http://www.guao.hk/tag/chrome-extensions
ƒ|ð¡Ó¡Í
°Dropbox ÓÌËÕÍ
ÍÛ¿ð¿Ì¤ÍÊÓð¤ÍQÍð¤¨ð¡§ÿ¥ÍÊÏÓ¤ýÌ₤Ì₤Òƒð¤ð¤Ó¨₤ÍÙÍ´ÓDropbox ð£ËÍGoogleÓgoogle DriveÍ̓ÛÒ§₤ÓSkyDriveÓð¡ð¤Ó¯ð¡ÓÓ¿Ó¿ÍÍÒ§Ð?nbsp;ÍÎð¡ÍQ?br />Read Here:
<Heavy quote>
"What does it even mean when people talk about storing things in the cloud? It sounds so…nebulous. Pun intended. But don't worry, I'm going to break it down for you.
When people talk about "cloud storage," they are talking about putting documents, pictures, and videos online so that they can be stored and accessed whenever you have an online connection. You need this.
Anyone who has ever lost files due to a computer crash will vouch for this. Storage to a hard-drive or physical device is important but you want to back up to the cloud too. And now we have options.
Google and Microsoft both rolled out their own cloud-based storage lockers this week, Google Drive, and Microsoft's SkyDrive. They're both competing with the gold standard of cloud storage, Dropbox.
Let me breakdown the differences.
Dropbox has long been my go-to service and they have really defined the category. It is a simple Web site that lets you upload your documents from any computer or mobile device and access them wherever you can get online. The first 2GB of space is free and for most folks that's plenty. The service integrates flawlessly with Mac and Windows and works seamlessly on your mobile phone too.
Here's a real world example of how I use Dropbox: Mom wants those 50 vacation photos I shot. I upload them to a Dropbox in a folder I call "Vacation Photos". I share the folder with my mom's email and she opens the folder on her computer 900 miles away. It's magic.
Google Drive is similar. It shows a folder on your desktop just like Dropbox but it's integrated with your entire Google experience. You get 5GB of storage for free, which is a pretty good deal, and when you log into Google Documents you'll notice that all your documents, photos, and attachments have become a part of Google Drive.
If you're a heavy Google user than there's no reason you wouldn't want to use Drive plus it's a great supplement to Dropbox. I personally back up all my photos to Google so now it's an easier experience for me.
If you're a dedicated Windows user and you can't live without Office then look no further than Microsoft's SkyDrive. You get more free storage than Google or Dropbox with a nice 7GB and the cost for an upgrade is cheaper too. SkyDrive integrates perfectly with all of your Office documents, spreadsheets, and PowerPoint presentations whether you're at your desktop or on the go.
No more emailing yourself the latest version of your PowerPoint presentation. What a pain! Now you can just save the version you're working on in one place and call it up in another when you're ready to work on it again.
Using each service is a matter of personal preference so pick the one that works for you. Just don't wait for a fire or flood before you start backing up your personal goodies to the cloud. Far too many people learn this lesson the hard way.
</quote end>
Read more: http://www.foxnews.com/scitech/2012/04/28/moving-to-cloud/#ixzz1tiBiDDis
1. Introduction
(Note: There are two versions of this paper -- a longer full version and a shorter printed version. The full version is available on the web and the conference CD-ROM.)The web creates new challenges for information retrieval. The amount of information on the web is growing rapidly, as well as the number of new users inexperienced in the art of web research. People are likely to surf the web using its link graph, often starting with high quality human maintained indices such as Yahoo! or with search engines. Human maintained lists cover popular topics effectively but are subjective, expensive to build and maintain, slow to improve, and cannot cover all esoteric topics. Automated search engines that rely on keyword matching usually return too many low quality matches. To make matters worse, some advertisers attempt to gain people's attention by taking measures meant to mislead automated search engines. We have built a large-scale search engine which addresses many of the problems of existing systems. It makes especially heavy use of the additional structure present in hypertext to provide much higher quality search results. We chose our system name, Google, because it is a common spelling of googol, or 10100 and fits well with our goal of building very large-scale search engines.
1.1 Web Search Engines -- Scaling Up: 1994 - 2000
Search engine technology has had to scale dramatically to keep up with the growth of the web. In 1994, one of the first web search engines, the World Wide Web Worm (WWWW) [McBryan 94] had an index of 110,000 web pages and web accessible documents. As of November, 1997, the top search engines claim to index from 2 million (WebCrawler) to 100 million web documents (from Search Engine Watch). It is foreseeable that by the year 2000, a comprehensive index of the Web will contain over a billion documents. At the same time, the number of queries search engines handle has grown incredibly too. In March and April 1994, the World Wide Web Worm received an average of about 1500 queries per day. In November 1997, Altavista claimed it handled roughly 20 million queries per day. With the increasing number of users on the web, and automated systems which query search engines, it is likely that top search engines will handle hundreds of millions of queries per day by the year 2000. The goal of our system is to address many of the problems, both in quality and scalability, introduced by scaling search engine technology to such extraordinary numbers.1.2. Google: Scaling with the Web
Creating a search engine which scales even to today's web presents many challenges. Fast crawling technology is needed to gather the web documents and keep them up to date. Storage space must be used efficiently to store indices and, optionally, the documents themselves. The indexing system must process hundreds of gigabytes of data efficiently. Queries must be handled quickly, at a rate of hundreds to thousands per second.These tasks are becoming increasingly difficult as the Web grows. However, hardware performance and cost have improved dramatically to partially offset the difficulty. There are, however, several notable exceptions to this progress such as disk seek time and operating system robustness. In designing Google, we have considered both the rate of growth of the Web and technological changes. Google is designed to scale well to extremely large data sets. It makes efficient use of storage space to store the index. Its data structures are optimized for fast and efficient access (see section 4.2). Further, we expect that the cost to index and store text or HTML will eventually decline relative to the amount that will be available (see Appendix B). This will result in favorable scaling properties for centralized systems like Google.
1.3 Design Goals
1.3.1 Improved Search Quality
Our main goal is to improve the quality of web search engines. In 1994, some people believed that a complete search index would make it possible to find anything easily. According to Best of the Web 1994 -- Navigators, "The best navigation service should make it easy to find almost anything on the Web (once all the data is entered)." However, the Web of 1997 is quite different. Anyone who has used a search engine recently, can readily testify that the completeness of the index is not the only factor in the quality of search results. "Junk results" often wash out any results that a user is interested in. In fact, as of November 1997, only one of the top four commercial search engines finds itself (returns its own search page in response to its name in the top ten results). One of the main causes of this problem is that the number of documents in the indices has been increasing by many orders of magnitude, but the user's ability to look at documents has not. People are still only willing to look at the first few tens of results. Because of this, as the collection size grows, we need tools that have very high precision (number of relevant documents returned, say in the top tens of results). Indeed, we want our notion of "relevant" to only include the very best documents since there may be tens of thousands of slightly relevant documents. This very high precision is important even at the expense of recall (the total number of relevant documents the system is able to return). There is quite a bit of recent optimism that the use of more hypertextual information can help improve search and other applications [Marchiori 97] [Spertus 97] [Weiss 96] [Kleinberg 98]. In particular, link structure [Page 98] and link text provide a lot of information for making relevance judgments and quality filtering. Google makes use of both link structure and anchor text (see Sections 2.1 and 2.2).1.3.2 Academic Search Engine Research
Aside from tremendous growth, the Web has also become increasingly commercial over time. In 1993, 1.5% of web servers were on .com domains. This number grew to over 60% in 1997. At the same time, search engines have migrated from the academic domain to the commercial. Up until now most search engine development has gone on at companies with little publication of technical details. This causes search engine technology to remain largely a black art and to be advertising oriented (seeAppendix A). With Google, we have a strong goal to push more development and understanding into the academic realm.Another important design goal was to build systems that reasonable numbers of people can actually use. Usage was important to us because we think some of the most interesting research will involve leveraging the vast amount of usage data that is available from modern web systems. For example, there are many tens of millions of searches performed every day. However, it is very difficult to get this data, mainly because it is considered commercially valuable.
Our final design goal was to build an architecture that can support novel research activities on large-scale web data. To support novel research uses, Google stores all of the actual documents it crawls in compressed form. One of our main goals in designing Google was to set up an environment where other researchers can come in quickly, process large chunks of the web, and produce interesting results that would have been very difficult to produce otherwise. In the short time the system has been up, there have already been several papers using databases generated by Google, and many others are underway. Another goal we have is to set up a Spacelab-like environment where researchers or even students can propose and do interesting experiments on our large-scale web data.
source: http://infolab.stanford.edu/~backrub/google.html
Abstract
In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/
To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date.
Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
I’m very proud of the business that we’ve created here at Mocality, but I’m especially proud of two things:
- Our crowdsourcing program. When we started this business, we knew that (unlike in the UK or US, where you can just kickstart your directory business with a DVD of business data bought from a commercial supplier), if we wanted a comprehensive database of Kenyan business, we would have to build it ourselves. We knew also that if we wanted to build the business quickly, we’d have to engage a lot of Kenyans to help us. So we built our crowd program that utilises M-PESA (Kenya’s ubiquitous Mobile Money system) to reward any Kenyan with a mobile phone who contributes entries to our database, once those entries have been validated by our team. Over two years, we’ve paid out Ksh. 11m (over $100,000) to thousands of individuals, and we have built Kenya’s most comprehensive directory, with over 170,000 verified listings. Personally, I regard the program as one of THE highlights of my 18 year career on the internet.
- From day 1, we aimed to target all Kenyan businesses, irrespective of size. As a result, for about 2/3rds of our listed businesses, Mocality is their first step onto the web. That’s about 100,000 businesses that Mocality has brought online.
Please bear these two facts in mind as you read what follows.
Our database IS our business, and we protect and tend it very carefully. We spot and block automated attacks, amongst other measures. We regularly contact our business owners, to help them keep their records up-to-date, and they are welcome to contact our call centre team for help whenever they need it.
In September, Google launched Getting Kenyan Businesses Online (GKBO). Whilst we saw aspects of their program that were competitive, we welcomed the initiative, as Kenya still has enough growth in it that every new entrant helps the overall market. We are also confident enough in our product, our local team, and our deep local commitment that we believe we can hold our own against any competition, playing fair.
Shortly after that launch, we started receiving some odd calls. One or two business owners were clearly getting confused because they wanted help with their website, and we don’t currently offer websites, only a listing. Initially, we didn’t think much of it, but the confusing calls continued through November.
The Forensic analysis
What follows is necessarily a little technical. I’ve tried to make it as clear as I can, but two definitions may help the lay reader:
- IP Address – the numerical id by which computers identify themselves online.
- User-Agent - When a browser requests a page from a webserver, it tells the server what make, model, and version of browser it is, so that the webserver can serve content tailored to that browser’s capabilities. Webservers keep a log of both these details for every page requested, allowing us to do interesting detective work.
Conclusion
Since October, Google’s GKBO appears to have been systematically accessing Mocality’s database and attempting to sell their competing product to our business owners. They have been telling untruths about their relationship with us, and about our business practices, in order to do so. As of January 11th, nearly 30% of our database has apparently been contacted.
Furthermore, they now seem to have outsourced this operation from Kenya to India.
When we started this investigation, I thought that we’d catch a rogue call-centre employee, point out to Google that they were violating our Terms and conditions (sections 9.12 and 9.17, amongst others), someone would get a slap on the wrist, and life would continue.
I did not expect to find a human-powered, systematic, months-long, fraudulent (falsely claiming to be collaborating with us, and worse) attempt to undermine our business, being perpetrated from call centres on 2 continents.
Google is a key part of our business strategy. Mocality will succeed if our member businesses are discoverable by people via Google. We actually track how well our businesses place on Google as a key metric, and have always regarded it as a symbiotic relationship. We are in the business of creating local Kenyan content that Google can sell their adwords against. More than 50% of our non-direct traffic comes via Google (paid or organic). For us, the cost of going elsewhere is NOT zero.
Furthermore, we spend a very significant sum on advertising with Google Kenya. I wouldn’t be surprised if we are one of their largest local customers, between Mocality and our sister site Dealfish.co.ke.
Kenya has a comparatively well-educated but poor population and high levels of unemployment. Mocality designed our crowd sourcing program to provide an opportunity for large numbers of people to help themselves by helping us. By apparently systematically trawling our database, and then outsourcing that trawl to another continent, Google isn’t just scalping us, they’re also scalping every Kenyan who has participated in our program.
I moved to Africa from the UK 30 months ago to be CEO of Mocality. When I moved, Kenya’s reputation as a corrupt place to do business made me nervous. I’ve been very happily surprised- until this point, I’ve not done business with any company here that was not completely honestly conducted. It is important for global businesses to adapt to local cultural practice, but ethics are an invariant. As a admirer of Google’s usually bold ethical stance around the world, to find those principles are not applied in Kenya is simply… saddening.
Someone, somewhere, has some questions to answer.
These are my personal top 3:
- If Google wanted to work with our data, why didn’t they just ask?
In discussions with various Google Kenya/Africa folks in the past, I’d raised the idea of working together more closely in Kenya. Getting Kenyan businesses online is precisely what we do. - Who authorised this? Until we uncovered the ‘India by way of Mountain View’ angle, I could have believed that this was a local team that somehow forgot the corporate motto, but not now.
- Who knew, and who SHOULD have known, even if they didn’t know?
read full here:
Search Engine Optimization is growing up. I am not ready to say the Wild West SEO days are completely eradicated, but in 2011 good search engine optimization is less about trickery and more about engaging content and audience development than ever before.
Over the years, quality optimizers have become more prone to avoid technical tricks like using CSS image replacement to inject keyword text or controlling the flow of PageRank by hiding links from search engines.
Search engines keep getting better at crawling and indexing. If you are unwilling to burn your website or risk your career, you follow the search engines’ terms of service.
During 2011 the conservative attitude toward code crossed chasm to apply to content. For years, websites churned-out poorly written, generic articles in the name of long-tail keyword optimization. It worked so well some people turned crappy content into startups.
Now, thanks to Panda, Google’s site-wide penalty for having too much low quality content, people are asking why anyone would put pages on a website that no one wants to read, share or link to? Without taking potshots at the past, most of those articles look juvenile and antiquated.
Made in Japan went from signifying cheap to marvelous. Made for the Web is growing-up too. It is this evolution which guides my SEO highlights for 2012. I separate things to keep in mind by code, design and content.
Code – Keep It Simple
While Google likes to tell us they are very good at crawling and understanding imperfect code, I prefer to assume search engines are dumb and help them every way I can. Simple code is honest code. It’s also easy to parse and analyze. Just because you can AJAX-up a page with accordions and fly-outs does not mean you should. The more code on a page, the more things that can go wrong from spider access to browser compatibility.
Follow standards and get as close to validated markup as reasonably possible. Make it easy for search engines to spider your site. Validating HTML and CSS does not automagically raise your rankings, but it will prevent crawl errors.
At the same time, don’t insist on validation since some perfectly good code will never validate. Follow search engine recommendations to Make AJAX, XML and Other Code Crawl able.
Make your CSS class and ID names obvious, especially for section div tags. Again, Google tells us they have gotten good at identifying headers, sidebars and footers. Part of that is almost assuredly knowing the most common div names.
- Make it easy on Google and Bing by naming your header div header.
- Name the CSS ID of your right sidebar div right-sidebar.
Why would you name a CSS Class xbr_001 when you can name it navigation? At the very least, it will make life a lot easier on your SEO team. They have enough work without the need to translate ambiguous naming structures.
Reserve h# tags for outlining principal content. I am amazed at the number of big brand websites that still use h# tags for font design. Tell your designers that h1, h2, h3, h4, h5 and h6 are off-limits and reserved for content writers and editors.
The only exception to this should be if your content management system uses h1 tags to create a proper headline. Embargo h# tags out of your headers, navigation, sidebars and footers too. They don’t belong there.
Web Design – Less Navigation Is More
Look at the Zen like efficiency of any Apple product. Steve Jobs was ruthless about eliminating the unnecessary and achieving clean Bauhaus efficiency.
By contrast, too many websites, especially enterprise sites, try to be all things to all people. Their administrators or managers fear they might miss out on a conversion for lack of a link.
Websites should have clean vertical internal linking. Every page should not link to every page. You do not need a site-wide menu three levels deep. As long as people feel that they are progressing toward their goal or the useful information they seek, they will click on two, three or four links to get there.
Look at your website analytics. Which pages receive the fewest visits? Are any in your navigation? If no one uses a link, why does it to be there?
A website’s most widely visited pages tend to be close to the homepage. Review your categories and sub-categories. Can you eliminate whole categories by merging or reassigning content? For example, does the management team need its own category or can you move it into the About section?
This is not just about eliminating distraction. It is a way to increase the internal flow of authority (PageRank, link juice, etc.) to SEO hub pages.
Content – Engagement & Agility
Emphasize Community and Conversation. If your business depends on the Internet and you have the budget to hire one more person, consider employing a community evangelist. High rankings require authority. Authority comes from off-site links and, to an extent, brand mentions.
Earning enough links to make a dent in your SEO requires a continuous stream of link worthy content combined with forging and fostering relationships with people who create links or influence lots of others through online conversation. This requires a large commitment of time to work with writers and designers and to network. Even when decentralized, this rarely works without a strong empowered leader.
Get out of the sales funnel. The people you want to buy your products or services are not going to blog about your company or mention it on Twitter. More likely, they are peers.
A good exercise to undertake is ask each employee, if they could pick one professional conference to attend, what would it be? Then look for the session speakers on Twitter, LinkedIn and Facebook. Find which ones are active online and gauge their influence. Are people in your company qualified to write authoritatively about these topics or speak at conferences?
This is how to find content topics for the post-Panda Web, things people want to converse about and link to. For example, if you have a cutting-edge API team, an API development blog could be the key to higher domain authority.
Understand Social Technographics. It will help you to find influencers and create content that people will want to link to and talk about.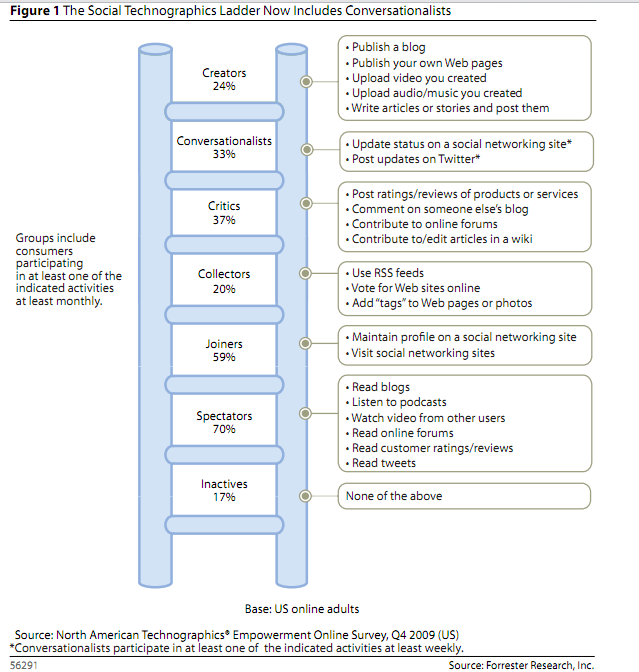
Embrace Agility
Realign your content generation and approval process so you can create near-daily web content and, if necessary, respond publically to something within an hour.
With Query Deserves Freshness, trending topics, news search and simply because of how social media conversations come and go, agility is important for getting noticed and getting links.
Update Your Content
If your website has older articles that read like Wikipedia or a hardcover World Book Encyclopedia, swap out old content for new. In the future, Panda will not get leaner, it will get meaner. If you have reason to worry, start fixing it now. Do not wait and hope Panda will not see your low quality content. I want to be very clear here:
- If you have decent quality content that provides real value, keep it whether it is SEO optimized or not. Yes, get to work optimizing older content doing things like selecting hub pages, optimizing text and cross-linking. But do not delete your old content.
- If you have content that seems overtly advertorial, is cheesy or reads robotic because it is so stuffed with keywords, begin the process of writing one-for-one replacements and update your old content over time. For the old-time SEOs out there, this brings new meaning to a page a day.
- If you have been hit by Panda already, I suggest removing your poor quality content, set-up 301 redirects to salvage the link authority, then begin rebuilding with high quality, link worthy content. Panda is a site-wide penalty. It is not going to go away until the offending content is removed or replaced.
Those are my 2012 SEO playbook highlights. In the past, content creation and link building were too separated. We had writers covering every long-tail key phrase possible while, in another room, link ninjas emailed and telephoned soliciting for individual links.
That model is becoming less and less sustainable. The Web is too big. Too many people contribute content. Social media offers an entirely new world of context. Today, SEO means finding an audience you can connect with, become a part of the community, give them insanely awesome content and reciprocate. This is the new SEO arms race.
Read source:
http://www.linklicious.me
read
tojoin