]]>
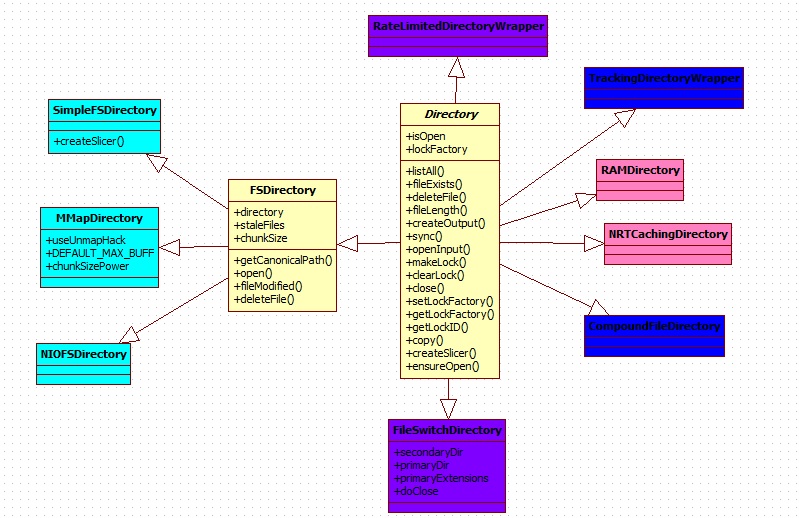
一:文件目錄
SimpleFSDirectory:FSDirectory的簡單實現,并發能力有限,遇到多線程讀同一個文件時會遇到瓶頸,通常用NIOFSDirectory或MMapDirectory代替。
NIOFSDirectory:通過java.nio's FileChannel實行定位讀取,支持多線程讀(默認情況下是線程安全的)。該類僅使用FileChannel進行讀操作,寫操作則是通過FSIndexOutput實現。
注意:NIOFSDirectory 不適用于Windows系統,另外如果一個訪問該類的線程,在IO阻塞時被interrupt或cancel,將會導致底層的文件描述符被關閉,后續的線程再次訪問NIOFSDirectory時將會出現ClosedChannelException異常,此種情況應用SimpleFSDirectory代替。
MMapDirectory:通過內存映射進行讀,通過FSIndexOutput進行寫的FSDirectory實現類。使用該類時要保證用足夠的虛擬地址空間。另外當通過IndexInput的close方法進行關閉時并不會立即關閉底層的文件句柄,只有GC進行資源回收時才會關閉。
為了能適應各個操作系統選擇最佳Directory方案,lucene 提供FSDirectory類的靜態方法open()實現自適應。
public static FSDirectory open(File path, LockFactory lockFactory) throws IOException {
if ((Constants.WINDOWS || Constants.SUN_OS || Constants.LINUX)
&& Constants.JRE_IS_64BIT && MMapDirectory.UNMAP_SUPPORTED) {
return new MMapDirectory(path, lockFactory);
} else if (Constants.WINDOWS) {
return new SimpleFSDirectory(path, lockFactory);
} else {
return new NIOFSDirectory(path, lockFactory);
}
}
二:內存目錄
RAMDirectory:常駐內存的Directory實現方式。默認通過SingleInstanceLockFactory(單實例鎖工廠)進行鎖的實現。該類不適合大量索引的情況。另外也不適用于多線程的情況。 在索引數據量大的情況下建議使用MMapDirectory代替。RAMDirectory是Directory抽象類在使用內存最為文件存儲的實現類,其主要是將所有的索引文件保存到內存中。這樣可以提高效率。但是如果索引文件過大的話,則會導致內存不足,因此,小型的系統推薦使用,如果大型的,索引文件達到G級別上,推薦使用FSDirectory。
NRTCachingDirectory:是對RAMDirectory的封裝,適用于近乎時時(near-real-time)操作的環境。
三:Direcotry的代理類及工具類
FileSwitchDirectory:文件切換的Directory實現.針對lucene的不同的索引文件使用不同的Directory .借助FileSwitchDirectory整合不同的Directory實現類的優點于一身
比如MMapDirectory,借助內存映射文件方式提高性能,但又要減少內存切換的可能 ,當索引太大的時候,內存映射也需要不斷地切換,這樣優點也可能變缺點,而之前的NIOFSDirectory實現java NIO的方式提高高并發性能,但又因高并發也會導致IO過多的影響,所以這次可以借助FileSwitchDirectory發揮他們兩的優點。
RateLimitedDirectoryWrapper:通過IOContext來限制讀寫速率的Directory封裝類。
CompoundFileDirectory:用于訪問一個組合的數據流。僅適用于讀操作。對于同一段內擴展名不同但文件名相同的所有文件合并到一個統一的.cfs文件和一個對應的.cfe文件內。
.cfs文件由Header,FileData和FileCount組成。.cfe文件由Header,FileCount,FileName,DataOffset,DataLength組成。.cfs文件中存儲著索引的概要信息及組合文件
的數目(FileCount)。.cfe文件存儲文件目錄的條目內容,內容中包括文件數據扇區的起始位置,文件的長度及文件的名稱。
TrackingDirectoryWrapper:Directory的代理類。用于記錄哪些文件被寫入和刪除。
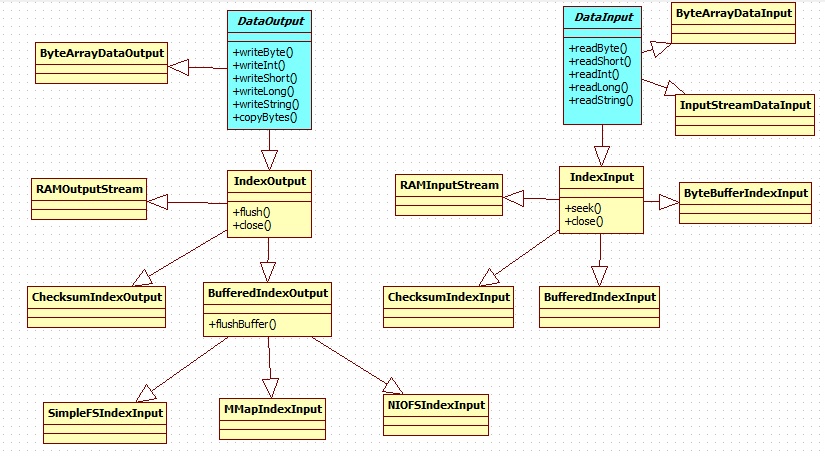
四:Direcotry讀寫對象的類圖
文章轉載過來的!
]]>
本機已經安裝了jdk1.6,而比較早期的項目需要依賴jdk1.5,于是同時在本機安裝了jdk1.5和jdk1.6.
安裝jdk1.5前,執行java -version得到
java version "1.6.0_38"
Java(TM) SE Runtime Environment (build 1.6.0_38-b05)
Java HotSpot(TM) 64-Bit Server VM (build 20.13-b02, mixed mode)
安裝完jdk1.5,并修改環境變量JAVA_HOME為D:\devSoftware\jdk1.5.再執行 java -version時,依然顯示:
java version "1.6.0_38"
Java(TM) SE Runtime Environment (build 1.6.0_38-b05)
Java HotSpot(TM) 64-Bit Server VM (build 20.13-b02, mixed mode)
看上去,新的環境變量JAVA_HOME=D:\devSoftware\jdk1.5并沒有生效。 在網上找了很多資料才發現:
在安裝JDK1.6時(本機先安裝jdk1.6再安裝的jdk1.5),自動將java.exe、javaw.exe、javaws.exe三個可執行文件復制到了C:\Windows\System32目錄,由于這個目錄在WINDOWS環境變量中的優先級高于JAVA_HOME設置的環境變量優先級
解決方案:將java.exe,javaw.exe,javaws.exe刪除即可。開啟新的命令行窗口,再執行java -version時,就得到了期望中的結果
java version "1.5.0_17"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_17-b04)
Java HotSpot(TM) 64-Bit Server VM (build 1.5.0_17-b04, mixed mode)
]]>
在2013年底公司接到一個項目用到lucene,這是我第一次正真接觸Lucene,代碼比較老3.6版本,不適合新項目的需求(空間查詢)。于是下載了最新版本 4.51,有帶“空間查詢”模塊。各大搜索引擎都沒有找到像樣例子,于是想到了lucene svn的 trunk目錄測試用例中找到了測試例子,開始了一段lucene之旅。
寫數據,創建IndexWriter,通過它的構造函數需要一個索引目錄(Diectory)和索引寫入配置項(InderWriterConfig),直接上代碼:
//設置寫入目錄(好幾種呵呵)
Directory d=FSDirectory.open(new File("D:/luceneTest"));
//設置分詞 StandardAnalyzer(會把句子中的字單個分詞)
Analyzer analyzer= new StandardAnalyzer(Version.LUCENE_45);
//設置索引寫入配置
IndexWriterConfig config=new IndexWriterConfig(Version.LUCENE_45,analyzer);
//設置創建模式
//config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
IndexWriter indexwriter= new IndexWriter(d,config);
上面四行代碼就創建好了indexwriter,下面把數據填入就好了,寫入有多種方式如下圖:

用 addDocment 舉例代碼如下:
Document doc=new Document();
doc.add(new StringField("id", "1", Store.YES));
doc.add(new StringField("name", "brockhong", Store.YES));
doc.add(new TextField("content", "lucene 文檔第一次寫看著給分吧", Store.YES));
//寫入數據
indexwriter.addDocument(doc);
//提交
indexwriter.commit();
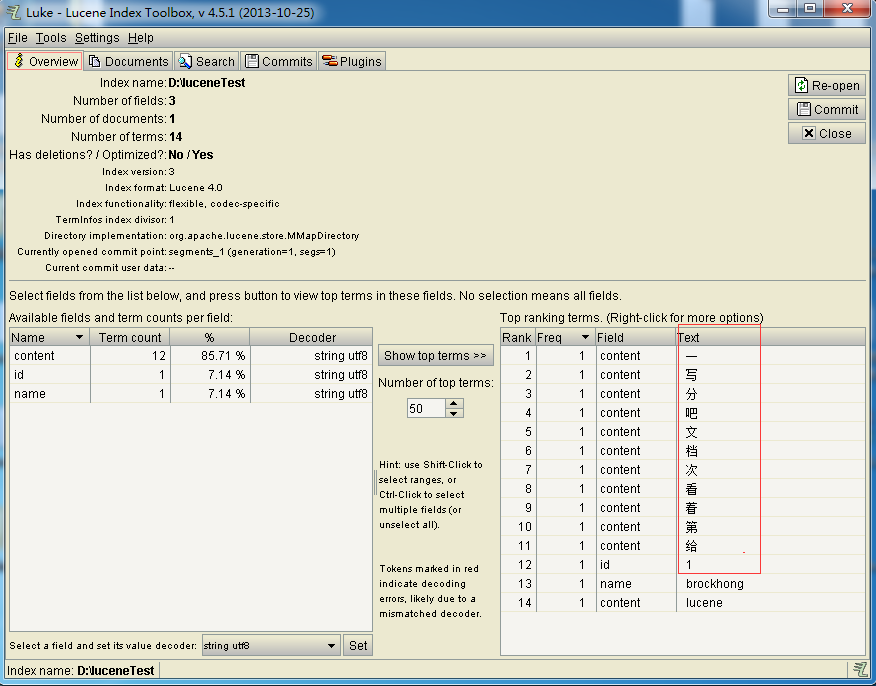
用 Luke 工具查看Text列,這是標準分詞惹的禍哦!寫入成功。
讀數據查詢,創建 IndexSearcher 構造函數設置indexReader ,輸入查詢條件,上面content字段數據設置了分詞,所以必須通過查詢解析類QueryParser設定分詞字段、版本、分詞模式,并通過parse方法得到查詢條件。代碼如下:
//讀數據
//創建 indexReader 這個已過時 IndexReader.open(d),里面的代碼一樣可能為了兼容老版本
IndexReader indexReader = DirectoryReader.open(d);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//查詢 設置分詞字段
QueryParser queryParser = new QueryParser(Version.LUCENE_45, "content",
new StandardAnalyzer(Version.LUCENE_45));
//or 關系 “給”、“分”
queryParser.setDefaultOperator(QueryParser.OR_OPERATOR);
Query query = queryParser.parse("給分");
TopDocs results = indexSearcher.search(query, 100);
int numTotalHits = results.totalHits;
System.out.println("共 " + numTotalHits + " 完全匹配的文檔");
ScoreDoc[] hits = results.scoreDocs;
for (int i = 0; i < hits.length; i++) {
Document document = indexSearcher.doc(hits[i].doc);
System.out.println("content:" + document.get("content"));
}
]]>
使用SAXReader的read(File file)方法時,如果xml文件異常會導致文件被服務器占用不能移動文件,建議不使用read(File file)方法而使用read(FileInputStream fis)等流的方式讀取文件,異常時關閉流,這樣就不會造成流未關閉,文件被鎖的現象了。(在服務器中運行時會鎖住文件,main方法卻不會)。
1、以下方式xml文件異常時會導致文件被鎖
- Document document = null;
- File file = new File(xmlFilePath);
- SAXReader saxReader = new SAXReader();
- try
- {
- document = saxReader.read(file);
- } catch (DocumentException e)
- {
- logger.error("將文件[" + xmlFilePath + "]轉換成Document異常", e);
- }
2、以下方式xml文件異常時不會鎖文件(也可以使用其他的流來讀文件)
- Document document = null;
- FileInputStream fis = null;
- try
- {
- fis = new FileInputStream(xmlFilePath);
- SAXReader reader = new SAXReader();
- document = reader.read(fis);
- }
- catch (Exception e)
- {
- logger.error("將文件[" + xmlFilePath + "]轉換成Document異常", e);
- }
- finally
- {
- if(fis != null)
- {
- try
- {
- fis.close();
- } catch (IOException e)
- {
- logger.error("將文件[" + xmlFilePath + "]轉換成Document,輸入流關閉異常", e);
- }
- }
- }
]]>
]]>
CGCS2000_3_Degree_GK_Zone_40
WKID: 4528 Authority: EPSG
Projection: Gauss_Kruger
False_Easting: 40500000.0
False_Northing: 0.0
Central_Meridian: 120.0
Scale_Factor: 1.0
Latitude_Of_Origin: 0.0
Linear Unit: Meter (1.0)
Geographic Coordinate System: GCS_China_Geodetic_Coordinate_System_2000
Angular Unit: Degree (0.0174532925199433)
Prime Meridian: Greenwich (0.0)
Datum: D_China_2000
Spheroid: CGCS2000
Semimajor Axis: 6378137.0
Semiminor Axis: 6356752.314140356
Inverse Flattening: 298.257222101
Java 自定義
經緯度轉換
///+proj=tmerc +lat_0=0 +lon_0=120 +k=1 +x_0=40500000 +y_0=0 +ellps=GRS80 +units=m +no_defs
Point2D.Double srcProjec = null;
Point2D.Double dstProjec = null;
Projection proj = ProjectionFactory.fromPROJ4Specification (proj4_w);
// "epsg:4528" 數據從proj4 拷貝 nad
// Point2D.Double srcProjec = null;
// Point2D.Double dstProjec = null;
// Projection proj = ProjectionFactory.getNamedPROJ4CoordinateSystem ("epsg:4528");
srcProjec = new Point2D.Double (120.159,30.267);
//40515348.2903 3349745.5395
dstProjec = proj.transform (srcProjec, new Point2D.Double ());
System.out.println ("TM:" + dstProjec);
// TM: Point2D.Double [644904.399587292, 400717.8948938238]
srcProjec = new Point2D.Double (40515348.2903 ,3349745.5395);
dstProjec = proj.inverseTransform (srcProjec, new Point2D.Double ());
System.out.println ("TM:" + dstProjec);
]]>
ORA-01033:ORACLEinitialization or shutdown in progress
解決方法
1)開始-運行-cmd
2)命令行中輸入SQLPLUS SYS/SYS AS SYSDBA
3)輸入SHUTDOWN
4)輸入STARTUP.注意這里是最重要的地方,在顯示相關數據后,它還會顯示為什么不能啟動的錯誤所在.
C:\Users\lenovo>SQLPLUSSYS/SYS AS SYSDBA
SQL*Plus: Release 10.2.0.3.0 - Production on星期三 7月 3 11:43:32 2013
Copyright (c) 1982, 2006, Oracle. All Rights Reserved.
連接到:
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 -Production
With the Partitioning, OLAPand Data Mining options
SQL> SHUTDOWN
ORA-01109:數據庫未打開
已經卸載數據庫。
ORACLE例程已經關閉。
SQL> STARTUP
ORACLE例程已經啟動。
Total System Global Area 293601280 bytes
Fixed Size 1290208 bytes
Variable Size 234881056 bytes
Database Buffers 50331648 bytes
Redo Buffers 7098368 bytes
數據庫裝載完畢。
ORA-01157:無法標識/鎖定數據文件 6 - 請參閱 DBWR 跟蹤文件
ORA-01110:數據文件 6: 'F:\DC\DB\SDRS\TS_SDRS.DBF'
SQL> alter databasedatafile'F:\DC\DB\SDRS\TS_SDRS.DBF'offline drop;
數據庫已更改。
SQL> alter database open;
數據庫已更改。
SQL> drop tablespaceTS_SDRS including contents;
表空間已刪除。
SQL> create undo tablespace TS_SDRS
2 datafile'CracleoradatasmsdbUNDOTBS01.DBF'size 2048M extent management local;
表空間已創建。
SQL> alter system setundo_tablespace=TS_SDRS;
系統已更改。
SQL> shutdown
數據庫已經關閉。
已經卸載數據庫。
ORACLE例程已經關閉。
SQL> startup
ORACLE例程已經啟動。
Total System Global Area 293601280 bytes
Fixed Size 1290208 bytes
Variable Size 243269664 bytes
Database Buffers 41943040 bytes
Redo Buffers 7098368 bytes
數據庫裝載完畢。
數據庫已經打開。
SQL>
------------------
ORA-01245、ORA-01547錯誤的解決
數據庫rman restore database 之后,執行recover database的時候,報告ORA-01245錯誤,詳細的錯誤信息如下:
SQL> recover database until cancel; ORA-00279: change 575876 generated at 12/01/2009 08:19:49 needed for thread 1 ORA-00289: suggestion : /oracle/flash_recovery_area/ORCL/archivelog/2009_12_01/o1_mf_1_2_%u_.arc ORA-00280: change 575876 for thread 1 is in sequence #2 Specify log: { auto ORA-00308: cannot open archived log '/oracle/flash_recovery_area/ORCL/archivelog/2009_12_01/o1_mf_1_2_%u_.arc' ORA-27037: unable to obtain file status Linux Error: 2: No such file or directory Additional information: 3 ORA-00308: cannot open archived log '/oracle/flash_recovery_area/ORCL/archivelog/2009_12_01/o1_mf_1_2_%u_.arc' ORA-27037: unable to obtain file status Linux Error: 2: No such file or directory Additional information: 3 ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below ORA-01245: offline file 2 will be lost if RESETLOGS is done ORA-01110: data file 2: '/oracle/oradata/orcl/undotbs01.dbf' SQL> |
[@more@]
檢查ORA-01245那一行,發現是datafile 2狀態為offline,解決的方法就是首先將datafile 2 online,然后再recover database。
| SQL> alter database datafile 2 online; Database altered. SQL> recover database until cancel; ORA-00279: change 575876 generated at 12/01/2009 08:19:49 needed for thread 1 ORA-00289: suggestion : /oracle/flash_recovery_area/ORCL/archivelog/2009_12_01/o1_mf_1_2_%u_.arc ORA-00280: change 575876 for thread 1 is in sequence #2 Specify log: { cancel Media recovery cancelled. SQL> alter database open resetlogs; Database altered. SQL> |
--------------------
ORA-01589: 要打開數據庫則必須使用 RESETLOGS 或 NOR
ORA-01589: 要打開數據庫則必須使用 RESETLOGS 或 NORESETLOGS
選項
SQL> alter database open
ORA-01589: 要打開數據庫則必須使用 RESETLOGS 或
NORESETLOGS 選項
SQL> alter database open resetlogs;
alter database
open resetlogs
*
ERROR 位于第 1 行:
ORA-01113: 文件 1 需要介質恢復
ORA-01110:
數據文件 1: 'E:\ORACLE\ORADATA\EYGLE\SYSTEM01.DBF'
SQL> recover database
using backup controlfile;
ORA-00279: 更改 1670743 (在 04/17/2008 14:13:16 生成)
對于線程 1 是必需的
ORA-00289: 建議: E:\ORACLE\ORA92\RDBMS\ARC00030.001
ORA-00280:
更改 1670743 對于線程 1 是按序列 # 30 進行的
指定日志: {<RET>=suggested | filename |
AUTO | CANCEL}
E:\oracle\oradata\EYGLE\REDO01.LOG
ORA-00310: 存檔日志包含序列
29;要求序列 30
ORA-00334: 歸檔日志:
'E:\ORACLE\ORADATA\EYGLE\REDO01.LOG'
SQL> recover database using
backup controlfile;
ORA-00279: 更改 1670743 (在 04/17/2008 14:13:16 生成) 對于線程 1
是必需的
ORA-00289: 建議: E:\ORACLE\ORA92\RDBMS\ARC00030.001
ORA-00280: 更改
1670743 對于線程 1 是按序列 # 30 進行的
指定日志: {<RET>=suggested | filename |
AUTO |
CANCEL}
E:\oracle\oradata\EYGLE\REDO02.LOG
已應用的日志。
完成介質恢復。
SQL>
alter database open resetlogs;
數據庫已更改。
OK,搞定了!
]]>
1.正則表達式字符串問題
首先輸入的regex是一個正則表達式,而不是一個普通的字符串,所以導致很多在正則表達式里面有特殊意義的比如 "." "|" "\" ,如果直接使用是不行的,另外一個方面我們輸入的regex是以字符串形式傳遞的,對有些字符必須要轉義,尤其是"\",下面請看例子
String[] aa = "aaa|bbb|ccc".split("|");//wrong
String[] aa = "aaa|bbb|ccc".split("\\|"); //
String[] aa = "aaa*bbb*ccc".split("*");//wrong
String[] aa = "aaa|bbb|ccc".split("\\*");
String[] aa = "aaa*bbb*ccc".split(".");//wrong
String[] aa = "aaa|bbb|ccc".split("\\.");
String[] aa = "aaa\\bbb\\bccc".split("\\");//wrong
String[] aa = "aaa\\bbb\\bccc".split("\\\\");
2.數組長度的問題
String a = "";
String[] b = a.split(",");
b.length為 1;
*
String a = "c";
String[] b = a.split(",");
b.length為 1;
**
String a = "c,,,";
String[] b = a.split(",");
b.length為 1;
***
String a = "c,,c";
String[] b = a.split(",");
b.length為 3;
****
String a = ",";
String[] b = a.split(",");
b.length為 0;
其實只要添加一個參數即可,例如
String str = "abcdef,ghijk,lmno,pqrst,,,";
String[] array = str.split(",");
輸出:abcdef,ghijk,lmno,pqrst,
String str = "abcdef,ghijk,lmno,pqrst,,,";
String[] array = str.split(",",-1);
輸出:abcdef,ghijk,lmno,pqrst,,,,
public String [] split (String regex, int limit)
最后一個參數limit是影響返回數組的長度的
=========================請關注紅色字體(括號內為注釋)==========================================
public String[] split(String regex)
- 根據給定的正則表達式的匹配來拆分此字符串。
該方法的作用就像是使用給定的表達式和限制參數 0 來調用兩參數
split方法。因此,結果數組中不包括結尾空字符串(直接使用會造成數組大小問題)。例如,字符串 "boo:and:foo" 產生帶有下面這些表達式的結果:
Regex 結果 : { "boo", "and", "foo" } o { "b", "", ":and:f" } - 參數:
regex- 定界正則表達式- 返回:
- 字符串數組,根據給定正則表達式的匹配來拆分此字符串,從而生成此數組。
public String[] split(String regex,
int limit)
- 根據匹配給定的正則表達式來拆分此字符串。
此方法返回的數組包含此字符串的每個子字符串,這些子字符串由另一個匹配給定的表達式的子字符串終止或由字符串結束來終止。數組中的子字符串按它們在此字符串中的順序排列。如果表達式不匹配輸入的任何部分,則結果數組只具有一個元素,即此字符串。
limit 參數控制模式應用的次數,因此影響結果數組的長度。如果該限制 n 大于 0,則模式將被最多應用 n - 1 次,數組的長度將不會大于 n,而且數組的最后項將包含超出最后匹配的定界符的所有輸入。如果 n 為非正,則模式將被應用盡可能多的次數,而且數組可以是任意長度。如果 n 為零,則模式將被應用盡可能多的次數,數組可有任何長度,并且結尾空字符串將被丟棄。
例如,字符串 "boo:and:foo" 使用這些參數可生成下列結果:
Regex Limit 結果 : 2 { "boo", "and:foo" } : 5 { "boo", "and", "foo" } : -2 { "boo", "and", "foo" } o 5 { "b", "", ":and:f", "", "" } o -2 { "b", "", ":and:f", "", "" } o 0 { "b", "", ":and:f" } 這種形式的方法調用 str.split(regex, n) 產生與以下表達式完全相同的結果:
Pattern.compile(regex).split(str, n) - 參數:
regex- 定界正則表達式limit- 結果閾值,如上所述- 返回:
- 字符串數組,根據給定正則表達式的匹配來拆分此字符串,從而生成此數組
]]>
while (true) {
l.add(Calendar.getInstance());
System.out.println(l.size());
}
605473
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Calendar.<init>(Unknown Source)
at java.util.GregorianCalendar.<init>(Unknown Source)
at java.util.Calendar.createCalendar(Unknown Source)
at java.util.Calendar.getInstance(Unknown Source)
at jodatestmemory.Main.main(Main.java:25)
]]>