
這里談談我在java多線程中的編寫經驗:
1.創建thread時,將主控類或者叫做調用類傳入構造函數中,例如:
Class A調用Class B,Class A作為Class B構造函數的參數。
這樣再創建一個子線程時,用同樣的方式實現,這樣主控類的實例變量就可以作為
全局變量,當然要注意同步。
2. 類同步中wait(),notify()一定要考慮好邏輯,不然有可能造成阻塞。
3. 如果多個線程調用或者目前不是很清楚有多少個線程進行通信,最好的辦法是
自己實現一個listener,然后調用類調用Listener的一個實例方法進行通信。
工作原理:
1) Listener接口提供同步方法 例如SynData();
2) 同步線程提供添加和刪除Listener的方法,同時在線程中對注冊Listener
的類進行輪流通知;
3) 使用給同步數據的線程類,繼承Listener接口,實現其方法,將本線程即將結束的數據發送到同步線程中;
其實這個原理來自于Java Swing技術。
由于時間關系,今天就談到這里,希望能拋磚引玉!!請大家多多指教!
下一次談一談我用上面的方式實現的一個網關實例,謝謝各位!
]]>
http://www.java2s.com/ExampleCode/J2ME/CatalogJ2ME.htm
]]>
java程序顯示中文是大家都遇到過的問題,尤其是JAD文件的中文問題,一般都用native2ascii工具轉換,這里收藏了native2ascii工具的詳細說明:
native2ascii - Native-to-ASCII Converter
Converts a file with native-encoded characters (characters which are non-Latin 1 and non-Unicode) to one with Unicode-encoded characters.
SYNOPSIS
native2ascii [options] [inputfile [outputfile]]
DESCRIPTION
The Java compiler and other Java tools can only process files which contain Latin-1 and/or Unicode-encoded (\udddd notation) characters. native2ascii converts files which contain other
character encodings into files containing Latin-1 and/or Unicode-encoded charaters.
If outputfile is omitted, standard output is used for output. If, in addition, inputfile is
omitted, standard input is used for input.
OPTIONS
-reverse
Perform the reverse operation: convert a file with Latin-1 and/or Unicode encoded characters to one with native-encoded characters.
-encoding encoding_name
Specify the encoding name which is used by the conversion procedure.
The default encoding is taken from System property file.encoding.
The encoding_name string must be a string taken from the first column of the table
below.
-------------------------------------------------------------
Converter Description
Class
-------------------------------------------------------------
8859_1 ISO 8859-1
8859_2 ISO 8859-2
8859_3 ISO 8859-3
8859_4 ISO 8859-4
8859_5 ISO 8859-5
8859_6 ISO 8859-6
8859_7 ISO 8859-7
8859_8 ISO 8859-8
8859_9 ISO 8859-9
Big5 Big5, Traditional Chinese
CNS11643 CNS 11643, Traditional Chinese
Cp037 USA, Canada(Bilingual, French), Netherlands,
Portugal, Brazil, Australia
Cp1006 IBM AIX Pakistan (Urdu)
Cp1025 IBM Multilingual Cyrillic: Bulgaria, Bosnia,
Herzegovinia, Macedonia(FYR)
Cp1026 IBM Latin-5, Turkey
Cp1046 IBM Open Edition US EBCDIC
Cp1097 IBM Iran(Farsi)/Persian
Cp1098 IBM Iran(Farsi)/Persian (PC)
Cp1112 IBM Latvia, Lithuania
Cp1122 IBM Estonia
Cp1123 IBM Ukraine
Cp1124 IBM AIX Ukraine
Cp1125 IBM Ukraine (PC)
Cp1250 Windows Eastern European
Cp1251 Windows Cyrillic
Cp1252 Windows Latin-1
Cp1253 Windows Greek
Cp1254 Windows Turkish
Cp1255 Windows Hebrew
Cp1256 Windows Arabic
Cp1257 Windows Baltic
Cp1258 Windows Vietnamese
Cp1381 IBM OS/2, DOS People's Republic of China (PRC)
Cp1383 IBM AIX People's Republic of China (PRC)
Cp273 IBM Austria, Germany
Cp277 IBM Denmark, Norway
Cp278 IBM Finland, Sweden
Cp280 IBM Italy
Cp284 IBM Catalan/Spain, Spanish Latin America
Cp285 IBM United Kingdom, Ireland
Cp297 IBM France
Cp33722 IBM-eucJP - Japanese (superset of 5050)
Cp420 IBM Arabic
Cp424 IBM Hebrew
Cp437 MS-DOS United States, Australia, New Zealand,
South Africa
Cp500 EBCDIC 500V1
Cp737 PC Greek
Cp775 PC Baltic
Cp838 IBM Thailand extended SBCS
Cp850 MS-DOS Latin-1
Cp852 MS-DOS Latin-2
Cp855 IBM Cyrillic
Cp857 IBM Turkish
Cp860 MS-DOS Portuguese
Cp861 MS-DOS Icelandic
Cp862 PC Hebrew
Cp863 MS-DOS Canadian French
Cp864 PC Arabic
Cp865 MS-DOS Nordic
Cp866 MS-DOS Russian
Cp868 MS-DOS Pakistan
Cp869 IBM Modern Greek
Cp870 IBM Multilingual Latin-2
Cp871 IBM Iceland
Cp874 IBM Thai
Cp875 IBM Greek
Cp918 IBM Pakistan(Urdu)
Cp921 IBM Latvia, Lithuania (AIX, DOS)
Cp922 IBM Estonia (AIX, DOS)
Cp930 Japanese Katakana-Kanji mixed with 4370 UDC,
superset of 5026
Cp933 Korean Mixed with 1880 UDC, superset of 5029
Cp935 Simplified Chinese Host mixed with 1880 UDC,
superset of 5031
Cp937 Traditional Chinese Host miexed with 6204 UDC,
superset of 5033
Cp939 Japanese Latin Kanji mixed with 4370 UDC,
superset of 5035
Cp942 Japanese (OS/2) superset of 932
Cp948 OS/2 Chinese (Taiwan) superset of 938
Cp949 PC Korean
Cp950 PC Chinese (Hong Kong, Taiwan)
Cp964 AIX Chinese (Taiwan)
Cp970 AIX Korean
EUCJIS JIS, EUC Encoding, Japanese
GB2312 GB2312, EUC encoding, Simplified Chinese
GBK GBK, Simplified Chinese
ISO2022CN ISO 2022 CN, Chinese
ISO2022CN_CNS CNS 11643 in ISO-2022-CN form, T. Chinese
ISO2022CN_GB GB 2312 in ISO-2022-CN form, S. Chinese
ISO2022KR ISO 2022 KR, Korean
JIS JIS, Japanese
JIS0208 JIS 0208, Japanese
KOI8_R KOI8-R, Russian
KSC5601 KS C 5601, Korean
MS874 Windows Thai
MacArabic Macintosh Arabic
MacCentralEurope Macintosh Latin-2
MacCroatian Macintosh Croatian
MacCyrillic Macintosh Cyrillic
MacDingbat Macintosh Dingbat
MacGreek Macintosh Greek
MacHebrew Macintosh Hebrew
MacIceland Macintosh Iceland
MacRoman Macintosh Roman
MacRomania Macintosh Romania
MacSymbol Macintosh Symbol
MacThai Macintosh Thai
MacTurkish Macintosh Turkish
MacUkraine Macintosh Ukraine
SJIS Shift-JIS, Japanese
UTF8 UTF-8
不過WTK可以直接解決JAD的中文問題:
settings>MidLets>MidLet-1屬性改成你想要顯示的中文后重新生成JAD和JAR文件即可。
]]>
1、 企業級應用框架的需求
在許多企業級應用中,例如數據庫連接、郵件服務、事務處理等都是一些通用企業需求模塊,這些模塊如果每次再開發中都由開發人員來完成的話,將會造成開發周期長和代碼可靠性差等問題。于是許多大公司開發了自己的通用模塊服務。這些服務性的軟件系列同陳為中間件。
2、 為了通用必須要提出規范,不然無法達到通用
在上面的需求基礎之上,許多公司都開發了自己的中間件,但其與用戶的溝通都各有不同,從而導致用戶無法將各個公司不同的中間件組裝在一塊為自己服務。從而產生瓶頸。于是提出標準的概念。其實J2EE就是基于JAVA技術的一系列標準。
注:中間件的解釋 中間件處在操作系統和更高一級應用程序之間。他充當的功能是:將應用程序運行環境與操作系統隔離,從而實現應用程序開發者不必為更多系統問題憂慮,而直接關注該應用程序在解決問題上的能力 。我們后面說到的容器的概念就是中間件的一種。
二、相關名詞解釋
容器:充當中間件的角色
WEB容器:給處于其中的應用程序組件(JSP,SERVLET)提供一個環境,使JSP,SERVLET直接更容器中的環境變量接口交互,不必關注其它系統問題。主要有WEB服務器來實現。例如:TOMCAT,WEBLOGIC,WEBSPHERE等。該容器提供的接口嚴格遵守J2EE規范中的WEB APPLICATION 標準。我們把遵守以上標準的WEB服務器就叫做J2EE中的WEB容器。
EJB容器:Enterprise java bean 容器。更具有行業領域特色。他提供給運行在其中的組件EJB各種管理功能。只要滿足J2EE規范的EJB放入該容器,馬上就會被容器進行高效率的管理。并且可以通過現成的接口來獲得系統級別的服務。例如郵件服務、事務管理。
WEB容器和EJB容器在原理上是大體相同的,更多的區別是被隔離的外界環境。WEB容器更多的是跟基于HTTP的請求打交道。而EJB容器不是。它是更多的跟數據庫、其它服務打交道。但他們都是把與外界的交互實現從而減輕應用程序的負擔。例如SERVLET不用關心HTTP的細節,直接引用環境變量session,request,response就行、EJB不用關心數據庫連接速度、各種事務控制,直接由容器來完成。
RMI/IIOP:遠程方法調用/internet對象請求中介協議,他們主要用于通過遠程調用服務。例如,遠程有一臺計算機上運行一個程序,它提供股票分析服務,我們可以在本地計算機上實現對其直接調用。當然這是要通過一定的規范才能在異構的系統之間進行通信。RMI是JAVA特有的。
JNDI:JAVA命名目錄服務。主要提供的功能是:提供一個目錄系統,讓其它各地的應用程序在其上面留下自己的索引,從而滿足快速查找和定位分布式應用程序的功能。
JMS:JAVA消息服務。主要實現各個應用程序之間的通訊。包括點對點和廣播。
JAVAMAIL:JAVA郵件服務。提供郵件的存儲、傳輸功能。他是JAVA編程中實現郵件功能的核心。相當MS中的EXCHANGE開發包。
JTA:JAVA事務服務。提供各種分布式事務服務。應用程序只需調用其提供的接口即可。
JAF:JAVA安全認證框架。提供一些安全控制方面的框架。讓開發者通過各種部署和自定義實現自己的個性安全控制策略。
EAI:企業應用集成。是一種概念,從而牽涉到好多技術。J2EE技術是一種很好的集成實現。
三、J2EE的優越性
1、 基于JAVA 技術,平臺無關性表現突出
2、 開放的標準,許多大型公司已經實現了對該規范支持的應用服務器。如BEA ,IBM,ORACLE等。
3、 提供相當專業的通用軟件服務。
4、 提供了一個優秀的企業級應用程序框架,對快速高質量開發打下基礎
四、體系結構圖
mailto:luopc@edu-edu.com.cn了解更詳細的通俗體系內容,請給我來信。
五、現狀
J2EE是由SUN 公司開發的一套企業級應用規范。現在最高版本是1.4。支持J2EE的應用服務器有IBM WEBSPHERE APPLICATION SERVER,BEA WEBLOGIC SERVER,JBOSS,ORACLE APPLICATION SERVER,SUN ONE APPLICATION SERVER 等。.
]]>
]]>