еҺҹеӯҗжҖ§пјҡдҝқиҜҒдәӢеҠЎдёӯзҡ„жүҖжңүж“ҚдҪңе…ЁйғЁжү§иЎҢжҲ–е…ЁйғЁдёҚжү§иЎҢгҖӮдҫӢеҰӮжү§иЎҢиқ{иҙҰдәӢеҠЎпјҢиҰҒд№ҲиҪ¬иМҺжҲҗеҠҹеQҢиҰҒд№ҲеӨұиҙҘгҖӮжҲҗеҠҹпјҢеҲҷйҮ‘йўқд»ҺиҪ¬еҮәеёҗжҲ·иҪ¬е…ҘеҲ°зӣ®зҡ„еёҗжҲшPјҢтq¶дё”дёӨдёӘеёҗжҲ·йҮ‘йўқһ®ҶеҸ‘з”ҹзӣёеә”зҡ„еҸҳеҢ–еQӣеӨұиҙҘпјҢеҲҷдёӨдёӘиМҺжҲпLҡ„йҮ‘йўқйғҪдёҚеҸҳгҖӮдёҚдјҡеҮәзҺ°иқ{еҮәеёҗжҲдhүЈдәҶй’ұеQҢиҖҢзӣ®зҡ„еёҗжҲдhІЎжңү收еҲ°й’ұзҡ„жғ…еҶьcҖ?/span>
дёҖиҮҙжҖ§пјҡдҝқиҜҒж•°жҚ®еә“е§ӢҫlҲдҝқжҢҒж•°жҚ®зҡ„дёҖиҮҙжҖ?#8212;—дәӢеҠЎж“ҚдҪңд№ӢеүҚжҳҜдёҖиҮҙзҡ„еQҢдәӢеҠЎж“ҚдҪңд№ӢеҗҺд№ҹжҳҜдёҖиҮҙзҡ„еQҢдёҚҪҺЎдәӢеҠЎжҲҗеҠҹдёҺеҗҰгҖӮеҰӮдёҠйқўзҡ„дҫӢеӯҗпјҢиҪ¬иМҺд№ӢеүҚе’Ңд№ӢеҗҺж•°жҚ®еә“йғҪдҝқжҢҒж•°жҚ®дёҠзҡ„дёҖиҮҙжҖ§гҖ?/span>
йҡ”зҰ»жҖ§пјҡеӨҡдёӘдәӢеҠЎтq¶еҸ‘жү§иЎҢзҡ„иҜқеQҢз»“жһңеә”иҜҘдёҺеӨҡдёӘдәӢеҠЎдёІиЎҢжү§иЎҢж•ҲжһңжҳҜдёҖж пLҡ„гҖӮжҳҫ然жңҖҪҺҖеҚ•зҡ„йҡ”зҰ»һ®ұжҳҜһ®ҶжүҖжңүдәӢеҠЎйғҪдёІиЎҢжү§иЎҢеQҡе…ҲжқҘе…Ҳжү§иЎҢеQҢдёҖдёӘдәӢеҠЎжү§иЎҢе®ҢдәҶжүҚе…Ғи®ёжү§иЎҢдёӢдёҖдёӘгҖӮдҪҶҳqҷж ·ж•°жҚ®еә“зҡ„ж•ҲзҺҮдҪҺдёӢеQҢеҰӮеQҡдёӨдёӘдёҚеҗҢзҡ„дәӢеҠЎеҸӘжҳҜиҜХdҸ–еҗҢдёҖжүТҺ•°жҚ®пјҢҳqҷж ·е®Ңе…ЁеҸҜд»Ҙтq¶еҸ‘ҳqӣиЎҢгҖӮдШ“дәҶжҺ§еҲ¶еЖҲеҸ‘жү§иЎҢзҡ„ж•Ҳжһңһ®ұжңүдәҶдёҚеҗҢзҡ„йҡ”зҰ»ҫU§еҲ«гҖӮдёӢйқўе°ҶиҜҰз»Ҷд»Ӣз»ҚгҖ?/span>
жҢҒд№…жҖ§пјҡжҢҒд№…жҖ§иЎЁҪCЮZәӢзү©ж“ҚдҪңе®ҢжҲҗд№ӢеҗҺпјҢеҜТҺ•°жҚ®еә“зҡ„еӘ„е“ҚжҳҜжҢҒд№…зҡ„пјҢеҚідӢЙж•°жҚ®еә“еӣ ж•…йҡңиҖҢеҸ—еҲ°з ҙеқҸпјҢж•°жҚ®еә“д№ҹеә”иҜҘиғҪеӨҹжҒўеӨҚгҖӮйҖҡеёёзҡ„е®һзҺ°ж–№ејҸжҳҜйҮҮз”Ёж—Ҙеҝ—гҖ?/span>
дәӢеҠЎйҡ”зҰ»ҫU§еҲ«еQ?/span>transaction isolation levelsеQүпјҡйҡ”зҰ»ҫU§еҲ«һ®ұжҳҜеҜ№еҜ№дәӢеҠЎтq¶еҸ‘жҺ§еҲ¶зҡ„зӯүҫU§гҖ?/span>ANSI/ ISOSQLһ®Ҷе…¶еҲҶдШ“дёІиЎҢеҢ–пјҲSERIALIZABLEеQүгҖҒеҸҜйҮҚеӨҚиҜ»пјҲREPEATABLE READеQүгҖҒиҜ»е·ІжҸҗдәӨпјҲREAD COMMITEDеQүгҖҒиҜ»жңӘжҸҗдәӨпјҲREAD UNCOMMITEDеQүеӣӣдёӘзӯүҫU§гҖӮдШ“дәҶе®һзҺ°йҡ”јӣИқс”еҲ«йҖҡеёёж•°жҚ®еә“йҮҮз”Ёй”ҒеQ?/span>LockеQүгҖӮдёҖиҲ¬еңЁҫ~–зЁӢзҡ„ж—¶еҖҷеҸӘйңҖиҰҒи®ҫҫ|®йҡ”јӣИқӯүҫU§пјҢиҮідәҺе…·дҪ“йҮҮз”Ёд»Җд№Ҳй”ҒеҲҷз”ұж•°жҚ®еә“жқҘи®„ЎҪ®гҖӮйҰ–е…Ҳд»ӢҫlҚеӣӣҝUҚзӯүҫU§пјҢ然еҗҺдёҫдҫӢи§ЈйҮҠеҗҺйқўдёүдёӘҪ{үзс”еQҲеҸҜйҮҚеӨҚиҜ…RҖҒиҜ»е·ІжҸҗдәӨгҖҒиҜ»жңӘжҸҗдәӨпјүдёӯдјҡеҮәзҺ°зҡ„еЖҲеҸ‘й—®йўҳгҖ?/span>
дёІиЎҢеҢ–пјҲSERIALIZABLEеQүпјҡжүҖжңүдәӢеҠЎйғҪдёҖдёӘжҺҘдёҖдёӘең°дёІиЎҢжү§иЎҢеQҢиҝҷж ·еҸҜд»ҘйҒҝе…ҚеүтиҜ»пјҲphantom readsеQүгҖӮеҜ№дәҺеҹәдәҺй”ҒжқҘе®һзҺ°еЖҲеҸ‘жҺ§еҲ¶зҡ„ж•°жҚ®еә“жқҘиҜЯ_јҢдёІиЎҢеҢ–иҰҒжұӮеңЁжү§иЎҢиҢғеӣҙжҹҘиҜўеQҲеҰӮйҖүеҸ–тqҙйҫ„ең?/span>10еҲ?/span>30д№Ӣй—ҙзҡ„з”ЁжҲшPјүзҡ„ж—¶еҖҷпјҢйңҖиҰҒиҺ·еҸ–иҢғеӣҙй”ҒеQ?/span>range lockеQүгҖӮеҰӮжһңдёҚжҳҜеҹәдәҺй”Ғе®һзҺ°тq¶еҸ‘жҺ§еҲ¶зҡ„ж•°жҚ®еә“еQҢеҲҷӢӮҖжҹҘеҲ°жңүиҝқеҸҚдёІиЎҢж“ҚдҪңзҡ„дәӢеҠЎж—УһјҢйңҖиҰҒж»ҡеӣһиҜҘдәӢеҠЎгҖ?/span>
еҸҜйҮҚеӨҚиҜ»еQ?/span>REPEATABLE READеQүпјҡжүҖжңүиў«SelectиҺ·еҸ–зҡ„ж•°жҚ®йғҪдёҚиғҪиў«дҝ®ж”№пјҢҳqҷж ·һ®ұеҸҜд»ҘйҒҝе…ҚдёҖдёӘдәӢеҠЎеүҚеҗҺиҜ»еҸ–ж•°жҚ®дёҚдёҖиҮҙзҡ„жғ…еҶөгҖӮдҪҶжҳҜеҚҙжІЎжңүеҠһжі•жҺ§еҲ¶тq»иҜ»еQҢеӣ дёшҷҝҷдёӘж—¶еҖҷе…¶д»–дәӢеҠЎдёҚиғҪжӣҙж”ТҺүҖйҖүзҡ„ж•°жҚ®еQҢдҪҶжҳҜеҸҜд»ҘеўһеҠ ж•°жҚ®пјҢеӣ дШ“еүҚдёҖдёӘдәӢеҠЎжІЎжңүиҢғеӣҙй”ҒгҖ?/span>
иҜХd·ІжҸҗдәӨеQ?/span>READ COMMITEDеQүпјҡиў«иҜ»еҸ–зҡ„ж•°жҚ®еҸҜд»Ҙиў«е…¶д»–дәӢеҠЎдҝ®ж”ҸVҖӮиҝҷж ·е°ұеҸҜиғҪеҜЖDҮҙдёҚеҸҜйҮҚеӨҚиҜ…RҖӮд№ҹһ®ұжҳҜиҜЯ_јҢдәӢеҠЎзҡ„иҜ»еҸ–ж•°жҚ®зҡ„ж—¶еҖҷиҺ·еҸ–иҜ»й”ҒпјҢдҪҶжҳҜиҜХd®Ңд№ӢеҗҺз«ӢеҚійҮҠж”ҫеQҲдёҚйңҖиҰҒзӯүеҲоCәӢеҠЎз»“жқҹпјүеQҢиҖҢеҶҷй”ҒеҲҷжҳҜдәӢеҠЎжҸҗдәӨд№ӢеҗҺжүҚйҮҠж”ҫгҖӮйҮҠж”ҫиҜ»й”Ғд№ӢеҗҺпјҢһ®ұеҸҜиғҪиў«е…¶д»–дәӢзү©дҝ®ж”№ж•°жҚ®гҖӮиҜҘҪ{үзс”д№ҹжҳҜSQL Serverй»ҳи®Өзҡ„йҡ”јӣИқӯүҫU§гҖ?/span>
иҜАLңӘжҸҗдәӨеQ?/span>READ UNCOMMITEDеQүпјҡҳqҷжҳҜжңҖдҪҺзҡ„йҡ”зҰ»Ҫ{үзс”еQҢе…Ғи®ёе…¶д»–дәӢеҠЎзңӢеҲ°жІЎжңүжҸҗдәӨзҡ„ж•°жҚ®гҖӮиҝҷҝUҚзӯүҫU§дјҡеҜЖDҮҙи„ҸиҜ»еQ?/span>Dirty ReadеQүгҖ?/span>
дҫӢеӯҗеQҡдёӢйқўиҖғеҜҹеҗҺйқўдёүз§Қйҡ”зҰ»Ҫ{үзс”еҜ№еә”зҡ„еЖҲеҸ‘й—®йўҳгҖӮеҒҮи®ҫжңүдёӨдёӘдәӢеҠЎгҖӮдәӢеҠ?/span>1жү§иЎҢжҹҘиҜў1еQҢ然еҗҺдәӢеҠ?/span>2жү§иЎҢжҹҘиҜў2еQҢ然еҗҺжҸҗдәӨпјҢжҺҘдёӢжқҘдәӢеҠ?/span>1дёӯзҡ„жҹҘиҜў1еҶҚжү§иЎҢдёҖӢЖЎгҖӮжҹҘиҜўеҹәдәҺд»ҘдёӢиЎЁҳqӣиЎҢеQ?/span>
еҸҜйҮҚеӨҚиҜ»(тq»иҜ»еQҢphantom reads)
дёҖдёӘдәӢеҠЎдёӯе…ҲеҗҺеҗ„жү§иЎҢдёҖӢЖЎеҗҢдёҖдёӘжҹҘиҜўпјҢдҪҶжҳҜҳq”еӣһзҡ„з»“жһңйӣҶеҚҙдёҚдёҖж —чҖӮеҸ‘з”ҹиҝҷҝUҚжғ…еҶү|ҳҜеӣ дШ“еңЁжү§иЎҢSelectж“ҚдҪңзҡ„ж—¶еҖҷжІЎжңүиҺ·еҸ–иҢғеӣҙй”ҒеQҲRange LockеQүпјҢеҜЖDҮҙе…¶д»–дәӢеҠЎд»Қ然еҸҜд»ҘжҸ’е…Ҙж–°зҡ„ж•°жҚ®гҖ?/p>
Transaction 1 | Transaction 2 |
/* Query 1 */ SELECT * FROM users WHERE age BETWEEN 10 AND 30; |
|
| /* Query 2 */ INSERT INTO users VALUES ( 3, 'Bob', 27 ); COMMIT; |
/* Query 1 */ SELECT * FROM users WHERE age BETWEEN 10 AND 30; |
|
жіЁж„Ҹtransaction 1еҜ№еҗҢдёҖдёӘжҹҘиҜўиҜӯеҸҘпјҲQuery 1еQүжү§иЎҢдәҶдёӨж¬ЎгҖ?еҰӮжһңйҮҮз”Ёжӣҙй«ҳҫU§еҲ«зҡ„йҡ”јӣИқӯүҫU§пјҲеҚідёІиЎҢеҢ–еQүзҡ„иҜқпјҢйӮЈд№ҲеүҚеҗҺдёӨж¬ЎжҹҘиҜўеә”иҜҘҳq”еӣһеҗҢж ·зҡ„з»“жһңйӣҶгҖӮдҪҶжҳҜеңЁеҸҜйҮҚеӨҚиҜ»йҡ”зҰ»Ҫ{үзс”дёӯеҚҙеүҚеҗҺдёӨж¬Ўҫl“жһңйӣҶдёҚдёҖж —чҖӮдҪҶжҳҜдШ“д»Җд№ҲеҸ«еҒҡеҸҜйҮҚеӨҚиҜИқӯүҫU§е‘ўеQҹйӮЈжҳҜеӣ дёшҷҜҘҪ{үзс”и§ЈеҶідәҶдёӢйқўзҡ„дёҚеҸҜйҮҚеӨҚиҜ»й—®йўҳгҖ?/p>
иҜХd·ІжҸҗдәӨеQҲдёҚеҸҜйҮҚеӨҚиҜ»еQҢNon-repeatable readsеQ?/h3>
еңЁйҮҮз”Ёй”ҒжқҘе®һзҺ°еЖҲеҸ‘жҺ§еҲ¶зҡ„ж•°жҚ®еә“зі»ҫlҹдёӯеQҢдёҚеҸҜйҮҚеӨҚиҜ»жҳҜеӣ дёәеңЁжү§иЎҢSelectж“ҚдҪңзҡ„ж—¶еҖҷжІЎжңүеҠ иҜ»й”ҒеQҲread lockеQүгҖ?/p>
Transaction 1 | Transaction 2 |
/* Query 1 */ SELECT * FROM users WHERE id = 1; |
|
| /* Query 2 */ UPDATE users SET age = 21 WHERE id = 1; COMMIT; |
/* Query 1 */ SELECT * FROM users WHERE id = 1; |
|
еңЁиҝҷдёӘдҫӢеӯҗеҪ“дёӯпјҢTransaction 2жҸҗдәӨжҲҗеҠҹ,жүҖд»ҘTransaction 1ҪW¬дәҢӢЖЎе°ҶиҺ·еҸ–дёҖдёӘдёҚеҗҢзҡ„ageеҖ?еңЁSERIALIZABLEе’ҢREPEATABLE READйҡ”зҰ»ҫU§еҲ«дё?ж•°жҚ®еә“еә”иҜҘиҝ”еӣһеҗҢдёҖдёӘеҖ№{ҖӮиҖҢеңЁREAD COMMITTEDе’ҢREAD UNCOMMITTEDҫU§еҲ«дёӯж•°жҚ®еә“ҳq”еӣһжӣҙж–°зҡ„еҖ№{ҖӮиҝҷж ·е°ұеҮәзҺ°дәҶдёҚеҸҜйҮҚеӨҚиҜ»гҖ?/p>
иҜАLңӘжҸҗдәӨ (и„ҸиҜ»еQҢdirty reads)
еҰӮжһңдёҖдёӘдәӢеҠ?иҜХdҸ–дәҶеҸҰдёҖдёӘдәӢеҠ?дҝ®ж”№зҡ„еҖы|јҢдҪҶжҳҜжңҖеҗҺдәӢеҠ?ж»ҡеӣһдәҶпјҢйӮЈд№ҲдәӢеҠЎ2һ®ЮpҜ»еҸ–дәҶдёҖдёӘи„Ҹж•°жҚ®еQҢиҝҷд№ҹе°ұжҳҜжүҖи°“зҡ„и„ҸиҜ»гҖӮеҸ‘з”ҹиҝҷҝUҚжғ…еҶөе°ұжҳҜе…Ғи®жҖәӢеҠЎиҜ»еҸ–жңӘжҸҗдәӨзҡ„жӣҙж–°гҖ?/p>
Transaction 1 | Transaction 2 |
/* Query 1 */ SELECT * FROM users WHERE id = 1; |
|
| /* Query 2 */ UPDATE users SET age = 21 WHERE id = 1; |
/* Query 1 */ SELECT * FROM users WHERE id = 1; |
|
RollBack |
ҫlйgёҠҳqҺНјҢеҸҜд»ҘҪ{үеҲ°дёӢйқўзҡ„иЎЁж ы|јҡ
йҡ”зҰ»Ҫ{үзс” | и„ҸиҜ» | дёҚеҸҜйҮҚеӨҚиҜ?/span> | тq»иҜ» |
иҜАLңӘжҸҗдәӨ | YES | YES | YES |
иҜХd·ІжҸҗдәӨ | NO | YES | YES |
еҸҜйҮҚеӨҚиҜ» | NO | NO | YES |
дёІиЎҢеҢ?/span> | NO | NO | NO |
solidDB® can store binary and character data up to 2147483647 (2G - 1) bytes long. When such data exceeds a certain length, the data is called a BLOB (Binary Large OBject) or CLOB (Character Large OBject), depending upon the data type that stores the information. CLOBS contain only "plain text" and can be stored in any of the following data types:
CHAR, WCHAR
VARCHAR, WVARCHAR
LONG VARCHAR (mapped to standard type CLOB),
LONG WVARCHAR (mapped to standard type NCLOB)
BLOBs can store any type of data that can be represented as a sequence of bytes, such as a digitized picture, video, audio, a formatted text document. (They can also store plain text, but you'll have more flexibility if you store plain text in CLOBs). BLOBs are stored in any of the following data types:
BINARY
VARBINARY
LONG VARBINARY (mapped to standard type BLOB)
Since character data is a sequence of bytes, character data can be stored in BINARY fields, as well as in CHAR fields. CLOBs can be considered a subset of BLOBs.
For convenience, we will use the term BLOBs to refer to both CLOBs and BLOBs.
For most non-BLOB data types, such as integer, float, date, etc., there is a rich set of valid operations that you can do on that data type. For example, you can add, subtract, multiply, divide, and do other operations with FLOAT values. Because a BLOB is a sequence of bytes and the database server does not know the "meaning" of that sequence of bytes (i.e. it doesn't know whether the bytes represent a movie, a song, or the design of the space shuttle), the operations that you can do on BLOBs are very limited.
solidDB does allow you to perform some string operations on CLOBs. For example, you can search for a particular substring (e.g. a person's name) inside a CLOB by using the LOCATE() function. Because such operations require a lot of the server's resources (memory and/or CPU time), solidDB allows you to limit the number of bytes of the CLOB that are processed. For example, you might specify that only the first 1 megabyte of each CLOB be searched when doing a string search. For more information, see the description of the MaxBlobExpressionSize configuration parameter in solidDB Administration Guide.
Although it is theoretically possible to store the entire blob "inside" a typical table, if the blob is large, then the server usually performs better if most or all of the blob is not stored in the table. In solidDB, if a blob is no more than N bytes long, then the blob is stored in the table. If the blob is longer than N bytes, then the first N bytes are stored in the table, and the rest of the blob is stored outside the table as disk blocks in the physical database file. The exact value of "N" depends in part upon the structure of the table, the disk page size that you specified when you created the database, etc., but is always at least 256. (Data 256 bytes or shorter is always stored in the table.)
If a data row size is larger than one third of the disk block size of the database file, you must store it partly as a BLOB.
The SYS_BLOBS system table is used as a directory for all BLOB data in the physical database file. One SYS_BLOB entry can accommodate 50 BLOB parts. If the BLOB size exceeds 50 parts, several SYS_BLOB entries per BLOB are needed.
The query below returns an estimate on the total size of BLOBs in the database.
select sum(totalsize) from sys_blobs
The estimate is not accurate, because the info is only maintained at checkpoints. After two empty checkpoints, this query should return an accurate response.
Sleepycat Software makes Berkeley DB, the most widely used application-specific data management software in the world with more than 200 million deployments. Customers such as Amazon, AOL, British Telecom, Cisco Systems, EMC, Ericsson, Google, Hitachi, HP, Motorola, RSA Security, Sun Microsystems, TIBCO and Veritas also rely on Berkeley DB for fast, scalable, reliable and cost-effective data management for their mission-critical applications.
иҜ?SleepycatиҪҜдҡgе…¬еҸёеҮәе“Ғзҡ„Berkeley DBжҳҜдёҖҝUҚеңЁзү№е®ҡзҡ„ж•°жҚ®з®ЎзҗҶеә”з”ЁзЁӢеәҸдёӯтqҝжіӣдҪҝз”Ёзҡ„ж•°жҚ®еә“ҫpИқ»ҹ,еңЁдё–з•ҢиҢғеӣҙеҶ…жңүи¶…ҳqҮдёӨдәҝзҡ„з”ЁжҲ·ж”ҜжҢҒ.и®ёеӨҡдё–з•ҢзҹҘеҗҚзҡ„еҺӮе•?еғҸAmazon, AOL, British Telecom, Cisco Systems, EMC, Ericsson, Google, Hitachi, HP, Motorola, RSA Security, Sun Microsystems, TIBCO д»ҘеҸҠ VeritasйғҪдҫқиө–дәҺBDBдёЮZ»–们зҡ„и®ёеӨҡе…ій”®жҖ§еә”з”ЁжҸҗдҫӣеҝ«йҖҹзҡ„,ејТҺҖ§зҡ„,еҸҜйқ зҡ?тq¶дё”й«ҳжҖ§дӯhжҜ”зҡ„ж•°жҚ®ҪҺЎзҗҶ.
2.д»ҘдёӢжҳҜchinaunix.netдёҠдёҖдҪҚй«ҳжүӢз»ҷеҮәзҡ„и§ЈйҮҠеQҢеңЁҳqҷйҮҢеј•з”ЁдёҖдёӢгҖ?/span>
mysqlһ®ұжҳҜз”ЁBDBе®һзҺ°зҡ?mysqlзҡ„еҗҺеҸ? гҖӮmysqlеҝ«пјҢBDBжҜ”mysqlҳqҳиҰҒеҝ«NеҖҚгҖ?/span>
BDBтq¶еҸ‘й«ҳдәҺRDBMSгҖ?nbsp;
е®ҡwҮҸж”ҜжҢҒеҸҜиҫҫ256TBгҖ?/span>
еҹЮZәҺHASHж”ҜжҢҒselectж•°жҚ®жҜ”RDBMSеҝ«гҖ?/span>
3.BDBж•°жҚ®еә“дёҺе…¶е®ғзҡ„еҮ ҝUҚж•°жҚ®еә“зҡ„жҜ”иҫғгҖ?/span>
BDBж•°жҚ®еә“дёҚеҗҢдёҺе…¶д»–еҮ з§Қж•°жҚ®еә?-е…ізі»еһӢпјҲRelational databasesеQүпјҢйқўеҗ‘еҜ№иұЎеһӢпјҲObject-oriented databasesеQүпјҢҫ|‘з»ңж•°жҚ®еә“пјҲNetwork databasesеQүпјҢе®ғжҳҜдёҖҝUҚеөҢе…ҘејҸеQҲembeded databases)ж•°жҚ®еә“гҖ?/span>
дёӢйқўе…Ҳз®ҖиҰҒиҜҙиҜҙBDBдёҺе…¶е®ғеҮ ҝUҚж•°жҚ®еә“зҡ„еҢәеҲ«пјҡ
еQ?еQүе®ғ们еҮ д№ҺйғҪж— дёҖдҫӢеӨ–зҡ„йҮҮз”ЁдәҶҫl“жһ„еҢ–жҹҘиҜўиҜӯӯaҖеQҲSQLеQүпјҢиҖҢBDBжІЎжңүгҖ?/span>
еQ?еQүе®ғ们еҮ д№ҺйғҪж— дёҖдҫӢеӨ–зҡ„йҮҮз”ЁдәҶе®ўжҲ·/жңҚеҠЎеҷЁжЁЎеһӢпјҢиҖҢBDBйҮҮз”Ёзҡ„жҳҜеөҢе…ҘејҸжЁЎеһӢгҖ?/span>
дёӢйқўжҳҜеңЁҫ|‘дёҠжү„Ўҡ„дёҖдәӣжңүе…іBDBзҡ„иө„ж–?и§ЈйҮҠдәҶBDBд№ӢжүҖд»Ҙдјҡе’ҢеҪ“еүҚжөҒиЎҢзҡ„еӨ§еӨҡж•°ж•°жҚ®еә“дёҚеҗҢзҡ„дёҖдәӣеҺҹеӣ?жүҖеј•иө„ж–ҷжңӘжіЁжҳҺеҮәеӨ„,еҗҺйқўзҡ„зҝ»иҜ‘жҳҜжҲ‘иҮӘе·ұеҠ зҡ„пјҡ
еQ?еQүBerkeley DB is an open source embedded database library that provides scalable, high-performance, transaction-protected data management services to applications. Berkeley DB provides a simple function-call API for data access and management.
иҜ‘пјҡBDBжҳҜдёҖдёӘејҖж”ҫжәҗд»Јз Ғзҡ„еөҢе…ҘејҸж•°жҚ®еә“зҡ„еҮҪж•°еә“пјҢе®ғдШ“еә”з”ЁҪEӢеәҸжҸҗдҫӣејТҺҖ§зҡ„еQҢй«ҳжҖ§иғҪзҡ„пјҢtransaction-protectedзҡ„ж•°жҚ®еә“ҪҺЎзҗҶжңҚеҠЎеQҢBDBдёәж•°жҚ®зҡ„и®үK—®е’Ңз®ЎзҗҶжҸҗдҫӣдәҶҪҺҖеҚ•зҡ„еә”з”ЁҪEӢеәҸжҺҘеҸЈAPIгҖ?/span>
еQ?еQүBerkeley DB is embedded because it links directly into the application. It runs in the same address space as the application. As a result, no inter-process communication, either over the network or between processes on the same machine, is required for database operations. Berkeley DB provides a simple function-call API for a number of programming languages, including C, C++, Java, Perl, Tcl, Python, and PHP. All database operations happen inside the library. Multiple processes, or multiple threads in a single process, can all use the database at the same time as each uses the Berkeley DB library. Low-level services like locking, transaction logging, shared buffer management, memory management, and so on are all handled transparently by the library.
иҜ‘пјҡBDBд№ӢжүҖд»ҘжҳҜеөҢе…ҘејҸж•°жҚ®еә“жҳҜеӣ дёәе®ғжҳҜзӣҙжҺҘиҝһеҲ°еә”з”ЁзЁӢеәҸдёӯзҡ„гҖӮе®ғе’Ңеә”з”ЁзЁӢеәҸеңЁеҗҢдёҖеҶ…еӯҳҪIәй—ҙҳqҗиЎҢгҖӮе…¶ҫl“жһңжҳҜпјҢдёҚз®Ўеә”з”ЁҪEӢеәҸжҳҜиҝҗиЎҢеңЁеҗҢдёҖеҸ°жңәеҷЁдёҠҳqҳжҳҜҳqҗиЎҢеңЁзҪ‘ҫlңдёҠеQҢеңЁҳqӣиЎҢж•°жҚ®еә“ж“ҚдҪңж—¶еQҢе®ғйғҪж— йңҖҳqӣиЎҢҳqӣзЁӢй—ҙйҖҡдҝЎгҖӮBDBдёшҷ®ёеӨҡзј–ҪEӢиҜӯӯaҖжҸҗдҫӣдәҶеҮҪж•°жҺҘеҸЈпјҢҳqҷдәӣиҜӯиЁҖеҢ…жӢ¬C, C++, Java, Perl, Tcl, Python, е’?PHPгҖӮжүҖжңүзҡ„ж•°жҚ®еә“ж“ҚдҪңйғҪеҸ‘з”ҹеңЁеҮҪж•°еә“еҶ…йғЁгҖӮеӨҡдёӘиҝӣҪEӢпјҢжҲ–иҖ…жҳҜдёҖдёӘиҝӣҪEӢдёӯзҡ„еӨҡдёӘзәҝҪEӢпјҢйғҪеҸҜд»ҘеҗҢж—¶дӢЙз”ЁBDBеQҢеӣ дёәе®ғ们е®һйҷ…жҳҜеңЁи°ғз”ЁBDBеҮҪж•°еә“гҖӮдёҖдәӣеғҸlocking, transaction logging, shared buffer management, memory managementҪ{үзӯүд№Ӣзұ»зҡ„дҪҺҫU§жңҚеҠЎйғҪеҸҜд»Ҙз”ұеҮҪж•°еә“йҖҸжҳҺең°еӨ„зҗҶгҖ?/span>
еQ?еQүThe library is extremely portable. It runs under almost all UNIX and Linux variants, Windows, and a number of embedded real-time operating systems. It runs on both 32-bit and 64-bit systems. It has been deployed on high-end Internet servers, desktop machines, and on palmtop computers, set-top boxes, in network switches, and elsewhere. Once Berkeley DB is linked into the application, the end user generally does not know that there's a database present at all.
иҜ‘пјҡBDBеҮҪж•°еә“жҳҜй«ҳеәҰеҸҜ移жӨҚзҡ„гҖӮе®ғеҸҜд»ҘҳqҗиЎҢеңЁеҮ д№ҺжүҖжңүзҡ„UNIXе’ҢLINUXҫpИқ»ҹд№ӢдёҠеQҢд№ҹж”ҜжҢҒWINDOWSе’ҢеӨҡҝUҚеөҢе…ҘејҸе®һж—¶ж“ҚдҪңҫpИқ»ҹгҖӮе®ғж—ўеҸҜд»ҘиҝҗиЎҢеңЁ32дҪҚзі»ҫlҹдёҠеQҢд№ҹеҸҜд»ҘҳqҗиЎҢең?4дҪҚзі»ҫlҹдёҠгҖӮе®ғӢz»и·ғеңЁй«ҳз«ҜжңҚеҠЎеҷЁеQҢжЎҢйқўзі»ҫlҹпјҢжҺҢдёҠз”өи„‘еQҢset-top boxesеQҢзҪ‘ҫlңдәӨжҚўжңәд»ҘеҸҠе…¶е®ғзҡ„дёҖдәӣйўҶеҹҹгҖӮдёҖж—ҰBDBиў«иҝһжҺҘеҲ°еә”з”ЁеҪ“дёӯд»ҘеҗҺеQҢз»Ҳз«Ҝз”ЁжҲ·дёҖиҲ¬жҳҜдёҚзҹҘйҒ“еҗҺз«Ҝж•°жҚ®еә“зҡ„еӯҳеңЁзҡ„гҖ?/span>
еQ?еQүBerkeley DB is scalable in a number of respects. The database library itself is quite compact (under 300 kilobytes of text space on common architectures), but it can manage databases up to 256 terabytes in size. It also supports high concurrency, with thousands of users operating on the same database at the same time. Berkeley DB is small enough to run in tightly constrained embedded systems, but can take advantage of gigabytes of memory and terabytes of disk on high-end server machines.
иҜ‘пјҡBDBеңЁи®ёеӨҡж–№йқўйғҪжҳҜеј№жҖ§зҡ„гҖӮеҮҪж•°еә“жң¬инnйқһеёёзҙ§еҮ‘еQҲеңЁеёёи§Ғзҡ„жңәеҷЁдҪ“ҫpЦMёҠеӨ§зәҰеҸӘеҚ з”ЁдёҚеҲ?00Kзҡ„textҪIәй—ҙеQҢдҪҶжҳҜе®ғеҸҜд»Ҙж“ҚдҪңеӨҡиҫҫ256TBзҡ„ж•°жҚ®гҖӮе®ғд№ҹж”ҜжҢҒй«ҳејәеәҰзҡ„еЖҲеҸ‘ж“ҚдҪңпјҢеҸҜд»ҘеҗҢж—¶е…Ғи®ёж•оC»ҘеҚғи®Ўзҡ„з”ЁжҲ·еңЁеҗҢдёҖдёӘж•°жҚ®еә“ҳqӣиЎҢж“ҚдҪңгҖӮеңЁй«ҳз«ҜжңҚеҠЎеҷЁйўҶеҹҹпјҢBDBжҳҜиғцеӨҹе°Ҹзҡ„пјҢе®ғеҸҜд»ҘеңЁй«ҳеәҰеҸ—йҷҗзҡ„еөҢе…ҘејҸҫpИқ»ҹдёҠиҝҗиЎҢпјҢдҪҶеҚҙеҸҜд»ҘеҲ©з”Ёй«ҳиҫҫGBйҮҸзс”зҡ„еҶ…еӯҳз©әй—ҙе’Ңй«ҳиҫҫTBйҮҸзс”зҡ„зЈҒзӣҳз©әй—ҙгҖ?/span>
еQ?еQүBerkeley DB generally outperforms relational and object-oriented database systems in embedded applications for a couple of reasons. First, because the library runs in the same address space, no inter-process communication is required for database operations. The cost of communicating between processes on a single machine, or among machines on a network, is much higher than the cost of making a function call. Second, because Berkeley DB uses a simple function-call interface for all operations, there is no query language to parse, and no execution plan to produce.
иҜ‘пјҡBDBеңЁеөҢе…ҘејҸеә”з”Ёж–ҡwқўзҡ„жҖ§иғҪжҜ”е…іҫpХdһӢж•°жҚ®еә“е’Ңйқўеҗ‘еҜ№иұЎзҡ„ж•°жҚ®еә“дјҳи¶Ҡзҡ„еҺҹеӣ жҳҜеӨҡж–№йқўзҡ„гҖӮйҰ–е…ҲпјҢеӣ дШ“еҮҪж•°еә“е’Ңеә”з”ЁжҳҜиҝҗиЎҢеңЁеҗҢдёҖең°еқҖҪIәй—ҙдёӯзҡ„еQҢзңҒжҺүдәҶж•°жҚ®еә“ж“ҚдҪңж—¶зҡ„иҝӣҪEӢй—ҙйҖҡдҝЎгҖӮиҖҢдј—жүҖе‘ЁзҹҘеQҢдёҚҪҺЎжҳҜеңЁеҚ•жңЮZёҠҳqҳжҳҜеңЁеҲҶеёғејҸҫpИқ»ҹдёҠпјҢҳqӣзЁӢй—ҙйҖҡдҝЎжүҖиҠЮqҡ„ж—үҷ—ҙҳqңеӨҡдәҺеҮҪж•°и°ғз”ЁжүҖиҰҒзҡ„ж—үҷ—ҙгҖӮе…¶ӢЖЎпјҢеӣ дШ“BDBеҜТҺүҖжңүзҡ„ж“ҚдҪңжҸҗдҫӣдәҶз®ҖӢzҒзҡ„еҮҪж•°и°ғз”ЁжҺҘеҸЈеQҢж— йңҖеҜТҺҹҘиҜўиҜӯӯaҖҳqӣиЎҢи§ЈжһҗеQҢд№ҹдёҚйңҖиҰҒйў„жү§иЎҢгҖ?/span>
еQ?еQүIn contrast to most other database systems, Berkeley DB provides relatively simple data access services.Berkeley DB supports only a few logical operations on records. They are:
Insert a record in a table.
Delete a record from a table.
Find a record in a table by looking up its key.
Update a record that has already been found.
иҜ‘пјҡдёҺе…¶д»–еӨ§еӨҡж•°ж•°жҚ®еә“зі»ҫlҹзӣёжҜ”пјҢBDBжҸҗдҫӣдәҶзӣёеҜ№з®ҖеҚ•зҡ„ж•°жҚ®и®үK—®жңҚеҠЎгҖӮBDBеҸӘж”ҜжҢҒеҜ№и®°еҪ•жүҖеҒҡзҡ„еҮ з§ҚйҖ»иҫ‘ж“ҚдҪңгҖӮе®ғ们жҳҜеQ?/span>
еңЁиЎЁдёӯжҸ’е…ҘдёҖжқЎи®°еҪ•гҖ?/span>
д»ҺиЎЁдёӯеҲ йҷӨдёҖжқЎи®°еҪ•гҖ?/span>
йҖҡиҝҮжҹҘиҜўй”®пјҲkeyеQүд»ҺиЎЁдёӯжҹҘжүҫдёҖжқЎи®°еҪ•гҖ?/span>
жӣҙж–°иЎЁдёӯе·Іжңүзҡ„дёҖжқЎи®°еҪ•гҖ?/span>
еQ?еQүBerkeley DB is not a standalone database server. It is a library, and runs in the address space of the application that uses it.It is possible to build a server application that uses Berkeley DB for data management. For example, many commercial and open source Lightweight Directory Access Protocol (LDAP) servers use Berkeley DB for record storage. LDAP clients connect to these servers over the network. Individual servers make calls through the Berkeley DB API to find records and return them to clients. On its own, however, Berkeley DB is not a server.
иҜ‘пјҡBDBдёҚжҳҜдёҖдёӘзӢ¬з«Ӣзҡ„ж•°жҚ®еә“жңҚеҠЎеҷЁгҖӮе®ғжҳҜдёҖдёӘеҮҪж•°еә“еQҢе’Ңи°ғз”Ёе®ғзҡ„еә”з”ЁҪEӢеәҸжҳҜиҝҗиЎҢеңЁеҗҢдёҖең°еқҖҪIәй—ҙдёӯзҡ„гҖӮеҸҜд»ҘжҠҠBDBдҪңдШ“ж•°жҚ®еә“з®ЎзҗҶзі»ҫlҹжқҘжһ„еҫҸжңҚеҠЎеҷЁзЁӢеәҸгҖӮжҜ”еҰӮпјҢжңүи®ёеӨҡе•Ҷдёҡзҡ„е’ҢејҖжәҗзҡ„иҪ»йҮҸҫU§зӣ®еҪ•и®ҝй—®еҚҸи®®пјҲLDAPеQүжңҚеҠЎеҷЁйғҪдӢЙз”ЁBDBеӯҳеӮЁи®°еҪ•гҖӮLDAPе®ўжҲ·з«ҜйҖҡиҝҮҫ|‘з»ңҳqһжҺҘеҲ°жңҚеҠЎеҷЁгҖӮжңҚеҠЎеҷЁи°ғз”ЁBDBзҡ„APIжқҘжҹҘжүҫи®°еҪ•еЖҲҳq”еӣһҫlҷе®ўжҲ—чҖӮиҖҢеңЁе®ғжң¬нw«иҖҢиЁҖеQҢBDBеҚҙдёҚжҳҜж•°жҚ®еә“зҡ„жңҚеҠЎеҷЁз«ҜгҖ?/span>
жүҖд»ҘпјҢBDBжҳҜдёҖҝUҚе®Ңе…ЁдёҚеҗҢдәҺе…¶е®ғж•°жҚ®еә“з®ЎзҗҶзі»ҫlҹзҡ„ж•°жҚ®еә“пјҢиҖҢдё”е®ғд№ҹдёҚжҳҜдёҖдёӘж•°жҚ®еә“жңҚеҠЎеҷЁз«ҜгҖ?/span>
4.BDBзҡ„дјҳзӮ№е’Ңҫ~әзӮ№гҖ?/span>
Berkeley DB is an ideal database system for applications that need fast, scalable, and reliable embedded database management. For applications that need different services, however, it can be a poor choice.
Berkeley DB was conceived and built to provide fast, reliable, transaction-protected record storage. The library itself was never intended to provide interactive query support, graphical reporting tools, or similar services that some other database systems provide.We have tried always to err on the side of minimalism and simplicity. By keeping the library small and simple, we create fewer opportunities for bugs to creep in, and we guarantee that the database system stays fast, because there is very little code to execute. If your application needs that set of features, then Berkeley DB is almost certainly the best choice for you.
иҜ‘пјҡеҪ“йқўеҜ№зҡ„жҳҜеҜ№жҖ§иғҪеQҢ规模е’ҢеҸҜйқ жҖ§иҰҒжұӮйғҪжҜ”иҫғй«ҳзҡ„еөҢе…ҘејҸеә”з”Ёзҡ„ж—¶еҖҷпјҢBDBжҳҜзҗҶжғізҡ„ж•°жҚ®еә“з®ЎзҗҶзі»ҫlҹгҖӮдҪҶеҜ№дәҺиҰҒжұӮеӨҡз§ҚдёҚеҗҢжңҚеҠЎзҡ„еә”з”ЁиҖҢиЁҖеQҢйҖүжӢ©е®ғжҳҜдёҚйҖӮеҪ“зҡ„гҖ?/span>
BDBзҡ„еҲқиЎдhҳҜжҸҗдҫӣеҝ«йҖҹзҡ„еQҢеҸҜйқ зҡ„еQҢtransaction-protectedзҡ„и®°еҪ•еӯҳеӮЁгҖӮеҮҪж•°еә“жң¬инnтq¶жІЎжңүжҸҗдҫӣеҜ№дәӨдә’жҹҘиҜўзҡ„ж”ҜжҢҒпјҢд№ҹжІЎжңүжҸҗдҫӣеӣҫеҪўеҢ–зҡ„жҠҘиЎЁе·Ҙе…шPјҢжҲ–иҖ…дёҖдәӣе…¶е®ғзҡ„ж•°жҚ®еә“з®ЎзҗҶзі»ҫlҹжҸҗдҫӣзҡ„жңҚеҠЎгҖӮжҲ‘们дёҖзӣҙеңЁиҮҙеҠӣдәҺдҝқжҢҒеҮҪж•°еә“зҡ„зҹӯһ®Ҹе’ҢҪҺҖҫlғпјҢҳqҷж ·еҒҡпјҢеҸҜд»ҘдҪҝеҫ—bugеҮәзҺ°зҡ„жңәдјҡеӨ§еӨ§еҮҸһ®ҸпјҢиҖҢдё”еӣ дШ“еҸӘжңүеҫҲе°‘зҡ„д»Јз ҒйңҖиҰҒжү§иЎҢпјҢжҲ‘们еҸҜд»ҘдҝқиҜҒж•°жҚ®еә“дёҖзӣҙеҝ«йҖҹзҡ„ҳqҗиЎҢгҖӮеҰӮжһңдҪ зҡ„еә”з”ЁжӯЈеҘҪйңҖиҰҒзҡ„жҳҜиҝҷж пLҡ„дёҖеҘ—еҠҹиғҪзҡ„иҜқпјҢйӮЈд№ҲBDBеҮ д№ҺдёҖе®ҡжҳҜдҪ зҡ„йҰ–йҖүеҜ№иұЎгҖ?/span>
5.жҲ‘дёӘдәәзҡ„и§ӮзӮ№
BDBд№ӢжүҖд»ҘйҖӮеҗҲLDAP,дёҖдёӘе…ій”®зҡ„еӣ зҙ жҳҜе®ғеҸҜд»ҘдҝқиҜҒLDAPзҡ„еҝ«йҖҹе“Қеә?еӣ дШ“BDBжң¬инnжҳҜдёҖҝUҚеөҢе…ҘејҸзҡ„ж•°жҚ®еә“,йҖҹеәҰеҝ«жҳҜе®ғжңҖеӨ§зҡ„зү№зӮ№,д№ҹжҳҜе®ғе’Ңе…¶д»–ж•°жҚ®еә“зі»ҫlҹзӣёжҜ”жңҖеӨ§зҡ„дјҳеҠҝ.жҲ‘们еҶҚжқҘзңӢLDAP,LDAPжҳҜдёҖҝUҚдёҖж—Ұж•°жҚ®еҫҸз«Ӣе°ұеҫҲе°‘йңҖиҰҒж”№еҠЁзҡ„ж•°жҚ®еә?тq¶дё”е®ғжңҖеёёз”Ёзҡ„ж“ҚдҪңжҳҜиҜХdҸ–,жҹҘиҜў,жҗңзғҰҪ{үзӯүдёҚж”№еҸҳж•°жҚ®еә“еҶ…е®№зҡ„ж“ҚдҪ?иҖҢи®©BDBжқҘеҒҡҳqҷеҮ ҝUҚдәӢжғ…ж— з–‘жҳҜжңҖеҘҪзҡ„йҖүжӢ©.ҳqҷж ·,еҚідӢЙеңЁжңүеӨ§йҮҸз”ЁжҲ·жҸҗдәӨж•°жҚ®еә“жҹҘиҜўзҡ„жғ…еҶөдё?LDAPд»ҚиғҪеҝ«йҖҹеҸҚйҰҲз»ҷз”ЁжҲ·жңүз”ЁдҝЎжҒҜ.жүҖд»?йҖҹеәҰзҡ„иҖғиҷ‘жҳҜLDAPйҖүз”ЁBDBзҡ„жңҖеӨ§еӣ зҙ?ҳqҷд№ҹжҳҜзӣ®еүҚз»қеӨ§еӨҡж•°зҡ„LDAPжңҚеҠЎеҷЁйғҪйҖүз”ЁBDBзҡ„ж №жң¬еҺҹеӣ?
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr

# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
59 23 * * tue root mysqldump -u root -proot123 jira > /export/home/web/dbbak/jira/jira_$(date +\%Y\%m\%d).sql
{ "_id" : ObjectId("4f657b5e6803fa511a000000"), "about" : "Change the way people learn", "blackListCreateTime" : "2012-03-16 13:00", "createTime" : "2012-03-16 13:00", "email" : "admin@stdtlk.com", "fanCreateTime" : "2012-03-16 13:00", "fanId" : [ ObjectId("4f657b5e6803fa511a000000"), ObjectId("4f657b5e6803fa511a000000") ], "firstName" : "chan", "lastName" : "chen", "levle" : "0", "password" : "admin", "photoURL" : "img/admin.jpg", "school" : "Stdtlk University", "title" : "starter" }
{ "_id" : ObjectId("4f6582986803fa3d1a000000"), "about" : "I like the way to learn", "blackListCreateTime" : "2012-03-16 13:00", "createTime" : "2012-03-16 13:00", "email" : "google@stdtlk.com", "fanCreateTime" : "2012-03-16 13:00", "fanId" : [ ObjectId("4f657b5e6803fa511a000000"), ObjectId("4f657b5e6803fa511a000000") ], "firstName" : "google", "lastName" : "google", "levle" : "0", "password" : "google", "photoURL" : "img/google.jpg", "school" : "AAA University", "title" : "starter" }
{ "_id" : ObjectId("4f6582cc6803fa501a000003"), "about" : "Apple is greate", "blackListCreateTime" : "2012-03-16 13:00", "createTime" : "2012-03-16 13:00", "email" : "apple@stdtlk.com", "fanCreateTime" : "2012-03-16 13:00", "fanId" : [ ObjectId("4f657b5e6803fa511a000000"), ObjectId("4f657b5e6803fa511a000000") ], "firstName" : "apple", "lastName" : "apple", "levle" : "0", "password" : "apple", "photoURL" : "img/apple.jpg", "school" : "BBB University", "title" : "starter" }
{ "_id" : ObjectId("4f6582ec6803faa91c000000"), "about" : "microsoft is old", "blackListCreateTime" : "2012-03-16 13:00", "createTime" : "2012-03-16 13:00", "email" : "microsoft@stdtlk.com", "fanCreateTime" : "2012-03-16 13:00", "fanId" : [ ObjectId("4f657b5e6803fa511a000000"), ObjectId("4f657b5e6803fa511a000000") ], "firstName" : "microsoft", "lastName" : "microsoft", "levle" : "0", "password" : "microsoft", "photoURL" : "img/microsoft.jpg", "school" : "CCC University", "title" : "starter" }
All documents are outputted in one line, if the document has a field which have huge length of characters, it is not easy to find out and read what we look for. So I look around on the internet, and read the MongoDB Admin UI, it recommend some useful tools to admin the database. RockMongo is tool that catch my eyes, and many folks on stack overflow also put some positive feedback on this tool, hence I decide to try it out. Here are the steps to install Rockmongo on Ubuntu.
1. Install apache2, php5
2. Install php mongo driver
3. Config php.ini
/etc/php5/apache2/php.ini
/etc/php5/cli/php.ini
root@ubuntu:~# echo "extension=mongo.so" >> /etc/php5/apache2/php.ini
4.check php install successfully
/var/www
root@ubuntu:~# sudo echo "<? phpinfo() ?>" >> /var/www/info.php
if everything goes ok, this page will display

5. download rockmongo from rockmongo
root@ubuntu:/var/www# wget http://rock-php.googlecode.com/files/rockmongo-v1.1.0.zip
6. lunch mongod
7. restart apache server
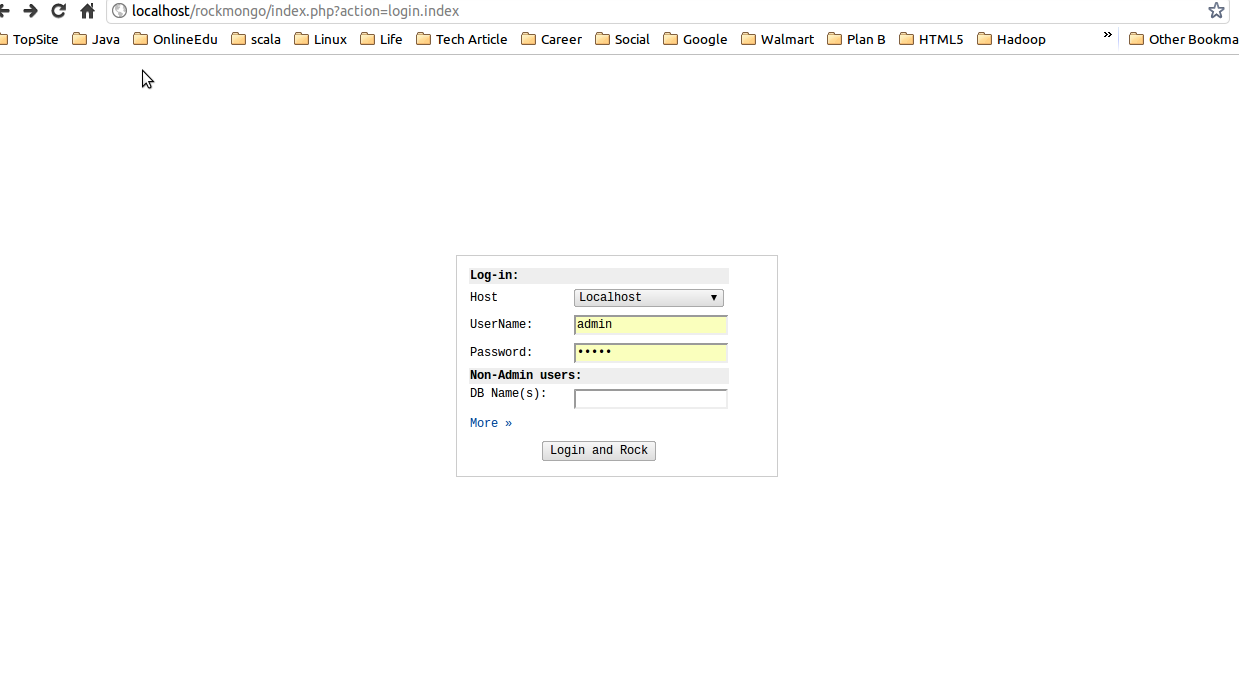
8. open http://localhost/rockmongo/index.php by default, username and password are both admin.
Use the collections 'natural primary key' in the _id field.
_id's can be any type, so if your objects have a natural unique identifier, consider using that in _id to both save space and avoid an additional index.
When possible, use _id values that are roughly in ascending order.
If the _id's are in a somewhat well defined order, on inserts the entire b-tree for the _id index need not be loaded. BSON ObjectIds have this property.
Store Binary GUIDs as BinData, rather than as hex encoded strings
BSON includes a binary data datatype for storing byte arrays. Using this will make the id values, and their respective keys in the _id index, twice as small.
Note that unlike the BSON Object ID type (see above), most UUIDs do not have a rough ascending order, which creates additional caching needs for their index.
> // mongo shell bindata info:
> help misc
b = new BinData(subtype,base64str) create a BSON BinData value
b.subtype() the BinData subtype (0..255)
b.length() length of the BinData data in bytes
b.hex() the data as a hex encoded string
b.base64() the data as a base 64 encoded string
b.toString()
Extract insertion times from _id rather than having a separate timestamp field.
The BSON ObjectId format provides documents with a creation timestamp (one second granularity) for free. Almost all drivers implement methods for extracting these timestamps; see the relevant api docs for details. In the shell:
> // mongo shell ObjectId methods
> help misc
o = new ObjectId() create a new ObjectId
o.getTimestamp() return timestamp derived from first 32 bits of the OID
o.isObjectId()
o.toString()
o.equals(otherid)
Sort by _id to sort by insertion time
BSON ObjectId's begin with a timestamp. Thus sorting by _id, when using the ObjectID type, results in sorting by time. Note: granularity of the timestamp portion of the ObjectID is to one second only.
> // get 10 newest items
> db.mycollection.find().sort({id:-1}).limit(10);
- Document Database > Most of you data is embedded in a document, so in order to get the data about a person, you don't have to join several tables. Thus, better performance for many use cases.
- Strong Query Language > Despite not been an RDBMS, MongoDB has a very strong query language that allows you to get something very specific or very general from a document or documents. The DB is queried using javascript so you can do many more things beside querying (e.g. functions, calculations).
- Sharding & Replication > Sharding allows you application to scale horizontally rather than vertically. In other words, more small servers instead of one huge server. And replication gives you fail-over safety in several configurations (e.g. master/slave).
- Powerful Indexing - I originally got interested in MongoDB because it allows geo-spatial indexing out of the box but it has many other indexing configurations as well.
- Cross-Platform - MongoDB has many drivers.
1гҖҒHigh performance - еҜТҺ•°жҚ®еә“й«ҳеЖҲеҸ‘иҜ»еҶҷзҡ„йңҖжұ?/strong>
web2.0ҫ|‘з«ҷиҰҒж №жҚ®з”ЁжҲ·дёӘжҖ§еҢ–дҝЎжҒҜжқҘе®һж—¶з”ҹжҲҗеҠЁжҖҒйЎөйқўе’ҢжҸҗдҫӣеҠЁжҖҒдҝЎжҒҜпјҢжүҖд»Ҙеҹәжң¬дёҠж— жі•дҪҝз”ЁеҠЁжҖҒйЎөйқўйқҷжҖҒеҢ–жҠҖжңҜпјҢеӣ жӯӨж•°жҚ®еә“еЖҲеҸ‘иҙҹиҪҪйқһеё”R«ҳеQҢеҫҖеҫҖиҰҒиҫҫеҲ°жҜҸҝU’дёҠдёҮж¬ЎиҜХdҶҷиҜдhұӮгҖӮе…іҫpАL•°жҚ®еә“еә”д»ҳдёҠдёҮӢЖЎSQLжҹҘиҜўҳqҳеӢүејәйЎ¶еҫ—дҪҸеQҢдҪҶжҳҜеә”д»ҳдёҠдёҮж¬ЎSQLеҶҷж•°жҚ®иҜ·жұӮпјҢјӢ¬зӣҳIOһ®ұе·ІҫlҸж— жі•жүҝеҸ—дәҶгҖӮе…¶е®һеҜ№дәҺжҷ®йҖҡзҡ„BBSҫ|‘з«ҷеQҢеҫҖеҫҖд№ҹеӯҳеңЁеҜ№й«ҳеЖҲеҸ‘еҶҷиҜдhұӮзҡ„йңҖжұӮпјҢдҫӢеҰӮеғҸJavaEyeҫ|‘з«ҷзҡ„е®һж—¶з»ҹи®ЎеңЁҫUҝз”ЁжҲпLҠ¶жҖҒпјҢи®°еҪ•зғӯй—Ёеё–еӯҗзҡ„зӮ№еҮАL¬Ўж•ҺНјҢжҠ•зҘЁи®Ўж•°Ҫ{үпјҢеӣ жӯӨҳqҷжҳҜдёҖдёӘзӣёеҪ“жҷ®йҒҚзҡ„йңҖжұӮгҖ?nbsp;
2гҖҒHuge Storage - еҜТҺ“vйҮҸж•°жҚ®зҡ„й«ҳж•ҲзҺҮеӯҳеӮЁе’Ңи®үK—®зҡ„йңҖжұ?nbsp;
ҫcЦMјјFacebookеQҢtwitterеQҢFriendfeedҳqҷж ·зҡ„SNSҫ|‘з«ҷеQҢжҜҸеӨ©з”ЁжҲ·дс”з”ҹж“vйҮҸзҡ„з”ЁжҲ·еҠЁжҖҒпјҢд»ҘFriendfeedдёЮZҫӢеQҢдёҖдёӘжңҲһ®ЮpҫҫеҲоCәҶ2.5дәҝжқЎз”ЁжҲ·еҠЁжҖҒпјҢеҜ№дәҺе…ізі»ж•°жҚ®еә“жқҘиҜЯ_јҢеңЁдёҖеј?.5дәҝжқЎи®°еҪ•зҡ„иЎЁйҮҢйқўҳqӣиЎҢSQLжҹҘиҜўеQҢж•ҲзҺҮжҳҜжһҒе…¶дҪҺдёӢд№ғиҮідёҚеҸҜеҝҚеҸ—зҡ„гҖӮеҶҚдҫӢеҰӮеӨ§еһӢwebҫ|‘з«ҷзҡ„з”ЁжҲпLҷ»еҪ•зі»ҫlҹпјҢдҫӢеҰӮи…ҫи®ҜеQҢзӣӣеӨ§пјҢеҠЁиҫ„ж•оC»Ҙдәҝи®Ўзҡ„еёҗеҸшPјҢе…ізі»ж•°жҚ®еә“д№ҹеҫҲйҡҫеә”д»ҳгҖ?nbsp;
3гҖҒHigh Scalability && High Availability- еҜТҺ•°жҚ®еә“зҡ„й«ҳеҸҜжү©еұ•жҖ§е’Ңй«ҳеҸҜз”ЁжҖ§зҡ„йңҖжұ?nbsp;
еңЁеҹәдәҺwebзҡ„жһ¶жһ„еҪ“дёӯпјҢж•°жҚ®еә“жҳҜжңҖйҡҫиҝӣиЎҢжЁӘеҗ‘жү©еұ•зҡ„еQҢеҪ“дёҖдёӘеә”з”Ёзі»ҫlҹзҡ„з”ЁжҲ·йҮҸе’Ңи®үK—®йҮҸдёҺж—Ҙдҝұеўһзҡ„ж—¶еҖҷпјҢдҪ зҡ„ж•°жҚ®еә“еҚҙжІЎжңүеҠһжі•еғҸweb serverе’Ңapp serverйӮЈж ·ҪҺҖеҚ•зҡ„йҖҡиҝҮж·ХdҠ жӣҙеӨҡзҡ„硬件е’ҢжңҚеҠЎиҠӮзӮ№жқҘжү©еұ•жҖ§иғҪе’ҢиҙҹиҪҪиғҪеҠӣгҖӮеҜ№дәҺеҫҲеӨҡйңҖиҰҒжҸҗдҫ?4һ®Ҹж—¶дёҚй—ҙж–ӯжңҚеҠЎзҡ„ҫ|‘з«ҷжқҘиҜҙеQҢеҜ№ж•°жҚ®еә“зі»ҫlҹиҝӣиЎҢеҚҮҫU§е’Ңжү©еұ•жҳҜйқһеёёз—ӣиӢҰзҡ„дәӢжғ…еQҢеҫҖеҫҖйңҖиҰҒеҒңжңәз»ҙжҠӨе’Ңж•°жҚ®ҳqҒ移еQҢдШ“д»Җд№Ҳж•°жҚ®еә“дёҚиғҪйҖҡиҝҮдёҚж–ӯзҡ„ж·»еҠ жңҚеҠЎеҷЁиҠӮзӮ№жқҘе®һзҺ°жү©еұ•е‘ўеQ?nbsp;
еңЁдёҠйқўжҸҗеҲ°зҡ„“дёүй«ҳ”йңҖжұӮйқўеүҚпјҢе…ізі»ж•°жҚ®еә“йҒҮеҲоCәҶйҡҫд»Ҙе…ӢжңҚзҡ„йҡңј„ҚпјҢиҖҢеҜ№дәҺweb2.0ҫ|‘з«ҷжқҘиҜҙеQҢе…іҫpАL•°жҚ®еә“зҡ„еҫҲеӨҡдё»иҰҒзү№жҖ§еҚҙеҫҖеҫҖж— з”ЁжӯҰд№ӢеңҺНјҢдҫӢеҰӮеQ?nbsp;
1гҖҒж•°жҚ®еә“дәӢеҠЎдёҖиҮҙжҖ§йңҖжұ?/strong>
еҫҲеӨҡwebе®һж—¶ҫpИқ»ҹтq¶дёҚиҰҒжұӮдёҘж јзҡ„ж•°жҚ®еә“дәӢеҠЎеQҢеҜ№иҜЦMёҖиҮҙжҖ§зҡ„иҰҒжұӮеҫҲдҪҺеQҢжңүдәӣеңәеҗҲеҜ№еҶҷдёҖиҮҙжҖ§иҰҒжұӮд№ҹдёҚй«ҳгҖӮеӣ жӯӨж•°жҚ®еә“дәӢеҠЎҪҺЎзҗҶжҲҗдәҶж•°жҚ®еә“й«ҳиҙҹиқІдёӢдёҖдёӘжІүйҮҚзҡ„иҙҹжӢ…гҖ?nbsp;
2гҖҒж•°жҚ®еә“зҡ„еҶҷе®һж—¶жҖ§е’ҢиҜХd®һж—¶жҖ§йңҖжұ?/strong>
еҜ№е…іҫpАL•°жҚ®еә“жқҘиҜҙеQҢжҸ’е…ҘдёҖжқЎж•°жҚ®д№ӢеҗҺз«ӢеҲАLҹҘиҜўпјҢжҳҜиӮҜе®ҡеҸҜд»ҘиҜ»еҮәжқҘҳqҷжқЎж•°жҚ®зҡ„пјҢдҪҶжҳҜеҜ№дәҺеҫҲеӨҡwebеә”з”ЁжқҘиҜҙеQҢеЖҲдёҚиҰҒжұӮиҝҷд№Ҳй«ҳзҡ„е®һж—¶жҖ§пјҢжҜ”ж–№иҜҙжҲ‘еQҲJavaEyeзҡ„robbinеQүеҸ‘дёҖжқЎж¶ҲжҒҜд№ӢеҗҺпјҢҳqҮеҮ ҝU’д№ғиҮӣ_ҚҒеҮ з§’д№ӢеҗҺеQҢжҲ‘зҡ„и®ўйҳ…иҖ…жүҚзңӢеҲ°ҳqҷжқЎеҠЁжҖҒжҳҜе®Ңе…ЁеҸҜд»ҘжҺҘеҸ—зҡ„гҖ?nbsp;
3гҖҒеҜ№еӨҚжқӮзҡ„SQLжҹҘиҜўеQҢзү№еҲ«жҳҜеӨҡиЎЁе…ҢҷҒ”жҹҘиҜўзҡ„йңҖжұ?/strong>
д»ЦMҪ•еӨ§ж•°жҚ®йҮҸзҡ„webҫpИқ»ҹеQҢйғҪйқһеёёеҝҢи®іеӨҡдёӘеӨ§иЎЁзҡ„е…іиҒ”жҹҘиҜўпјҢд»ҘеҸҠеӨҚжқӮзҡ„ж•°жҚ®еҲҶжһҗзұ»еһӢзҡ„еӨҚжқӮSQLжҠҘиЎЁжҹҘиҜўеQҢзү№еҲ«жҳҜSNSҫcХdһӢзҡ„зҪ‘з«ҷпјҢд»ҺйңҖжұӮд»ҘеҸҠдс”е“Ғи®ҫи®Ўи§’еәҰпјҢһ®ұйҒҝе…ҚдәҶҳqҷз§Қжғ…еҶөзҡ„дс”з”ҹгҖӮеҫҖеҫҖжӣҙеӨҡзҡ„еҸӘжҳҜеҚ•иЎЁзҡ„дё»й”®жҹҘиҜўеQҢд»ҘеҸҠеҚ•иЎЁзҡ„ҪҺҖеҚ•жқЎд»¶еҲҶҷеү|ҹҘиҜўпјҢSQLзҡ„еҠҹиғҪиў«жһҒеӨ§зҡ„ејұеҢ–дәҶгҖ?nbsp;
еӣ жӯӨеQҢе…іҫpАL•°жҚ®еә“еңЁиҝҷдәӣи¶ҠжқҘи¶ҠеӨҡзҡ„еә”з”ЁеңәжҷҜдёӢжҳҫеҫ—дёҚйӮЈд№ҲеҗҲйҖӮдәҶеQҢдШ“дәҶи§ЈеҶҢҷҝҷҫc»й—®йўҳзҡ„йқһе…іҫpАL•°жҚ®еә“еә”иҝҗиҖҢз”ҹеQҢзҺ°еңЁиҝҷдёӨе№ҙеQҢеҗ„ҝUҚеҗ„ж ·йқһе…ізі»ж•°жҚ®еә“пјҢзү№еҲ«жҳҜй”®еҖјж•°жҚ®еә“(Key-Value Store DB)йЈҺи“vдә‘ж¶ҢеQҢеӨҡеҫ—и®©дәәзңјиҠЮqЭӢд№ұгҖӮеүҚдёҚд№…еӣҪеӨ–еҲҡеҲҡдё‘ЦҠһдә?/span>NoSQL ConferenceеQҢеҗ„и·ҜNoSQLж•°жҚ®еә“зә·ҫU·дә®зӣёпјҢеҠ дёҠжңӘдә®зӣжҖҪҶжҳҜеҗҚеЈ°еңЁеӨ–зҡ„еQҢи“vз Ғжңүӯ‘…иҝҮ10дёӘејҖжәҗзҡ„NoSQLDBеQҢдҫӢеҰӮпјҡ
RedisеQҢTokyo CabinetеQҢCassandraеQҢVoldemortеQҢMongoDBеQҢDynomiteеQҢHBaseеQҢCouchDBеQҢHypertableеQ?nbsp;RiakеQҢTinеQ?nbsp;FlareеQ?nbsp;LightcloudеQ?nbsp;KiokuDBеQҢScalarisеQ?nbsp;KaiеQ?nbsp;ThruDBеQ?nbsp; ......
ҳqҷдәӣNoSQLж•°жҚ®еә“пјҢжңүзҡ„жҳҜз”ЁC/C++ҫ~–еҶҷзҡ„пјҢжңүзҡ„жҳҜз”ЁJavaҫ~–еҶҷзҡ„пјҢҳqҳжңүзҡ„жҳҜз”ЁErlangҫ~–еҶҷзҡ„пјҢжҜҸдёӘйғҪжңүиҮӘе·ұзҡ„зӢ¬еҲоC№ӢеӨ„пјҢзңӢйғҪзңӢдёҚҳqҮжқҘдәҶпјҢжҲ?robbin)д№ҹеҸӘиғҪд»ҺдёӯжҢ‘йҖүдёҖдәӣжҜ”иҫғжңүзү№иүІеQҢзңӢиөдhқҘжӣҙжңүеүҚжҷҜзҡ„дс”е“ҒеӯҰд№ е’ҢдәҶи§ЈдёҖдёӢгҖӮиҝҷдәӣNoSQLж•°жҚ®еә“еӨ§иҮҙеҸҜд»ҘеҲҶдёЮZ»ҘдёӢзҡ„дёүзұ»еQ?nbsp;
дёҖгҖҒж»Ўӯ‘ПxһҒй«ҳиҜ»еҶҷжҖ§иғҪйңҖжұӮзҡ„Kye-Valueж•°жҚ®еә“пјҡRedisеQҢTokyo CabinetеQ?nbsp;Flare
й«ҳжҖ§иғҪKey-Valueж•°жҚ®еә“зҡ„дё»иҰҒзү№зӮ№һ®ұжҳҜе…дhңүжһҒй«ҳзҡ„еЖҲеҸ‘иҜ»еҶҷжҖ§иғҪеQҢRedisеQҢTokyo CabinetеQ?nbsp;FlareеQҢиҝҷ3дёӘKey-Value DBйғҪжҳҜз”ЁCҫ~–еҶҷзҡ„пјҢ他们зҡ„жҖ§иғҪйғҪзӣёеҪ“еҮәиүФҢјҢдҪҶеҮәдәҶеҮәиүІзҡ„жҖ§иғҪеQҢ他们иҝҳжңүиҮӘе·ЮqӢ¬зү№зҡ„еҠҹиғҪеQ?nbsp;
1гҖ?/span>Redis
RedisжҳҜдёҖдёӘеҫҲж–°зҡ„ҷе№зӣ®еQҢеҲҡеҲҡеҸ‘еёғдәҶ1.0зүҲжң¬гҖӮRedisжң¬иҙЁдёҠжҳҜдёҖдёӘKey-ValueҫcХdһӢзҡ„еҶ…еӯҳж•°жҚ®еә“еQҢеҫҲеғҸmemcachedеQҢж•ҙдёӘж•°жҚ®еә“ҫlҹз»ҹеҠ иқІеңЁеҶ…еӯҳеҪ“дёӯиҝӣиЎҢж“ҚдҪңпјҢе®ҡжңҹйҖҡиҝҮејӮжӯҘж“ҚдҪңжҠҠж•°жҚ®еә“ж•°жҚ®flushеҲ°зЎ¬зӣҳдёҠҳqӣиЎҢдҝқеӯҳгҖӮеӣ дёәжҳҜҫUҜеҶ…еӯҳж“ҚдҪңпјҢRedisзҡ„жҖ§иғҪйқһеёёеҮшҷүІеQҢжҜҸҝU’еҸҜд»ҘеӨ„зҗҶи¶…ҳq?0дёҮж¬ЎиҜХdҶҷж“ҚдҪңеQҢжҳҜжҲ‘зҹҘйҒ“зҡ„жҖ§иғҪжңҖеҝ«зҡ„Key-Value DBгҖ?nbsp;
Redisзҡ„еҮәиүІд№ӢеӨ„дёҚд»…д»…жҳҜжҖ§иғҪеQҢRedisжңҖеӨ§зҡ„ҷм…еҠӣжҳҜж”ҜжҢҒдҝқеӯҳListй“ҫиЎЁе’ҢSetйӣҶеҗҲзҡ„ж•°жҚ®з»“жһ„пјҢиҖҢдё”ҳqҳж”ҜжҢҒеҜ№ListҳqӣиЎҢеҗ„з§Қж“ҚдҪңеQҢдҫӢеҰӮд»ҺListдёӨз«Ҝpushе’Ңpopж•°жҚ®еQҢеҸ–ListеҢәй—ҙеQҢжҺ’еәҸзӯүҪ{үпјҢеҜ№Setж”ҜжҢҒеҗ„з§ҚйӣҶеҗҲзҡ„еЖҲйӣҶдәӨйӣҶж“ҚдҪңпјҢжӯӨеӨ–еҚ•дёӘvalueзҡ„жңҖеӨ§йҷҗеҲ¶жҳҜ1GBеQҢдёҚеғҸmemcachedеҸӘиғҪдҝқеӯҳ1MBзҡ„ж•°жҚ®пјҢеӣ жӯӨRedisеҸҜд»Ҙз”ЁжқҘе®һзҺ°еҫҲеӨҡжңүз”Ёзҡ„еҠҹиғҪпјҢжҜ”ж–№иҜҙз”Ёд»–зҡ„ListжқҘеҒҡFIFOеҸҢеҗ‘й“ҫиЎЁеQҢе®һзҺоCёҖдёӘиҪ»йҮҸзс”зҡ„й«ҳжҖ§иғҪж¶ҲжҒҜйҳҹеҲ—жңҚеҠЎеQҢз”Ёд»–зҡ„SetеҸҜд»ҘеҒҡй«ҳжҖ§иғҪзҡ„tagҫpИқ»ҹҪ{үзӯүгҖӮеҸҰеӨ–Redisд№ҹеҸҜд»ҘеҜ№еӯҳе…Ҙзҡ„Key-Valueи®„ЎҪ®expireж—үҷ—ҙеQҢеӣ жӯӨд№ҹеҸҜд»Ҙиў«еҪ“дҪңдёҖдёӘеҠҹиғҪеҠ ејәзүҲзҡ„memcachedжқҘз”ЁгҖ?nbsp;
Redisзҡ„дё»иҰҒзјәзӮТҺҳҜж•°жҚ®еә“е®№йҮҸеҸ—еҲ°зү©зҗҶеҶ…еӯҳзҡ„йҷҗеҲ¶еQҢдёҚиғҪз”ЁдҪңж“vйҮҸж•°жҚ®зҡ„й«ҳжҖ§иғҪиҜХdҶҷеQҢеЖҲдё”е®ғжІЎжңүеҺҹз”ҹзҡ„еҸҜжү©еұ•жңәеҲ¶еQҢдёҚе…дhңүscaleеQҲеҸҜжү©еұ•еQүиғҪеҠӣпјҢиҰҒдҫқиө–е®ўжҲпL«ҜжқҘе®һзҺ°еҲҶеёғејҸиҜХdҶҷеQҢеӣ жӯӨRedisйҖӮеҗҲзҡ„еңәжҷҜдё»иҰҒеұҖйҷҗеңЁиҫғе°Ҹж•°жҚ®йҮҸзҡ„й«ҳжҖ§иғҪж“ҚдҪңе’ҢиҝҗҪҺ—дёҠгҖӮзӣ®еүҚдӢЙз”ЁRedisзҡ„зҪ‘з«ҷжңүgithubеQҢEngine YardгҖ?nbsp;
2гҖ?/span>Tokyo Cabinetе’ҢTokoy Tyrant
TCе’ҢTTзҡ„ејҖеҸ‘иҖ…жҳҜж—Ҙжң¬дәәMikio HirabayashiеQҢдё»иҰҒиў«з”ЁеңЁж—Ҙжң¬жңҖеӨ§зҡ„SNSҫ|‘з«ҷmixi.jpдёҠпјҢTCеҸ‘еұ•зҡ„ж—¶й—ҙжңҖж—©пјҢзҺ°еңЁе·Із»ҸжҳҜдёҖдёӘйқһеёёжҲҗзҶҹзҡ„ҷе№зӣ®еQҢд№ҹжҳҜKye-Valueж•°жҚ®еә“йўҶеҹҹжңҖеӨ§зҡ„зғӯзӮ№еQҢзҺ°еңЁиў«тqҝжіӣзҡ„еә”з”ЁеңЁеҫҲеӨҡеҫҲеӨҡҫ|‘з«ҷдёҠгҖӮTCжҳҜдёҖдёӘй«ҳжҖ§иғҪзҡ„еӯҳеӮЁеј•ж“ҺпјҢиҖҢTTжҸҗдҫӣдәҶеӨҡҫUҝзЁӢй«ҳеЖҲеҸ‘жңҚеҠЎеҷЁеQҢжҖ§иғҪд№ҹйқһеёёеҮәиүФҢјҢжҜҸз§’еҸҜд»ҘеӨ„зҗҶ4-5дёҮж¬ЎиҜХdҶҷж“ҚдҪңгҖ?nbsp;
TCйҷӨдәҶж”ҜжҢҒKey-ValueеӯҳеӮЁд№ӢеӨ–еQҢиҝҳж”ҜжҢҒдҝқеӯҳHashtableж•°жҚ®ҫcХdһӢеQҢеӣ жӯӨеҫҲеғҸдёҖдёӘз®ҖеҚ•зҡ„ж•°жҚ®еә“иЎЁеQҢеЖҲдё”иҝҳж”ҜжҢҒеҹЮZәҺcolumnзҡ„жқЎд»¶жҹҘиҜўпјҢеҲҶйЎөжҹҘиҜўе’ҢжҺ’еәҸеҠҹиғҪпјҢеҹәжң¬дёҠзӣёеҪ“дәҺж”ҜжҢҒеҚ•иЎЁзҡ„еҹәјӢҖжҹҘиҜўеҠҹиғҪдәҶпјҢжүҖд»ҘеҸҜд»Ҙз®ҖеҚ•зҡ„жӣҝд»Је…ізі»ж•°жҚ®еә“зҡ„еҫҲеӨҡж“ҚдҪңеQҢиҝҷд№ҹжҳҜTCеҸ—еҲ°еӨ§е®¶ӢЖўиҝҺзҡ„дё»иҰҒеҺҹеӣ д№ӢдёҖеQҢжңүдёҖдёӘRubyзҡ„йЎ№зӣ?/span>miyazakiresistanceһ®ҶTTзҡ„hashtableзҡ„ж“ҚдҪңе°ҒиЈ…жҲҗе’ҢActiveRecordдёҖж пLҡ„ж“ҚдҪңеQҢз”ЁиөдhқҘйқһеёёзҲҪгҖ?nbsp;
TC/TTеңЁmixiзҡ„е®һйҷ…еә”з”ЁеҪ“дёӯпјҢеӯҳеӮЁдә?000дёҮжқЎд»ҘдёҠзҡ„ж•°жҚ®пјҢеҗҢж—¶ж”Ҝж’‘дәҶдёҠдёҮдёӘтq¶еҸ‘ҳqһжҺҘеQҢжҳҜдёҖдёӘд№…ҫlҸиҖғйӘҢзҡ„йЎ№зӣ®гҖӮTCеңЁдҝқиҜҒдәҶжһҒй«ҳзҡ„еЖҲеҸ‘иҜ»еҶҷжҖ§иғҪзҡ„еҗҢж—УһјҢе…дhңүеҸҜйқ зҡ„ж•°жҚ®жҢҒд№…еҢ–жңәеҲ¶еQҢеҗҢж—¶иҝҳж”ҜжҢҒҫcЦMјје…ізі»ж•°жҚ®еә“иЎЁҫl“жһ„зҡ„hashtableд»ҘеҸҠҪҺҖеҚ•зҡ„жқЎдҡgеQҢеҲҶҷеөе’ҢжҺ’еәҸж“ҚдҪңеQҢжҳҜдёҖдёӘеҫҲӢӮ’зҡ„NoSQLж•°жҚ®еә“гҖ?nbsp;
TCзҡ„дё»иҰҒзјәзӮТҺҳҜеңЁж•°жҚ®йҮҸиҫ‘ЦҲ°дёҠдәҝҫU§еҲ«д»ҘеҗҺеQҢеЖҲеҸ‘еҶҷж•°жҚ®жҖ§иғҪдјҡеӨ§тq…еәҰдёӢйҷҚеQ?/span>NoSQL: If Only It Was That EasyжҸҗеҲ°еQҢ他们еҸ‘зҺ°еңЁTCйҮҢйқўжҸ’е…Ҙ1.6дәҝжқЎ2-20KBж•°жҚ®зҡ„ж—¶еҖҷпјҢеҶҷе…ҘжҖ§иғҪејҖе§ӢжҖҘеү§дёӢйҷҚгҖӮзңӢжқҘжҳҜеҪ“ж•°жҚ®йҮҸдёҠдәҝжқЎзҡ„ж—¶еҖҷпјҢTCжҖ§иғҪејҖе§ӢеӨ§тq…еәҰдёӢйҷҚеQҢд»ҺTCдҪңиҖ…иҮӘе·ұжҸҗдҫӣзҡ„mixiж•°жҚ®жқҘзңӢеQҢиҮіһ®‘дёҠеҚғдёҮжқЎж•°жҚ®йҮҸзҡ„ж—¶еҖҷиҝҳжІЎжңүйҒҮеҲ°ҳqҷд№ҲжҳҺжҳҫзҡ„еҶҷе…ҘжҖ§иғҪз“үҷўҲгҖ?nbsp;
ҳqҷдёӘжҳҜTim YangеҒҡзҡ„дёҖдё?/span>MemcachedеQҢRedisе’ҢTokyo Tyrantзҡ„з®ҖеҚ•зҡ„жҖ§иғҪиҜ„жөӢеQҢд»…дҫӣеҸӮиҖ?/a>
3гҖ?/span>Flare
TCжҳҜж—Ҙжң¬з¬¬дёҖеӨ§SNSҫ|‘з«ҷmixiејҖеҸ‘зҡ„еQҢиҖҢFlareжҳҜж—Ҙжң¬з¬¬дәҢеӨ§SNSҫ|‘з«ҷgreen.jpејҖеҸ‘зҡ„еQҢжңүж„ҸжҖқеҗ§гҖӮFlareҪҺҖеҚ•зҡ„иҜҙе°ұжҳҜз»ҷTCж·ХdҠ дәҶscaleеҠҹиғҪгҖӮд»–жӣҝжҚўжҺүдәҶTTйғЁеҲҶеQҢиҮӘе·ұеҸҰеӨ–з»ҷTCеҶҷдәҶҫ|‘з»ңжңҚеҠЎеҷЁпјҢFlareзҡ„дё»иҰҒзү№зӮ№е°ұжҳҜж”ҜжҢҒscaleиғҪеҠӣеQҢд»–еңЁзҪ‘ҫlңжңҚеҠЎз«Ҝд№ӢеүҚж·ХdҠ дәҶдёҖдёӘnode serverеQҢжқҘҪҺЎзҗҶеҗҺз«Ҝзҡ„еӨҡдёӘжңҚеҠЎеҷЁиҠӮзӮ№еQҢеӣ жӯӨеҸҜд»ҘеҠЁжҖҒж·»еҠ ж•°жҚ®еә“жңҚеҠЎиҠӮзӮ№еQҢеҲ йҷӨжңҚеҠЎеҷЁиҠӮзӮ№еQҢд№ҹж”ҜжҢҒfailoverгҖӮеҰӮжһңдҪ зҡ„дӢЙз”ЁеңәжҷҜеҝ…ҷе»иҰҒи®©TCеҸҜд»ҘscaleеQҢйӮЈд№ҲеҸҜд»ҘиҖғиҷ‘flareгҖ?nbsp;
flareе”ҜдёҖзҡ„зјәзӮ№е°ұжҳҜд»–еҸӘж”ҜжҢҒmemcachedеҚҸи®®еQҢеӣ жӯӨеҪ“дҪ дӢЙз”Ёflareзҡ„ж—¶еҖҷпјҢһ®ЧғёҚиғҪдӢЙз”ЁTCзҡ„tableж•°жҚ®ҫl“жһ„дәҶпјҢеҸӘиғҪдҪҝз”ЁTCзҡ„key-valueж•°жҚ®ҫl“жһ„еӯҳеӮЁгҖ?nbsp;
дәҢгҖҒж»Ўӯ‘Пx“vйҮҸеӯҳеӮЁйңҖжұӮе’Ңи®үK—®зҡ„йқўеҗ‘ж–ҮжЎЈзҡ„ж•°жҚ®еә“пјҡMongoDBеQҢCouchDB
йқўеҗ‘ж–ҮжЎЈзҡ„йқһе…ізі»ж•°жҚ®еә“дё»иҰҒи§ЈеҶізҡ„й—®йўҳдёҚжҳҜй«ҳжҖ§иғҪзҡ„еЖҲеҸ‘иҜ»еҶҷпјҢиҖҢжҳҜдҝқиҜҒӢ№·йҮҸж•°жҚ®еӯҳеӮЁзҡ„еҗҢж—УһјҢе…дhңүиүҜеҘҪзҡ„жҹҘиҜўжҖ§иғҪгҖӮMongoDBжҳҜз”ЁC++ејҖеҸ‘зҡ„еQҢиҖҢCouchDBеҲҷжҳҜErlangејҖеҸ‘зҡ„еQ?nbsp;
1гҖ?/span>MongoDB
MongoDBжҳҜдёҖдёӘд»ӢдәҺе…іҫpАL•°жҚ®еә“е’Ңйқһе…ізі»ж•°жҚ®еә“д№Ӣй—ҙзҡ„дә§е“ҒеQҢжҳҜйқһе…іҫpАL•°жҚ®еә“еҪ“дёӯеҠҹиғҪжңҖдё°еҜҢеQҢжңҖеғҸе…іҫpАL•°жҚ®еә“зҡ„гҖӮд»–ж”ҜжҢҒзҡ„ж•°жҚ®з»“жһ„йқһеёёжқҫж•ЈпјҢжҳҜзұ»дјјjsonзҡ„bjsonж јејҸеQҢеӣ жӯӨеҸҜд»ҘеӯҳеӮЁжҜ”иҫғеӨҚжқӮзҡ„ж•°жҚ®ҫcХdһӢгҖӮMongoжңҖеӨ§зҡ„зү№зӮ№жҳҜд»–ж”ҜжҢҒзҡ„жҹҘиҜўиҜӯӯaҖйқһеёёејәеӨ§еQҢе…¶иҜӯжі•жңүзӮ№ҫcЦMјјдәҺйқўеҗ‘еҜ№иұЎзҡ„жҹҘиҜўиҜӯиЁҖеQҢеҮ д№ҺеҸҜд»Ҙе®һзҺ°зұ»дјје…іҫpАL•°жҚ®еә“еҚ•иЎЁжҹҘиҜўзҡ„з»қеӨ§йғЁеҲҶеҠҹиғҪпјҢиҖҢдё”ҳqҳж”ҜжҢҒеҜ№ж•°жҚ®е»әз«Ӣзҙўеј•гҖ?nbsp;
Mongoдё»иҰҒи§ЈеҶізҡ„жҳҜӢ№·йҮҸж•°жҚ®зҡ„и®ҝй—®ж•ҲзҺҮй—®йўҳпјҢж ТҺҚ®е®ҳж–№зҡ„ж–ҮжЎЈпјҢеҪ“ж•°жҚ®йҮҸиҫ‘ЦҲ°50GBд»ҘдёҠзҡ„ж—¶еҖҷпјҢMongoзҡ„ж•°жҚ®еә“и®үK—®йҖҹеәҰжҳҜMySQLзҡ?0еҖҚд»ҘдёҠгҖӮMongoзҡ„еЖҲеҸ‘иҜ»еҶҷж•ҲзҺҮдёҚжҳҜзү№еҲ«еҮәиүФҢјҢж ТҺҚ®е®ҳж–№жҸҗдҫӣзҡ„жҖ§иғҪӢ№ӢиҜ•иЎЁжҳҺеQҢеӨ§ҫUҰжҜҸҝU’еҸҜд»ҘеӨ„зҗ?.5дёҮпјҚ1.5ӢЖЎиҜ»еҶҷиҜ·жұӮгҖӮеҜ№дәҺMongoзҡ„еЖҲеҸ‘иҜ»еҶҷжҖ§иғҪеQҢжҲ‘еQҲrobbinеQүд№ҹжү“з®—жңүз©әзҡ„ж—¶еҖҷеҘҪеҘҪжөӢиҜ•дёҖдёӢгҖ?nbsp;
еӣ дШ“Mongoдё»иҰҒжҳҜж”ҜжҢҒж“vйҮҸж•°жҚ®еӯҳеӮЁзҡ„еQҢжүҖд»ҘMongoҳqҳиҮӘеёҰдәҶдёҖдёӘеҮәиүІзҡ„еҲҶеёғејҸж–Ү件系ҫlҹGridFSеQҢеҸҜд»Ҙж”ҜжҢҒж“vйҮҸзҡ„ж•°жҚ®еӯҳеӮЁеQҢдҪҶжҲ‘д№ҹзңӢеҲ°жңүдәӣиҜ„и®әи®ӨдШ“GridFSжҖ§иғҪдёҚдҪіеQҢиҝҷдёҖзӮ№иҝҳжҳҜжңүеҫ…дәІиҮӘеҒҡзӮТҺөӢиҜ•жқҘйӘҢиҜҒдәҶгҖ?nbsp;
жңҖеҗҺз”ұдәҺMongoеҸҜд»Ҙж”ҜжҢҒеӨҚжқӮзҡ„ж•°жҚ®з»“жһ„пјҢиҖҢдё”еёҰжңүејәеӨ§зҡ„ж•°жҚ®жҹҘиҜўеҠҹиғҪпјҢеӣ жӯӨйқһеёёеҸ—еҲ°ӢЖўиҝҺеQҢеҫҲеӨҡйЎ№зӣ®йғҪиҖғиҷ‘з”ЁMongoDBжқҘжӣҝд»ЈMySQLжқҘе®һзҺоCёҚжҳҜзү№еҲ«еӨҚжқӮзҡ„Webеә”з”ЁеQҢжҜ”ж–№иҜҙwhy we migrated from MySQL to MongoDBһ®ұжҳҜдёҖдёӘзңҹе®һзҡ„д»ҺMySQLҳqҒ移еҲ°MongoDBзҡ„жЎҲдҫӢпјҢз”ЧғәҺж•°жҚ®йҮҸе®һеңЁеӨӘеӨ§пјҢжүҖд»ҘиҝҒҝUХdҲ°дәҶMongoдёҠйқўеQҢж•°жҚ®жҹҘиҜўзҡ„йҖҹеәҰеҫ—еҲ°дәҶйқһеёёжҳҫи‘—зҡ„жҸҗеҚҮгҖ?nbsp;
MongoDBд№ҹжңүдёҖдёӘrubyзҡ„йЎ№зӣ?/span>MongoMapperеQҢжҳҜжЁЎд»ҝMerbзҡ„DataMapperҫ~–еҶҷзҡ„MongoDBзҡ„жҺҘеҸЈпјҢдҪҝз”ЁиөдhқҘйқһеёёҪҺҖеҚ•пјҢеҮ д№Һе’ҢDataMapperдёҖжЁЎдёҖж шPјҢеҠҹиғҪйқһеёёејәеӨ§жҳ“з”ЁгҖ?nbsp;
2гҖҒCouchDB
CouchDBзҺ°еңЁжҳҜдёҖдёӘйқһеёёжңүеҗҚж°”зҡ„йЎ№зӣ®пјҢдјйg№ҺдёҚз”ЁеӨҡд»ӢҫlҚдәҶгҖӮдҪҶжҳҜжҲ‘еҚҙеҜ№CouchDBжІЎжңүд»Җд№Ҳе…ҙӯ‘ЈпјҢдё»иҰҒжҳҜеӣ дёәCouchDBд»…д»…жҸҗдҫӣдәҶеҹәдәҺHTTP RESTзҡ„жҺҘеҸЈпјҢеӣ жӯӨCouchDBеҚ•зәҜд»ҺеЖҲеҸ‘иҜ»еҶҷжҖ§иғҪжқҘиҜҙеQҢжҳҜйқһеёёҫpҹзі•зҡ„пјҢҳqҷи®©жҲ‘з«ӢеҲАLҠӣејғдәҶеҜ№CouchDBзҡ„е…ҙӯ‘ЈгҖ?nbsp;
дёүгҖҒж»Ўӯ‘ій«ҳеҸҜжү©еұ•жҖ§е’ҢеҸҜз”ЁжҖ§зҡ„йқўеҗ‘еҲҶеёғејҸи®ЎҪҺ—зҡ„ж•°жҚ®еә“пјҡCassandraеQҢVoldemort
йқўеҗ‘scaleиғҪеҠӣзҡ„ж•°жҚ®еә“е…¶е®һдё»иҰҒи§ЈеҶізҡ„й—®йўҳйўҶеҹҹе’ҢдёҠиҝ°дёӨзұ»ж•°жҚ®еә“иҝҳдёҚеӨӘдёҖж шPјҢе®ғйҰ–е…Ҳеҝ…ҷеАLҳҜдёҖдёӘеҲҶеёғејҸзҡ„ж•°жҚ®еә“ҫpИқ»ҹеQҢз”ұеҲҶеёғеңЁдёҚеҗҢиҠӮзӮ№дёҠйқўзҡ„ж•°жҚ®еә“е…ұеҗҢжһ„жҲҗдёҖдёӘж•°жҚ®еә“жңҚеҠЎҫpИқ»ҹеQҢеЖҲдё”ж №жҚ®иҝҷҝUҚеҲҶеёғејҸжһ¶жһ„жқҘжҸҗдҫӣonlineзҡ„пјҢе…дhңүејТҺҖ§зҡ„еҸҜжү©еұ•иғҪеҠӣпјҢдҫӢеҰӮеҸҜд»ҘдёҚеҒңжңәзҡ„ж·ХdҠ жӣҙеӨҡж•°жҚ®иҠӮзӮ№еQҢеҲ йҷӨж•°жҚ®иҠӮзӮ№зӯүҪ{үгҖӮеӣ жӯӨеғҸCassandraеёёеёёиў«зңӢжҲҗжҳҜдёҖдёӘејҖжәҗзүҲжң¬зҡ„Google BigTableзҡ„жӣҝд»Је“ҒгҖӮCassandraе’ҢVoldemortйғҪжҳҜз”ЁJavaејҖеҸ‘зҡ„еQ?nbsp;
1гҖ?/span>Cassandra
Cassandraҷе№зӣ®жҳҜFacebookең?008тqҙејҖжәҗеҮәжқҘзҡ„еQҢйҡҸеҗҺFacebookиҮӘе·ұдҪҝз”ЁCassandraзҡ„еҸҰеӨ–дёҖдёӘдёҚејҖжәҗзҡ„еҲҶж”ҜеQҢиҖҢејҖжәҗеҮәжқҘзҡ„Cassandraдё»иҰҒиў«Amazonзҡ„DynamiteеӣўйҳҹжқҘз»ҙжҠӨпјҢтq¶дё”Cassandraиў«и®ӨдёәжҳҜDynamite2.0зүҲжң¬гҖӮзӣ®еүҚйҷӨдәҶFacebookд№ӢеӨ–еQҢtwitterе’Ңdigg.comйғҪеңЁдҪҝз”ЁCassandraгҖ?nbsp;
Cassandraзҡ„дё»иҰҒзү№зӮ№е°ұжҳҜе®ғдёҚжҳҜдёҖдёӘж•°жҚ®еә“еQҢиҖҢжҳҜз”ЧғёҖе Ҷж•°жҚ®еә“иҠӮзӮ№е…ұеҗҢжһ„жҲҗзҡ„дёҖдёӘеҲҶеёғејҸҫ|‘з»ңжңҚеҠЎеQҢеҜ№Cassandraзҡ„дёҖдёӘеҶҷж“ҚдҪңеQҢдјҡиў«еӨҚеҲ¶еҲ°е…¶д»–иҠӮзӮ№дёҠеҺ»еQҢеҜ№Cassandraзҡ„иҜ»ж“ҚдҪңеQҢд№ҹдјҡиў«и·Ҝз”ұеҲ°жҹҗдёӘиҠӮзӮ№дёҠйқўеҺ»иҜХdҸ–гҖӮеҜ№дәҺдёҖдёӘCassandraҫҹӨйӣҶжқҘиҜҙеQҢжү©еұ•жҖ§иғҪжҳҜжҜ”иҫғз®ҖеҚ•зҡ„дәӢжғ…еQҢеҸӘҪҺЎеңЁҫҹӨйӣҶйҮҢйқўж·ХdҠ иҠӮзӮ№һ®ұеҸҜд»ҘдәҶгҖӮжҲ‘зңӢеҲ°жңүж–Үз« иҜҙFacebookзҡ„CassandraҫҹӨйӣҶжңүи¶…ҳq?00еҸ°жңҚеҠЎеҷЁжһ„жҲҗзҡ„ж•°жҚ®еә“ҫҹӨйӣҶгҖ?nbsp;
Cassandraд№ҹж”ҜжҢҒжҜ”иҫғдё°еҜҢзҡ„ж•°жҚ®ҫl“жһ„е’ҢеҠҹиғҪејәеӨ§зҡ„жҹҘиҜўиҜӯиЁҖеQҢе’ҢMongoDBжҜ”иҫғҫcЦMјјеQҢжҹҘиҜўеҠҹиғҪжҜ”MongoDBҪEҚејұдёҖдәӣпјҢtwitterзҡ„ег^еҸ°жһ¶жһ„йғЁй—ЁйўҶеҜјEvan WeaverеҶҷдәҶдёҖҪӢҮж–Үз« д»ӢҫlҚCassandraеQ?/span>http://blog.evanweaver.com/articles/2009/07/06/up-and-running-with-cassandra/еQҢжңүйқһеёёиҜҰз»Ҷзҡ„д»ӢҫlҚгҖ?nbsp;
Cassandraд»ҘеҚ•дёӘиҠӮзӮТҺқҘиЎЎйҮҸеQҢе…¶иҠӮзӮ№зҡ„еЖҲеҸ‘иҜ»еҶҷжҖ§иғҪдёҚжҳҜзү№еҲ«еҘҪпјҢжңүж–Үз« иҜҙиҜ„жөӢдёӢжқҘCassandraжҜҸз§’еӨ§зәҰдёҚеҲ°1дёҮж¬ЎиҜХdҶҷиҜдhұӮеQҢжҲ‘д№ҹзңӢеҲоCёҖдәӣеҜ№ҳqҷдёӘй—®йўҳҳqӣиЎҢиҙЁз–‘зҡ„иҜ„и®әпјҢдҪҶжҳҜиҜ„дӯhCassandraеҚ•дёӘиҠӮзӮ№зҡ„жҖ§иғҪжҳҜжІЎжңүж„Ҹд№үзҡ„еQҢзңҹе®һзҡ„еҲҶеёғејҸж•°жҚ®еә“и®үK—®ҫpИқ»ҹеҝ…然жҳҜnеӨҡдёӘиҠӮзӮ№жһ„жҲҗзҡ„зі»ҫlҹпјҢе…¶еЖҲеҸ‘жҖ§иғҪеҸ–еҶідәҺж•ҙдёӘзі»ҫlҹзҡ„иҠӮзӮ№ж•°йҮҸеQҢиө\з”ұж•ҲзҺҮпјҢиҖҢдёҚд»…д»…жҳҜеҚ•иҠӮзӮ№зҡ„еЖҲеҸ‘иҙҹиҪҪиғҪеҠӣгҖ?nbsp;
2гҖ?/span>Voldemort
VoldemortжҳҜдёӘе’ҢCassandraҫcЦMјјзҡ„йқўеҗ‘и§ЈеҶіscaleй—®йўҳзҡ„еҲҶеёғејҸж•°жҚ®еә“зі»ҫlҹпјҢCassandraжқҘиҮӘдәҺFacebookҳqҷдёӘSNSҫ|‘з«ҷеQҢиҖҢVoldemortеҲҷжқҘиҮӘдәҺLinkedinҳqҷдёӘSNSҫ|‘з«ҷгҖӮиҜҙиөдhқҘSNSҫ|‘з«ҷдёәжҲ‘们иөAзҢ®дәҶnеӨҡзҡ„NoSQLж•°жҚ®еә“пјҢдҫӢеҰӮCassandarеQҢVoldemortеQҢTokyo CabinetеQҢFlareҪ{үзӯүгҖӮVoldemortзҡ„иө„ж–ҷдёҚжҳҜеҫҲеӨҡпјҢеӣ жӯӨжҲ‘жІЎжңүзү№еҲ«д»”ҫlҶеҺ»й’Иқ ”еQҢVoldemortе®ҳж–№ҫlҷеҮәVoldemortзҡ„еЖҲеҸ‘иҜ»еҶҷжҖ§иғҪд№ҹеҫҲдёҚй”ҷеQҢжҜҸҝU’и¶…ҳqҮдәҶ1.5дёҮж¬ЎиҜХdҶҷгҖ?nbsp;
д»ҺFacebookејҖеҸ‘CassandraеQҢLinkedinејҖеҸ‘VoldemortеQҢжҲ‘们д№ҹеҸҜд»ҘеӨ§иҮҙзңӢеҮәеӣҪеӨ–еӨ§еһӢSNSҫ|‘з«ҷеҜ№дәҺеҲҶеёғејҸж•°жҚ®еә“еQҢзү№еҲ«жҳҜеҜТҺ•°жҚ®еә“зҡ„scaleиғҪеҠӣж–ҡwқўзҡ„йңҖжұӮжҳҜеӨҡд№ҲҢD·еҲҮгҖӮеүҚйқўжҲ‘еQҲrobbinеQүжҸҗеҲҺНјҢwebеә”з”Ёзҡ„жһ¶жһ„еҪ“дёӯпјҢwebеұӮе’ҢappеұӮзӣёеҜТҺқҘиҜҙйғҪеҫҲе®№жҳ“жЁӘеҗ‘жү©еұ•пјҢе”Ҝжңүж•°жҚ®еә“жҳҜеҚ•зӮ№зҡ„пјҢжһҒйҡҫscaleеQҢзҺ°еңЁFacebookе’ҢLinkedinеңЁйқһе…ізі»еһӢж•°жҚ®еә“зҡ„еҲҶеёғејҸж–ҡwқўжҺўзғҰдәҶдёҖжқЎеҫҲеҘҪзҡ„ж–№еҗ‘еQҢиҝҷд№ҹжҳҜдёЮZ»Җд№ҲзҺ°еңЁCassandraҳqҷд№Ҳзғӯй—Ёзҡ„дё»иҰҒеҺҹеӣ гҖ?nbsp;
еҰӮд»ҠеQҢNoSQLж•°жҚ®еә“жҳҜдёӘдЧoдәәеҫҲе…ҙеҘӢзҡ„йўҶеҹҹпјҢжҖАLҳҜдёҚж–ӯжңүж–°зҡ„жҠҖжңҜж–°зҡ„дс”е“ҒеҶ’еҮәжқҘеQҢж”№еҸҳжҲ‘们已ҫlҸеЕһжҲҗзҡ„еӣәжңүзҡ„жҠҖжңҜи§ӮеҝөпјҢжҲ‘иҮӘе·ұпјҲrobbinеQүзЁҚеҫ®дәҶи§ЈдәҶдёҖдәӣпјҢһ®ұж„ҹи§үиҮӘе·ұж·ұж·Юqҡ„жІүиҝ·ҳqӣеҺ»дәҶпјҢеҸҜд»ҘиҜҙNoSQLж•°жҚ®еә“йўҶеҹҹд№ҹжҳҜеҚҡеӨ§зІҫж·Юqҡ„еQҢжҲ‘еQҲrobbinеQүд№ҹеҸӘиғҪӢ№…е°қиҫ„жӯўеQҢжҲ‘еQҲrobbinеQүеҶҷҳqҷзҜҮж–Үз« ж—ўжҳҜиҮӘе·ұдёҖзӮ№зӮ№й’Иқ ”еҝғеҫ—еQҢд№ҹжҳҜжҠӣз –еј•зҺүпјҢеёҢжңӣеҗёеј•еҜ№иҝҷдёӘйўҶеҹҹжңүҫlҸйӘҢзҡ„жңӢеҸӢжқҘи®Ёи®әе’ҢдәӨӢ№ҒгҖ?nbsp;
д»ҺжҲ‘еQҲrobbinеQүдёӘдәәзҡ„е…ҙи¶ЈжқҘиҜҙеQҢеҲҶеёғејҸж•°жҚ®еә“зі»ҫlҹдёҚжҳҜжҲ‘иғҪе®һйҷ…з”ЁеҲ°зҡ„жҠҖжңҜпјҢеӣ жӯӨдёҚжү“ҪҺ—иҠұж—үҷ—ҙж·ұе…ҘеQҢиҖҢе…¶д»–дёӨдёӘж•°жҚ®йўҶеҹҹпјҲй«ҳжҖ§иғҪNoSQLDBе’Ңж“vйҮҸеӯҳеӮЁNoSQLDBеQүйғҪжҳҜжҲ‘еҫҲж„ҹе…ҙи¶Јзҡ„пјҢзү№еҲ«жҳҜRedisеQҢTT/TCе’ҢMongoDBҳq?дёӘNoSQLж•°жҚ®еә“пјҢеӣ жӯӨжҲ‘жҺҘдёӢжқҘһ®ҶеҶҷдёүзҜҮж–Үз« еҲҶеҲ«иҜҰз»Ҷд»Ӣз»Қҳq?дёӘж•°жҚ®еә“гҖ?/span>