推薦文章
使用 dom4j 解析 XML http://www.ibm.com/developerworks/cn/xml/x-dom4j.html
dom4j [百度百科] http://baike.baidu.com/view/1460716.htm
官網 http://www.dom4j.org/
]]>
同時也感謝其他作者,你們的文章給了我不少啟發
/Files/kiant/iis_tomcat.rar
]]>
Struts2.0標簽庫(三)表單標簽
及 Struts 2深入詳解 by.孫鑫
描述
對于表單標簽,分為兩種標簽:form標簽本身,和所有來包裝單個的表單元素的其他標簽.form標簽本身的行為不同于它內部的元素,這是很重要的.在我們為所有表單標簽,包括form標簽在內,提供一個參考手冊之前,我們必須先描述一些通用的屬性.
通用屬性
| 屬性 | Theme | 數據類型 | 描述 |
| cssClass | simple | String | 定義 html class 屬性 |
| cssStyle | simple | String | 定義html style 屬性 |
| title | simple | String | 定義html title 屬性 |
| disabled | simple | String | 定義html disabled 屬性 |
| label | xhtml | String | 定義表單元素的label |
| labelPosition | xhtml | String | 定義表單元素的label位置(top/left),缺省為left |
| requiredposition | xhtml | String | 定義required 標識相對label元素的位置 (left/right),缺省是 right |
| name | simple | String | 表單元素的name映射 |
| required | xhtml | Boolean | 在label中添加 * (true增加,否則不增加) |
| tabIndex | simple | String | 定義html tabindex 屬性 |
| value | simple | Object | 定義表單元素的value |
Javascript相關屬性
| 屬性 | Theme | 數據類型 | 描述 |
| onclick | simple | String | html javascript onclick 屬性 |
| ondbclick | simple | String | html javascript ondbclick 屬性 |
| onmousedown | simple | String | html javascript onmousedown 屬性 |
| onmouseup | simple | String | html javascript onmouseup 屬性 |
| onmouseover | simple | String | html javascript onmouseover 屬性 |
| onmouseout | simple | String | html javascript onmouseout 屬性 |
| onfocus | simple | String | html javascript onfocus 屬性 |
| onblur | simple | String | html javascript onblur 屬性 |
| onkeypress | simple | String | html javascript onkeypress 屬性 |
| onkeyup | simple | String | html javascript onkeyup 屬性 |
| onkeydown | simple | String | html javascript onkeydown 屬性 |
| onselect | simple | String | html javascript onselect 屬性 |
| onchange | simple | String | html javascript onchange 屬性 |
]]>
Struts2權威指南--基于WebWork核心的MVC開發 作者:李剛
浪曦_Struts2應用開發系列 講師:風中葉
Max On Java 的 Struts 2.0 系列
一、前言
Struts2 是 WebWork 的升級。它同樣適用攔截器作為處理(Advice),以用戶的業務邏輯控制器為目標,創建一個控制器代理。
Tomcat 文件服務器配置項目:
</Host>
path:URL虛擬路徑
docBase:對應的物理地址
reloadable:是否自動更新,發布后建議為 false
二、安裝
Struts2 的幾個核心 jar 文件:
commons-logging-1.0.4.jar、
freemarker-2.3.8.jar、
ognl-2.6.11.jar、
struts2-core-2.0.11.jar、
xwork-2.0.4.jar
三、配置:
編輯Web應用的web.xml配置文件,配置Struts 2的核心Filter。
<web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun. com/xml/ns/j2ee/web-app_2_4.xsd">

<!-- 定義Struts 2的FilterDispatcher的Filter -->
<filter>
<!-- 定義核心Filter的名字 -->
<filter-name>struts2</filter-name>
<!-- 定義核心Filter的實現類 -->
<filter-class>org.apache.Struts2.dispatcher.FilterDispatcher</ filter-class>
</filter>
<!-- FilterDispatcher用來初始化Struts 2并且處理所有的Web請求 -->
<filter-mapping>
<filter-name>Struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>
配置Action
<!-- 指定Struts 2配置文件的DTD信息 -->
<!DOCTYPE struts PUBLIC"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN""http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="strutsqs" extends="struts-default">
<action name="Login" class="lee.LoginAction">
<result name="error">/error.jsp</result>
<result name="success">/welcome.jsp</result>
</action>
</package>
</struts>
Struts 2還有一個配置 Struts 2全局屬性的 Properties 文件:
struts.devMode = false
#指定當Struts 2配置文件改變后,Web框架是否重新加載Struts 2配置文件
struts.configuration.xml.reload=true
ps. 更詳細的請閱覽
Max On Java 的 Struts 2.0 系列:為Struts 2.0做好準備
]]>
1、事務
1-1、類別
● 本地事務
如果事務只和一個資源管理器有關,則為本地事物。在本地事務中,事務管理器只是將事務的管理委托給底層的資源管理器。
● 分布式事務
分布式事務和多個可能不同的資源管理器以一種協調的方式進行交互。
1-2、Java 中事務處理
JDBC 事務:由底層數據庫事務管理器控制,操作比較簡單,但是不適合控制多個應用程序組件的事務,并且沒有傳播的上下問。
JTA 和 JTS:Java 事務 API 和 Java 事務服務,可以跨越多個組件和數據庫使用事務。在應用程序使用 JTA 控制事務操作時,需要從 JNDI 上下文中獲取 UserTranscation 和數據源。
UserTranscation ut = (UserTranscation) ctx.lookup("UserTranscation");
1-3、Hibernate 事務
● 基于 JDBC
Transcation 事務對象必須從 Session 中獲取,即事務必須和一個 Session 相關聯。
采用 Hibernate 內置的 current session 和上下文管理。
<property name="current_session_context_class">thread</property>
...
sessionFactory.getCurrentSession().beginTranscation();
● 基于 JTA
提供了跨 Session 的事務管理能力。
使用 SessionFactory.getCurrentSession() 方法簡化事務上下文的傳播,即在事務綁定 Session。
雖然一個 Session 范圍內可以存在多個事務操作,但是 Hibernate 并不支持嵌套的事務模型。
tx1
tx2
...
tx2.commit();
//數據庫操作,操作無效
tx1.commit();
2、并發控制
如果事務都是串行執行,則許多資源將處于空閑狀態。為了充分利用資源,發揮數據庫共享資源的優勢,必須允許多個事務并發地執行。
在單處理機系統中,事務并發執行實際上是這些并行事務輪流交叉執行,即交叉并發方式,并不是真正的并行執行。在多處理機系統中,每個處理機運行一個事務,實現事務真正意義上的并存運行,即同時并發方式。
當多個用戶并發地存取數據庫時,就會產生多個事務同時存取同一數據的情況。所以,必須實現一個控制系統,使一個事務所做的修改不會對其他事務所做的修改產生負面影響,這就是并發控制。
2-1、封鎖
對并發操作進行的正確調度,防止并發操作破壞了事務的隔離性。采用封鎖技術,事務 T 可以向系統發出請求,對某個對象例如表、記錄加鎖,在事務 T 釋放鎖之前,其他事務不能更新這些數據對象。
基本的封鎖有:
排他鎖(Exclusive Locks,X 鎖):寫鎖或者獨占鎖。
共享鎖(Share Locks,S 鎖):讀鎖。允許和其他事務一起讀取數據對象D,但不能對D 做任何修改。
2-2、事務隔離
使用封鎖技術,事務對申請的資源加鎖,但是會影響數據庫性能。根據數據對象封鎖的程度,可以分成多種不同的事務隔離級別。
數據并發執行時,產生不一致的現象:
丟失更新(Lost Update)
兩個事務讀入同一數據并修改,然后提交修改,T2 提交的結果破壞了 T1 提交的結果,導致 T1 的修改丟失。
② 不可重復讀
事務T1 讀取數據后,事務T2 執行了同一數據的跟新操作,使得事務 T1 無法再現前一次讀取的結果。
事務1 讀取某一數據后,事務2 對該數據作了修改,事務1 再次讀取時,得到數據和前一次不一致。
① 事務1 讀取某一些記錄后,事務2 刪除了同一數據源的部分數據,事務1 再次讀取時,發現某些記錄丟失。
① 事務1 讀取某一些記錄后,事務2 插入了同一數據源的新數據,事務1 再次讀取時,發現某些記錄增加。
③ 讀“臟”數據
事務T1 修改某一數據,并將其寫回物理數據庫。事務T2 讀取同一數據后,事務T1 由于某種原因被撤銷,數據庫將已經修改的數據恢復原值,導致事務T2 保持的數據和數據庫中的數據產生了不一致。
ANSI SQL-99 標準定義了下列隔離級別:
● 未提交讀(Read Uncommitted):隔離事務的最低級別,只能保證不會讀取到物理上損壞的數據。H:1;允許產生:①②③
● 已提交讀(Read Committed):常見數據庫引擎的默認級別,保證一個事務不會讀取到另一個事務已修改但未提交的數據。H:2;允許產生:①②
● 可重復讀(Repeatable Read):保證一個事務不能更新已經由另一個事務讀取但是未提交的數據。相當于應用中的已提交讀和樂觀并發控制。H:4;允許產生:①
● 可串行化(Serializable):隔離事務的最高級別,事務之間完全隔離。系統開銷最大。H:8;允許產生:
在數據庫中,可以手工設置事務的隔離級別。
Hibernate 在配置文件中聲明事務的隔離級別,Hibenate 獲取數據庫連接后,將根據隔離級別自動設置數據庫連接為指定的事務隔離級別。
<property name="connection.isolation">8</property>
2-3、并發控制類型
根據使用的鎖定策略和隔離等級,可以把事務的并發控制分為兩種:
① 悲觀并發控制
用戶使用時鎖定數據。主要應用于數據爭用激烈的環境中,以及發生并發沖突時用鎖保護數據的成本低于回滾事務成本的環境中。
Hibernate 的悲觀鎖定不在內存中鎖定數據,由底層數據庫負責完成。
② 樂觀并發控制
用戶讀取數據時不鎖定數據。當一個用戶更新數據時,系統將進行檢查該用戶讀取數據后其他用戶是否更改了該數據,是則產生一個錯誤,一般情況下,收到錯誤信息的用戶將回滾事務并重新開始。主要用戶數據爭用不大,且偶爾回滾事務的成本低于讀取數據時鎖定數據的成本的環境中。
Hibernate 中使用元素 version 和 timestamp 實現樂觀并發控制模式的版本控制,并提供多種編程方式。版本是數據庫表中的一個字段,可以是一個遞增的整數,也可以是一個時間戳,它們對應 Java 持久化類的一個屬性。事務提交成功后,Hibernate 自動修改版本號。如果另外一個事務同時訪問同一數據,若發現提交前的版本號和事前載入的版本號有出入,則認為發生了沖突,事務停止執行,撤銷操作,并拋出異常。應用程序必須捕捉該異常并做出一定的處理。
⒈應用程序級別的版本控制
⒉長生命周期會話的自動化版本控制
⒊托管對象的自動化版本控制
⒋定制自動化版本控制
3、Hibernate 緩存
Hibernate 提供兩級緩存架構,第一級緩存是 Session 內的緩存,第二級緩存是一個可插拔的緩存,能夠借助第三方的組件實現。如果應用程序中經常使用同樣的條件查詢數據,還可以使用查詢緩存來提高查詢效率。
針對緩存的范圍,可以將 Hibernate 持久層緩存分為三個層次:
① 事務級緩存
緩存只能被當前事務訪問。緩存的生命周期以來與事務的生命周期。事務緩存由 Session 實現。一個 Session 的緩存的內容只有在本 Session 實例范圍內可用。
② 應用級緩存
緩存在某個應用范圍內被所有事務共享。緩存的生命周期依賴于應用程序的生命周期。應用級緩存由 SessionFactory 實現,Session 實例由其創建,并共享其緩存。
③ 分布式緩存
集群環境中,緩存被一個 JVM 或多個 JVM 的進程共享。分布式緩存由多個應用級的緩存實例組成,緩存中的數據被復制到集群環境中的每個 JVM 節點,JVM 間通過遠程通信來保證緩存中數據的一致性。
3-1、緩存查詢結果
經常使用同樣的條件查詢數據,則可使用查詢緩存。查詢緩存需要和二級緩存聯合使用,在二級緩存中,可以專門為查詢緩存開辟一個命名緩存區域。查詢緩存啟動后將創建兩個緩存區域,org.hibernate.cache.StandardQueryCache 實現保存查詢結果集;org.hibernate.cache.UpdateTimestampsCache 實現保存最近更新的查詢表的時間戳。
<property name="cache.use_query_cache">true</propery>
//使用查詢緩存
query.setCacheable(true);
//給查詢緩存指定特定的命名緩存區域
query.setCacheRegion("queryCache");
//如果其他進程更新了結果集,強行刷新緩沖區域
query.setCacheMode(CacheMode.REFRESH);
//刷新某個或全部的緩存
SessionFactory.evictQueries() 方法
4、高級特性
4-1、數據庫連接池 ConnectionProvider
J2SE 環境中使用建議。
4-2、使用數據源
Hibernate 中,DatasourceConnectionProvider 實現了 ConnectionProvider 接口并封裝了數據源的獲取方法,充當了 Hibernate 和數據源間的適配器。
J2EE 環境中使用建議。
4-3、過濾數據
把公共的數據過濾條件提取出來。從 Hibernate 3.0 開始,可以利用 Hibernate Filter 對某個類或集合附加預先定義的過濾條件,在查詢時過濾指定條件的數據。該過濾器是全局有效的,使用時候,還可以指定特定參數。
4-4、批量處理
批量處理引發異常的根源在于緩存中保存了過多的持久化實例而耗盡內存。
① 應用程序級別的批處理
指定 Hibernate 處理 SQL 語句時,必須積累到指定數量后再向數據庫提交操作。
<property name="jdbc.batch_size">20</property>
② 無狀態 Session(StatelessSession)
StatelessSession 接口沒有持久化上下文,也不負責持久化實例的生命周期,沒有一級緩存,操作也不會影響到二級和查詢緩存。
③ 使用 DML 風格的 HQL 語句繞過內存直接進行數據處理
"delete Product p where p.id > :id"
4-4、延遲加載
設置延遲加載的屬性和集合只能在該實例依附的 Session 范圍內被訪問,會話關閉后,實例從持久態轉為托管態,再次訪問該實例的一些屬性時候,有可能會拋出 LazyInitializationException 異常。
① 屬性延遲加載(大對象)
② 持久化類延遲加載
③ 集合延遲加載
4-5、數據抓取策略(Fetching strategies)
可以在 Hibernate 中設定相應的數據抓取策略,減少系統產生的數據庫查詢操作,優化系統性能。
在 Hibernate 中,延遲(lazy)定義了一種契約,用來表示托管狀態實例中那些數據是有效的,而抓取(fetch)是用來調整 Hibernate 性能的。
4-5、監控性能
org.hibernate.stat 包提供的工具類。
5、附錄
5-1、XML 元數據
18.2. XML映射元數據 - Hibernate reference 3.2.0 ga 正式版中文參考手冊
18.3. 操作XML數據 (通過dom4j會話讀入和更新應用程序中的XML文檔)
5-2、開源工具箱
CownewStudio 是一個基于 Eclipse 的 Hibernate 正向建模輔助工具。通過它用戶能以圖形化的方式建立對象模型,然后根據模型生成持久化類、映射文件和數據庫表。
JDBMonitor。模擬一個 JDBC 驅動來代替真正的 JDBC 驅動,截取應用程序對數據庫的操作,并以合適的方式記錄下來,提供性能分析的來源和依據。
]]>
1、查詢返回
● 查詢語句可以返回多個對象或屬性,存放在 Object[] 隊列中。
● 將查詢結果的所有屬性都存放在一個 List 對象中:
select new list(xxx.xxxx,xx.xx) .....
這里的 new list 是實例化 java.util.ArraryList 對象。
● 將查詢結果封裝成一個安全的 Java 對象
select new EncCustomer(xx.xxx, xx.xx)....
● 將查詢結果封裝成 Map 對象(利用別名)
select new map(xx.xxx as aaaa, xx.xxxx as bb) .....
.....
Map obj = (Map)list.get(i);
obj.get("aaaa");
obj.get("bb");
● distinct 刪除重復數據
2、參數綁定機制
●
q.setParameter("name", name);
Hibernate 能根據參數值的 Java 類型推斷出對應的映射類型,對于日期類型,如 java.util.Date 類型,會對應多種映射類型,這時候需要顯示指定。
q.setParameter("date", Hibernate.DATE);
●
q.setProperties(obj);
根據 obj 的屬性名對應 HQL 語義中定義的命名參數進行查詢。
3、HQL 子查詢
用于子查詢的集合函數 size()、minIndex()、maxIndex()、minElement()、maxElement() 和 elements()。
4、集合過濾
對于某持久化對象的 items 屬性內元素性能優化(過濾集合內數據、排序等)。
Session.createFilter(object, string);
返回是 Query 類型
參數 object 是持久化對象的集合。
參數 string 是 HQL 的過濾條件
//過濾 prod 的集合 items
List items = session.createFilter(prod.getItems(),
"this.unitCost<100 order by this.ListPrice desc").List();
//綁定過濾的結果 itmes 到屬性
prod.setItems(items);
5、條件查詢 QBC
5-1、Restrictions 過濾結果集
5-2、結果集排序
.addOrder(Order.asc("name"))
.addOrder(Order.desc("category"))
.list();
5-3、createCriteria() 關聯查詢
List list = sess.createCriteria(Product.class)
.add(Restrictions.like("name", "%o%"))
.createCriteria("items")
.add(Restrictions.ge("listPrice", new Float(100.0))
.list();
//返回一個新的 Criteria 實例,該實例引用 items 集合中的元素,并且為該集合元素增加了元素屬性 listPrice 大于等于 100.0 的過濾條件。
或者使用別名
.createAlias("items", "ite")
.add(Restrictions.ge("ite.listPrice", new Float(100.0))
5-4、設置加載策略
.setFetchMode("items", FetchMode.EAGER)
.list();
DEFAULT:默認
EAGER/JOIN:強制立即加載
LAZY/SELECT:強制延遲加載
5-5、聚合和分組 org.hibernate.criterion.Projections
.setProjection(Projections.rowCount())
.uniqueResult();
.add(Projections.groupProperty("imagePath"))
.list();
5-6、離線與子查詢
離線查詢方式在 Session 范圍之外定義一個離線查詢,然后使用任意的 Session 執行查詢。該方法主要通過 org.hibernate.criterion.DetachedCriteria 類實現。
6、Native SQL 查詢
應用程序中使用與數據庫相關的 SQL 查詢語句
6-1、Native SQL 應用程序接口
主要使用 SQLQuery.addEntity() 實現返回結果為實體的查詢,SQLQuery.addScalar() 則返回標量值。
SQLQuery.addJoin(String alias, String path) 用于將映射對象所關聯的實體或集合對應起來。
6-2、命名查詢
sess.getNamedQuery(string);
在 xml 文件中使用 <! [CDATA []] > 元表示其中的內容是區分其他元素定義的純文本。例如: < 符號。
6-3、使用存儲過程
Hibernate 3.0 以上的版本已經支持和利用存儲過程來進行查詢,存儲過程返回的參數是標量與實體,這里可以利用返回類型的定義將存儲過程返回的參數映射到對象的屬性中。
<sql-query name="productQuery" callable="true">
<return alias="prod" class="petstore.domain.Product">
<return-property name="productId" column="PRODUCTID" />
<return-property name="description" column="DESCRIPTION" />
<return-property name="name" column="NAME" />
</return>
{? = call getProduct(?)}
</sql-query>
List list = query.list();
]]>
1、對象關系映射
1-1、單向多對一關聯
產品和分類的關系:多個不同產品屬于同一種分類。
private Category category;
<many-to-one name="category" column="categoryId" not-null="true" />
1-2、一對多映射
private Set products = new HashSet();
<set name="products" <!--Category 中集合屬性名稱為 products-->
table="product" <!--集合屬性對應表的名稱為 product-->
schema="test" <!--表的 schema 名稱為 test-->
lazy="true" <!--此集合采用延時加載策略-->
inverse="true" <!--由關聯屬性的另一方作為關聯的主控方-->
cascade="delete" <!--采用級聯刪除,當 Category 被刪除時關聯的此集合內容也將被刪除-->
sort="natural" <!--自然排序集合內容-->
order-by="productId asc" <!--按 productId 字段升序排列集合內容-->
>
<key column="category_fk" />
<one-to-many class="petstore.domain.Product" />
</set>
1-3、繼承映射
2、Hibernate 操作對象
2-1、對象的三種狀態
● 瞬時態(Transient)--VO(Value Ojbect)
對象實例產生到被 JVM 垃圾回收為止并不受 Hibernate 框架管理。
● 持久態(Persistent)--PO(Persistent Ojbect)
對象實例被 Hibernate 框架管理,該對象可能是剛被保存的,或剛從數據庫中被加載的。Hibernate 會檢測處于持久態的對象任何改動,在當前操作單元執行完畢將對象與數據庫同步,即將對象的屬性保存到數據庫映射對應的字段中。簡單點說就是該實體對象與 session 發生關系,而且處于 session 的有效期內。
● 托管態(Detached)--VO(Value Ojbect)
與持久對象關聯的 Session 被關閉后,對象就變為托管的,可繼續被修改。托管對象如果重新關聯到某個新的 Session 上,會再次變為持久的,同時改動也將會被持久化到數據庫。這個期間的轉變過程可以看作是應用程序事務,即中間會給用戶思考時間的長時間運行的操作單元。
處于托管態對象具有與數據庫表記錄間的聯系(持久化標識,identifier)。
2-2、對象操作的應用程序接口
● 修改對象
對于已經持久化的對象,不需要調用某個特定的方法就可以實現修改持久化,因為 Hibernate 會自動調用 flush() 方法保證與數據庫的同步。
對于處于托管狀態的實例,Hibernate 通過提供 Session.update() 或 Session.merge() 方法,重新關聯托管實例。但是需要注意的是:如果具有持久化標識(identifier)的對象之前已經被另一個會話連接(secondSession)裝載了,應用程序關聯操作會發生異常。
使用 merge() 方法時,用戶不必考慮 session 的狀態,可隨時將修改保存到數據庫中。例如:Session 中存在相同標識的持久化實例時,Hibernate 便會根據用戶給出的對象狀態覆蓋原有的持久化實例的狀態。
另外,Hibernate 還提供了 saveOrUpdate()方法,它即可分配新持久化標識(identifier),保存瞬時(transient)對象,又可更新/重新關聯托管的(identifier)實例。
● 刪除對象
通過 HQL 語句,調用重載的 delete(),可以一次刪除多個對象。
session.delete("from Customer as c where c.customerId <3");
● 查詢對象
已知對象表示符值查詢
對象標識符未知查詢 HQL
根據某些特定條件查詢 QBC,Query By Criteria
按詳例查詢 QBE,Query By Example
調用數據庫查詢 native SQL
查詢條件參數 ? 查詢條件參數索引,由 0 開始。
查詢條件實名 :name
外置命名查詢
在映射文件定義查詢語句,將程序與查詢語句分離:
<query name="CategoryById"
<! [CDATA[
from Category c where c.categoryId>? ]]>
</query>
程序調用:
Query q = sess.getNamedQuery("CategoryById");
q.setLong(0, name);
List cats = q.List();
用 Query 提供的 iterate() 方法遍歷查詢結果,如果查詢的結果在 session 或二級緩存(second-level cache)中,那么使用 iterate() 方法可以得到更好的性能。
如果 JDBC 驅動支持可滾動的 ResuleSet,Query 接口可以使用 ScrollableResults,允許你在查詢結果中靈活移動(需要保持數據庫連接和游標 cursor 處于抑制打開狀態)。
ScrollableResults cates = q.scroll();
cates.first()
cates.scroll(5);
● cascade 和 inverse 級聯操作
inverse
只對 set,one-to-many(或 many-to-many)有效,對于 many-to-one,one-to-one 無效
對集合起整體作用
cascade
對關系標記都有效
對集合的一個元素起作用,如果集合為空,那么 cascade 不會引發關聯操作
作用時機:在 flush 時(commit 會自動執行 flush),hibernate 會自行判斷每個 set 是否有變化,對有變化的 set 執行相應的 SQL,if (inverse) return。即:cascade 在前,inverse 在后。
異常:
org.hibernate.exception.ConstraintViolationException: could not insert
原因是 category_fk 字段約束不能為空,而在新建的 Product 對象時插入了空值,而且關聯關系由 Caterogy 對象維持,而被關聯的 Product 對象不知道自己與哪個 Category 對象關聯。說到底就是 pro 對象的 categoryId 值為空。
]]>
1-1、使用 ThreadLocal 控制 Session
應用程序根據配置文件構建應用程序運行的環境,建立全局范圍內的 SessionFactory 對象。其內部包含了 Hibernate 運行的全部細節,是產生 Session 的工廠,它是線程安全的,只能在系統啟動時實例化一次,系統運行期間不可修改。
Session 對象是 Hibernate 操作數據的核心,數據庫的操作、對象生命周期的管理、應用事務的劃分,都需要在 Session 對象中完成。Session 對象不是線程安全的,如果試圖讓多個線程同時使用一個 Session 對象,將會產生數據混亂,造成數據庫的數據不一致。而且頻繁開關 Session 是巨大的系統消耗。
為了安全地使用 Session 對象,需要應用 Java 語言中的線程綁定機制--ThreadLocal,它代表一個線程的私有存取空間,能夠隔離多線程環境中的并發機制,減少 Session 對象的創建和銷毀次數,降低系統資源浪費。




 }
} }
}1-2、建立數據庫結構
使用 Hibernate 時,設計生成數據庫表結構的方式分成兩種。
1、手工用 SQL 語句設計數據表結構
2、使用 Hibernate 根據映射文件自動構建數據庫模式
hibernate.cfg.xml:
<property name="hbm2dll.auto">creat</property>
<property name="show_sql">true</property>
log4j.properties
log4j.logger.org.hibernate.tool.hbm2dll=debug
Hibernate 自行管理的數據庫表結構:
● none:不產生任何動作。
● create:在應用啟動時,自動生成數據庫表結構并導入到數據庫中。
● create-drop:同 create,但在應用關閉時,刪除已生成的數據庫表結構;此方式常在測試時使用。
● update:在應用啟動時,檢查持久化類和映射文件的改變,更新數據庫表結構,比如:持久化類添加一個屬性后,Hibernate 能自動添加對應字段到對應的數據庫表中。
3、使用 Session 操作數據庫
Hibernate 能自動管理系統中的持久化類和數據庫模式,通過 Session 對象實現對象模型和關系模型的相互操作。
Session 提供數據訪問的接口:
● get():從數據庫獲取數據對象,不存在時則返回 null。
● load():從數據庫獲取數據對象,不存在時則拋出異常。
● createQuery():根據條件查詢數據對象。
● save()、update()、delete() 等方法。
2、Hibernate 基本組件接口
● Configuration(org.hibernate.cfg.Configuration)
Hibernate 應用的入口,它使用配置文件初始化運行環境,是 SessionFactory 的工廠。通常情況下,一個應用程序中只允許創建一個單例的 Configuration 實例。
● SessionFactory(org.hibernate.SessionFactory)
是一個線程安全的高速緩存,其中包含了單一數據庫和已編譯映射文件的元數據,在運行環境不可改變。它是 Session 的工廠,并能從 ConnectionProvider 中獲取 JDBC 連接。它可能持有一個可選的能在進程級別或者集群級別事務間重用的數據緩存(二級緩存)。SessionFactory 從 Configuration 中獲取,在一個應用范圍中,不允許改變。
● Session(org.hibernate.Session)
單線程的短生命周期的對象,是應用程序和持久化存儲的一次對話。封裝了一個 JDBC 連接,也是 Transaction 的工廠。它保持一個持久化對象的強制緩存(一級緩存),用來遍歷對象圖或者根據標識符查詢對象。Session 提供了一系列方法,可以方便地實現對象持久化操作。
● Transcation(org.hibernate.Transcation)
可選,單線程、短生命周期的對象,應用程序用它來表示一批任務的原子操作。是底層 JDBC,JTA 或者 CORBA 事務的抽象。一個 Session 在某些情況下可能跨越多個 Transcation 事務。
● ConnectionProvider(org.hibernate.connection.ConnectionProvider)
可選,JDBC 連接的工廠和連接池,是底層 Datasource 或 DriverManager 的抽象應用,對應用程序不可見。可擴展實現。
● TranscationFactory(org.hibernate.TranscationFactory)
可選,事務實例工廠。對應用程序不可見。可擴展實現。
在最小集合應用框架中,應用程序直接使用 JDBC/JTA,并自行完成事務處理。
conn = DriverManager.getConnection(xxx);
conn.setAutoCommit(false);
...
conn.commit();
3、Hibernate 生命周期
① Configuration 對象根據配置文件的設置,讀取屬性配置信息。
② Configuration 對象根據配置信息,按照映射文件、類緩存、集合緩存、監聽器、事件的順序依次讀取并解析。
③ 通過調用 Configuration 對象構建 SessionFactory。
④ 調用 SessionFactory 實例獲得 Session 對象。
⑤ 啟動事務。
⑥ 提交事務。
⑦ 關閉應用(Session 和 SessionFactory)。
4、Hibernate 中對象的狀態
為了區分持久化類的實例對象,根據對象和會話的關聯狀態,可以分為三種情況:
● 暫態狀態。對象剛建立,還沒有使用 Hibernate 進行保存。該對象在數據庫中沒有記錄,也不在 session 緩存中。如果該對象是自動生成主鍵,則該對象的對象標識符為空。
● 持久化對象。對象已經通過 Hibernate 進行了持久化,數據庫中已經存在對應的記錄。如果該對象是自動生成主鍵,則該對象的對象標識符已被賦值。
● 托管對象。該對象是經過 Hibernate 保存過或者從數據庫中取出的,但是與之關聯的 session 已經被關閉。雖然它擁有對象標識符,且數據庫中存在對應的記錄,但是已經不再被 Hibernate 管理。
ps. [轉] PO BO VO DTO POJO DAO概念及其作用(附轉換圖)
5、對象標識符
關系數據庫表的主鍵在 Java 應用環境中的體現。
5-1、關系型數據庫的主鍵生成機制
序列生成主鍵,整數
自動增長組件,整數
全局統一標識符 GUID(Globally Unique Identifier),字符串主鍵
5-2、Java 環境中的對象識別機制
引用比較,比地址 “==”
內容比較,比數據 equals() 方法
5-3、Hibernate 對象識別符的作用
在生成 Java 對象時,給標識屬性分配一個唯一的值,用于區分同一個類的多個不同的實例。體現在 Hibernate 中就是對象標識符。
5-4、Hibernate 內置標識符生成器的使用方法
org.hibernate.id.IdentifierGenerator 接口。
ps. 映射對象標識符
5-5、使用復合主鍵時組合標識符的使用方法(常用于遺留的系統中)
嵌入式組合標識符/映射式組合標識符,映射多個主鍵字段和持久化類的多個屬性。
6、配置 Hibernate
6-1、配置方式
可編程還是文件配置方式
Hibernate JDBC 配置屬性
hibernate.jdbc.fatch_size:指定 JDBC 抓取數據的數量大小,非零值
hibernate.jdbc.batach_size:允許 Hibernate 使用 JDBC2 的批量更新,非零值,建議 5 到 30
hibernate.jdbc.provider_class:自定義的 ConnectionProvider 類名,用于向 Hibernate 提供 JDBC 連接
hibernate.jdbc.autocommit:確認是否開啟 JDBC 自動提交功能,默認為 false 不自動提交
6-2、方言
屏蔽底層數據庫系統的方言機制,方便與數據庫間遷移。
MySQL:org.hibernate.dialect.MySQLDialect
MySQL with InnoDB:org.hibernate.dialect.MySQLInnoDBDialect
MySQL with MyISAM:org.hibernate.dialect.MySQLMyISAMDialect
6-3、Hibernate 日志系統
使用 Log4J 作為 Hibernate 的日志系統,需要將 Log4J 的庫文件 log4j.jar 放置到類路徑下(其發布包以包含 Log4J 的庫文件)。然后編寫日志配置文件 log4j.properties 并放到 classpath 路徑中。
Log4J 中,幾個日志輸出級別的順序是:只輸出高于或等于 設定級別 的記錄。
trace < debug < info < warn < error < fatal
在開發模式中,可以選擇 DEBUG 級別的輸出;應用部署后,可以配置為 ERROR。

7、Hibernate 映射類型
7-1、時間日期映射類型(內置映射類型)
Java 語言提供了 java.util.Date 和 java.util.Calendar 兩個類實現時間的運算。此外,JDBC 還提供了 java.util.Date 的三個擴展類 java.sql.Timestamp、java.sql.Time 和 java.sql.Date 分別對應標準 SQL 數據類型中的 TIMESPAME/DATETIME(時間日期)、TIME(時間)、DATE(日期)。
java.util.Date/java.sql.Date H:date SQL:DATE
java.util.Time/java.sql.Time H:time SQL:TIME
java.util.Date/java.sql.Timestamp H:timestamp SQL:TIMESTAMP/DATETIME
java.util.Calendar H:calendar SQL:TIMESTAMP/DATETIME
java.util.Calendar H:calendar_date SQL:DATE
7-2、自定義映射類型
]]>
數據庫技術已經成為企業信息平臺的核心。應用程序必須將業務相關的數據通過一定方式持久化到數據庫,還應能夠從數據庫獲取已有的數據,以適當的形式提供給客戶或支撐系統的運行。
關鍵點:如何高效地存取數據、簡化編程模型、降低應用的復雜度
在系統中引入持久層,負責所有相關數據的持久化操作,可以為整個應用系統提供一個高層、統一、安全、并發的數據持久機制。
1、對象持久化技術
1-1、Java 對象序列化
序列化是 Java 語言中內置的輕量級數據持久化機制,該機制可以將任何實現了 java.io.Serializable 接口的對象轉化為連續的字節流數據,保存在文件中,或者通過網絡進行傳輸。這些數據日后可被還原為原先的對象狀態。
缺點:局限性大,查詢只能返回數據流的下一個對象,不提供部分的讀取和更新,不提供對象的生命周期管理,只是簡單的讀取和寫入,不提供并發和事務特性。
1-2、使用 JDBC
JDBC(Java Database Connectivity)是用來訪問關系數據庫系統的標準 Java API。JDBC 只是提供訪問數據的接口,其底層實現有特定的數據庫廠商實現。
缺點:直接使用 JDBC 實現持久化時,SQL 語句和應用代碼混雜在一起,邏輯混亂。另外直接使用 SQL 操作數據庫,不是面向對象。
1-3、使用 JDO
Java 數據對象(Java Data Object)是 JCP(Java Community Process)發布的一個規范,是 Java 對象持久化的標準。JDO 僅定義了標準的編程接口,而把關系映射的定義留給軟件供應商實現。
1-4、實體 EJB
實體 EJB(Enterpise Java Bean)是 Java 領域的數據持久化標準。
1-5、對象關系映射
對象關系映射(Ojbect Relation Mapping)在對象模型和關系模型之間建立溝通的橋梁。ORM 技術封裝了數據持久化的操作細節,為應用程序提供了一只訪問的接口,使應用程序可以專注于業務邏輯的處理。它采用 POJO(Plain Old Java Object,簡單的傳統對象)作為域對象的表述,不涉及域對象之外的技術細節,降低的 ORM 技術的侵入性,實現簡單,便于測試,具備高擴展性。
2、對象關系映射模型
一個完整的對象關系映射框架,應具備以下四個方面:
①、一個元數據映射規范,負責持久化類、類屬性的數據庫表、字段的映射,實現對象和關系的語義連接。
②、一組對象操作接口,用于完成數據的增加、刪除、修改和更新等操作。
③、一種面向對象的查詢語言,該語言能理解繼承、多態和關聯等面向對象特性,實現基于對象的查詢并在對象之間導航。
④、一系列與數據庫現關的技術實現和最佳實踐,保證系統的完整性并提高系統的可用性和擴展性。比如:事務、緩存和數據抓取策略等。
對象模型(類、屬性、關聯) <==> 關系模型(表、字段、約束)
ps. <Hibernate 完全手冊>
ISBN 978-7-111-23764-8
機械工業出版社
侯志松 余周 鄭煥 等編著
]]>
JDBC-ODBC 橋連(不需驅動)
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection conn = DriverManager.getConnection("jdbc:odbc:test", "sa", "love2you");
SQL SERVER 2005 直連 [驅動下載]
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
Connection conn = DriverManager.getConnection(
"jdbc:sqlserver://10.0.0.99:1433;databaseName=deviantART",
"sa",
"love2you");
轉==============
常用 JDBC 驅動名字和 URL 列表
ODBC driver
sun.jdbc.odbc.JdbcOdbcDriver
jdbc:odbc:name
用 COM.ibm.db2.jdbc.net.DB2Driver 連接到 DB2 數據庫
一個 DB2 URL 的示例:
jdbc:db2://aServer.myCompany.com:50002/name
用 com.sybase.jdbc.SybDriver連接到 Sybase 數據庫
一個 Sybase URL 的示例:
jdbc:sybase:Tds:aServer.myCompany.com:2025
MySQL driver
com.mysql.jdbc.Driver
jdbc:mysql://hostname:3306/dbname?useUnicode=true&characterEncoding=GBK
Microsoft SQL Server Driver
com.microsoft.jdbc.sqlserver.SQLServerDriver
jdbc:microsoft:sqlserver://127.0.0.1:1433;DatabaseName=WapSvc;User=sa;Password=pwd
Informix
com.informix.jdbc.IfxDriver
jdbc:informix-sqli://hostname:1526/dbname:INFORMIXSERVER=informixservername;user=username;password=password
Oracle
oracle.jdbc.driver.OracleDriver
jdbc:oracle:thin:@hostname:1521:<SID>
Postgresql
org.postgresql.Driver
jdbc:postgresql://localhost/soft
Apache Derby/Java DB
org.apache.derby.jdbc.ClientDriver
jdbc:derby://localhost:1527/databaseName;create=true
Access 是通過 ODBC 連接的. Excel 也可以. 甚至可以動態構造連接字符串:
這樣可以直接連接到 Access 數據庫文件.
jdbc:odbc:DRIVER={Microsoft Access Driver (*.mdb)};DBQ=c:\mydata.mdb
類似的 Excel 文件也可以用類似方法:
jdbc:odbc:Driver={Microsoft Excel Driver (*.xls)};DBQ=.\mydata.xls
]]>
]]>
]]>
]]>
java.lang.ClassNotFoundException: org.springframework.web.struts.ContextLoaderPlugIn
解決方法:加載 spring.jar 包
報 無法初始化
at org.apache.struts.action.ActionServlet.initModulePlugIns(
解決方法:刪除 asm-2.2.3.jar
springdao 報空指針異常
java.lang.NullPointerException
springdao.EcAccountDAO.save(EcAccountDAO.java:48)
解決方法:沒有加載 spring配置文件就訪問了dao類
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
EcAccountLevelDAO dao = (EcAccountLevelDAO)ctx.getBean("EcAccountLevelDAO");
Servlet action is not available
先檢查web.xml,struts-config.xml等文件有沒寫錯,然后檢查那些struts的包有沒有加全.. 或者 spring + struts 插件載入時出錯
ENCTYPE="multipart/form-data"
提交得方式就把那個文件作為流來傳輸了,普通字符串就傳不過去了!
去掉之后默認都是傳遞字符串,所以只把那個文本框里面得字符串提交過去!
修改表后數據庫表打開不能 報錯
有可能是因為 DAO 文件沒有加載 @Transcational 標記,導致事務(會話?)一直在運行,沒有關閉。
多表連查,有外鍵對象存在的情況下,外鍵對象也需要鏈接查詢,才能引入的并入結果集
EcOpus (opus, accout, catepoies)
from Opus opus, Accout accout, Catepoise catepoise
where ......
IllegalStateException
若已從響應(request,response)中獲得 ServletOutputStream 對象或 PrintWriter 對象,則不能使用 forward方法,否則會拋出該異常。
]]>
]]>
request.getContextPath() /deviantART
獲得容器上下文路徑,一般為網站的相對路徑(項目名)。如果為根目錄,則返回值為 ""。
request.getServletPath() /test/MyJsp.jsp
獲得 Servlet 相對路徑。
request.getRequestURI() /deviantART/test/MyJsp.jsp
獲得請求路徑。
request.getRealPath("") D:\Program Files\apache-tomcat-6.0.16\webapps\deviantART
request.getRealPath("/AAAA/BBBB") D:\Program Files\apache-tomcat-6.0.16\webapps\deviantART\AAAA\BBBB
獲得絕對路徑(不推薦使用)。
########################################################
application.getContextPath() /deviantART
application.getRealPath("") D:\Program Files\apache-tomcat-6.0.16\webapps\deviantART
application.getRealPath("AA/BB") D:\Program Files\apache-tomcat-6.0.16\webapps\deviantART\AA\BB
application.getRealPath(request.getServletPath())
D:\Program Files\apache-tomcat-6.0.16\webapps\deviantART\test\MyJsp.jsp
##########################################################
replaceAll("\\\\","xxxx"); 表示一個"\"
]]>
struts+spring+hibernate 組裝web應用
用spring、Hibernate、Struts組建輕量級架構
]]>
]]>
]]>
]]>
]]>
http://support.microsoft.com/kb/914277/zh-cn
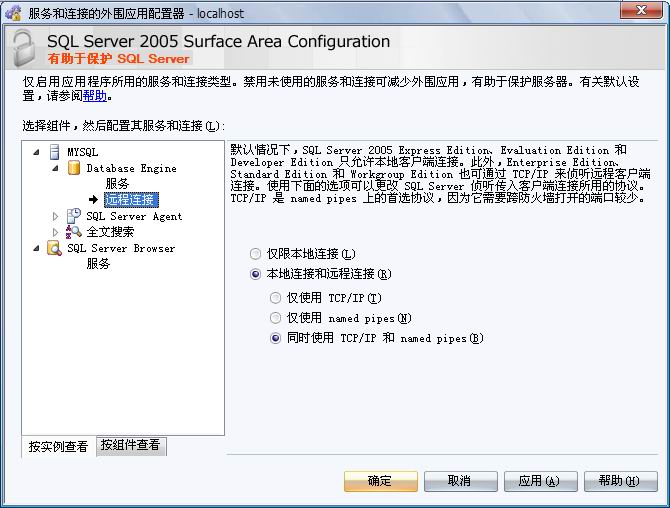
二、通過 TCP 端口直接到 SQL Server 實例 (端口默認值是 1433)
為SQL Server使用非標準的端口 http://www.windbi.com/showtopic-293.aspx
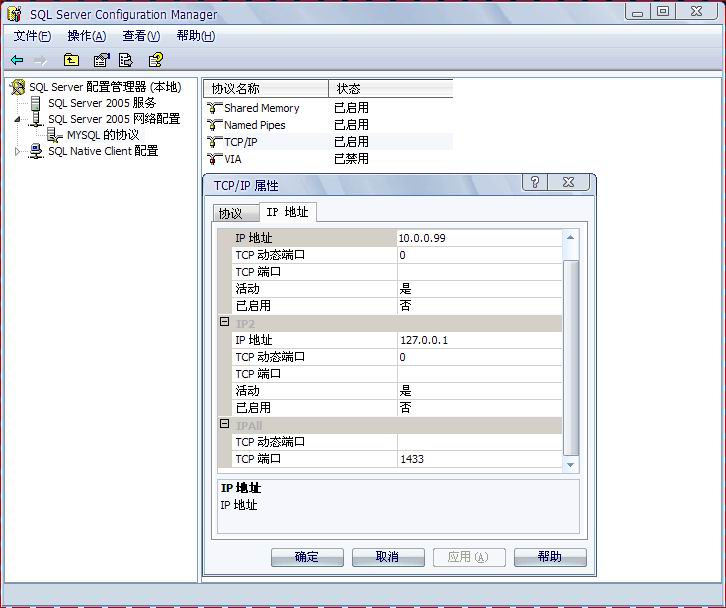
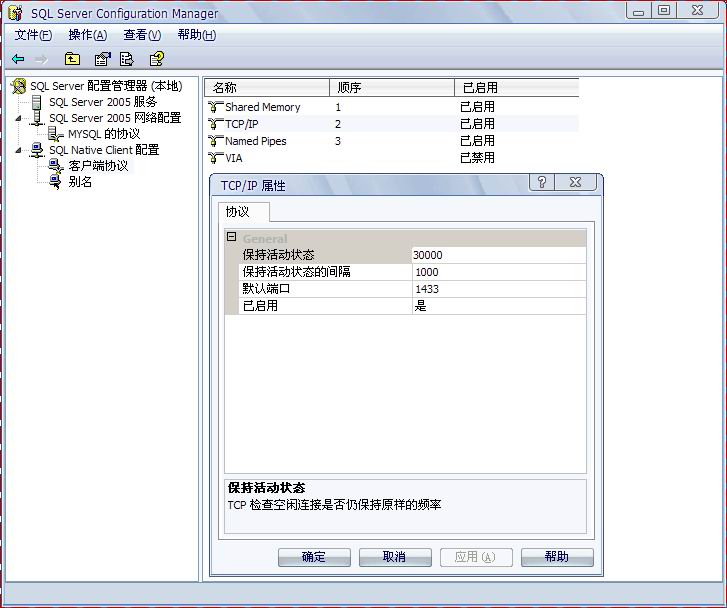
三、程序中使用端口連接數據庫
在連接到 SQL Server 數據庫之前,必須首先在本地計算機或服務器上安裝 SQL Server,并且必須在本地計算機上安裝 JDBC 驅動程序。
Microsoft SQL Server 2005 JDBC Driver 1.2 下載
使用 JDBC 驅動程序 http://msdn.microsoft.com/zh-cn/library/ms378526.aspx
創建連接 URL http://msdn.microsoft.com/zh-cn/library/ms378428.aspx
myeclicse怎么與sql server 2005連接 http://zhidao.baidu.com/question/55043158.html?fr=qrl&test=query
四、SQL 2005 更改sa密碼
http://topic.csdn.net/u/20071130/13/54df9ff6-ad1d-45a3-9d9b-da6a33714227.html
時間匆忙,沒一一驗證過。
]]>