ΫW?/span>δΗ?/span>φ≠ΞοΦ¨binφ•΅δögεΛΙγ¦°εΫïφΖΜεä†εàΑPathΨp»ùΜüεè‰ι΅èδΗ≠εç≥ιÖçγΫ°φàêεäüεQ?br />
φ•ΑεΨèδΗÄδΗΣCΫE΄εΚèφΚêφ•΅δΜ”ûΦ¨η°ë÷êçε≠½δΊ™(f®¥)hello.c
ΫW§ε¦¦φ≠ΞοΦ¨εΦÄεß?>‰qêηΓ¨->ηΨ™εÖΞcmdε¦ûηûRεQ¨ηΩ¦εÖΞφéßεàΕεèΑεQ¨ηΩ¦εÖΞφΚêφ•΅δögφâÄε€®γö³γ¦°εΫï
ηΨ™εÖΞεëΫδΉo(h®¥)gcc hello.c -g -o xxxεQ¨xxxεç≥δΊ™(f®¥)Ψ~•η·ë‰qûφéΞεêéεè·‰qêηΓ¨γö³φ•΅δΜΕεêç
φï≤ε΅Με¦ûηûRιî°εêéεQ¨εΑ±εè·δΜΞ‰qêηΓ¨Ψ~•η·ëεêéεΨ½ΫE΄εΚèεQöxxx.exe
ε€®εëΫδΜΛηΓ¨δΗ≠φï≤εÖΞxxxεç¦_è·‰qêηΓ¨CΫE΄εΚèηéΖεΨ½‰qêηΓ¨Ψl™φû€ψÄ?br />
ε€®ηΩêηΓ¨δΗ≠εΨàεè·ηÉΫε΅ΚγéΑε±èρqïδΗÄι½ΣηĨηΩ΅γö³γéΑη±ΓοΦ¨‰qôφ½ΕεÄôεèΣηΠ¹ε€®ΫE΄εΚèγö³φ€Äεêéεä†δΗäη·≠εèΞοΦö(x®§)system("pause");εç¦_è·ηßΘεÜ≥
δΜäεΛ©δΗ≠εçàεQ¨φàëΫH¹γ³ΕφÉœx(ch®°ng)êûφΗÖφΞöUnicode壨UTF-8δΙ΄ι½¥γö³εÖ≥ΨpΜοΦ¨δΚéφ‰·û°±εΦÄεß΄ε€®Ψ|ëδΗäφüΞηΒ³φ•ôψÄ?/span>
Ψl™φû€εQ¨ηΩôδΗΣι½°ιΔ‰φ·îφàëφÉ≥η±Γγö³εΛçφù²εQ¨δΜéεçàιΞ≠εêéδΗÄ㦥〴εàΑφôöδΗ?γ²ΙοΦ¨φâçγ°½εàùφ≠ΞφêûφΗÖφΞöψÄ?/span>
δΗ΄ιùΔû°±φ‰·φàëγö³ΫWîη°ΑεQ¨δΗΜηΠ¹γî®φùΞφï¥γêÜη΅ΣεΖόqö³φÄùηΒ\ψIJδΫÜφ‰·οΦ¨φàëεΑΫι΅èη·ïε¦ë÷ÜôεΨ½ιÄöδΩ½φ‰™φ΅²εQ¨εΗ¨φ€¦ηÉΫε·ΙεÖΕδΜ•φ€΄εè΄φ€âγî®ψIJφ·ïγΪüοΦ¨ε≠½γ§ΠΨ~•γ†¹φ‰·η°ΓΫé½φ€ΚφäÄφ€·γö³εüΚγü≥εQ¨φÉ≥ηΠ¹γÜüΨlÉδ΄…γî®η°ΓΫé½φ€ΚεQ¨εΑ±εΩÖιΓΜφ΅²εΨ½δΗÄγ²Ιε≠½ΫWΠγΦ•γ†¹γö³γüΞη·ÜψÄ?/span>
1. ASCII�/strong>
φàëδΜ§γüΞι¹™εQ¨ε€®η°Γγ°½φ€ΚεÜÖιÉ®οΦ¨φâÄφ€âγö³δΩΓφ¹·φ€ÄΨlàιÉΫηΓ®γΛΚδΗόZΗÄδΗΣδΚ¨‰q¦εàΕγö³ε≠½ΫWΠδΗ≤ψIJφ·èδΗÄδΗΣδΚ¨‰q¦εàΕδΫçοΦàbitεQâφ€â0ε£?δΗΛγßçγäΕφĹο֨妆φ≠ΛεÖΪδΗΣδΚ¨ηΩ¦εàΕδΫçû°±εè·δΜΞγΜ³εêàε΅Κ256ΩUçγäΕφĹοΦ¨‰qôηΔΪΩUνCΊ™(f®¥)δΗÄδΗΣε≠½ηä²οΦàbyteεQâψIJδΙüû°±φ‰·η·Ώ_(d®Δ)Φ¨δΗÄδΗΣε≠½ηä²δΗÄεÖ±εè·δΜΞγî®φùΞηΓ®ΫC?56ΩUçδΗçεê¨γö³γäΕφĹοΦ¨φ·èδΗÄδΗΣγäΕφĹε·ΙεΚîδΗÄδΗΣγ§ΠεèχPΦ¨û°±φ‰·256δΗΣγ§ΠεèχPΦ¨δΜ?000000εà?1111111ψÄ?/span>
δΗäδΗΣδΗ•γΚΣ60ρq¥δΜΘεQ¨γΨéε¦ΫεàΕε°öδΚÜ(ji®Θn)δΗÄεΞ½ε≠½ΫWΠγΦ•γ†¹οΦ¨ε·Ιη΄±η·≠ε≠½ΫWΠδΗéδΚ¨ηΩ¦εàΕδΫçδΙ΄ι½¥γö³εÖ≥ΨpΜοΦ¨ε¹öδΚÜ(ji®Θn)ΨlüδΗÄηß³ε°öψIJηΩôηΔΪγßΑδΗΚASCIIγ†¹οΦ¨δΗÄ㦥φ≤Ωγî®η΅≥δΜäψÄ?/span>
ASCIIγ†¹δΗÄεÖόpß³ε°öδΚÜ(ji®Θn)128δΗΣε≠½ΫWΠγö³Ψ~•γ†¹εQ¨φ·îεΠ²γ©Κφ†?#8220;SPACE”φ‰?2εQàδΚ¨‰q¦εàΕ00100000εQâοΦ¨εΛßεÜôγö³ε≠½φ·çAφ‰?5εQàδΚ¨‰q¦εàΕ01000001εQâψIJηΩô128δΗΣγ§ΠεèχPΦàε¨Öφ΄§32δΗΣδΗçηÉΫφâ™εçΑε΅ΚφùΞγö³φéßεàΕΫWΠεèΖεQâοΦ¨εèΣεç†γî®δΚÜ(ji®Θn)δΗÄδΗΣε≠½ηä²γö³εêéιùΔ7δΫçοΦ¨φ€ÄεâçιùΔγö?δΫçγΜüδΗÄηß³ε°öδΗ?ψÄ?/span>
2ψĹιùûASCIIΨ~•γ†¹
η΄όp·≠γî?28δΗΣγ§ΠεèοL(f®Ξng)Φ•γ†¹εΑ±εΛüδΚÜ(ji®Θn)εQ¨δΫÜφ‰·γî®φùΞηΓ®ΫCΚεÖΕδΜ•η·≠≠aÄεQ?28δΗΣγ§Πεèδh‰·δΗçεΛüγö³ψIJφ·îεΠ²οΦ¨ε€®φ≥ïη·≠δΗ≠εQ¨ε≠½φ·çδΗäφ•“é(gu®©)€âφ≥®ιü≥ΫWΠεèΖεQ¨ε°É?y®≠u)°±φ½†φ≥ïγî®ASCIIγ†¹ηΓ®ΫCΚψIJδΚéφ‰·οΦ¨δΗÄδΚ¦φ§ß΄z≤ε¦Ϋε°ΕεΑ±εܦ_°öεQ¨εà©γî®ε≠½ηä²δΗ≠ι½≤γΫ°γö³φ€ÄιΪ‰δ(sh®¥)ΫçΨ~•εÖΞφ•Αγö³ΫWΠεèΖψIJφ·îεΠ²οΦ¨φ≥ïη·≠δΗ≠γö³éγö³γΦ•γ†¹δΊ™(f®¥)130εQàδΚ¨‰q¦εàΕ10000010εQâψIJηΩôφ†ΖδΗÄφùΞοΦ¨‰qôδΚ¦΄Τßφ¥≤ε¦Ϋε°ΕδΫΩγî®γö³γΦ•γ†¹δΫ™ΨpΜοΦ¨εè·δΜΞηΓ®γΛΚφ€ÄεΛ?56δΗΣγ§Πεè½ςÄ?/span>
δΫÜφ‰·εQ¨ηΩô顨εèàε΅ΚγéΑδΚ?ji®Θn)φ•Αγö³ι½°ιΔ‰ψIJδΗçεê¨γö³ε¦Ϋε°Εφ€âδΗçεê¨γö³ε≠½φ·çεQ¨ε¦†φ≠ΛοΦ¨ε™ΣφÄïε°ÉδΜ§ιÉΫδΫΩγî®256δΗΣγ§ΠεèοL(f®Ξng)ö³Ψ~•γ†¹φ•ΙεΦèεQ¨δΜΘηΓ®γö³ε≠½φ·çεç¥δΗçδΗÄφ†½ςIJφ·îεΠ²οΦ¨130ε€®φ≥ïη·≠γΦ•γ†¹δΗ≠δΜΘηΓ®δΚ?#233;εQ¨ε€®εΗ¨δΦ·φùΞη·≠Ψ~•γ†¹δΗ≠εç¥δΜΘηΓ®δΚ?ji®Θn)ε≠½φ·çGimel (Ή£)εQ¨ε€®δΩ³η·≠Ψ~•γ†¹δΗ≠εèàδΦ?x®§)δΜΘηΓ®εèΠδΗÄδΗΣγ§Πεè½ςIJδΫÜφ‰·δΗçΫéΓφÄéφ†ΖεQ¨φâÄφ€âηΩôδΚ¦γΦ•γ†¹φ•ΙεΦèδΗ≠εQ?—127ηΓ®γΛΚγö³γ§Πεèδh‰·δΗÄφ†οL(f®Ξng)ö³εQ¨δΗçδΗÄφ†οL(f®Ξng)ö³εèΣφ‰·128—255γö³ηΩôδΗĨDϋc(di®Θn)Ä?/span>
η΅≥δΚéδΚöφ¥≤ε¦Ϋε°Εγö³φ•΅ε≠½οΦ¨δΫΩγî®γö³γ§ΠεèΖεΑ±φ¦¥εΛöδΚ?ji®Θn)οΦ¨φ±âε≠½û°±εΛöη?0δΗ΅εΖΠεèüκIJδΗÄδΗΣε≠½ηä²εèΣηÉΫηΓ®ΫC?56ΩUçγ§ΠεèχPΦ¨η²·ε°öφ‰·δΗçεΛüγö³εQ¨εΑ±εΩÖιΓΜδΫΩγî®εΛöδΗΣε≠½ηä²ηΓ®ηΨΨδΗÄδΗΣγ§Πεè½ςIJφ·îεΠ²οΦ¨ΫéÄδΫ™δΗ≠φ•΅εΗΗηß¹γö³Ψ~•γ†¹φ•ΙεΦèφ‰·GB2312εQ¨δ΄…γî®δΗΛδΗΣε≠½ηä²ηΓ®ΫCόZΗÄδΗΣφ±âε≠½οΦ¨φâÄδΜΞγêÜη°όZΗäφ€ÄεΛöεè·δΜΞηΓ®ΫC?56x256=65536δΗΣγ§Πεè½ςÄ?/span>
δΗ≠φ•΅Ψ~•γ†¹γö³ι½°ιΔ‰ι€ÄηΠ¹δΗ™φ•΅η°®η°ΚοΦ¨‰qôγ·΅ΫWîη°ΑδΗçφΕâεè?qi®Δng)ψIJηΩô顨εèΣφ¨΅ε΅ΚεQ¨ηôΫγ³âôÉΫφ‰·γî®εΛöδΗΣε≠½ηä²ηΓ®γΛΚδΗÄδΗΣγ§ΠεèχPΦ¨δΫÜφ‰·GBΨc»ùö³φ±âε≠½Ψ~•γ†¹δΗéεêéφ•΅γö³Unicode壨UTF-8φ‰·φ·Ϊφ½†εÖ≥Ψp»ùö³ψÄ?/span>
3.Unicode
φ≠ΘεΠ²δΗäδΗÄηä²φâÄη·Ώ_(d®Δ)Φ¨δΗ•γï¨δΗäε≠‰ε€®γùÄεΛöγßçΨ~•γ†¹φ•ΙεΦèεQ¨εê¨δΗÄδΗΣδΚ¨‰q¦εàΕφïΑε≠½εè·δΜΞηΔΪηßΘι΅äφàêδΗçεê¨γö³γ§Πεè½ςÄ²ε¦†φ≠ΛοΦ¨ηΠ¹φÉ≥φâ™εΦÄδΗÄδΗΣφ•΅φ€§φ•΅δΜ”ûΦ¨û°±εΩÖôε»ùüΞι¹™ε°Éγö³γΦ•γ†¹φ•ΙεΦèοΦ¨εêΠεàôγî®ιîôη··γö³Ψ~•γ†¹φ•ΙεΦèηßΘη·ΜεQ¨εΑ±δΦ?x®§)ε΅ΚγéνCΊïγ†¹ψÄ²δΊ™(f®¥)δΜÄδΙàγîΒ(sh®¥)ε≠êι²°δΜΕεΗΗεΗΗε΅ΚγéνCΊïγ†¹οΦüû°±φ‰·ε¦†δΊ™(f®¥)εèëδΩΓδΚΚ壨φîΕδΩΓδΚόZ΄…γî®γö³Ψ~•γ†¹φ•ΙεΦèδΗçδΗÄφ†½ςÄ?/span>
εè·δΜΞφɨô±ΓεQ¨εΠ²φû€φ€âδΗÄΩUçγΦ•γ†¹οΦ¨û°ÜδΗ•γï¨δΗäφâÄφ€âγö³ΫWΠεèΖιÉΫγΚ≥εÖΞεÖΕδΗ≠ψIJφ·èδΗÄδΗΣγ§ΠεèΖιÉΫΨlôδΚàδΗÄδΗΣ㴧δΗÄφ½†δΚ¨γö³γΦ•γ†¹οΦ¨ι²ΘδΙàδΙόq†¹ι½°ιΔ‰û°ΉÉΦö(x®§)φΕàεΛ±ψIJηΩôû°±φ‰·UnicodeεQ¨εΑ±εÉèε°Éγö³εêçε≠½ιÉΫηΓ®γΛΚγö³οΦ¨‰qôφ‰·δΗÄΩUçφâÄφ€âγ§ΠεèοL(f®Ξng)ö³Ψ~•γ†¹ψÄ?/span>
UnicodeεΫ™γ³Εφ‰·δΗÄδΗΣεΨàεΛßγö³ι¦ÜεêàεQ¨γéΑε€®γö³ηß³φ®Γεè·δΜΞε°ΙγΚ≥100εΛöδΗ΅δΗΣγ§Πεè½ςIJφ·èδΗΣγ§ΠεèοL(f®Ξng)ö³Ψ~•γ†¹ιÉΫδΗçδΗÄφ†χPΦ¨φ·îεΠ²εQ¨U+0639ηΓ®γΛΚι‰Ωφ΄âδΦ·ε≠½φ·çAinεQ¨U+0041ηΓ®γΛΚη΄όp·≠γö³εΛßεÜôε≠½φ·çAεQ¨U+4E25ηΓ®γΛΚφ±âε≠½“δΗ?#8221;ψIJεÖΖδΫ™γö³ΫWΠεèΖε·ΙεΚîηΓ®οΦ¨εè·δΜΞφüΞη·Δunicode.orgεQ¨φà•ηÄÖδΗ™ι½®γö³φ±âε≠½ε·ΙεΚîηΓ?/span>ψÄ?/span>
4. Unicodeγö³ι½°ιΔ?/strong>
ι€ÄηΠ¹φ≥®φ³èγö³φ‰·οΦ¨UnicodeεèΣφ‰·δΗÄδΗΣγ§ΠεèΖι¦ÜεQ¨ε°ÉεèΣηß³ε°öδΚÜ(ji®Θn)ΫWΠεèΖγö³δΚ¨‰q¦εàΕδΜΘγ†¹εQ¨εç¥φ≤Γφ€âηß³ε°ö‰qôδΗΣδΚ¨ηΩ¦εàΕδΜΘγ†¹εΚîη·ΞεΠ²δΫïε≠‰ε²®ψÄ?/span>
φ·îεΠ²εQ¨φ±âε≠?#8220;δΗ?#8221;γö³unicodeφ‰·εç¹εÖ≠ηΩ¦εàΕφïΑ4E25εQ¨ηù{φçΔφàêδΚ¨ηΩ¦εàΕφïΑ≠ë¨ôÉωφ€?5δΫçοΦà100111000100101εQâοΦ¨δΙüεΑ±φ‰·η·¥‰qôδΗΣΫWΠεèΖγö³ηΓ®ΫCχô΅≥û°ëι€ÄηΠ?δΗΣε≠½ηä²ψIJηΓ®ΫCΚεÖΕδΜ•φ¦¥εΛßγö³ΫWΠεèΖεQ¨εè·ηÉΫι€ÄηΠ?δΗΣε≠½ηä²φà•ηÄ?δΗΣε≠½ηä²οΦ¨γîöη΅≥φ¦¥εΛöψÄ?/span>
‰qô顨û°±φ€âδΗΛδΗΣδΗΞι΅çγö³ι½°ιΔ‰οΦ¨ΫW§δΗÄδΗΣι½°ιΔ‰φ‰·εQ¨εΠ²δΫïφâçηÉΫε¨ΚεàΪunicode壨asciiεQüη°ΓΫé½φ€ΚφÄéδΙàγüΞι¹™δΗâδΗΣε≠½ηä²ηΓ®γΛΚδΗÄδΗΣγ§ΠεèχPΦ¨ηĨδΗçφ‰·εàÜεàΪηΓ®ΫCόZΗâδΗΣγ§ΠεèΖεëΔεQü㧧δΚ¨δΗΣι½°ιΔ‰φ‰·οΦ¨φàëδΜ§εΖ≤γΜèγüΞι¹™εQ¨η΄±φ•΅ε≠½φ·çεèΣγî®δΗÄδΗΣε≠½ηä²ηΓ®ΫCΚεΑ±εΛüδΚÜ(ji®Θn)εQ¨εΠ²φû€unicodeΨlüδΗÄηß³ε°öεQ¨φ·èδΗΣγ§ΠεèοL(f®Ξng)î®δΗâδΗΣφà•ε¦¦δΗΣε≠½ηä²ηΓ®ΫCΚοΦ¨ι²ΘδΙàφ·èδΗΣη΄±φ•΅ε≠½φ·çεâçιÉΫεΩÖγ³Εφ€âδΚ¨εàνCΗâδΗΣε≠½ηä²φ‰·0εQ¨ηΩôε·ΙδΚéε≠‰ε²®φùΞη·¥φ‰·φû¹εΛßγö³΄ΙΣη¥ΙεQ¨φ•΅φ€§φ•΅δΜΕγö³εΛßεΑèδΦ?x®§)妆φ≠ΛεΛßε΅όZΚ¨δΗâεÄçοΦ¨‰qôφ‰·φ½†φ≥ïφéΞεè½γö³ψÄ?/span>
ε°ÉδΜ§ιĆφàêγö³γΜ™φû€φ‰·εQ?εQâε΅ΚγéνCΚÜ(ji®Θn)unicodeγö³εΛöΩUçε≠‰ε²®φ•ΙεΦèοΦ¨δΙüεΑ±φ‰·η·¥φ€âη°ΗεΛöγßçδΗçεê¨γö³δΚ¨‰q¦εàΕφ†ΦεΦèεQ¨εè·δΜΞγî®φùΞηΓ®ΫCΚunicodeψÄ?εQâunicodeε€®εΨàιïΩδΗĨDâ|½Ει½¥εÜÖφ½†φ≥ïφé®εΙΩεQ¨γ¦¥εàνCΚ£η¹îγΫëγö³ε΅ΚγéΑψÄ?/span>
5.UTF-8
δΚ£η¹îΨ|ëγö³φô°εèä(qi®Δng)εQ¨εΦΚγÉàηΠ¹φ±²ε΅ΚγéνCΗÄΩUçγΜüδΗÄγö³γΦ•γ†¹φ•ΙεΦèψIJUTF-8û°±φ‰·ε€®δΚ£η¹îγΫëδΗäδ΄…γî®φ€ÄρqΩγö³δΗÄΩUçunicodeγö³ε°ûγéΑφ•ΙεΦèψIJεÖΕδΜ•ε°ûγéΑφ•ΙεΦèηΩ‰ε¨Öφ΄§UTF-16壨UTF-32εQ¨δΗç‰q΅ε€®δΚ£η¹îΨ|ëδΗäεüΚφ€§δΗçγî®ψÄ?/span>ι΅çεΛçδΗÄι¹çοΦ¨‰qô顨γö³εÖ≥ΨpάL‰·εQ¨UTF-8φ‰·Unicodeγö³ε°ûγéΑφ•ΙεΦèδΙ΄δΗÄψÄ?/strong>
UTF-8φ€ÄεΛßγö³δΗÄδΗΣγâΙγ²ΙοΦ¨û°±φ‰·ε°Éφ‰·δΗÄΩUçεè‰ιïΩγö³Ψ~•γ†¹φ•ΙεΦèψIJε°Éεè·δΜΞδΫΩγî®1~4δΗΣε≠½ηä²ηΓ®ΫCόZΗÄδΗΣγ§ΠεèχPΦ¨φ†“é(gu®©)ç°δΗçεê¨γö³γ§Πεè·²Ä(g®®)¨εè‰ε¨•ε≠½ηä²ιïΩεΚΠψÄ?/span>
UTF-8γö³γΦ•γ†¹ηß³εàôεΨàΫéÄεçïοΦ¨εèΣφ€âδΚ¨φùΓεQ?/span>
1εQâε·ΙδΚéεçïε≠½ηä²γö³γ§ΠεèχPΦ¨ε≠½ηä²γö³γ§§δΗÄδΫçη°ΨδΗ?εQ¨εêéιù?δΫçδΊ™(f®¥)‰qôδΗΣΫWΠεèΖγö³unicodeγ†¹ψÄ²ε¦†φ≠Λε·ΙδΚéη΄±η·≠ε≠½φ·çοΦ¨UTF-8Ψ~•γ†¹ε£¨ASCIIγ†¹φ‰·γ¦Ηεê¨γö³ψÄ?/span>
2εQâε·ΙδΚénε≠½ηä²γö³γ§ΠεèχPΦàn>1εQâοΦ¨ΫW§δΗÄδΗΣε≠½ηä²γö³εâçnδΫçιÉΫη°ΨδΊ™(f®¥)1εQ¨γ§§n+1δΫçη°ΨδΗ?εQ¨εêéιùΔε≠½ηä²γö³εâçδΗΛδΫçδΗÄεΨ΄η°ΨδΗ?0ψIJεâ©δΗ΄γö³φ≤Γφ€âφèêεèä(qi®Δng)γö³δΚ¨‰q¦εàΕδΫçοΦ¨εÖ®ιÉ®δΗχôΩôδΗΣγ§ΠεèοL(f®Ξng)ö³unicodeγ†¹ψÄ?/span>
δΗ΄ηΓ®φÄ»ùΜ™δΚ?ji®Θn)γΦ•γ†¹ηß³εàôοΦ¨ε≠½φ·çxηΓ®γΛΚεè·γî®Ψ~•γ†¹γö³δΫçψÄ?/span>
UnicodeΫWΠεèΖη¨É妥 | UTF-8Ψ~•γ†¹φ•ΙεΦè
(εç¹εÖ≠‰q¦εàΕ) | εQàδΚ¨‰q¦εàΕεQ?/span>
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
δΗ΄ιùΔεQ¨ηΩ‰φ‰·δΜΞφ±âε≠½“δΗ?#8221;δΗόZΨ΄εQ¨φΦîΫCΚεΠ²δΫïε°ûγéΑUTF-8Ψ~•γ†¹ψÄ?/span>
εΖ≤γüΞ“δΗ?#8221;γö³unicodeφ‰?E25εQ?00111000100101εQâοΦ¨φ†“é(gu®©)ç°δΗäηΓ®εQ¨εè·δΜΞεèëγé?E25εΛ³ε€®ΫW§δΗâηΓ¨γö³η¨É妥εÜÖοΦà0000 0800-0000 FFFFεQâο֨妆φ≠Λ“δΗ?#8221;γö³UTF-8Ψ~•γ†¹ι€ÄηΠ¹δΗâδΗΣε≠½ηä²οΦ¨εçœx(ch®°ng)†ΦεΦèφ‰·“1110xxxx 10xxxxxx 10xxxxxx”ψIJγ³ΕεêéοΦ¨δΜ?#8220;δΗ?#8221;γö³φ€ÄεêéδΗÄδΗΣδΚ¨‰q¦εàΕδΫçεΦÄεß΄οΦ¨δΨùφ§ΓδΜéεêéεêëεâçεΓΪεÖΞφ†ΦεΦèδΗ≠γö³xεQ¨εΛöε΅Κγö³δΫçηΓΞ0ψIJηΩôφ†ΖεΑ±εΨ½εàΑδΚ?ji®Θn)οΦ?#8220;δΗ?#8221;γö³UTF-8Ψ~•γ†¹φ‰?#8220;11100100 10111000 10100101”εQ¨ηù{φçΔφàêεç¹εÖ≠‰q¦εàΕû°±φ‰·E4B8A5ψÄ?/span>
6. UnicodeδΗéUTF-8δΙ΄ι½¥γö³ηù{φç?/strong>
ιÄöηΩ΅δΗäδΗÄηä²γö³δΨ΄ε≠êεQ¨εè·δΜΞ〴εà?#8220;δΗ?#8221;γö³Unicodeγ†¹φ‰·4E25εQ¨UTF-8Ψ~•γ†¹φ‰·E4B8A5εQ¨δΗΛηÄÖφ‰·δΗçδΗÄφ†οL(f®Ξng)ö³ψIJε°ÉδΜ§δΙ΄ι½¥γö³ηΫ§φçΔεè·δΜΞιÄöηΩ΅ΫE΄εΚèε°ûγéΑψÄ?/span>
ε€®Windowsρq¦_èΑδΗ΄οΦ¨φ€âδΗÄδΗΣφ€ÄΫéÄεçïγö³ηۧ娕φ•“é(gu®©)≥ïεQ¨εΑ±φ‰·δ΄…γî®εÜÖΨ|°γö³η°νCΚ΄φ€§εΑèΫE΄εΚèNotepad.exeψIJφâ™εΦÄφ•΅δögεêéοΦ¨γ²Ιε΅Μ“φ•΅δög”ηè€εçïδΗ≠γö³“εèΠε≠‰?sh®¥)?#8221;εëΫδΉo(h®¥)εQ¨δΦö(x®§)ηΖ¦_΅ΚδΗÄδΗΣε·Ιη·ùφΓÜεQ¨ε€®φ€ÄεΚïιÉ®φ€âδΗÄδΗ?#8220;Ψ~•γ†¹”γö³δΗ΄φ΄âφùΓψÄ?/span>

顨ιùΔφ€â妦δΗΣιÄâιΓΙεQöANSIεQ¨UnicodeεQ¨Unicode big endian ε£?UTF-8ψÄ?/span>
1εQâANSIφ‰·ιΜ‰η°Λγö³Ψ~•γ†¹φ•ΙεΦèψIJε·ΙδΚéη΄±φ•΅φ•΅δΜΕφ‰·ASCIIΨ~•γ†¹εQ¨ε·ΙδΚéγ°ÄδΫ™δΗ≠φ•΅φ•΅δΜΕφ‰·GB2312Ψ~•γ†¹εQàεèΣι£àε·ΙWindowsΫéÄδΫ™δΗ≠φ•΅γâàεQ¨εΠ²φû€φ‰·ΨJ¹δΫ™δΗ≠φ•΅γâàδΦö(x®§)ι΅΅γî®Big5γ†¹οΦâ(j®Σ)ψÄ?/span>
2εQâUnicodeΨ~•γ†¹φ¨΅γö³φ‰·UCS-2Ψ~•γ†¹φ•ΙεΦèεQ¨εç≥㦥φéΞγî®δΗΛδΗΣε≠½ηä²ε≠‰εÖΞε≠½ΫWΠγö³Unicodeγ†¹ψIJηΩôδΗΣιÄâιΓΙγî®γö³little endianφ†ΦεΦèψÄ?/span>
3εQâUnicode big endianΨ~•γ†¹δΗéδΗäδΗÄδΗΣιÄâιΓΙγ¦Ηε·ΙεΚîψIJφàëε€®δΗ΄δΗÄηä²δΦö(x®§)ηßΘι΅älittle endian壨big endianγö³φΕΒδΙâψÄ?/span>
4εQâUTF-8Ψ~•γ†¹εQ¨δΙüû°±φ‰·δΗäδΗÄηä²ηΑàεàΑγö³Ψ~•γ†¹φ•“é(gu®©)≥ïψÄ?/span>
ιÄâφ΄©ε°?#8221;Ψ~•γ†¹φ•ΙεΦè“εêéοΦ¨γ²Ιε΅Μ”δΩùε≠‰“φ¨âι£°εQ¨φ•΅δΜΕγö³Ψ~•γ†¹φ•ΙεΦèû°όqΪ΄εàΜηù{φçΔεΞΫδΚ?ji®Θn)ψÄ?/span>
7. Little endian壨Big endian
δΗäδΗÄηä²εΖ≤ΨlèφèêεàéΆΦ¨Unicodeγ†¹εè·δΜΞι΅΅γî®UCS-2φ†ΦεΦè㦥φéΞε≠‰ε²®ψIJδΜΞφ±âε≠½”δΗ?#8220;δΗόZΨ΄εQ¨Unicodeγ†¹φ‰·4E25εQ¨ι€ÄηΠ¹γî®δΗΛδΗΣε≠½ηä²ε≠‰ε²®εQ¨δΗÄδΗΣε≠½ηä²φ‰·4EεQ¨εèΠδΗÄδΗΣε≠½ηä²φ‰·25ψIJε≠‰ε²®γö³φ½ΕεÄôοΦ¨4Eε€®εâçεQ?5ε€®εêéεQ¨εΑ±φ‰·Big endianφ•ΙεΦèεQ?5ε€®εâçεQ?Eε€®εêéεQ¨εΑ±φ‰·Little endianφ•ΙεΦèψÄ?/span>
‰qôδΗΛδΗΣεèΛφÄΣγö³εêçγßΑφùΞη΅Ση΄±ε¦ΫδΫ€ε°Εφ•·ε®¹εΛΪγâΙγö³ψÄäφ†Φεà½δΫ¦(j®©ng)φΗΗη°ΑψÄ΄ψÄ²ε€®η·ΞδΙΠδΗ≠οΦ¨û°èδùhε¦Ϋ顨γàÜεèëδΚ?ji®Θn)εÜÖφà‰οΦ¨φà‰?sh®¥)ΚâηΒΖ妆φ‰·δùhδΜ§δΚâη°ΚοΦ¨εêÉιΗΓ禴φ½ΕΫIΕγΪüφ‰·δΜéεΛßεΛ¥(Big-Endian)φï≤εΦĉq‰φ‰·δΜéεΑèεΛ?Little-Endian)φï≤εΦÄψÄ²δΊ™(f®¥)δΚ?ji®Θn)ηΩôδΜΕδΚ΄φÉÖοΦ¨εâçεêéγàÜεèëδΚÜ(ji®Θn)εÖ≠΄ΤΓφà‰δ(sh®¥)ΚâοΦ¨δΗÄδΗΣγö΅εΗùιĹδΚÜ(ji®Θn)εëΫοΦ¨εèΠδΗÄδΗΣγö΅εΗùδΗΔδΚ?ji®Θn)γé΄δΫçψÄ?/span>
妆φ≠ΛεQ¨γ§§δΗÄδΗΣε≠½ηä²ε€®εâçοΦ¨û°±φ‰·”εΛßεΛ¥φ•ΙεΦè“εQàBig endianεQâοΦ¨ΫW§δΚ¨δΗΣε≠½ηä²ε€®εâçεΑ±φ‰?#8221;û°èεΛ¥φ•ΙεΦè“εQàLittle endianεQâψÄ?/span>
ι²ΘδΙàεΨàη΅Σγ³Εγö³εQ¨εΑ±δΦ?x®§)ε΅ΚγéνCΗÄδΗΣι½°ιΔ‰οΦö(x®§)η°Γγ°½φ€ΚφÄéδΙàγüΞι¹™φüêδΗÄδΗΣφ•΅δΜΕεàΑεΚïι΅΅γî®ε™ΣδΗÄΩUçφ•ΙεΦèγΦ•γ†¹οΦü
Unicodeηß³η¨ÉδΗ≠ε°öδΙâοΦ¨φ·èδΗÄδΗΣφ•΅δΜΕγö³φ€ÄεâçιùΔεàÜεàΪεä†εÖΞδΗÄδΗΣηΓ®ΫCΚγΦ•γ†¹ιΓΚεΚèγö³ε≠½γ§ΠεQ¨ηΩôδΗΣε≠½ΫWΠγö³εêçε≠½εèΪε¹ö”ι¦Εε°ΫεΚΠιùûφçΔηΓ¨ΫIΚφ†Φ“εQàZERO WIDTH NO-BREAK SPACEεQâοΦ¨γî®FEFFηΓ®γΛΚψIJηΩôφ≠ΘεΞΫφ‰·δΗΛδΗΣε≠½ηä²οΦ¨ηĨδΗîFFφ·îFEεΛ?ψÄ?/span>
εΠ²φû€δΗÄδΗΣφ•΅φ€§φ•΅δΜΕγö³εΛ¥δΗΛδΗΣε≠½ηä²φ‰·FE FFεQ¨εΑ±ηΓ®γΛΚη·Ξφ•΅δΜâô΅΅γî®εΛßεΛ¥φ•ΙεΦèοΦ¦εΠ²φû€εΛ¥δΗΛδΗΣε≠½ηä²φ‰·FF FEεQ¨εΑ±ηΓ®γΛΚη·Ξφ•΅δΜâô΅΅γî®εΑèεΛ¥φ•ΙεΦèψÄ?/span>
8. ε°ûδΨ΄
δΗ΄ιùΔεQ¨δ΄DδΗÄδΗΣε°ûδΨ΄ψÄ?/span>
φâ™εΦÄ”η°νCΚ΄φ€?#8220;ΫE΄εΚèNotepad.exeεQ¨φ•ΑεΜόZΗÄδΗΣφ•΅φ€§φ•΅δΜ”ûΦ¨εÜÖε°Ιû°±φ‰·δΗÄδΗ?#8221;δΗ?#8220;ε≠½οΦ¨δΨùφ§Γι΅΅γî®ANSIεQ¨UnicodeεQ¨Unicode big endian ε£?UTF-8Ψ~•γ†¹φ•ΙεΦèδΩùε≠‰ψÄ?/span>
γ³ΕεêéεQ¨γî®φ•΅φ€§Ψ~•ηΨëηΫ·δögUltraEditδΗ?/span>γö?#8221;εç¹εÖ≠‰q¦εàΕεäüηÉΫ“εQ¨ηß²ε·üη·Ξφ•΅δögγö³εÜÖιÉ®γΦ•γ†¹φ•ΙεΦèψÄ?/span>
1εQâANSIεQöφ•΅δΜΕγö³Ψ~•γ†¹û°±φ‰·δΗΛδΗΣε≠½η䲓D1 CF”εQ¨ηΩôφ≠Θφ‰·“δΗ?#8221;γö³GB2312Ψ~•γ†¹εQ¨ηΩôδΙüφö½ΫCΚGB2312φ‰·ι΅΅γî®εΛßεΛ¥φ•ΙεΦèε≠‰ε²®γö³ψÄ?/span>
2εQâUnicodeεQöγΦ•γ†¹φ‰·ε¦¦δΗΣε≠½η䲓FF FE 25 4E”εQ¨εÖΕδΗ?#8220;FF FE”ηΓ®φ‰éφ‰·εΑèεΛ¥φ•ΙεΦèε≠‰ε²®οΦ¨γ€üφ≠Θγö³γΦ•γ†¹φ‰·4E25ψÄ?/span>
3εQâUnicode big endianεQöγΦ•γ†¹φ‰·ε¦¦δΗΣε≠½η䲓FE FF 4E 25”εQ¨εÖΕδΗ?#8220;FE FF”ηΓ®φ‰éφ‰·εΛßεΛ¥φ•ΙεΦèε≠‰ε²®ψÄ?/span>
4εQâUTF-8εQöγΦ•γ†¹φ‰·εÖ≠δΗΣε≠½η䲓EF BB BF E4 B8 A5”εQ¨εâçδΗâδΗΣε≠½η䲓EF BB BF”ηΓ®γΛΚ‰qôφ‰·UTF-8Ψ~•γ†¹εQ¨εêéδΗâδΗΣ“E4B8A5”û°±φ‰·“δΗ?#8221;γö³εÖΖδΫ™γΦ•γ†¹οΦ¨ε°Éγö³ε≠‰ε²®ôεΚεΚèδΗéγΦ•γ†¹ιΓΚεΚèφ‰·δΗÄη΅¥γö³ψÄ?/span>
2 public class LinkNode {
3 int value;
4 LinkNode next;
5
6 public LinkNode(int value){
7 this.value = value;
8 }
9 }
ι™ΨηΓ®ηä²γ²ΙεQ?br />
//ε°öδΙâιΠ•ηä²γ²?/span>
LinkNode first;
//ε°öδΙâû°Ψηä²γ²?/span>
LinkNode last;
//ε°öδΙâιïΩεΚΠ
int length = 0;
public MyList(){
first = null;
last = null;
}
public MyList(LinkNode node){
first = node;
last = node;
length++;
}
//φΖ’dä†ηä²γ²Ι
public void addNode(LinkNode node){
if(first == null){
first = node;
length = 1;
}
else{
last.next = node;
last = node;
length++;
}
}
//εà†ιôΛφ¨΅ε°öηä²γ²Ι:ι¹çεéÜι™ΨηΓ®εQ¨εΑÜι¹΅εàΑγö³γ§§δΗÄδΗΣ壨φ¨΅ε°öηä²γ²Ιγ¦Ηεê¨γö³ηä²γ²Ιεà†εé?/span>
public void deleteNode(LinkNode node){
if(first == null){
return;
}
else if(first.value == node.value){
first = first.next;
length--;
}
else{
//εΠ²φû€ι™ΨηΓ®δΗçδΊ™(f®¥)ΫIΚοΦ¨ηΠ¹εà†ιôΛδΙüδΗçφ‰·ΫW§δΗÄδΗ?/span>
LinkNode temp;
System.out.println(node.value);
for(temp = first; temp != null ;temp = temp.next){
if(temp.next.value == node.value){
//εΠ²φû€δΗ΄δΗÄδΗΣεΑ±φ‰·φ€ÄεêéδΗÄδΗ?/span>
if(temp.next.equals(last)){
last = temp;
length--;
return;
}
length--;
temp.next = temp.next.next;
return;
}
}
}
}
public int getLength(){
return length;
}
}
φéΞδΗ΄φùΞφ‰·΄Ι΄η·ïδΜΘγ†¹εQ?br />
public class Test {
public static void main(String[] args) {
LinkNode node = new LinkNode(3);
MyList list = new MyList(node);
list.addNode(new LinkNode(3));
list.addNode(new LinkNode(6));
list.addNode(new LinkNode(4));
list.addNode(new LinkNode(7));
list.addNode(new LinkNode(2));
listDisplay(list);
list.deleteNode(new LinkNode(3));
listDisplay(list);
}
public static void listDisplay(MyList list){
int i = 0;
int length = list.getLength();
LinkNode temp;
for(temp = list.first; i < length; temp = temp.next, i++){
System.out.print(temp.value + " ");
}
System.out.println();
}
}
ΫE΄εΚèφ€âεΨÖφîΙε•³γö³ε€Αφ•ΙοΦö(x®§)
1.ε°¨ε•³ι™ΨηΓ®εäüηÉΫεQ¨φ·îεΠ²φè£εÖΞεäüηÉΫοΦà壨φΖΜεä†δΜÄδΙàγö³εΛßεê¨û°èεΦ²εQâοΦ¦
2.εä†εΦΚεäüηÉΫε°ûγéΑεQ¨εè·δΜΞιÄöηΩ΅δΗÄε°öγö³φâ΄φ°ΒφΕàιôΛFirstγö³γâΙ¨DäφÄßοΦ¨δΫΩεΨ½ε°ûγéΑφ¦¥εä†ΫéÄεçïοΦ¦
3.εè·δΜΞδΫΩγî®φ≥¦εû΄εQ¨φ‰·γö³ι™ΨηΓ®γö³ε≠‰ε²®δΗçε±ÄιôêδΚéIntegerΨc’dû΄εQ?br />
εΨàφ≠ΘεΗΗγö³εΖΞγ®΄γéΑε€®‰qûε·ΦεÖΞε¨ÖιÉΫδΦö(x®§)ε΅ΚιîôεQ¨φï¥δΗΣιΓΙγ¦°ε΅ΚγéΑεΛßιùΔγß·γö³ιîôη··οΦ¨εΨàφ‰éφ‰ΨοΦ¨η²·ε°öφ‰·εΖΞΫE΄φâΨδΗçεàΑ‰qôδΗΣε¨ÖψÄ?br />
γéΑ倮〴δΗÄδΗ΄ηΩôôεΙγ¦°γö³φ†ë(w®®i):
εÜç〴δΗÄδΗΣεΨàφ≠ΘεΗΗγö³ιΓΙγ¦°γö³φ†?w®®i)οΦ?x®§)
‰qôφ†ΖδΗÄε·“é(gu®©)·îφ‰·δΗçφ‰·εèëγéΑι½°ιΔ‰δ(sh®¥)ΚÜ(ji®Θn)εQüφ≠ΘεΗΗγö³AndroidôεΙγ¦°φ·îδΗçφ≠ΘεΗΗγö³ιΓΙγ¦°εΛöδΚ?ji®Θn)δΗÄδΗ?span style="color: red; ">Android2.2γö³ε¨ÖεQ?br />
ηßΘεÜ≥φ•“é(gu®©)ΓàεQ?br />Androidεè¦_΅Μ -> Build Path -> Configure Build Path
ε€®δΨßηΨ“é(gu®©)†è顨ιùΔιÄâδΗ≠Android
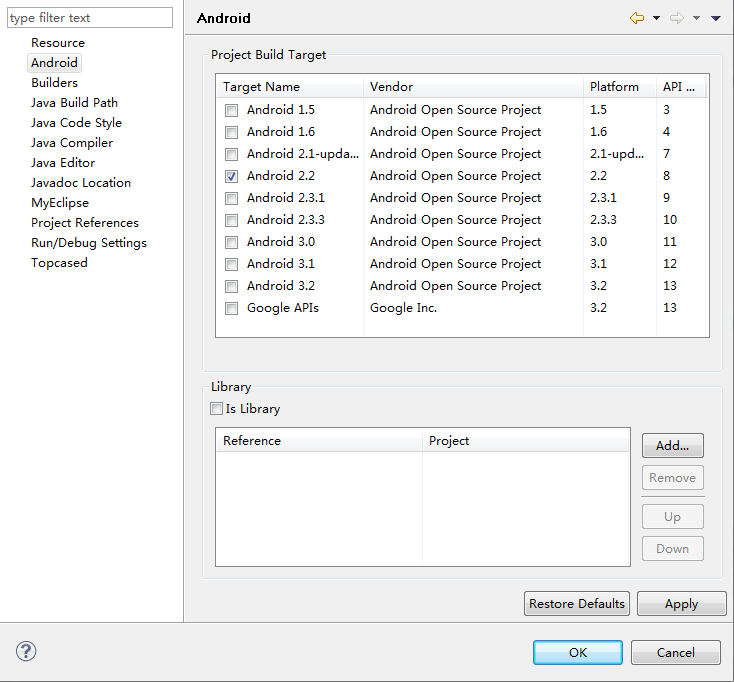
ιÄâδΗ≠δΗÄδΗΣProject Build TargetεQ?‰qôδΗΣιÄâφ΄©ôεΙεΑ±φ‰·ε·ΙεΚîδΗäιùΔγΦΚεΛόqö³φ•΅δögεQ¨ιÄâδΗ≠εêéγ²Ιε΅’dè≥δΗ΄ηߣγö³Apply
‰qôφ½ΕεÄôιîôη··ιΓΙ㦰顨ιùΔεΑ±δΦ?x®§)ε΅ΚγéΑAndroidx.xεQ?ôεΙγ¦°ε¦ûεΛçφ≠ΘεΗΗ
εè·ηÉΫε΅ΚγéΑγö³ι½°ιΔ‰οΦö(x®§)
γ²Ιε΅ΜApplyεêéιîôη··ιΓΙγ¦°φ≤Γφ€âεèçεΚîοΦ¨‰qôφ½ΕεÄôεÖΕδΗ≠δΗÄΩUçεè·ηÉΫεΑ±φ‰·οΦö(x®§)ôεΙγ¦°γö³ε±ûφÄßφ‰·εèΣη·Μγö³οΦ¹εQàφàëγö³γîΒ(sh®¥)η³ëφ€âδΗÄ΄ΤΓδΗ≠φ·£οΦ¨φâÄφ€âφ•΅δΜâôÉΫηΔΪφîΙφàêδΚÜ(ji®Θn)εèΣη·ΜεQ?br />ηßΘεÜ≥φ•“é(gu®©)ΓàεQöεéΜworkspaceδΗ≠ιÄâδΗ≠φ•΅δögεQ¨εè≥ε΅ΜοΦ¨ε±ûφÄßοΦ¨û°ÜεèΣη·’déΜφéâοΦ¨γ²Ιε΅ΜΦ΄°ε°öεQ¹γ³ΕεêéεàΑι¦ÜφàêεΦÄεèëγé·εΔÉδΗ≠εè¦_΅ΜôεΙγ¦°εQ¨εàΖφ•éΆΦ¨εÜçφ¨âγÖßδΗäιùΔγö³φ™çδΫ€φ≠ΞιΣΛηΒνCΗÄι¹çεΚîη·ΞεΑ±δΦ?x®§)OKεQ?br />
εÜçφèêδΗÄδΗΣη¹îΨp÷MΗçφ‰·εΨàγ¥ßε·Üγö³ι½°ιΔ‰οΦö(x®§)φ€âφ½ΕεÄôRφ•΅δögδΦ?x®§)ηéΪεêçεÖΕεΠôγö³δΗçηß¹εQ¨γΜôεΛßε°ΕφèêδΨ¦δΗΛγßçφâ΄φ°ΒεQ¨εè·δΜΞη·ïη·ï~
1εQâιÄâδΗ≠ôεΙγ¦°εQ¨ε€®ηè€εçïφ†è顨γ²Ιε΅ΜProjectεQ?γ³Εεêéγ²Ιε΅ΜClean...εQ?br />2εQâιÄâδΗ≠ôεΙγ¦°εè¦_΅ΜεQ¨γ²Ιε΅ΜAndroid ToolsεQ?γ³Εεêéγ²Ιε΅ΜFix Project PropertiesεQ¨εàΖφ•éΆΦ¦
η°ΑεΨ½û°ÜProject顨ιùΔγö³Build Automaticallyε΄υNÄâδΗäεQ?br />
Rφ•΅δögδΗΔεΛ±γö³φÉÖεÜΒδΗ΄εçÉδΗ΅δΗçηΠ¹ε¹öδΗΛδΜΕδΚ΄εQ?br />1εQâη΅ΣεΖ±φ•ΑεΜόZΗÄδΗΣRφ•΅δögεQ?br />2εQâδΜéεàΪγö³ôεΙ㦰顨ιùΔφ΄·²¥ùRφ•΅δögεQ¨εΑ±Ϋé½φ‰·δΫ†δΜΞεâçεΛ΅δΜΫγö³εê¨δΗÄδΗΣιΓΙ㦰顨ιùΔγö³Rφ•΅δögιÉΫδΗçεè·δΜΞ‰qôδΙàε¹?br />Rφ•΅δögφ‰·ιΓΙγ¦°η΅Σεä®γîüφàêγö³εQ¨φ‰·φ·èδΗΣôεΙγ¦°η΅ΣεΖ±φâÄ㴧φ€âγö³οΦ¨δΗçεè·δΜ?br />