Table
Table用來定義entity主表的name,catalog,schema等屬性。
元數(shù)據(jù)屬性說明:
- name: 表名
- catalog: 對應關(guān)系數(shù)據(jù)庫中的catalog
- schema:對應關(guān)系數(shù)據(jù)庫中的schema
- UniqueConstraints:定義一個UniqueConstraint數(shù)組,指定需要建唯一約束的列
@Entity
@Table(name="CUST")
public class Customer { ... }
SecondaryTable
一個entity class可以映射到多表,SecondaryTable用來定義單個從表的名字,主鍵名字等屬性。
元數(shù)據(jù)屬性說明:
- name: 表名
- catalog: 對應關(guān)系數(shù)據(jù)庫中的catalog
- schema:對應關(guān)系數(shù)據(jù)庫中的schema
- pkJoin: 定義一個PrimaryKeyJoinColumn數(shù)組,指定從表的主鍵列
- UniqueConstraints:定義一個UniqueConstraint數(shù)組,指定需要建唯一約束的列
下面的代碼說明Customer類映射到兩個表,主表名是CUSTOMER,從表名是CUST_DETAIL,從表的主鍵列和主表的主鍵列類型相同,列名為CUST_ID。
@Entity
@Table(name="CUSTOMER")
@SecondaryTable(name="CUST_DETAIL",pkJoin=@PrimaryKeyJoinColumn(name="CUST_ID"))
public class Customer { ... }
SecondaryTables
當一個entity class映射到一個主表和多個從表時,用SecondaryTables來定義各個從表的屬性。
元數(shù)據(jù)屬性說明:
- value: 定義一個SecondaryTable數(shù)組,指定每個從表的屬性。
@Table(name = "CUSTOMER")
@SecondaryTables( value = {
@SecondaryTable(name = "CUST_NAME", pkJoin = { @PrimaryKeyJoinColumn(name = "STMO_ID", referencedColumnName = "id") }),
@SecondaryTable(name = "CUST_ADDRESS", pkJoin = { @PrimaryKeyJoinColumn(name = "STMO_ID", referencedColumnName = "id") }) })
public class Customer {}
UniqueConstraint
UniqueConstraint定義在Table或SecondaryTable元數(shù)據(jù)里,用來指定建表時需要建唯一約束的列。
元數(shù)據(jù)屬性說明:
- columnNames:定義一個字符串數(shù)組,指定要建唯一約束的列名。
@Entity
@Table(name="EMPLOYEE",
uniqueConstraints={@UniqueConstraint(columnNames={"EMP_ID", "EMP_NAME"})}
)
public class Employee { ... }
Column
Column元數(shù)據(jù)定義了映射到數(shù)據(jù)庫的列的所有屬性:列名,是否唯一,是否允許為空,是否允許更新等。
元數(shù)據(jù)屬性說明:
- name:列名。
- unique: 是否唯一
- nullable: 是否允許為空
- insertable: 是否允許插入
- updatable: 是否允許更新
- columnDefinition: 定義建表時創(chuàng)建此列的DDL
- secondaryTable: 從表名。如果此列不建在主表上(默認建在主表),該屬性定義該列所在從表的名字。
public class Person {
@Column(name = "PERSONNAME", unique = true, nullable = false, updatable = true)
private String name;
@Column(name = "PHOTO", columnDefinition = "BLOB NOT NULL", secondaryTable="PER_PHOTO")
private byte[] picture;
JoinColumn
如果在entity class的field上定義了關(guān)系(one2one或one2many等),我們通過JoinColumn來定義關(guān)系的屬性。JoinColumn的大部分屬性和Column類似。
元數(shù)據(jù)屬性說明:
- name:列名。
- referencedColumnName:該列指向列的列名(建表時該列作為外鍵列指向關(guān)系另一端的指定列)
- unique: 是否唯一
- nullable: 是否允許為空
- insertable: 是否允許插入
- updatable: 是否允許更新
- columnDefinition: 定義建表時創(chuàng)建此列的DDL
- secondaryTable: 從表名。如果此列不建在主表上(默認建在主表),該屬性定義該列所在從表的名字。
下面的代碼說明Custom和Order是一對一關(guān)系。在Order對應的映射表建一個名為CUST_ID的列,該列作為外鍵指向Custom對應表中名為ID的列。
public class Custom {
@OneToOne
@JoinColumn(
name="CUST_ID", referencedColumnName="ID", unique=true, nullable=true, updatable=true)
public Order getOrder() {
return order;
}
JoinColumns
如果在entity class的field上定義了關(guān)系(one2one或one2many等),并且關(guān)系存在多個JoinColumn,用JoinColumns定義多個JoinColumn的屬性。
元數(shù)據(jù)屬性說明:
- value: 定義JoinColumn數(shù)組,指定每個JoinColumn的屬性。
下面的代碼說明Custom和Order是一對一關(guān)系。在Order對應的映射表建兩列,一列名為CUST_ID,該列作為外鍵指向Custom對應表中名為ID的列,另一列名為CUST_NAME,該列作為外鍵指向Custom對應表中名為NAME的列。
public class Custom {
@OneToOne
@JoinColumns({
@JoinColumn(name="CUST_ID", referencedColumnName="ID"),
@JoinColumn(name="CUST_NAME", referencedColumnName="NAME")
})
public Order getOrder() {
return order;
}
Id
聲 明當前field為映射表中的主鍵列。id值的獲取方式有五種:TABLE, SEQUENCE, IDENTITY, AUTO, NONE。Oracle和DB2支持SEQUENCE,SQL Server和Sybase支持IDENTITY,mysql支持AUTO。所有的數(shù)據(jù)庫都可以指定為AUTO,我們會根據(jù)不同數(shù)據(jù)庫做轉(zhuǎn)換。NONE (默認)需要用戶自己指定Id的值。元數(shù)據(jù)屬性說明:
- generate():主鍵值的獲取類型
- generator():TableGenerator的名字(當generate=GeneratorType.TABLE才需要指定該屬性)
下面的代碼聲明Task的主鍵列id是自動增長的。(Oracle和DB2從默認的SEQUENCE取值,SQL Server和Sybase該列建成IDENTITY,mysql該列建成auto increment。)
@Entity
@Table(name = "OTASK")
public class Task {
@Id(generate = GeneratorType.AUTO)
public Integer getId() {
return id;
}
}
IdClass
當entity class使用復合主鍵時,需要定義一個類作為id class。id class必須符合以下要求:類必須聲明為public,并提供一個聲明為public的空構(gòu)造函數(shù)。必須實現(xiàn)Serializable接,覆寫 equals()和hashCode()方法。entity class的所有id field在id class都要定義,且類型一樣。
元數(shù)據(jù)屬性說明:
- value: id class的類名
public class EmployeePK implements java.io.Serializable{
String empName;
Integer empAge;
public EmployeePK(){}
public boolean equals(Object obj){ ......}
public int hashCode(){......}
}
@IdClass(value=com.acme.EmployeePK.class)
@Entity(access=FIELD)
public class Employee {
@Id String empName;
@Id Integer empAge;
}
MapKey
在一對多,多對多關(guān)系中,我們可以用Map來保存集合對象。默認用主鍵值做key,如果使用復合主鍵,則用id class的實例做key,如果指定了name屬性,就用指定的field的值做key。
元數(shù)據(jù)屬性說明:
- name: 用來做key的field名字
下面的代碼說明Person和Book之間是一對多關(guān)系。Person的books字段是Map類型,用Book的isbn字段的值作為Map的key。
@Table(name = "PERSON")
public class Person {
@OneToMany(targetEntity = Book.class, cascade = CascadeType.ALL, mappedBy = "person")
@MapKey(name = "isbn")
private Mapbooks = new HashMap ();
}
OrderBy
在一對多,多對多關(guān)系中,有時我們希望從數(shù)據(jù)庫加載出來的集合對象是按一定方式排序的,這可以通過OrderBy來實現(xiàn),默認是按對象的主鍵升序排列。
元數(shù)據(jù)屬性說明:
- value: 字符串類型,指定排序方式。格式為"fieldName1 [ASC|DESC],fieldName2 [ASC|DESC],......",排序類型可以不指定,默認是ASC。
下面的代碼說明Person和Book之間是一對多關(guān)系。集合books按照Book的isbn升序,name降序排列。
@Table(name = "MAPKEY_PERSON")
public class Person {
@OneToMany(targetEntity = Book.class, cascade = CascadeType.ALL, mappedBy = "person")
@OrderBy(name = "isbn ASC, name DESC")
private Listbooks = new ArrayList ();
}
PrimaryKeyJoinColumn
在三種情況下會用到PrimaryKeyJoinColumn。
- 繼承。
- entity class映射到一個或多個從表。從表根據(jù)主表的主鍵列(列名為referencedColumnName值的列),建立一個類型一樣的主鍵列,列名由name屬性定義。
- one2one關(guān)系,關(guān)系維護端的主鍵作為外鍵指向關(guān)系被維護端的主鍵,不再新建一個外鍵列。
元數(shù)據(jù)屬性說明:
- name:列名。
- referencedColumnName:該列引用列的列名
- columnDefinition: 定義建表時創(chuàng)建此列的DDL
下面的代碼說明Customer映射到兩個表,主表CUSTOMER,從表CUST_DETAIL,從表需要建立主鍵列CUST_ID,該列和主表的主鍵列id除了列名不同,其他定義一樣。
@Entity
@Table(name="CUSTOMER")
@SecondaryTable(name="CUST_DETAIL",pkJoin=@PrimaryKeyJoinColumn(name="CUST_ID",referencedColumnName="id"))
public class Customer {
@Id(generate = GeneratorType.AUTO)
public Integer getId() {
return id;
}
}
下面的代碼說明Employee和EmployeeInfo是一對一關(guān)系,Employee的主鍵列id作為外鍵指向EmployeeInfo的主鍵列INFO_ID。
@Table(name = "Employee")
public class Employee {
@OneToOne
@PrimaryKeyJoinColumn(name = "id", referencedColumnName="INFO_ID")
EmployeeInfo info;
}
PrimaryKeyJoinColumns
如果entity class使用了復合主鍵,指定單個PrimaryKeyJoinColumn不能滿足要求時,可以用PrimaryKeyJoinColumns來定義多個PrimaryKeyJoinColumn。
元數(shù)據(jù)屬性說明:
- value: 一個PrimaryKeyJoinColumn數(shù)組,包含所有PrimaryKeyJoinColumn。
下面的代碼說明了Employee和EmployeeInfo是一對一關(guān)系。他們都使用復合主鍵,建表時需要在Employee表建立一個外鍵,從Employee的主鍵列id,name指向EmployeeInfo的主鍵列INFO_ID和INFO_NAME.
@Entity
@IdClass(EmpPK.class)
@Table(name = "EMPLOYEE")
public class Employee {
private int id;
private String name;
private String address;
@OneToOne(cascade = CascadeType.ALL)
@PrimaryKeyJoinColumns({
@PrimaryKeyJoinColumn(name="id", referencedColumnName="INFO_ID"),
@PrimaryKeyJoinColumn(name="name" , referencedColumnName="INFO_NAME")})
EmployeeInfo info;
}
@Entity
@IdClass(EmpPK.class)
@Table(name = "EMPLOYEE_INFO")
public class EmployeeInfo {
@Id
@Column(name = "INFO_ID")
private int id;
@Id
@Column(name = "INFO_NAME")
private String name;
}
Version
Version指定實體類在樂觀事務中的version屬性。在實體類重新由EntityManager管理并且加入到樂觀事務中時,保證完整性。每一個類只能有一個屬性被指定為version,version屬性應該映射到實體類的主表上。
下面的代碼說明versionNum屬性作為這個類的version,映射到數(shù)據(jù)庫中主表的列名是OPTLOCK。
@Version
@Column("OPTLOCK")
protected int getVersionNum() { return versionNum; }
Lob
Lob指定一個屬性作為數(shù)據(jù)庫支持的大對象類型在數(shù)據(jù)庫中存儲。使用LobType這個枚舉來定義Lob是二進制類型還是字符類型。
LobType枚舉類型說明:
- BLOB 二進制大對象,Byte[]或者Serializable的類型可以指定為BLOB。
- CLOB 字符型大對象,char[]、Character[]或String類型可以指定為CLOB。
元數(shù)據(jù)屬性說明:
- fetch: 定義這個字段是lazy loaded還是eagerly fetched。數(shù)據(jù)類型是FetchType枚舉,默認為LAZY,即lazy loaded.
- type: 定義這個字段在數(shù)據(jù)庫中的JDBC數(shù)據(jù)類型。數(shù)據(jù)類型是LobType枚舉,默認為BLOB。
下面的代碼定義了一個BLOB類型的屬性和一個CLOB類型的屬性。
@Lob
@Column(name="PHOTO" columnDefinition="BLOB NOT NULL")
protected JPEGImage picture;
@Lob(fetch=EAGER, type=CLOB)
@Column(name="REPORT")
protected String report;
JoinTable
JoinTable在many-to-many關(guān)系的所有者一邊定義。如果沒有定義JoinTable,使用JoinTable的默認值。
元數(shù)據(jù)屬性說明:
- table:這個join table的Table定義。
- joinColumns:定義指向所有者主表的外鍵列,數(shù)據(jù)類型是JoinColumn數(shù)組。
- inverseJoinColumns:定義指向非所有者主表的外鍵列,數(shù)據(jù)類型是JoinColumn數(shù)組。
下面的代碼定義了一個連接表CUST和PHONE的join table。join table的表名是CUST_PHONE,包含兩個外鍵,一個外鍵是CUST_ID,指向表CUST的主鍵ID,另一個外鍵是PHONE_ID,指向表PHONE的主鍵ID。
@JoinTable(
table=@Table(name=CUST_PHONE),
joinColumns=@JoinColumn(name="CUST_ID", referencedColumnName="ID"),
inverseJoinColumns=@JoinColumn(name="PHONE_ID", referencedColumnName="ID")
)
TableGenerator
TableGenerator定義一個主鍵值生成器,在Id這個元數(shù)據(jù)的generate=TABLE時,generator屬性中可以使用生成器的名字。生成器可以在類、方法或者屬性上定義。
生成器是為多個實體類提供連續(xù)的ID值的表,每一行為一個類提供ID值,ID值通常是整數(shù)。
元數(shù)據(jù)屬性說明:
- name:生成器的唯一名字,可以被Id元數(shù)據(jù)使用。
- table:生成器用來存儲id值的Table定義。
- pkColumnName:生成器表的主鍵名稱。
- valueColumnName:生成器表的ID值的列名稱。
- pkColumnValue:生成器表中的一行數(shù)據(jù)的主鍵值。
- initialValue:id值的初始值。
- allocationSize:id值的增量。
下面的代碼定義了兩個生成器empGen和addressGen,生成器的表是ID_GEN。
@Entity public class Employee {
...
@TableGenerator(name="empGen",
table=@Table(name="ID_GEN"),
pkColumnName="GEN_KEY",
valueColumnName="GEN_VALUE",
pkColumnValue="EMP_ID",
allocationSize=1)
@Id(generate=TABLE, generator="empGen")
public int id;
...
}
@Entity public class Address {
...
@TableGenerator(name="addressGen",
table=@Table(name="ID_GEN"),
pkColumnValue="ADDR_ID")
@Id(generate=TABLE, generator="addressGen")
public int id;
...
}
SequenceGenerator
SequenceGenerator定義一個主鍵值生成器,在Id這個元數(shù)據(jù)的generator屬性中可以使用生成器的名字。生成器可以在類、方法或者屬性上定義。生成器是數(shù)據(jù)庫支持的sequence對象。
元數(shù)據(jù)屬性說明:
- name:生成器的唯一名字,可以被Id元數(shù)據(jù)使用。
- sequenceName:數(shù)據(jù)庫中,sequence對象的名稱。如果不指定,會使用提供商指定的默認名稱。
- initialValue:id值的初始值。
- allocationSize:id值的增量。
下面的代碼定義了一個使用提供商默認名稱的sequence生成器。
@SequenceGenerator(name="EMP_SEQ", allocationSize=25)
DiscriminatorColumn
DiscriminatorColumn定義在使用SINGLE_TABLE或JOINED繼承策略的表中區(qū)別不繼承層次的列。
元數(shù)據(jù)屬性說明:
- name:column的名字。默認值為TYPE。
- columnDefinition:生成DDL的sql片斷。
- length:String類型的column的長度,其他類型使用默認值10。
下面的代碼定義了一個列名為DISC,長度為20的String類型的區(qū)別列。
@Entity
@Table(name="CUST")
@Inheritance(strategy=SINGLE_TABLE,
discriminatorType=STRING,
discriminatorValue="CUSTOMER")
@DiscriminatorColumn(name="DISC", length=20)
public class Customer { ... }
1.盡量使用many-to-one,避免使用單項one-to-many
2.靈活使用單向one-to-many
3.不用一對一,使用多對一代替一對一
4.配置對象緩存,不使用集合緩存
5.一對多使用Bag 多對一使用Set
6.繼承使用顯示多態(tài) HQL:from object polymorphism="exlicit" 避免查處所有對象
7.消除大表,使用二級緩存
對于上面這些,Robbin進行了詳細的講解。
one-to-many:
使用inverse=false(default),對象的關(guān)聯(lián)關(guān)系是由parent對象來維護的
而inverse=true的情況下,一般用戶雙向多對多關(guān)聯(lián),由子對象維護關(guān)聯(lián)關(guān)系,增加子對象的時候需要顯示:child.setParent(child)
為了提高性能,應該盡量使用雙向one-to-many inverse=true,在MVC結(jié)構(gòu)中的DAO接口中應該直接用Session持久化對象,避免通過關(guān)聯(lián)關(guān)系(這句話有點不理解),而在單項關(guān)系中正確使用二級緩存,則可以大幅提高以查詢?yōu)橹鞯膽谩?br>
多對一性能問題比較少,但是要避免經(jīng)典N+1問題。
通過主鍵進行關(guān)聯(lián),相當于大表拆分小表。(這個是區(qū)分面向?qū)ο笤O(shè)計和面向過程設(shè)計的一個關(guān)鍵點)
list、bag、set的正確運用
one-to-many:
A、使用list 需要維護Index Column字段,不能被用于雙向關(guān)聯(lián),而且必須使用inverse=false,需要謹慎使用在某些稀有場合(基本上是不予考慮使用)
B、bag/set在one-to-many中語義基本相同,推薦使用bag
many-to-one:
A、bag和set不同,bag允許重復插入,建議使用set
在龐大的集合分頁中應該使用session.createFilter
session.createFilter(parent.getChildren(),""),setFirstResult(0),setMaxResult(10))
避免N+1 參考(http://www.javaeye.com/post/266972)
在多對一的情況下,查詢child對象,當在頁面上顯示每個子類的父類對象的時候會導致N+1次查詢,需要采用下面的方法避免:many-to-one fetch="join|select"(該方法可能有問題)
inverse=true 無法維護集合緩存(還不是很理解集合緩存和對象緩存)
OLTP類型的web應用,可以群集水平擴展,不可避免的出現(xiàn)數(shù)據(jù)庫瓶頸
框架能降低訪問數(shù)據(jù)庫的壓力,采用緩存是衡量一個框架是否優(yōu)秀的重要標準,從緩存方面看Hibernate
A、對象緩存,細顆粒度,是針對表的級別,透明化訪問,因為有不改變代碼的好處,所以是ORM提高性能的法寶
B、Hibernate是目前ORM框架中緩存性能最好的框架
C、查詢緩存
最后Robbin還針對大家經(jīng)常出現(xiàn)的Hibernate vs iBatis的討論進行了一個總結(jié):
對于OLTP應用,使用ORM框架 而OLEB應用(不確定是什么應用)最好采用JDBC或者其他方法處理
Hibernate傾向于細顆粒度設(shè)計,面向?qū)ο螅瑢⒋蟊聿鸱譃槎鄠€小表,消除冗余字段,通過二級緩存提升性能。
iBatis傾向于粗顆粒度設(shè)計,面向關(guān)系,盡量把表合并,通過Column冗余,消除關(guān)聯(lián)關(guān)系,但是iBatis沒有有效的緩存手段。
web.xml?
// 這里不需要配置字符過濾,網(wǎng)上有的例子加了,實際上
webwork.properties里設(shè)置如下就可以了頁面也是GBK
webwork.locale=zh_CN
webwork.i18n.encoding=GBK
---------------------------
???????? "http://java.sun.com/dtd/web-app_2_3.dtd" >
< web-app >
?? < context-param >
????? < param-name > contextConfigLocation </ param-name >
???? < param-value > /WEB-INF/classes/applicationContext.xml </ param-value >
? </ context-param >
? < listener >
?? < listener-class >
???? org.springframework.web.context.ContextLoaderListener
?? </listener-class>
?</listener>
?<listener>
??<listener-class>
???? com.atlassian.xwork.ext.ResolverSetupServletContextListener
?? </listener-class>
?</listener>
????<!--
????<servlet>
????<servlet-name>context</servlet-name>
?????????????<servlet-class>
??????????????? org.springframework.web.context.ContextLoaderServlet
???????????? </servlet-class>
?????????????<load-on-startup>1</load-on-startup>
?????</servlet>
?????-->
????<servlet>
????????<servlet-name>webwork</servlet-name>
????????<servlet-class>
??????????? com.opensymphony.webwork.dispatcher.ServletDispatcher
???????? </servlet-class>
????????<load-on-startup>3</load-on-startup>
????</servlet>
?<servlet>
??<servlet-name>freemarker</servlet-name>
??<servlet-class>
????? com.opensymphony.webwork.views.freemarker.FreemarkerServlet
?? </servlet-class>
??<load-on-startup>10</load-on-startup>
?</servlet>
????<servlet-mapping>
????????<servlet-name>webwork</servlet-name>
????????<url-pattern>*.action</url-pattern>
????</servlet-mapping>
?<servlet-mapping>
??<servlet-name>freemarker</servlet-name>
??<url-pattern>*.ftl</url-pattern>
?</servlet-mapping>
????<welcome-file-list>
????????<welcome-file>index.html</welcome-file>
????</welcome-file-list>
????<taglib>
????????<taglib-uri>webwork</taglib-uri>
????????<taglib-location>/WEB-INF/webwork.tld</taglib-location>
????</taglib>
</web-app>
---------------------------
xwork.xml
==================---------------------------------------------
<! DOCTYPE?xwork?PUBLIC?"-//OpenSymphony?Group//XWork?1.0//EN"
????????? "http://www.opensymphony.com/xwork/xwork-1.0.dtd" >
< xwork >
?? < include? file ="webwork-default.xml" />
???? < package? name ="users" ?extends ="webwork-default"
????????externalReferenceResolver =
?????????????????????? "com.atlassian.xwork.ext.SpringServletContextReferenceResolver" >
???????? < interceptors >
???????????? < interceptor? name ="reference-resolver"
?????????????? class ="com.opensymphony.xwork.interceptor.ExternalReferencesInterceptor" />
???????????? < interceptor-stack? name ="myDefaultWebStack" >
???????????????? < interceptor-ref? name ="defaultStack" />
???????????????? < interceptor-ref? name ="reference-resolver" />
???????????????? < interceptor-ref? name ="model-driven" />
??????? < interceptor-ref? name ="params" />
???????????? </ interceptor-stack >
???????? </ interceptors >
< default-interceptor-ref? name ="myDefaultWebStack" />
???????? < action? name ="blogUser" ?class ="com.jsblog.action.BlogUserAction" >
??? < external-ref? name ="baseDao" > baseDaoTarget </ external-ref > ????
??? //這里是把applicationContext里配置的DAO?注入action里?action里要有baseDao屬性
??? < result? name ="success" > /add.htm </ result >
?? </ action >
-------------------------------------------------------------------------
applicationContext.xml
---------------------------------------------------------------------------
<! DOCTYPE?beans?PUBLIC?"-//SPRING//DTD?BEAN//EN"
?????????? "http://www.springframework.org/dtd/spring-beans.dtd" >
< beans? default-autowire ="no" ?default-dependency-check ="none"
? ? ? ?? default-lazy-init ="false" >
???? < bean? id ="dataSource" ?class ="org.apache.commons.dbcp.BasicDataSource"?
???????? destroy-method="close">
????????<property?name="driverClassName">
????????????<value>com.microsoft.jdbc.sqlserver.SQLServerDriver</value>
????????</property>
????????<property?name="url">
????????????<value>
????????????? jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=jsblog;SelectMethod=cursor
??????????? </value>
????????</property>
????????<property?name="username">
????????????<value>sa</value>
????????</property>
????????<property?name="password">
????????????<value>jfy</value>
????????</property>
????</bean>
????<bean?id="sessionFactory"
??????????class="org.springframework.orm.hibernate.LocalSessionFactoryBean">
????????<property?name="dataSource">
????????????<ref?local="dataSource"/>
????????</property>
????????<property?name="mappingResources">
????????????<list>
????????????????<value>com/jsblog/BlogUserForm.hbm.xml</value>
????????????</list>
????????</property>
????????<property?name="hibernateProperties">
????????????<props>
????????????????<prop?key="hibernate.dialect">
????????????????????net.sf.hibernate.dialect.SQLServerDialect
????????????????</prop>
????????????????<prop?key="hibernate.show_sql">true</prop>
????????????</props>
????????</property>
????</bean>
????<bean?id="transactionManager"
??????????class="org.springframework.orm.hibernate.HibernateTransactionManager">
????????<property?name="sessionFactory">
????????????<ref?local="sessionFactory"/>
????????</property>
????</bean>
????<bean?id="baseDaoTarget"?class="com.jsblog.dao.BlogUserDao">
????????<property?name="sessionFactory">
????????????<ref?local="sessionFactory"/>
????????</property>
????</bean>
</beans>
---------------------------------------------------------------------------
BlogUserDao.java
---------------------------------------------------------------------------
import ?org.springframework.orm.hibernate.support.HibernateDaoSupport;
import ?org.springframework.orm.hibernate.HibernateCallback;
import ?org.springframework.orm.hibernate.SessionFactoryUtils;
import ?com.jsblog.BlogUserForm;
import ?java.io.Serializable;
import ?java.util.List;
import ?net.sf.hibernate.HibernateException;
import ?net.sf.hibernate.Session;
public ? class ?BlogUserDao? extends ?HibernateDaoSupport? implements ?BaseDao?{
???? public ? void ?insert(BlogUserForm?bloguser)?{
????????getHibernateTemplate().save(bloguser);
????}
}
Hibernate 和 Spring 這兩個突出的開源框架被越來越多的應用到 J2EE 中。盡管目標有著不同的問題空間,它們卻共享一個關(guān)鍵特性:依賴注入。
在對象返回到客戶端之前 Spring 協(xié)助挑選出這些對象間依賴關(guān)系,減少客戶端代碼量。而 Hibernate
專門挑選出在完整的對象模型返回客戶端之前由數(shù)據(jù)模型表現(xiàn)的依賴關(guān)系。當使用 JDBC
直接從數(shù)據(jù)模型映射到對象模型時,我們通常需要書寫大量的代碼來構(gòu)建對象模型。Hibernate 的出現(xiàn)淘汰了這種繁瑣的編碼工作。
Hibernate 2.x 提供基本的表到對象的映射,標準關(guān)聯(lián)映射(包括 one-to-one, one-to-many 以及
many-to-many 關(guān)系),多態(tài)映射,等等。Hibernate 3.x
沿著路線繼續(xù)前進,formula、filter、subselect 等,使映射更加靈活,提供用細粒度的解釋特性。
在本文中,將闡述 formula 到底有哪些特性可幫助我們進行模型轉(zhuǎn)換。Hibernate 3.x 之前,formula 屬性只能出現(xiàn)在
property 元素中。但是到了現(xiàn)在,你可以在許多元素中使用 Hibernate 3.x 提供的 formula 屬性或元素(formula
用法方面都是一樣的),包括
discriminator、element、many-to-many、map-key、map-key-many-to-many、以及
property。它增加了 OR 映射的靈活性,因此允許對復雜數(shù)據(jù)模型更加細粒的解釋。
下面有兩個 formula 應用場景:
1. formula 用于評估結(jié)果的場合。在 discriminator、element、map-key、map-key-many-to-many以及 property 元素中注入 formula。
2. formula 用于連接目的的場合。在 many-to-one、one-to-one 以及 many-to-many 元素中注入 formula。
范疇 1:從 formula 獲得評估結(jié)果
Discriminator
在真實的數(shù)據(jù) schema 中,經(jīng)常出現(xiàn)一個表被用于描述其他表的情況。formula 可協(xié)助提供靈活的多態(tài) OR 映射。
在圖 1 的范例中,有兩個表:Product 和 ProductRelease。每條 product 記錄都有一個
ProductReleaseID 參考相應的產(chǎn)品出廠記錄,包括 product release name、type、release date
等等。

圖 1. Product 和 product release
ProductRelease 表中有個有趣的屬性 SubProductAllowable,該屬性的值為 1 或 0。值為 1 代表允許任何的次品出廠,但是 0 不允許次品出廠。
圖 2 展示了由數(shù)據(jù)模型解釋的對象模型。Nested 接口定義了 getSubProducts 和 setSubProducts
方法。NestedProduct 類繼承 Product 基類并實現(xiàn) Nested 接口。無論產(chǎn)品數(shù)據(jù)記錄是 Product 或
NestedProduct,都取決于產(chǎn)品出廠記錄中 SubProductAllowable 的值。

圖 2. Product 和產(chǎn)品出廠對象域模型
為了完成模型轉(zhuǎn)換,我們使用如下的 Hibernate 3.x 映射:
 <hibernate-mapping> <class name="Product" discriminator-value="0" lazy="false"> <id name="id" type="long"/> <discriminator formula="(select pr.SubProductAllowable from ProductRelease pr where pr.productReleaseID= productReleaseID)" type="integer" /> <subclass name="NestedProduct" discriminator-value="1"/> </class></hibernate-mapping>
<hibernate-mapping> <class name="Product" discriminator-value="0" lazy="false"> <id name="id" type="long"/> <discriminator formula="(select pr.SubProductAllowable from ProductRelease pr where pr.productReleaseID= productReleaseID)" type="integer" /> <subclass name="NestedProduct" discriminator-value="1"/> </class></hibernate-mapping> 如果 formula 表達式評估結(jié)果為 0 時--也就是不允許次品出廠--那么對象將是 Product 類。如果結(jié)果是
1,那么對象將是 NestedProduct。在表 1 和 2 中,表 Product
的第一條記錄(ProductID=10000001),已初始化的類將是 NestedProduct,因為它參考一條
SubProductAllowable=1 的 ProductRelease 記錄。表 Product
的第二條記錄(ProductID=20000001),已初始化的類將是 Product,因為它參考一條
SubProductAllowable=0 的 ProductRelease 記錄。
| S/N | ProductReleaseID |
SubProductAllowable |
... |
| 1 | 11 | 1 | ?- |
| 2 | 601 | 0 | ?- |
| S/N | ProductID |
ProductReleaseID |
... |
| 1 | 10000001 | 11 | ?- |
| 2 | 20000001 | 601 | ... |
Property
在 property 元素中的 formula 允許對象屬性包含特定引伸值,比如對結(jié)果進行 sum、average、max 等等。
<property name="averagePrice" formula="(select avg(pc.price) from PriceCatalogue pc, SelectedItems si where si.priceRefID=pc.priceID)"/>此外,formula 也能協(xié)助從基于當前記錄的特定值向其它表檢索數(shù)據(jù)。例如:
<property name="currencyName" formula="(select cur.name from currency cur where cur.id= currencyID)"/> 這將由助于從 currency 表檢索 currency name。正如你所看到的,這樣直接映射可消除許多轉(zhuǎn)換編碼。
map-key
formula 允許 map-key 持有任何可能的值。下列范例(圖 3),我們想讓 Role_roleID 成為對象模型的 map-key(圖 4)。

圖 3. 用戶角色數(shù)據(jù) schema

圖 4. 用戶角色對象模型
在前面的數(shù)據(jù) schema 中,User 和 Role 由 User_has_Role 通過 many-to-many 關(guān)系關(guān)聯(lián)調(diào)用。為了獲取某個 User 所有的指派角色,我們進行如下映射:
<hibernate-mapping> <class name="User"> <id name="userID"/> <map name="roles" table="UserRole"/> <key column="User_userID"/> <map-key formula="Role_RoleID" type="string"/> <many-to-many column="Role_RoleID" class="Role"/> </map> </class> <class name="Role"> <id name="roleID"/> </class></hibernate-mapping> Role_RoleID 通常用于連接 many-to-many 元素的欄位值。Hibernate 通常不允許
Role_RoleID 出現(xiàn)在 map-key 和 many-to-many 的欄位屬性中。但是有了 formula,Role_RoleID
也能用于 map-key。
element、map-key-many-to-many 以及其他
element 和 property 類似,能從任何有效的 formula 表達式賦予評估值。
map-key-many-to-many 中 formula 的用法類似于 map-key。但是,map-key-many-to-many 通常用于三重關(guān)系,map key 是一個被自己參考的對象,而不是被參考的屬性。
那么,到底哪些情況下 formula 不支持呢?有些數(shù)據(jù)庫(例如 Oracle 7)就不支持嵌入式 select 語句(也就是說一條
select SQL 內(nèi)嵌在另外一條 select SQL 語句中),這種情況 formula 就不支持評估結(jié)果。因此,你應該首先檢查嵌入式
select SQL 語句是否被支持。
一旦 Hibernate 的映射拿 formula 表達式作為 select SQL 選取的一部分,請確認數(shù)據(jù)庫 SQL 方言是否允許使用 formula,盡管這樣將降低代碼輕便性。
范疇 2:formula 用于連接
many-to-one
另一個普遍的場景是真實世界的數(shù)據(jù)模型是所有者關(guān)系映射,這意味著映射是不同于 one-to-one、one-to-many 以及
many-to-many 關(guān)系的,formula 是提供所有者關(guān)系管理元素中的一個。圖 5
展示了某公司可有多個聯(lián)系人,但是其中只有一個為默認聯(lián)系人的范例。一個公司有多個聯(lián)系人是典型的 one-to-many
關(guān)系。但是,為了標識默認聯(lián)系人,ContactPerson 表使用了 defaultFlag 參數(shù)(1 是 yes, 0是 no)。

圖 5. 用戶角色數(shù)據(jù) schema

圖 6. 用戶角色對象模型
為了說明對象模型(圖 6)中默認聯(lián)系人關(guān)系,我們使用如下映射文件:
<hibernate-mapping> <class name="Company" table="Company"> <id name="id" /> <many-to-one name="defaultContactPerson" property-ref="defaultContactPerson"> <column name="id"/> <formula>1</formula> </many-to-one> </class> <class name="Person" > <id name="id" /> <properties name="defaultContactPerson"> <property name="companyID" /> <property name="defaultFlag" /> </properties> </class></hibernate-mapping> 如上,我們把 companyID 和 defaultFlag 組織到名為 defaultContactPerson 的
properties 元素中,做為 Person 表的 unique key。Company 類中的 many-to-one 元素連接
Person 表的 defaultContactPerson properties 元素。輸出的 SQL 像這樣:
select c.id, p.id from Company c, Person p where p.companyID=c.id and p.defaultFlag=1
one-to-one
Hibernate 中,one-to-one 主要用于兩張表共享同一主鍵的情況。對于外鍵關(guān)聯(lián),我們通常使用 many-to-one
來代替。但是,有了 formula,one-to-one 可以通過外鍵連接表。上面的 many-to-one 范例可以通過
one-to-one 來映射:
<hibernate-mapping> <class name="Company" table="Company" > <id name="id" /> <one-to-one name="defaultContactPerson" property-ref="defaultContactPerson" > <formula>id</formula> <formula>1</formula> </one-to-one> </class> <class name="Person" > <id name="id" /> <properties name="defaultContactPerson"> <property name="companyID" /> <property name="defaultFlag" /> </properties> </class></hibernate-mapping> many-to-many
formula 用于當 many-to-many 元素為關(guān)系表和實體表連接的特殊關(guān)系,盡管通常沒有必要這樣用。
總結(jié)
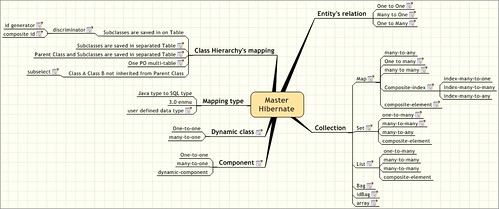
1 Entity's relation
1.1 One to One
一個對象的一個實例對應另一個對象的一個實例從數(shù)據(jù)庫角度描述,一個表中的一條記錄對應另外一個表中唯一一條記錄
public class Image{
private Long id;
private String imgName;
private Blog value; //to store binary of image
......
}
Image.hbm.xml
<class name="Image" dynamic-update="true">
<id...
<property...
</class>
public class Product{
private Long id;
private String name;
private double price;
private Image photo;
}
<class name=...dynamic-update="true" lazy="true"
<id...
<property...
<one-to-one name="photo" class="package.Image" cascade="all" outer-join="auto" constrained="false"/>
</class>
1.2 Many to One
一個對象對應另一個對象的多個實例,從數(shù)據(jù)庫角度描述,是在一個數(shù)據(jù)表中的一條記錄對應另外一個數(shù)據(jù)表中對條記錄.
public class PersonalCompute{
private Long computerId;
private String cpu;
......
private Programmer owner;
}
<class name="Programmer" table="Programmer">
<id...
<property...
</class>
<class name="PersonalCompute" table="PCS">
<id....
<property...
<many-to-one name="owner" column="programmerId" class="Programmer">
</many-to-one>
1.3 One to Many
The same example as Many to One.But we stand at Programmer class's view point.
public class Programmer{
...
private Set computers = new HashSet();
}
<class name="Programmer" table="Programmer">
<id...
<property...
<set name="computers" inverse="true" cascade="all">
<key column="programmerId" />
<one-to-many class="PersonalComputers">
</one-to-many>
</set>
2 Collection
2.1 Map
<class name="Team">
...
<map name="members">
<key foreign-key="fk">
<column name="teamNumber">
</key>
<index column="teamRole" type="string"/>
<element column="name" ...
</map>
showcase:
Team team1 = new Team();
team1.setName(xx);
team1.getMembers.put("index","content");
......
sess.save...
2.1.1 many-to-any
2.1.2 One to many
單單使用Map做存儲往往無法表達復雜的對象,如果要講對象 map進行映射:
One Team,multi-members
Public class Member{
...
private Team team;
}
<class name="Team">
...
<map name="members" inverse="false">
<key column="team" foreign-key="fk"/>
<index type="string" column="teamRole"/>
<one-to-many class="Member"/>
</map>
<class name="member">
<id...
<property...
<many-to-one name="team" />
showcase:
Team team = new Team();
team.setName("xx");
Member mem1 = new Member();
mem1.setXX
mem1.setXX
Member mem2 = new Member();
mem2.setXX
mem2.setXX
team.getMembers().put("xx",mem1);
team.getMembers().put("xx2",mem2);
2.1.3 many to many
<class name="Team">
<id
<propery
<map name="members" inverse="false" table="teamHasMembers">
<key column="team" foreign-key="fk"/>
<index type="string" column="teamRole"/>
<many-to-many class="member" outer-join="auto">
<column name="member"/>
</many-to-many>
</map>
<class name="Member">
<id
<property
<map name="teams" table="memberAtTeams">
<key....
teamRole is their common key of Map.
Team
|
id |
name |
|
2 |
team2 |
Member
|
di |
name |
age |
|
1 |
davy |
23 |
memberAtTeams
|
member |
team |
teamRole |
|
1 |
2 |
coach |
teamHasMembers
|
team |
member |
teamRole |
|
2 |
1 |
coach |
2.1.4 Composite-index
復雜Index 可以是一個類。
public class Position{
private String role;
private String scene;
public Position()....
getter...
setter...
}
<class name="Team">
<id...
<property...
<map name="members" inverse="false">
<key column="team" foreign-key="fk"/>
<composite-index class="Position">
<key-property..
<key-property...
</composite-index>
<one-to-many class="Member"/>
</map>
...
<class name="Member">
<id...
<property...
<many-to-one name="team"/>
</class>
index-many-to-one
index-many-to-many
index-many-to-any
2.1.5 composite-element
<import class="Member"/>
<class name="Team">
<id...
<property...
<map name="members" table="teamMembers">
<key column="teamId"/>
<index...
<composite-element class="Member">
<parent name="parent"/>
<property...
<property...
</composite-element>
</map>
2.2 Set
<class name="Team">
<..
<set name="members" inverse="false">
<key column="team" foreign-key="fk"/>
<elemnet column="name" type="string"/>
</set>
2.2.1 one-to-many
<set name="xx" column="">
<key column="" foreign-key="fk"/>
<one-to-many class="BB"/>
</set>
2.2.2 many-to-many
<class name="Team">
<id..
<property...
<set name="members" inverse="false" table="teamHasMembers">
<key column="team" foreign-key="fk">
<many-to-many class="Member" outer-join="auto">
<column name="member"/>
</set>
</class>
<class name="Member">
<id..
<property...
<set name="members" inverse="true" table="memberAtTeams">
<key column="member" foreign-key="fk">
<many-to-many class="Member" outer-join="auto">
<column name="team"/>
</set>
</class>
2.2.3 many-to-any
2.2.4 composite-element
2.3 List
<list name="members" inverse="false">
<key column="team" foreign-key="fk"/>
<index column="teamMember"/>
<element column="name" type="string"/>
</list>
2.3.1 one-to-many
2.3.2 many-to-many
2.3.3 many-to-many
2.3.4 composite-element
2.4 Bag
It can contains JDK's Collection and List interface type's object.
2.5 idBag
與bag相比多出了collection-id屬性
<ibdbag name="">
<collection-id column="mbid" type="long">
<generator class="
</collection-id>
<key..
<element..
</idbag>
2.6 array
public class Team{
//...
private String[] members;
}
<array name="members" inverse="false">
<key column="team" foreign-key="fk"/>
<index column="teamNumber"/>
<element column="name" type="string"/>
</array>
3 Component
<class name="Country">
<id..
<property...
<component name="position">
<property...
</component>
Public class Country{
//..
private Position position;
}
3.1 One-to-one
3.2 many-to-one
3.3 dynamic-component
4 Dynamic class
<dynamic-class entity-name="Country">
<id name="id" type="long">
<generator class="
</id>
<property name="name" column="NAME" type="string"/>
</..
4.1 One-to-one
4.2 many-to-one
5 Mapping type
5.1 Java type to SQL type
5.2 3.0 enmu
5.3 user defined data type
need implements org.hibernate.usertype.CompositeUserType or org.hibernate.usertype.UserType interface.
6 Class Hierarchy's mapping
6.1 Subclasses are saved in on Table
6.1.1 discriminator
Sapmle:
Class AbstractParent{
String id;
/*important*/
String discriminator
}
Class ChildA{
String childA;
}
Class ChildB{
String childB;
}
=========DB=========
|
colum name |
data type |
memo |
|
id |
varchar |
|
|
childA |
varchar |
|
|
childB |
varchar |
|
|
class_type |
varchar |
used to identify subclass:A B |
========mapping config file====
<class name="AbstractParent" table="PARENT" abstract="true">
<id...
<discriminator column="CLASS_TYPE" type="string"/>
<property......
<subclass name="ChildA" discriminator-value="A">
<property name="childA"/>
</subclass>
<subclass......
id generator
· increment
· identity
· sequence
·
· seqhilo
· uuid
· guid
· native
· assigned
· foreign
composite id
<composite-id>
<key-property name=""/>
<key-property name=""/>
</composite-id>
6.2 Subclasses are saved in separated Table
并不為父類Container建立映射文件 Box與Bottle的映射文件也如沒有關(guān)系一樣普通的建立 但是對Container取得操作
List pcs = sess.createQuery("from com.be.david.Container").list();
if(!cs.isEmpty()){
...
}
會將Box與Container數(shù)據(jù)都取出來 這是Hibernate默認隱式完成的
6.3 Parent Class and Subclasses are saved in separated Table
<class name="Container" table="CONTAINER">
<id...
<property...
<joined-subclass name="Box" table="CONTAINER_BOX">
<key column="ContainerId"/>
<property...
</joined-subclass>
<joined-subclass name="Bottle" table="CONTAINER_BOTTLE">
<key...
<property...
</joined-subclass>
</class>
6.4 One
public Class Person{
public String id;
public String name;
public String sex;
public String address;
public String city;
public String zipcode;
}
we wanna save address related attributes(blue ones).Use join
<class name="Person" table="PERSON">
<id...
<property ...
<join table="ADDRESS">
<key column="addressID"/>
<property name="address"/>
...
</join>
</class>
6.5 Class A Class B not inherited from Parent Class
6.5.1 subselect
We can use subselct to make ChildA and ChildB standalone.So how can we get all data including ChindA and ChildB?
<class name="ChildA" table="parent">
<id...
<property...
</class>
<class name="ChildB" table="parent">
<id...
<property...
</class>
<class name="Parent" mutable="false">
<subselect>
select * from ChildA
union
select * from ChildB
</subselect>
<sychronize table="ChildA"/>
<sychronize table="ChildB"/>
<id...
<property...
</class>
不用多說了,已經(jīng)注釋很詳細了,希望對你有幫助
<?xml version="1.0" encoding="utf-8"?>
<project name="利用工具開發(fā)Hibernate" default="help" basedir=".">
<!-- ****** 環(huán)境設(shè)置,可以根據(jù)自己的實際配置自行更改 ***** -->
<!-- ****** http://blog.csdn.net/fasttalk ***** -->
<!-- ****** http://www.tkk7.com/asktalk ***** -->
<!-- 源文件目錄, 可以通過 項目->屬性->Java構(gòu)建路徑 更改 -->
<property name="src.dir" value="./src" />
<!-- 輸出的class文件目錄,可以通過 項目->屬性->Java構(gòu)建路徑 更改 -->
<property name="class.dir" value="./bin" />
<!-- 庫文件目錄 -->
<property name="lib.dir" value="E:/workspace/java/hibernate3" />
<!-- 定義類路徑 -->
<path id="project.class.path">
<fileset dir="${lib.dir}">
<include name="*.jar"/>
</fileset>
<pathelement location="${class.dir}" />
</path>
<!-- ************************************************************** -->
<!-- 使用說明 -->
<!-- ************************************************************** -->
<target name="help">
<echo message="利用工具開發(fā)Hibernate" />
<echo message="-----------------------------------" />
<echo message="" />
<echo message="提供以下任務:" />
<echo message="" />
<echo message="generate-hbm --> 運行HibernateDoclet,生成 Hibernate 類的映射文件" />
<echo message="schemaexport --> 運行SchemaExport,利用 hbm.xml 文件生成數(shù)據(jù)表" />
<echo message="" />
</target>
<!-- ************************************************************** -->
<!-- Hbm2Java 任務 在hibernate3中無法實現(xiàn) -->
<!-- ************************************************************** -->
<target name="generate-code" >
<echo message="運行 Hbm2Java 任務, 利用 hbm.xml 文件生成Java類文件"/>
<taskdef name="hbm2java"
classname="org.hibernate.tool.instrument.InstrumentTask"
classpathref="project.class.path">
</taskdef>
<hbm2java output="${src.dir}">
<fileset dir="${src.dir}">
<include name="**/*.hbm.xml"/>
</fileset>
</hbm2java>
</target>
<!-- ************************************************************** -->
<!-- HibernateDoclet 任務 -->
<!-- ************************************************************** -->
<target name="generate-hbm" >
<echo message="運行HibernateDoclet,生成 Hibernate 類的映射文件"/>
<taskdef name="hibernatedoclet"
classname="xdoclet.modules.hibernate.HibernateDocletTask"
classpathref="project.class.path">
</taskdef>
<!--
destdir 輸出目錄;
force, 每次都強行執(zhí)行,覆蓋原有文件;
-->
<hibernatedoclet destdir="${src.dir}"
excludedtags="@version,@author,@todo" force="true" encoding="GBK"
verbose="true">
<fileset dir="${src.dir}">
<include name="**/*.java"/>
</fileset>
<hibernate version="3.0" xmlencoding="utf-8" />
</hibernatedoclet>
</target>
<!-- ************************************************************** -->
<!-- SchemaExport 任務 -->
<!-- ************************************************************** -->
<target name="schemaexport">
<echo message="運行SchemaExport,利用 hbm.xml 文件生成數(shù)據(jù)表"/>
<taskdef name="schemaexport"
classname="org.hibernate.tool.hbm2ddl.SchemaExportTask"
classpathref="project.class.path">
</taskdef>
<!--
quiet=true 不要把腳本輸出到stdout;
drop=true 只進行drop tables的步驟 ;
text=true 不執(zhí)行在數(shù)據(jù)庫中運行的步驟 ;
output=my_schema.ddl 把輸出的ddl腳本輸出到一個文件 ;
config=hibernate.cfg.xml 從XML文件讀入Hibernate配置 ;
properties=hibernate.properties 從文件讀入數(shù)據(jù)庫屬性 ;
format=true 把腳本中的SQL語句對齊和美化 ;
delimiter=x 為腳本設(shè)置行結(jié)束符
-->
<schemaexport properties="src/hibernate.properties"
quiet="no" text="no" drop="no" output="schema-export.sql" >
<fileset dir="${src.dir}">
<include name="**/*.hbm.xml"/>
</fileset>
</schemaexport>
</target>
</project>
如果轉(zhuǎn)載,請標明出處,謝謝
1.1 Hibernate API 變化
1.1.1 包名
1.1.2 org.hibernate.classic包
1.1.3 Hibernate所依賴的第三方軟件包
1.1.4 異常模型
1.1.5 Session接口
1.1.6 createSQLQuery()
1.1.7 Lifecycle 和 Validatable
接口
1.1.8 Interceptor接口
1.1.9 UserType和CompositeUserType接口
1.1.10 FetchMode類
1.1.11 PersistentEnum類
1.1.12 對Blob 和Clob的支持
1.1.13 Hibernate中供擴展的API的變化
1.2 元數(shù)據(jù)的變化
1.2.1 檢索策略
1.2.2 對象標識符的映射
1.2.3 集合映射
1.2.4 DTD
1.3 查詢語句的變化
1.3.1 indices()和elements()函數(shù)
盡管Hibernate 3.0
與Hibernate2.1的源代碼是不兼容的,但是當Hibernate開發(fā)小組在設(shè)計Hibernate3.0時,為簡化升級Hibernate版本
作了周到的考慮。對于現(xiàn)有的基于Hibernate2.1的Java項目,可以很方便的把它升級到Hibernate3.0。
本文描述了Hibernate3.0版本的新變化,Hibernate3.0版本的變化包括三個方面:
(1)API的變化,它將影響到Java程序代碼。
(2)元數(shù)據(jù),它將影響到對象-關(guān)系映射文件。
(3)HQL查詢語句。
值得注意的是, Hibernate3.0并不會完全取代Hibernate2.1。在同一個應用程序中,允許Hibernate3.0和Hibernate2.1并存。
1.1 Hibernate API 變化
1.1.1 包名
Hibernate3.0的包的根路徑為: “org.hibernate”
,而在Hibernate2.1中為“net.sf.hibernate”。這一命名變化使得Hibernate2.1和Hibernate3.0能夠同
時在同一個應用程序中運行。
如果希望把已有的應用升級到Hibernate3.0,那么升級的第一步是把Java源程序中的所有“net.sf.hibernate”替換為“org.hibernate”。
Hibernate2.1中的“net.sf.hibernate.expression”包被改名為“org.hibernate.criterion”。假如應用程序使用了Criteria
API,那么在升級的過程中,必須把Java源程序中的所有“net.sf.hibernate.expression”替換為“org.hibernate.criterion”。
如果應用使用了除Hibernate以外的其他外部軟件,而這個外部軟件又引用了Hibernate的接口,那么在升級時必須十分小心。例如EHCache擁有自己的CacheProvider:
net.sf.ehcache.hibernate.Provider,在這個類中引用了Hibernate2.1中的接口,在升級應用時,可以采用以下辦法之一來升級EHCache:
(1)手工修改net.sf.ehcache.hibernate.Provider類,使它引用Hibernate3.0中的接口。
(2)等到EHCache軟件本身升級為使用Hibernate3.0后,使用新的EHCache軟件。
(3)使用Hibernate3.0中內(nèi)置的CacheProvider:org.hibernate.cache.EhCacheProvider。
1.1.2 org.hibernate.classic包
Hibernate3.0把一些被廢棄的接口都轉(zhuǎn)移到org.hibernate.classic中。
1.1.3 Hibernate所依賴的第三方軟件包
在Hibernate3.0的軟件包的lib目錄下的README.txt文件中,描述了Hibernate3.0所依賴的第三方軟件包的變化。
1.1.4 異常模型
在Hibernate3.0中,HibernateException異常以及它的所有子類都繼承了java.lang.RuntimeException。因此在編譯時,編譯器不會再檢查HibernateException。
1.1.5 Session接口
在Hibernate3.0中,原來Hibernate2.1的Session接口中的有些基本方法也被廢棄,但為了簡化升級,這些方法依然是可用的,可以通過org.hibernate.classic.Session子接口來訪問它們,例如:
org.hibernate.classic.Session session=sessionFactory.openSession();
session.delete("delete from Customer ");
在Hibernate3.0
中,org.hibernate.classic.Session接口繼承了org.hibernate.Session接口,在
org.hibernate.classic.Session接口中包含了一系列被廢棄的方法,如find()、interate()等。
SessionFactory接口的openSession()方法返回org.hibernate.classic.Session類型的實例。如果希
望在程序中完全使用Hibernate3.0,可以采用以下方式創(chuàng)建Session實例:
org.hibernate.Session session=sessionFactory.openSession();
如果是對已有的程序進行簡單的升級,并且希望仍然調(diào)用Hibernate2.1中Session的一些接口,可以采用以下方式創(chuàng)建Session實例:
org.hibernate.classic.Session session=sessionFactory.openSession();
在Hibernate3.0中,Session接口中被廢棄的方法包括:
* 執(zhí)行查詢的方法:find()、iterate()、filter()和delete(String hqlSelectQuery)
* saveOrUpdateCopy()
Hibernate3.0一律采用createQuery()方法來執(zhí)行所有的查詢語句,采用DELETE 查詢語句來執(zhí)行批量刪除,采用merge()方法來替代
saveOrUpdateCopy()方法。
提
示:在Hibernate2.1中,Session的delete()方法有幾種重載形式,其中參數(shù)為HQL查詢語句的delete()方法在
Hibernate3.0中被廢棄,而參數(shù)為Ojbect類型的的delete()方法依然被支持。delete(Object
o)方法用于刪除參數(shù)指定的對象,該方法支持級聯(lián)刪除。
Hibernate2.1沒有對批量更 新和批量刪除提供很好的支持,參見<<精通Hibernate>>一書的第13章的13.1.1節(jié)(批量更新和批量刪除),而 Hibernate3.0對批量更新和批量刪除提供了支持,能夠直接執(zhí)行批量更新或批量刪除語句,無需把被更新或刪除的對象先加載到內(nèi)存中。以下是通過 Hibernate3.0執(zhí)行批量更新的程序代碼:
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlUpdate = "update Customer set name = :newName
where name = :oldName";
int updatedEntities = s.createQuery( hqlUpdate )
.setString( "newName", newName )
.setString( "oldName", oldName )
.executeUpdate();
tx.commit();
session.close();
以下是通過Hibernate3.0執(zhí)行批量刪除的程序代碼:
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlDelete = "delete Customer where name =
:oldName";
int deletedEntities = s.createQuery( hqlDelete )
.setString( "oldName", oldName )
.executeUpdate();
tx.commit();
session.close();
1.1.6 createSQLQuery()
在Hibernate3.0中,Session接口的createSQLQuery()方法被廢棄,被移到org.hibernate.classic.Session接口中。Hibernate3.0采用新的SQLQuery接口來完成相同的功能。
1.1.7 Lifecycle 和 Validatable 接口
Lifecycle和Validatable 接口被廢棄,并且被移到org.hibernate.classic包中。
1.1.8 Interceptor接口
在Interceptor 接口中加入了兩個新的方法。
用戶創(chuàng)建的Interceptor實現(xiàn)類在升級的過程中,需要為這兩個新方法提供方法體為空的實現(xiàn)。此外,instantiate()方法的參數(shù)作了修
改,isUnsaved()方法被改名為isTransient()。
1.1.9 UserType和CompositeUserType接口
在UserType和CompositeUserType接口中都加入了一些新的方法,這兩個接口被移到org.hibernate.usertype包中,用戶定義的UserType和CompositeUserType實現(xiàn)類必須實現(xiàn)這些新方法。
Hibernate3.0提供了ParameterizedType接口,用于更好的重用用戶自定義的類型。
1.1.10 FetchMode類
FetchMode.LAZY 和 FetchMode.EAGER被廢棄。取而代之的分別為FetchMode.SELECT 和FetchMode.JOIN。
1.1.11 PersistentEnum類
PersistentEnum被廢棄并刪除。已經(jīng)存在的應用應該采用UserType來處理枚舉類型。
1.1.12 對Blob 和Clob的支持
Hibernate對Blob和Clob實例進行了包裝,使得那些擁有Blob或Clob類型的屬性的類的實例可以被游離、序列化或反序列化,以及傳遞到merge()方法中。
1.1.13 Hibernate中供擴展的API的變化
org.hibernate.criterion、 org.hibernate.mapping、 org.hibernate.persister和org.hibernate.collection
包的結(jié)構(gòu)和實現(xiàn)發(fā)生了重大的變化。多數(shù)基于Hibernate
2.1 的應用不依賴于這些包,因此不會被影響。如果你的應用擴展了這些包中的類,那么必須非常小心的對受影響的程序代碼進行升級。
1.2 元數(shù)據(jù)的變化
1.2.1 檢索策略
在Hibernate2.1中,lazy屬性的默認值為“false”,而在Hibernate3.0中,lazy屬性的默認值為“true”。在升級映
射文件時,如果原來的映射文件中的有關(guān)元素,如<set>、<class>等沒有顯式設(shè)置lazy屬性,那么必須把它們都顯式的
設(shè)置為lazy=“true”。如果覺得這種升級方式很麻煩,可以采取另一簡單的升級方式:在<hibernate-mapping>元素中
設(shè)置: default-lazy=“false”。
1.2.2 對象標識符的映射
unsaved-value屬性是可選的,在多數(shù)情況下,Hibernate3.0將把unsaved-value="0" 作為默認值。
在Hibernate3.0中,當使用自然主鍵和游離對象時,不再強迫實現(xiàn)Interceptor.isUnsaved()方法。
如果沒有設(shè)置這個方法,當Hibernate3.0無法區(qū)分對象的狀態(tài)時,會查詢數(shù)據(jù)庫,來判斷這個對象到底是臨時對象,還是游離對象。不過,顯式的使用
Interceptor.isUnsaved()方法會獲得更好的性能,因為這可以減少Hibernate直接訪問數(shù)據(jù)庫的次數(shù)。
1.2.3 集合映射
<index>元素在某些情況下被<list-index>和<map-key>元素替代。此外,Hibernate3.0用<map-key-many-to-many>
元素來替代原來的<key-many-to-many>.元素,用<composite-map-key>元素來替代原來的<composite-index>元素。
1.2.4 DTD
對象-關(guān)系映射文件中的DTD文檔,由原來的:
http://hibernate.sourceforge.net/hibernate-mapping-2.0.dtd
改為:
http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd
1.3 查詢語句的變化
Hibernate3.0
采用新的基于ANTLR的HQL/SQL查詢翻譯器,不過,Hibernate2.1的查詢翻譯器也依然存在。在Hibernate的配置文件中,
hibernate.query.factory_class屬性用來選擇查詢翻譯器。例如:
(1)選擇Hibernate3.0的查詢翻譯器:
hibernate.query.factory_class= org.hibernate.hql.ast.ASTQueryTranslatorFactory
(2)選擇Hibernate2.1的查詢翻譯器
hibernate.query.factory_class= org.hibernate.hql.classic.ClassicQueryTranslatorFactory
提示:ANTLR是用純Java語言編寫出來的一個編譯工具,它可生成Java語言或者是C++的詞法和語法分析器,并可產(chǎn)生語法分析樹并對該樹進行遍歷。ANTLR由于是純Java的,因此可以安裝在任意平臺上,但是需要JDK的支持。
值得注意的是, Hibernate3.0的查詢翻譯器存在一個Bug:不支持某些theta-style連結(jié)查詢方言:如Oracle8i的OracleDialect 方言、Sybase11Dialect。解決這一問題的辦法有兩種:(1)改為使用支持ANSI-style連結(jié)查詢的方言,如 Oracle9Dialect,(2)如果升級的時候遇到這一問題,那么還是改為使用Hibernate2.1的查詢翻譯器。
1.3.1 indices()和elements()函數(shù)
在HQL的select子句中廢棄了indices()和elements()函數(shù),因為這兩個函數(shù)的語法很讓用戶費解,可以用顯式的連接查詢語句來替代 select elements(...) 。而在HQL的where子句中,仍然可以使用elements()函數(shù)。
2 <props>
3 <prop key="hibernate.dialect">org.hibernate.dialect.Oracle9Dialect</prop>
4 <prop key="hibernate.show_sql">false</prop>
5 <!-- Create/update the database tables automatically when the JVM starts up
6 <prop key="hibernate.hbm2ddl.auto">update</prop> -->
7 <!-- Turn batching off for better error messages under PostgreSQL
8 <prop key="hibernate.jdbc.batch_size">100</prop> -->
9 <prop key="hibernate.jdbc.batch_size">50</prop>
10 </props>
11 </property>
2、如果是超大的系統(tǒng),建議生成htm文件。加快頁面提升速度。
3、不要把所有的責任推在hibernate上,對代碼進行重構(gòu),減少對數(shù)據(jù)庫的操作,盡量避免在數(shù)據(jù)庫查詢時使用in操作,以及避免遞歸查詢操作,代碼質(zhì)量、系統(tǒng)設(shè)計的合理性決定系統(tǒng)性能的高低。
4、 對大數(shù)據(jù)量查詢時,慎用list()或者iterator()返回查詢結(jié)果,
(1). 使用List()返回結(jié)果時,Hibernate會所有查詢結(jié)果初始化為持久化對象,結(jié)果集較大時,會占用很多的處理時間。
(2). 而使用iterator()返回結(jié)果時,在每次調(diào)用iterator.next()返回對象并使用對象時,Hibernate才調(diào)用查詢將對應的對象初始 化,對于大數(shù)據(jù)量時,每調(diào)用一次查詢都會花費較多的時間。當結(jié)果集較大,但是含有較大量相同的數(shù)據(jù),或者結(jié)果集不是全部都會使用時,使用iterator ()才有優(yōu)勢。
5、在一對多、多對一的關(guān)系中,使用延遲加載機制,會使不少的對象在使用時方會初始化,這樣可使得節(jié)省內(nèi)存空間以及減少數(shù)據(jù)庫的負荷,而且若PO中的集合沒有被使用時,就可減少互數(shù)據(jù)庫的交互從而減少處理時間。
6、對含有關(guān)聯(lián)的PO(持久化對象)時,若default-cascade="all"或者 “save-update”,新增PO時,請注意對PO中的集合的賦值操作,因為有可能使得多執(zhí)行一次update操作。
7、 對于大數(shù)據(jù)量新增、修改、刪除操作或者是對大數(shù)據(jù)量的查詢,與數(shù)據(jù)庫的交互次數(shù)是決定處理時間的最重要因素,減少交互的次數(shù)是提升效率的最好途徑,所以在 開發(fā)過程中,請將show_sql設(shè)置為true,深入了解Hibernate的處理過程,嘗試不同的方式,可以使得效率提升。盡可能對每個頁面的顯示, 對數(shù)據(jù)庫的操作減少到100----150條以內(nèi)。越少越好。
以上是在進行struts+hibernate+spring進行項目開發(fā)中,對hibernate性能優(yōu)化的幾點心得。