1> 通过此语句查询正在锁定的SESSION_ID:
 SELECT SESSION_ID FROM V$LOCKED_OBJECT,USER_OBJECTS WHERE V$LOCKED_OBJECT.OBJECT_ID = USER_OBJECTS.OBJECT_ID
SELECT SESSION_ID FROM V$LOCKED_OBJECT,USER_OBJECTS WHERE V$LOCKED_OBJECT.OBJECT_ID = USER_OBJECTS.OBJECT_ID
2> ÈÄöËøáΩW¨‰∏ÄÊ≠•Êü•ËØ¢Âà∞ÁöÑSESSION_IDÊü•ËØ¢SERIAL#
SELECT SERIAL# FROM V$SESSION WHERE SID='12'(Ê≠§Â§Ñ'12'‰∏ÞZ∏äÈù¢Êü•ËØ¢Âà∞Áö?/span>'SESSION_ID')
3> ÊÝ“é(gu®©)çÆ1,2Ê≠•Êü•ËØ¢Âà∞ÁöÑSESSION_IDÂíåSERIAL#ÊâßË°å
ALTER SYSTEM KILL SESSION '12,154'(12‰∏∫SESSION_IDÁöÑÂÄ? 154‰∏∫SERIAL#ÁöÑÂÄ?4> ¶ÇÊûúÂà©Á∏äÈù¢ÁöÑÂëΩ‰ª§ÊùÄÊ≠÷M∏ĉ∏™ËøõΩEãÂêéÂQåËøõΩEãÁä∂ÊÄÅË¢´æ|Ɖÿì(f®¥)"killed"ÂQå‰ΩÜÊòØÈîÅÂÆöÁöÑ˵ÑÊ∫êÂæàÈïøÊóâôó¥Ê≤°ÊúâË¢´ÈáäÊîæÔºåÈÇ£‰πàòqòÂè؉ª•Âú®os‰∏ÄæUßÂÜçÊùÄÊ≠»ùõ∏Â∫îÁöÑòqõÁ®ã(æUøÁ®ã)ÂQåȶñÂÖàÊâßË°å‰∏ãÈù¢ÁöÑËØ≠Âè•Ëé∑ÂæóÂΩìÂâçòqõÁ®ã(æUøÁ®ã)ÁöÑÊÝáΩC∫PIDÂQ?br />
select spid, osuser, s.program 2
from v$session s,v$process p3
where s.paddr=p.addr and s.sid=12 (12Êò؉∏äÈù¢ÁöÑSESSION_ID)ÁÑ∂ÂêéÂú®OSÈÄöËøቪ’dä°Ωé°ÁêÜÂô®ÊâæÂà∞ÂØπÂ∫îÁöÑòqõÁ®ãÂQåÂú®ÊùÄÊ≠ªËøô‰∏™ËøõΩE?æUøÁ®ã)
‰ª•‰∏ãËΩ؉ögãπãËØïÁéØ¢ɉ∏∫Spring,Struts1
1„ÄÅÈÄöËøástruts1Êèê‰æõÁöÑÊè퉪∂Êú∫Âà”ûºåÈááÁî®SpringÊèê‰æõÁöÑContextLoaderPlugIn
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE struts-config PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 1.2//EN" "http://struts.apache.org/dtds/struts-config_1_2.dtd">
<struts-config>
<global-exceptions />
<global-forwards />
<message-resources parameter="com.portal.ApplicationResources" />
<!-- ÈÄöËøáS1Êèê‰æõÁöÑÊè퉪∂Êú∫Âà∂Êù•ÂàùÂßãÂåñSpringÂÆπÂô®ÂQåÂäÝËΩΩSpringÈÖçÁΩÆÊñá‰ög
<plug-in
className="org.springframework.web.struts.ContextLoaderPlugIn">
<!--
1„ÄÅContextLoaderPlugInȪòËƧÂäÝËù≤ÈÖçÁΩÆÊñá‰ögÂëΩÂêçËßÑÂàôÊòØactionServlet-servlet.xml,ÂÖ∂‰∏≠actionServlet
ÊòØÈÖçæ|Æorg.apache.struts.action.ActionServletÊó∂ÊåáÂÆöÁöÑservletÂêçÁß∞
2„ÄÅÈÄöËøáÈÖçÁΩÆcontextConfigLocation±ûÊÄßÊù•ÊåáÁÇπSpringÈÖçÁΩÆÊñá‰ögÁöщΩçæ|?§ö‰∏™ÈÖçÁΩÆÊñá‰ögÂè؉ª•‰ΩøÁî® ÈÄóÂè∑","„ÄÅÂàÜÂè?;"„ÄÅÁ©∫ÊÝ? "
-->
<set-property property="contextConfigLocation"
value="/WEB-INF/conf/spring-application.xml,/WEB-INF/conf/**/spring*.xml" />
</plug-in>
-->
</struts-config>
2„ÄÅÈááÁî®SpringÊèê‰æõÁöÑContextLoaderListenerÊù•ÂàùÂßãÂåñ(Â∫îÁî®ÊúçÂä°Âô®ÈúÄ˶ÅÊîØÊåÅListener,Servlet2.3ÁâàÊú¨Âè?qi®¢ng)‰ª•‰?
<context-param>
<description>ÈÄöËøáÈÖçÁΩÆcontextConfigLocation±ûÊÄßÊù•ÊåáÁÇπSpringÈÖçÁΩÆÊñá‰ögÁöщΩçæ|?§ö‰∏™ÈÖçÁΩÆÊñá‰ögÂè؉ª•‰ΩøÁî® ÈÄóÂè∑","„ÄÅÂàÜÂè?;"„ÄÅÁ©∫ÊÝ? "</description>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/conf/spring-application.xml /WEB-INF/conf/**/spring*.xml</param-value>
</context-param>
<listener>
<description>ÈÄöËøáContextLocaderListenerÊù•ÂàùÂßãÂåñSpringÂÆπÂô®ÂQåÂäÝËΩΩSpringÈÖçÁΩÆÊñá‰ög</description>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
3、采用load-on-startup Servlet 来初始化Spring容器
<servlet>
<description>
通过load-on-startup Servlet来初始化Spring容器
Ëؕ¶ljΩïServlet Á∫éÊèê‰æõ"ÂêéÂè∞"ÊúçÂä°ÂQå‰Ωú‰∏∫ÂÆπÂô®ÁÆ°ÁêÜÂ∫îÁ∏≠ÁöÑÂÖ∂‰ªñbeanÂQå‰∏çÈúÄ˶ÅÂìçÂ∫îÂÆ¢ÊàØÇØ∑ʱÇÔºåÂõÝÊ≠§ÊóÝÈ°ªÈÖçÁΩÆservlet-mapping
</description>
<servlet-name>applicationContext</servlet-name>
<servlet-class>org.springframework.web.context.ContextLoaderServlet</servlet-class>
<load-on-startup>0</load-on-startup>
</servlet>
1. ‰∏§Â§ßÂÖ≥ÈîÆÁâ“é(gu®©)Ä?
ÈõÜÁæ§Êò؉∏ÄælÑÂçèÂêåÂ∑•‰ΩúÁöÑÊúçÂä°ÂÆû‰ΩìÂQåÁª•Êèê‰æõÊØîÂçï‰∏ÄÊúçÂä°ÂÆû‰ΩìÊõ¥ÂÖ∑Êâ©Â±ïÊÄ߉∏éÂèØÁî®ÊÄßÁöÑÊúçÂä°Úqõ_è∞„ÄÇÂú®ÂÆ¢Êà∑Á´ØÁúãÊù•Ôºå‰∏ĉ∏™ÈõÜæü§Â∞±Ë±°Êò؉∏ĉ∏™ÊúçÂä°ÂÆû‰ΩìÔºå‰Ω܉∫ãÂÆû‰∏äÈõÜÁæ§Áî◊É∏ÄælÑÊúçÂä°ÂÆû‰ΩìÁªÑÊàê„Älj∏éÂçï‰∏ÄÊúçÂä°ÂÆû‰ΩìÁõ∏ÊØîËæÉÔºåÈõÜÁæ§Êèê‰æõ‰∫?ji®£n)‰ª•‰∏ã‰∏§‰∏™ÂÖ≥ÈîÆÁâπÊÄßÔºö(x®¨)
· ÂèØÊâ©Â±ïÊÄßÔºçÂQçÈõÜæü§ÁöÑÊÄßËÉΩ‰∏çÈôê‰∫éÂçï‰∏ÄÁöÑÊúçÂä°ÂÆû‰ΩìÔºåÊñ∞ÁöÑÊúçÂä°ÂÆû‰ΩìÂè؉ª•Âä®ÊÄÅÂú∞ÂäÝÂÖ•Âà∞ÈõÜæü§Ôºå‰ªéËÄå¢ûº∫ÈõÜæü§ÁöÑÊÄßËÉΩ„Ä?/p>
· È´òÂèØÁî®ÊÄßÔºçÂQçÈõÜæü§ÈÄöËøáÊúçÂä°ÂÆû‰ΩìÂÜó‰Ωô‰ΩøÂÆ¢ÊàÔL(f®•ng)´ØÂÖç‰∫éËΩ¿LòìÈÅáÂà∞out of serviceÁöÑË≠¶Âëä„ÄÇÂú®ÈõÜÁ槉∏≠ÔºåÂêåÊÝ∑ÁöÑÊúçÂä°Âè؉ª•Áî±Â§ö‰∏™ÊúçÂä°ÂÆû‰ΩìÊèê‰æõ„ÄǶÇÊûú‰∏ĉ∏™ÊúçÂä°ÂÆû‰Ω짱˥•‰∫Ü(ji®£n)ÂQåÂ趉∏ĉ∏™ÊúçÂä°ÂÆû‰Ω쉺ö(x®¨)Êé•Áư§Þp”|ÁöÑÊúçÂä°ÂÆû‰Ωì„ÄÇÈõÜæü§Êèê‰æõÁöщªé‰∏ĉ∏™Âá∫ÈîôÁöÑÊúçÂä°ÂÆû‰ΩìÊާçÂà∞Â趉∏ĉ∏™ÊúçÂä°ÂÆû‰ΩìÁöÑÂäüËÉΩ¢ûº∫‰∫?ji®£n)Â∫îÁî®ÁöÑÂèØÁî®ÊÄß„Ä?/p>
2. 两大能力
‰∏ÞZ∫Ü(ji®£n)ÂÖ‰húâÂèØÊâ©Â±ïÊÄßÂíåÈ´òÂèØÁî®ÊÄßÁâπÁÇπÔºåÈõÜÁæ§ÁöÑÂøÖôÂ’dÖ∑§ቪ•‰∏ã‰∏§Â§ßËÉΩÂäõÔºö(x®¨)
· Ë¥üËù≤ÂùáË°°ÂQçÔºçË¥üËù≤ÂùáË°°ËÉΩÊä䉪’dä°ÊØîËæÉÂùáË°°Âú∞ÂàÜÂ∏ÉÂà∞ÈõÜÁæ§ÁéØ¢ɉ∏ãÁöÑËÆ°ÁÆóÂíåÁΩëælú˵ÑÊ∫ê„Ä?/p>
· ÈîôËØØÊާçÂQçÔºçÁî◊É∫éÊüêÁßçÂéüÂõÝÂQåÊâßË°åÊüê‰∏™‰ìQÂä°ÁöÑ˵ÑÊ∫êÂá∫Áé∞ÊïÖÈöúÂQåÂ趉∏ÄÊúçÂä°ÂÆû‰Ωì‰∏≠ÊâßË°åÂêå‰∏ĉª’dä°ÁöÑ˵ÑÊ∫êÊé•ÁùÄÂÆåÊàꉪ’dä°„ÄÇËøôøUçÁ∫é‰∏ĉ∏™ÂÆû‰Ωì‰∏≠ÁöÑ˵ÑÊ∫ê‰∏çËÉΩÂ∑•‰ΩúÔºåÂ趉∏ĉ∏™ÂÆû‰Ωì‰∏≠ÁöÑ˵ÑÊ∫êÈÄèÊòéÁöÑÁëÙæl≠ÂÆåÊàê‰ìQÂä°ÁöÑòqáÁ®ãÂè´ÈîôËØØÊާç„Ä?/p>
Ë¥üËù≤ÂùáË°°ÂíåÈîôËØØÊާçÈÉΩ˶ÅʱÇÂêÑÊúçÂä°ÂÆû‰Ωì‰∏≠ÊúâÊâßË°åÂêå‰∏ĉª’dä°ÁöÑ˵ÑÊ∫êÂ≠òÂú®ÔºåËÄå‰∏îÂØπ‰∫éÂêå‰∏ĉª’dä°ÁöÑÂêщ∏™ËµÑÊ∫êÊù•ËØþ_(d®¢)ºåÊâß˰剪’dä°ÊâÄÈúÄÁöщø°ÊÅØËßÜÂõæÔºà‰ø°ÊÅ؉∏ä‰∏ãÊñáÔºâ(j®™)ÂøÖÈ°ªÊò؉∏ÄÊÝÔL(f®•ng)öÑ„Ä?/p>
3. ‰∏§Â§ßÊäÄÊú?
ÂÆûÁé∞ÈõÜÁæ§Âä°ÂøÖ˶ÅÊú≪•‰∏ã‰∏§Â§ßÊäÄÊúØÔºö(x®¨)
· ÈõÜÁæ§Âú∞ÂùÄÂQçÔºçÈõÜÁæ§Áî±Â§ö‰∏™ÊúçÂä°ÂÆû‰ΩìÁªÑÊàêÔºåÈõÜÁæ§ÂÆ¢Êà∑Á´ØÈÄöËøáËÆâKóÆÈõÜÁæ§ÁöÑÈõÜæü§Âú∞ÂùÄËé∑ÂèñÈõÜÁæ§ÂÜÖÈÉ®ÂêÑÊúçÂä°ÂÆû‰ΩìÁöÑÂäüËÉΩ„ÄÇÂÖ∑ÊúâÂçï‰∏ÄÈõÜÁæ§Âú∞ÂùÄÂQà‰πüÂè´Âçï‰∏ÄÂΩ±ÂÉèÂQâÊòØÈõÜÁæ§Áöщ∏ĉ∏™Âü∫Êú¨ÁâπÂæÅ„ÄÇÁª¥Êä§ÈõÜæü§Âú∞ÂùÄÁöÑËÆææ|ÆË¢´øUÓCÿì(f®¥)Ë¥üËù≤ÂùáË°°Âô®„ÄÇË¥üËΩΩÂùáË°°Âô®ÂÜÖÈɮ˥üË¥£Ωé°ÁêÜÂêщ∏™ÊúçÂä°ÂÆû‰ΩìÁöÑÂäÝÂÖ•ÂíåÈÄÄÂá∫Ôºå§ñÈɮ˥üË¥£ÈõÜÁæ§Âú∞ÂùÄÂêëÂÜÖÈÉ®ÊúçÂä°ÂÆû‰ΩìÂú∞ÂùÄÁöÑËù{Ê碄ÄÇÊúâÁöÑË¥üËΩΩÂùáË°°Âô®ÂÆûÁé∞ÁúüÊ≠£ÁöÑË¥üËΩΩÂùáË°°ÁÆóÊ≥ïÔºåÊúâÁöÑÂè™ÊîØÊåʼnìQÂä°ÁöÑËΩ¨Ê碄ÄÇÂè™ÂÆûÁé∞‰ª’dä°ËΩ¨Êç¢ÁöÑË¥üËΩΩÂùáË°°Âô®ÈÄÇÁ∫éÊîØÊåÅACTIVE-STANDBYÁöÑÈõÜæü§ÁéØ¢ÉÔºåÂú®ÈÇ£ÈáåÔºåÈõÜÁ槉∏≠Âè™Êúâ‰∏ĉ∏™ÊúçÂä°ÂÆû‰ΩìÂ∑•‰ΩúÔºåÂΩìÊ≠£Âú®Â∑•‰ΩúÁöÑÊúçÂä°ÂÆû‰ΩìÂèëÁîüÊïÖÈöúÊó”ûºåË¥üËù≤ÂùáË°°Âô®ÊääÂêéÊù•ÁöщìQÂä°Ëù{ÂêëÂè¶Â§ñ‰∏ĉ∏™ÊúçÂä°ÂÆû‰Ωì„Ä?/p>
· ÂÜÖÈÉ®ÈÄö‰ø°ÂQçÔºç‰∏ÞZ∫Ü(ji®£n)ËÉΩÂçèÂêåÂ∑•‰Ωú„ÄÅÂÆûÁé∞Ë¥üËΩΩÂùáË°°ÂíåÈîôËØØÊާçÂQåÈõÜæü§ÂêÑÂÆû‰ΩìÈó¥ÂøÖô¿Ló∂Â∏îRÄö‰ø°ÂQåÊØî¶ÇË¥üËΩΩÂùáË°°Âô®ÂØ“é(gu®©)úçÂä°ÂÆû‰ΩìÂøÉ(j®©)Ë∑œx(ch®Æng)µãËØï‰ø°ÊÅØ„ÄÅÊúçÂä°ÂÆû‰ΩìÈ󥉪’dä°ÊâßË°å‰∏ä‰∏ãÊñá‰ø°ÊÅØÁöÑÈÄö‰ø°„Ä?/p>
ÂÖ‰húâÂêå‰∏ĉ∏™ÈõÜæü§Âú∞ÂùĉΩøÂæóÂÆ¢Êà∑Á´ØËÉΩËÆâKóÆÈõÜÁæ§Êèê‰æõÁöÑËÆ°ΩéóÊúçÂä°Ôºå‰∏ĉ∏™ÈõÜæü§Âú∞Âùĉ∏ãÈöêËóè‰∫Ü(ji®£n)Âêщ∏™ÊúçÂä°ÂÆû‰ΩìÁöÑÂÜÖÈÉ®Âú∞ÂùÄÂQå‰ã…ÂæóÂÆ¢ÊàØǶÅʱÇÁöÑËÆ°ÁÆóÊúçÂä°ËÉΩÂú®Âêщ∏™ÊúçÂä°ÂÆû‰Ωì‰πãÈó¥ÂàÜÂ∏É„ÄÇÂÜÖÈÉ®ÈÄö‰ø°ÊòØÈõÜæü§ËÉΩÊ≠£Â∏∏òqêËù{ÁöÑÂü∫ºãÄÂQåÂÆɉΩøÂæóÈõÜÁæ§ÂÖ‰húâÂùáË°°Ë¥üËù≤ÂíåÈîôËØØÊާçÁöÑËÉΩÂäõ„Ä?/p>
集群分类
LinuxÈõÜÁ槉∏ªË¶ÅÂàÜÊàê‰∏â§ßæc? È´òÂèØÁî®ÈõÜæü§Ôºå Ë¥üËù≤ÂùáË°°ÈõÜÁæ§ÂQåÁßëÂ≠¶ËÆ°ΩéóÈõÜæü?
È´òÂèØÁî®ÈõÜæü? High Availability Cluster)
负蝲均衡集群(Load Balance Cluster)
øUëÂ≠¶ËÆ°ÁÆóÈõÜÁæ§(High Performance Computing Cluster)
================================================
ÂÖ∑‰ΩìÂåÖÊã¨ÂQ?/p>
Linux High Availability È´òÂèØÁî®ÈõÜæü?nbsp;
(ÊôÆÈÄö‰∏§ËäÇÁÇπÂèåÊú∫ÁÉ≠§áÂQå§öËäÇÁÇπHAÈõÜÁæ§ÂQåRAC, shared, share-nothingÈõÜÁæ§Ω{?
Linux Load Balance 负蝲均衡集群
(LVSΩ{?...)
Linux High Performance Computing È´òÊÄßËÉΩøUëÂ≠¶ËÆ°ÁÆóÈõÜÁæ§
(Beowulf æcªÈõÜæü?...)
ÂàÜÂ∏ɺèÂ≠òÂÇ?nbsp;
ÂÖ∂‰ªñæcªlinuxÈõÜÁæ§
(¶ÇOpenmosix, rendering farm Ω{?.)
详细介绍
1. È´òÂèØÁî®ÈõÜæü?High Availability Cluster)
Â∏∏ËßÅÁöÑÂ∞±Êò?‰∏™ËäÇÁÇπÂÅöÊàêÁöÑHAÈõÜÁæ§ÂQåÊúâÂæà§öÈÄö‰øóÁöщ∏çøUëÂ≠¶ÁöÑÂêçøUéÕºåÊØî¶Ç"ÂèåÊú∫ÁÉ≠§á", "ÂèåÊú∫‰∫í§á", "ÂèåÊú∫".
È´òÂèØÁî®ÈõÜæü§ËߣÂÜ≥ÁöÑÊò؉øùÈöúÁî®ÊàÔL(f®•ng)öÑÂ∫îÁî®ΩEãÂ∫èÊåÅÁÆã(hu®§)ÂØπ§ñÊèê‰æõÊúçÂä°ÁöÑËÉΩÂäõ„Ä?(Ë؉h≥®ÊÑèÈ´òÂèØÁî®ÈõÜÁæ§Êó¢‰∏çÊòØÁî®Êù•‰øùÊ䧉∏öÂä°Êï∞ÊçÆÁöÑÂQå‰øùÊä§ÁöÑÊòØÁî®ÊàÔL(f®•ng)öщ∏öÂä°ΩEãÂ∫èÂØπ§ñ‰∏çÈó¥Êñ≠Êèê‰æõÊúçÂä°ÔºåÊääÂõÝËΩ؉ög/ºã¨‰ög/‰∫ÞZÿì(f®¥)ÈÄÝÊàêÁöÑÊïÖÈöúÂØπ‰∏öÂä°ÁöÑ™Ñ(ji®£ng)ÂìçÈôç‰ΩéÂà∞ÊúÄûÆèÁ®ãÂ∫?„Ä?/p>
2. 负蝲均衡集群(Load Balance Cluster)
Ë¥üËù≤ÂùáË°°æp»ùªüÂQöÈõÜæü§‰∏≠ÊâÄÊúâÁöÑËäÇÁÇπÈÉΩ§щ∫éÊ¥ªÂä®Áä∂ÊÄÅÔºåÂÆɉª¨ÂàÜÊëäæp»ùªüÁöÑÂ∑•‰ΩúË¥üËΩΩ„Älj∏ÄËà¨WebÊúçÂä°Âô®ÈõÜæü§„ÄÅÊï∞ÊçÆÂ∫ìÈõÜÁæ§ÂíåÂ∫îÁî®ÊúçÂä°Âô®ÈõÜÁæ§ÈÉΩ±û‰∫éËøôøUçÁ±ªÂûã„Ä?/p>
Ë¥üËù≤ÂùáË°°ÈõÜÁ槉∏ÄËà¨Á∫éÁõ∏Â∫îÁΩëælúËØ∑ʱÇÁöÑæ|ëÈ°µÊúçÂä°Âô®ÔºåÊï∞ÊçÆÂ∫ìÊúçÂä°Âô®„ÄÇËøôøUçÈõÜæü§Âè؉ª•Âú®Êé•Âà∞Ë؉h±ÇÊó”ûºåãÇÄ(g®®)Êü•Êé•ÂèóËØ∑ʱÇËæÉ?y®≠u)ÆëÔºå‰∏çÁπÅÂøôÁöÑÊúçÂä°Âô®ÔºåÚq∂ÊääË؉h±ÇËΩ¨Âà∞òqô‰∫õÊúçÂä°Âô®‰∏ä„ÄljªéãÇÄ(g®®)Êü•ÂÖ∂‰ªñÊúçÂä°Âô®Áä∂ÊÄÅËøô‰∏ÄÁÇπ‰∏äÁúãÔºåË¥üËù≤ÂùáË°°ÂíåÂÆπÈîôÈõÜæü§ÂæàÊé•ËøëÂQå‰∏çÂêå‰πã§ÑÊòØÊï∞Èáè‰∏äÊõ¥Â§ö„Ä?/p>
3. øUëÂ≠¶ËÆ°ÁÆóÈõÜÁæ§(High Performance Computing Cluster)
È´òÊÄßËÉΩËÆ°ÁÆó(High Perfermance Computing)ÈõÜÁæ§ÂQåÁÆÄøU∞HPCÈõÜÁ槄ÄÇËøôæcªÈõÜæü§Ëá¥Âäõ‰∫éÊèê‰æõÂçï‰∏™ËÆ°ÁÆóÊú∫Êâĉ∏çËÉΩÊèê‰æõÁöѺ∫§ßÁöÑËÆ°ÁÆóËÉΩÂäõ„Ä?/p>
高性能计算分类  
„ÄÄÈ´òÂêûÂêêËÆ°Ωé?High-throughput Computing)
„ÄÄ„ÄÄÊúâ‰∏ÄæcªÈ´òÊÄßËÉΩËÆ°ÁÆóÂQåÂè؉ª•ÊääÂÆÉÂàÜÊàêËã•Úq≤Âè؉ª•Â∆àË°åÁöÑÂ≠ê‰ìQÂä°ÔºåËÄå‰∏îÂêщ∏™Â≠ê‰ìQÂä°ÂΩºÊ≠§Èó¥Ê≤°Êú≪ĉπàÂÖ≥ËÅî„ÄÇ˱°Âú®ÂÆ∂ÊêúÂت§ñÊòü‰∫∫Ôºà SETI@HOME -- Search for Extraterrestrial Intelligence at Home ÂQâÂ∞±ÊòØËøô‰∏Äæc’dûãÂ∫îÁÄÇËøô‰∏ÄôÂπÁõÆÊòØÂà©Áî®Internet‰∏äÁöÑÈó≤ÁΩÆÁöÑËÆ°Ωéó˵ÑÊ∫êÊù•ÊêúÂت§ñÊòü‰∫∫„ÄÇSETIôÂπÁõÆÁöÑÊúçÂä°Âô®ûÆ܉∏ÄælÑÊï∞ÊçÆÂíåÊï∞ÊçÆÊ®°ÂºèÂèëÁªôInternet‰∏äÂèÇÂäÝSETIÁöÑËÆ°ΩéóËäÇÁÇπÔºåËÆ°ÁÆóËäÇÁÇπÂú®ÁªôÂÆöÁöÑÊï∞ÊçƉ∏äÁî®ælôÂÆöÁöÑÊ®°ÂºèËøõË°åÊêúÁ¥¢ÔºåÁÑ∂ÂêéûÆÜÊêúÁ¥¢ÁöÑælìÊûúÂèëÁªôÊúçÂä°Âô®„ÄÇÊúçÂä°Âô®Ë¥üË¥£ûÆ܉ªéÂêщ∏™ËÆ°ÁÆóËäÇÁÇπòqîÂõûÁöÑÊï∞ÊçÆʱáÈõÜÊàêÂÆåÊï¥ÁöÑÊï∞ÊçÆ„ÄÇÂõ݉∏¯ôøôøUçÁ±ªÂûãÂ∫îÁî®Áöщ∏ĉ∏™ÂÖ±ÂêåÁâπÂæÅÊòØÂú®ÊìvÈáèÊï∞ÊçƉ∏äÊêúÁɶ(ch®≥)Êüê‰∫õÊ®°ÂºèÂQåÊâĉª•ÊääòqôÁ±ªËÆ°ÁÆóøUÓCÿì(f®¥)È´òÂêûÂêêËÆ°Ωéó„ÄÇÊâÄË∞ìÁöÑInternetËÆ°ÁÆóÈÉΩ±û‰∫éËøô‰∏ÄæcÖRÄÇÊåâÁÖ?FlynnÁöÑÂàÜæcªÔºåÈ´òÂêûÂêêËÆ°Ωéó±û‰∫éSIMDÂQàSingle Instruction/Multiple DataÂQâÁöÑËåÉÁ籠Ä?/p>
分布计算(Distributed Computing)
„ÄÄ„ÄÄÂ趉∏ÄæcªËÆ°ΩéóÂàö•ΩÂíåÈ´òÂêûÂêêËÆ°ΩéóÁõ∏ÂèçÔºåÂÆɉª¨ËôΩÁÑ∂Âè؉ª•ælôÂàÜÊàêËã•Úq≤Â∆àË°åÁöÑÂ≠ê‰ìQÂä°Ôºå‰ΩÜÊòØÂ≠ê‰ìQÂä°Èó¥ËÅîÁ≥ªÂæàÁ¥ßÂØÜÔºåÈúÄ˶ŧßÈáèÁöÑÊï∞ÊçƉ∫§Ê碄ÄÇÊåâÁÖßFlynnÁöÑÂàÜæcªÔºåÂàÜÂ∏ɺèÁöÑÈ´òÊÄßËÉΩËÆ°ÁÆó±û‰∫éMIMDÂQàMultiple Instruction/Multiple DataÂQâÁöÑËåÉÁ籠Ä?/p>
4. ÂàÜÂ∏ɺèÔºàÈõÜÁæ§ÂQâ‰∏éÈõÜÁæ§ÁöÑËÅîæp÷M∏éÂå∫Âà´
ÂàÜÂ∏ɺèÊòØÊåáÂ∞܉∏çÂêåÁöщ∏öÂä°ÂàÜÂ∏ÉÂú®‰∏çÂêåÁöÑÂú∞ÊñèVÄ?
ËÄåÈõÜæü§ÊåáÁöÑÊòØûÆÜÂáÝÂè∞ÊúçÂä°Âô®Èõ܉∏≠Âú®‰∏Ä˵¯PºåÂÆûÁé∞Âêå‰∏ĉ∏öÂä°„Ä?
ÂàÜÂ∏ɺè‰∏≠ÁöÑÊØè‰∏ĉ∏™ËäÇÁÇπÔºåÈÉΩÂè؉ª•ÂÅöÈõÜÁ槄Ä?
ËÄåÈõÜæü§Â∆à‰∏ç‰∏ÄÂÆöÂ∞±ÊòØÂàÜÂ∏ɺèÁöÑ„Ä?
‰∏æ‰æãÂQöÂ∞±ÊØî¶ÇÊñ∞ʵ™æ|ëÔºåËÆâKóÆÁöщùh§ö‰∫Ü(ji®£n)ÂQ剪ñÂè؉ª•ÂÅö‰∏ĉ∏™Áæ§ÈõÜÔºåÂâçÈù¢Êîæ‰∏ĉ∏™ÂìçÂ∫îÊúçÂä°Âô®ÂQåÂêéÈù¢ÂáÝÂè∞ÊúçÂä°Âô®ÂÆåÊàêÂêå‰∏ĉ∏öÂä°ÂQå¶ÇÊûúÊúâ‰∏öÂä°ËÆâKóÆÁöÑÊó∂ÂÄôÔºåÂìçÂ∫îÊúçÂä°Âô®ÁúãÂì™Âè∞ÊúçÂä°Âô®ÁöÑË¥üËù≤‰∏çÊòØÂæàÈáçÂQåÂ∞±ûÆÜÁªôÂ왉∏ÄÂè∞ÂéªÂÆåÊàê„Ä?
ËÄåÂàÜÂ∏ɺèÂQ剪éΩHÑÊÑè‰∏äÁêÜËߣԺå‰πüË∑üÈõÜÁæ§Â∑Ɖ∏ç§öÔºå ‰ΩÜÊòØÂÆÉÁöÑælÑÁªáÊØîËæÉÊùæÊï£ÂQå‰∏çÂÉèÈõÜæü§ÔºåÊúâ‰∏ĉ∏™ÁªÑæláÊÄßÔºå‰∏ÄÂè∞ÊúçÂä°Âô®ÂûƉ∫Ü(ji®£n)ÂQåÂÖ∂ÂÆÉÁöÑÊúçÂä°Âô®Âè؉ª•È°∂‰∏äÊù•„Ä?
ÂàÜÂ∏ɺèÁöÑÊØè‰∏ĉ∏™ËäÇÁÇπÔºåÈÉΩÂÆåÊàê‰∏çÂêåÁöщ∏öÂä°ÂQå‰∏ĉ∏™ËäÇÁÇπÂûƉ∫?ji®£n)ÔºåÂì™Ëøô‰∏™‰∏öÂä°Â∞±‰∏çÂèØËÆâKóƉ∫?ji®£n)„Ä?/p>
Êú¨ÊñáÊù•Ëá™CSDNÂçöÂÆ¢ÂQåËù{ËΩΩËØ∑ÊÝáÊòéÂá∫§ÑÂQöhttp://blog.csdn.net/tanghongru1983/archive/2009/04/28/4130356.aspx
import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader; public class MyEclipseGen {
public class MyEclipseGen {

 private static final String LL = "Decompiling this copyrighted software is a violation of both your license agreement and the Digital Millenium Copyright Act of 1998 (http://www.loc.gov/copyright/legislation/dmca.pdf). Under section 1204 of the DMCA, penalties range up to a $500,000 fine or up to five years imprisonment for a first offense. Think about it; pay for a license, avoid prosecution, and feel better about yourself.";
private static final String LL = "Decompiling this copyrighted software is a violation of both your license agreement and the Digital Millenium Copyright Act of 1998 (http://www.loc.gov/copyright/legislation/dmca.pdf). Under section 1204 of the DMCA, penalties range up to a $500,000 fine or up to five years imprisonment for a first offense. Think about it; pay for a license, avoid prosecution, and feel better about yourself."; public String getSerial(String userId, String licenseNum) {
public String getSerial(String userId, String licenseNum) { java.util.Calendar cal = java.util.Calendar.getInstance(); cal.add(1, 3); cal.add(6, -1); java.text.NumberFormat nf = new java.text.DecimalFormat("000"); licenseNum = nf.format(Integer.valueOf(licenseNum)); String verTime = new StringBuilder("-").append( new java.text.SimpleDateFormat("yyMMdd").format(cal.getTime())) .append("0").toString(); String type = "YE3MP-"; String need = new StringBuilder(userId.substring(0, 1)).append(type) .append("300").append(licenseNum).append(verTime).toString(); String dx = new StringBuilder(need).append(LL).append(userId) .toString(); int suf = this.decode(dx); String code = new StringBuilder(need).append(String.valueOf(suf)) .toString(); return this.change(code);
java.util.Calendar cal = java.util.Calendar.getInstance(); cal.add(1, 3); cal.add(6, -1); java.text.NumberFormat nf = new java.text.DecimalFormat("000"); licenseNum = nf.format(Integer.valueOf(licenseNum)); String verTime = new StringBuilder("-").append( new java.text.SimpleDateFormat("yyMMdd").format(cal.getTime())) .append("0").toString(); String type = "YE3MP-"; String need = new StringBuilder(userId.substring(0, 1)).append(type) .append("300").append(licenseNum).append(verTime).toString(); String dx = new StringBuilder(need).append(LL).append(userId) .toString(); int suf = this.decode(dx); String code = new StringBuilder(need).append(String.valueOf(suf)) .toString(); return this.change(code); }private int decode(String s) { int i; char[] ac; int j; int k; i = 0; ac = s.toCharArray(); j = 0; k = ac.length; while (j < k) { i = (31 * i) + ac[j]; j++; } return Math.abs(i);}private String change(String s) { byte[] abyte0; char[] ac; int i; int k; int j; abyte0 = s.getBytes(); ac = new char[s.length()]; i = 0; k = abyte0.length; while (i < k) { j = abyte0[i]; if ((j >= 48) && (j <= 57)) { j = (((j - 48) + 5) % 10) + 48; } else if ((j >= 65) && (j <= 90)) { j = (((j - 65) + 13) % 26) + 65; } else if ((j >= 97) && (j <= 122)) { j = (((j - 97) + 13) % 26) + 97; } ac[i] = (char) j; i++; } return String.valueOf(ac);}public MyEclipseGen() { super();}public static void main(String[] args) { try { System.out.println("please input register name:"); BufferedReader reader = new BufferedReader(new InputStreamReader( System.in)); String userId = null; userId = reader.readLine(); MyEclipseGen myeclipsegen = new MyEclipseGen(); String res = myeclipsegen.getSerial(userId, "5"); System.out.println("Serial:" + res); reader.readLine(); } catch (IOException ex) { }}
}private int decode(String s) { int i; char[] ac; int j; int k; i = 0; ac = s.toCharArray(); j = 0; k = ac.length; while (j < k) { i = (31 * i) + ac[j]; j++; } return Math.abs(i);}private String change(String s) { byte[] abyte0; char[] ac; int i; int k; int j; abyte0 = s.getBytes(); ac = new char[s.length()]; i = 0; k = abyte0.length; while (i < k) { j = abyte0[i]; if ((j >= 48) && (j <= 57)) { j = (((j - 48) + 5) % 10) + 48; } else if ((j >= 65) && (j <= 90)) { j = (((j - 65) + 13) % 26) + 65; } else if ((j >= 97) && (j <= 122)) { j = (((j - 97) + 13) % 26) + 97; } ac[i] = (char) j; i++; } return String.valueOf(ac);}public MyEclipseGen() { super();}public static void main(String[] args) { try { System.out.println("please input register name:"); BufferedReader reader = new BufferedReader(new InputStreamReader( System.in)); String userId = null; userId = reader.readLine(); MyEclipseGen myeclipsegen = new MyEclipseGen(); String res = myeclipsegen.getSerial(userId, "5"); System.out.println("Serial:" + res); reader.readLine(); } catch (IOException ex) { }} }
}Ê≥®ÂÜåÊñ“é(gu®©)≥ïÂQ?br /> window -> preferences -> myeclipse -> subscription
HibernateÂ≠¶‰πÝ(f®§n)ΩWîËÆ∞
1„Ä?/span>HibernateÊÝ∏ÂøÉ(j®©)æc÷M∏éÊé•Âè£
1-1.Configurationæc?/span>
ConfigurationÁöÑÂÖ•Âè£ÔºåÂÆÉË¥üË¥£ÈÖçæ|ÆÂíåÂêØÂä®Hibernate,HibernateÂÆû‰æãÂäÝËù≤ÈÖçÁΩÆÊñá‰ög‰ø°ÊÅØ(hibernate.cfg.xml),ÁöÑÂÜÖÂÆπÂ∆àÂàõÂæèSessionFactory.
1-2.SessionFactory接口
SessionFactory‰∏ĉ∏?/span>SessionFactory‰∏ÄËà¨Â∞±ÊòØÊåá‰∏ĉ∏™Êï∞ÊçÆÂ∫ì)‰∏≠Ëé∑Âæ?/span>SessionÂÖ‰hú≪•‰∏ãÁâπÁÇπÂQ?/span>
1) ÂÆû‰æãÂè؉ª•Ë¢´Â∫îÁî?/span> 2) ÂQåÂõ݉∏∫ÂÆÉÈúÄ˶ʼn∏ĉ∏™Âæà§ßÁöÑæ~ìÂ≠òÂQåÁî®Êù•Â≠òÊî˘N¢ÑÂÆö‰πâÁö?/span>SQLÂQå¶ÇÊûú‰∏ĉ∏™Â∫îÁî®Á®ãÂ∫è‰∏≠Âè™ËÆøÈóƉ∏ĉ∏™Êï∞ÊçÆÂ∫ì ÂÆû‰æã„Ä?/span>
1-3.Session 接口
Session‰∏≠Â∫îÁî®ÊúÄÈ¢ëÁπÅÁöÑÊé•Â裄Ä?/span>SessionÂQåÂÆÉË¥üË¥£Ωé°ÁêÜÊâÄÊúâ‰∏éÊåʼnπÖÂåñÁõ∏ÂÖ≥ÁöÑÊìç‰ΩúÂQö¶ÇÂ≠òÂÇ®„ÄÅÊõ¥Êñ∞„ÄÅÂàÝÈô§ÂíåÂäÝËù≤ÂØπ˱°Ω{â„Ä?/span>Session 1) ÂÆû‰æã„Ä?/span>
2) Session ÂÆû‰æãÂQåÂú®ÊØèʨ°Ë؉h±ÇòqáÁ®ãʱáÊÄ’dèä(qi®¢ng)Êó∂Âàõª∫ÂíåÈîÄÊØ?/span> Session 3) SessionÁöÑÁºìÂ≠òË¢´øUÓCÿì(f®¥)Hibernate1-4.TransactionÊé•Âè£
TransactionÊ°ÜÊû∂Áöщ∫ãÂä°Êé•Â裄ÄÇÂÆÉÂØπÂ∫ï±ÇÁöщ∫ãÂä°Êé•Âè£ÂÅö‰∫Ü(ji®£n)ûÆÅË£ÖÂQåÂåÖÊã¨Ôºö(x®¨)JDBC APIòqôÊÝ∑‰ΩøÂæóHibernateÊé•Âè£Êù•Áî≥Êòé‰∫ãÂä°ËæπÁïåÔºåòqôÊúâÂ䩉∫éÂ∫îÁî®ΩEãÂ∫èÂÜç‰∏çÂêåÁöÑÁéØ¢ÉÂíåÂÆπÂô®‰∏≠øU¿L§ç„Ä?/span>
1-5.QueryÂí?/span>CriteriaÊé•Âè£
ÁöÑÊü•ËØ¢Êé•Âè£ÔºåÁ∫鉪éÊï∞ÊçÆÂ≠òÂÇ®Ê∫êÊü•ËØ¢ÂØπ˱°Âè?qi®¢ng)ÊéßÂà∂ÊâßË°åÊü•ËØ¢ÁöÑòqáÁ®ã„Ä?/span>QueryÂQõËÄ?/span>CriteriaÊõ¥ÂäÝÈù¢ÂêëÂØπ˱°ÂQ?/span>Criteria2„Ä?/span>Hibernate‰∏≠Â∏∏Áî®Áöщ∫ãÂä°ÈöîÁ¶ªæUßÂà´
|
Â∏îRáè |
ÂÄ?/span> |
说明 |
||||||||
|
TRANSACTION_NONE |
0 |
TRANSACTION_READ_UNCOMMITTED |
1 |
ÂQâ„Äʼn∏çÂèØÈáç§çËتÂíåËôöËتԺàphantom read
TRANSACTION_READ_COMMITTED |
2 |
TRANSACTION_REPEATABLE_READ |
4 |
TRANSACTION_SERIALIZABLE |
8 |
‰∏≠Á¶ÅÊ≠¢Áöщ∫ãÈ°πÂQåÂêåÊó∂ËøòºõÅÊ≠¢Âá∫Áé∞òqôÁßçÊÉÖÂܵÂQöÊüê‰∏ĉ∫ãÂä°ËØ’dèñÊâÄÊúâʪ°≠ë?/span> WHERE Êù°‰ögÁöÑË°åÂQåÁ¨¨‰∏ĉ∏™‰∫ãÂä°ÈáçÊñ∞ËتÂèñʪ°≠ë≥Áõ∏ÂêåÊù°‰ª∂ÁöÑË°åÔºåÚq∂Âú®ΩW¨‰∫åã∆°ËتÂèñÊó∂Ëé∑ÂæóÈ¢ù§ñÁö?#8220;Ëô?#8221;Ë°å„Ä?/span> |
3„Ä?/span>Hibernate‰∏≠ÂÆû‰æãÁöÑÁä∂ÊÄ?/span>
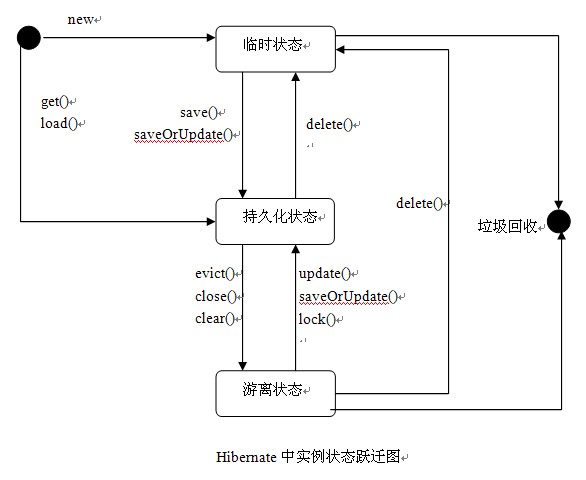
3-1ÂQö‰èÕ(f®¥)Êó∂Áä∂ÊÄ?/span>
1ÂQ?span style="font: 7pt 'Times New Roman'"> æ~ìÂ≠ò?sh®¥)∏≠Ôºå‰πüÂè؉ª•ËØ¥‰∏çË¢´‰ª÷MΩï‰∏ĉ∏?/span>Session2ÂQ?span style="font: 7pt 'Times New Roman'"> ÂØπ˱°òqõÂÖ•‰∏¥Êó∂Áä∂ÊÄ?/span>
1ÂQ?nbsp;ËØ≠Âè•ÂàöÂàõªÞZ∏ĉ∏?/span>Java2ÂQ?nbsp;SessionÊñ“é(gu®©)≥ïËÉΩ‰ã…‰∏ĉ∏™ÊåʼnπÖÂåñÊàñ‰èÕ(f®¥)Êó∂ËѱΩé°ÂØπ˱°Ëù{Ê碉ÿì(f®¥)‰∏¥Êó∂ÂØπ˱°„ÄÇÂØπ‰∫éËѱΩé°ÂØπ˱°Ôºådelete()æ~ìÂ≠ò?sh®¥)∏≠ÂàÝÈô§„Ä?/span>
3-2ÂQöÊåʼnπÖÂåñÁä∂ÊÄ?/span>
‰øùËØÅÊÝáËØ܉∏?/span>Java1ÂQ?nbsp;ÂÆû‰æãÁöÑÁºìÂ≠ò‰(sh®¥)∏≠ÂQå‰πüÂè؉ª•ËØþ_(d®¢)ºåÊåʼnπÖÂåñÂØπ˱°ÊÄ¿LòØË¢´‰∏ĉ∏?/span>Session2ÂQ?nbsp;3ÂQ?nbsp;SessionSessionÂØπ˱°òqõÂÖ•ÊåʼnπÖÂåñÁä∂ÊÄÅ„Ä?/span>
4ÂQ?nbsp;SessionÁöÑÊñπÊ≥ïËÉΩ§üÊää‰∏¥Êó∂ÂØπ˱°ËΩ¨ÂèòÊàêÊåʼnπÖÂåñÂØπ˱°„Ä?/span>
5ÂQ?nbsp;SessionÊà?/span>get()6ÂQ?nbsp;QueryÊñ“é(gu®©)≥ïòqîÂõûÁö?/span>list7ÂQ?nbsp;Session„Ä?/span>saveOrUpdate()Êñ“é(gu®©)≥ï‰ΩøËѱΩé°ÂØπ˱°Ëù{Âèò‰(sh®¥)ÿì(f®¥)ÊåʼnπÖÂåñÂØπ˱°„Ä?/span>
Âú®Ê∏ÖÁêÜÁºìÂ≠òÊó∂‰º?x®¨)Êääòqô‰∏™‰∏¥Êó∂ÂØπ˱°‰πüËù{ÂèòÊàêÊåʼnπÖÂåñÂØπ˱°„Ä?/span>HibernateÂÆû‰æãÁöÑÁºìÂ≠ò‰(sh®¥)∏≠ÂQåÊï∞ÊçÆÂ∫ìË°®‰∏≠ÁöÑÊØèÊù°ËÆ∞ÂΩïÂè™ÂØπÂ∫îÂî؉∏ÄÁöÑÊåʼnπÖÂåñÂØπ˱°ÂQå‰πüûƱÊòØËØ¥Âú®‰∏ĉ∏?/span>SessionÂêå‰∏ĉ∏?/span>OIDÁöÑÊòØÁõ∏ÂêåÁöÑÂØπ˱°„Ä?/span>
3-3ÂQöËѱΩé°Áä∂ÊÄ?/span>
Âà∞Âè¶Â§ñÁöÑòqõÁ®ã„ÄÇÂÆÉÊã•ÊúâÊåʼnπÖÂåñÊÝáËØÜÔºåÚq∂‰∏îÂú®Êï∞ÊçÆÂ∫ì‰∏≠ÂèØËÉΩÂ≠òÂú®‰∏ĉ∏™ÂØπÂ∫îÁöÑË°å„ÄÇÂØπ‰∫éËѱΩé°Áä∂ÊÄÅÁöÑÂÆû‰æãÂQ?/span>HibernateÊÝáËØÜÁöÑÂÖ≥æpÖRÄ?/span>
1ÂQ?span style="font: 7pt 'Times New Roman'"> ÁöÑÁºìÂ≠ò‰(sh®¥)∏≠ÂQå‰πüÂè؉ª•ËØþ_(d®¢)ºåËÑÞqÆ°ÂØπ˱°‰∏çË¢´Session2ÂQ?span style="font: 7pt 'Times New Roman'"> ÂâçÊèêÊù°‰ögÊòØÊ≤°ÊúâÂÖ∂‰ªñÁ®ãÂ∫èÂàÝÈô§‰∫Ü(ji®£n)òqôÊù°ËÆ∞ÂΩï)3ÂQ?span style="font: 7pt 'Times New Roman'"> ÂÖåôÅîÂQåÂõÝÊ≠?/span>HibernateSession1) Áö?/span>close()ÁöÑÁºìÂ≠òË¢´Ê∏ÖÁ©∫ÂQåÁºìÂ≠ò‰(sh®¥)∏≠ÁöÑÊâÄÊúâÊåʼnπÖÂåñÂØπ˱°ÈÉΩÂèò?sh®¥)∏¯ôѱΩé°ÂØπ˱°Ôºå¶ÇÊûúÂú®Â∫îÁî®Á®ãÂ∫è‰∏≠Ê≤°ÊúâºïÁî®ÂèòÈáèºïÁî®òqô‰∫õËÑÞqÆ°ÂØπ˱°ÂQ剪ñ‰ª¨Â∞±‰º?x®¨)ÁªìÊùüÁîüÂëΩÂë®Êúü„Ä?/span>
2) SessionÊñ“é(gu®©)≥ïËÉΩ§ü‰ªéÁºìÂ≠ò‰(sh®¥)∏≠ÂàÝÈô§‰∏ĉ∏™ÊåʼnπÖÂåñÂØπ˱°ÂQå‰ã…ÂÆÉÂèò?sh®¥)∏¯ôѱΩé°Áä∂ÊÄÅÔºåÂΩ?/span>SessionÊñ“é(gu®©)≥ïÂQ剪éæ~ìÂ≠ò?sh®¥)∏≠ÂàÝÈô§‰∏ĉ∫õÊåʼnπÖÂåñÂØπ˱°„ÄljΩÜÊòاöÊï∞ÊÉÖÂܵ‰∏ã‰∏çÊé®Ëçê‰ã…Áî®ËØ•Êñ“é(gu®©)≥ïÂQåËÄåÂ∫îËØ•ÈÄöËøáÊü•ËØ¢ËØ≠Ë®ÄÂQåÊàñËÄÖÊòæΩC∫ÁöÑÂØ∆Dà™Êù•ÊéßÂà∂ÂØπ˱°ÂõæÁöÑÊ∑±Â∫¶„Ä?/span>
1.ÂÆâË£ÖRoseÂê?ȪòËƧÊòØÈúÄ˶ÅËÆ∏ÂèØËØʼnπ¶ÁöÑ..Âé÷M∏ãËΩΩ‰∏™ÁÝ¥ËߣÁö?.Êàë‰∏䉺݉∫Ü(ji®£n)ÁÝ¥ËߣÊñá‰ög..ÁÇπÂáªòqôÈáå‰∏ãËù≤Rose 2003ÁÝ¥Ëߣ
2.ÂÖàÁî®ÁÝ¥ËߣÂéãÁæÉÂåÖÈáåÁö?rational.exeÂQålmgrd.exe ˶ÜÁõñÂàÓCΩÝÁö?\ÂÆâË£ÖÁõÆÂΩïÁöÑRartional\commen\‰∏?br />
3.ÁÑ∂ÂêéËÆÓC∫ãÊú¨Êâì开 license.dat, ‰øÆÊîπÈáåÈù¢Áö?SERVER yourPC ANY DAEMON rational "C:\Program Files\Rational\Common\rational.exe"
Êî“é(gu®©)àê SERVER ‰ΩÝÁöÑÊú∫Âô®Âê?ANY DAEMON rational "‰ΩÝÁöÑÂÆâË£ÖÁõÆÂΩï\rational.exe" ,ÊãØÇ¥ùÂà∞CommonÁõÆÂΩï‰∏?.
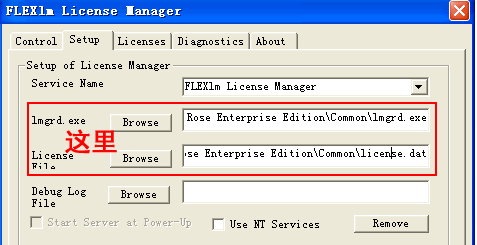
4. ûÆÜFlexlm.cplÊãØÇ¥ùÂà∞C:\winnt\system32\‰∏ãÔºå Âú®ÊéßÂàâôù¢ÊùâKáåòqêË°å FlexLm License ManagerÂQ?nbsp;
òqêË°åÂê? Âú?Setup Èù¢ÊùøÈÖçÁΩÆÊñá‰ögË∑ØÂæÑÂQålmgrd.exe -> ‰ΩÝÁöÑÂÆâË£ÖÁõÆÂΩï \Common\lmgrd.exe, ËÄ?License File ‰∏ÞZΩÝÊîπËøáÁö?license.dat ...
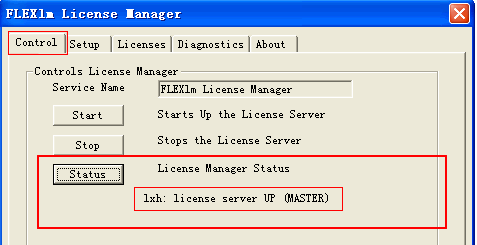
5.Âú®ControlÈù¢ÊùøÁÇπÂáªStartÂQå¶ÇÊûúÊàêÂäüÁöÑËØùÁÇπÂáªStatusÊåâÈíÆûÆÜÊòæΩC?‰ΩÝÁöÑÊú∫Âô®ÂêçÔºö(x®¨)license server UP (MASTER) ËØ¥ÊòéÊàêÂäü‰∫?
§Þp”|ÁöÑËØùÈáçÂê؉∏ĉ∏ãFlexLm License ManagerûƱÊ≤°ÈóÆÈ¢ò?sh®¥)∫Ü(ji®£n)„Ä?nbsp;
6.¶ÇÊûúºπÂá∫ÂØπËØùÊ°ÜLicense Key Administrator WizardÂê? ÈÄâÂÆöPoint to a Rational License Server to get my licensesÂQåÂçïÂá÷M∏ã‰∏ÄÊ≠•Ôºå
Server NameÊñáÊú¨Ê°Ü‰∏≠°´ÂÜô‰ΩÝÁöÑÊú∫Âô®Âè?ÂèØËÉΩÂ∑≤Áªè°´Â•Ω)ÂQåÂçïÂá’dÆåÊàê„Ä?(ÊàêÂäüÁöÑËØù‰º?x®¨)Âá∫ÁéÓC∏§Â±èÁöÑlicenses)
Ê≥®ÊÑèÂQöÊú¨ÊñáËù{ËáªIºö(x®¨)http://www.cnblogs.com/lixianhuei/archive/2006/01/09/313644.html
with rollup „Ä?/span>with cube„Ä?/span>grouping CUBE Âí?ROLLUP ‰πãÈó¥ÁöÑÂå∫Âà´Âú®‰∫éÔºö(x®¨) CUBE ÁîüÊàêÁöÑÁªìÊûúÈõÜÊòÑ°§∫‰∫?ji®£n)ÊâÄÈÄâÂàó‰∏≠ÂĺÁöÑÊâÄÊúâÁªÑÂêàÁöÑËÅöÂêà„Ä? ROLLUP ÁîüÊàêÁöÑÁªìÊûúÈõÜÊòÑ°§∫‰∫?ji®£n)ÊâÄÈÄâÂàó‰∏≠ÂĺÁöÑÊüê‰∏ıÇʨ°ælìÊûÑÁöÑËÅöÂêà„Ä? grouping: ÂΩìÁî® CUBE Êà?ROLLUP òqêÁÆóΩW¶Ê∑ªÂäÝË°åÊó”ûºåÈôÑÂäÝÁöÑÂàóËæìÂá∫ÂÄÈgÿì(f®¥)1ÂQåÂΩìÊâÄÊ∑’däÝÁöÑË°å‰∏çÊòØÁî?CUBE Êà?ROLLUP ‰∫ßÁîüÊó”ûºåÈôÑÂäÝÂàóÂÄÈgÿì(f®¥)0„Ä? --‰æã如 DECLARE @T TABLE(ÂêçÁß∞ VARCHAR(1) , Âá∫ÁâàÂï?VARCHAR(10), ‰ª‰hݺ1 INT, ‰ª‰hݺ2 INT) INSERT @T SELECT 'a', 'Âåó‰∫¨', 11, 22 UNION ALL SELECT 'a', 'ÂõõÂ∑ù', 22, 33 UNION ALL SELECT 'b', 'ÂõõÂ∑ù', 12, 23 UNION ALL SELECT 'b', 'Âåó‰∫¨', 10, 20 UNION ALL SELECT 'b', 'ÊòÜÊòé', 20, 30 SELECT ÂêçÁß∞, Âá∫ÁâàÂï? SUM(‰ª‰hݺ1) AS ‰ª‰hݺ1, SUM(‰ª‰hݺ2) AS ‰ª‰hݺ2, GROUPING(ÂêçÁß∞) AS CHECKÂêçÁß∞, GROUPING(Âá∫ÁâàÂï? AS CHECKÂá∫ÁâàÂï? FROM @T GROUP BY ÂêçÁß∞,Âá∫ÁâàÂï?WITH CUBE /* ÂêçÁß∞ Âá∫ÁâàÂï? ‰ª‰hݺ1 ‰ª‰hݺ2 CHECKÂêçÁß∞ CHECKÂá∫ÁâàÂï? ---- ---------- ----------- ----------- ------- -------- a Âåó‰∫¨ 11 22 0 0 a ÂõõÂ∑ù 22 33 0 0 a NULL 33 55 0 1 b Âåó‰∫¨ 10 20 0 0 b ÊòÜÊòé 20 30 0 0 b ÂõõÂ∑ù 12 23 0 0 b NULL 42 73 0 1 NULL NULL 75 128 1 1 NULL Âåó‰∫¨ 21 42 1 0 NULL ÊòÜÊòé 20 30 1 0 NULL ÂõõÂ∑ù 34 56 1 0 ÂQàÊâÄÂΩ±ÂìçÁöÑË°åÊïÓCÿì(f®¥) 11 Ë°åÔºâ(j®™) */ --ÂàÜÊûê /*group by ‰∏§ÂàóÂQöÂêçøU∞Êúâ‰∏§‰∏™æc’dà´A,B;ÊâÄÊúâÁî±CUBEòqêÁÆóËÄåÁîüÊàêË°åÁöÑÊòØ ÂêçÁß∞ Âá∫ÁâàÂï? ‰ª‰hݺ1 ‰ª‰hݺ2 CHECKÂêçÁß∞ CHECKÂá∫ÁâàÂï? ---- ---------- ----------- ----------- ------- -------- a NULL 33 55 0 1 b NULL 42 73 0 1 Âá∫ÁâàÂïÜÊúâ‰∏â‰∏™æc’dà´ÂQåÊâÄÊúâÁî±CUBEòqêÁÆóËÄåÁîüÊàêË°åÁöÑÊòØ ÂêçÁß∞ Âá∫ÁâàÂï? ‰ª‰hݺ1 ‰ª‰hݺ2 CHECKÂêçÁß∞ CHECKÂá∫ÁâàÂï? ---- ---------- ----------- ----------- ------- -------- NULL Âåó‰∫¨ 21 42 1 0 NULL ÊòÜÊòé 20 30 1 0 NULL ÂõõÂ∑ù 34 56 1 0 ‰ª•Âèä(qi®¢ng) NULL NULL 75 128 1 1 */ SELECT ÂêçÁß∞, Âá∫ÁâàÂï? SUM(‰ª‰hݺ1) AS ‰ª‰hݺ1, SUM(‰ª‰hݺ2) AS ‰ª‰hݺ2 FROM @T GROUP BY ÂêçÁß∞,Âá∫ÁâàÂï?WITH ROLLUP /* ÂêçÁß∞ Âá∫ÁâàÂï? ‰ª‰hݺ1 ‰ª‰hݺ2 ---- ---------- ----------- ----------- a Âåó‰∫¨ 11 22 a ÂõõÂ∑ù 22 33 a NULL 33 55 b Âåó‰∫¨ 10 20 b ÊòÜÊòé 20 30 b ÂõõÂ∑ù 12 23 b NULL 42 73 NULL NULL 75 128 */